学术论文GPT源码解读:从chatpaper、chatwithpaper到gpt_academic
前言
之前7月中旬,我曾在微博上说准备做“20个LLM大型项目的源码解读”

针对这个事,目前的最新情况是
- 已经做了的:LLaMA、Alpaca、ChatGLM-6B、deepspeedchat、transformer、langchain、langchain-chatglm知识库
- 准备做的:chatpaper、deepspeed、Megatron-LM
- 再往后则:BERT、GPT、pytorch、chatdoctor、baichuan、BLOOM/BELLE、Chinese LLaMA、PEFT BLIP2 llama.cpp
总之,够未来半年忙了。为加快这个事情的进度,本文解读两个关于学术论文的GPT(由于我司每周都有好几个或为申博、或为评职称、或为毕业而报名论文1V1发表辅导的,比如中文期刊、EI会议、ei期刊/SCI等等,所以对这个方向一直都是高度关注,我司也在做类似的LLM产品,敬请期待)
- 一个是chatpaper:https://github.com/kaixindelele/ChatPaper
- 一个是gpt_academic:https://github.com/binary-husky/gpt_academic
我把这两个项目的结构做了拆解/解析,且基本把原有代码的每一行都补上了注释,如果大家对任何一行代码有疑问,可以随时在本文评论区留言,我会及时做补充说明
第一部分 ChatPaper:论文对话、总结、翻译
ChatPaper的自身定位是全流程加速科研:论文总结+专业级翻译+润色+审稿+审稿回复,因为论文更多是PDF的格式,故针对PDF的对话、总结、翻译,便不可避免的涉及到PDF的解析
1.1 ChatPaper/ChatReviewerAndResponse
1.1.1 对PDF的解析:ChatReviewerAndResponse/get_paper.py
// 待更
1.1.2 论文审查:ChatReviewerAndResponse/chat_reviewer.py
使用OpenAI的GPT模型进行论文审查的脚本。它首先定义了一个Reviewer类来处理审查工作,然后在if __name__ == '__main__':语句下使用argparse处理命令行参数,并调用chat_reviewer_main函数来开始审查过程
- 导入模块:与第一段代码相似,但新增了一些库,如jieba、tenacity等
- 命名元组定义:用于保存与论文审稿相关的参数
ReviewerParams = namedtuple("ReviewerParams",["paper_path","file_format","research_fields","language"], ) - 判断文本中是否包含中文:
def contains_chinese(text):for ch in text:if u'\u4e00' <= ch <= u'\u9fff':return Truereturn False - 插入句子到文本
主要功能是在给定文本的每隔一定数量的单词或中文字符后插入一个指定的句子。如果文本行包含中文字符,则使用jieba分词工具来切分中文,否则使用空格来切分:def insert_sentence(text, sentence, interval):# 将输入文本按换行符分割成行lines = text.split('\n')# 初始化一个新的行列表new_lines = []# 遍历每一行for line in lines:# 检查行中是否包含中文字符if contains_chinese(line):# 如果是中文,使用jieba分词工具进行分词words = list(jieba.cut(line))# 定义分隔符为空字符(对于中文分词)separator = ''else:# 如果不包含中文,按空格分割行words = line.split()# 定义分隔符为空格(对于英文或其他非中文语言)separator = ' '# 初始化一个新的单词列表new_words = []# 初始化一个计数器count = 0# 遍历当前行的每一个单词for word in words:# 将当前单词添加到新的单词列表new_words.append(word)# 计数器增加count += 1# 检查是否达到了插入句子的间隔if count % interval == 0:# 在达到指定间隔时,将要插入的句子添加到新的单词列表new_words.append(sentence)# 将新的单词列表连接起来,并添加到新的行列表new_lines.append(separator.join(new_words))# 将新的行列表连接起来,返回结果return '\n'.join(new_lines) - 论文审稿类:定义了一个Reviewer类,包含以下功能:
第一阶段审稿:先是基于论文标题和摘要,选择要审稿的部分
然后分别实现两个函数# 定义Reviewer类 class Reviewer:# 初始化方法,设置属性def __init__(self, args=None):if args.language == 'en':self.language = 'English'elif args.language == 'zh':self.language = 'Chinese'else:self.language = 'Chinese' # 创建一个ConfigParser对象self.config = configparser.ConfigParser()# 读取配置文件self.config.read('apikey.ini')# 获取某个键对应的值 self.chat_api_list = self.config.get('OpenAI', 'OPENAI_API_KEYS')[1:-1].replace('\'', '').split(',')self.chat_api_list = [api.strip() for api in self.chat_api_list if len(api) > 5]self.cur_api = 0self.file_format = args.file_format self.max_token_num = 4096self.encoding = tiktoken.get_encoding("gpt2")def validateTitle(self, title):# 修正论文的路径格式rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'new_title = re.sub(rstr, "_", title) # 替换为下划线return new_title
一个stage_1,主要功能是为了与GPT-3模型进行对话,获取模型对于文章的两个最关键部分的选择意见
一个chat_review,主要功能是调用GPT-3模型进行论文审稿,对输入的文章文本进行审查,并按照预定格式生成审稿意见def stage_1(self, paper):# 初始化一个空列表,用于存储生成的HTML内容htmls = []# 初始化一个空字符串,用于存储文章的标题和摘要text = ''# 添加文章的标题text += 'Title: ' + paper.title + '. '# 添加文章的摘要text += 'Abstract: ' + paper.section_texts['Abstract']# 计算文本的token数量text_token = len(self.encoding.encode(text))# 判断token数量是否超过最大token限制的一半减去800if text_token > self.max_token_num/2 - 800:input_text_index = int(len(text)*((self.max_token_num/2)-800)/text_token)# 如果超出,则截取文本以满足长度要求text = text[:input_text_index]# 设置OpenAI API的密钥openai.api_key = self.chat_api_list[self.cur_api]# 更新当前使用的API索引self.cur_api += 1# 如果当前API索引超过API列表的长度,则重置为0self.cur_api = 0 if self.cur_api >= len(self.chat_api_list)-1 else self.cur_api# 创建与GPT-3的对话消息messages = [{"role": "system","content": f"You are a professional reviewer in the field of {args.research_fields}. "f"I will give you a paper. You need to review this paper and discuss the novelty and originality of ideas, correctness, clarity, the significance of results, potential impact and quality of the presentation. "f"Due to the length limitations, I am only allowed to provide you the abstract, introduction, conclusion and at most two sections of this paper."f"Now I will give you the title and abstract and the headings of potential sections. "f"You need to reply at most two headings. Then I will further provide you the full information, includes aforementioned sections and at most two sections you called for.\n\n"f"Title: {paper.title}\n\n"f"Abstract: {paper.section_texts['Abstract']}\n\n"f"Potential Sections: {paper.section_names[2:-1]}\n\n"f"Follow the following format to output your choice of sections:"f"{{chosen section 1}}, {{chosen section 2}}\n\n"},{"role": "user", "content": text},]# 调用OpenAI API与GPT-3进行对话response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages,)# 初始化一个空字符串,用于存储模型的回复result = ''# 遍历模型的回复,将其添加到结果字符串中for choice in response.choices:result += choice.message.content# 打印模型的回复print(result)# 返回模型的回复,将其分割为多个部分return result.split(',')def chat_review(self, text):# 设置OpenAI API的密钥openai.api_key = self.chat_api_list[self.cur_api]# 更新当前使用的API密钥索引self.cur_api += 1# 如果当前API密钥索引超过API密钥列表的长度,则将其重置为0self.cur_api = 0 if self.cur_api >= len(self.chat_api_list)-1 else self.cur_api# 定义用于审稿提示的token数量review_prompt_token = 1000# 计算输入文本的token数量text_token = len(self.encoding.encode(text))# 计算输入文本的截取位置input_text_index = int(len(text)*(self.max_token_num-review_prompt_token)/text_token)# 截取文本并添加前缀input_text = "This is the paper for your review:" + text[:input_text_index]# 从'ReviewFormat.txt'文件中读取审稿格式with open('ReviewFormat.txt', 'r') as file:review_format = file.read()# 创建与GPT-3的对话消息messages=[{"role": "system", "content": "You are a professional reviewer in the field of "+args.research_fields+". Now I will give you a paper. You need to give a complete review opinion according to the following requirements and format:"+ review_format +" Please answer in {}.".format(self.language)},{"role": "user", "content": input_text},]# 调用OpenAI API与GPT-3进行对话response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages,)# 初始化一个空字符串,用于存储模型的回复result = ''# 遍历模型的回复,将其添加到结果字符串中for choice in response.choices:result += choice.message.content# 在结果中插入特定的句子,警告不允许复制result = insert_sentence(result, '**Generated by ChatGPT, no copying allowed!**', 15)# 追加伦理声明result += "\n\n⚠伦理声明/Ethics statement:\n--禁止直接复制生成的评论用于任何论文审稿工作!\n--Direct copying of generated comments for any paper review work is prohibited!"# 打印分隔符和结果print("********"*10)print(result)print("********"*10)# 打印相关的token使用信息和响应时间print("prompt_token_used:", response.usage.prompt_tokens)print("completion_token_used:", response.usage.completion_tokens)print("total_token_used:", response.usage.total_tokens)print("response_time:", response.response_ms/1000.0, 's')# 返回模型生成的审稿意见return resultdef review_by_chatgpt(self, paper_list):# 创建一个空列表用于存储每篇文章审稿后的HTML格式内容htmls = []# 遍历paper_list中的每一篇文章for paper_index, paper in enumerate(paper_list):# 使用第一阶段审稿方法选择文章的关键部分sections_of_interest = self.stage_1(paper)# 初始化一个空字符串用于提取文章的主要部分text = ''# 添加文章的标题text += 'Title:' + paper.title + '. '# 添加文章的摘要text += 'Abstract: ' + paper.section_texts['Abstract']# 查找并添加“Introduction”部分intro_title = next((item for item in paper.section_names if 'ntroduction' in item.lower()), None)if intro_title is not None:text += 'Introduction: ' + paper.section_texts[intro_title]# 同样地,查找并添加“Conclusion”部分conclusion_title = next((item for item in paper.section_names if 'onclusion' in item), None)if conclusion_title is not None:text += 'Conclusion: ' + paper.section_texts[conclusion_title]# 遍历sections_of_interest,添加其他感兴趣的部分for heading in sections_of_interest:if heading in paper.section_names:text += heading + ': ' + paper.section_texts[heading]# 使用ChatGPT进行审稿,并得到审稿内容chat_review_text = self.chat_review(text=text)# 将审稿的文章编号和内容添加到htmls列表中htmls.append('## Paper:' + str(paper_index+1))htmls.append('\n\n\n')htmls.append(chat_review_text)# 获取当前日期和时间,并转换为字符串格式date_str = str(datetime.datetime.now())[:13].replace(' ', '-')try:# 创建输出文件夹export_path = os.path.join('./', 'output_file')os.makedirs(export_path)except:# 如果文件夹已存在,则不执行任何操作pass# 如果是第一篇文章,则写模式为'w',否则为'a'mode = 'w' if paper_index == 0 else 'a'# 根据文章标题和日期生成文件名file_name = os.path.join(export_path, date_str+'-'+self.validateTitle(paper.title)+"."+self.file_format)# 将审稿内容导出为Markdown格式并保存self.export_to_markdown("\n".join(htmls), file_name=file_name, mode=mode)# 清空htmls列表,为下一篇文章做准备htmls = [] - 主程序部分:
定义了一个chat_reviewer_main 函数,该函数创建了一个Reviewer对象,并对指定路径中的PDF文件进行审稿
主程序中定义了命令行参数解析,并调用了chat_reviewer_main 函数def chat_reviewer_main(args): reviewer1 = Reviewer(args=args)# 开始判断是路径还是文件: paper_list = [] if args.paper_path.endswith(".pdf"):paper_list.append(Paper(path=args.paper_path)) else:for root, dirs, files in os.walk(args.paper_path):print("root:", root, "dirs:", dirs, 'files:', files) #当前目录路径for filename in files:# 如果找到PDF文件,则将其复制到目标文件夹中if filename.endswith(".pdf"):paper_list.append(Paper(path=os.path.join(root, filename))) print("------------------paper_num: {}------------------".format(len(paper_list))) [print(paper_index, paper_name.path.split('\\')[-1]) for paper_index, paper_name in enumerate(paper_list)]reviewer1.review_by_chatgpt(paper_list=paper_list)
在主程序中增加了审稿时间的计算功能if __name__ == '__main__': parser = argparse.ArgumentParser()parser.add_argument("--paper_path", type=str, default='', help="path of papers")parser.add_argument("--file_format", type=str, default='txt', help="output file format")parser.add_argument("--research_fields", type=str, default='computer science, artificial intelligence and reinforcement learning', help="the research fields of paper")parser.add_argument("--language", type=str, default='en', help="output lauguage, en or zh")reviewer_args = ReviewerParams(**vars(parser.parse_args()))start_time = time.time()chat_reviewer_main(args=reviewer_args)print("review time:", time.time() - start_time)
// 待更
相关文章:
学术论文GPT源码解读:从chatpaper、chatwithpaper到gpt_academic
前言 之前7月中旬,我曾在微博上说准备做“20个LLM大型项目的源码解读” 针对这个事,目前的最新情况是 已经做了的:LLaMA、Alpaca、ChatGLM-6B、deepspeedchat、transformer、langchain、langchain-chatglm知识库准备做的:chatpa…...
)
单链表(C语言版)
单链表:理解、实现与应用 单链表(Singly Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素,并通过节点之间的链接建立起它们的关系。每个节点包含一个数据元素和一个指向下一个节点的指针。相比于…...
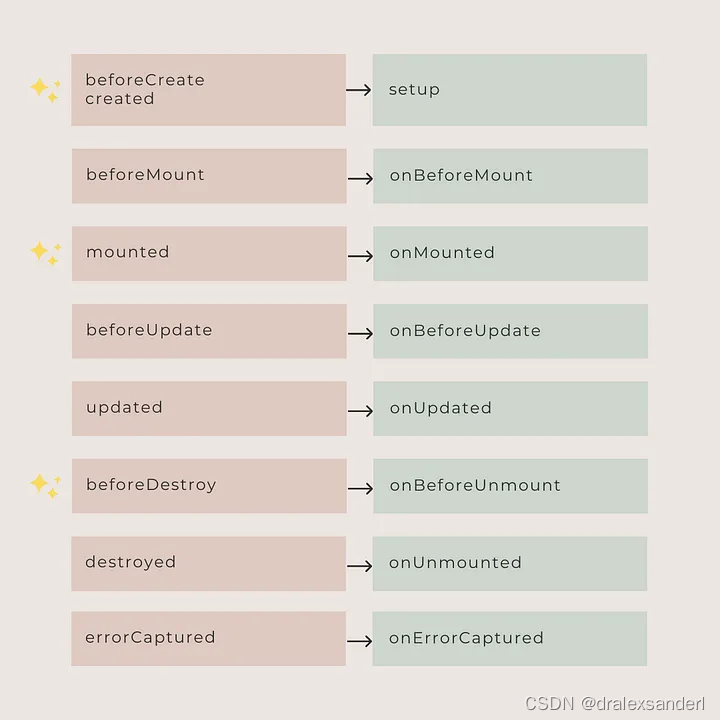
初学vue3时应该注意的几个问题
初学vue3时应该注意的几个问题 声明响应式 响应式数据的声明在vue2的时候很简单,在data中声明就行了。但现在可以使用多个方式。 reactive用于声明Object, Array, Map, Set; ref用于声明String, Number, Boolean 使用reactive来声明基础数据类型(Str…...

基于Selenium技术方案的爬虫入门实践
通过爬虫技术抓取网页,动态加载的数据或包含 JavaScript 的页面,需要使用一些特殊的技术和工具。以下是一些常用的技术方法: 使用浏览器模拟器:使用像 Selenium、PhantomJS 或其他类似工具可以模拟一个完整的浏览器环境࿰…...

【C++入门到精通】C++入门 —— vector (STL)
阅读导航 前言一、vector简介1. 概念2. 特点 二、vector的使用1.vector 构造函数2. vector 空间增长问题⭕resize 和 reserve 函数 3. vector 增删查改⭕operator[] 函数 三、迭代器失效温馨提示 前言 前面我们讲了C语言的基础知识,也了解了一些数据结构࿰…...

git简单使用
1.在 远端仓库创建好仓库 2.在本地中创建仓库 mkdir 仓库名 cd 仓库名 3.初始化(可以省略) git init 4.添加远端仓库 git remote add origin https://gitee.com/zengtian_7/pet_home.git 5.初始化代码库:当你创建一个全新的代码库时,…...

CSS—选择器
目录 一、CSS简介 二、HTML页面中常用的元素 三、CSS语法规则 四、常用的选择器 五、CSS的三种使用方法 六、选择器参考 一、CSS简介 CSS (Cascading Style Sheets,层叠样式表),是一种用来为结构化文档(如 HTML 文档或 XML 应…...

【Unity实战系列】Unity的下载安装以及汉化教程
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,怎么说呢,其实这才是我以后真正想写想做的东西,虽然才刚开始,但好歹,我总算是启程了。今天要分享…...
电脑IP地址错误无法上网怎么办?
电脑出现IP地址错误后就将无法连接网络,从而无法正常访问互联网。那么当电脑出现IP地址错误时该怎么办呢? 确认是否禁用本地连接 你需要先确定是否禁用了本地网络连接,如果发现禁用,则将其启用即可。 启用方法:点击桌…...
机器视觉项目流程和学习方法
机器视觉项目流程: 00001. 需求分析和方案建立 00002. 算法流程规划和业务逻辑设计 00003. 模块化编程和集成化实现 00004. 调试和优化,交付客户及文档 学习机器视觉的方法: 00001. 实战学习,结合项目经验教训 00002. 学习…...
LNMP环境搭建wordpress以及跳转后台报404解决
基于上文配置好的LNMP环境继续搭建wordpress 目录 一.到官网下载tar.gz包,并上传到Linux上,也可以通过复制链接地址进行下载 二. 将wordpress中的所有文件移动到你nginx.conf中指定目录中 三.为wordpress配置数据库 四.到浏览器进行注册 1.刚开始…...

Nginx+Tomcat的动静分离
首先准备好5台机子:2台装有tomcat,3台装有nginx 1.关闭5台机子的防火墙 systemctl stop firewalld systemctl disable firewalld setenforce 0 Nginx1 vim /usr/local/nginx/conf/nginx.conf#在--#pid-- 下做四层代理 stream {upstream test {server …...

Tomcat部署与优化
目录 一、Tomcat介绍 二、Tomcat核心组件 1、web容器:完成web服务器的功能,web应用 2、servlet容器:名字:catalina,处理servlet代码 servlet的功能 3、jsp:jsp动态页面翻译成servlet代码,用…...

jmeter工具使用
jmeter工具使用 官方下载 安装好jdk后,下载之后直接运行即可 基本流程 1、首先添加线程组 线程组:JMeter是由Java实现的,并且使用一个Java线程来模拟一个用户,因此线程组(Thread Group)就是指一组用户的…...

【uniapp】封装一个全局自定义的模态框
【需求描述】 在接口401处,需要实现全局提示并弹出自定义模态框的功能。考虑到uni-app内置的模态框和app原生提示框的自定义能力有限,我决定自行封装全局自定义的模态框,以此为应用程序提供更加统一且个性化的界面。 【效果图】 【封装】 主…...
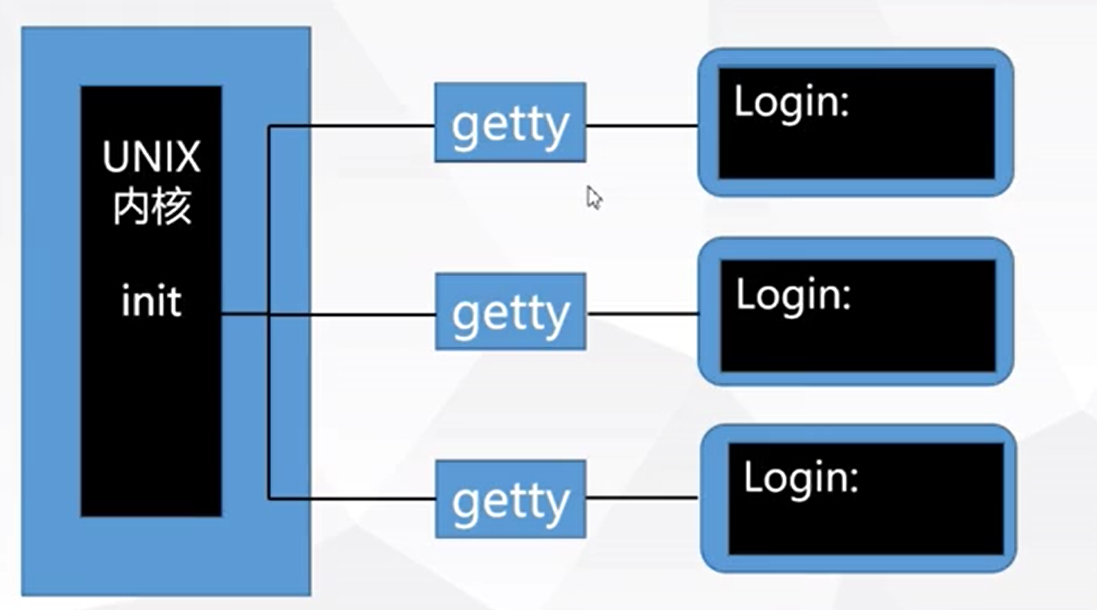
UNIX 入门
与 UNIX 建立连接启动会话登录命令提示符修改口令退出系统 简单的 UNIX 命令命令格式ls 命令who 命令虚拟终端 tty伪终端 ptywho am i 命令 cal 命令help 命令man 命令 shell 概述shell 命令更换 shell临时更改 shell永久更改 shell 登录过程 与 UNIX 建立连接 启动会话 要启…...
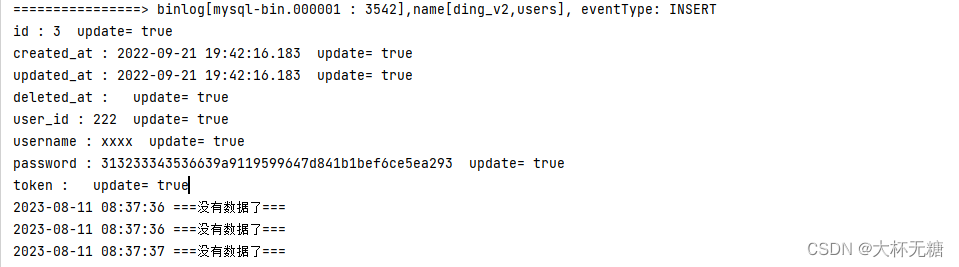
Golang通过alibabaCanal订阅MySQLbinlog
最近在做redis和MySQL的缓存一致性,一个方式是订阅MySQL的BinLog文件,我们使用阿里巴巴的Canal的中间件来做。 Canal是服务端和客户端两部分构成,我们需要先启动Canal的服务端,然后在Go程序里面连接Canal服务端,即可监…...

Python flask-restful 框架讲解
1、简介 Django 和 Flask 一直都是 Python 开发 Web 的首选,而 Flask 的微内核更适用于现在的云原生微服务框架。但是 Flask 只是一个微型的 Web 引擎,所以我们需要扩展 Flask 使其发挥出更强悍的功能。 python flask框架详解:https://blog.…...

MySQL_约束、多表关系
约束 概念:就是用来作用表中字段的规则,用于限制存储在表中的数据。 目的:保证数据库中数据的正确性,有效性和完整性。 约束演示 #定义一个学生表,表中要求如下: #sn 表示学生学号,要求使用 …...
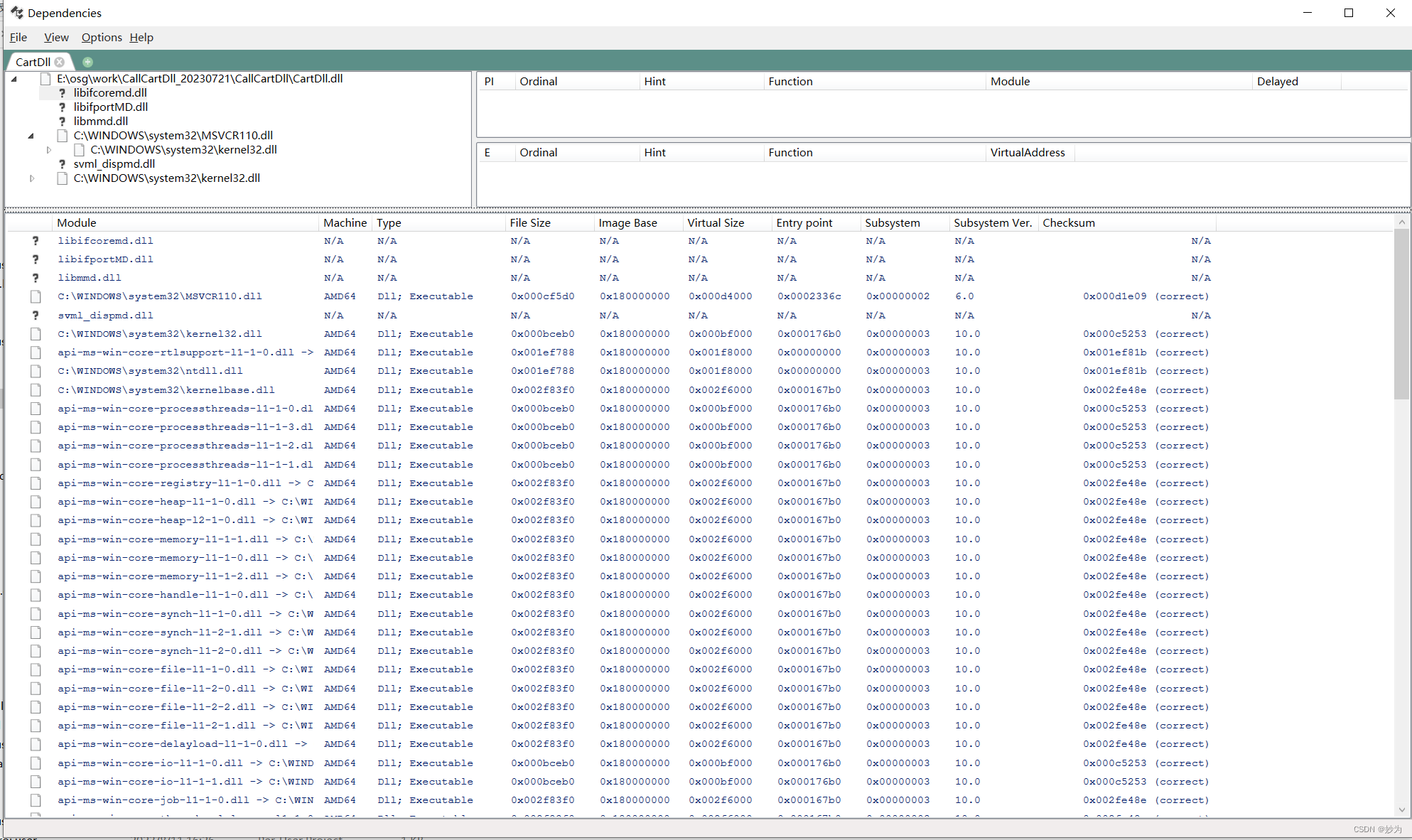
在Qt中使用LoadLibrary无法加载DLL
Qt系列文章目录 文章目录 Qt系列文章目录前言一、问题分析 前言 最近因项目需要使用qt做开发,之前使用LoadLibrary加载dll成功,很庆幸,当一切都那么顺风顺水的时候,测试同事却发现,在windows平台上个别电脑上加载dll会…...
)
Zynq PL动态部署避坑指南:从Vivado工程到/dev/ttyUL0出现的全链路解析(含常见错误排查)
Zynq PL动态部署避坑指南:从Vivado工程到/dev/ttyUL0出现的全链路解析 在嵌入式系统开发中,Zynq系列SoC因其独特的PS(Processing System)和PL(Programmable Logic)架构而备受青睐。然而,当开发者…...

Lenovo在2026年汉诺威工业博览会上展示生产级AI解决方案,助力制造商将交付周期缩短最高85%
94%的制造商将在2026年加大AI投入,Lenovo推出的解决方案助力企业从试点迈向规模化生产,在成本、质量和运营表现方面实现可衡量的提升 面对持续的供应链波动和运营复杂度上升,制造商在提升效率、抗风险能力和响应速度方面面临越来越大的压力。…...
)
别再到处找资源了!一个百度网盘链接搞定IC设计EDA学习环境(附工艺库与避坑指南)
一站式IC设计学习环境:高效搭建EDA工具链的终极方案 在集成电路设计的学习道路上,无数初学者都曾陷入同样的困境——花费大量时间在论坛、网盘和各种资源站点间来回切换,只为拼凑出一个能用的EDA工具环境。当你终于下载完几十GB的安装包&…...

科技领袖警示:AI、生物工程与气候危机的未来风险
1. 科技领袖的警示:我们为何需要关注未来风险那天我在整理书架时,偶然翻到一本2015年的《时代》杂志,封面正是比尔盖茨、埃隆马斯克和霍金三人的合影,标题赫然写着"他们警告的世界"。这让我想起过去十年间,这…...

你以为的“查重”可能早就不是你以为的样子了:好写作AI重新定义论文检测
先问一个有点扎心的问题:你有多久没有真正理解过“查重”这两个字了? 我知道你的答案可能是——“这有什么好理解的?查重不就是看我的论文和别人的像不像吗?像的地方多了就要修改,不像就没问题。” 这个答案在五年前…...

EventBus @Subscribe注解全解析:除了threadMode,sticky和priority这两个属性你用对了吗?
EventBus Subscribe注解深度解析:解锁sticky与priority的高级玩法 当EventBus的Subscribe注解出现在你的Android代码中时,大多数开发者可能只关注了threadMode这个属性。但今天我们要把聚光灯转向两个常被忽视却同样强大的功能:sticky事件和p…...
的常见编译错误与解决)
避坑指南:在Windows 10/11上用QT Creator集成USBCAN库(ControlCAN.dll)的常见编译错误与解决
避坑指南:在Windows 10/11上用QT Creator集成USBCAN库(ControlCAN.dll)的常见编译错误与解决 当你在QT Creator中尝试集成USBCAN设备的ControlCAN库时,可能会遇到各种令人沮丧的编译错误。这些错误往往源于库文件配置不当、路径问…...

机器学习自学路线:从零到实战的系统化指南
1. 机器学习自学路线图:从零开始的系统化实践指南第一次打开sklearn文档时,我被各种算法名词淹没的体验至今记忆犹新。作为经历过这个阶段的从业者,我想分享一条验证过的学习路径——这不是理论堆砌,而是用20%的核心知识解决80%实…...

中文医疗对话数据集:构建智能医疗问答系统的核心技术资产
中文医疗对话数据集:构建智能医疗问答系统的核心技术资产 【免费下载链接】Chinese-medical-dialogue-data Chinese medical dialogue data 中文医疗对话数据集 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-medical-dialogue-data 中文医疗对话数据…...

手写一个自动断言Skill:30行代码,省你每天2小时
很多人已经开始感觉到,测试这件事正在悄悄变天。 不是危言耸听。上个月我和几个大厂的技术总监聊,大家普遍提到一个现象:AI写代码的速度已经超过人工Review的速度,但测试左移、持续交付、质量内建这些喊了多年的口号,反…...