ClickHouse常见的引擎和使用
1.日志引擎
日志引擎特点
1.数据存储在磁盘上
2.写入时将数据追加在文件末尾
3.不支持突变操作
4.不支持索引
5.非原子地写入数据
6.引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作
建表语法示例
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
column1_name [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
column2_name [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = StripeLog
1.1StripeLog
建表语法示例:
CREATE TABLE stripe_log_table
(
create_date DateTime,
message_type String,
message String
)
ENGINE = StripeLog;
插入数据:
INSERT INTO stripe_log_table VALUES (now(),'REGULAR','The first regular message');
INSERT INTO stripe_log_table VALUES (now(),'REGULAR','The second regular message'),(now(),'WARNING','The first warning message');
1.2Log
建表语法示例:
CREATE TABLE log_table
(
create_date DateTime,
message_type String,
message String
)
ENGINE = Log;
1.3TinyLog
建表语法示例:
CREATE TABLE tiny_log_table
(
create_date DateTime,
message_type String,
message String
)
ENGINE = TinyLog;
2.合并引擎
2.1MergeTree(重要引擎)
1.存储的数据按主键排序
2.可以使用分区
3.支持数据副本
4.支持数据采样
2.1.1建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
参数详解
ENGINE:引擎名和参数
ENGINE = MergeTree(). MergeTree 引擎没有参数。
ORDER BY:排序键
可以是一组列的元组或任意的表达式。 例如: ORDER BY (CounterID, EventDate) 。
如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键。
如果不需要排序,可以使用 ORDER BY tuple().
PARTITION BY:分区键 ,可选项
大多数情况下,不需要分使用区键。即使需要使用,也不需要使用比月更细粒度的分区键。分区不会加快查询(这与 ORDER BY 表达式不同)。
永远也别使用过细粒度的分区键。不要使用客户端指定分区标识符或分区字段名称来对数据进行分区(而是将分区字段标识或名称作为 ORDER BY 表达式的第一列来指定分区)。
要按月分区,可以使用表达式 toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列。分区名的格式会是 "YYYYMM" 。
PRIMARY KEY:如果要 选择与排序键不同的主键,在这里指定,可选项
默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。 因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
SAMPLE BY:用于抽样的表达式,可选项
如果要用抽样表达式,主键中必须包含这个表达式。例如: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)) 。
TTL: 指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表,可选项
表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
TTL date + INTERVAl 1 DAY
规则的类型 DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'指定了当满足条件(到达指定时间)时所要执行的动作:移除过期的行,还是将数据片段(如果数据片段中的所有行都满足表达式的话)移动到指定的磁盘(TO DISK 'xxx') 或 卷(TO VOLUME 'xxx')。默认的规则是移除(DELETE)。可以在列表中指定多个规则,但最多只能有一个DELETE的规则。
SETTINGS — 控制 MergeTree 行为的额外参数,可选项:
index_granularity :索引粒度。索引中相邻的『标记』间的数据行数。默认值8192 。参考数据存储。
index_granularity_bytes:索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。
min_index_granularity_bytes:允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。参考数据存储
enable_mixed_granularity_parts:是否启用通过 index_granularity_bytes 控制索引粒度的大小。在19.11版本之前, 只有 index_granularity 配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes 配置能够提升ClickHouse的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。
use_minimalistic_part_header_in_zookeeper:ZooKeeper中数据片段存储方式 。如果use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。
min_merge_bytes_to_use_direct_io:使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置 min_merge_bytes_to_use_direct_io = 0 ,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024 字节。
merge_with_ttl_timeout: TTL合并频率的最小间隔时间,单位:秒。默认值: 86400 (1 天)。
write_final_mark:是否启用在数据片段尾部写入最终索引标记。默认值: 1(不要关闭)。
merge_max_block_size: 在块中进行合并操作时的最大行数限制。默认值:8192
storage_policy:存储策略。 参见 使用具有多个块的设备进行数据存储.
min_bytes_for_wide_part,min_rows_for_wide_part 在数据片段中可以使用Wide格式进行存储的最小字节数/行数。您可以不设置、只设置一个,或全都设置。参考:数据存储
max_parts_in_total:所有分区中最大块的数量(意义不明)
max_compress_block_size:在数据压缩写入表前,未压缩数据块的最大大小。您可以在全局设置中设置该值(参见max_compress_block_size)。建表时指定该值会覆盖全局设置。
min_compress_block_size:在数据压缩写入表前,未压缩数据块的最小大小。您可以在全局设置中设置该值(参见min_compress_block_size)。建表时指定该值会覆盖全局设置。
max_partitions_to_read:一次查询中可访问的分区最大数。您可以在全局设置中设置该值(参见max_partitions_to_read)。
2.1.2创建表示例
CREATE TABLE index_test
(
i_id UInt64,
root_id UInt64,
parent_id UInt64,
path String,
index_id UInt64,
task_id UInt64,
cluster_id UInt64,
host_id UInt64,
scence_inst_id UInt64,
code String,
update_date DateTime,
v1 String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(update_date)
PRIMARY KEY (i_id)
ORDER BY (i_id,index_id,update_date)
SETTINGS index_granularity = 8192;
注意:主键必须是 order by 字段的前缀字段,和索引生成依据有关
2.1.3二级索引创建
2.1.4数据TTL设置
2.1.4.1列级别TTL
2.1.4.2表级别TTL
2.2Memory(内存引擎)
内存引擎查询速度快速,断电丢失数据,一般适用临时表或者高性能测试用
2.2.1创建临时表使用示例
CREATE TABLE temp_autorun_t_index
ENGINE=Memory
AS
SELECT path,code,v1 FROM autorun_t_index limit 10;
相关文章:

ClickHouse常见的引擎和使用
1.日志引擎 日志引擎特点 1.数据存储在磁盘上 2.写入时将数据追加在文件末尾 3.不支持突变操作 4.不支持索引 5.非原子地写入数据 6.引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作 建表语法示例 CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( …...

构建之法 - 软件工程实践教学:一线教师的13问
福州大学单红老师的软工课程总结 2020春,不一样的学期不一样的软工实践 单红⽼师在总结中,提出了13条疑惑,《构建之法》的作者邹欣⽼师就单红⽼师提出的每⼀条疑惑,给出了⾃⼰的思考,与他进⾏探讨交流。欢迎你也来参与…...

联调 matlab 遇到的一些事儿
记录当时遇到的问题,因为平时不写 matlab,所以没有深入的理解。 版本兼容 当时遇到的第一个问题就是不同版本 matlab 带来的兼容性问题。同时开发使用的是 2021a 版本,而调试时使用的是 2022b 版本。在新版本中某些函数已被弃用,…...

时序预测 | Matlab实现基于GRNN广义回归神经网络的电力负荷预测模型
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 时序预测 | Matlab实现基于GRNN广义回归神经网络的电力负荷预测模型 1.Matlab实现基于GRNN广义回归神经网络的电力负荷预测模型 2.单变量时间序列预测; 3.多指标评价,评价指标包括:R2、MAE、MBE等,代码质量极高…...
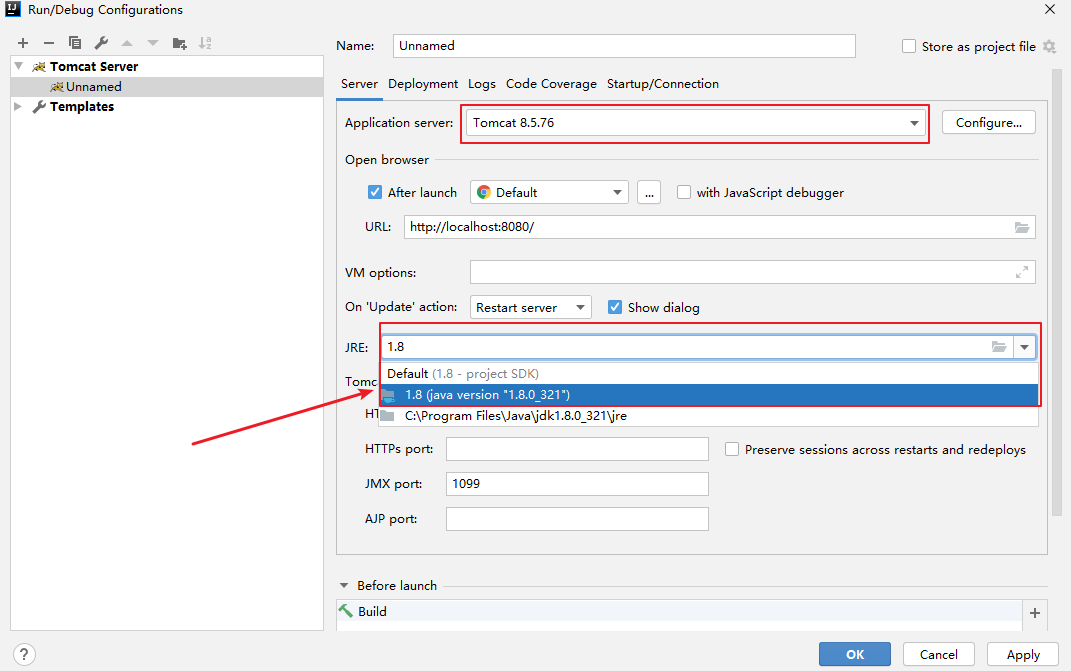
3.2 Tomcat基础
1. Tomcat概述 Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,属于轻量级应用服务器。 Tomcat版本:apache-tomcat-8.5.76。 2.IDEA集成Tomcat 第一步 第二步 第三步 编辑切换为居中 添加图片注释,不超过 140 字࿰…...
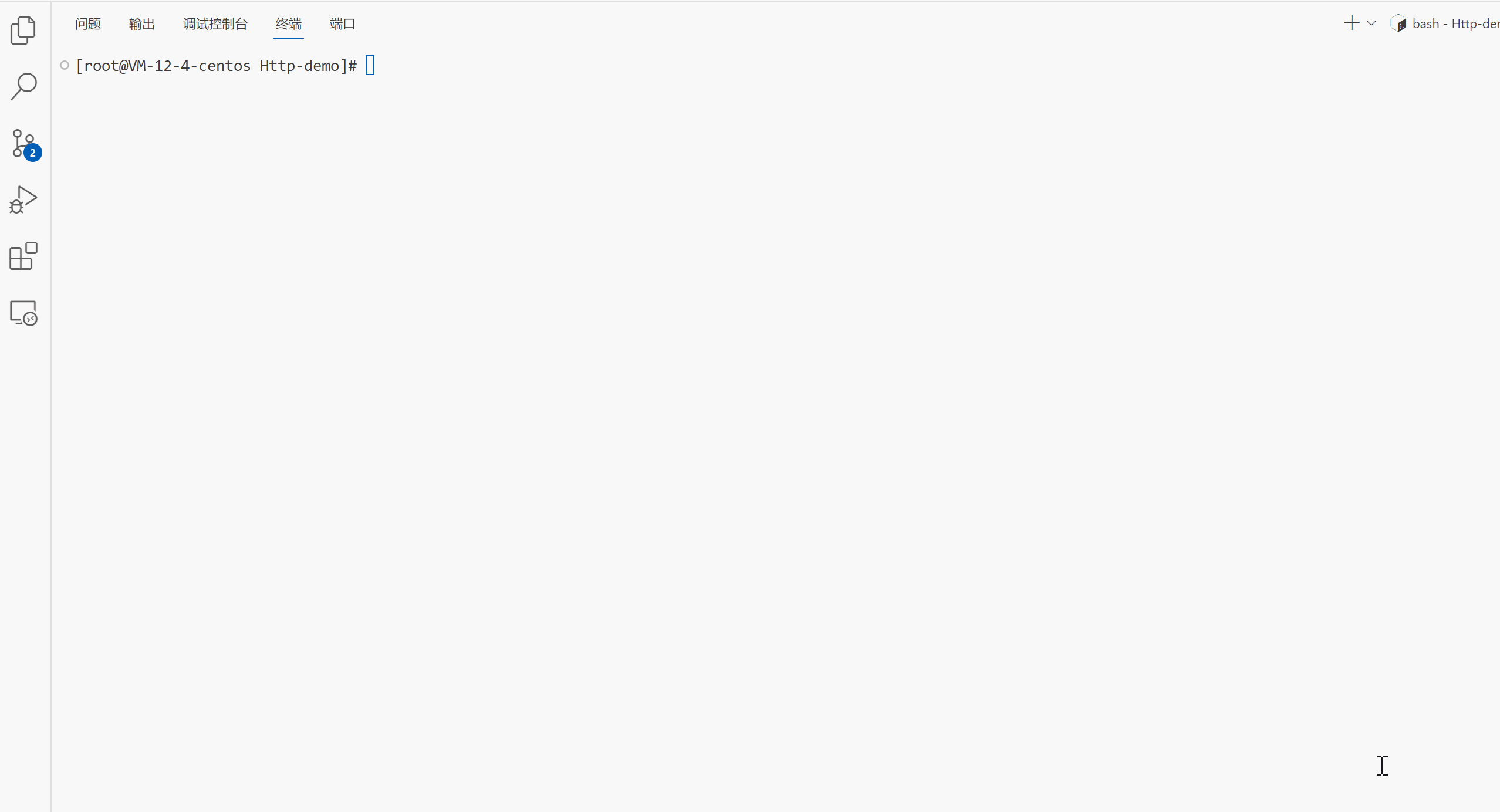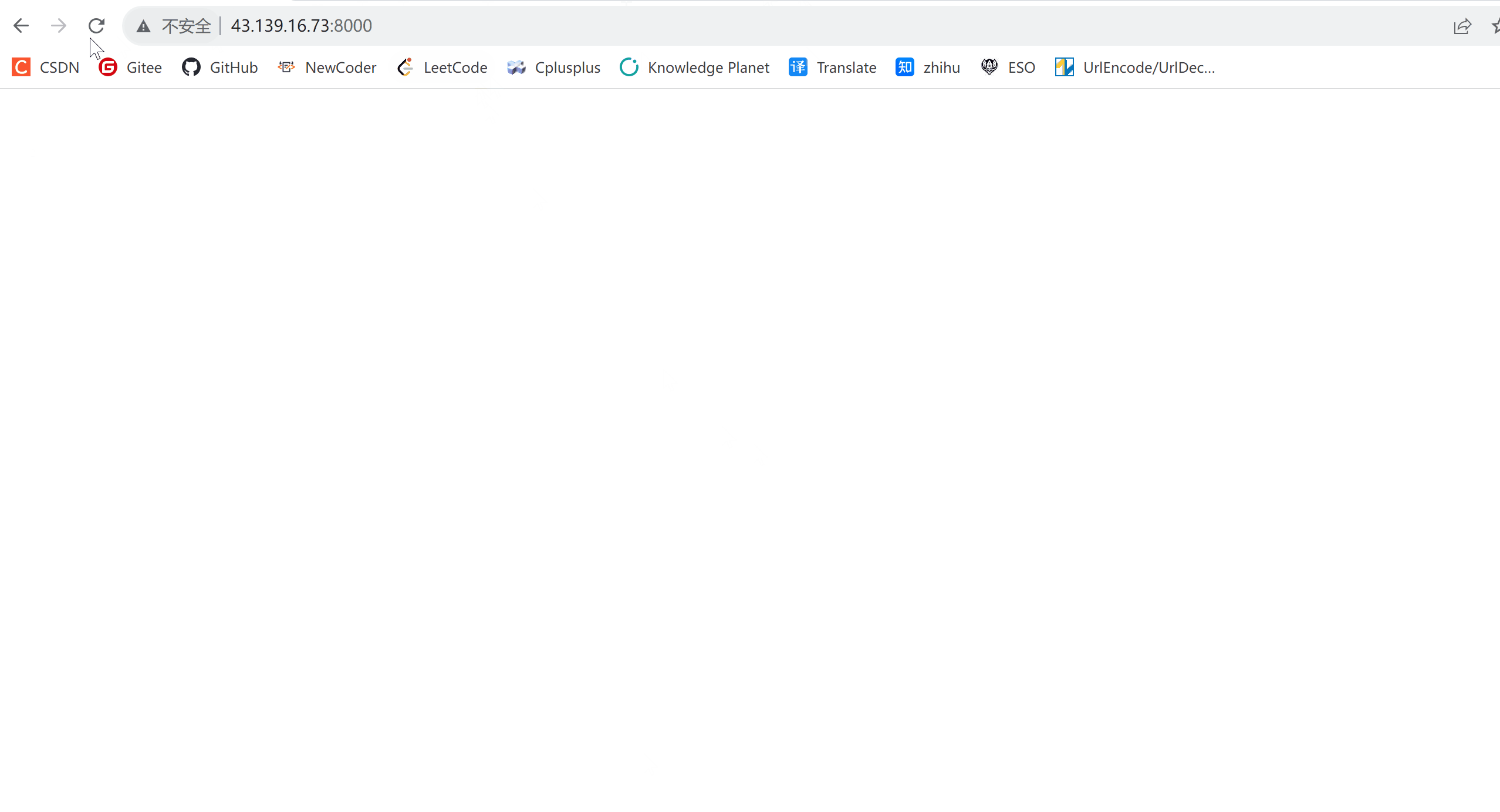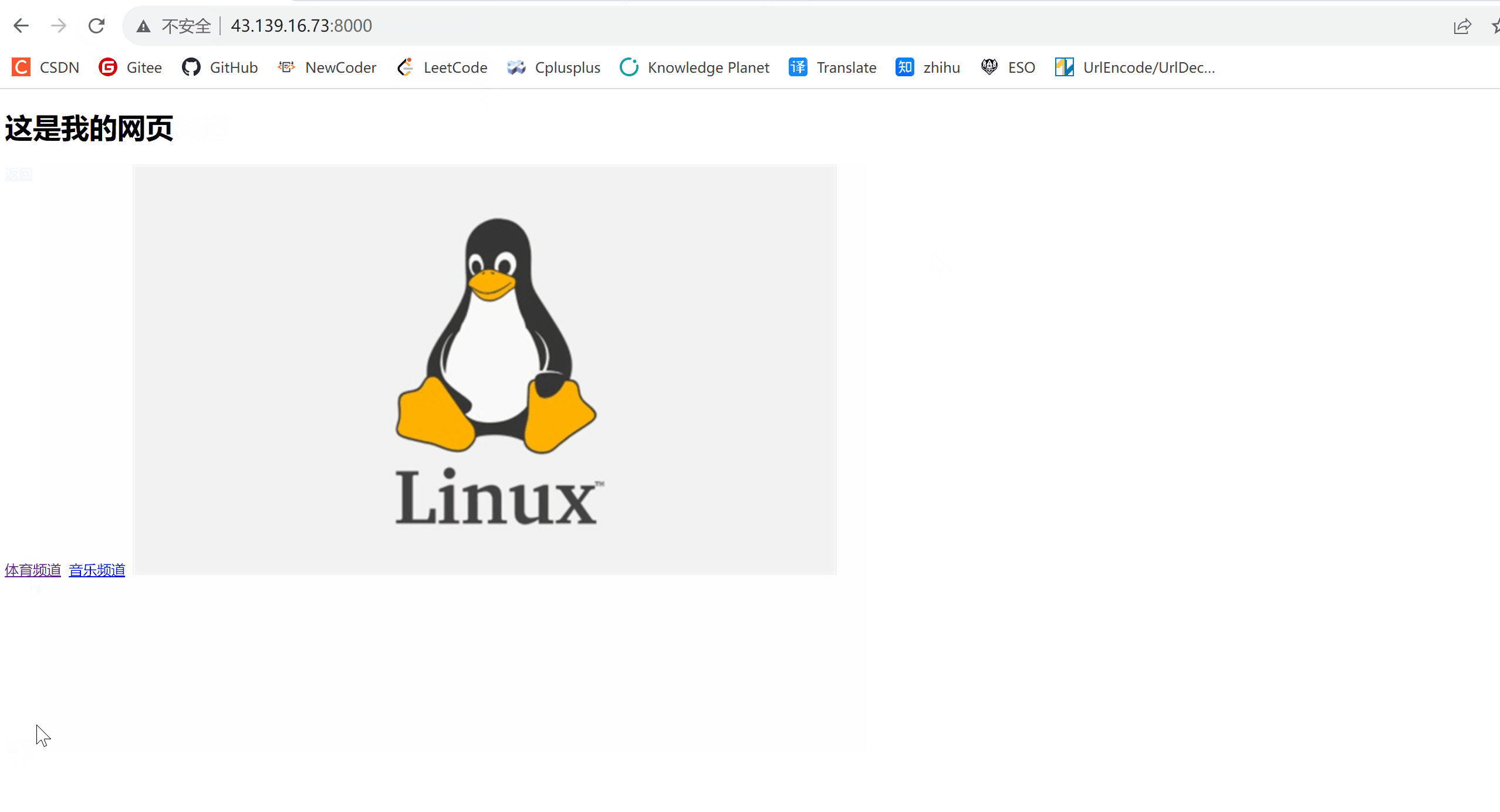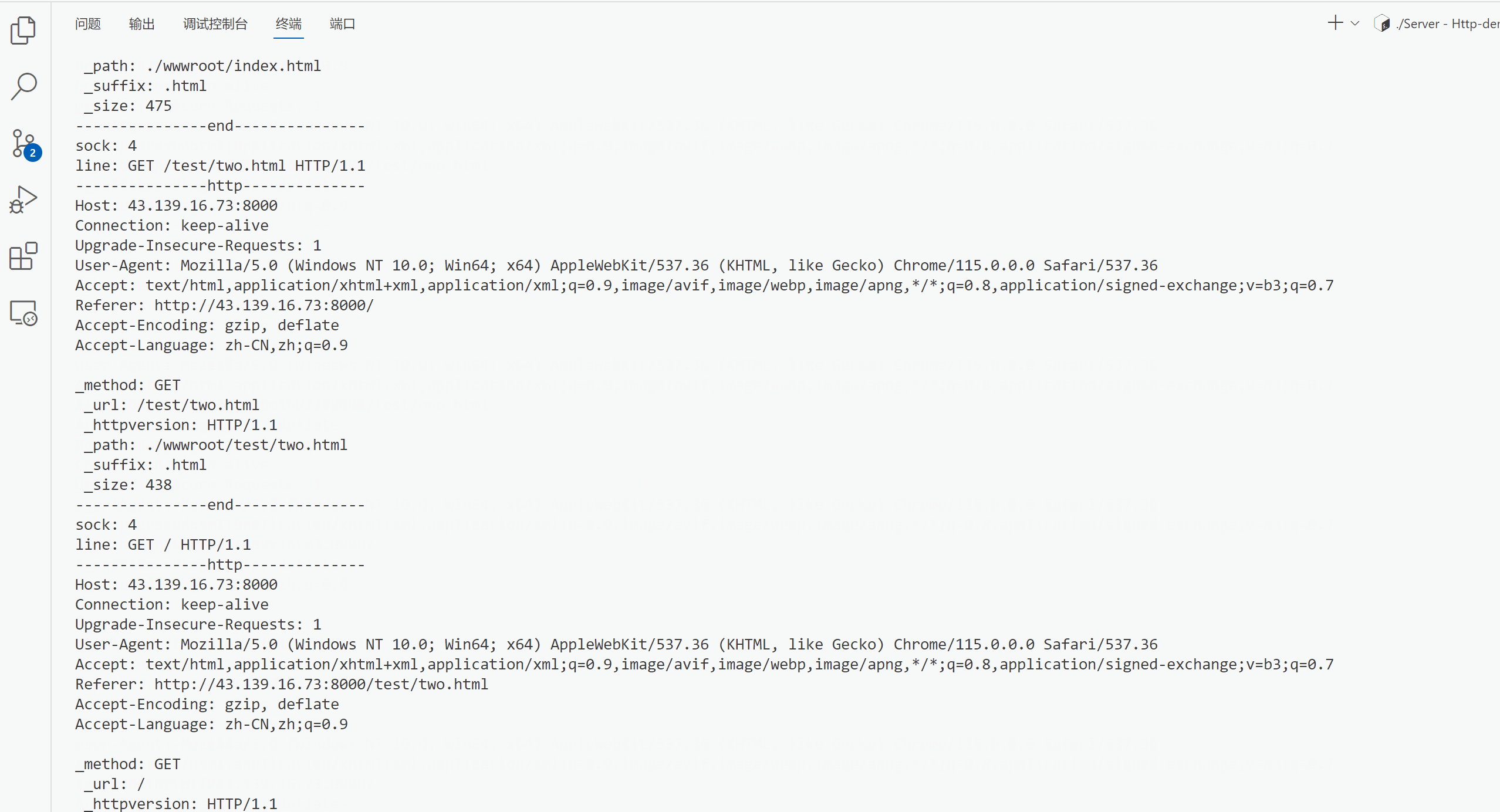
认识http的方法、Header、状态码以及简单实现一个http的业务逻辑
文章目录 http的方法http状态码http重定向http常见Header实现简单业务逻辑Protocol.hppUtil.hppServer.hppServer.cc 效果 http的方法 方法说明支持的HTTP版本GET获取资源1.0/1.1POST传输实体主体1.0/1.1PUT传输文件1.0/1.1HEAD获得报文首部1.0/1.1DELETE删除文件1.0/1.1OPTIO…...

Faiss在windows下安装和使用
pip install faiss-cpu 直接安装可能出现问题: error: command swig.exe failed: No such file or directory 安装swig即可解决,安装方式...
【JavaEE进阶】SpringBoot项目的创建
文章目录 一. SpringBoot简介1. 什么是SpringBoot?2. SpringBoot的优点 二. SpringBoot项目创建1. 使用IDEA创建2. 使用网页创建SpringBoot项目 三. 运行SpringBoot项目 一. SpringBoot简介 1. 什么是SpringBoot? Spring Boot 是一个用于快速构建基于 Spring 框架的应用程序…...
)
c++二进制转化十进制代码(小数)
#include <bits/stdc.h> using namespace std; int mid; double er_shi(string a){int lena;double sum0;int p0;int q-1;int yn1;//判断是否小数 lenaa.length();//字符串长度 for(int i0;i<lena;i){if(a[i].){midi;yn0;break;} }if(yn0){for(int jmid-1;j>0;j--…...

07_ansible, 条件选择、加载客户事件、在roles和includes上面应用’when’语句、条件导入、基于变量选择文件和模版、注册变量
10.条件选择 10.1.When语句 10.2.加载客户事件 10.3.在roles和includes上面应用’when’语句 10.4.条件导入 10.5.基于变量选择文件和模版 10.6.注册变量 10.条件选择 转自:http://www.ansible.com.cn/docs/playbooks_conditionals.html#id3 常常来说,一个play的…...

4个简化IT服务台任务的ChatGPT功能
最近几个月,ChatGPT 风靡全球,这是一个 AI 聊天机器人,使用户能够生成脚本、文章、锻炼图表等。这项技术在各行各业都有无穷无尽的应用,在本文中,我们将研究这种现代技术如何帮助服务台团队增强服务交付和客户体验。 什…...
群晖7.X版安装cpolar内网穿透
群晖7.X版安装cpolar内网穿透套件 文章目录 群晖7.X版安装cpolar内网穿透套件前言1. 下载cpolar的群晖系统套件1.1 在“套件中心” 选择“手动安装”1.2 完成套件安装 2. 进入cpolar软件信息页3. 点击“免费注册”轻松获得cpolar账号 前言 随着群晖系统的更新换代,…...
[保研/考研机试] KY183 素数 北京航空航天大学复试上机题 C++实现
题目链接: 素数https://www.nowcoder.com/share/jump/437195121691718444910 描述 输入一个整数n(2<n<10000),要求输出所有从1到这个整数之间(不包括1和这个整数)个位为1的素数,如果没有则输出-1。 输入描述: 输入有多…...
Java基础入门篇——IDEA开发第一个入门程序(五)
目录 一、IDEA层级结构分类 二、IDEA层级结构介绍 三、IDEA层级关系 四、创建IDEA中的第一个代码 一、IDEA层级结构分类 IntelliJ IDEA的项目结构主要分为以下几个层级: Project: 项目Module: 模块Package: 包Class: 类 一个项目里面…...
系统学习Linux-Redis基础
一、redis概述 NoSQL(非关系型数据库、内存存储) 类型 文档型数据库(Document-oriented database)如MongoDB; 列族数据库(Column-family database)如HBase、Cassandra等; 图形数…...
)
实现缓存el-table分页大小,用户新建标签打开该页面需保持分页大小(考虑是否为嵌入式页面)
需求:每个表格的分页大小 以本地缓存的方式存到浏览器本地,然后用户下次打开的时候 获取这个本地存储的值 如果没有就用页面默认的值,如果有 则先判断是不是有效的(是) 无效用默认 有效就用这个缓存值,需要区分是否为嵌入式页面 分析…...

056B R包ENMeval教程-基于R包ENMeval对MaxEnt模型优化调参和结果评价制图(更新)
056B-1 资料下载 056B-2 R包ENMeval在MaxEnt模型优化调参中的经典案例解读 056B-3 R软件和R包ENMeval工具包安装 056B-4 R软件和R包ENMeval安装报错解决办法 056B-5 环境数据格式要求和处理流程 056B-6 分布数据格式要求和处理流程 056B-7 基于R包ENMeval对MaxEnt模型优化…...

MySQL_数据库的DDL语句(表的创建与修改)
DDL 数据库操作 查看当前有哪些数据库 SHOW databases;#查看哪些数据库查询当前数据库 SELECT database();创建数据库 create database [ if not exists ] 数据库名 [ default charset 字符集 ] [ collate 排序 规则 ] ;创建一个sycoder数据库, 使用数据库默认的字符集 CREATE…...

常见面试题:字节序判别和转换
在计算机中,字节序指的是多字节数据的存储顺序。最常见的字节序有两种:大端字节序(Big-Endian)和小端字节序(Little-Endian)。 大端字节序是指最高有效位(Most Significant Bit,简称…...

Maxwell与canal工具对比
Maxwell和Canal是两种不同的数据同步工具,都是在数据迁移、数据同步、数据分发等领域发挥作用的工具,但是它们之间存在一些差异。 Maxwell Maxwell是一种开源的MySQL数据库同步工具,它可以将MySQL数据库的binlog转化为JSON格式,…...

Vim终端配置避坑指南:从Toggleterm快捷键冲突到多窗口管理的实战解决方案
Vim终端配置避坑指南:从Toggleterm快捷键冲突到多窗口管理的实战解决方案 在Vim生态中,终端集成一直是提升开发效率的关键环节。当开发者从基础配置转向高阶工作流时,往往会遇到三大典型困境:快捷键冲突导致模式切换混乱、多终端窗…...
)
用逻辑分析仪抓波形,手把手教你调试AT24C08的I2C读写时序(附代码避坑点)
用逻辑分析仪精准调试AT24C08的I2C通信:从波形捕获到代码优化的完整指南 当你在深夜调试一块无法正常读写的AT24C08 EEPROM芯片时,是否曾盯着示波器上那些跳动的波形感到无从下手?I2C通信作为嵌入式开发中最常见的协议之一,其看似…...

别再浪费本地显卡了!用Google Colab免费GPU跑PyTorch模型,保姆级避坑指南
别再浪费本地显卡了!用Google Colab免费GPU跑PyTorch模型,保姆级避坑指南 当你面对一个复杂的深度学习项目时,本地显卡的算力往往捉襟见肘。特别是训练大型神经网络时,动辄数小时甚至数天的计算时间让个人开发者望而却步。但你可能…...
配置驱动,告别黑屏和卡Clean)
避坑指南:在Arch上为笔记本双显卡(如NVIDIA Optimus)配置驱动,告别黑屏和卡Clean
Arch Linux笔记本双显卡配置避坑指南:从黑屏到完美渲染 每次在Arch Linux上折腾NVIDIA双显卡配置,总有种在雷区跳舞的刺激感——一步错就可能陷入黑屏的深渊。特别是当你在咖啡厅刚装完驱动,自信满满地重启后,迎接你的却是那个令人…...

企业微信AI客服源码系统– 部署简单,维护方便,全程技术支持
温馨提示:文末有资源获取方式在当今数字化服务场景中,企业如何低成本实现724小时智能客户支持?一套稳定、易用的客服系统源码成为关键。以下基于实际开发经验,梳理该解决方案的核心优势:一、技术架构与部署优势PHP原生…...

5分钟快速掌握SketchUp STL插件:3D打印模型转换的完整解决方案
5分钟快速掌握SketchUp STL插件:3D打印模型转换的完整解决方案 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 在…...

5分钟快速上手QtScrcpy:安卓设备键鼠映射与屏幕控制的终极指南
5分钟快速上手QtScrcpy:安卓设备键鼠映射与屏幕控制的终极指南 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 想要在电脑上玩手游吗?想用键盘鼠标控制安卓设…...
)
Java 25虚拟线程性能断崖式跃迁:阿里云真实订单链路压测数据(RT从412ms→23ms,附全链路火焰图)
第一章:Java 25虚拟线程演进脉络与高并发架构新范式Java 25正式将虚拟线程(Virtual Threads)从预览特性转为标准特性,标志着JVM并发模型进入“轻量级线程即原语”时代。这一转变并非孤立演进,而是历经Project Loom多年…...
)
Loom响应式转型不是选择题:2024年高并发Java系统必须完成的3项技术对齐(附迁移ROI测算表)
第一章:Loom响应式转型不是选择题:2024年高并发Java系统必须完成的3项技术对齐(附迁移ROI测算表) Java Loom 项目已随 JDK 21 正式进入生产就绪阶段,其虚拟线程(Virtual Threads)与结构化并发&a…...

六大AI企业服务全景解析:技术路线、核心优势与企业选型指南
六大AI企业服务全景解析:技术路线、核心优势与企业选型指南在大模型应用全面落地的当下,企业AI服务不再局限于单一的模型调用,而是朝着专业化、场景化、合规化、高可控方向细分。不同厂商基于差异化技术架构与路线,形成了各自的核…...