深度学习(37)—— 图神经网络GNN(2)
深度学习(37)—— 图神经网络GNN(2)
这一期主要是一些简单示例,针对不同的情况,使用的数据都是torch_geometric的内置数据集
文章目录
- 深度学习(37)—— 图神经网络GNN(2)
- 1. 一个graph对节点分类
- 2. 多个graph对图分类
- 3.Cluster-GCN:当遇到数据很大的图
1. 一个graph对节点分类
from torch_geometric.datasets import Planetoid # 下载数据集用的
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import GCNConv
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import torch
from torch.nn import Linear
import torch.nn.functional as F# 可视化部分
def visualize(h, color):z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())plt.figure(figsize=(10, 10))plt.xticks([])plt.yticks([])plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")plt.show()# 加载数据
dataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures()) # transform预处理
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.
print()
print(data)
print('===========================================================================================================')# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')# 网络定义
class GCN(torch.nn.Module):def __init__(self, hidden_channels):super().__init__()torch.manual_seed(1234567)self.conv1 = GCNConv(dataset.num_features, hidden_channels)self.conv2 = GCNConv(hidden_channels, dataset.num_classes)def forward(self, x, edge_index):x = self.conv1(x, edge_index)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.conv2(x, edge_index)return xmodel = GCN(hidden_channels=16)
print(model)# 训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()def train():model.train()optimizer.zero_grad()out = model(data.x, data.edge_index)loss = criterion(out[data.train_mask], data.y[data.train_mask])loss.backward()optimizer.step()return lossdef test():model.eval()out = model(data.x, data.edge_index)pred = out.argmax(dim=1)test_correct = pred[data.test_mask] == data.y[data.test_mask]test_acc = int(test_correct.sum()) / int(data.test_mask.sum())return test_accfor epoch in range(1, 101):loss = train()print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
2. 多个graph对图分类
- 图也可以进行batch,做法和图像以及文本的batch是一样的
- 和对一张图中的节点分类不同的是:多了聚合操作
将各个节点特征汇总成全局特征,将其作为整个图的编码
import torch
from torch_geometric.datasets import TUDataset # 分子数据集:https://chrsmrrs.github.io/datasets/
from torch_geometric.loader import DataLoader
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.nn import global_mean_pool# 加载数据
dataset = TUDataset(root='data/TUDataset', name='MUTAG')
print(f'Dataset: {dataset}:')
print('====================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.
print(data)
print('=============================================================')# Gather some statistics about the first graph.
# print(f'Number of nodes: {data.num_nodes}')
# print(f'Number of edges: {data.num_edges}')
# print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
# print(f'Has isolated nodes: {data.has_isolated_nodes()}')
# print(f'Has self-loops: {data.has_self_loops()}')
# print(f'Is undirected: {data.is_undirected()}')train_dataset = dataset
print(f'Number of training graphs: {len(train_dataset)}')# 数据用dataloader加载
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
for step, data in enumerate(train_loader):print(f'Step {step + 1}:')print('=======')print(f'Number of graphs in the current batch: {data.num_graphs}')print(data)print()# 模型定义
class GCN(torch.nn.Module):def __init__(self, hidden_channels):super(GCN, self).__init__()torch.manual_seed(12345)self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)self.conv2 = GCNConv(hidden_channels, hidden_channels)self.conv3 = GCNConv(hidden_channels, hidden_channels)self.lin = Linear(hidden_channels, dataset.num_classes)def forward(self, x, edge_index, batch):# 1.对各节点进行编码x = self.conv1(x, edge_index)x = x.relu()x = self.conv2(x, edge_index)x = x.relu()x = self.conv3(x, edge_index)# 2. 平均操作x = global_mean_pool(x, batch) # [batch_size, hidden_channels]# 3. 输出x = F.dropout(x, p=0.5, training=self.training)x = self.lin(x)return xmodel = GCN(hidden_channels=64)
print(model)# 训练
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
def train():model.train()for data in train_loader: # Iterate in batches over the training dataset.out = model(data.x, data.edge_index, data.batch) # Perform a single forward pass.loss = criterion(out, data.y) # Compute the loss.loss.backward() # Derive gradients.optimizer.step() # Update parameters based on gradients.optimizer.zero_grad() # Clear gradients.def test(loader):model.eval()correct = 0for data in loader: # Iterate in batches over the training/test dataset.out = model(data.x, data.edge_index, data.batch)pred = out.argmax(dim=1) # Use the class with highest probability.correct += int((pred == data.y).sum()) # Check against ground-truth labels.return correct / len(loader.dataset) # Derive ratio of correct predictions.for epoch in range(1, 3):train()train_acc = test(train_loader)print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}')
3.Cluster-GCN:当遇到数据很大的图
- 传统的GCN,层数越多,计算越大
- 针对每个cluster进行GCN计算之后更新,数据量会小很多
但是存在问题:如果将一个大图聚类成多个小图,最大的问题是如何丢失这些子图之间的连接关系?——在每个batch中随机将batch里随机n个子图连接起来再计算
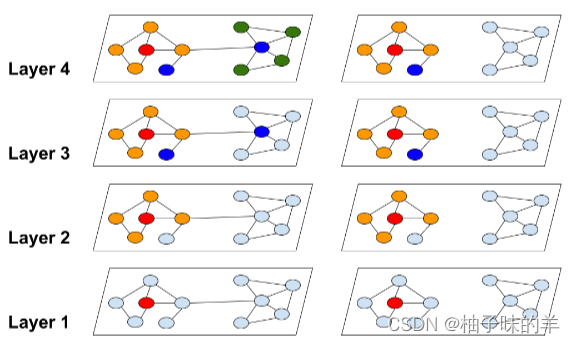
-
使用
torch_geometric的内置方法- 首先使用cluster方法分区
- 之后使用clusterloader构建batch
【即】分区后对每个区域进行batch的分配
# 遇到特别大的图该怎么办?
# 图中点和边的个数都非常大的时候会遇到什么问题呢?
# 当层数较多时,显存不够import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.loader import ClusterData, ClusterLoaderdataset = Planetoid(root='data/Planetoid', name='PubMed', transform=NormalizeFeatures())
print(f'Dataset: {dataset}:')
print('==================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.
print(data)
print('===============================================================================================================')# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.3f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')# 数据分区构建batch,构建好batch,1个epoch中有4个batch
torch.manual_seed(12345)
cluster_data = ClusterData(data, num_parts=128) # 1. 分区
train_loader = ClusterLoader(cluster_data, batch_size=32, shuffle=True) # 2. 构建batch.total_num_nodes = 0
for step, sub_data in enumerate(train_loader):print(f'Step {step + 1}:')print('=======')print(f'Number of nodes in the current batch: {sub_data.num_nodes}')print(sub_data)print()total_num_nodes += sub_data.num_nodes
print(f'Iterated over {total_num_nodes} of {data.num_nodes} nodes!')# 模型定义
class GCN(torch.nn.Module):def __init__(self, hidden_channels):super(GCN, self).__init__()torch.manual_seed(12345)self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)self.conv2 = GCNConv(hidden_channels, dataset.num_classes)def forward(self, x, edge_index):x = self.conv1(x, edge_index)x = x.relu()x = F.dropout(x, p=0.5, training=self.training)x = self.conv2(x, edge_index)return xmodel = GCN(hidden_channels=16)
print(model)# 训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()def train():model.train()for sub_data in train_loader:out = model(sub_data.x, sub_data.edge_index)loss = criterion(out[sub_data.train_mask], sub_data.y[sub_data.train_mask])loss.backward()optimizer.step()optimizer.zero_grad()def test():model.eval()out = model(data.x, data.edge_index)pred = out.argmax(dim=1)accs = []for mask in [data.train_mask, data.val_mask, data.test_mask]:correct = pred[mask] == data.y[mask]accs.append(int(correct.sum()) / int(mask.sum()))return accsfor epoch in range(1, 51):loss = train()train_acc, val_acc, test_acc = test()print(f'Epoch: {epoch:03d}, Train: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')
这个还是很基础的一些,下一篇会说如何定义自己的数据。还有进阶版的案例。
所有项目代码已经放在github上了,欢迎造访
相关文章:
深度学习(37)—— 图神经网络GNN(2)
深度学习(37)—— 图神经网络GNN(2) 这一期主要是一些简单示例,针对不同的情况,使用的数据都是torch_geometric的内置数据集 文章目录 深度学习(37)—— 图神经网络GNN(…...
Unity游戏源码分享-乐节奏休闲游戏源码 guitar hero 支持mobile
Unity游戏源码分享-乐节奏休闲游戏源码 guitar hero 支持mobile 完整版下载地址:https://download.csdn.net/download/Highning0007/88198766...
VS Code配置Prettier格式化Apex
先决条件 安装nodejs和npm安装vs code安装salesforce extension pack 配置Prettier Apex 创建本地Salesforce项目 (Standard) command shift p -> SFDX: Create Project with Manifest -> Standard 打开terminal运行npm init生成package.json文件 安装prettier ap…...

Spring-Cloud-Loadblancer详细分析_4
在RoundRobinLoadBalancer.choose中的serviceInstanceListSupplierProvider就是获取服务列表的关键,那么此对象是怎么拿到的呢,让我们回到RoundRobinLoadBalancer的创建过程 Configuration(proxyBeanMethods false) ConditionalOnDiscoveryEnabled pub…...
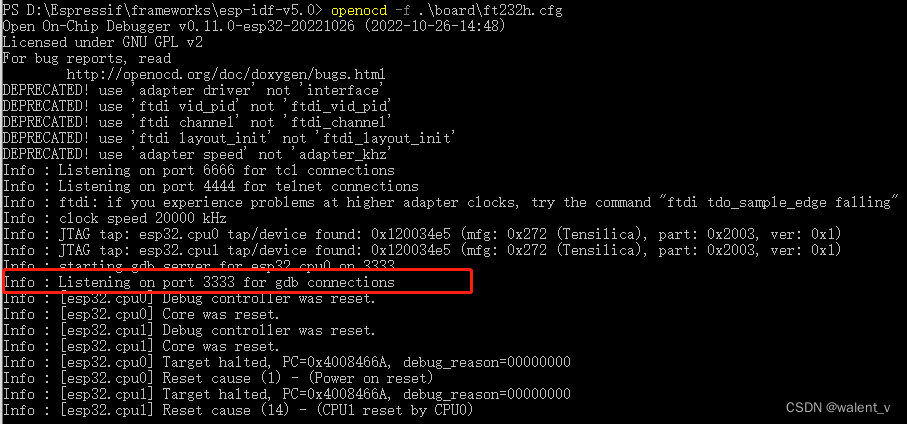
openocd调试esp32(通过FT232H)
之前在学习ESP32,其中有一部分课程是学习openocd通过JTAG调试程序的,因为我用的是ESP32-wroom,usb端口没有集成对应的usb转jtag的ft232,查了ESP32相关的资料(JTAG 调试 - ESP32 - — ESP-IDF 编程指南 latest 文档 (es…...

Nokia5110使用方法及实例编写51单片机
文章目录 Nokia5110实物图引脚和原理图51单片机实例软件模拟SPI实现控制Nokia5110显示字符发送字节时序图(图片太多了,关键图片已截取出来)初始化需要配置实例编写回顾接线结束Nokia5110 Nokia是诺基亚拆下来的屏幕。使用SPI控制 84x48 的点阵 LCD,可以显示 4 行汉字,采用…...

3个月快速入门LoRa物联网传感器开发
在这里插入图片描述 快速入门LoRa物联网传感器开发 LoRa作为一种LPWAN(低功耗广域网络)无线通信技术,非常适合物联网传感器和行业应用。要快速掌握LoRa开发,需要系统学习理论知识,并通过实际项目积累经验。 摘要: 先学习LoRa基础知识:原理、网络架构、协议等,大概需要2周时间…...

【小梦C嘎嘎——启航篇】内存管理小知识~
【小梦C嘎嘎——启航篇】内存管理小知识~😎 前言🙌malloc/calloc/realloc的区别?new 与 deletenew与delete要找好搭档才能保证万无一失 new 与 delete的内部实现细节是怎么样的呢???new 的内部实现细节dele…...
)
ClickHouse查看执行计划(EXPLAIN语法)
1.EXPLAIN 语法示例 EXPLAIN [AST | SYNTAX | QUERY TREE | PLAN | PIPELINE | ESTIMATE | TABLE OVERRIDE] [setting value, ...] [ SELECT ... | tableFunction(...) [COLUMNS (...)] [ORDER BY ...] [PARTITION BY ...] [PRIMARY KEY] [SAMPLE BY ...] [T…...
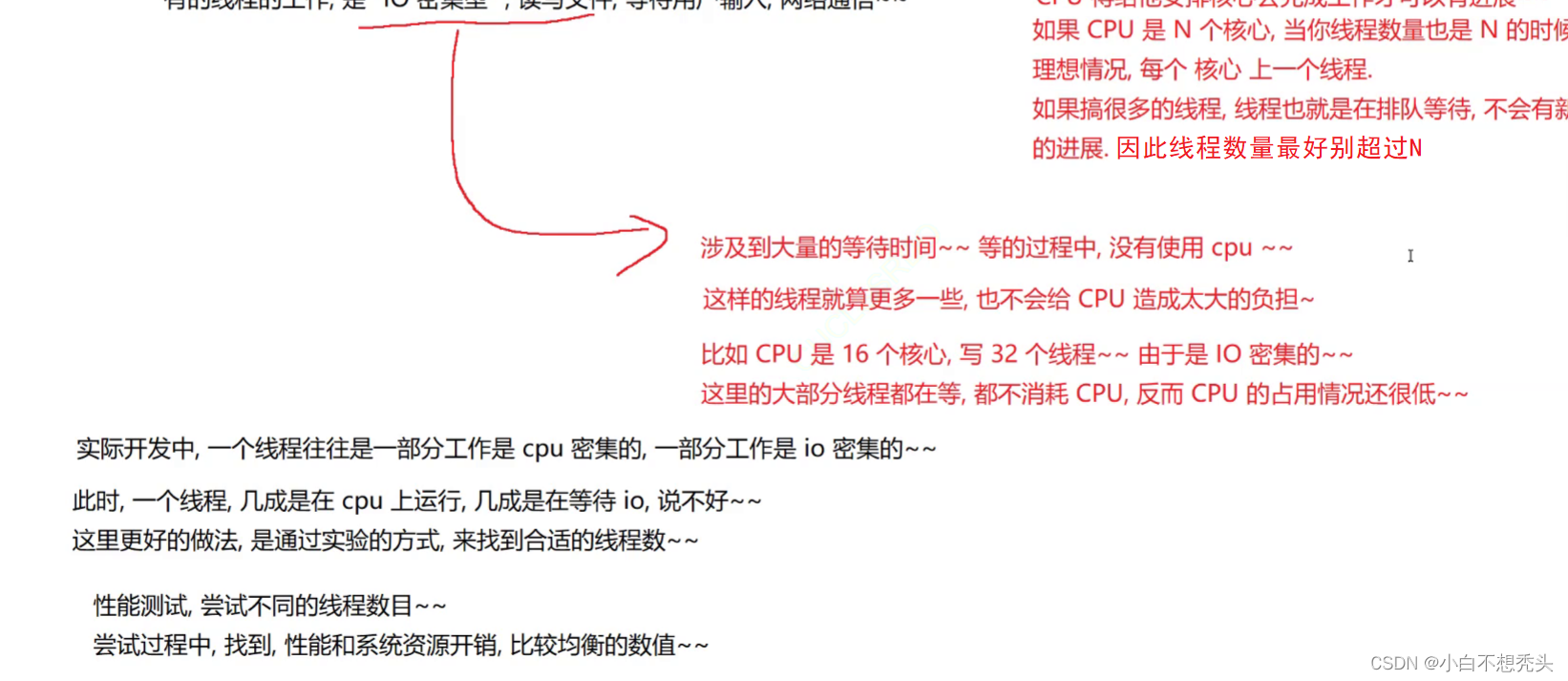
线程池
线程池 什么是线程池? 想象一下 假设我是个漂亮妹子,这时候接受了舔狗A的表白,随着时间的推移,逐渐不喜欢A这小子了,于是我就想换个男朋友,可是 1.处理分手,需要消耗一定成本 2.再找一个新对象…...

配置:Terminal和oh-my-posh
目录 命令行安装oh-my-posh查看安装情况配置PowerShell启用oh-my-posh、设置主题配色安装字体Terminal中的配置 命令行安装oh-my-posh Set-ExecutionPolicy Bypass -Scope Process -Force; Invoke-Expression ((New-Object System.Net.WebClient).DownloadString(https://ohmy…...
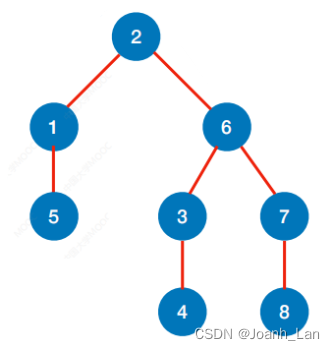
数据结构--BFS求最短路
数据结构–BFS求最短路 BFS求⽆权图的单源最短路径 注:⽆权图可以视为⼀种特殊的带权图,只是每条边的权值都为1 以 2 为 b e g i n 位置 以2为begin位置 以2为begin位置 代码实现 //求顶点u到其他顶点的最短路径 void BFS_MIN_Distance(Graph G, int u…...
FPGA应用学习笔记----定点除法的gold算法流水线设计
猜一个Y0 a和b上下都Y0 分母越接近一,分子就越接近答案 误差: 下一步迭代为 Y的迭代值: 误差值: 代码的实现如上所示...

Nginx转发的原理和负载均衡
一、Nginx转发的原理 Nginx是一个高性能的反向代理服务器,它可以用于实现请求的转发和负载均衡。以下是Nginx转发的基本原理: 客户端发送请求:客户端向Nginx服务器发送HTTP请求。 Nginx接收请求:Nginx服务器接收到客户端的请求。…...

怎么换ip地址 电脑切换ip地址方法
互联网时代,IP地址是我们在网络上进行通信和访问的身份标识。有时候,我们可能需要更改IP地址,以便获得更好的网络体验或绕过某些限制。本文将介绍如何使用深度IP转换器来更改IP地址。 1:了解IP地址 IP地址是一个由数字和点组成的标…...

软件设计基础
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 软件项目管理。 在经历了软件危机和大连的软件项目失败以后,人们对软件工程专业的现状进行了多次分析。得出了普遍性的结论&…...

OptaPlanner笔记5
2.4 与spring boot集成 2.4.4 添加依赖 <dependency><groupId>org.optaplanner</groupId><artifactId>optaplanner-spring-boot-starter</artifactId> </dependency>2.4.8 创建求解器服务 import org.optaplanner.core.api.solver.Solv…...

PS注意事项优漫动游
PS入门注意事项AdobePhotoshop是目前最流行的平面设计软件之一。可以说,只要你接触平面设计,那么无论早晚,你都要和它打交道。关于Photoshop,要说的实在太多太多,但不论你想让它成为你的左膀右臂,或者仅仅是…...

matplotlib 判断鼠标是否点击在当前线上
在开发中有一个需求:对生成的一条线进行拖拽。 我将这个方法实现在线所在的类里,这个过程中需要判断鼠标是否点击在当前线上,从而实现拖拽。 实现代码如下: # 点击事件 def on_press(self,event):if event.inaxes ! self.ax:retur…...
的用法 —— 筑梦之路)
bash中(冒号破折号)的用法 —— 筑梦之路
${PUBLIC_INTERFACE:-eth0} :- 的用途是什么? 含义:如果 $PUBLIC_INTERFACE 存在且不是 null,则返回其值,否则返回 "eth0"。 ${parameter:-word} 使用默认值。如果 parameter 未设置或为 null,则 word 的扩…...

超越Agent:当服务器不让装软件时,用Zabbix SNMP监控的3种高阶玩法与模板优化
超越Agent:Zabbix SNMP监控在受限环境下的高阶实践 想象一下这样的场景:凌晨三点,你被告警电话惊醒,一台关键业务服务器出现性能问题。但当你准备登录排查时,却发现这台服务器严格禁止安装任何监控Agent——这是许多运…...

科研党必备:葵花8号卫星NetCDF数据从申请到下载的全链路指南
科研党必备:葵花8号卫星NetCDF数据从申请到下载的全链路指南 气象卫星数据是气候研究、灾害预警和农业监测的重要基础。作为东亚地区覆盖最广的静止气象卫星之一,葵花8号(Himawari-8)提供的NetCDF格式数据因其标准化结构和丰富元数…...

Salt Player终极使用指南:从新手到专家的15个实用技巧
Salt Player终极使用指南:从新手到专家的15个实用技巧 【免费下载链接】SaltPlayerSource Salt Player (A local music player trusted and chosen by hundreds of thousands of users) for Android Release, Feedback. 项目地址: https://gitcode.com/GitHub_Tre…...

intv_ai_mk11惊艳案例:用‘分点说明’指令生成直播复盘报告,覆盖数据/话术/节奏
intv_ai_mk11惊艳案例:用分点说明指令生成直播复盘报告,覆盖数据/话术/节奏 1. 直播复盘报告生成效果展示 直播结束后,运营团队最头疼的就是整理复盘报告。传统方式需要人工回看录像、统计数据、分析话术,耗时耗力。而使用intv_…...

技术债务灾难:行业集体埋雷
冰山之下,测试之困在追求敏捷与快速交付的软件开发现代洪流中,“技术债务”已从一个晦涩的工程隐喻,演变为悬在无数项目头顶的达摩克利斯之剑。对于身处质量保障一线的软件测试从业者而言,技术债务远非开发团队的内部烦恼…...

一镜通古今:Rokid AI Glasses 驱动的古建筑文物全流程智能讲解终端
一. 前言 在文旅产业数字化、沉浸式体验升级的行业浪潮下,AR 智能穿戴设备正逐步打破传统文旅讲解的边界,让文物古迹走出展牌文字,以鲜活、立体、随身化的方式与游客完成跨时空对话。传统景区、博物馆讲解模式长期存在诸多痛点:人…...

告别演讲超时焦虑:PPT悬浮计时器如何让你成为时间掌控大师?
告别演讲超时焦虑:PPT悬浮计时器如何让你成为时间掌控大师? 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 你是否曾在重要演讲中因为忘记时间而匆忙收尾?是否在课堂演示时因…...

全面修复:Windows更新重置工具的完整使用指南
全面修复:Windows更新重置工具的完整使用指南 【免费下载链接】Script-Reset-Windows-Update-Tool This script reset the Windows Update Components. 项目地址: https://gitcode.com/gh_mirrors/sc/Script-Reset-Windows-Update-Tool Script-Reset-Windows…...

Face Analysis WebUI新手指南:如何准确分析人脸年龄、性别和头部姿态
Face Analysis WebUI新手指南:如何准确分析人脸年龄、性别和头部姿态 1. 引言:人脸分析的实际价值 想象一下,你正在整理家庭相册,想知道照片中每个人的年龄;或者你运营着一个社交媒体平台,需要分析用户头…...

Local SDXL-Turbo入门必看:零基础玩转‘所见即所得’流式生图
Local SDXL-Turbo入门必看:零基础玩转‘所见即所得’流式生图 想象一下这样的场景:你在键盘上输入"一只可爱的猫咪",屏幕上瞬间就出现了一只猫咪的轮廓。你再输入"戴着墨镜",猫咪立刻戴上了酷酷的墨镜。继续…...