提速Rust编译器!
Nethercote是一位研究Rust编译器的软件工程师。最近,他正在探索如何提升Rust编译器的性能,在他的博客文章中介绍了Rust编译器是如何将代码分割成代码生成单元(CGU)的以及rustc的性能加速。
他解释了不同数量和大小的CGU之间的权衡以及Rustc是如何使用LLVM并行化代码生成和优化的。此外,Nethercote还探索了一些形成和排序CGU的替代方法,并报告了他的实验结果。
Nethercote发现,很多时候,无法在编译速度、内存占用、编译体积和质量上都实现提升,一个指标的提升,经常伴随另一个性能指标的下降。尽管他没有发现比现有方法更明显的改进,但还是希望在未来继续研究这个问题。
如何提升Rust编译器速度?这篇文章或许能帮助到你!
1、LLVM:Rust编译加速的秘诀
Rust的MIR是HIR到LLVM IR的中间产物,将MIR转换为LLVM IR,然后将其传递给LLVM,从而生成机器代码。在此过程中,LLVM能通过处理多个模块实现并行。Rustc使用LLVM加速Rust的编译。我们称其中的每个模块为“代码生成单元(CGU)”。
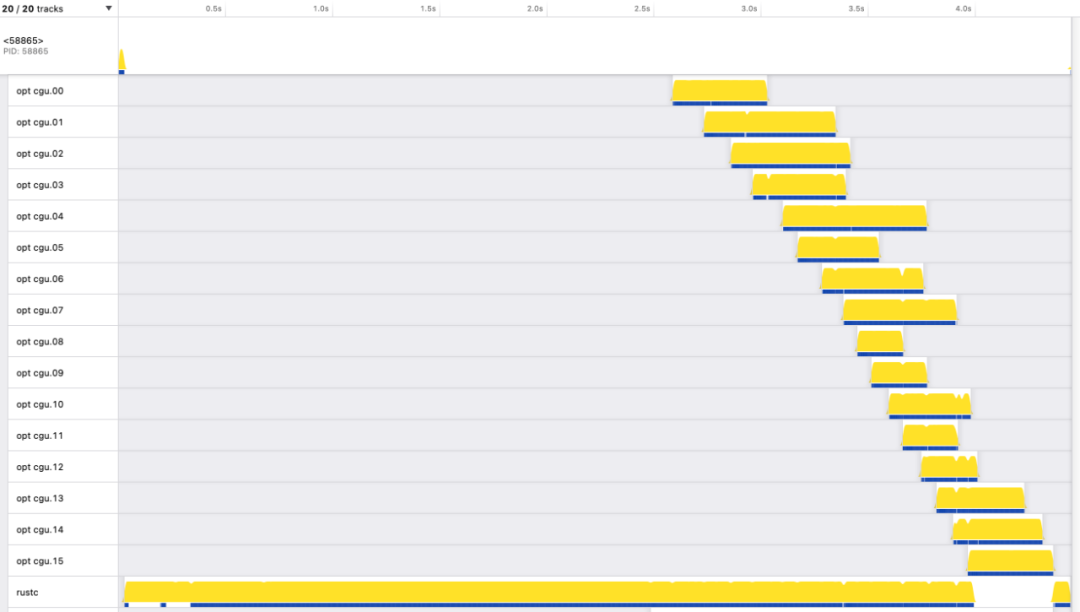
图:时间位于 x 轴上,每条水平线代表一个线程。主线程显示在顶部,标有 PID。它在开始时处于活动状态,时间足以产生另一个标记为 的线程rustc。rustc底部显示的线程在大部分执行过程中都处于活动状态。还有 16 个 LLVM 线程标记opt cgu.00为 到opt cgu.15,每个线程都会在短时间内处于活动状态。
CGU实际上是如何形成的呢?粗略地说,Rust 程序由许多函数组成,这些函数形成一个有向图,其中从一个函数到另一个函数的调用构成了一条边。我们需要将这个图分割成块(CGU),这是一个图分区问题。我们希望创建大小大致相等的 CGU(因此 LLVM 处理它们所需的时间长度大致相同),并最大限度地减少它们之间的边数(因为这使 LLVM 的工作更轻松,并带来更好的代码质量) 。
实际上,由于我们上面看到的阶梯效应,我们不希望 CGU 的大小完全相同。理想的情况是 CGU 大小存在与梯度相匹配的轻微梯度。这样,所有 CGU 将完全相同地完成处理,以实现最大程度的并行化。
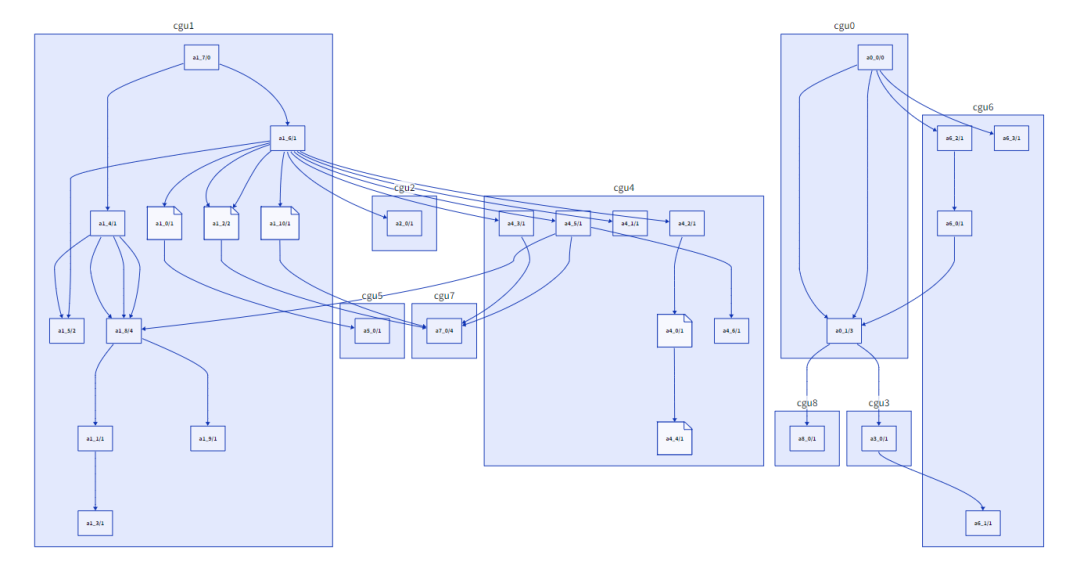
合并之前的CGU(9个)
Nethercote认为在合并之前“调整”CGU可能会有所帮助,在某些情况下将函数从一个CGU移动到另一个。例如,如果在CGU A中被调用f的叶函数(即不调用任何其他函数的叶函数)在CGU B中有一个调用方g,那么将f从A移动到B是有意义的,从而去除CGU间的边。(还有其他类似的情况涉及非叶函数,移动也有意义)。我实现了这一点,它给出了一些适度的改进,但我目前还没有决定它是否值得额外的复杂性。
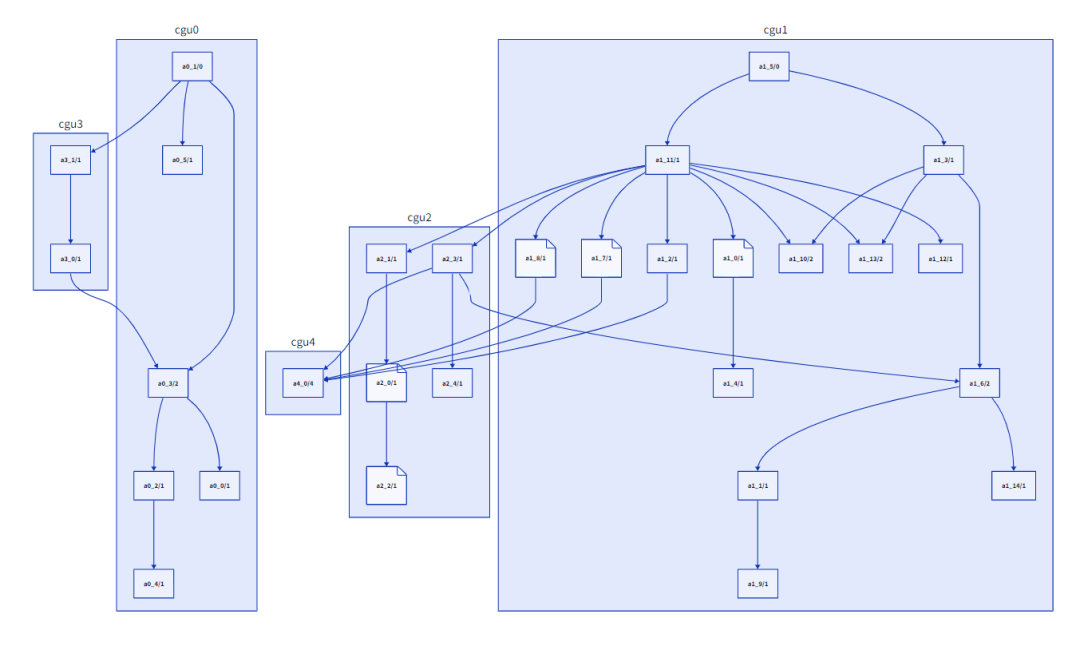
调整之后的CGU(5个)
在实现这一点的同时,我还花了一些时间来可视化调用图。我从GraphViz开始。这些图表对于非常小的程序来说看起来不错,但对于较大的程序来说,它们很快就变得无法读取和导航。我在Mastodon上抱怨过这一点,并得到了使用d2的建议,d2速度较慢,但图形可读性更强。

2、后端并行方法的软肋
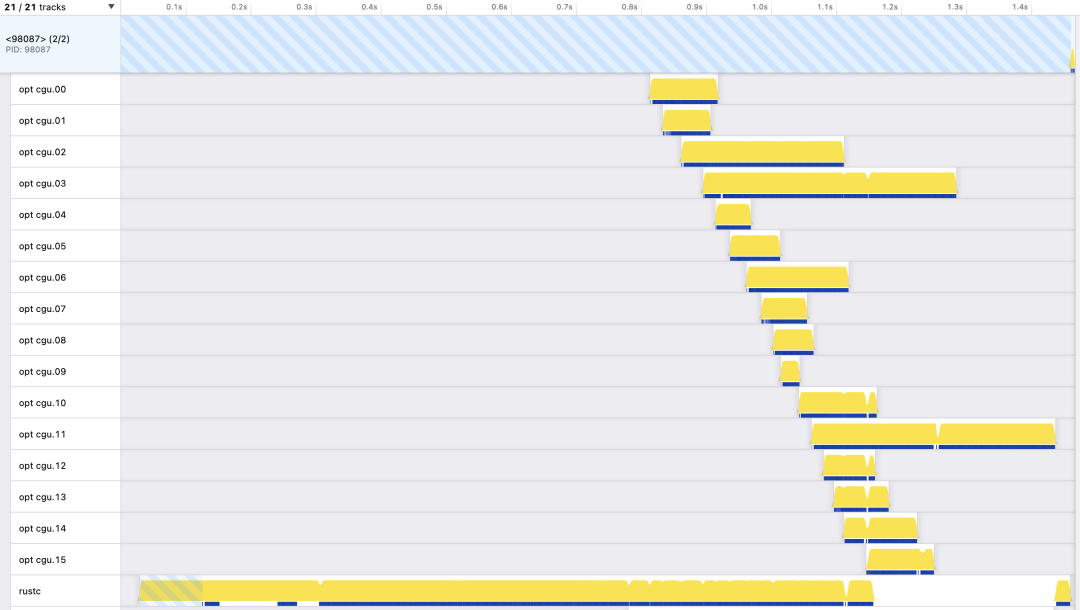
图划分是一个 NP 难题。有几种常见的算法,实现起来相当复杂。相反,rustc 做了一些更简单的事情。首先简单地为每个 Rust 模块创建一个 CGU:模块中的每个函数都放入同一个 CGU 中。然后,如果 CGU 数量超过限制(默认情况下,非增量构建为 16 个,增量构建为 256 个),它会重复合并两个最小的 CGU,直到达到限制。这种方法简单、快速,并以有用的方式利用特定领域的知识——程序模块往往提供良好的自然边界。
所有这一切都依赖于测量 CGU 大小的方法。目前使用CGU中的MIR语句的数量来估计LLVM处理CGU需要多长时间。这里有很大的设计空间,有许多其他可能的形成和规划CGU 的方法。
这种转换对Rust众多语法糖进行了脱糖,并且极大精简了Rust的语法(但并非其语法子集),是观察和分析Rust代码的常用手段,尤其是在控制流图和借用检查等方面。
在这篇文章的最后,Nethercote提供了几个数据集的链接,每个数据集都记录了编译rust -performance基准时每个CGU的测量值。这些数据集包括许多测量静态代码大小的输入(独立变量),例如,函数数量和MIR数量等。
Nethercote试着用scikit-learn做一些基本的分析。并且,通过这些基本的分析,能让Nethercote仔细推敲到底应该搜集哪些测量值。
通过一系列的改进优化,他获得的最终数据集比刚开始时的数据更准确。但是,并没有通过这些数据获得多少实际的结果。实际上,每次我对测量的内容改变后都会得到完全不同的结果。
3、实现更快的Lexer
词法分析(lexical analysis)是编译器的第一个阶段,实现词法分析的代码称为lexer。
有人最近研究了logos(https://github.com/maciejhirsz/logos)这个在rust中广受欢迎的lexer。
此前,logos声称其目标是能比手动实现的lexer更快,作者提出了质疑,因为在他看来,通用性和性能无法兼得。因此,他一步步实现了lexer,探索了多种优化技巧,并与logos进行了多轮性能对比。
最终的结果表明,手动实现的基于状态机的lexer比logos实现了20%左右的性能提升。
4、从错误中学习:使用Rust实现DLL注入
Rust是一种注重安全性的编程语言,但在某些情况下,开发人员可能需要使用unsafe关键字来执行某些操作。unsafe可以提供更高的性能,但可能会牺牲安全性。因此,开发人员在使用时需要非常小心。几个使用unsafe的常见场景包括:访问裸指针、调用外部C函数等,并提供了一些建议和最佳实践,以确保在使用unsafe时不会引入潜在的安全隐患。
举个应用方面的例子:原来,作者一直在用C++编写逆向工具,但是,C++这门语言并不友好,于是研究了下如何使用Rust实现DLL注入的“工具”。
大致原理就是让Rust首先生成一个C样式的DLL,然后,使用unsafe操作裸指针,操作程序内存,最后实现DLL注入就可以了。
5、期待更准确的估计函数
Nethercote 希望具有数据分析专业知识的人可以做得更好,重点关注以下几个方面:
1)更匹配的估计函数
2)想要使编译器比现在更快,一个更好的估计函数也许不会达到预期的效果。我提出了一些更好的统计方法,但并没有提升编译速度,甚至变差。
3)CGU调度效果不可预测,你不能假设一个估计函数好几个百分点就会使编译器更快。话虽如此,我希望改进力度足够大,能够转化为实际的加速。
4)对于估计函数来说,最好高估CGU编译所需的时间,而不是低估。
5)我很担心过度拟合。数据集来自一台机器,但实际上,rustc会运行在不同的机器上,具有各种各样的体系结构和微体系结构。
6)这些数据集来自单一版本的rustc,使用单一版本的LLVM。我担心随着时间的推移准确性可能会漂移。
7)我更喜欢不太复杂且易于理解的估计函数。当前的函数非常简单,在大多数情况下只是增加了基本模块和语句的数量。例如:0大小的CGU应该别估计为花费非常接近于0的时间。
8)估计函数有一个明确的问题,即如果不考虑其内部公式,计算MIR语句可能非常不准确。特别是,单个MIR语句可能变得很长。举个例子:深度向量压力测试的MIR包含一条语句,该语句定义了包含超过100,000个元素的向量字面量。不出所料,当前的估计函数严重低估了编译这个基准所需的时间。
Nethercote最后提醒:希望以上的请求是合理的!
以下是上文提到的数据集:
- 调试构建,主要基准测试
https://nnethercote.github.io/aux/2023/07/25/Debug-Primary.txt
- 选择构建,主要基准
https://nnethercote.github.io/aux/2023/07/25/Opt-Primary.txt
- 调试构建,二级基准测试
https://nnethercote.github.io/aux/2023/07/25/Debug-Secondary.txt
- 选择构建,二级基准
https://nnethercote.github.io/aux/2023/07/25/Opt-Secondary.txt
- 顺便说一句:在这些数据集中,主要基准测试比次要基准测试更重要,次要基准测试包括压力测试、微基准测试和其它不符合实际的代码。
相关内容拓展:(技术前沿)
近10年间,甚至连传统企业都开始大面积数字化时,我们发现开发内部工具的过程中,大量的页面、场景、组件等在不断重复,这种重复造轮子的工作,浪费工程师的大量时间。
针对这类问题,低代码把某些重复出现的场景、流程,具象化成一个个组件、api、数据库接口,避免了重复造轮子。极大的提高了程序员的生产效率。
推荐一款程序员都应该知道的软件JNPF快速开发平台,采用业内领先的SpringBoot微服务架构、支持SpringCloud模式,完善了平台的扩增基础,满足了系统快速开发、灵活拓展、无缝集成和高性能应用等综合能力;采用前后端分离模式,前端和后端的开发人员可分工合作负责不同板块,省事又便捷。
体验官网:https://www.jnpfsoft.com/?csdn,还没有了解低代码这项技术可以赶紧体验学习!
参考资料:
1.https://nnethercote.github.io/2023/07/25/how-to-speed-up-the-rust-compiler-data-analysis-assistance-requested.html
2.https://geo-ant.github.io/blog/2023/unsafe-rust-exploration/
3.https://nnethercote.github.io/2023/07/11/back-end-parallelism-in-the-rust-compiler.html
相关文章:
提速Rust编译器!
Nethercote是一位研究Rust编译器的软件工程师。最近,他正在探索如何提升Rust编译器的性能,在他的博客文章中介绍了Rust编译器是如何将代码分割成代码生成单元(CGU)的以及rustc的性能加速。 他解释了不同数量和大小的CGU之间的权衡…...
QT创建项目
可选择CMake或qmake...

基于vue3+webpack5+qiankun实现微前端
一 主应用改造(又称基座改造) 1 在主应用中安装qiankun(npm i qiankun -S) 2 在src下新建micro-app.js文件,用于存放所有子应用。 const microApps [// 当匹配到activeRule 的时候,请求获取entry资源,渲染到containe…...

华为OD真题--完美走位--带答案
2023华为OD统一考试(AB卷)题库清单-带答案(持续更新)or2023年华为OD真题机考题库大全-带答案(持续更新) 题目描述 输入一个长度为4的倍数的字符串Q,字符串中仅包含WASD四个字母。 将这个字符串中的连续子串…...
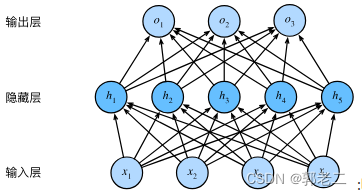
【AI】《动手学-深度学习-PyTorch版》笔记(十四):多层感知机
AI学习目录汇总 1、多层感知机网络结构 1.1 线性模型:softmax回归 在前面介绍过,使用softmax回归来处理分类问题时,每个输出通过都一个仿射函数计算,网络结构如下,输入和输出之间为全链接层: 1.2 多层感知机 多层感知机就是在输入和输出中间再添加一个或多个全链接…...
本地开发 npm 好用的http server、好用的web server、静态服务器
好用的web server总结 有时需要快速启动一个web 服务器(http服务器)来伺服静态网页,安装nginx又太繁琐,那么可以考虑使用npm serve、http-server、webpack-dev-server。 npm serve npm 的serve可以提供给http server功能&#…...
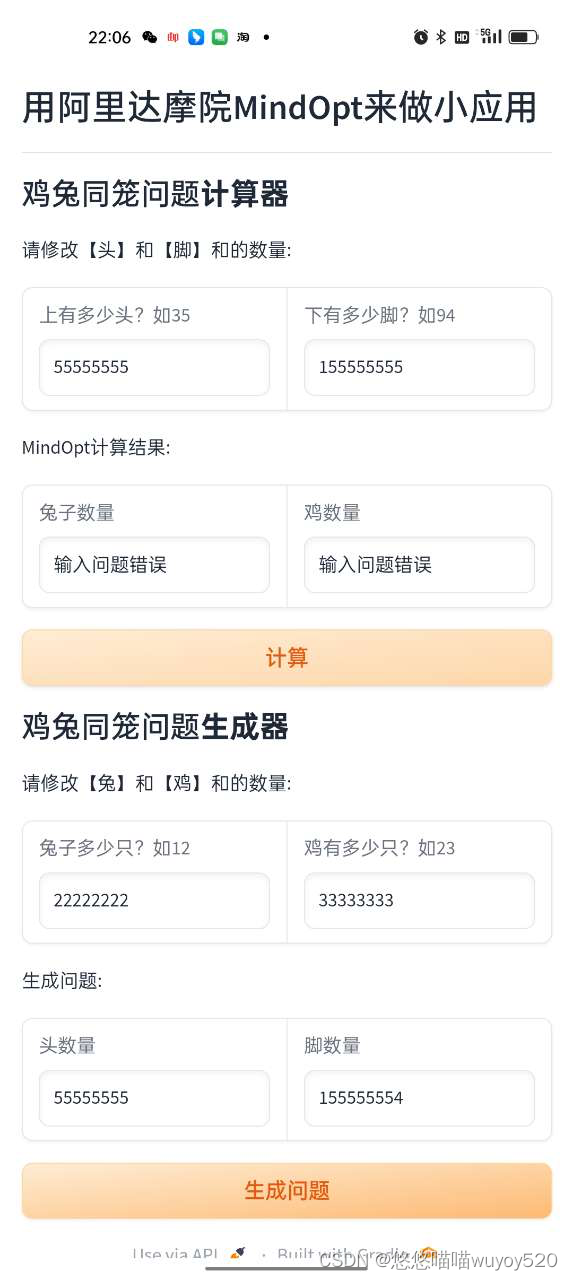
Gradio入门,并搭个鸡兔同笼问题小应用,附源码(MindOpt)
应用链接: https://979427749bc9ceec34.gradio.live 是公开访问链接,3天有效。 在modelscope中的创空间发布长期有效:https://modelscope.cn/studios/wuyoy520v01/MindOpt_Chicken-with-rabbit-cage/summary。 应用图如下,源代码见正文。 知…...

redis核心知识点简略笔记
value数据类型 string 二进制安全 list 有序、可重复 set 无序、不重复 hash field-value的map sorted set 不重复、通过double类型score分数排序 场景 string 计数器缓存分布式锁访问频率控制分布式session hash 购物车等对象属性灵活修改 list 定时排行榜 set 收藏 sorte…...
消息中间件 —— 初识Kafka
文章目录 1、Kafka简介1.1、消息队列1.1.1、为什么要有消息队列?1.1.2、消息队列1.1.3、消息队列的分类1.1.4、p2p 和 发布订阅MQ的比较1.1.5、消息系统的使用场景1.1.6、常见的消息系统 1.2、Kafka简介1.2.1、简介1.2.2、设计目标1.2.3、kafka核心的概念 2、Kafka的…...
Ceph集群安装部署
Ceph集群安装部署 目录 Ceph集群安装部署 1、环境准备 1.1 环境简介1.2 配置hosts解析(所有节点)1.3 配置时间同步2、安装docker(所有节点)3、配置镜像 3.1 下载ceph镜像(所有节点执行)3.2 搭建制作本地仓库(ceph-01节点执行)3.3 配置私有仓库(所有节点执行)3.4 为 Docker 镜像…...

PXC基于docker搭建mysql集群全过程
之前用mysql自带的bin-log复制,总是因为各种冲突,同步就阻塞掉了,一旦阻塞掉了,不主动发现,同步就终止了。还需要想办法手动去处理。所以考虑重新搭建集群。发现PXC方案不错,可以上两台,对服务器…...
项目知识点记录
1.使用druid连接池 使用properties配置文件: driverClassName com.mysql.cj.jdbc.Driver url jdbc:mysql://localhost:3306/book?useSSLtrue&setUnicodetrue&charsetEncodingUTF-8&serverTimezoneGMT%2B8 username root password 123456 #初始化链接数…...

【HDFS】ListenableFuture在HDFS中的应用
本文主要介绍以下内容: ListenableFuture提供的功能和基本使用方法;AsyncLogger、IPCLoggerChannel(它是AsyncLogger的子类)QuorumCall类一、ListenableFuture的基本使用 ListenableFuture 是 Guava 库中提供的一个接口,它扩展了 JDK 中的 Future 接口,并添加了异步任务…...

Databend 开源周报第 105 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 Databend 轻量级…...

ArcGISPro随机森林自动化调参分类预测模型展示
更改ArcGISPro的python环境变量请参考文章 ArcGISPro中如何使用机器学习脚本_Z_W_H_的博客-CSDN博客 脚本文件如下 点击运行 结果展示 负类预测概率 正类预测概率 二值化概率 文件夹(模型验证结果) 数据集数据库 ROC曲线 由于个人数据量太少所以…...

科技资讯|苹果手机版Vision Pro头显专利曝光,内嵌苹果手机使用
根据美国商标和专利局(USPTO)公示的清单,苹果公司近日获得了一项头显相关的技术专利,展示了一款亲民款 Vision Pro 头显,可以将 iPhone 放置在头显内部充当屏幕。 根据patentlyapple 媒体报道,这是苹果公司…...

Linux服务器映射到本地磁盘
内容来自网友博客。 把linux服务器上的文件夹映射到本地作为一个磁盘来访问,步骤如下 一. samba的安装: sudo apt-get install samba // (sudo get temp root auth) sudo apt-get install smbfs //旧版本 sudo apt-get install cifs-utils //新版本 上…...

条条大路通罗马系列—— 使用 Hiredis-cluster 连接 Amazon ElastiCache for Redis 集群
前言 Amazon ElastiCache for Redis 是速度超快的内存数据存储,能够提供亚毫秒级延迟来支持 实时应用程序。适用于 Redis 的 ElastiCache 基于开源 Redis 构建,可与 Redis API 兼容,能够与 Redis 客户端配合工作,并使用开放的 Re…...

元宇宙核能发电VR模拟仿真实训教学为建设新型电力系统提供重要支撑
随着“碳达峰、碳中和”目标与建设新型能源体系的提出,在元宇宙环境下建设电力系统是未来发展的趋势。以物联网、区块链、数字孪生、混合现实等技术为主要代表的元宇宙技术体系及其在电力和能源系统中的应用,将会促进智能电网的发展,为建设新…...
我的Python教程:使用Pyecharts画柱状图
Pyecharts是一个用于生成 Echarts 图表的 Python 库。Echarts 是一个基于 JavaScript 的数据可视化库,提供了丰富的图表类型和交互功能。通过 Pyecharts,你可以使用 Python 代码生成各种类型的 Echarts 图表,例如折线图、柱状图、饼图、散点图…...
)
从ISO9506到实际报文:手把手用Wireshark解码一个MMS数据包(含ASN.1/BER解析实战)
从ISO9506到实际报文:手把手用Wireshark解码一个MMS数据包(含ASN.1/BER解析实战) 当你面对工业控制网络中捕获的陌生流量时,能否准确识别出隐藏在TCP端口102背后的MMS协议通信?本文将带你从协议标准出发,通…...

OpenClaw近期生态安全事件解读:从RCE漏洞到Skill供应链投毒分析
引言 2025年底至2026年初,AI领域从对话式大模型向自主式智能代理(Agentic AI)发生了重大转变。在这一浪潮中,由开发者Peter Steinberger主导的开源项目OpenClaw(早期名为Clawdbot与Moltbot)成为最具颠覆性…...

别再为农田边界发愁了!用GEE的MODIS数据给Landsat影像‘开个挂’,30米精度轻松拿捏
农田边界提取革命:用GEE融合MODIS与Landsat实现亚像元级精度 当500米分辨率的MODIS遇上30米精度的Landsat,会产生怎样的化学反应?在农业遥感领域,这个看似不可能的组合正在颠覆传统农田边界提取的工作流程。本文将带您探索如何通过…...

SATA系列专题之七:NCQ指令重排与FPDMA传输机制深度剖析
1. 从机械臂到智能管家:NCQ如何重塑硬盘工作逻辑 想象一下老式点唱机点播歌曲的场景:机械臂必须按照用户点歌的先后顺序移动到对应黑胶唱片的位置。如果第一首歌在最外侧,第二首歌在最内侧,机械臂就不得不来回摆动——这就是传统硬…...

绕过平台敏感词审查?聊聊零宽度字符的‘另类’用法与安全风险
零宽度字符:技术原理、应用场景与安全防御实践 在数字世界的文字海洋里,潜藏着一类特殊的"隐形墨水"——它们不占据视觉空间,却能改变文本的呈现方式。这类被称为零宽度字符的Unicode元素,原本是为了解决多语言排版问题…...

从电机控制到新能源并网:深入浅出图解Clark/Park变换的工程应用场景
从电机控制到新能源并网:深入浅出图解Clark/Park变换的工程应用场景 坐标变换技术就像电力电子领域的"瑞士军刀",在不同应用场景中展现出惊人的适应性。第一次接触Clark和Park变换时,许多工程师都会被矩阵运算吓退,但真…...

Arduino 运行异常的 7 个典型诱因与规避策略
1. 函数调用过载引发的崩溃 Arduino最常见的崩溃场景之一就是函数调用堆栈溢出。这个问题特别容易出现在递归函数设计中,我曾经在一个温控项目中就踩过这个坑。当时为了计算温度变化趋势,我写了个递归函数,结果设备运行不到半小时就自动重启。…...

【AGI能源治理黄金标准】:从IEEE P2857到中国《智能能源代理系统规范》强制实施前夜的关键适配指南
第一章:AGI能源治理黄金标准的全球演进与时代意义 2026奇点智能技术大会(https://ml-summit.org) 随着通用人工智能(AGI)从理论构想加速迈向系统级部署,其算力消耗已突破传统数据中心能效边界。全球头部研究机构与政策制定者正协…...

终极Visual C++运行库一键解决方案:告别DLL缺失的5个简单步骤
终极Visual C运行库一键解决方案:告别DLL缺失的5个简单步骤 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否经常遇到"无法启动程序&#…...

华硕路由器AdGuard Home完整部署指南:打造无广告家庭网络终极方案
华硕路由器AdGuard Home完整部署指南:打造无广告家庭网络终极方案 【免费下载链接】Asuswrt-Merlin-AdGuardHome-Installer The Official Installer of AdGuardHome for Asuswrt-Merlin 项目地址: https://gitcode.com/gh_mirrors/as/Asuswrt-Merlin-AdGuardHome-…...