测试老鸟经验总结,Jmeter性能测试-重要指标与性能结果分析(超细)
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
Aggregate Report 是 JMeter 常用的一个 Listener,中文被翻译为“聚合报告
如果大家都是做Web应用的性能测试,例如只有一个登录的请求,那么在Aggregate Report中,会显示一行数据,共有10个字段,含义分别如下。
1、Lable:每个Jmeter的element(例如Http Request)都有一个Name属性,这里显示就是Name属性的值
2、Samples:表示这次测试一共发出了多少次请求,如果模拟10用户,每个用户迭代10次,那么这里显示100
3、Average:平均响应时间–默认情况下是单个Request的平均时间,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时间
4、Median:50%用户响应时间
5、90%Line:90%用户的响应时间
6、Min:最小响应时间
7、Max:最大响应时间
8、Error%:本次测试出现错误的请求的数量/请求总数
9、Troughput:吞吐量—默认情况下表示每秒完成的请求数量(Request per second),当使用了Transaction Controller时,也可以表示类似Loadruner的Transaction per second数
10、KB/Sec:每秒从服务器端接收的数量,相当于Loadrunner的Throughput/Sec
描述性统计与性能结果分析
疑惑点:90%响应时间是什么意思?这个值在进行性能分析时有什么作用?
为什么要有90%用户响应时间?
因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?
你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?
假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?
假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?

在上面这个表中包含了几个不同的列,其含义如下:
CmdID:测试时被请求的页面
NUM:响应成功的请求数量
MEAN:所有成功的请求的响应时间的平均值
STD DEV:标准差
MIN: 响应时间的最小值
50 th(60/70/80/90/95 th):如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义
MAX:响应时间的最大值
性能测试小结
1、90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%;
2、对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况;
3、(重点)从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。
也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;
对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的;
4、你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。
这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的;
5、 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况;
6、在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。
实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的;
7、上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
聚合报告中的,吞吐量=完成的transaction数/完成这些transaction数所需要的时间;
平均响应时间=所有响应时间的总和/完成的transaction数;
失败率=失败的个数/transaction数总的来说,对于jmeter的结果分析,主要就是对jtl文件中原始数据的整理。
8、TestPlan :是整个Jmeter测试执行的容器
9、ThreadGroup :模拟请求,定义线程数、Ramp-Up Period、循环次数。
10、Step1 :循环控制器 ,控制Sample的执行次数。
11、怎样计算Ramp-up period时间?
Ramp-up period是指每个请求发生的总时间间隔,单位是秒。
如果Number of Threads设置为5,而Ramp-up period是10,那么每个请求之间的间隔就是10/5,也就是2秒。
Ramp-up period设置为0,就是同时并发请求。
12、为什么Aggregate Report结果中的Total值不是真正的总和?
JMeter给结果中total的定义是并不完全指总和,为了方便使用,它的值表现了所在列的代表值,比如min值,它的total就是所在列的最小值。
13、在运行结果中为何有rate为N/A的情况出现?
可能因为JMeter自身问题造成,再次运行可以得到正确结果。
14、在使用JMeter测试时,是完全模拟用户操作么?造成的结果也和用户操作完全相同么?
是的。JMeter完全模拟用户操作,所以操作记录会全部写入DB.在运行失败时,可能会产生错误数据,这就取决于脚本检查是否严谨,否则错误数据也会进入DB,给程序运行带来很多麻烦。
小心缓存(类似查询接口压测,先问问有没有做缓存);
瓶颈处持续压测,测试系统稳定性;
线上真实的一模一样的环境配置;
缓存洞穿,持续压测/去缓存压测/有缓存压测;
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通

二、接口自动化项目实战

三、Web自动化项目实战
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
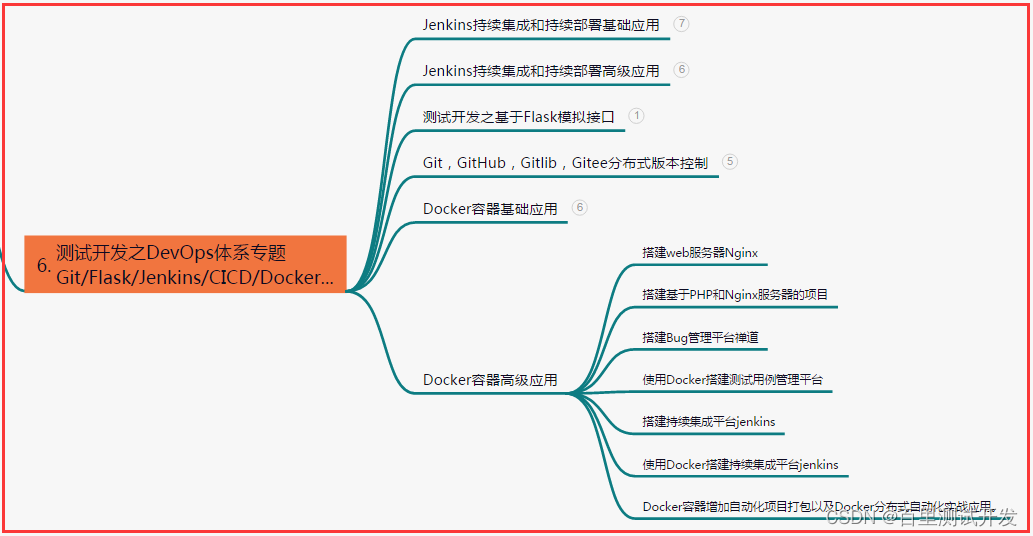
七、常用自动化测试工具

八、JMeter性能测试
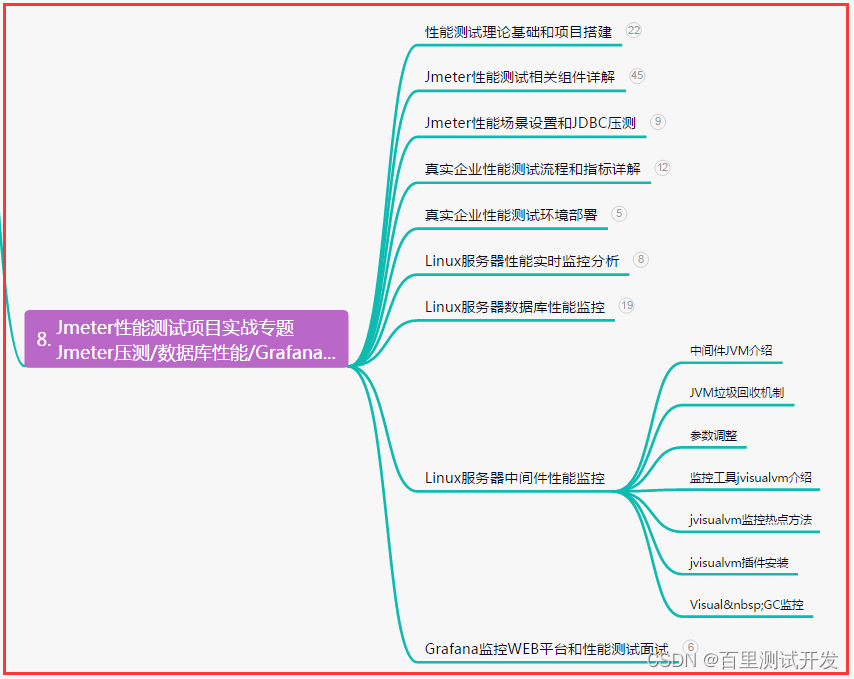
九、总结(尾部小惊喜)
奋斗是一种态度,成功是一种选择。不论遇到多大困难,不抛弃、不放弃,坚持追求梦想的信念。每一次努力都是改变命运的机会,相信自己的力量,勇往直前!
生命不息,奋斗不止。燃烧心中的激情,追寻内心的渴望。困难只是暂时的,坚持是永恒的力量。拥抱挑战,超越极限,只要敢于去追逐,成功必将属于你!
不要因为失败而停下脚步,而是因为脚步而改变未来。勇敢面对挑战,坚持自己的梦想,相信自己的实力。每一次努力都是收获的种子,不断奋斗。
相关文章:
测试老鸟经验总结,Jmeter性能测试-重要指标与性能结果分析(超细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Aggregate Report …...
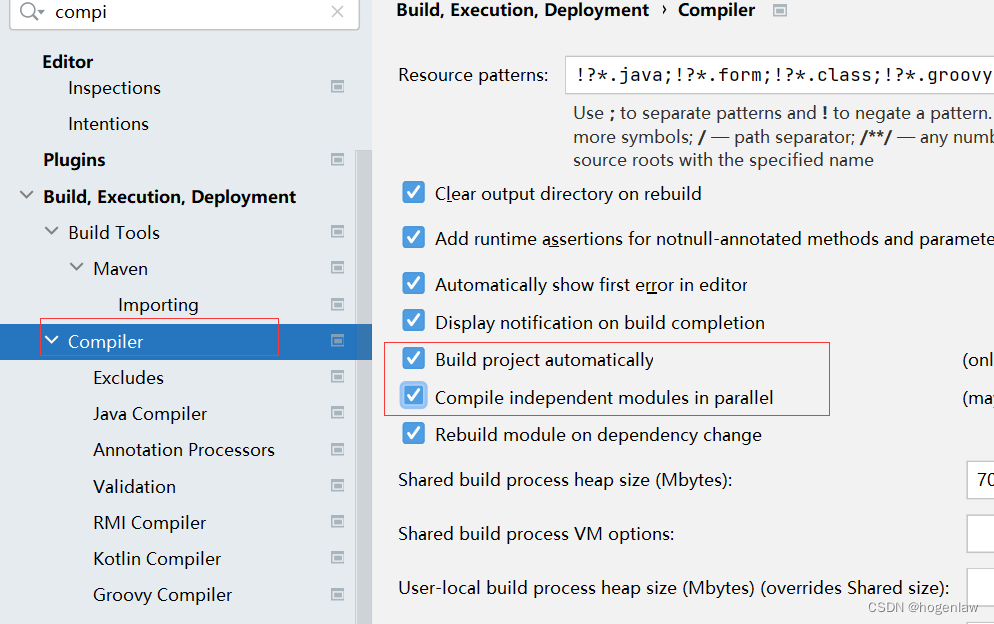
IDEA设置Maven自动编译model
IDEA设置Maven自动编译model 项目工程结构IDEA maven设置 项目工程结构 假设我们的项目结构是下图这样,也就是一个父工程下包含多个子模块,其中dubbo-01-api是公共模块,其它两个模块要想使用必须在pom文件中引入。 本地开发要想不会报错&am…...

关于本地mockjs的使用
安装mockjs npm install mockjs -s在src下新建目录mockData,所有mock请求可以放该文件夹下面。例如在mockData文件夹下新建一个home.js文件。用来处理首页的请求数据 home.js export default {getHomeData:()>{return{code:200,data:{tableData:[{name:张三,se…...

hive 中最常用日期处理函数
hive 常用日期处理函数 在工作中,日期函数是提取数据计算数据必须要用到的环节。哪怕是提取某个时间段下的明细数据也得用到日期函数。今天和大家分享一下常用的日期函数。为什么说常用呢?其实这些函数在数据运营同学手上是几乎每天都在使用的。 技术交…...
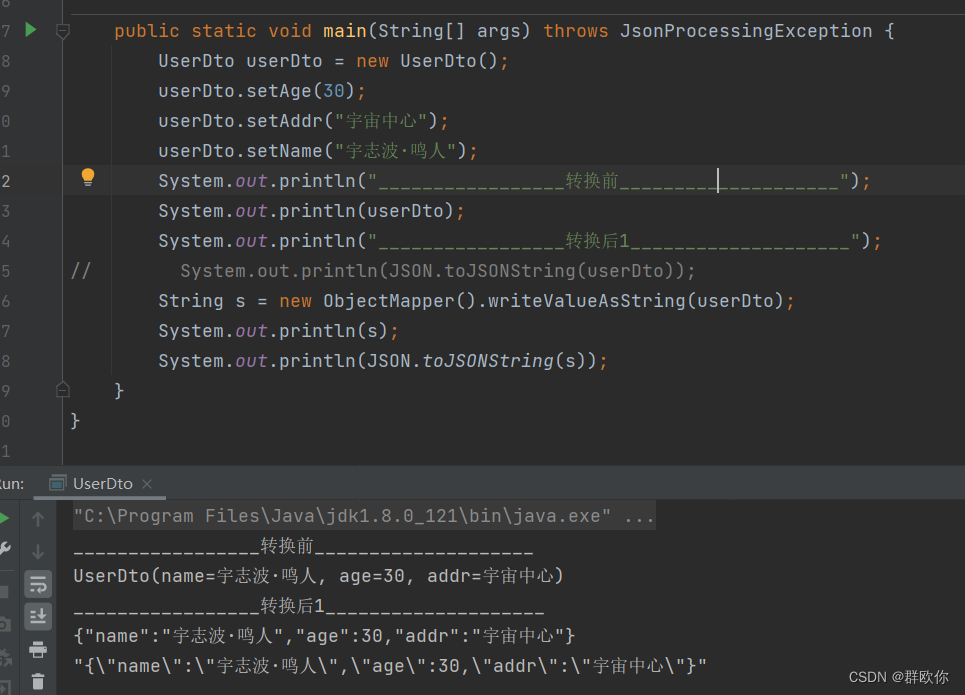
记录一下Java实体转json字段顺序问题
特殊需求,和C交互他们那边要求字段顺序要和他们定义的一致(批框架) 如下: Data public class UserDto {private String name;private Integer age;private String addr; }未转换前打印: 转换后打印: 可以看到转换为json顺序打印…...
)
微积分入门:总结归纳汇总(一)
基础 标准符号约定: ( s i n x ) n (sinx)^n (sinx)...

ubuntu python虚拟环境venv搭配systemd服务实战(禁用缓存下载--no-cache-dir)
文章目录 参考文章目录结构步骤安装venv查看python版本创建虚拟环境激活虚拟环境运行我们程序看缺少哪些依赖库,依次安装它们接下来我们配置python程序启动脚本,脚本中启动python程序前需先激活虚拟环境配置.service文件然后执行部署脚本,成功…...

案例15 Spring Boot入门案例
1. 选择Spring Initializr快速构建项目 2. 设置项目信息 3. 选择依赖 4. 设置项目名称 5. 项目结构 6. 项目依赖 自动配置了Spring MVC、内置了Tomcat、配置了Logback(日志)、配置了JSON。 7. 创建HelloController类 com.wfit.boot.hello目录下创建HelloCo…...

物联网是下一个风口吗?
随着科技的持续进步,物联网行业正在迅速兴起,展现出巨大的潜力。那么,物联网行业的未来是什么样的呢? 1. 5G技术的广泛应用和普及 随着5G技术的快速发展和商业化推广,物联网行业将迎来一个巨大的飞跃。5G技术的高速传…...

8月9日上课内容 nginx反向代理与负载均衡
负载均衡工作当中用的很多的,也是面试会问的很重要的一个点 负载均衡:通过反向代理来实现(nginx只有反向代理才能做负载均衡) 正向代理的配置方法(用的较少) 反向代理的方式:四层代理与七层代…...
易服客工作室:Elementor AI简介 – 彻底改变您创建网站的方式
Elementor 作为领先的 WordPress 网站构建器,是第一个添加本机 AI 集成的。Elementor AI 的第一阶段将使您能够生成和改进文本和自定义代码(HTML、自定义代码和自定义 CSS)。我们还已经在进行以下阶段的工作,其中将包括基于人工智…...

ClickHouse的数据类型
1.整数型 固定长度的整型,包括有符号整型或无符号整型。整型范围(-2n-1~2n-1-1): Int8 - [-128 : 127] Int16 - [-32768 : 32767] Int32 - [-2147483648 : 2147483647] Int64 - [-9223372036854775808 : 9223372036854775807]无符…...
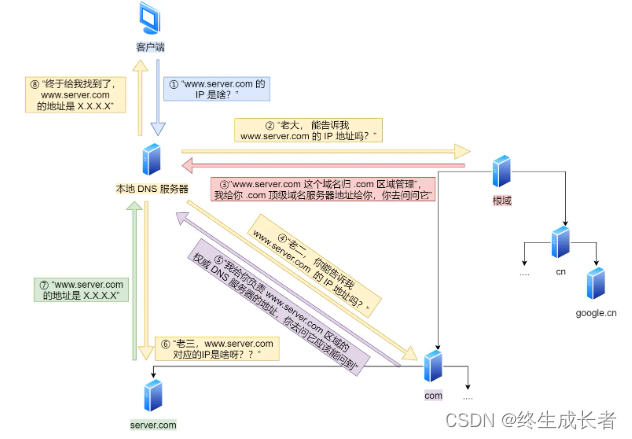
计算机网络—IP
这里写目录标题 IP的基本认识网络层与数据链路层有什么关系IP地址基础知识IP 地址的分类什么是A、B、C类地址广播地址用来做什么什么是D、E类广播多播地址用于什么IP分类的优点IP分类的缺点 无分类地址CIDR如何划分网络号和主机号怎么进性子网划分 公有 IP 地址与私有 IP 地址公…...

Java 的 Stream
一、创建 Stream 1.1、创建 Stream 流 1.1.1、List 集合获取 Stream 流 Collection<String> list new ArrayList<>(); Stream<String> s1 list.stream(); 1.1.2、Map 集合获取 stream 流 Map<String, Integer> map new HashMap<>(); // …...

SolidUI社区-Discord
背景 随着文本生成图像的语言模型兴起,SolidUI想帮人们快速构建可视化工具,可视化内容包括2D,3D,3D场景,从而快速构三维数据演示场景。SolidUI 是一个创新的项目,旨在将自然语言处理(NLP)与计算机图形学相…...

Spring MVCSpring Boot
文章目录 Spring MVC什么是MVC模式Spring MVC优点SpringMVC 运行流程SpringMVC组件SpringMVC常用的注解有哪些SpringMVC的拦截器和过滤器有什么区别?执行顺序是什么 SpringBoot对SpringBoot的理解Spring和SpringBoot的关系?SpringBoot有哪些核心注解Spri…...
)
01-集群安装JDK(普通用户)
机器部署 集群规划 我们准备三台服务器kk01、kk02、kk03,内存4G、硬盘50G、处理器4核心2内核(总8) kk01使用 192.168.188.128 kk02使用 192.168.188.129 kk03使用 192.168.188.130 模板机准备 我们先创建一台作为模板机,后…...

小龟带你妙写排序之选择排序
选择排序 一. 原理二. 题目三. 思路分析四. 代码 一. 原理 选择排序(Selection-sort)是一种简单直观的排序算法。 工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未…...

深入解析 SOCKS5 代理及其在网络安全与爬虫中的应用
在当今数字化时代,网络安全和数据获取成为了互联网时代的重要课题。为了实现安全的网络连接和高效的数据采集,各种代理技术应运而生。本文将深入探讨 SOCKS5 代理及其在网络安全和爬虫领域的应用,同时比较其与其他代理方式的优势与劣势。 1.…...
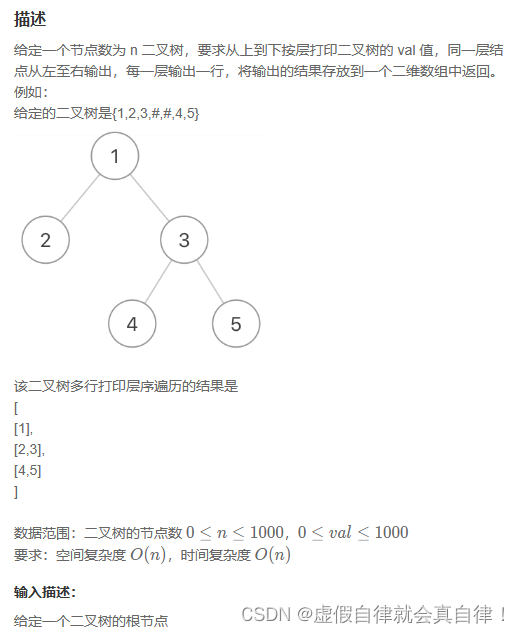
day9 10-牛客67道剑指offer-JZ66、19、20、75、23、76、8、28、77、78
文章目录 1. JZ66 构建乘积数组暴力解法双向遍历 2. JZ19 正则表达式匹配3. JZ20 表示数值的字符串有限状态机遍历 4. JZ75 字符流中第一个不重复的字符5. JZ23 链表中环的入口结点快慢指针哈希表 6. JZ76 删除链表中重复的结点快慢指针三指针如果只保留一个重复结点 7. JZ8 二…...

【Java】继承:从入门到JVM底层,一篇搞定
【Java】继承——语言根基(三)继承:从入门到JVM底层,一篇搞定一、继承到底在表达什么?1.1 is-a关系1.2 什么时候别用继承?二、语法速览三、底层原理:new一个子类对象,内存里发生了什…...
与方差D(XY)计算实例)
深入解析二维随机变量的期望E(XY)与方差D(XY)计算实例
1. 二维随机变量基础概念回顾 在正式进入计算实例之前,我们先花点时间梳理几个关键概念。二维随机变量听起来可能有点抽象,但其实可以把它想象成一对形影不离的好朋友——X和Y总是同时出现。比如统计一个班级学生的身高(X)和体重(Y),或者记录…...

如何用积木报表在5分钟内创建专业级数据报表?终极指南来了!
如何用积木报表在5分钟内创建专业级数据报表?终极指南来了! 【免费下载链接】JimuReport 开源的报表工具与BI大屏,完美替代帆软和Tableau,提供强大的报表能力。一款类似Excel的报表设计器和大屏设计!完全在线傻瓜式拖拽…...
指工作频率低于 1GHz 的无线通信频段)
简单理解:Sub-1GHz(Sub-1 Gigahertz)指工作频率低于 1GHz 的无线通信频段
Sub-1GHz(Sub-1 Gigahertz)指工作频率低于 1GHz 的无线通信频段(通常指 169/315/433/470/868/915MHz 等免授权 ISM 频段),核心是远距离、低功耗、强穿墙、低干扰的物联网无线技术。一、核心特点(vs 2.4GHz&…...
)
STM32H743双FDCAN实战:手把手教你搞定消息RAM分区与过滤表共存(附完整代码)
STM32H743双FDCAN实战:消息RAM分区与过滤表共存深度解析 第一次在H743上同时启用双FDCAN通道时,我遇到了一个诡异现象——CAN1接收的数据偶尔会出现在CAN2的缓冲区里。经过三天调试才发现,问题根源在于那10KB共享消息RAM的配置方式。与传统的…...

Qwen3-4B模型入门教程:部署后如何确认服务正常并开始使用?
Qwen3-4B模型入门教程:部署后如何确认服务正常并开始使用? 1. 教程目标与准备工作 刚部署完Qwen3-4B模型,你可能会有这样的疑问:服务真的跑起来了吗?怎么知道模型已经准备好接受请求了?本教程将带你一步步…...
)
Matlab导入ARXML老报错?手把手教你排查UUID冲突、工具链兼容等常见坑(基于真实项目经验)
Matlab处理ARXML文件实战避坑指南:从UUID冲突到工具链兼容的深度解析 最近在汽车电子领域,AUTOSAR架构已经成为行业标配。作为工程师,我们经常需要在Matlab/Simulink环境中处理ARXML文件,但这个过程往往充满各种"坑"。上…...

如何用解构赋值快速提取数组前几个元素到独立变量
数组解构可安全提取前若干元素,长度不足时对应变量为undefined;支持跳过元素、设置默认值、获取剩余元素(...rest须在末尾);嵌套解构需严格匹配结构,函数参数解构需防null/undefined报错。用 const [a, b, …...

5分钟掌握PlantUML Editor:专业级代码驱动UML绘图工具实战指南
5分钟掌握PlantUML Editor:专业级代码驱动UML绘图工具实战指南 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 还在为绘制复杂的UML图表而烦恼吗?传统的拖拽式绘图…...

WarcraftHelper终极指南:5个简单步骤让魔兽争霸3在现代Windows系统完美运行
WarcraftHelper终极指南:5个简单步骤让魔兽争霸3在现代Windows系统完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸…...