ID3 决策树
西瓜数据集D如下:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
即集合D为分类问题,分类瓜的好坏是一个二分类问题,故|y| =2 ,故只存在p1,p2
信息熵为衡量信息混乱程度的量
记好瓜比例为p1,坏瓜比例为p2
1. 若全是好瓜 , 则 p 1 = 1 , p 2 = 0 E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k = − ( p 1 l o g 2 p 1 + p 2 l o g 2 p 2 ) = 1 ⋅ l o g 2 ⋅ 1 + 0 ⋅ l o g 2 ⋅ 0 = 0 2. 若全是好瓜 , 则 p 1 = 0 , p 2 = 1 E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k = − ( p 1 l o g 2 p 1 + p 2 l o g 2 p 2 ) = 0 ⋅ l o g 2 ⋅ 0 + 1 ⋅ l o g 2 ⋅ 1 = 0 则完全不混乱为全是好瓜或全是坏瓜 , E n t ( D ) = 0 2. 若全是好坏瓜个一半 , 则 p 1 = 1 2 , p 2 = 1 2 E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k = − ( p 1 l o g 2 p 1 + p 2 l o g 2 p 2 ) = − ( 1 2 ⋅ l o g 2 ⋅ 1 2 + 1 2 ⋅ l o g 2 ⋅ 1 2 ) = 1 则最混乱为 E n t ( D ) = 1 1.若全是好瓜,则p_1=1,p_2=0 \\ Ent(D) = -\sum\limits _{k=1}^{|y|}p_klog_2p_k \\= -(p_1log_2p_1 + p_2log_2p_2 ) \\=1\cdot log_2\cdot 1 + 0\cdot log_2\cdot 0 \\=0\\ 2.若全是好瓜,则p_1=0,p_2=1 \\ Ent(D) = -\sum\limits _{k=1}^{|y|}p_klog_2p_k \\= -(p_1log_2p_1 + p_2log_2p_2 ) \\=0\cdot log_2\cdot 0 + 1\cdot log_2\cdot 1 \\=0\\ 则完全不混乱为全是好瓜或全是坏瓜,Ent(D) = 0\\ 2.若全是好坏瓜个一半,则p_1=\frac12,p_2=\frac12 \\ Ent(D) = -\sum\limits _{k=1}^{|y|}p_klog_2p_k \\= -(p_1log_2p_1 + p_2log_2p_2 ) \\=-(\frac12\cdot log_2\cdot \frac12 + \frac12\cdot log_2\cdot \frac12 )\\=1\\ 则最混乱为Ent(D) = 1 1.若全是好瓜,则p1=1,p2=0Ent(D)=−k=1∑∣y∣pklog2pk=−(p1log2p1+p2log2p2)=1⋅log2⋅1+0⋅log2⋅0=02.若全是好瓜,则p1=0,p2=1Ent(D)=−k=1∑∣y∣pklog2pk=−(p1log2p1+p2log2p2)=0⋅log2⋅0+1⋅log2⋅1=0则完全不混乱为全是好瓜或全是坏瓜,Ent(D)=02.若全是好坏瓜个一半,则p1=21,p2=21Ent(D)=−k=1∑∣y∣pklog2pk=−(p1log2p1+p2log2p2)=−(21⋅log2⋅21+21⋅log2⋅21)=1则最混乱为Ent(D)=1
当前样本集合D中第k类样本所占比例为pk(k=1,2,3,…,|y|),则D的信息熵为:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D) = -\sum\limits _{k=1}^{|y|}p_klog_2p_k Ent(D)=−k=1∑∣y∣pklog2pk
信息增益为:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a) = Ent(D) - \sum\limits _{v=1}^V \frac{|Dv|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
import math
D = [
['青绿','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['乌黑','蜷缩','沉闷','清晰','凹陷','硬滑','是'],
['乌黑','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['青绿','蜷缩','沉闷','清晰','凹陷','硬滑','是'],
['浅白','蜷缩','浊响','清晰','凹陷','硬滑','是'],
['青绿','稍蜷','浊响','清晰','稍凹','软粘','是'],
['乌黑','稍蜷','浊响','稍糊','稍凹','软粘','是'],
['乌黑','稍蜷','浊响','清晰','稍凹','硬滑','是'],
['乌黑','稍蜷','沉闷','稍糊','稍凹','硬滑','否'],
['青绿','硬挺','清脆','清晰','平坦','软粘','否'],
['浅白','硬挺','清脆','模糊','平坦','硬滑','否'],
['浅白','蜷缩','浊响','模糊','平坦','软粘','否'],
['青绿','稍蜷','浊响','稍糊','凹陷','硬滑','否'],
['浅白','稍蜷','沉闷','稍糊','凹陷','硬滑','否'],
['乌黑','稍蜷','浊响','清晰','稍凹','软粘','否'],
['浅白','蜷缩','浊响','模糊','平坦','硬滑','否'],
['青绿','蜷缩','沉闷','稍糊','稍凹','硬滑','否']
]
A = ['色泽','根蒂','敲声','纹理','脐部','触感','好瓜']# 当前样本集合D中第k类样本所占比例为pk(k=1,2,3,…,|y|)
# 计算A的信息熵,以数据最后一列为分类
def getEnt(D):# 获取一个类型k->出现次数的mapkMap = dict()for dLine in D:# 获取分类值kk = dLine[len(dLine) - 1]# 获取当前k出现的次数kNum = kMap.get(k)if kNum is None:kMap[k] = 1else:kMap[k] = kNum + 1# 遍历mapdLen = len(D)rs = 0for kk in kMap:pk = kMap[kk]/dLenrs = rs + pk * math.log2(pk)return -rs# 求信息增益,aIndex为属性列号
def getGain(D,aIndex):dMap = dict()for dLine in D:# 获取属性k = dLine[aIndex]# 属性所属的数组dChildren = dMap.get(k)if dChildren is None:dChildren = []dMap[k] = dChildrendChildren.append(dLine)rs = 0 for key in dMap:dChildren = dMap[key]entx = getEnt(dChildren)print(entx)r = len(dChildren)/len(D) * entxrs = rs + rreturn getEnt(D) - rs
相关文章:

ID3 决策树
西瓜数据集D如下: 编号色泽根蒂敲声纹理脐部触感好瓜1青绿蜷缩浊响清晰凹陷硬滑是2乌黑蜷缩沉闷清晰凹陷硬滑是3乌黑蜷缩浊响清晰凹陷硬滑是4青绿蜷缩沉闷清晰凹陷硬滑是5浅白蜷缩浊响清晰凹陷硬滑是6青绿稍蜷浊响清晰稍凹软粘是7乌黑稍蜷浊响稍糊稍凹软粘是8乌黑稍蜷浊响清晰…...

简单线性回归:预测事物间简单关系的利器
文章目录 🍀简介🍀什么是简单线性回归?🍀简单线性回归的应用场景使用步骤:注意事项: 🍀代码演示🍀结论 🍀简介 在数据科学领域,线性回归是一种基本而强大的统…...
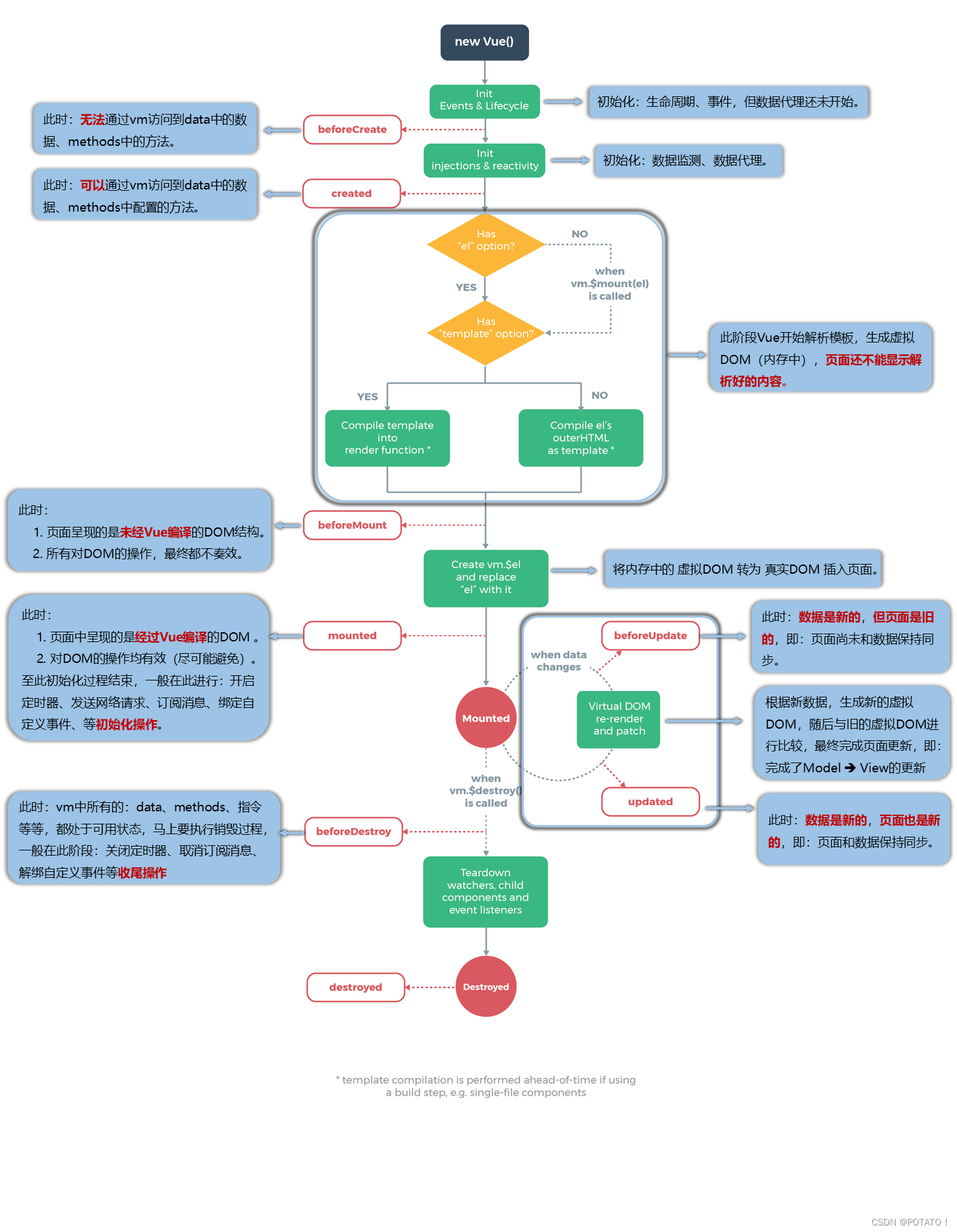
Vue2-收集表单数据、过滤器、内置指令与自定义指令、Vue生命周期
🥔:我徒越万重山 千帆过 万木自逢春 更多Vue知识请点击——Vue.js VUE2-Day4 收集表单数据1、不同标签的value属性2、v-model的三个修饰符 过滤器内置指令与自定义指令1、内置指令2、自定义指令定义语法(1)函数式(2&am…...

正则表达式学习详解
正则表达式 正则表达式(Regular Expression),通常简称为正则或正则表达式,是一种用于描述字符串模式的工具。它是由一系列字符和特殊字符组成的字符串,用于定义搜索模式或进行字符串匹配、替换、提取等操作。 正则表…...
)
工具箱:在线免费使用的文档工具:(PDF转换,图片压缩等)
这些都是博主亲自使用过的,可以使用。 PDF转换器: http://www.pdfdo.com/ 图片压缩: 免费在线图片/视频压缩工具 | 图片压缩 | 免费 JPG PNG GIF 图像压缩 (yalijuda.com) 文档OCR转EXCEL: 文字识别 OCR_ 图片文字识别_图片文字智能识别…...
Qt6之QStackedWidget——Qt仿ToDesk(2)
一、 QStackedWidget概述 QStackedWidget也叫堆栈窗体类,它继承于QFrame,主要与QListWidget等结合使用,实现“一个界面多个页面切换”。 二、QStackedWidget示例 如下图,当点击左边 QListWidget里的菜单时,右边跟随切…...
Harbor企业镜像仓库部署(本地)
简述: Docker 官方镜像仓库是用于管理公共镜像的地方,大家可以在上面找到想要的镜像,也可以把自己的镜像推送上去。但是有时候服务器无法访问互联网,或者不希望将自己的镜像放到互联网上,那么就需要用到 Docker Regis…...

【Linux】如何打包成动静态库,第三方动静态库如何使用?
文章目录 1. 打包成静态库2. 打包成动态库(共享库)3. 使用第三方静态库4. 使用第三方动态库 5. 动态库的加载6. 注意事项 库的名称:去掉前面的 lib 去掉后面的 .a(版本号) .so(版本号) 剩下的,才是库正真的名称。 查看文件依赖库…...

SAP MM学习笔记20- SAP中的英文2 - SD中英文,日语,中文
SD模块中的英文,日语,中文 对照。 販売管理 日本語英語中国語受注伝票sales order销售订单出荷伝票delivery order交货订单ピッキングリストpicking list领货清单シップメント伝票shipment document发运单据出庫確認post goods issue发货确认請求伝票b…...

计算机网络中的一些基本概念
IP地址: 址用于定位主机的网络地址。是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节).**端口号:**在网络通信中,IP地址用于标识主机网络地址,端口号可以标识主机中发送数据、接收数据的进程。简单…...

pytest 用例运行方式
一、命令行方式运行 执行某个目录下所有的用例,符合规范的所有用例 进入到对应的目录,直接执行pytest; 例如需要执行testcases 下的所有用例; 可以进入testcases 目录; 然后执行pytest 进入对应目录的上级目录,执行pytest 目录名称/ ; ; 例如需要执行testcases 下…...

简单入门seleniumUI自动化测试
目录 一、selenium的介绍 二、selenium的原理 三、selenium的八种元素定位的方法 1、ID定位: 2 、name定位: 3、class定位: 4、tag定位: 5、link_text定位: 6、partial_link_text定位: 7、css定位…...

Excel(1):表头或列头冻结
1.需求 对于较大的excel,通常需要固定一部分内容,另一份内容为可翻动。 2.解决方式 在视图中选择冻结窗格,需要注意的是,选择冻结窗格时,窗格的左上方的表格区域是固定不动的,只可以向下或者向右活动。...
通达OA SQL注入漏洞【CVE-2023-4166】
通达OA SQL注入漏洞【CVE-2023-4166】 一、产品简介二、漏洞概述三、影响范围四、复现环境POC小龙POC检测工具: 五、修复建议 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损…...
全网最细,Python接口自动化测试-Session会话保持(实战详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 在接口测试的过程…...

Java项目初始化ES、MYSQL表结构及表数据
一、初始化MYSQL数据 public boolean initMysql() throws Exception {log.info("initMysql.start");//获取所连接的数据库名称String database systemMapper.getDatabase();if (StringUtils.isBlank(database)) {throw new BusinessException("连接数据库失败,…...

2023-08-13力扣每日一题
链接: 88. 合并两个有序数组 题意: 如题 解: 从后往前(从大到小)插入排序,这样就不会影响原先的有序性 实际代码: #include<bits/stdc.h> using namespace std; void merge(vector…...
下一代深度学习的思考与若干问题
下一代深度学习的思考和若干问题...

【Linux】IP协议——网络层
目录 IP协议 基本概念 IP协议格式 分片与组装 网段划分 特殊的IP地址 IP地址的数量限制 私网IP地址和公网IP地址 路由 路由表生成算法 IP协议 IP协议全称为“网际互连协议(Internet Protocol)”,IP协议是TCP/IP体系中的网络层协议…...
【CSS学习笔记】
学习内容 1.css是什么 2.CSS怎么用(快速入门) 3.CSS选择器(重点 难点) 4.美化页面(文字、阴影、超链接、列表、渐变…) 5.盒子模型 6.浮动 7.定位 8.网页动画(特效) 1.什么是CSS C…...

新手必看:无人机电调协议全解析——从PWM到Dshot的进阶指南
1. 无人机电调协议入门:从PWM开始说起 第一次接触无人机时,听到"电调"这个词可能会觉得有点懵。简单来说,电调就是电子调速器(Electronic Speed Controller),它负责把飞控的指令翻译成电机能听懂…...

如何用Audiveris将纸质乐谱转换为数字音乐?5步搞定专业级音乐识别
如何用Audiveris将纸质乐谱转换为数字音乐?5步搞定专业级音乐识别 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对一叠泛黄的纸质乐谱感到束手无策?…...

X-AnyLabeling3.2实战:从零部署到自定义模型自动标注
1. X-AnyLabeling3.2安装与环境配置 第一次接触X-AnyLabeling这个开源标注工具时,我就被它的自动标注功能吸引了。相比传统的手动标注,它能节省80%以上的时间。不过安装过程确实有些坑要避开,这里分享我的实战经验。 首先需要准备Anaconda环境…...

大数据处理效率翻倍:GPU算力租用vs自建服务器,性价比实测
引言:当大数据遇上算力瓶颈 凌晨三点,运维工作群突发消息提示:“ETL任务出现异常崩溃,引发内存溢出。”此类问题本月已发生第四次。团队于2019年采购的GPU服务器,在2025年海量数据的冲击下已显乏力——原本2小时可完成…...

【技术综述】世界模型演进图谱:从Dyna到Sora,理解与预测的双重变奏
1. 世界模型的起源与核心使命 1989年,强化学习先驱Richard Sutton在论文中首次提出Dyna架构时,可能没想到这个概念会成为人工智能理解世界的基石。当时他正在思考一个简单却深刻的问题:智能体如何像人类一样,通过想象来规划行动&…...

如何高效使用智能清理工具:Windows Cleaner完整操作指南
如何高效使用智能清理工具:Windows Cleaner完整操作指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为电脑C盘爆红而焦虑吗?Windo…...

DeepSeek-R1-Distill-Llama-8B实操指南:Ollama模型权重路径修改与自定义加载
DeepSeek-R1-Distill-Llama-8B实操指南:Ollama模型权重路径修改与自定义加载 1. 认识DeepSeek-R1-Distill-Llama-8B推理模型 DeepSeek-R1系列是专门针对推理任务优化的新一代模型,其中DeepSeek-R1-Distill-Llama-8B是基于Llama架构的蒸馏版本。这个8B参…...

5分钟搞定!Ollama部署DeepSeek-R1推理模型,小白也能用的AI解题工具
5分钟搞定!Ollama部署DeepSeek-R1推理模型,小白也能用的AI解题工具 1. 引言:为什么选择DeepSeek-R1-Distill-Qwen-7B 你是否遇到过复杂的数学题解不出来?或者需要快速生成专业报告却无从下手?DeepSeek-R1-Distill-Qw…...
)
海康工业相机C语言SDK实战:从零配置一个完整的视觉采集程序(附完整代码)
海康工业相机C语言SDK实战:从零构建视觉采集系统的完整指南 工业视觉系统在现代制造业中扮演着越来越重要的角色,而相机作为系统的"眼睛",其稳定高效的采集能力直接影响整个系统的性能。本文将带您从零开始,使用海康工业…...

JavaSE 基础语法 - 初始 Java
一、Java是什么? Java 是一门面向对象的、跨平台的高级编程语言,由 Sun Microsystems 公司(后被 Oracle 收购)于 1995 年推出,设计初衷是 “Write Once, Run Anywhere(一次编写,到处运行&#x…...