计算机竞赛 GRU的 电影评论情感分析 - python 深度学习 情感分类
1 前言
🔥学长分享优质竞赛项目,今天要分享的是
🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
这是一个较为新颖的竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目介绍
其实,很明显这个项目和微博谣言检测是一样的,也是个二分类的问题,因此,我们可以用到学长之前提到的各种方法,即:
朴素贝叶斯或者逻辑回归以及支持向量机都可以解决这个问题。
另外在深度学习中,我们可以用CNN-Text或者RNN以及LSTM等模型最好。
当然在构建网络中也相对简单,相对而言,LSTM就比较复杂了,为了让不同层次的同学们可以接受,学长就用了相对简单的GRU模型。
如果大家想了解LSTM。以后,学长会给大家详细介绍。
2 情感分类介绍
其实情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。一般而言:情绪类别:正面/负面。当然,这就是为什么本人在前面提到情感分析实际上也是二分类问题的原因。
3 数据集
学长本次使用的是非常典型的IMDB数据集。
该数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
查看其数据集的文件夹:这是train和test文件夹。
接下来就是以train文件夹介绍里面的内容
然后就是以neg文件夹介绍里面的内容,里面会有若干的text文件:
4 实现
4.1 数据预处理
#导入必要的包
import zipfile
import os
import io
import random
import json
import matplotlib.pyplot as plt
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embedding
from paddle.fluid.dygraph.base import to_variable
from paddle.fluid.dygraph import GRUUnit
import paddle.dataset.imdb as imdb
#加载字典
def load_vocab():
vocab = imdb.word_dict()
return vocab
#定义数据生成器
class SentaProcessor(object):
def __init__(self):
self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")
步骤
-
首先导入必要的第三方库
-
接下来就是数据预处理,需要注意的是:数据是以数据标签的方式表示一个句子,因此,每个句子都是以一串整数来表示的,每个数字都是对应一个单词。当然,数据集就会有一个数据集字典,这个字典是训练数据中出现单词对应的数字标签。
4.2 构建网络
这次的GRU模型分为以下的几个步骤
- 定义网络
- 定义损失函数
- 定义优化算法
具体实现如下
#定义动态GRUclass DynamicGRU(fluid.dygraph.Layer):def __init__(self,size,param_attr=None,bias_attr=None,is_reverse=False,gate_activation='sigmoid',candidate_activation='relu',h_0=None,origin_mode=False,):super(DynamicGRU, self).__init__()self.gru_unit = GRUUnit(size * 3,param_attr=param_attr,bias_attr=bias_attr,activation=candidate_activation,gate_activation=gate_activation,origin_mode=origin_mode)self.size = sizeself.h_0 = h_0self.is_reverse = is_reversedef forward(self, inputs):hidden = self.h_0res = []for i in range(inputs.shape[1]):if self.is_reverse:i = inputs.shape[1] - 1 - iinput_ = inputs[ :, i:i+1, :]input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)hidden, reset, gate = self.gru_unit(input_, hidden)hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)res.append(hidden_)if self.is_reverse:res = res[::-1]res = fluid.layers.concat(res, axis=1)return res
class GRU(fluid.dygraph.Layer):
def init(self):
super(GRU, self).init()
self.dict_dim = train_parameters[“vocab_size”]
self.emb_dim = 128
self.hid_dim = 128
self.fc_hid_dim = 96
self.class_dim = 2
self.batch_size = train_parameters[“batch_size”]
self.seq_len = train_parameters[“padding_size”]
self.embedding = Embedding(
size=[self.dict_dim + 1, self.emb_dim],
dtype=‘float32’,
param_attr=fluid.ParamAttr(learning_rate=30),
is_sparse=False)
h_0 = np.zeros((self.batch_size, self.hid_dim), dtype=“float32”)
h_0 = to_variable(h_0)
self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 训练模型
def train():with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因为要进行很大规模的训练,因此我们用的是GPU,如果没有安装GPU的可以使用下面一句,把这句代码注释掉即可# with fluid.dygraph.guard(place = fluid.CPUPlace()):
processor = SentaProcessor()
train_data_generator = processor.data_generator(batch_size=train_parameters[“batch_size”], phase=‘train’)
model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

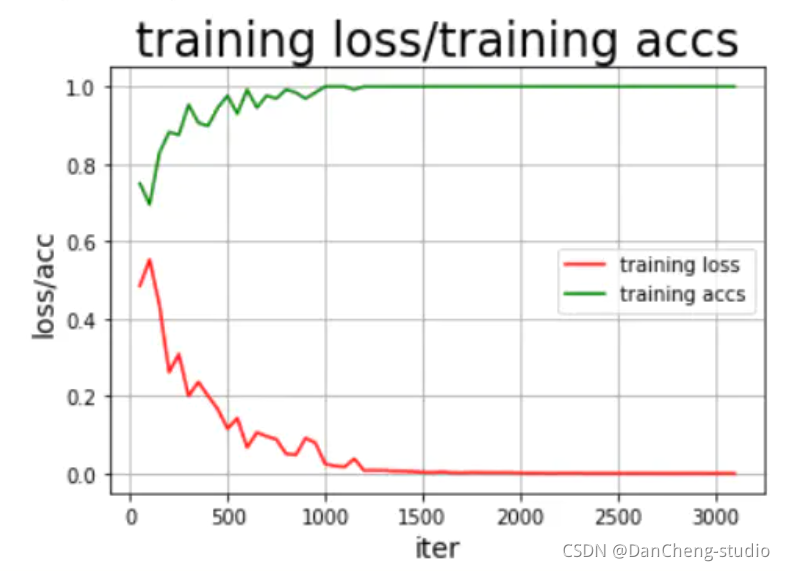
4.4 模型评估

结果还可以,这里说明的是,刚开始的模型训练评估不可能这么好,很明显是过拟合的问题,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将GRU模型换为更为合适的RNN中的LSTM以及bi-
LSTM模型会好很多。
4.5 模型预测
train_parameters["batch_size"] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('预测结果为:正面概率为:%0.5f,负面概率为:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

训练的结果还是挺满意的,到此为止,我们的本次项目实验到此结束。
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 GRU的 电影评论情感分析 - python 深度学习 情感分类
1 前言 🔥学长分享优质竞赛项目,今天要分享的是 🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这…...
论文阅读 - Neutral bots probe political bias on social media
论文链接:Neutral bots probe political bias on social media | EndNote Click 试图遏制滥用行为和错误信息的社交媒体平台被指责存在政治偏见。我们部署中立的社交机器人,它们开始关注 Twitter 上的不同新闻源,并跟踪它们以探究平台机制与用…...
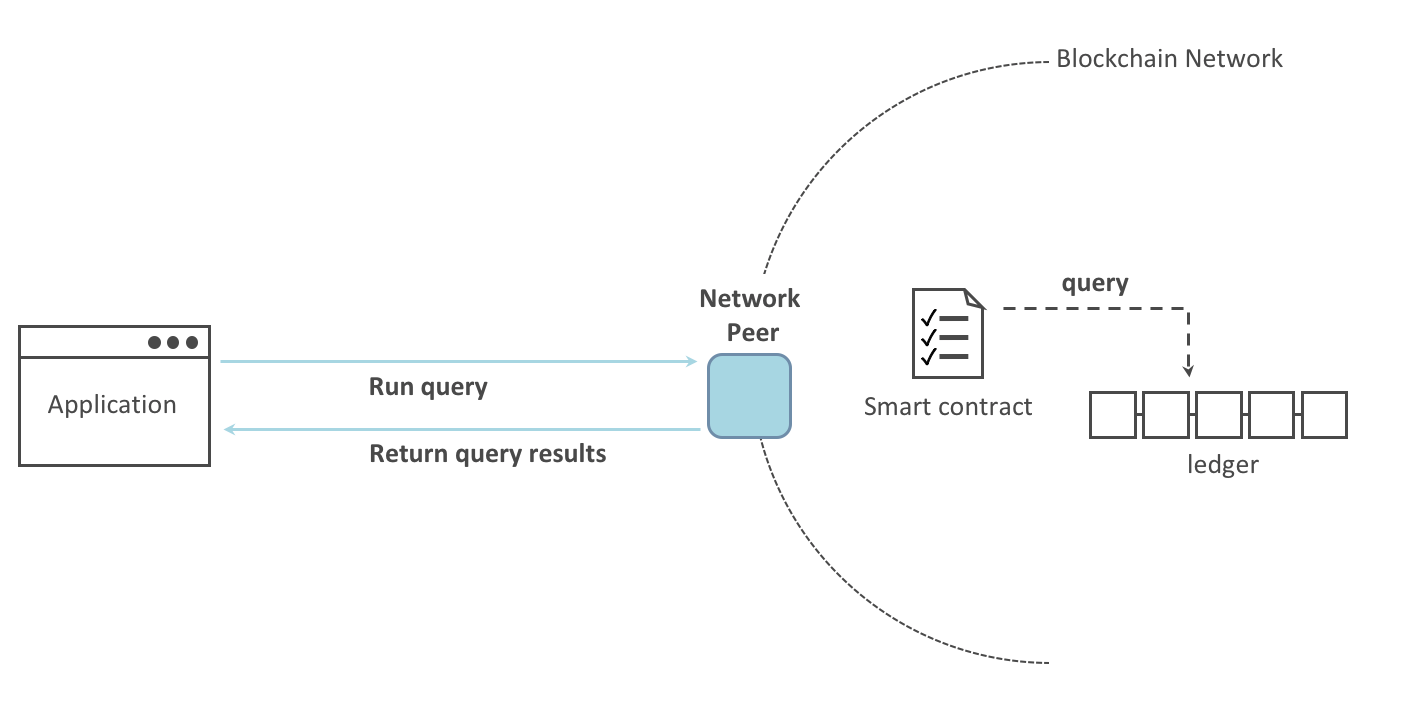
Fabric系列 - 知识点整理
知识点 源码编译 主机编译 容器编译 手动部署(docker-compose) 单peer 多peer 中途加peer 多主机多peer 链码 语法, 接口 (go版) 命令行调用 ca server 在DApp中使用SDK调用 (js版) 部署的几个阶段 部署1排序和1节点, 1组织1通道 光部署能Dapp 带ca server (每个组织一个)…...
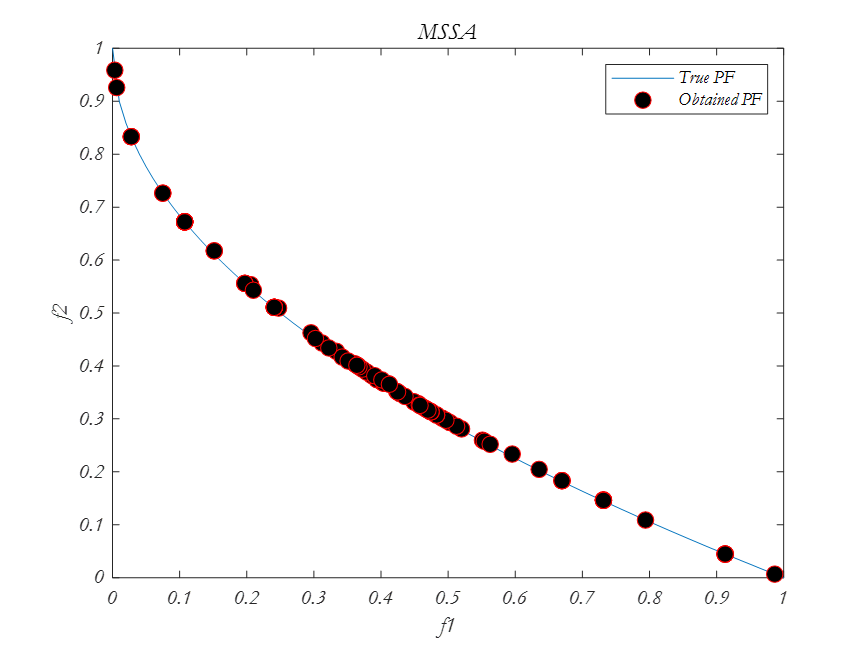
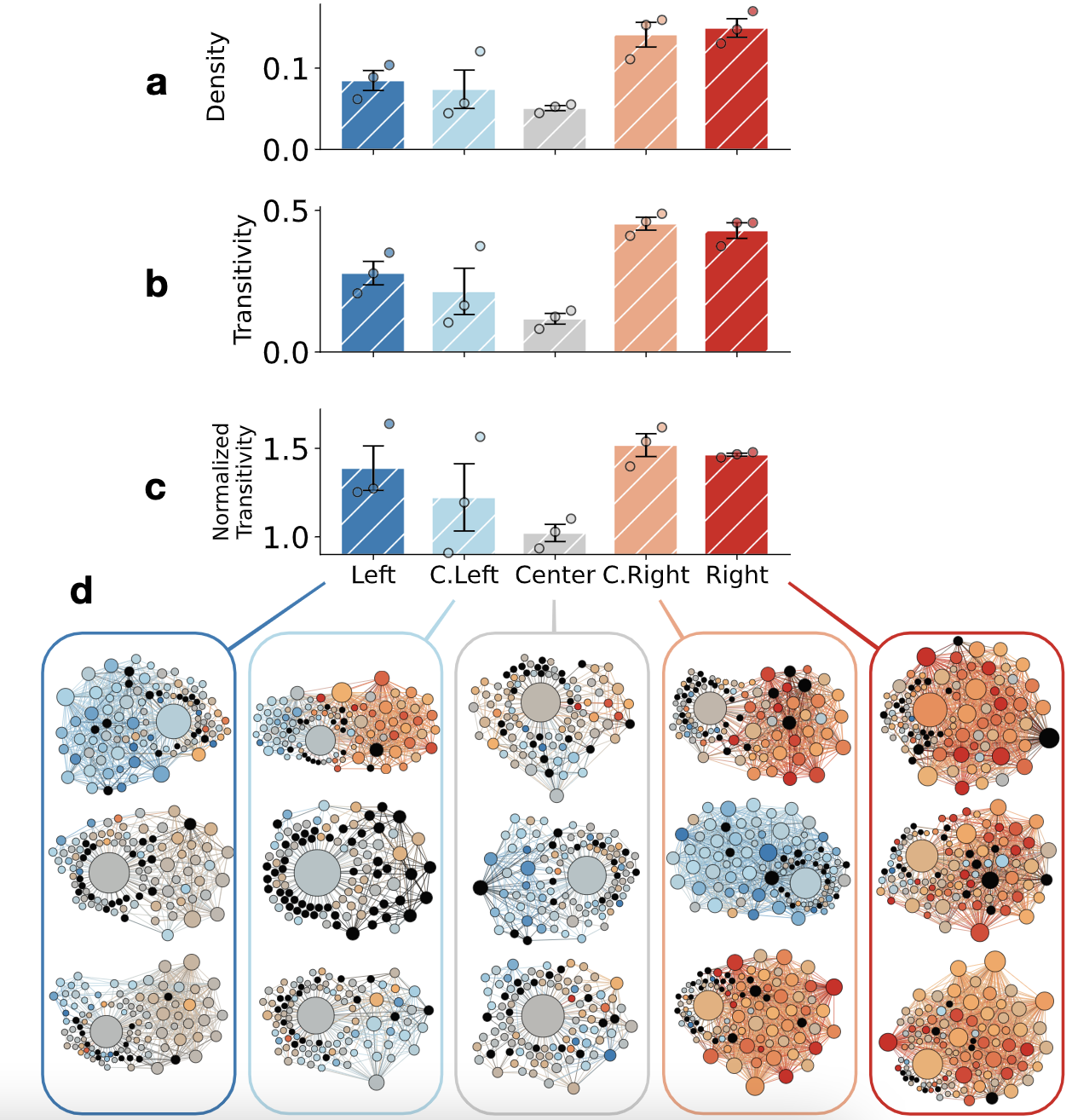
多目标优化算法之樽海鞘算法(MSSA)
樽海鞘算法的主要灵感是樽海鞘在海洋中航行和觅食时的群聚行为。相关文献表示,多目标优化之樽海鞘算法的结果表明,该算法可以逼近帕雷托最优解,收敛性和覆盖率高。 通过给SSA算法配备一个食物来源库来解决第一个问题。该存储库维护了到目前为…...
阿里云轻量应用服务器使用教程_创建配置_远程连接_网站上线
阿里云轻量应用服务器怎么使用?阿里云百科分享轻量应用服务器从选择创建、配置建站环境、轻量服务器应用服务器远程连接、开端口到网站上线全流程: 目录 阿里云轻量应用服务器使用教程 步骤一:购买一台轻量应用服务器 步骤二:…...

自监督学习的概念
Self-Supervised Learning (SSL)的主要思想是解决先验任务来学习特征提取器,在不使用标签的情况下生成有用的表示。 这里先验任务是指, 先使用原始数据和特征提取器来提取出 数据的有效表示. 对比方法(即对比学习, Contrastiv…...
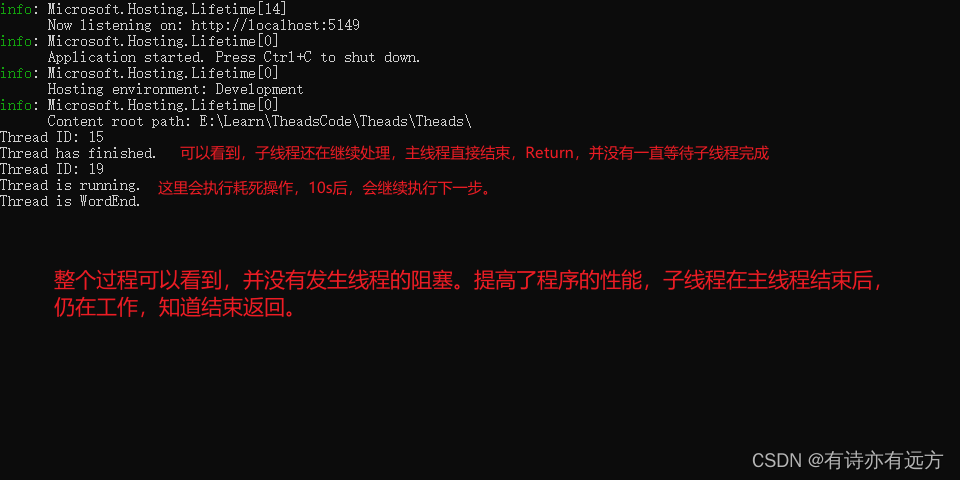
C#多线程开发详解
C#多线程开发详解 持续更新中。。。。。一、为什么要使用多线程开发1.提高性能2.响应性3.资源利用4.任务分解5.并行计算6.实时处理 二、多线程开发缺点1.竞态条件2.死锁和饥饿3.调试复杂性4.上下文切换开销5.线程安全性 三、多线程开发涉及的相关概念常用概念(1)lock(2)查看当前…...

Linux 基础篇(六)sudo和添加信任用户
一、sudo 1.是什么? 给被信任的普通用户授权,让被信任的普通用户能执行root用户才能执行的命令的一个命令。 2.为什么? 很多时候我们要在被信任的普通用户下执行一些root用户才能执行的命令,如 yum… 所以需要有一个命令能给普通用…...
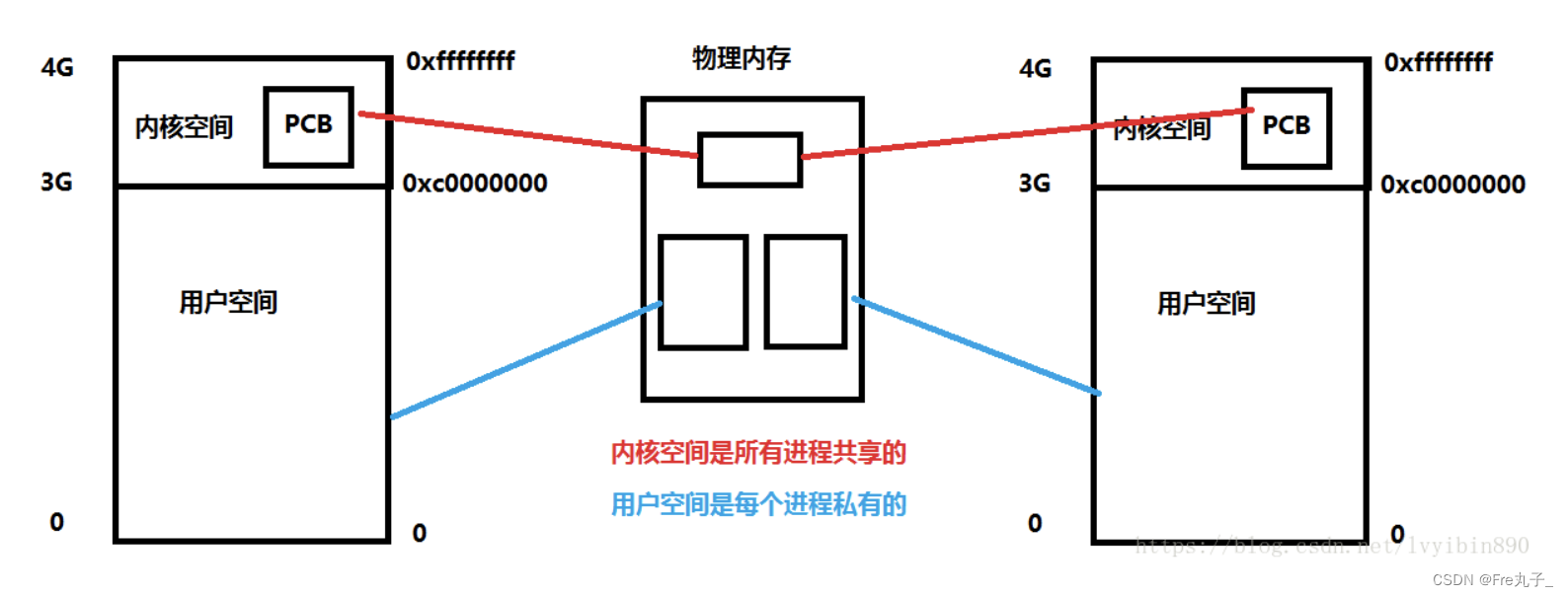
【Linux】程序地址空间
程序地址空间 首先引入地址空间的作用什么是地址空间为什么要有地址空间 首先引入地址空间的作用 1 #include <stdio.h>2 #include <unistd.h>3 #include <stdlib.h>4 int g_val 100;6 int main()7 {8 pid_t id fork();9 if(id 0)10 {11 int cn…...

springboot 设置自定义启动banner背景图 教程
springboot banner Spring Boot中的banner是在应用程序启动时显示的一个ASCII艺术字符或文本。它被用来给用户展示一些关于应用程序的信息,例如名称、版本号或者公司标志等。 使用Spring Boot的默认设置,如果项目中有一个名为“banner.txt”的文件放置…...

CSS的引入方式有哪些?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 内联样式(Inline Styles)⭐ 内部样式表(Internal Stylesheet)⭐ 外部样式表(External Stylesheet)⭐ 导入样式表(Import Stylesheet)⭐ 写在最…...
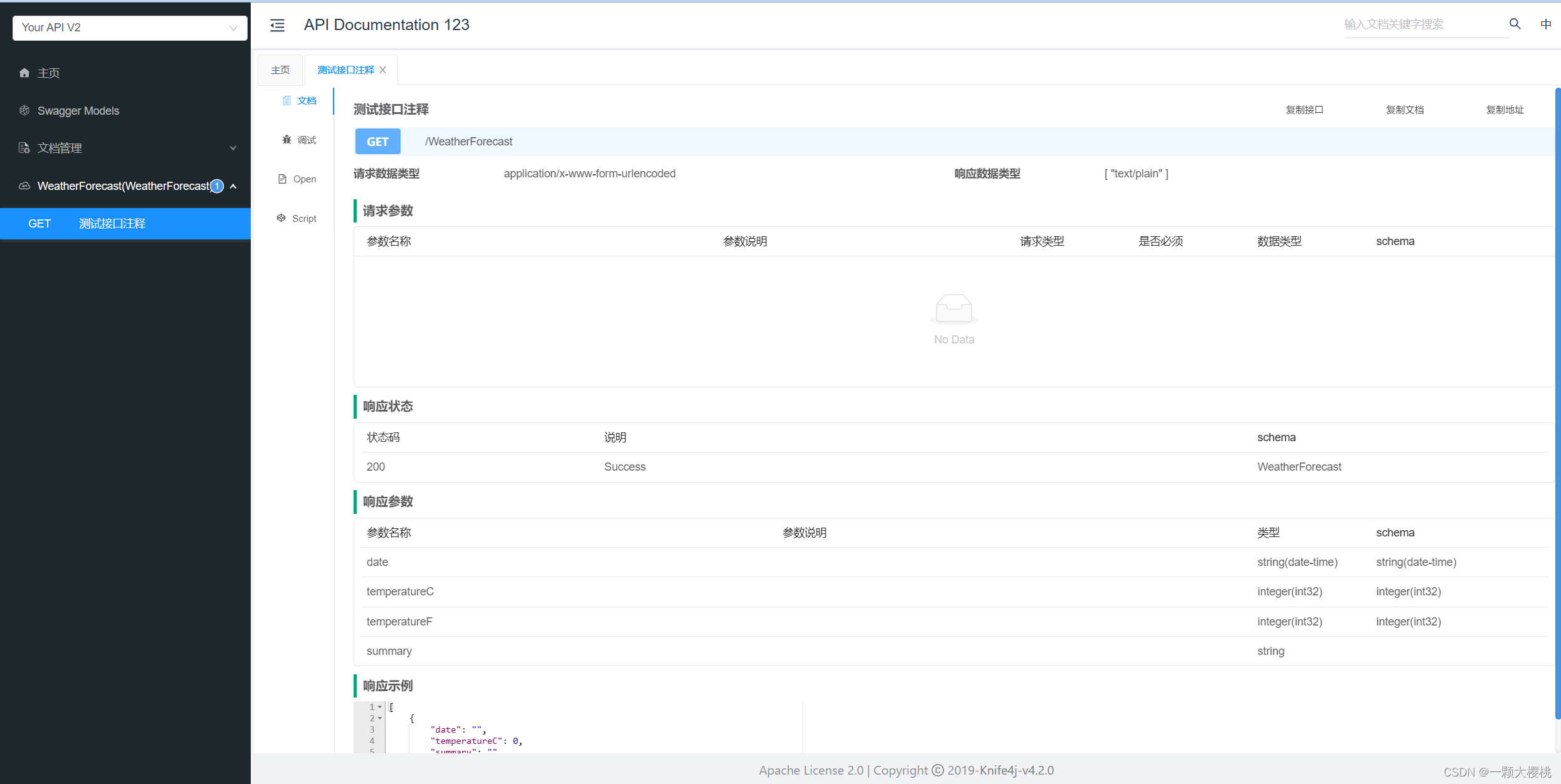
.net core的Knife4jUI,让swagger更精致
要在 .NET Core 中使用 IGeekFan.AspNetCore.Knife4jUI,您可以按照以下步骤进行配置: 首先,安装 IGeekFan.AspNetCore.Knife4jUI NuGet 包。可以通过 Visual Studio 的 NuGet 包管理器或者 .NET CLI 进行安装。 在 Startup.cs 文件的 Config…...

Android 开发中需要了解的 Gradle 知识
作者:wkxjc Gradle 是一个基于 Groovy 的构建工具,用于构建 Android 应用程序。在 Android 开发中,了解 Gradle 是非常重要的,因为它是 Android Studio 默认的构建工具,可以帮助我们管理依赖项、构建应用程序、运行测试…...

Linux之【进程间通信(IPC)】-总结篇
Linux之【进程间通信(IPC)】-总结篇 管道System V共享内存System V消息队列System V信号量IPC资源的管理方式 往期文章 1.进程间通信之管道 2.进程间通信之System V共享内存 管道 进程之间具有独立性,拥有自己的虚拟地址空间,因…...
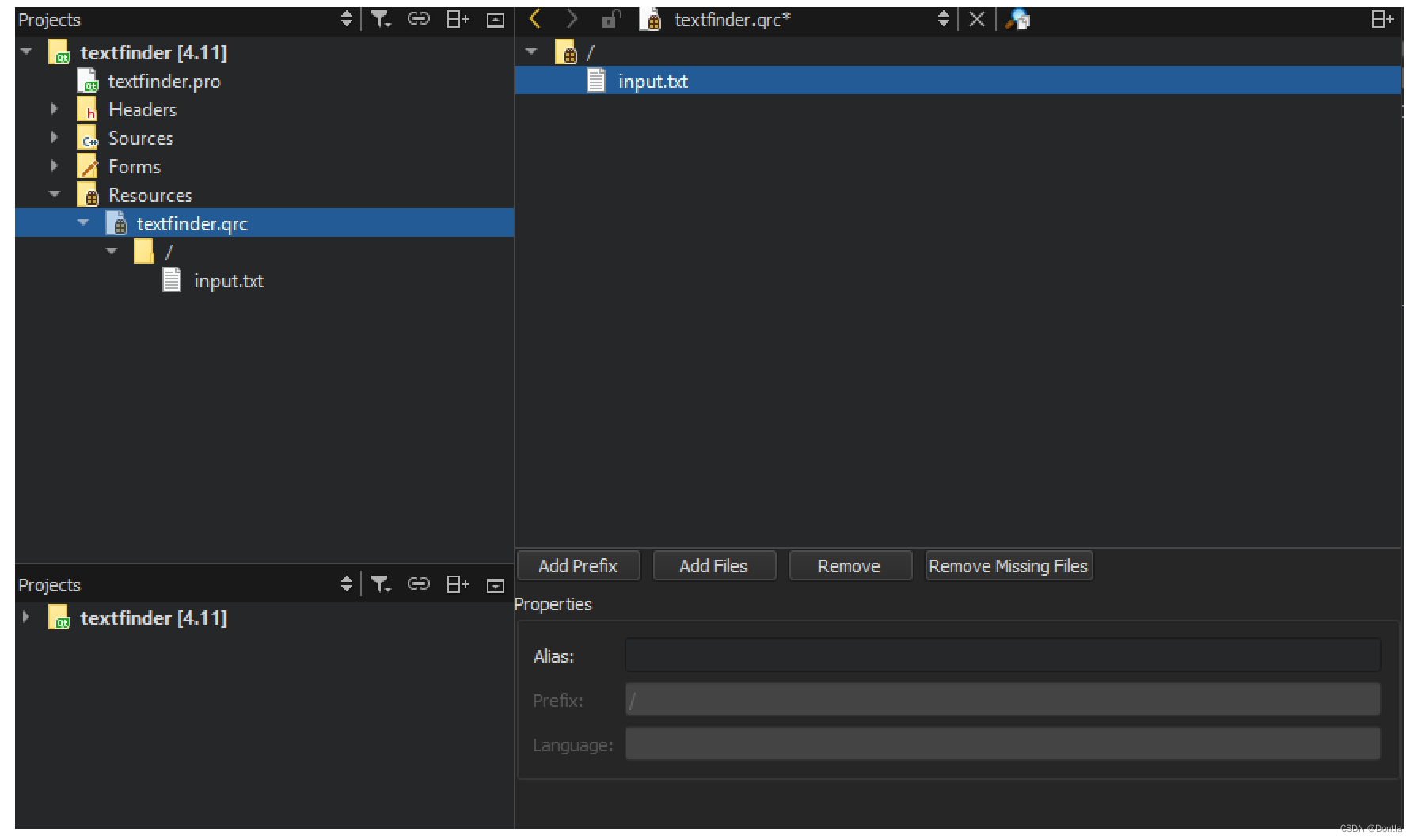
C++QT教程3——手册4.11.1自带教程(笔记)——创建一个基于Qt Widget的应用程序
文章目录 创建一个基于Qt Widget的应用程序创建Text Finder项目素材文件 填补缺失的部分设计用户界面完成头文件完成源文件创建资源文件 编译和运行程序 参考文章 创建一个基于Qt Widget的应用程序 本教程介绍如何使用Qt Creator创建一个小型Qt应用程序,名为Text F…...
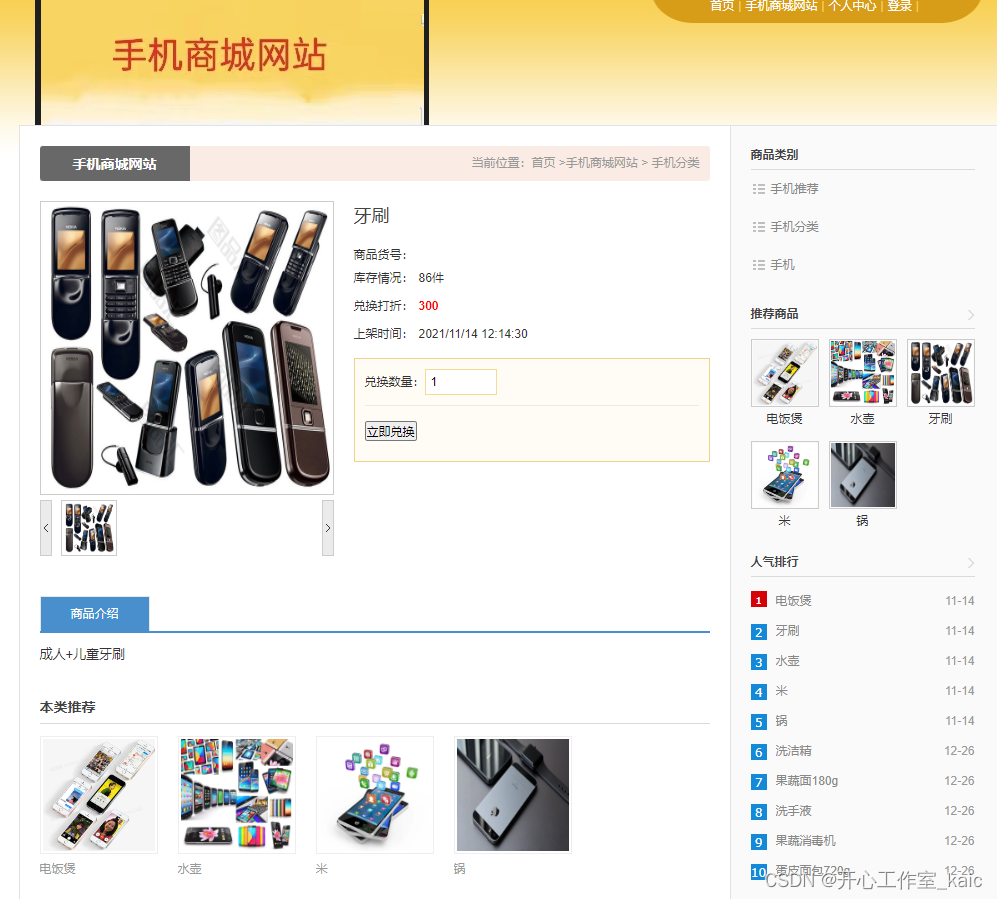
手机商城网站的分析与设计(论文+源码)_kaic
目录 摘 要 1 1 绪论 2 1.1选题背景意义 2 1.2国内外研究现状 2 1.2.1国内研究现状 2 1.2.2国外研究现状 3 1.3研究内容 3 2 网上手机商城网站相关技术 4 2.1.NET框架 4 2.2Access数据库 4 2.3 JavaScript技术 4 3网上手机商城网站分析与设…...
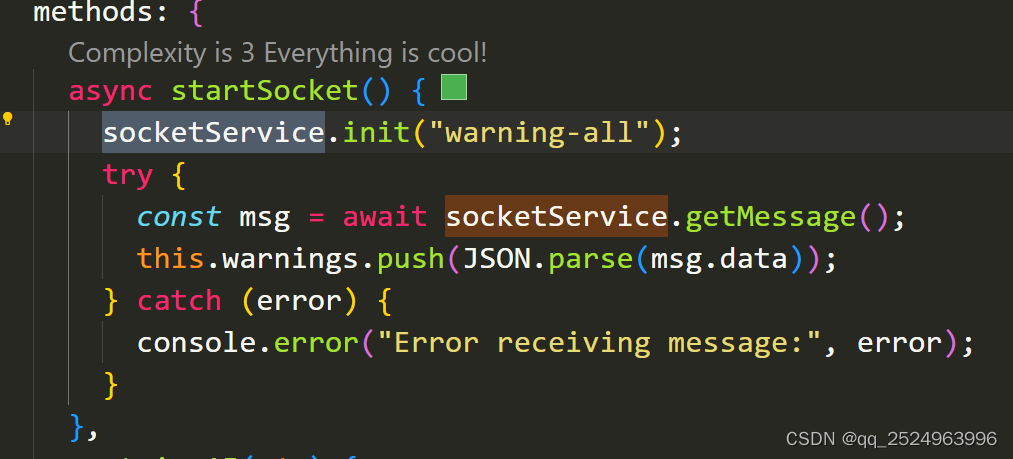
vue2 封装 webSocket 开箱即用
第一步: 下载 webSocket npm install vue-native-websocket --save 第二步: 需要在 main.js 中 引入 import websocket from vue-native-websocket; Vue.use(websocket, , {connectManually: true, // 手动连接format: json, // json格式reconnection:…...
使用fopen等标准C库来操作文件
fopen 需要的头文件: #include <stdio.h> 函数原型: FILE *fopen(const char *pathname, const char *mode); 参数: pathname: 文件路径mode: “r” :以只读方式打开文件,该文件必须存在。“w” ÿ…...

Spring-Cloud-Loadblancer详细分析_1
背景 从SpringCloud 2020 版本之后,组件移除了除 Eureka 以外,所有 Netflix 的相关,包括最常用的 Ribbon Hystrix 等,所以 SpringCloud 在 spring-cloud-commons 提供了Loadbalancer 用来替代 Ribbon。本系列就来介绍Loadbalance…...

键盘键码keyCode对照表
字母和数字键的键码值(KeyCode)按键键码按键键码A65J74B66K75C67L76D68M77E69N78F70O79G71P80H72Q81I73R82 字母和数字键的键码值(KeyCode)按键键码按键键码S83149T84250U85351V86452W87553X88654Y89755Z90856048957 数字键盘上的键的键码值(KeyCode)按键键码按键键码0968104…...

参数化飞机几何建模工具:OpenVSP的航空工程设计完整指南
参数化飞机几何建模工具:OpenVSP的航空工程设计完整指南 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP OpenVSP(Open Vehicle Sketch Pad)作为NASA开源的一款…...
)
保姆级教程:用Docker Compose一键部署Mineru 2.5 API与Gradio服务(昇腾310/910B)
保姆级教程:用Docker Compose一键部署Mineru 2.5 API与Gradio服务(昇腾310/910B) 在AI应用开发领域,如何快速部署高性能的推理服务一直是开发者关注的焦点。Mineru 2.5作为基于华为昇腾NPU优化的开源项目,通过VLLM引擎…...

2025最权威的六大AI学术神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当前,各种AI生成内容检测工具越发普遍,好多创作者面临内容被错误判定…...

终极指南:IntelliJ IDEA Markdown插件开发全解析
终极指南:IntelliJ IDEA Markdown插件开发全解析 【免费下载链接】idea-markdown Markdown language support for IntelliJ IDEA (abandonned). 项目地址: https://gitcode.com/gh_mirrors/id/idea-markdown 你是否在JetBrains系列IDE中寻找更优质的Markdown…...
)
AIAgent模型蒸馏黄金公式(含KL散度+任务感知注意力蒸馏Loss代码级实现)
第一章:AIAgent模型蒸馏黄金公式的理论基石与工程价值 2026奇点智能技术大会(https://ml-summit.org) AI Agent模型蒸馏并非简单参数压缩,而是面向任务闭环的**认知能力迁移过程**。其核心在于将大型Agent(如具备规划、工具调用、反思能力的…...

OpenClaw人人养虾:openclaw voicecall
发起语音通话。 概要 openclaw voicecall [选项] 描述 openclaw voicecall 命令用于通过 OpenClaw 发起语音通话。Agent 可以通过语音与用户进行实时对话,支持多种语音识别和合成提供商。适用于电话客服、语音助手等场景。 选项 选项缩写说明默认值--provider…...

如何用MelonLoader实现Unity游戏模组开发的终极跨平台方案
如何用MelonLoader实现Unity游戏模组开发的终极跨平台方案 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 你是否曾为Unity游戏…...

前端开发技术演进:一个小小开发者的浅显思考
写在前面! 3.3章节、3.4章节、4.2章节、6.2章节、大白话凝练等处有求于AI。 本文系个人浅见,疏漏之处在所难免,恳请各位方家不吝赐教。路漫漫其修远兮,吾将上下而求索。 作为一名在前端开发领域摸爬滚打小有几年的开发者ÿ…...

弦音墨影新手必看:5分钟掌握水墨界面下的视频语义提问技巧
弦音墨影新手必看:5分钟掌握水墨界面下的视频语义提问技巧 1. 水墨智能新体验:像在画中对话的视频理解工具 你是否曾经面对一段视频,想要快速找到某个特定画面却无从下手?或者想要了解视频中的细节内容,却需要反复拖…...

Cortex-A7 MPCore 架构
鉴于学习的硬件使用的是Cortex-A7架构,本章学习该架构的相关知识。了解了 Cortex-A7 架构以后有利于我们后面的学习,因为后面有很多例程涉及到 Cortex-A7 架构方面的知识,比如处理器模型、 Cortex-A7 寄存器组等等。Cortex-A7 MPCore 简介Cor…...