springboot第35集:微服务与flutter安卓App开发
| Google Play | play.google.com/apps/publis…[1] |
|---|---|
| 应用宝 | open.qq.com/[2] |
| 百度手机助手 | app.baidu.com/[3] |
| 360 手机助手 | dev.360.cn/[4] |
| vivo 应用商店 | dev.vivo.com.cn/[5] |
| OPPO 软件商店(一加) | open.oppomobile.com/[6] |
| 小米应用商店 | dev.mi.com/[7] |
| 华为应用市场 | developer.huawei.com/consumer/cn…[8] |
| 阿里应用分发平台(豌豆荚) | open.uc.cn/[9] |
| 搜狗手机助手 | zhushou.sogou.com/open/[10] |
| 锤子应用商店 | dev.smartisan.com/[11] |
| 魅族应用商店 | open.flyme.cn/[12] |
| 金立软件商店 | open.appgionee.com/[13] |
| 安智市场 | dev.anzhi.com/[14] |
| 酷安市场 | developer.coolapk.com[15] |
| 联想乐商店 | open.lenovo.com/[16] |
| 三星应用开发者平台 | support-cn.samsung.com/App/Develop…[17] |

软著是必要的,提前准备好,软著申请大概需要1-2周时间才能下来。提前把APP名字想好,然后同步准备软著。这个越提前越好,因为软著的价格和时间有关,时间要求越高,越贵。特殊行业需要提供其他证明或授权,比如新闻的需要新新闻相关的,金融的需要金融相关的。最近很多app都要求ICP证、app安全评估报告、银行合作等等。
icon/应用介绍/截图,截图要提前准备,按照尺寸要求。
使用
Wrap布局: 将Wrap组件包裹住选项,这样可以在水平空间不足时自动换行,以避免溢出屏幕。Wrap可以根据内容的大小自动调整布局。提取通用方法: 将类似的代码块提取为通用方法,以减少重复代码。这将帮助你简化代码并使其更易于维护。
缩小间距: 调整
SizedBox组件的宽度,以减少选项之间的间距。你可以根据需要微调间距的大小。
springboot微服务如何在服务器上查看日志
查看控制台输出:在服务器上启动Spring Boot微服务时,控制台会输出日志信息。您可以通过SSH登录到服务器,并在控制台中查看应用程序的输出日志。
查看日志文件:Spring Boot会将日志输出到指定的日志文件中,默认情况下,Spring Boot会将日志输出到应用程序的工作目录下的
logs文件夹中。您可以通过SSH登录到服务器,然后使用文本编辑器或者命令行工具查看日志文件。使用日志管理工具:在生产环境中,通常会使用专业的日志管理工具来集中管理和查看日志。常见的日志管理工具包括ELK Stack(Elasticsearch、Logstash、Kibana)、Splunk等。这些工具可以帮助您在服务器上集中收集、搜索和分析日志信息,便于快速定位问题。
使用日志级别控制:在Spring Boot中,可以通过配置日志级别来控制日志的输出。常见的日志级别有DEBUG、INFO、WARN、ERROR等。您可以根据需求将日志级别设置为适当的级别,以便只输出关键信息。
在Linux或Unix系统中,您可以使用cat命令或tail命令来查看日志文件的内容。以下是常用的命令示例:
使用
cat命令查看完整的日志文件内容:cat /path/to/your/logfile.log使用
tail命令查看日志文件的末尾部分(默认显示最后10行):tail /path/to/your/logfile.log您也可以使用
-n参数指定显示的行数,例如显示最后20行:tail -n 20 /path/to/your/logfile.log如果日志文件比较大,可以使用
less命令进行分页查看:less /path/to/your/logfile.log使用
space键向下翻页,使用b键向上翻页,使用q键退出查看。
如果您希望在实时监视日志文件的更新,可以使用tail命令的-f参数:
tail -f /path/to/your/logfile.log这将实时显示日志文件的末尾部分,并持续监视文件的更新。
server:此部分用于配置嵌入式服务器属性。port:此属性指定服务器将监听的端口号。在此情况下,服务器将监听00000端口。
spring:application:name: servicespring:此部分包含Spring Boot相关的配置。application:此子部分用于配置Spring应用程序属性。name:此属性设置Spring应用程序的名称。在此情况下,应用程序名称设置为"sys-service"。
cloud:nacos:discovery:server-addr:username:password:cloud:此部分用于配置Spring Cloud组件。nacos:此子部分用于配置Nacos服务发现。discovery:此子部分配置Nacos发现的属性。server-addr:此属性用于指定Nacos服务器的地址。应填写Nacos服务器的地址,例如:server-addr: http://localhost:8848。username:如果需要与Nacos服务器进行身份验证,则可以使用此属性进行配置。如果不需要身份验证,则可以将此属性留空。password:如果需要与Nacos服务器进行身份验证,则可以使用此属性配置密码。如果不需要身份验证,则可以将此属性留空。
private Set<Integer> topONumSet; //所有权限组织的顶级组织序号
// 注入 Spring 的环境变量,用于获取配置信息 @Autowired private Environment env;
// 通过 @Value 注解获取配置文件中的属性值
// 系统数据库地址
@Value("${sys.datasource.url}")
// 系统数据库密码
// 系统数据库驱动类名
// 创建名为 "sysDataSource" 的 Bean,作为系统数据源
// 打印系统数据库地址到日志
// 设置 DruidDataSource 的属性
dataSource
// 设置数据库连接地址
// 设置数据库用户名
// 设置数据库密码
// 设置数据库驱动类名
dataSource.setInitialSize(2); // 设置初始化时的连接数
dataSource.setMaxActive(20); // 设置最大活跃连接数
dataSource.setMinIdle(0); // 设置最小空闲连接数
dataSource.setMaxWait(60000); // 设置获取连接的最大等待时间
dataSource.setValidationQuery("SELECT 1"); // 设置用于校验连接是否有效的 SQL 查询语句
setTestOnBorrow(false); // 设置是否在获取连接时校验连接的有效性
setTestWhileIdle(true); // 设置是否在空闲时校验连接的有效
setPoolPreparedStatements(false); // 设置是否缓存预编译语句
setDefaultAutoCommit(false); // 设定不自动提交事务// 创建名为 "sysSqlSessionFactory" 的 Bean,用于管理系统数据库的 SqlSessionFactory
// 设置系统数据源
// 设置系统数据库的 MyBatis Mapper 文件的位置,指定 mapper 文件所在的目录
// 设置 MyBatis 的插件,这里使用了 ComConfig 类中的 pageHelperSetting() 方法返回的拦截器
// 返回配置好的 SqlSessionFactory
// 创建日志记录器,用于输出日志信息
// 从配置文件中获取 Redis 的主机名
// 从配置文件中获取 Redis 的端口号
// 从配置文件中获取 Redis 的连接超时时间
// 从配置文件中获取 Redis 的密码
// 从配置文件中获取 Redis 的数据库索引
// 从配置文件中获取 Redis 连接池的最大空闲连接数
// 从配置文件中获取 Redis 连接池的最小空闲连接数
// 创建名为 "sysRedisTemplate" 的 Bean,用于管理 RedisTemplate 实例
// 创建 Jedis 连接工厂 jedisConnectionFactory
// 设置 Redis 主机名
// 设置 Redis 端口号
// 设置 Redis 密码
// 设置存储的数据库索引
// 设置连接超时时间
// 使用连接池
// 创建 Jedis 连接池配置
// 设置连接池的最大空闲连接数
// 设置连接池的最小空闲连接数
// 将连接池配置设置给连接工厂
// 调用 ComConfig 类中的 strRedisTemplate 方法,创建并配置 RedisTemplate 实例,并返回该实例 jedisConnectionFactory// 声明一个静态变量来保存 Spring 的 ApplicationContext 对象
// 实现接口 ApplicationContextAware 的方法,用于获取 Spring 的 ApplicationContext 对象
// 将传入的 ApplicationContext 对象赋值给静态变量 context
// 提供一个静态方法,根据 Bean 名称获取对应的 Spring Bean 实例
// 如果 context 为空,则返回 null
// 提供一个静态方法,用于获取所有已注册的 Bean 名称
// 返回所有已注册的 Bean 名称数组// 定义一个静态方法,用于配置 MyBatis 分页插件 PageHelper
// 创建一个 PageInterceptor 对象作为分页插件的实例
// 创建一个 Properties 对象用于设置分页插件的属性
// 将 offset 参数当成页码
// 使用 RowBounds 分页时进行 count 查询
// 是否合理化分页参数(启用合理化时,如果 pageNum < 1,会自动设置为 1;如果 pageNum > pages,会自动设置为 pages)
properties.setProperty("dialect", "mysql"); //4.0.0以后不要配置数据源
// 当 pageSize=0 时查询返回全部结果(相当于没有执行分页查询)
// 支持通过 Mapper 接口参数来传递分页参数
// 不返回 Page 类型,返回 PageInfo 类型
// 将设置好的属性赋值给分页插件
// 返回配置好的分页插件实例// 定义一个静态方法,用于配置 RedisTemplate
// 创建一个 RedisTemplate 实例
// 设置连接工厂,即连接到 Redis 的配置
// 设置 key 和 hash key 的序列化方式为 StringRedisSerializer
/ 设置 hash value 和 value 的序列化方式为 StringRedisSerializer
// 初始化 RedisTemplate
// 返回配置好的 RedisTemplate 实例// 用于注入配置属性值 spring.application.name
// 实现 EnvironmentAware 接口,用于获取 Spring 的 Environment 对象
// 在 Spring 环境准备就绪后,会调用此方法
// 检查是否已经设置了系统属性 "project.name",如果没有设置,则将 applicationName 的值赋给该系统属性// 静态Logger,用于日志记录
// 用于存储 RestHighLevelClient 实例
// 用于存储 BulkProcessor 实例
// 在初始化阶段执行的方法
// 创建基本的凭证提供者
// 创建 RestClientBuilder
// 创建 RestHighLevelClient 实例
// 创建 BulkProcessor.Listener 实例
// 在执行批处理前调用 beforeBulk
// 在执行批处理后调用(成功) afterBulk
// 在执行批处理后调用(失败) afterBulk
// 创建 BulkProcessor.Builder 实例
// 设置 BulkProcessor 的配置属性
// 到达10000条时刷新
// 内存到达8M时刷新
// 设置的刷新间隔10s
// 设置允许执行的并发请求数
// 设置重试策略
// 构建 BulkProcessor 实例
// 创建名为 "esRestHighLevelClient" 的 RestHighLevelClient Bean
// 在销毁阶段执行的方法
// 创建名为 "esRestBulkProcessor" 的 BulkProcessor Bean
// 获取 HttpHost 数组// 启用Swagger2注解
// 启用Knife4j注解,Knife4j是Swagger的增强工具包
// 创建一个名为 createRestApi 的 Docket Bean
// 创建一个 Docket 实例,使用 Swagger 2 规范
// 设置API信息
// 扫描带有 @ApiOperation 注解的方法
// 扫描指定包下的类
// 匹配所有路径
// 设置全局参数
// 创建一个 ApiInfo 实例,用于设置 API 文档信息
// API 标题
// 服务条款 URL
// API 版本// 将自定义的拦截器注入为一个 Bean
// 配置内容协商,设置默认的响应内容类型为 JSON 格式
// 配置跨域资源共享(CORS)规则
.allowedOrigins("*") // 允许的源
// 允许的HTTP方法
"POST", "GET", "PUT", "OPTIONS", "DELETE"
// 预检请求的缓存时间
// 允许跨域请求携带认证信息
// 添加拦截器,并配置拦截规则和排除规则
.addPathPatterns("/**") // 拦截所有路径// 添加静态资源处理器,用于处理 Swagger UI 页面
// 配置默认的 Servlet 处理器// 自动注入 SysMenuService
// API 操作文档的注解,描述接口的用途和输入参数
// POST 请求映射到 /pageQuery,接收 JSON 请求体
// 将 JSON 请求体解析为 xxx 对象
// 创建 xxxBO 对象,用于业务操作
// 调用 xxxService 的分页查询方法
// 返回失败响应,并记录错误日志// 定义API标签
// 使用Lombok注解,自动生成Logger
// 表明这是一个REST控制器
// 静态Logger,用于记录日志
// 自动注入 SysOrgService、SysUserOrgService、SysRoleOrgService
// 自动注入 RedisTemplate
// 调用 xxxService 的删除组织方法
// 删除与该组织相关的用户组织关联信息
// 构建 SysRoleOrg 对象,设置组织ID,并删除与该组织相关的角色组织关联信息
// 创建 Page 对象并拷贝 PageInfo 属性
// 将传入的 JSON 请求体转换为 组织树 对象
// 用于存储组织树节点的列表
// 未传入 orgId,默认根节点为父节点
// 默认根
// 获取缓存中的 系统组织 对象
// 创建根节点
// 添加根节点到树节点列表
// 递归添加子节点
// 获取所有权限编号集合
// 获取缓存中的 系统组织 对象
// 判断是否具有权限
// 创建权限不足的返回结果
// 创建根节点
// 添加根节点到树节点列表
// 递归添加子节点
// 未传入 orgId,默认根节点为父节点
// 批量查询根据权限编号集合获取的 系统组织 列表
// 查找用户顶级机构
// 获取缓存中的顶级子节点 SysOrg 对象
// 如果根节点的子节点列表为空,则初始化子节点列表
// 添加子节点到根节点的子节点列表// 表示这是一个 RESTful 风格的 Controller
// 根据角色ID删除旧的角色菜单关联
// 循环插入新的角色菜单关联
// 记录日志,表示批量新增角色菜单成功,并输出新增的角色菜单关联列表
// 创建成功的返回结果
// 记录异常信息,表示批量新增角色菜单失败
// 创建失败的返回结果
// 后续方法类似,实现角色菜单的删除、查询和查询用户菜单等功能// 如果系统菜单列表不为空且长度大于0,则执行以下操作
//制作父菜单Id映射
// 创建用于存储父菜单Id映射的 HashMap
/ 创建用于存储菜单Id映射的 HashMap
// 遍历系统菜单列表中的每个菜单项
// 获取当前菜单项的父菜单Id
// 获取存储在父菜单Id映射中的子菜单Id列表
// 如果列表为空,则将子菜单Id列表初始化为空列表
// 将当前菜单项的菜单Id添加到子菜单Id列表中
// 将菜单Id与菜单项对象建立映射关系
// 设置根菜单Id为配置文件中的 menuRoot 属性值
// 通过递归调用 sysAppMenuService 的 getChildMenuNode 方法构建菜单树
// 如果构建的菜单树为空,则初始化为一个空的列表// 从缓存中获取组织信息的JSON数据
// 使用 xx 将 xxxStr 中的JSON数据映射为 xxx 对象
// 从缓存中获取组织信息的JSON数据
// 将角色的组织编号设置为所属组织的编号
// 遍历查询结果中的角色列表
根据组织ID查询组织信息// 获取用户所属组织信息
// 插入新的系统用户记录
// 添加用户所属组织,以及菜单角色
List<SysUserRole> sysUserRoleList = new ArrayList<>();
// Populate sysUserRoleList with SysUserRole objectsList<String> roleIdList = new ArrayList<>();
if (sysUserRoleList != null && sysUserRoleList.size() > 0) {roleIdList = sysUserRoleList.stream().map(s -> s.getRoleId()) // 提取每个元素的 roleId 属性.collect(Collectors.toList()); // 将提取出的 roleId 值收集到 roleIdList
}System.out.println(roleIdList);假设sysUserRoleList中包含以下两个对象:
SysUserRole(roleId = "123")SysUserRole(roleId = "456")
在这种情况下,运行示例代码后,输出会是:
[123, 456]这表示我们从sysUserRoleList中提取了两个不同的roleId值,分别为"123"和"456",然后将它们存放在了roleIdList中。
ClickHouse 是一个用于联机分析处理(OLAP)的开源列式数据库管理系统(DBMS)。它专门设计用于处理大规模数据分析工作负载,可以在秒级甚至亚秒级内查询数十亿行数据。ClickHouse 的列式存储和数据压缩技术使其在分析查询性能方面表现出色。它广泛用于需要快速数据分析的场景,如在线广告业务、数据仓库、日志分析等。
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview
参考资料
[1]
https://play.google.com/apps/publish/?hl=zh-CN: https://link.juejin.cn?target=https%3A%2F%2Fplay.google.com%2Fapps%2Fpublish%2F%3Fhl%3Dzh-CN
[2]http://open.qq.com/: https://link.juejin.cn?target=http%3A%2F%2Fopen.qq.com%2F
[3]http://app.baidu.com/: https://link.juejin.cn?target=http%3A%2F%2Fapp.baidu.com%2F
[4]http://dev.360.cn/: https://link.juejin.cn?target=http%3A%2F%2Fdev.360.cn%2F
[5]https://dev.vivo.com.cn/: https://link.juejin.cn?target=https%3A%2F%2Fdev.vivo.com.cn%2F
[6]http://open.oppomobile.com/: https://link.juejin.cn?target=http%3A%2F%2Fopen.oppomobile.com%2F
[7]https://dev.mi.com/: https://link.juejin.cn?target=https%3A%2F%2Fdev.mi.com%2F
[8]http://developer.huawei.com/consumer/cn/: https://link.juejin.cn?target=http%3A%2F%2Fdeveloper.huawei.com%2Fconsumer%2Fcn%2F
[9]http://open.uc.cn/: https://link.juejin.cn?target=http%3A%2F%2Fopen.uc.cn%2F
[10]http://zhushou.sogou.com/open/: https://link.juejin.cn?target=http%3A%2F%2Fzhushou.sogou.com%2Fopen%2F
[11]http://dev.smartisan.com/: https://link.juejin.cn?target=http%3A%2F%2Fdev.smartisan.com%2F
[12]http://open.flyme.cn/: https://link.juejin.cn?target=http%3A%2F%2Fopen.flyme.cn%2F
[13]http://open.appgionee.com/: https://link.juejin.cn?target=http%3A%2F%2Fopen.appgionee.com%2F
[14]http://dev.anzhi.com/: https://link.juejin.cn?target=http%3A%2F%2Fdev.anzhi.com%2F
[15]https://developer.coolapk.com: https://link.juejin.cn?target=https%3A%2F%2Fdeveloper.coolapk.com
[16]http://open.lenovo.com/: https://link.juejin.cn?target=http%3A%2F%2Fopen.lenovo.com%2F
[17]http://support-cn.samsung.com/App/DeveloperChina/Home/Index: https://link.juejin.cn?target=http%3A%2F%2Fsupport-cn.samsung.com%2FApp%2FDeveloperChina%2FHome%2FIndex
相关文章:
springboot第35集:微服务与flutter安卓App开发
Google Playplay.google.com/apps/publis…[1]应用宝open.qq.com/[2]百度手机助手app.baidu.com/[3]360 手机助手dev.360.cn/[4]vivo 应用商店dev.vivo.com.cn/[5]OPPO 软件商店(一加)open.oppomobile.com/[6]小米应用商店dev.mi.com/[7]华为应用市场dev…...

java 把list转成json
在Java中,将List转换成JSON格式是非常常见的任务。JSON是一种轻巧的数据交换格式,非常适合于Web应用程序,特别是前端开发。 使用Java将List转换成JSON格式的最简单方法是通过JSON库。最常用的JSON库是 Jackson,它提供了快速&…...
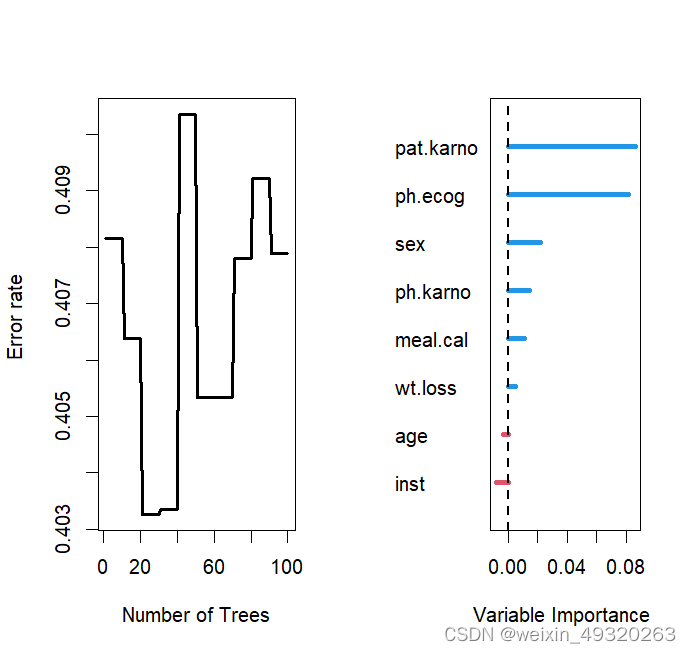
R语言实现随机生存森林(2)
library(survival) library(randomForestSRC) help(package"randomForestSRC") #构建普通的随机生存森林 data(cancer,package"survival") lung$status<-lung$status-1 rfsrc.fit1 <- rfsrc(Surv(time, status) ~ ., lung,ntree 100,block.size 1,…...

泛型类接口方法学习
一、泛型 1 概念 泛型(Generics),广泛的类型。最大用途是给集合容器添加标签,让开发人员知道容器里面放到是什么类型,并且自动对放入集合的元素进行类型检查。 类比实参和形参,我们在对方法中的变量操作时,并没有指…...
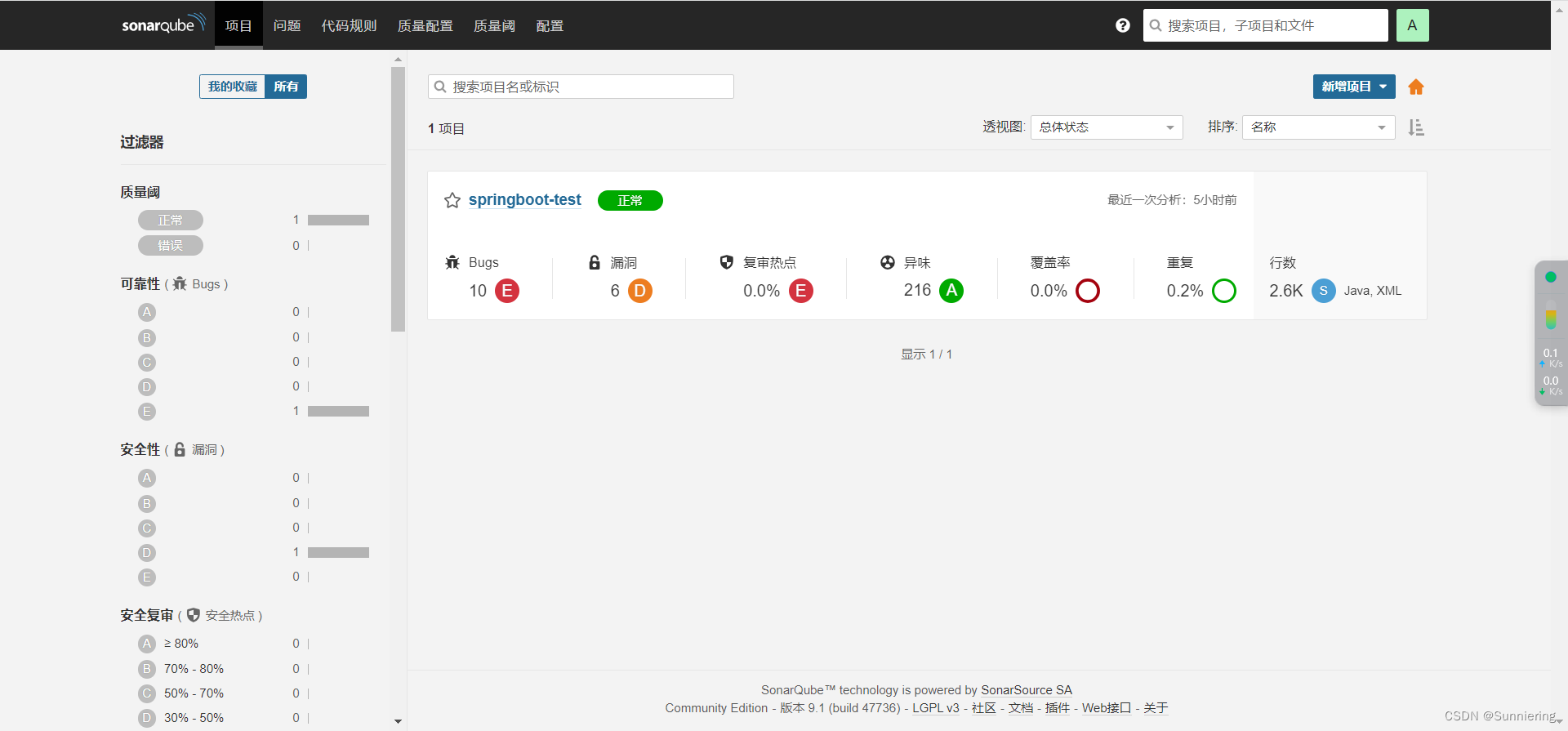
Docker自动化部署安装(十)之安装SonarQube
这里选择的是: sonarqube:9.1.0-community (推荐使用) postgres:9.6.23 数据库(sonarqube7.9及以后便不再支持mysql,版本太低的话里面的一些插件会下载不成功的) 1、docker-sonarqube.yml文件 version: 3 services:sonarqube:container_name: sonar…...

[QT/C++]如何得知鼠标事件是由触摸事件转换而来的,使得鼠标触摸事件分离
依据来源:https://doc.qt.io/qt-5/qml-qtquick-mouseevent.html 具体是在event事件或者mouse系列事件中捕获到鼠标事件后,用如下代码判断鼠标事件是否由触摸事件转换而来的 if(mouseEvent->source()Qt::MouseEventSynthesizedBySystem){qDebug()<&…...

消防态势标绘工具,为消防基层工作助力
背景介绍 无人机测绘技术在消防领域的应用越来越普及,高清的二维正射影像和倾斜摄影实景三维模型能为消防态势标绘提供高质量的素材,消防队急需一个简便易用的、能够基于这些二三维的高清地图成果进行态势标绘的工具软件,使得消防“六熟悉”…...
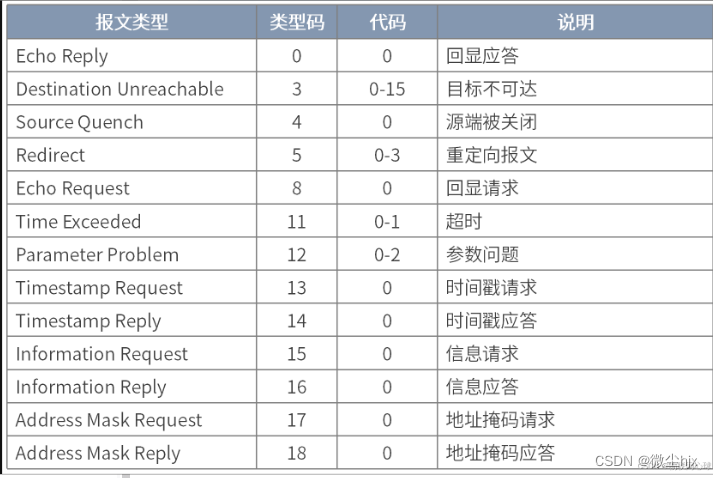
网络协议栈-基础知识
1、分层模型 1.1、OSI七层模型 1、OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型 ,是一个逻辑上的定义,一个规范,它把网络从逻辑上分为了7层。 2、每一层都有相关…...
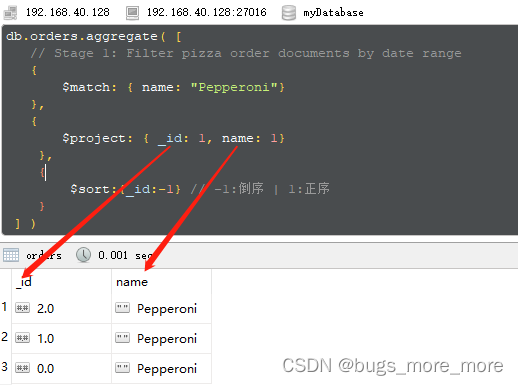
[Mongodb 5.0]聚合操作
本文对应Aggregation Operations — MongoDB Manual 正文 此章节主要介绍了Aggregation Pipeline,其实就是将若干个聚合操作放在管道中进行执行,每一个聚合操作的结果作为下一个聚合操作的输入,每个聚合指令被称为一个stage。 在正式开始学…...

Shell 变量
Shell 变量 定义变量时,变量名不加美元符号($,PHP语言中变量需要),如: your_name"runoob.com" 注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样…...

SRM订单管理:优化供应商关系
一、概述SRM订单管理的概念: SRM订单管理是指在供应商关系管理过程中,有效管理和控制订单的创建、处理和交付。它涉及与供应商之间的沟通、合作和协调,旨在实现订单的准确性、可靠性和及时性。 二、SRM订单管理的流程: 1. 订单创…...
Unity 实现2D地面挖洞!涂抹地形(碰撞部分,方法二)
文章目录 前言一、初始化虚拟点1.1点结构:1.2每个点有的状态:1.3生成点结构: 二、实例化边缘碰撞盒2.1计算生成边缘碰撞盒 三、涂抹部分3.1.虚拟点3.2.鼠标点3.3.内圈3.4.外圈 四、关于优化结语: 前言 老规矩先上效果图 继上一篇涂抹地形文章讲解发出后,有不少网友…...

简化Gerber数据传输过程丨GC PowerPlace简介
离线编程,保持高效 GC PowerPlace提供了客户驱动的增强功能和新功能,以简化Gerber数据传输过程。GC PowerPlace是汇编编程的焦点,它接受几乎任何来源的数据,并为大多数PCB制造应用程序生成程序和文件。 功能特征 01、主要特点 …...
rust关于项目结构包,Crate和mod和目录的组织
rust 最近开始学习rust语言。感觉这门语言相对java确实是难上很多。开几个文章把遇到的问题记录一下 rust关于包,Crate 关于包,Crate这块先看看官方书籍怎么说的 crate 是 Rust 在编译时最小的代码单位。如果你用 rustc 而不是 cargo 来编译一个文件…...
如何微调优化你的ChatGPT提示来提高对话质量
ChatGPT会话质量很大程度上取决于微调优化提示的艺术。本文旨在阐明微调提示的复杂性,以确保你可以充分发挥ChaGPT这一颠覆性工具的潜力。 与ChatGPT对话的关键部分是“提示”。即:你输入的问题或陈述,它决定了人工智能的响应。类似于引导对…...

微信小程序实现下拉刷新
一、设置微信小程序所有页面都可以下拉刷新 1、在app.json的"window"中进行配置 (1)把"backgroundTextStyle":“light"改为"backgroundTextStyle”:“dark” (2)添加"enablePullDownRefresh…...

一、编程规约
一、编程规约 (一)命名风格 不以下划线(_)或美元符号($)开始和结束不用中文拼音避免歧视或侮辱性词语类名用UpperCamelCase风格,以下情况例外:DO/PO/DTO等方法名、参数名、成员变量、局部变量使用lowerCam…...

pytest数据驱动 pandas
pytest数据驱动 pandas 主要过程:用pandas读取excel里面的数据,然后进行百度查询,并断言 pf pd.read_excel(data_py.xlsx, usecols[1,2])print(pf.values)输出:[[‘听妈妈的话’ ‘周杰伦’] [‘遇见’ ‘孙燕姿’] [‘伤心太平…...

Modbus工业RFID设备在自动化生产线中的应用
传统半自动化生产线在运作的过程,因为技工的熟练程度,专业素养的不同,在制造过程中过多的人为干预,工厂将很难对每条生产线的产能进行标准化管理和优化。如果半自动化生产线系统是通过前道工序的作业结果和检测结果来决定产品在下…...

见证马斯克的钞能力,AI.com再次易主,OpenAI投掷1100万美金购买AI.com刚满五个月
我们又一次见证了马斯克的钞能力。上次是去年他用440亿美元买下推特。 高价值的AI.com域名在2021年易主后,闲置过一段时间,今年2月份突然重定向到ChatGPT。 对于ChatGPT用户来说,每次访问都要在浏览器里敲这些字符:https://chat.o…...
)
告别手动映射!用AD域控组策略批量给员工电脑挂载共享盘(Windows Server 2016实战)
企业级共享存储自动化部署指南:基于AD域控的组策略实战每当新员工入职或部门调整时,IT管理员最头疼的莫过于重复配置几十台电脑的共享盘映射。财务部需要访问M盘的报表目录,市场部要连接N盘的设计素材,而手动设置不仅效率低下&…...

AI写文章,你的创作新伙伴
你有没有想过,有一天写文章这件事可以变得像聊天一样轻松?别急着摇头,前阵子我在一个写作论坛里翻到一篇帖子,楼主问大家每天写稿累不累,结果底下好多人分享说,他们现在都靠工具来辅助了。而其中被提到最多…...

基于可解释机器学习的心电图预测胸片异常:技术原理与临床实践
1. 项目概述:当心电图“看见”胸片在急诊室或者基层医疗点,一个呼吸急促、胸痛的患者被送来,临床医生面临的首要决策往往是:是否需要立刻安排胸部X光检查?胸片是评估心肺和胸腔状况的基石,但它需要设备、技…...

Wand-Enhancer:三步解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:三步解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高额订阅费用…...

告别内存泄漏!Cocos Creator 2.4+ AssetManager资源释放的完整避坑指南
Cocos Creator 2.4 AssetManager资源释放的完整避坑指南在游戏开发中,资源管理一直是影响性能和稳定性的关键因素。随着Cocos Creator 2.4版本推出全新的AssetManager系统,开发者获得了更强大的资源管理能力,但也面临着新的挑战。本文将深入探…...

华硕笔记本性能优化终极指南:如何用G-Helper替代Armoury Crate提升体验
华硕笔记本性能优化终极指南:如何用G-Helper替代Armoury Crate提升体验 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivob…...

Frida Hook Java层还原App签名算法实战
1. 这不是“破解”,而是理解通信逻辑的必要手段你打开某物App,点击下单,网络请求瞬间发出——但抓包一看,body里全是密文,header里带着一串32位字符串,看着像MD5,但每次请求都变;用B…...

HFSS的Solution type及其激励端口设置规则
本文围绕Ansys HFSS 电磁仿真展开,依次探讨辐射边界特性、软件求解类型、PCB 板载天线求解选型、两类端口原理差异、端口信号地判定与集总端口参考面设置、求解与端口适配规则六大板块内容,完整梳理如下:一、HFSS 辐射边界条件相关讨论基本定…...

科技助力,具身智能体在幼儿园科技启蒙中的应用
具身机器人通过互动式学习、多感官体验和情境化教学,为幼儿科技启蒙提供创新支持。其应用可围绕以下方向展开:互动游戏设计 开发基于肢体动作的交互游戏,如通过机器人模仿幼儿舞蹈动作,激发参与兴趣。语言与逻辑训练 利用机器人讲…...

HTTPS静态资源403/404根因排查:从Nginx配置到SELinux权限
1. 这不是SSL证书的问题,而是HTTP服务配置的“隐身故障”你刚在云服务商控制台花了几十块钱买了张正规CA签发的SSL证书,上传到Nginx或Apache,配好了443端口,https://yourdomain.com打开首页也绿锁高亮,一切看起来都对—…...