分布式任务调度(XXL-JOB)
什么是分布式任务调度?
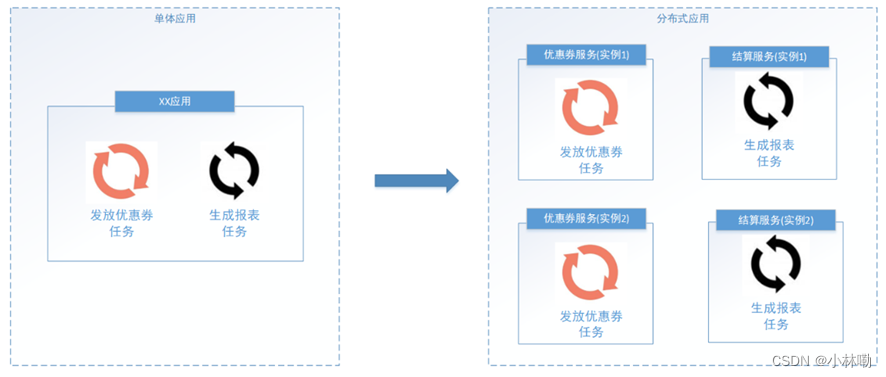
任务调度顾名思义,就是对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。通常任务调度的程序是集成在应用中的,比如:优惠卷服务中包括了定时发放优惠卷的的调度程序,结算服务中包括了定期生成报表的任务调度程序,由于采用分布式架构,一个服务往往会部署多个冗余实例来运行我们的业务,在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度,如下图:
1、并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。
2、高可用
若某一个实例宕机,不影响其他实例来执行任务。
3、弹性扩容
当集群中增加实例就可以提高并执行任务的处理效率。
4、任务管理与监测
对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
5、避免任务重复执行
当任务调度以集群方式部署,同一个任务调度可能会执行多次,比如在上面提到的电商系统中到点发优惠券的例子,就会发放多次优惠券,对公司造成很多损失,所以我们需要控制相同的任务在多个运行实例上只执行一次。
XXL-JOB
主要有调度中心、执行器、任务

调度中心:
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码;
主要职责为执行器管理、任务管理、监控运维、日志管理等
任务执行器:
负责接收调度请求并执行任务逻辑;
只要职责是注册服务、任务执行服务(接收到任务后会放入线程池中的任务队列)、执行结果上报、日志服务等
任务:负责执行具体的业务处理。

执行流程:
1.任务执行器根据配置的调度中心的地址,自动注册到调度中心
2.达到任务触发条件,调度中心下发任务
3.执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
4.执行器消费内存队列中的执行结果,主动上报给调度中心
5.当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
搭建XXL-JOB
GitHub:https://github.com/xuxueli/xxl-job![]() https://github.com/xuxueli/xxl-job
https://github.com/xuxueli/xxl-job
码云:https://gitee.com/xuxueli0323/xxl-job![]() https://gitee.com/xuxueli0323/xxl-job
https://gitee.com/xuxueli0323/xxl-job
在本机已经安装完毕xxljob
F:\javaSoftWare\xxl-job-2.3.1
1.使用idea已maven项目的方式,打开解压后的zip文件

xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
doc :文档资料,包含数据库脚本
2.创建数据库:xxl_job_2.3.1

首先修改doc下的tables_xxl_job.sql脚本内容:
| Java |
将tables_xxl_job.sql脚本导入xxl_job_2.3.1数据库,导入成功,刷新表,如下图:

修改xxl-job-admin任务调度中心下application.properties的配置文件内容,修改数据库链接地址:
| Java
|
3.然后启动xxl-job-admin任务调度中心,
运行com.xxl.job.admin.XxlJobAdminApplication
启动成功访问 http://localhost:8080/xxl-job-admin
账号和密码:admin/ 123456

虚拟机中已经创建的xxl-job调度中心的容器,后边调用使用docker容器运行xxl-job。
启动docker容器:docker start xxl-job-admin
访问:http://192.168.101.65:8088/xxl-job-admin/
账号和密码:admin/123456
4.执行器
4.1在对应模块添加依赖(在父工程中已经指定了版本号)
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId>
</dependency>
4.2在nacos中配置xxl-job
xxl:job:admin: addresses: http://localhost:8080/xxl-job-adminexecutor:appname: media-process-serviceaddress: ip: port: 9999logpath: /data/applogs/xxl-job/jobhandlerlogretentiondays: 30accessToken: default_token
完整nacos如下:
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.101.65:3306/xc148_media?serverTimezone=UTC&userUnicode=true&useSSL=false&username: rootpassword: mysqlcloud:config:override-none: trueminio:endpoint: http://192.168.101.65:9000accessKey: minioadminsecretKey: minioadminbucket:files: mediafilesvideofiles: video
xxl:job:admin: addresses: http://192.168.101.65:8088/xxl-job-adminexecutor:appname: media-process-serviceaddress: ip: port: 9999logpath: /data/applogs/xxl-job/jobhandlerlogretentiondays: 30accessToken: default_tokenvideoprocess:ffmpegpath: D:/soft/ffmpeg/ffmpeg.exeappname这是执行器的应用名,稍后在调度中心配置执行器时要使用
4.3将示例文件拷贝到要使用的模块的配置文件目录中
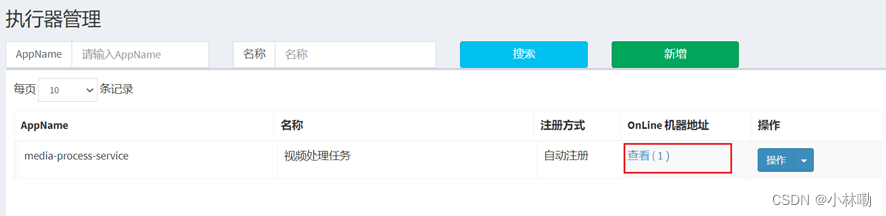
4.4进入调度中心添加执行器



到此完成工程配置xxl-job执行器,在xxl-job调度中心添加执行器,下边准备测试执行器与调度中心是否正常通信,因为接口工程依赖了service工程,所以启动媒资管理模块的接口工程。
启动后观察日志,出现下边的日志表示执行器在调度中心注册成功
![]()
同时观察调度中心中的执行器界面
5.下边编写任务,任务类的编写方法参考示例工程,如下图

/*** @description 测试执行器* @author Mr.M* @date 2022/9/13 20:32* @version 1.0*/@Component@Slf4j
public class SampleJob {/*** 1、简单任务示例(Bean模式)*/@XxlJob("testJob")public void testJob() throws Exception {log.info("开始执行.....");}}
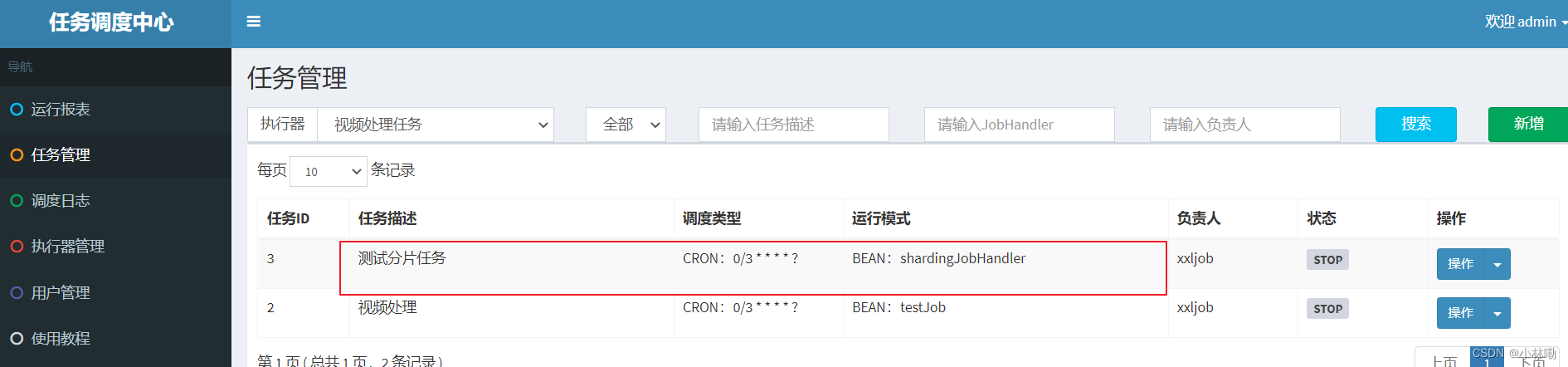
下边在调度中心添加任务,进入任务管理

点击新增,填写任务信息

注意红色标记处:
调度类型选择Cron,并配置Cron表达式设置定时策略。
运行模式有BEAN和GLUE,bean模式较常用就是在项目工程中编写执行器的任务代码,GLUE是将任务代码编写在调度中心。
JobHandler任务方法名填写@XxlJob注解中的名称。
添加成功,启动任务

通过调度日志查看任务执行情况

下边启动媒资管理的service工程,启动执行器。
观察执行器方法的执行。

如果要停止任务需要在调度中心操作
任务跑一段时间注意清理日志

6.分片广播
掌握了xxl-job的基本使用,下边思考如何进行分布式任务处理呢?如下图,我们会启动多个执行器组成一个集群,去执行任务。
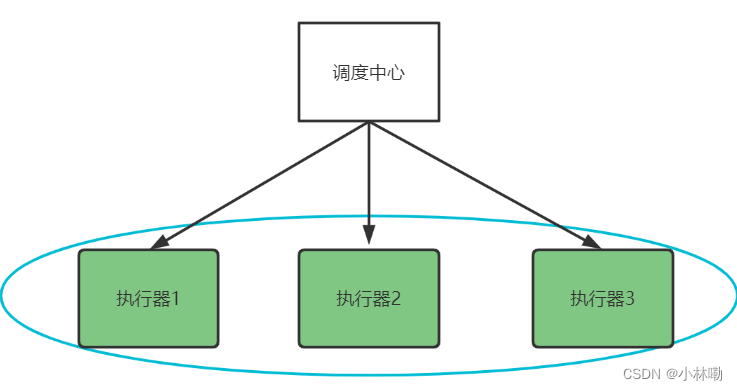
执行器在集群部署下调度中心有哪些调度策略呢?
查看xxl-job官方文档,阅读高级配置相关的内容:
| SQL |
第一个:每次调度选择集群中第一台执行器。
最后一个:每次调度选择集群中最后一台执行器。
轮询:按照顺序每次调度选择一台执行器去调度。
随机:每次调度随机选择一台执行器去调度。
CONSISTENT_HASH:按任务的hash值选择一台执行器去调度。
其它策略请自行阅读文档。
下边要重点说的是分片广播策略,分片是指是调度中心将集群中的执行器标上序号:0,1,2,3...,广播是指每次调度会向集群中所有执行器发送调度请求,请求中携带分片参数。
如下图:

每个执行器收到调度请求根据分片参数自行决定是否执行任务。
另外xxl-job还支持动态分片,当执行器数量有变更时,调度中心会动态修改分片的数量。
作业分片适用哪些场景呢?
- 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
- 广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等。
所以,广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群分布式处理任务。
使用说明:
"分片广播" 和普通任务开发流程一致,不同之处在于可以获取分片参数进行分片业务处理。
Java语言任务获取分片参数方式:
BEAN、GLUE模式(Java),可参考Sample示例执行器中的示例任务"ShardingJobHandler":
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
分片参数属性说明:
index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
total:总分片数,执行器集群的总机器数量;
下边测试作业分片:
1、定义作业分片的任务方法
| Java |
2、在调度中心添加任务

高级配置说明:
| Plain Text |
添加成功:
启动任务,观察日志
在任务中通是开启两个节点,复制两份模块的具体方法如下:
在idea中的上方run处点击,然后进入到Edit Configuration,注意想要复制的是MediaApplication这个module,点击上方第三个按钮复制后,点击modify options,然后输入配置的文件,此时应该去nacos中找,在nacos中对应的api的配置文件是module运行的端口,但是此处要注意,我们要先将nacos配置为本地文件优先的模式,不然本地文件是不会生效的,具体的配置方式如下:
#配置本地优先
spring:cloud:config:override-none: true然后我们要注意,根据nacos的配置文件来写要更爱的端口号的形式,在api的nacos配置文件中,port如下所示:可以看到,port的路径是server下的port,所以port在modify options中配置为以D开头的-Dserver.port=63051 (等号中间不要加空格)

同时我们要避免执行器的端口冲突,执行器是mediaService所以要去对应的service的nacos的配置文件去配置。下图就是service的nacos配置文件,此处注意到,执行器的端口配置在xxl:executor:port下,所以modify options中在前面的Dserver.port=63051 后添加一个空格,然后加上
-Dxxl.job.executor.port=9998
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.101.65:3306/xc148_media?serverTimezone=UTC&userUnicode=true&useSSL=false&username: rootpassword: mysqlcloud:config:override-none: trueminio:endpoint: http://192.168.101.65:9000accessKey: minioadminsecretKey: minioadminbucket:files: mediafilesvideofiles: video
xxl:job:admin: addresses: http://192.168.101.65:8088/xxl-job-adminexecutor:appname: media-process-serviceaddress: ip: port: 9999logpath: /data/applogs/xxl-job/jobhandlerlogretentiondays: 30accessToken: default_tokenvideoprocess:ffmpegpath: D:/soft/ffmpeg/ffmpeg.exe

下边启动两个执行器实例,观察每个实例的执行情况
首先在nacos中配置media-service的本地优先配置:
| YAML |
将media-service启动两个实例
两个实例的在启动时注意端口不能冲突:
实例1 在VM options处添加:-Dserver.port=63051 -Dxxl.job.executor.port=9998
实例2 在VM options处添加:-Dserver.port=63050 -Dxxl.job.executor.port=9999
例如:

启动两个实例
观察任务调度中心,稍等片刻执行器有两个

观察两个执行实例的日志:

另一实例的日志如下:
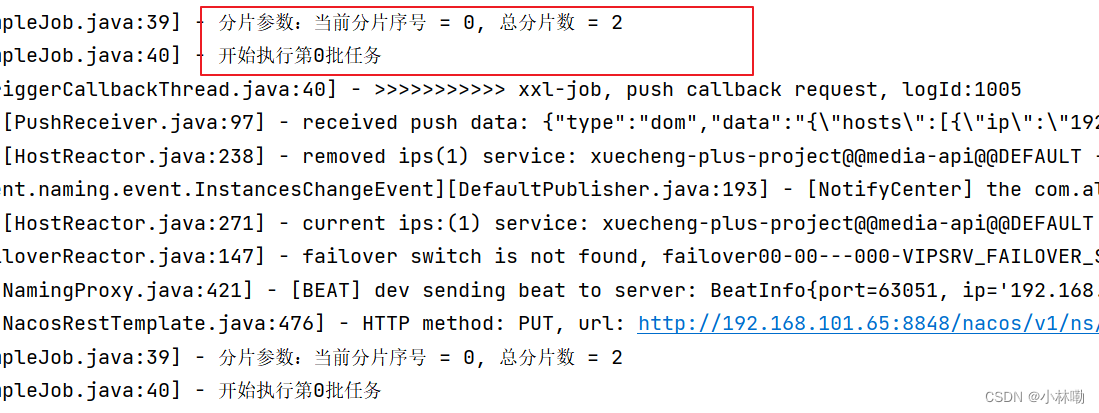
从日志可以看每个实例的分片序号不同。
到此作业分片任务调试完成,此时我们可以思考:
当一次分片广播到来,各执行器如何根据分片参数去分布式执行任务,保证执行器之间执行的任务不重复呢?
相关文章:
分布式任务调度(XXL-JOB)
什么是分布式任务调度? 任务调度顾名思义,就是对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。通常任务调度的程序是集成在应用中的,比如:…...
Django框架之模型视图--Session
Session 1 启用Session Django项目默认启用Session。 可以在settings.py文件中查看,如图所示 如需禁用session,将上图中的session中间件注释掉即可。 2 存储方式 在settings.py文件中,可以设置session数据的存储方式,可以保存…...
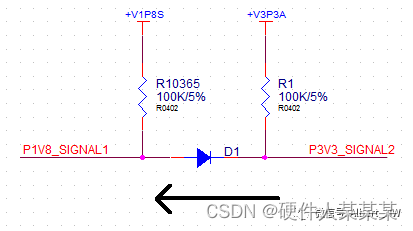
二极管的“几种”应用
不知大家平时有没有留意,二极管的应用范围是非常广的,下面我们来看看我想到几种应用,也可以加深对电路设计的认识: A,特性应用: 由于二极管的种类非常之多,这里这个大类简单罗列下:…...
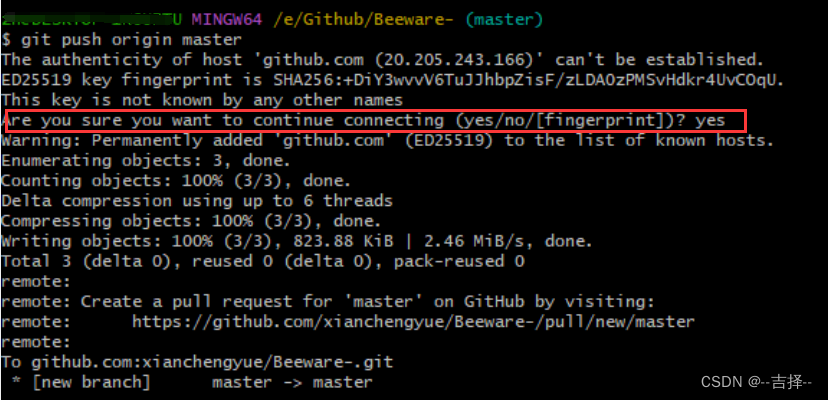
github上传本地文件详细过程
repository 也就是俗称的仓库 声明:后续操作基于win10系统 前提:有一个github账号、电脑安装了git(官方安装地址) 目的: 把图中pdf文件上传到github上的个人仓库中 效果: 温馨提示: git中复制: ctrl insert…...
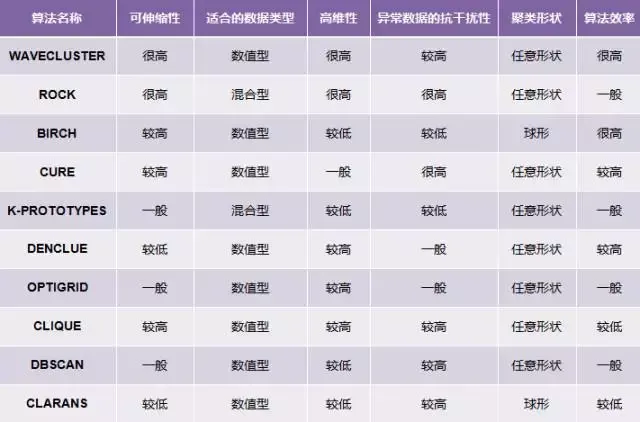
常用聚类算法分析
1. 什么是聚类 1.1. 聚类的定义 聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起…...

OSG三维渲染引擎编程学习之五十八:“第五章:OSG场景渲染” 之 “5.16 简单光源”
目录 第五章 OSG场景渲染 5.16 简单光源 5.16.1 场景中使用光源 5.16.2 简单光源示例 第五章 OSG场景渲染 OSG存在场景树和渲染树,“场景数”的构建在第三章“OSG场景组...
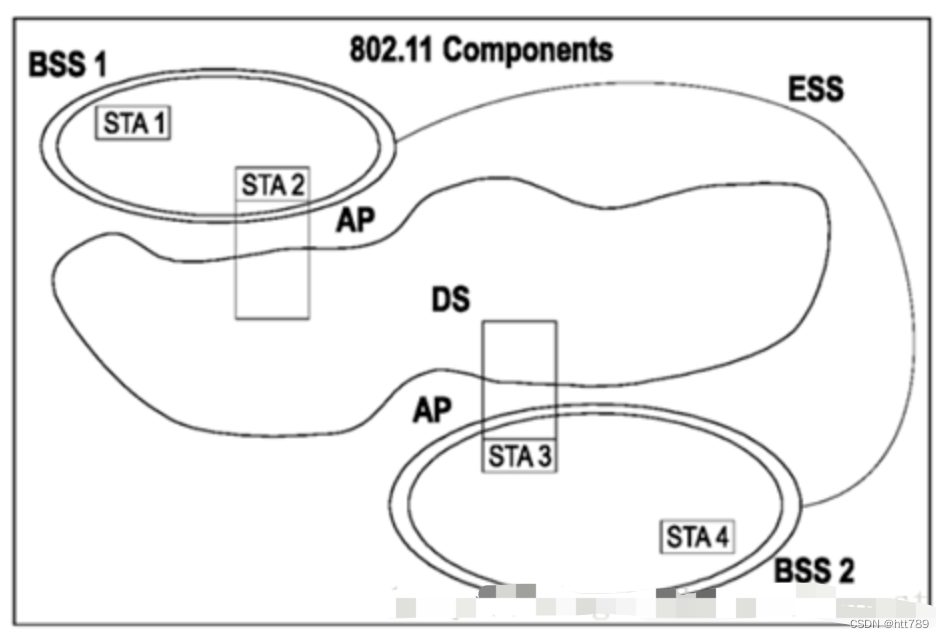
80211无线网络架构
无线网络架构物理组件BSS(Basic Service Set)基本服务集BSSID(BSS Identification)ssid(Service Set Identification)ESS(Extended Service Set)扩展服务集物理组件 无线网络包含四…...
基于springboot+vue的便利店库存管理系统
基于springbootvue的便利店库存管理系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景…...

3|物联网控制|计算机控制-刘川来胡乃平版|第1章:绪论|青岛科技大学课堂笔记|U1 ppt
目录绪论(2学时)常用仪表设备(3学时)计算机总线技术(4学时)过程通道与人机接口(6学时)数据处理与控制策略(6学时)网络与通讯技术(3学时࿰…...
js打印本地pdf(使用HttpPrinter打印插件)
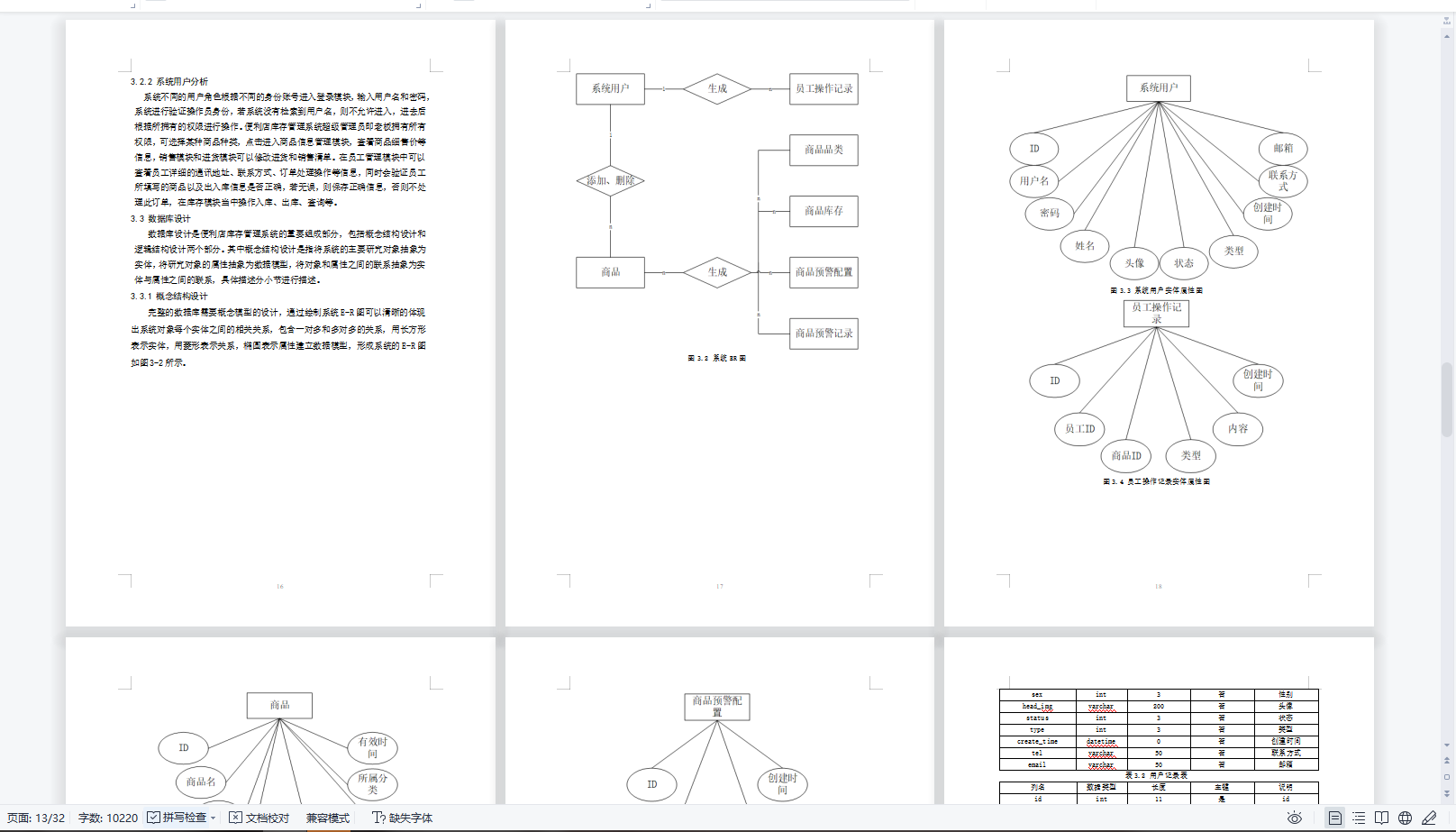
js打印本地pdf(使用HttpPrinter打印插件)第一步:启动HttpPrinter打印插件第二步:用浏览器打开示例文件\调用示例\websocket协议示例\html\打印pdf.html输入pdf地址 点击 “下载并打印pdf文件”按钮,就可以静默打印了。…...
 | 机试题算法思路 【2023】)
华为OD机试 - 双十一(Python) | 机试题算法思路 【2023】
最近更新的博客 【新解法】华为OD机试 - 关联子串 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 停车场最大距离 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 任务调度 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试…...

2020年UML 秋季期末测试题
1.UML的全称是(B )。A.Unified Making LanguageB.Unified Modeling LanguageC.Unified Meodem languageD.Unify Modeling Language2.UML主要应用于( C)。A.基于螺旋模型的结构化开发方法B.基于数据的数据流开发方法C.基于对象的面…...
SpringCloud - Ribbon负载均衡
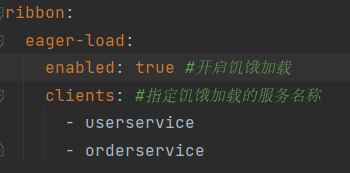
目录 负载均衡流程 负载均衡策略 Ribbon加载策略 负载均衡流程 Ribbon将http://userservice/user/1请求拦截下来,帮忙找到真实地址http://localhost:8081LoadBalancerInterceptor类对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表&…...

Spring Boot + Redis 实现分布式锁
一、业务背景有些业务请求,属于耗时操作,需要加锁,防止后续的并发操作,同时对数据库的数据进行操作,需要避免对之前的业务造成影响。二、分析流程使用 Redis 作为分布式锁,将锁的状态放到 Redis 统一维护&a…...

CAD二次开发 插件初始化接口IExtensionApplication
前言:在实际项目开发中,我们总会遇到一些问题。比如说在CAD打开之前,修改注册表的内容,或者解决CAD在没有完全加载想要的dll情况下,功能运行报错的bug。因此,下面和大家介绍一下IExtensionApplication接口 …...

kafka-11-kafka的监控工具和常用配置参数
kafka官方文档 参考Kafka三款监控工具比较 1 查看kafka的版本 进入kafka所在目录,通过查看libs目录下的jar包。 2.11是scala的版本,2.0.0是kafka的版本。 测试环境 #systemctl start zookeeper #systemctl start kafkka 2 kafka的常用配置 Kafka使用…...

前端PWA渐进式加载技术
1.什么是PWA? 渐进式网络应用(PWA)是谷歌在2015年底提出的概念。基本上算是web应用程序,但在外观和感觉上与原生app类似。支持PWA的网站可以提供脱机工作、推送通知和设备硬件访问等功能。 2.PWA有那些优点? 更小更…...

【ubuntu 22.04不识别ch340串口】
这个真是挺无语的,发现国内厂商普遍对开源环境不感兴趣,ch340官方linux驱动好像被厂家忘了,现在放出来的驱动还是上古内核版本: 于是,驱动居然要用户自己编译安装。。还好网上有不少大神:链接,…...

解决:eclipse绿化版Resource注解报Resource cannot be resolved to a type问题
如图: 网上解决教程很多,我的eclipse是绿化版的,不需要安装 解决办法如下: 1、在eclipse中,进入到Window->Preferences->Java->Installed JREs中 默认显示如下: 2、点击Add-->Standard VM--…...

初识Cookie和Session
Cookie和Session出于安全考虑,浏览器不让网页直接操作文件系统,而Cookie就是一个折中的方案,可以让网页暂存一些数据在本地,不能存复杂的对象,只能存字符串。Cookie是按照域名分类的,这个很好理解。如何理解…...

告别“模板感”:打造高转化企业官网的全流程指南
在互联网流量红利见顶的今天,企业官网早已不再是简单的“网络名片”。面对同质化严重的模板网站,用户早已审美疲劳。一个真正有价值的网站,不仅要颜值在线,更要有清晰的定位和严密的逻辑支撑。它既是品牌形象的门面,更…...

手把手教你用OpenMP和CUDA加速ICP配准:从单核到GPU的完整性能对比
手把手教你用OpenMP和CUDA加速ICP配准:从单核到GPU的完整性能对比 ICP(Iterative Closest Point)算法是点云配准领域的经典方法,但在处理大规模点云时常常面临性能瓶颈。本文将深入探讨如何利用OpenMP和CUDA技术对ICP算法进行多线…...

核心代码编程-社交网络相同爱好好友查询-200分
题目描述:在一个社交网络中,用户之间通过"关注"关系形成有向图。每个用户有两个属性 ﹣用户ID(整数字符串) ﹣兴趣标列表(字符串数组) 现在需要实现一个函数,查询…...

微软UFO项目:统一AI模型调用的抽象层设计与工程实践
1. 项目概述:当“统一”成为AI开发的新范式最近在折腾大模型应用开发的朋友,可能都绕不开一个痛点:模型太多,工具链太杂。想用闭源的GPT-4处理文本,用开源的Llama搞本地推理,再用DALL-E 3生成图片ÿ…...

AI赋能的两种逻辑企业如何选?:从「AI+行业」
在人工智能全面重构产业格局的今天,用不用 AI 已经不是问题,怎么用 AI 才是生死关键。同样是布局 AI,有的企业只实现小幅增效,有的企业却直接颠覆行业、重塑价值链。 核心差距,就在于选择了 「AI 行业」的加法逻辑&am…...

为什么你的v8出图突然“高级感崩塌”?3分钟定位色彩语义锚点失效+实时修复模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的v8出图突然“高级感崩塌”? V8 引擎本身并不直接“出图”——这一表述实为开发者对前端渲染链路中某环节异常的戏谑指代。真正崩塌的,往往是基于 V8 驱动的 Canvas/We…...

GraphQL-WS服务器配置:完整参数详解与最佳实践
GraphQL-WS服务器配置:完整参数详解与最佳实践 【免费下载链接】graphql-ws Coherent, zero-dependency, lazy, simple, GraphQL over WebSocket Protocol compliant server and client. 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-ws GraphQL-WS…...

3D模型格式转换终极指南:如何用stltostp快速将STL转为STEP格式
3D模型格式转换终极指南:如何用stltostp快速将STL转为STEP格式 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到这样的困境?辛苦设计的3D打印模型在STL格式…...

Clawless框架:构建合规网页数据抓取系统的设计哲学与实践指南
1. 项目概述与核心价值最近在GitHub上闲逛,发现了一个名为“Clawless”的项目,作者是HainanZhao。这个项目名挺有意思,“Clawless”直译是“无爪”,听起来像是一个温和无害的工具。点进去一看,发现它是一个用于自动化处…...

嵌入式GUI设计:资源受限下的高效人机交互实践
1. 嵌入式GUI设计的核心挑战与价值定位在咖啡机、车载仪表、医疗设备等嵌入式系统中,图形用户界面(GUI)承担着人机交互的关键桥梁作用。与桌面端或移动端GUI不同,嵌入式GUI面临三大独特约束:首先,硬件资源极度受限——典型嵌入式处…...