ClickHouse(十八):Clickhouse Integration系列表引擎

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. HDFS
1.1 语法
1.2 其他配置
1.3 示例
2. MySQL
2.1 语法
2.2 示例
2.3 测试 replace_query
2.4 测试 on_duplicate_clause
3. Kafka
3.1 语法
3.2 示例
3.3 示例
ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
1. HDFS
HDFS引擎支持ClickHouse 直接读取HDFS中特定格式的数据文件,目前文件格式支持Json,Csv文件等,ClickHouse通过HDFS引擎建立的表,不会在ClickHouse中产生数据,读取的是HDFS中的数据,将HDFS中的数据映射成ClickHouse中的一张表,这样就可以使用SQL操作HDFS中的数据。
ClickHouse并不能够删除HDFS上的数据,当我们在ClickHouse客户端中删除了对应的表,只是删除了表结构,HDFS上的文件并没有被删除,这一点跟Hive的外部表十分相似。
1.1 语法
ENGINE = HDFS(URI, format)注意:URI是HDFS文件路径,format指定文件格式。HDFS文件路径中文件为多个时,可以指定成some_file_?,或者当数据映射的是HDFS多个文件夹下数据时,可以指定somepath/* 来指定URI
1.2 其他配置
由于HDFS配置了HA 模式,有集群名称,所以URI使用mycluster HDFS集群名称时,ClickHouse不识别,这时需要做以下配置:
- 将hadoop路径下$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件复制到/etc/clickhouse-server目录下。
- 修改/etc/init.d/clickhouse-server 文件,加入一行 “export LIBHDFS3_CONF=/etc/clickhouse-server/hdfs-site.xml”
- 重启ClickHouse-server 服务
serveice clickhouse-server restart
当然,这里也可以不做以上配置,在写HDFS URI时,直接写成对应的节点+端口即可。
1.3 示例
#在HDFS路径 hdfs://mycluster/ch/路径下,创建多个csv文件,写入一些数据c1.csv文件内容:1,张三,192,李四,20c2.csv文件内容:3,王五,214,马六,22#创建表 t_hdfs,使用HDFS引擎node1 :) create table t_hdfs(id UInt8,name String,age UInt8) engine = HDFS('hdfs://mycluster/ch/*.csv','CSV')#查询表 t_hdfs中的数据node1 :) select * from t_hdfs;┌─id─┬─name─┬─age─┐│ 3 │ 王五 │ 21 ││ 4 │ 马六 │ 22 │└────┴──────┴─────┘┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 19 ││ 2 │ 李四 │ 20 │└────┴──────┴─────┘注意:这里表t_hdfs不会在clickhouse对应的节点路径下创建数据目录,同时这种表映射的是HDFS路径中的csv文件,不能插入数据,t_hdfs是只读表。#创建表 t_hdfs2 文件 ,使用HDFS引擎node1 :) create table t_hdfs2(id UInt8,name String,age UInt8) engine = HDFS('hdfs://mycluster/chdata','CSV');#向表 t_hdfs2中写入数据node1 :) insert into t_hdfs2 values(5,'田七',23),(6,'赵八',24);#查询表t_hdfs2中的数据node1 :) select * from t_hdfs2;┌─id─┬─name─┬─age─┐│ 5 │ 田七 │ 23 ││ 6 │ 赵八 │ 24 │└────┴──────┴─────┘注意:t_hdfs2表没有直接映射已经存在的HDFS文件,这种表允许查询和插入数据。2. MySQL
ClickHouse MySQL数据库引擎可以将MySQL某个库下的表映射到ClickHouse中,使用ClickHouse对数据进行操作。ClickHouse同样支持MySQL表引擎,即映射一张MySQL中的表到ClickHouse中,使用ClickHouse进行数据操作,与MySQL数据库引擎一样,这里映射的表只能做查询和插入操作,不支持删除和更新操作。
2.1 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);- 以上语法的解释如下:
- host:port - MySQL服务器名称和端口
- database - MySQL 数据库。
- table - 映射的MySQL中的表
- user - 登录mysql的用户名
- password - 登录mysql的密码
- replace_query - 将INSERT INTO 查询是否替换为 REPLACE INTO 的标志,默认为0,不替换。当设置为1时,所有的insert into 语句更改为 replace into 语句。当插入的数据有重复主键数据时,此值为0默认报错,此值为1时,主键相同这条数据,默认替换成新插入的数据。
- on_duplicate_clause - 默认不使用。当插入数据主键相同时,可以指定只更新某列的数据为新插入的数据,对应于on duplicate key 后面的语句,其他的值保持不变,需要replace_query 设置为0。
2.2 示例
#在mysql 中创建一张表 t_ch,指定id为主键CREATE TABLE t_ch (id INT,NAME VARCHAR (255),age INT,PRIMARY KEY (id))#向表中增加一些数据insert into t_ch values (1,"张三",18),(2,"李四",19),(3,"王五",20)#在ClickHouse中创建MySQL引擎表 t_mysql_enginenode1 :) create table t_mysql_engine (:-] id UInt8,:-] name String,:-] age UInt8:-] )engine = MySQL('node2:3306','test','t_ch','root','123456');#查询ClickHouse表 t_mysql_engine 中的数据:node1 :) select * from t_mysql_engine;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 │└────┴──────┴─────┘#在ClickHouse中向表 t_mysql_engine中插入一条数据node1 :) insert into t_mysql_engine values (4,'马六','21');┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 21 │└───┴─────┴───┘#在ClickHouse中向表 t_mysql_engine中再插入一条数据,这里主键重复,报错。node1 :) insert into t_mysql_engine values (4,'田七','22');Exception: mysqlxx::BadQuery: Duplicate entry '4' for key'PRIMARY' (node2:3306).注意:在clickhouse 中 t_mysql_engine表不会在ClickHouse服务器节点上创建数据目录。2.3 测试 replace_query
#在mysql 中删除表 t_ch,重新创建,指定id为主键CREATE TABLE t_ch (id INT,NAME VARCHAR (255),age INT,PRIMARY KEY (id))#向表中增加一些数据insert into t_ch values (1,"张三",18),(2,"李四",19),(3,"王五",20)#在ClickHouse中删除MySQL引擎表 t_mysql_engine,重建node1 :) create table t_mysql_engine (:-] id UInt8,:-] name String,:-] age UInt8:-] )engine = MySQL('node2:3306','test','t_ch','root','123456',1);#查询ClickHouse表 t_mysql_engine 中的数据:node1 :) select * from t_mysql_engine;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 │└────┴──────┴─────┘#在ClickHouse中向表 t_mysql_engine中插入一条数据,主键重复。这里由于指定了replace_query = 1 ,所以当前主键数据会被替换成新插入的数据。node1 :) insert into t_mysql_engine values (3,'马六','21');#查询ClichHouse t_mysql_engine表数据node1 :) select * from t_mysql_engine;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 马六 │ 21 │└────┴──────┴─────┘2.4 测试 on_duplicate_clause
#在mysql 中删除表 t_ch,重新创建,指定id为主键CREATE TABLE t_ch (id INT,NAME VARCHAR (255),age INT,PRIMARY KEY (id))#向表中增加一些数据insert into t_ch values (1,"张三",18),(2,"李四",19),(3,"王五",20)#在ClickHouse中删除MySQL引擎表 t_mysql_engine,重建node1 :) create table t_mysql_engine (:-] id UInt8,:-] name String,:-] age UInt8:-] )engine = MySQL('node2:3306','test','t_ch','root','123456',0,'update age = values(age)');#查询ClickHouse表 t_mysql_engine 中的数据:node1 :) select * from t_mysql_engine;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 │└────┴──────┴─────┘#在ClickHouse 中向表 t_mysql_engine中插入一条数据node1 :) insert into t_mysql_engine values (4,'马六','21');┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 21 │└──┴─────┴────┘#在ClickHouse中向表 t_mysql_engine中插入一条数据,主键重复。node1 :) insert into t_mysql_engine values (4,'田七','100');#查询ClichHouse t_mysql_engine表数据node1 :) select * from t_mysql_engine;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 100 │└────┴──────┴─────┘3. Kafka
ClickHouse中还可以创建表指定为Kafka为表引擎,这样创建出的表可以查询到Kafka中的流数据。对应创建的表不会将数据存入ClickHouse中,这里这张kafka引擎表相当于一个消费者,消费Kafka中的数据,数据被查询过后,就不会再次被查询到。
3.1 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = Kafka()SETTINGSkafka_broker_list = 'host:port',kafka_topic_list = 'topic1,topic2,...',kafka_group_name = 'group_name',kafka_format = 'data_format'[,]- 对以上参数的解释:
- kafka_broker_list: 以逗号分隔的Kafka Broker节点列表
- kafka_topic_list : topic列表
- kafka_group_name : kafka消费者组名称
- kafka_format : Kafka中消息的格式,例如:JSONEachRow、CSV等等,具体参照https://clickhouse.tech/docs/en/interfaces/formats/。这里一般使用JSONEachRow格式数据,需要注意的是,json字段名称需要与创建的Kafka引擎表中字段的名称一样,才能正确的映射数据。
3.2 示例
#创建表 t_kafka_consumer ,使用Kafka表引擎node1 :) create table t_kafka_consumer (:-] id UInt8,:-] name String,:-] age UInt8:-] ) engine = Kafka():-] settings:-] kafka_broker_list='node1:9092,node2:9092,node3:9092',:-] kafka_topic_list='ck-topic',:-] kafka_group_name='group1',:-] kafka_format='JSONEachRow';#启动kafka,在kafka中创建ck-topic topic,并向此topic中生产以下数据:创建topic:kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic ck-topic --partitions 3 --replication-factor 3生产数据:kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic ck-topic生产数据如下:{"id":1,"name":"张三","age":18}{"id":2,"name":"李四","age":19}{"id":3,"name":"王五","age":20}{"id":4,"name":"马六","age":21}{"id":5,"name":"田七","age":22}#在ClickHouse中查询表 t_kafka_consumer数据,可以看到生产的数据node1 :) select * from t_kafka_consumer;┌─id─┬─name─┬─age─┐│ 2 │ 李四 │ 19 ││ 5 │ 田七 │ 22 ││ 1 │ 张三 │ 18 ││ 4 │ 马六 │ 21 ││ 3 │ 王五 │ 20 │└────┴──────┴─────┘注意:再次查看表 t_kafka_consumer数据 ,我们发现读取不到任何数据,这里对应的ClikcHouse中的Kafka引擎表,只是相当于是消费者,消费读取Kafka中的数据,数据被消费完成之后,不能再次查询到对应的数据。以上在ClickHouse中创建的Kafka引擎表 t_kafka_consumer 只是一个数据管道,当查询这张表时就是消费Kafka中的数据,数据被消费完成之后,不能再次被读取到。如果想将Kafka中topic中的数据持久化到ClickHouse中,我们可以通过物化视图方式访问Kafka中的数据,可以通过以下三个步骤完成将Kafka中数据持久化到ClickHouse中:
- 创建Kafka 引擎表,消费kafka中的数据。
- 再创建一张ClickHouse中普通引擎表,这张表面向终端用户查询使用。这里生产环境中经常创建MergeTree家族引擎表。
- 创建物化视图,将Kafka引擎表数据实时同步到终端用户查询表中。
3.3 示例
#在ClickHouse中创建 t_kafka_consumer2 表,使用Kafka引擎node1 :) create table t_kafka_consumer2 (:-] id UInt8,:-] name String,:-] age UInt8:-] ) engine = Kafka():-] settings:-] kafka_broker_list='node1:9092,node2:9092,node3:9092',:-] kafka_topic_list='ck-topic',:-] kafka_group_name='group1',:-] kafka_format='JSONEachRow';#在ClickHouse中创建一张终端用户查询使用的表,使用MergeTree引擎node1 :) create table t_kafka_mt(:-] id UInt8,:-] name String,:-] age UInt8:-] ) engine = MergeTree():-] order by id;#创建物化视图,同步表t_kafka_consumer2数据到t_kafka_mt中node1 :) create materialized view view_consumer to t_kafka_mt:-] as select id,name,age from t_kafka_consumer2;注意:物化视图在ClickHouse中也是存储数据的,create materialized view view_consumer to t_kafka_mt 语句是将物化视图view_consumer中的数据存储到到对应的t_kafka_mt 表中,这样同步的目的是如果不想继续同步kafka中的数据,可以直接删除物化视图即可。#向Kafka ck-topic中生产以下数据:生产数据:kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic ck-topic生产数据如下:{"id":1,"name":"张三","age":18}{"id":2,"name":"李四","age":19}{"id":3,"name":"王五","age":20}{"id":4,"name":"马六","age":21}{"id":5,"name":"田七","age":22}#查询表 t_kafka_mt中的数据,数据同步完成。node1 :) select * from t_kafka_mt;┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 ││ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 21 ││ 5 │ 田七 │ 22 │└────┴──────┴─────┘👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse(十八):Clickhouse Integration系列表引擎
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

日常BUG——代码提交到了本地但是没有push,删除了本地分支如何恢复
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 代码在本地提交了,但是没有push到远程,然后删除了本地的分支。想要恢…...
Markdown语法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Markdown语法目录 前言1.标题2.文本样式3.列表四.图片5.链接6.目录7.代码片7.表格8.注脚9.注释10.自定义列表11.LaTeX数学公式12.插入甘特图13.插入UML图14.插入Merimaid流程…...

vue3表格,编辑案例
index.vue <script setup> import { onMounted, ref } from "vue"; import Edit from "./components/Edit.vue"; import axios from "axios";// TODO: 列表渲染 const list ref([]); const getList async () > {const res await ax…...
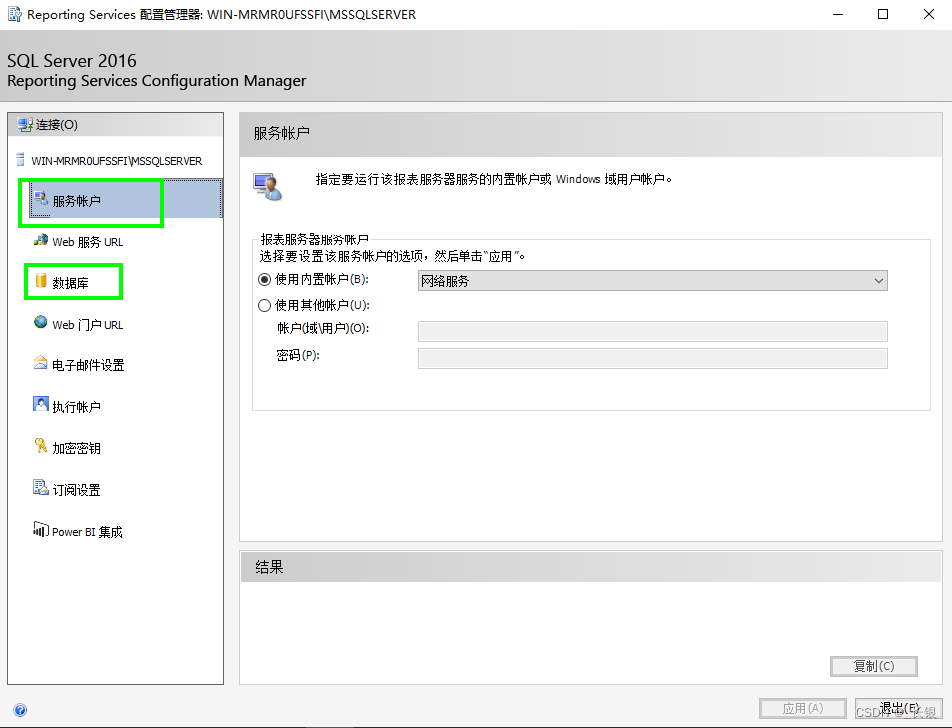
SQL Server Reporting Services 报错:报表服务器无法访问服务帐户的私钥
解决这个问题,有小伙伴提到可以使用命令 exec DeleteEncryptedContent 但这对这边的环境时行不通的,我在【服务账户】的配置和【数据库】的配置中到使用了域账户,试了几次都不行。改成使用内置账户就好了。具体原因还没扒拉(欢迎…...
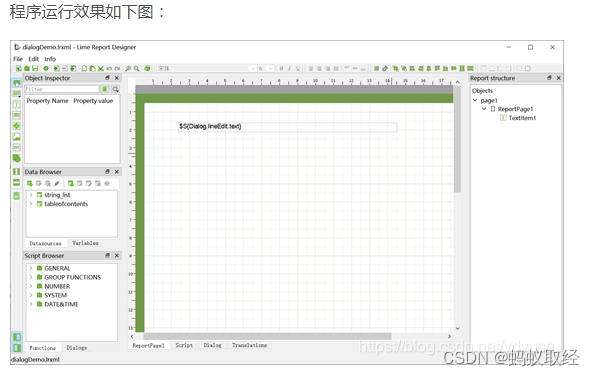
QT报表Limereport v1.5.35编译及使用
1、编译说明 下载后QT CREATER中打开limereport.pro然后直接编译就可以了。编译后结果如下图: 一次编译可以得到库文件和DEMO执行程序。 2、使用说明 拷贝如下图编译后的lib目录到自己的工程目录中。 release版本的重新命名为librelease. PRO文件中配置 QT …...

互联网发展历程:从中继器口不够到集线器的引入
互联网的发展,就像一场不断演进的技术盛宴,每一步的变革都在推动着我们的世界向前。然而,在网络的早期,一项重要的技术问题曾困扰着人们:当中继器的接口数量不足时,如何连接更多的设备?这时&…...

vue+flask基于知识图谱的抑郁症问答系统
vueflask基于知识图谱的抑郁症问答系统 抑郁症已经成为当今社会刻不容缓需要解决的问题,抑郁症的危害主要有以下几种:1.可导致病人情绪低落:抑郁症的病人长期处于悲观的状态中,感觉不到快乐,总是高兴不起来。2.可导致工…...

操作格子---算法集
问题描述 有 n 个格子,从左到右放成一排,编号为 1-n。 共有 m 次操作,有 3 种操作类型: 1.修改一个格子的权值。 2.求连续一段格子权值和。 3.求连续一段格子的最大值。 对于每个 2、3 操作输出你所求出的结果。 输入格式 第一行 …...

科研绘图chapter1:绘图原则与配色基础
本系列会持续更新,主要参考datawhale的开源课程。详见: https://github.com/datawhalechina/paper-chart-tutorial 文章目录 1.1 科研论文配图的绘制基础1.2 科研论文配图的配色基础1.2.1 配色模式1.2.2 色环配色原则1.3 配色工具/网站 1.1 科研论文配图…...

Linux下grep通配容易混淆的地方
先上一张图: 我希望找到某个版本为8的一个libXXX.8XXX.so ,那么应该怎么写呢? 先看这种写法对不对: 是不是结果出乎你的意料之外? 那么我们来看一下规则: 这里的 "*" 表示匹配前一个字符的零个或多个 于是我们就不难理解了: lib*8*.so 表示 包…...

WebRTC音视频通话-WebRTC本地视频通话使用ossrs服务搭建
iOS开发-ossrs服务WebRTC本地视频通话服务搭建 之前开发中使用到了ossrs,这里记录一下ossrs支持的WebRTC本地服务搭建。 一、ossrs是什么? ossrs是什么呢? SRS(Simple Realtime Server)是一个简单高效的实时视频服务器,支持RTM…...

基于SpringBoot和Freemarker的页面静态化
页面静态化能够缓轻数据库的压力,还能提高页面的并发能力,但是网页静态化是比较适合大规模且相对变化不太频繁的数据。 页面静态化在实际应用中还是比较常见的,比如博客详情页、新闻网站或者文章类网站等等。这类数据变化不频繁比较适合静态…...

给软件增加license
搞计算机的,都知道软件license,版权,著作权等。在商业软件中,常用的模式是一年一付,或者五年一付,即软件的使用权不是无限年限的,在设计软件的时候,开发者就需要考虑这个问题。要实现这个功能&a…...

vue中实现订单支付倒计时
需求 创建订单后15分钟内进行支付,否则订单取消。 实现 思路: 获取当前时间和支付超时时间(在创建时间的基础上增加15分钟即为超时时间,倒计时多久根据自己的实际需求,这里为15分钟),支付超时…...

途乐证券-新手炒股快速入门教程?
随着互联网和金融商场的不断发展,越来越多的人开端重视股票商场。但是对于股市新手来说,怎么快速入门炒股成为了一个困扰他们的难题。以下从多个角度分析,提供一份新手炒股快速入门教程。 1. 了解根本概念 首要,股市新手需求了解…...

【冒泡排序及其优化】
冒泡排序及其优化 冒泡排序核心思想 冒泡排序的核⼼思想就是:两两相邻的元素进⾏⽐较 1题目举例 给出一个倒序数组:arr[10]{9,8,7,6,5,4,3,2,1,0} 请排序按小到大输出 1.1题目分析 这是一个完全倒序的数组,所以确定冒泡排序的趟数࿰…...

TypeScript 泛型的深入解析与基本使用
系列文章目录 文章目录 系列文章目录前言一、泛型的概念二、泛型函数三、泛型类四、泛型接口五、泛型约束总结 前言 泛型是TypeScript中的一个重要概念,它允许我们在定义函数、类或接口时使用参数化类型,增强了代码的灵活性和重用性。本文将深入探讨泛型…...

【Terraform学习】保护敏感变量(Terraform配置语言学习)
实验步骤 创建 EC2 IAM 角色 导航到IAM 在左侧菜单中,单击角色 。单击创建角色该按钮以创建新的 IAM 角色。 在创建角色部分,为角色选择可信实体类型: AWS 服务 使用案例:EC2 单击下一步 添加权限:现在,您可以看到…...

海国图志#1:这一周难忘瞬间,吐血整理,不得不看
这里记录每周值得分享的新闻大图,周日发布。 文章以高清大图呈现,解说以汉语为主,英语为辅,英语句子均来自NYTimes、WSJ、The Guardian等权威媒体原刊。 存档时段:20230731-20230806 乌克兰,波罗当卡 一名妇…...

未来趋势洞察:后端开发技术的前沿动态与发展方向
在数字化浪潮席卷全球的今天,后端开发作为支撑各类应用的核心力量,正经历着前所未有的变革。随着云计算、人工智能、物联网等新兴技术的迅猛发展,后端开发技术也在不断演进,呈现出一系列新的趋势和方向。本文将深入探讨未来后端开…...

如何让孩子从零开始学习Python编程?BBC micro:bit实战指南
如何让孩子从零开始学习Python编程?BBC micro:bit实战指南 【免费下载链接】Python-For-Kids A FREE comprehensive online Python development tutorial FOR KIDS utilizing an official BBC micro:bit Development Board going step-by-step into the world of Py…...

ComfyUI-Custom-Scripts自动完成功能完整指南:提升AI绘画效率的终极解决方案
ComfyUI-Custom-Scripts自动完成功能完整指南:提升AI绘画效率的终极解决方案 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custo…...

Bi-LSTM vs CNN-BiLSTM:实战对比哪个模型更适合你的时间序列预测任务?
Bi-LSTM与CNN-BiLSTM实战抉择:时间序列预测的黄金选择法则当面对时间序列预测任务时,选择正确的模型架构往往能决定项目的成败。Bi-LSTM和CNN-BiLSTM作为两种主流的深度学习模型,各自在特定场景下展现出独特优势。本文将带您深入剖析这两种模…...

qmcdump完整指南:3步轻松解密QQ音乐加密文件
qmcdump完整指南:3步轻松解密QQ音乐加密文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是一款简…...

ros2_control 代码架构分析
ros2_control 代码架构分析 一、整体框架 1.1 代码框架 ├── ros2_control/ # ★ 框架本体(vendored,jazzy 分支) │ ├── controller_manager/ # 核心运行时:ros2_control_node │ ├── hardware_interface/ # 硬件抽象 +…...
:含风险预判矩阵、利益相关方触达热力图与监管审计应答话术库)
谷歌内部CSR策划SOP首次流出(非公开版):含风险预判矩阵、利益相关方触达热力图与监管审计应答话术库
更多请点击: https://codechina.net 第一章:Gemini CSR活动策划的底层逻辑与战略定位 Gemini CSR(Corporate Social Responsibility)活动并非孤立的品牌传播动作,而是深度嵌入企业技术价值观与长期可持续发展框架的战…...

使用Taotoken CLI工具一键配置多开发环境与工具密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境与工具密钥 基础教程类,面向需要在不同机器或为不同工具(如OpenCl…...

Nodejs后端服务集成Taotoken多模型API的实践路径
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs后端服务集成Taotoken多模型API的实践路径 对于Node.js后端开发者而言,将大模型能力集成到现有应用中是常见的需…...

免费开源!NVIDIA显卡色彩校准终极方案:novideo_srgb完整指南
免费开源!NVIDIA显卡色彩校准终极方案:novideo_srgb完整指南 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/no…...