kafka使用心得(二)
kafka进阶
消息顺序保证
Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序。
消费者和分区的对应关系
参考这篇文章。
分区文件
一个分区对应着log.dirs下的一个子目录,例如主题test1的0号分区,其对应目录的内容为:
ls test1-0
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex
分别有日志文件和索引文件。
Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是那些没有建立索引的Message也不能一次定位到其在数据文件中的位置,从而需要做一次局部的顺序扫描,但是这次顺序扫描的范围就很小了。
总的来说,log+index的设计方式类似于hdfs上的MapFile,MapFile也是通过“定位到大致位置”+“局部顺序扫描”来快速定位的。
分区副本
分区有多个副本,其中一个是leader副本,leader副本通过特定的策略选举产生,其他是follower副本。读写操作均由leader副本处理,follower副本仅仅是从leader副本处把新的消息同步过来,这个过程有一定延迟,所以follower副本的消息可能略少于leader副本,这在一定阈值范围内是可以容忍的。
kafka的主从副本机制与mysql的对比:
1、由于只从leader副本处读写,kafka的分区副本并不支持负载均衡,而纯粹是一种高可靠设计。mysql的slave是可以分摊查询压力的。由此也可看出,kafka分区副本的一致性保证要强于mysql的读写分离。
2、为保证生产者的效率,leader和follower之间是异步同步,不会因为某个follower太慢拖慢整个集群。这点跟mysql的master/slave异步同步是相似的。
3、leader宕机,会从follower(follower副本一般会放到不同的机器上)中选举新的leader,可以认为是不存在单点问题的。mysql不会从slave中选举新的master,而是通过双主双活(近似于主备机)措施来保证master可用。
消费者位置(offset)
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在Kafka中这个位置信息有个专门的术语:位移(offset)。很多消息引擎都把这部分信息保存在服务器端(broker端)。这样做的好处当然是实现简单,但会有三个主要的问题:
- broker从此变成有状态的,会影响伸缩性;
- 需要引入应答机制(acknowledgement)来确认消费成功。
- 由于要保存很多consumer的offset信息,必然引入复杂的数据结构,造成资源浪费。
而Kafka选择了不同的方式:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。
老版本(0.8及之前)的位移是提交到zookeeper中的,目录结构是:/consumers/<group.id>/offsets//,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此kafka提供了另一种解决方案:增加consumer offsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息,结构大概是:
group id + topic-partition + offset
我们可以使用bin/kafka-consumer-groups.sh 来查看offset。
- 列出基于java consumer API访问的所有consumer group
./kafka-consumer-groups.sh --bootstrap-server xx.xx.xx.xx:9092 --list
列出基于zk访问的consumer group(kafka的最新版本里已没有–zookeeper选项了):
./kafka-consumer-groups.sh --zookeeper localhost:2181 --list
- 查看某consumer group的offset
./kafka-consumer-groups.sh --bootstrap-server xx.xx.xx.xx:9092 --describe --group uniquelip1
输出是这样的:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID
mykafka 0 0 0 0 -
heyHaha1 0 1974 30887 28913 -
记录了该consumer组commit过(注意不是消费过,而是commit过)的各topic下分区的当前位置(CURRENT-OFFSET)及最后一个消息的位置(LOG-END-OFFSET,简称LEO)
enable.auto.commit
特别注意:enable.auto.commit默认是开启的!所以,如果要手工控制offset,必须显式关闭:
props.put("enable.auto.commit", "false");
建议显式关闭,因为commit动作必须在消息真正被业务消费之后才能执行,否则在异常情况下可能导致消息丢失。比如提前commit,但此刻消息只处理了部分,这时进程core掉,即使随后进程重启,由于offset已被commit成最新的值new-pos,new-pos之前可能有部分消息已经无法处理了。
auto.offset.reset值含义解释
三个值:earliest、latest、none
earliest
当各分区下有已提交的offset(即CURRENT-OFFSET有效,下同)时,从提交的offset开始消费;
无提交的offset时(例如该topic尚未被当前consumer组消费),从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;
无提交的offset时,等待消费新产生的数据,对已存在的历史数据会置之不理。注意若关闭了enable.auto.commit,此时查看的offset的位置如下:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
test4 0 - 5 - consumer-1-b4c5c879-c649-4198-9e4c-13735e9eaab4 /10.180.53.159 consumer-1
我们发现CURRENT-OFFSET的值是-,并非一个有效值。
none
topic各分区都存在已提交的offset时,从offset后开始消费;
只要有一个分区不存在已提交的offset,则抛出异常:
Undefined offset with no reset policy for partition: test4-0
经测试,auto.offset.reset默认是latest。
offset小结
offset是一个客户端的概念,而非服务端概念,每个consumer组都有自己独立的offset,互不干扰,只是offset信息会存在服务端的磁盘里而已。
生产者已经往某个topic插入数据,但consumer却从该topic取不到数据,有两种可能:
1、CURRENT-OFFSET等于LEO,说明该consumer所在的组已经消费过消息了,看看是否忽略了“enable.auto.commit默认是开启”的情况;
2、consumer访问的是一个之前未访问过的topic,该topic有历史数据但无新的数据到来,由于auto.offset.reset默认是latest,consumer会挂住等待新的消息。
enable.auto.commit
默认为true,kafka后台会每隔5s(默认值,可以通过auto_commit_interval_ms修改)自动提交一次offset。所以,如果用auto commit选项,消费和commit之间实际上是有延迟的。
实际使用中,consumer定期poll,且auto.offset.reset=latest,且开启了auto commit,则有可能在消费之后,commit之前,consumer group就会因没有初始offset信息而被kafka后台干掉,从而导致后续每次都poll不到消息。为解决该问题,此时应该手工commit。
特别说明一下,如果consumer group没有消耗任何消息就显式commit,且auto.offset.reset=latest,此时CURRENT-OFFSET会被设置为LEO。
consumer group
consumer构成的组。组中的consumer会被分配到不同的partition上。因此,一条消息只会被Consumer Group中的一个Consumer消费。
关于producer
producer的send方法是异步的,它会将ProducerRecord缓存起来,然后由单独的sender线程批量发送。
KafkaProducer是线程安全的,且按照官方文档,多线程共享一个producer实例性能更好。
我们看KafkaProducer有一个close方法,其中所做的事情包含:
将缓存里的消息清空;
关闭sender线程。
所以,KafkaProducer其实是一个运算资源的集合体。
性能测试脚本(0.8版本)
./kafka-producer-perf-test.sh --broker-list localhost:9092 --messages 1000000 --topics test1 --threads 6 --message-size 1000 --batch-size 200 --compression-codec 0
参数说明:
--messages <Long: count> The number of messages to send or consume (default: 9223372036854775807) --threads <Integer: number of threads> Number of sending threads. (default: 1)可令线程数等于分区数--message-size <Integer: size> The size of each message. (default: 100) --batch-size <Integer: size> Number of messages to write in a single batch. (default: 200) --compression-codec <Integer: If set, messages are sent compressed supported codec: NoCompressionCodec (default: 0) as 0, GZIPCompressionCodec as 1, SnappyCompressionCodec as 2, LZ4CompressionCodec as 3> kafka调优
producer总体架构
有几点需注意:
- producer的send只是把消息放到发送缓存里,会有单独的发送线程把消息从socket发送给kafka服务器,这也说明producer必然是线程安全的;
- 发送缓存使用了内存池机制,它维护了一个freelist,里面都是batch.size大小的内存块,一旦涉及内存分配或回收,只是简单的从这个freelist里pop或push内存块,几乎不涉及java堆分配,自然也无需gc;
- 发送线程会等到一个batch.size大小的内存块被消息填满才发送,这样可提升produce效率。一个内存块对应一个分区,所以同一时间,可能有多个内存块从socket发送给不同的节点;
- 整个发送缓存的大小由buffer.memory参数指定。
produce调优总结
我们看produce的“远端执行”性能数据,有几个结论:
- producer建议做成单例在多线程间共享,多个producer实例会将发送的消息总量分摊掉,造成的结果是:一方面由于多producer的分摊,消息不能及时发送(因为每个producer有batch.size的约束),另一方面多个producer的消息可能堆在一起发送,产生大量的网络IO。
- 指示发送缓存大小的batch.size不能设置太小,否则严重影响发送效率。这点可跟写文件时的进程内缓存做一类比,实际上batch.size的默认值为16k,也是诸实现中写文件时进程内缓存的常用大小(一般是8k或16k)。
- acks=1,表示仅等待分区的leader副本返回,而非所有的isr副本返回,虽然效率提升了,但可能存在单点风险。
- compression.type=snappy或lz4可极大提升produce效率,压缩之后,意味着相同的batch.size内存块可以发送更多的消息,提升了吞吐量。
顺带说一下压缩的问题,kafka producer支持三种压缩格式:
gzip、snappy和lz4
压缩比方面,三者的关系是:
gzip > lz4 > snappy
gzip压缩比最高。
压缩解压效率方面则反过来:
gzip < lz4 < snappy
snappy压缩解压效率最高。
其中,gzip是jdk自带的,lz4 是kafka自带的,snappy则需要额外的snappy-java包才可支持。lz4和snappy压缩库的协议都是apache 2.0,商业友好。
还有一些可能的性能提升点:
- 控制消息的大小,避免超过batch.size的值。因为producer内部有一个BufferPool,消息所需内存空间的分配不是用new,而是分配自该pool,从而避免gc。一旦消息大小超过batch.size,意味着无法使用pool,只能new,从而带来gc开销。
buffer.memory和batch.size
我们在producer config里指定的两个参数:
props.put("buffer.memory", 33554432);
props.put("batch.size", 16384);
最终是用于构造BufferPool:
//totalSize就是buffer.memory, batchSize就是batch.size
this.free = new BufferPool(totalSize, batchSize, metrics, time, metricGrpName);
则可知buffer.memory就是缓存池的内存总量,而batchSize则是缓存池里每个内存块的大小,这些内存块构成了一个free链表。BufferPool.allocate里计算可用空间的几行代码证明了这一点:
//poolableSize就是batch.size,size是待分配的大小
int freeListSize = this.free.size() * this.poolableSize;
//availableMemory是原始的、还未分配过的内存量
if (this.availableMemory + freeListSize >= size) {// we have enough unallocated or pooled memory to immediately// satisfy the requestfreeUp(size);this.availableMemory -= size;......return ByteBuffer.allocate(size);
}
这里有个疑问,似乎producer将batch.size作为标准大小,如果待分配的内存量不是这个标准值,就new之,关于这点,也可从deallocate实现里取得印证:
public void deallocate(ByteBuffer buffer, int size) {lock.lock();try {if (size == this.poolableSize && size == buffer.capacity()) {buffer.clear();this.free.add(buffer);} else {this.availableMemory += size;}Condition moreMem = this.waiters.peekFirst();if (moreMem != null)moreMem.signal();} finally {lock.unlock();}}
只有待回收的内存量恰好等于batch.size才会放入free队列,供后续复用。如不等的话,只是简单的增加availableMemory的大小,实际走的还是jvm的gc释放流程。
压缩
kafka自带支持的是gzip和lz4压缩,snappy要额外的库支持,这是MemoryRecordsBuilder类里的相关代码:
private static MemoizingConstructorSupplier snappyOutputStreamSupplier = new MemoizingConstructorSupplier(new ConstructorSupplier() {@Overridepublic Constructor get() throws ClassNotFoundException, NoSuchMethodException {return Class.forName("org.xerial.snappy.SnappyOutputStream").getConstructor(OutputStream.class, Integer.TYPE);}});private static MemoizingConstructorSupplier snappyInputStreamSupplier = new MemoizingConstructorSupplier(new ConstructorSupplier() {@Overridepublic Constructor get() throws ClassNotFoundException, NoSuchMethodException {return Class.forName("org.xerial.snappy.SnappyInputStream").getConstructor(InputStream.class);}});
其中,snappyOutputStreamSupplier用于producer的压缩,snappyInputStreamSupplier则用于consumer的解压。
关于几种压缩算法,有人做了验证,结论如下:
1)不管对于大量数据或是少量数据,压缩性能snappy都是最佳,只是在数据量大的情况下,压缩性能略慢于lz4。通过对比还是可以发现snappy要优于lz4,难怪hadoop选用snappy。
2)从压缩比来看无疑xz是最出色的,而且解压速度相对于压缩比来说也是相当可观,就是压缩太慢。追加高压缩比对解压速度有要求的可以使用看看。(xz和common xz其实是一样的)
3)综合来看jdk gzip和common zip不论是压缩比和解压性能都不错,对于解压和压缩比有要求的可以使用,但仔细分析发现common gzip更善于处理大数据量的压缩。
4)最后,bzip2压缩比还可以,但是压缩和解压速度都偏慢。
consumer总体架构
总体结构比较简单,大致流程是:
consumer先通过Coordinator与服务端交互完成rebalance操作(多个consumer构成一个ConsumerGroup,rebalance相当于组内的负载均衡),rebalance之后,哪些分区分配给哪个consumer就确定了,这时fetcher要准备从服务端拿消息了,但还有两个关键参数要告诉服务端:一是分区上次提交的offset,即我要从哪个位置开始读;二是我最多要读多大数据量。前者由Coordinator从服务端的offset topic里获得,后者则由max.partition.fetch.bytes参数指定。
consumer调优总结
测试下来有几点:
- max.partition.fetch.bytes并非越大越好,需均衡考虑producer的写入速度及网络IO的开销,设置过大会导致等待时间较长且一次网络传输量较大, 实测使用默认值(1M)较好。
- 合理设置“心跳超时”和“连续poll调用间隔超时”,kafka 0.10.1版本之前,这两种监测是用同一个参数session.timeout.ms表示,0.10.1之后则分别用session.timeout.ms(心跳超时)和max.poll.interval.ms(连续poll调用间隔超时)表示。0.10.1版本之后,我们可将session.timeout.ms设小点(默认是10s),确保服务端尽快监测到consumer挂掉,同时可将max.poll.interval.ms设大点(默认300s),争取更多的消息处理时间。但0.10.1版本之前,我们不能为了更长的处理时间而把session.timeout.ms调的过大,那样服务端无法快速监测到consumer挂掉的情况,反而导致费时甚久的消息处理白做了。
- connections.max.idle.ms是连接空闲关闭时间,但consumer似乎有重连机制,即使我们故意延迟超出这个时间,依然可以poll出数据;
max.partition.fetch.bytes
consumer向kafka server申请数据,需构造FetchRequest,这里有两个关键参数要告诉服务端:一是分区offset,即我要从哪个位置开始读;二是我要读多大数据量。前者可从kafka的offset topic里获得,我们可以得到最近一次consumer提交的该分区的位置。后者就是由max.partition.fetch.bytes指定。涉及的代码是:
Fetcher.javaprivate Map<Node, FetchRequest.Builder> createFetchRequests() {// 获得kafka集群的信息Cluster cluster = metadata.fetch();Map<Node, LinkedHashMap<TopicPartition, FetchRequest.PartitionData>> fetchable = new LinkedHashMap<>();for (TopicPartition partition : fetchablePartitions()) {//找到leader,因为只有leader副本支持读写Node node = cluster.leaderFor(partition);if (node == null) {metadata.requestUpdate();} else if (this.client.pendingRequestCount(node) == 0) {// if there is a leader and no in-flight requests, issue a new fetchLinkedHashMap<TopicPartition, FetchRequest.PartitionData> fetch = fetchable.get(node);if (fetch == null) {fetch = new LinkedHashMap<>();fetchable.put(node, fetch);}//得到该分区上次commit的位置,并将其作为本次fetch的起始offset//fetchSize就是max.partition.fetch.bytes,//表示每次fetch的最大字节数long position = this.subscriptions.position(partition);fetch.put(partition, new FetchRequest.PartitionData(position, this.fetchSize));
session.timeout.ms和max.poll.interval.ms
两者的差异stackoverflow上有帖子解释,总结下来有几点:
- kafka consumer有两种超时检查,一是心跳监测、二是连续poll调用间隔监测,前者预防consumer挂掉(包括网络断链),后者预防consumer处理的太慢。
- kafka 0.10.1版本之前,这两种监测是用一个参数session.timeout.ms表示的,0.10.1之后则分别用session.timeout.ms(心跳监测超时)和max.poll.interval.ms(连续poll调用间隔超时)表示。这样修改的原因是,保证尽快检测到consumer挂掉的同时允许更长的消息处理耗时。修改的方法则是为心跳监测单独起一个线程,跟消息处理线程隔离开。
为何要有两种超时监测机制?我估计还是kafka的ConsumerGroup支持组内负载均衡的缘故,上述两种超时间隔一旦达到,服务端就认为该consumer会拖慢整体性能(无论挂掉还是消息处理慢都会拖整个ConsumerGroup的后腿),就会从ConsumerGroup中移除该consumer,并启动consumer rebalance(注意,rebalance由服务端触发,且视情况,有必要才触发),但如果仅仅是消息处理太慢,而非网络连接问题,我们不排除rebalance后重新选择旧的consumer的可能。
下面是在0.10.2下触发"poll调用间隔超时"的代码,我们设置poll查询间隔超时为10s:
private static KafkaConsumer<String, String> getConsumer(boolean fromBeginning){......Properties props = new Properties();props.put("bootstrap.servers", ip + ":9092");props.put("group.id", "uniquelip1");props.put("enable.auto.commit", "false");props.put("session.timeout.ms", 10000);props.put("max.poll.interval.ms", 10000); //设置poll查询间隔超时为10sprops.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);return consumer;}
然后强行在poll和commit间sleep 20s,从而触发“poll调用间隔超时”:
private static void consume(String topic, int expectNum){boolean hasPrinted = false;try (KafkaConsumer<String, String> consumer = getConsumer(true)){int total = 0;consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener(){public void onPartitionsRevoked(Collection<TopicPartition> partitions){LOGGER.info("before rebalance,after consumer poll, topic:{}",partitions.stream().map(x -> x.toString()).collect(Collectors.joining(";")));}public void onPartitionsAssigned(Collection<TopicPartition> partitions){LOGGER.info("after rebalance,before consumer poll, topic:{}",partitions.stream().map(x -> x.toString()).collect(Collectors.joining(";")));}});while (total < expectNum){ConsumerRecords<String, String> records = consumer.poll(1000);total += records.count();LOGGER.info("consume {} msgs now", total);if (!hasPrinted && records.count() > 0){System.out.println(records.iterator().next().value());hasPrinted = true;}Util.safeSleep(20000);LOGGER.info("sleep 20s");try{consumer.commitSync();}catch(Exception e){e.printStackTrace(new LogPrintWriter(LOGGER));}}System.out.println("total " + total + " msgs consumed");}}
打印错误如下:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the timebetween subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeo
ut or by reducing the maximum size of batches returned in poll() with max.poll.records.
kafka 0.9版本下报的错则是:
commit offsets exception:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured session.timeout.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
我们看到这两段信息就是一字之差,从0.9的“This means that the time between subsequent calls to poll() was longer than the configured session.timeout.ms”改为0.10的“This means that the time
between subsequent calls to poll() was longer than the configured max.poll.interval.ms”。从侧面也印证了前面的说法。
注意,我们的测试代码为consumer增加了ConsumerRebalanceListener,可以侦测到服务端的consumer rebalance,日志中会反复打印如下信息:
before rebalance,after consumer poll, topic:test1-0;test1-5;test1-2;test1-1;test1-4;test1-3after rebalance,before consumer poll, topic:test1-0;test1-5;test1-2;test1-1;test1-4;test1-3
而且我们的consumer在commit失败后,下一次poll仍能查出数据(仍是老的数据,因commit失败了),说明旧的consumer依然被服务端rebalance到了,只要随后的消息处理不超时,consumer仍能正常的消费后续消息。
还有一个疑问,既然是“poll调用间隔超时”,那为何会在commit时抛出异常而不是下次poll之时呢?我们注意到rebalance动作其实是发生在commit之前的(其实是在consumer的poll函数里),这点从日志可以看出:
2017-12-25 14:31:13 [ main ] - [ INFO ] Revoking previously assigned partitions [test1-0, test1-5, test1-2, test1-1, test1-4, test1-3] for group uniquelip1
2017-12-25 14:31:13 [ main ] - [ INFO ] before rebalance,after consumer poll, topic:test1-0;test1-5;test1-2;test1-1;test1-4;test1-3
2017-12-25 14:31:13 [ main ] - [ INFO ] (Re-)joining group uniquelip1
2017-12-25 14:31:13 [ main ] - [ INFO ] Successfully joined group uniquelip1 with generation 21
2017-12-25 14:31:13 [ main ] - [ INFO ] Setting newly assigned partitions [test1-0, test1-5, test1-2, test1-1, test1-4, test1-3] for group uniquelip1
2017-12-25 14:31:13 [ main ] - [ INFO ] after rebalance,before consumer poll, topic:test1-0;test1-5;test1-2;test1-1;test1-4;test1-3
2017-12-25 14:31:13 [ main ] - [ INFO ] consume 2500 msgs now
2017-12-25 14:31:33 [ main ] - [ INFO ] sleep 20s
2017-12-25 14:31:33 [ main ] - [ ERROR ] org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the timebetween subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeo
ut or by reducing the maximum size of batches returned in poll() with max.poll.records.
2017-12-25 14:31:33 [ main ] - [ ERROR ] at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.sendOffsetCommitRequest(ConsumerCoordinator.java:698)
2017-12-25 14:31:33 [ main ] - [ ERROR ] at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.commitOffsetsSync(ConsumerCoordinator.java:577)
2017-12-25 14:31:33 [ main ] - [ ERROR ] at org.apache.kafka.clients.consumer.KafkaConsumer.commitSync(KafkaConsumer.java:1091)
2017-12-25 14:31:33 [ main ] - [ ERROR ] at KafkaTest.consume(KafkaTest.java:229)
2017-12-25 14:31:33 [ main ] - [ ERROR ] at KafkaTest.main(KafkaTest.java:70)
也就是说commit时,server的rebalance已经发生了,此时consumer和server的状态已经不一致了,在server看来,你这个consumer干的太慢,我早就把你的活分给其他consumer,这部分活就不让你干了,如果你继续commit offset,有可能导致多个consumer同时操作同一个分区,这是kafka的基本原则所不允许的,所以server端只能在commit时报错,而不会容忍你的错误到下一次的poll。从最终的结果看,commit失败,意味着我这个consumer所做的一切消息处理都白做了。
如果我们已经合理的设置了"连续poll调用间隔超时"的值,接下来只能通过:
1、控制consume速度(通过调小max.poll.records);
2、优化消息处理效率
这两种方法来保证消息处理耗时在"连续poll调用间隔超时"之内了。
但,如果这样做还不能完全避免“连续poll调用超时”,又该如何应对?
首先,由于"连续poll调用间隔超时"必然导致服务端rebalance,原本由consumer A处理的partition很可能被分配给其他的consumer,这会导致consumerA commit失败(一个分区同一时间只能被ConsumerGroup中的一个consumer消费),则consumer A已经处理尚未commit的那部分消息也会被其他consumer重复处理。如果我们没法将“消息处理”+“offset commit”放在一个事务中,通过事务回滚来回退消息,就只能依赖业务侧来提供去重机制(例如全局唯一主键)或者干脆允许消息重复。
同时,我们也要考虑最极端的情况,即消息处理出现大量积压,导致反复出现“连续poll调用超时”,此时建议调用consumer.unsubscribe让consumer退订,停止从kafka拿消息,直到消息积压的情况有所改善,再重新订阅拿消息。
相关文章:
)
kafka使用心得(二)
kafka进阶 消息顺序保证 Kafka它在设计的时候就是要保证分区下消息的顺序,也就是说消息在一个分区中的顺序是怎样的,那么消费者在消费的时候看到的就是什么样的顺序。 消费者和分区的对应关系 参考这篇文章。 分区文件 一个分区对应着log.dirs下的…...

(二)掌握最基本的Linux服务器用法——Linux下简单的C/C++ 程序、项目编译
1、静态库与动态库 静态库(Static Library):静态库是编译后的库文件,其中的代码在编译时被链接到程序中,因此它会与程序一起形成一个独立的可执行文件。每个使用静态库的程序都会有自己的库的副本,这可能会导致内存浪费。常用后缀…...
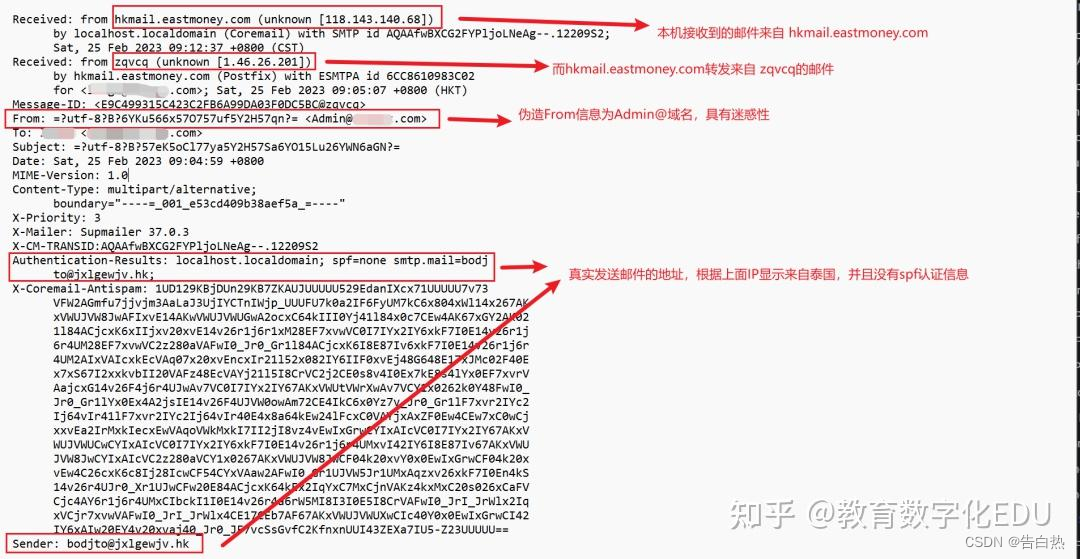
应急响应-钓鱼邮件的处理思路溯源及其反制
0x00 钓鱼邮件的危害 1.窃取用户敏感信息,制作虚假网址,诱导用户输入敏感的账户信息后记录 2.携带病毒木马程序,诱导安装,使电脑中病毒木马等 3.挖矿病毒的传输,勒索病毒的传输等等 0x01 有指纹的钓鱼邮件的溯源处理…...
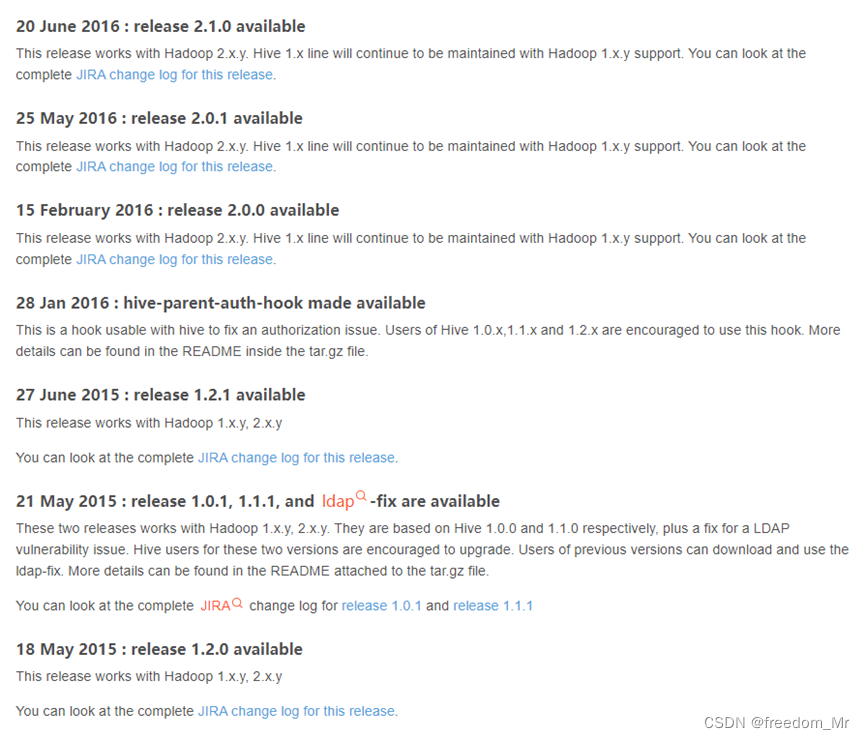
Hadoop Hbase Hive 版本对照一览
这里写目录标题 一、Hadoop 与 Hbase 版本对照二、Hadoop 与 Hive 版本对照 官网内容记录,仅供参考 一、Hadoop 与 Hbase 版本对照 二、Hadoop 与 Hive 版本对照...

Postgresql 基础使用语法
1.数据类型 1.数字类型 类型 长度 说明 范围 与其他db比较 Smallint 2字节 小范围整数类型 32768到32767 integer 4字节 整数类型 2147483648到2147483647 bigint 8字节 大范围整数类型 -9233203685477808到9223203685477807 decimal 可变 用户指定 精度小…...

Qt 之 QDebug,QString
文章目录 前言一、QDebug二、QString总结 前言 一、QDebug QDebug是Qt中用于进行调试和输出日志的类。它提供了一种便捷的方式来输出各种类型的数据,并可轻松地与流式输出一起使用,方便调试和查看程序的运行情况。 引入QDebug: 在使用QDebug…...

【C++】面试题
1、都说c是面向对象的语言,面向对象的三个特性能 [展开] 介绍一下吗? 封装:封装是一种集中管理的思想,把内部的数据和实现方法组合在一起,并且不对外暴漏内部的数据和实现方法,只对外提供几个接口来完成函数…...
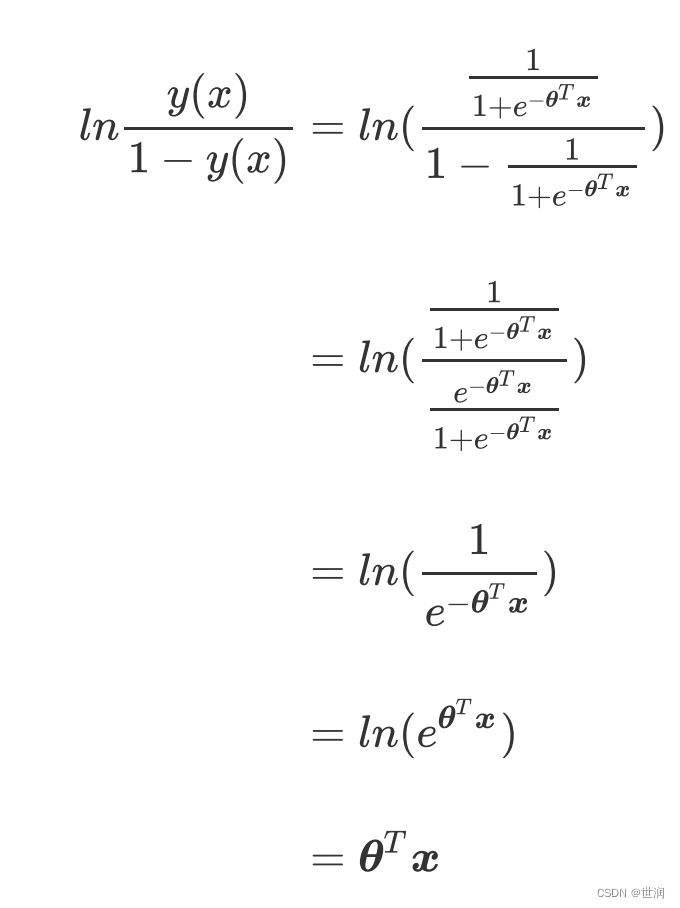
机器学习算法之-逻辑回归(1)
什么是回归 回归树,随机森林的回归,无一例外他们都是区别于分类算法们,用来处理和预测连续型标签的算法。然而逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问…...

JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译) java多线程面试问题 1. 进程和线程之间有什么不同? 一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用。而线程是在进程中执行的一个任务。Java运行环境是一个包含了不同的类和程序…...
正中优配:2023新股上市涨跌幅规则?新股上市涨跌幅限制为几天?
A股与美股不同,股票存在涨跌幅限制,那么,2023新股上市涨跌幅规矩?新股上市涨跌幅限制为几天?下面正中优配为我们预备了相关内容,以供参阅。 2023年新股上市涨跌幅存在以下规矩: 1、主板初次公开…...

如何查看线程在哪个cpu核上
1、ps -eLF查看PSR值 2、 taskset -pc $pid(进程/线程) 参考链接:https://blog.csdn.net/test1280/article/details/87993669...
【Vue前端】设置标题用于SEO优化
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 1.vue全局配置2.创建并暴露getPageTitle方法3.通过全局前置守卫设置title4.页面上引用title5.项目使用中英文翻译,title失效 1.vu…...

maven install
maven install maven 的 install 命令,当我们的一个 maven 模块想要依赖其他目录下的模块时,直接添加会找不到对应的模块,只需要找到需要引入的模块,执行 install 命令,就会将该模块放入本地仓库,就可以进…...
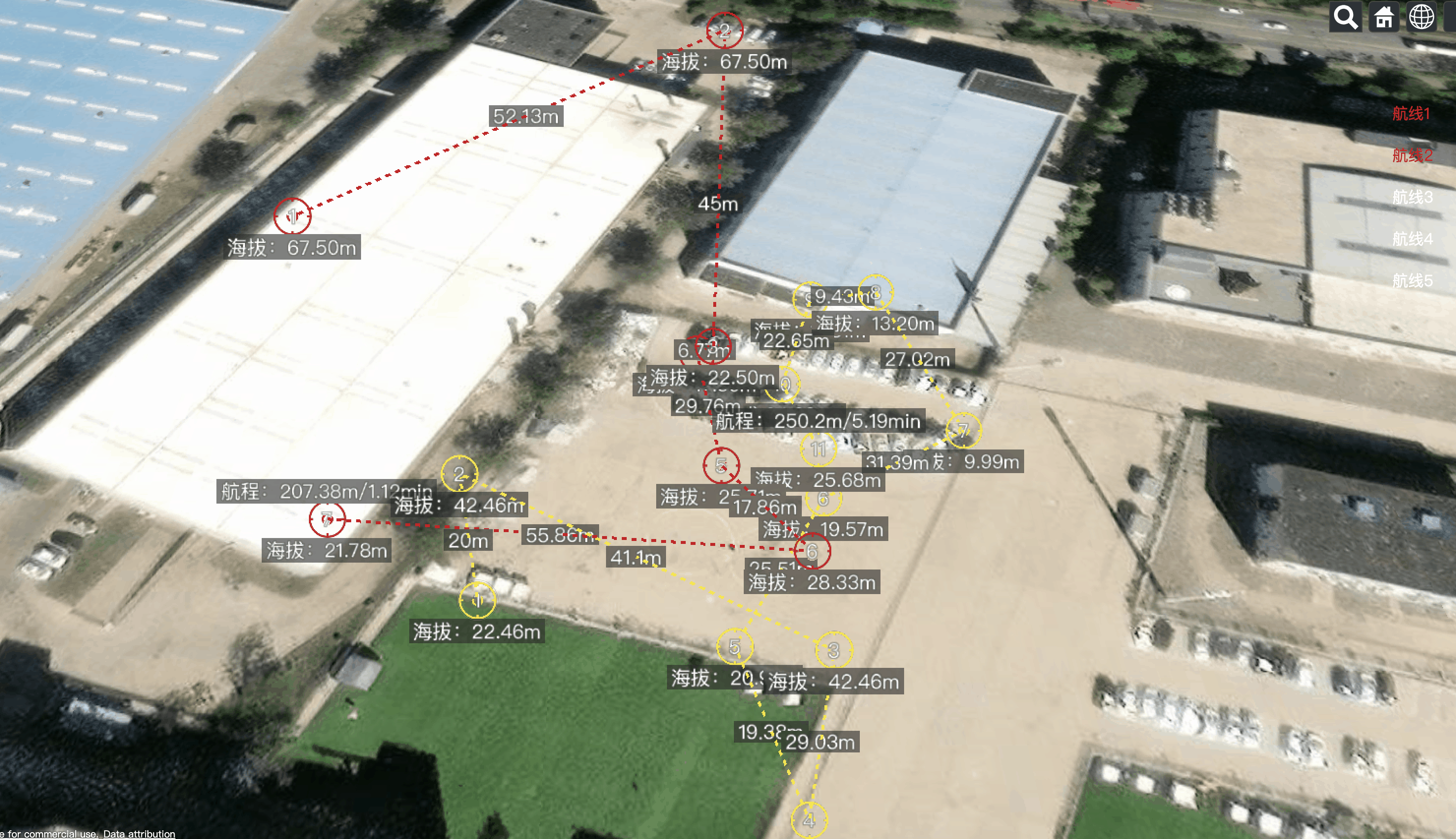
Vue.js2+Cesium1.103.0 七、Primitive 绘制航线元素
Vue.js2Cesium1.103.0 七、Primitive 绘制航线元素 用 Primitive 绘制航线元素,包括航点图标,航线线段,线段距离标注,航点序号,海拔标注,总航程等信息。 可同时绘制多条航线;可根据 id 清除指…...

Mybatis 源码 ④ :TypeHandler
文章目录 一、前言二、DefaultParameterHandler1. DefaultParameterHandler#setParameters1.1 UnknownTypeHandler1.2 自定义 TypeHandler 三、DefaultResultSetHandler1. hasNestedResultMaps2. handleRowValuesForNestedResultMap2.1 resolveDiscriminatedResultMap2.2 creat…...

RabbitMQ和JMeter,一个完美的组合!优化你的中间件处理方式
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息中间件,它是基于Erlang语言编写的,并发能力强,性能好,是目前主流的消息队列中间件之一。 RabbitMQ的安装可参照官网( https://www.rabbitmq.c…...

WARNING: IPv4 forwarding is disabled. Networking will not work
当我在运行某条语句的时候 docker run -it -p 30001:22 --namecentos-ssh centos /bin/bash 提示 WARNING: IPv4 forwarding is disabled. Networking will not work. 解决: vim /usr/lib/sysctl.d/00-system.conf net.ipv4.ip_forward1 systemctl restart networ…...
@EnableConofigurationProperties注解的用法)
SpringBoot复习:(40)@EnableConofigurationProperties注解的用法
一、配置文件: server.port9123 二、配置类: package cn.edu.tju.config;import com.mysql.fabric.Server; import org.springframework.boot.autoconfigure.web.ServerProperties; import org.springframework.boot.context.properties.EnableConfigu…...

Live Market是如何做跨境客户服务的?哪些技术赋能?
在面对不同的海外市场和用户群体时,如何进行有效地出海营销是跨境商家面临的挑战。其中消费者服务管理和卖家保障尤其关键,如何做好客户服务管理?包括处理好客户投诉,提升消费者满意度是所有跨境商家和品牌独立站卖家非常重视的问题。 在数字化浪潮席卷之下&#…...
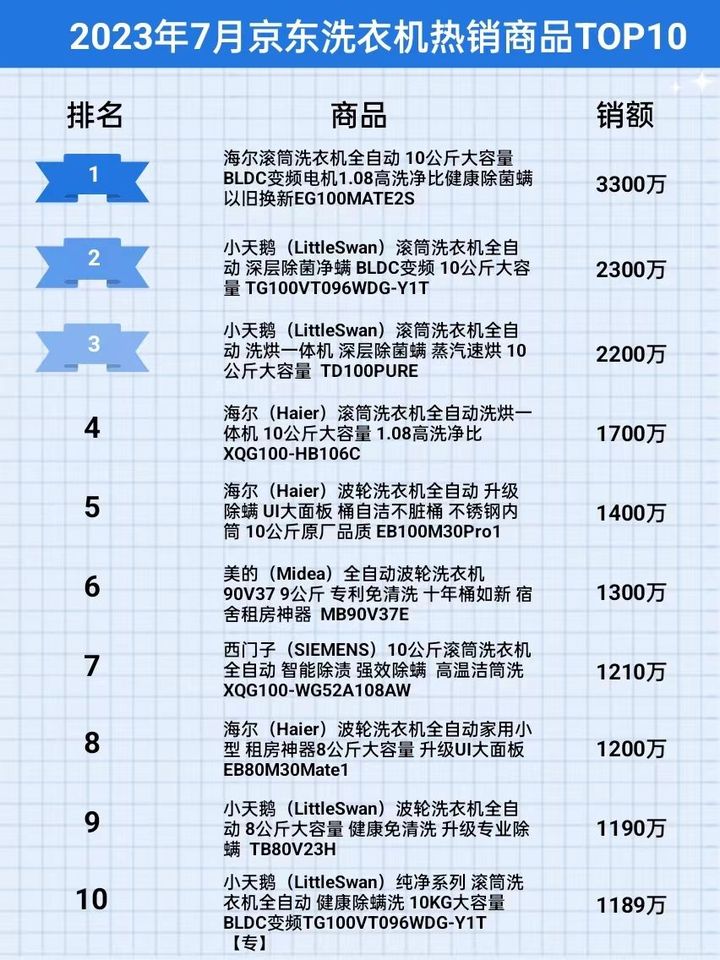
2023年7月京东洗衣机行业品牌销售排行榜(京东数据分析软件)
2023年上半年,洗衣机市场表现平淡,同环比来看出货量都有一定程度的下滑。7月份,洗衣机市场仍未改变这一下滑态势。 根据鲸参谋电商数据分析平台的相关数据显示,7月份,京东平台洗衣机的销量为109万,环比下降…...

Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用 当企业将大模型能力集成到业务流程中时,除了关注模型…...
丢失的那些事儿)
Allegro出Gerber避坑指南:关于NC钻孔层(MANUFACTURING/NCLEGEND)丢失的那些事儿
Allegro出Gerber避坑指南:NC钻孔层丢失问题深度解析与实战解决方案 在PCB设计领域,Gerber文件输出是设计到生产的最后一道关键环节。许多经验丰富的设计师都曾遇到过这样的场景:按照标准流程操作,却在最终检查时发现NC钻孔图例层(…...

龙芯3A5000工业主板实战:从硬件部署到软件生态的国产化替代指南
1. 项目概述:一颗“中国芯”的工业级落地 最近,圈子里关于国产自主平台的消息又热闹了起来。这次的主角,是集特智能新推出的一款工业主板,核心搭载了龙芯3A5000处理器和7A2000桥片。对于长期深耕工业控制、边缘计算、网络安全这些…...

AI智能体Skills设计:从API工具到核心能力的工程实践
1. 从“工具”到“能力”:重新理解AI智能体的Skills最近和几个做AI应用开发的朋友聊天,发现一个挺有意思的现象:大家一提到给智能体加“Skills”,第一反应往往是去翻看官方文档,找那个叫“Tools”或者“Functions”的列…...

Wireshark进阶实战:15分钟定位真实网络故障根因
1. 这不是“又一个Wireshark教程”,而是我三年里修过的27个真实网络故障现场 你打开Wireshark,看到满屏滚动的TCP、HTTP、DNS包,心里发虚——不是不会点“开始捕获”,而是根本不知道该盯哪一行、为什么这一行比那一行重要、哪个字…...

Kali365 钓鱼平台突袭 Microsoft 365 用户:FBI 紧急预警新型 OAuth 令牌攻击链
近期,美国联邦调查局(FBI)联合网络安全与基础设施安全局(CISA)发布了一则编号为 I-052126-PSA 的私营行业通知,披露了一个正在暗处快速膨胀的威胁——名为 Kali365 的网络钓鱼即服务(PhaaS&…...

5个步骤在Windows Hyper-V上完美运行macOS虚拟机
5个步骤在Windows Hyper-V上完美运行macOS虚拟机 【免费下载链接】OSX-Hyper-V OpenCore configuration for running macOS on Windows Hyper-V. 项目地址: https://gitcode.com/gh_mirrors/os/OSX-Hyper-V 你是否想在Windows电脑上体验macOS的流畅操作?OSX-…...

终极Ghidra逆向工程指南:30分钟从零掌握二进制分析
终极Ghidra逆向工程指南:30分钟从零掌握二进制分析 【免费下载链接】ghidra Ghidra is a software reverse engineering (SRE) framework 项目地址: https://gitcode.com/GitHub_Trending/gh/ghidra Ghidra作为一款由美国国家安全局(NSAÿ…...

Hermes Agent 自定义供应商配置指向 Taotoken 的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 自定义供应商配置指向 Taotoken 的步骤 对于使用 Hermes Agent 进行 AI 应用开发的团队而言,统一管理模型…...

RISC-V MCU移植RTOS实战:以鸿蒙OS LiteOS-M与CH32V307为例
1. 项目概述与核心思路 最近在折腾一块沁恒微电子的CH32V307开发板,这是一颗基于RISC-V架构的MCU,性能不错,外设也丰富。手头正好有个任务,需要把华为的鸿蒙OS LiteOS-M内核给移植上去。这活儿听起来挺唬人,但实际拆解…...