Python分享之 Spider
一、网络爬虫
网络爬虫又被称为网络蜘蛛,我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python',会有大量和Python相关的网页被检索出来,百度和谷歌是如何从海量的网页中检索出你想要的资源,他们靠的就是派出大量蜘蛛去网页上爬取,检索关键字,建立索引数据库,经过复杂的排序算法,结果按照搜索关键字相关度的高低展现给你。
千里之行,始于足下,我们从最基础的开始学习如何写一个网络爬虫,实现语言使用Python。
二、Python如何访问互联网
想要写网络爬虫,第一步是访问互联网,Python如何访问互联网呢?
在Python中,我们使用urllib包访问互联网。(在Python3中,对这个模块做了比较大的调整,以前有urllib和urllib2,在3中对这两个模块做了统一合并,称为urllib包。包下面包含了四个模块,urllib.request,urllib.error,urllib.parse,urllib.robotparser),目前主要使用的是urllib.request。
我们首先举一个最简单的例子,如何获取获取网页的源码:
import urllib.request
response = urllib.request.urlopen('https://docs.python.org/3/')
html = response.read()
print(html.decode('utf-8'))三、Python网络简单使用
首先我们用两个小demo练一下手,一个是使用python代码下载一张图片到本地,另一个是调用有道翻译写一个翻译小软件。
3.1根据图片链接下载图片,代码如下:
import urllib.requestresponse = urllib.request.urlopen('http://www.3lian.com/e/ViewImg/index.html?url=http://img16.3lian.com/gif2016/w1/3/d/61.jpg')
image = response.read()with open('123.jpg','wb') as f:f.write(image)其中response是一个对象
输入:response.geturl()
->'http://www.3lian.com/e/ViewImg/index.html?url=http://img16.3lian.com/gif2016/w1/3/d/61.jpg'
输入:response.info()
-><http.client.HTTPMessage object at 0x10591c0b8>
输入:print(response.info())
->Content-Type: text/html
Last-Modified: Mon, 27 Sep 2004 01:23:20 GMT
Accept-Ranges: bytes
ETag: "0f4b59230a4c41:0"
Server: Microsoft-IIS/8.0
Date: Sun, 14 Aug 2016 07:16:01 GMT
Connection: close
Content-Length: 2827
输入:response.getcode()
->200
3.1使用有道词典实现翻译功能
我们想实现翻译功能,我们需要拿到请求链接。首先我们需要进入有道首页,点击翻译,在翻译界面输入要翻译的内容,点击翻译按钮,就会向服务器发起一个请求,我们需要做的就是拿到请求地址和请求参数。
我在此使用谷歌浏览器实现拿到请求地址和请求参数。首先点击右键,点击检查(不同浏览器点击的选项可能不同,同一浏览器的不同版本也可能不同),进入图一所示,从中我们可以拿到请求请求地址和请求参数,在Header中的Form Data中我们可以拿到请求参数。

代码段如下:
import urllib.request
import urllib.parseurl = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'
data = {}
data['type'] = 'AUTO'
data['i'] = 'i love you'
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
print(html)上述代码执行如下:
{"type":"EN2ZH_CN","errorCode":0,"elapsedTime":0,"translateResult":[[{"src":"i love you","tgt":"我爱你"}]],"smartResult":{"type":1,"entries":["","我爱你。"]}}
对于上述结果,我们可以看到是一个json串,我们可以对此解析一下,并且对代码进行完善一下:
import urllib.request
import urllib.parse
import jsonurl = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'
data = {}
data['type'] = 'AUTO'
data['i'] = 'i love you'
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
target = json.loads(html)
print(target['translateResult'][0][0]['tgt'])四、规避风险
服务器检测出请求不是来自浏览器,可能会屏蔽掉请求,服务器判断的依据是使用‘User-Agent',我们可以修改改字段的值,来隐藏自己。代码如下:
import urllib.request
import urllib.parse
import jsonurl = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'
data = {}
data['type'] = 'AUTO'
data['i'] = 'i love you'
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)
print(target['translateResult'][0][0]['tgt'])上述做法虽然可以隐藏自己,但是还有很大问题,例如一个网络爬虫下载图片软件,在短时间内大量下载图片,服务器可以可以根据IP访问次数判断是否是正常访问。所有上述做法还有很大的问题。我们可以通过两种做法解决办法,一是使用延迟,例如5秒内访问一次。另一种办法是使用代理。
延迟访问(休眠5秒,缺点是访问效率低下):
import urllib.request
import urllib.parse
import json
import timewhile True:content = input('please input content(input q exit program):')if content == 'q':break;url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}data['type'] = 'AUTO'data['i'] = contentdata['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')req = urllib.request.Request(url, data)req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')response = urllib.request.urlopen(url, data)html = response.read().decode('utf-8')target = json.loads(html)print(target['translateResult'][0][0]['tgt'])time.sleep(5)代理访问:让代理访问资源,然后讲访问到的资源返回。服务器看到的是代理的IP地址,不是自己地址,服务器就没有办法对你做限制。
步骤:
1,参数是一个字典{'类型' : '代理IP:端口号' } //类型是http,https等
proxy_support = urllib.request.ProxyHandler({})
2,定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
3,安装opener(永久安装,一劳永逸)
urllib.request.install_opener(opener)
3,调用opener(调用的时候使用)
opener.open(url)
五、批量下载网络图片
图片下载来源为**网
图片下载的关键是找到图片的规律,如找到当前页,每一页的图片链接,然后使用循环下载图片。下面是程序代码(待优化,正则表达式匹配,IP代理):
import urllib.request
import osdef url_open(url):req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0')response = urllib.request.urlopen(req)html = response.read()return htmldef get_page(url):html = url_open(url).decode('utf-8')a = html.find('current-comment-page') + 23b = html.find(']',a)return html[a:b]def find_image(url):html = url_open(url).decode('utf-8')image_addrs = []a = html.find('img src=')while a != -1:b = html.find('.jpg',a,a + 150)if b != -1:image_addrs.append(html[a+9:b+4])else:b = a + 9a = html.find('img src=',b)for each in image_addrs:print(each)return image_addrsdef save_image(folder,image_addrs):for each in image_addrs:filename = each.split('/')[-1]with open(filename,'wb') as f:img = url_open(each)f.write(img)def download_girls(folder = 'girlimage',pages = 20):os.mkdir(folder)os.chdir(folder)url = 'http://****.net/ooxx/'page_num = int(get_page(url))for i in range(pages):page_num -= ipage_url = url + 'page-' + str(page_num) + '#comments'image_addrs = find_image(page_url)save_image(folder,image_addrs)if __name__ == '__main__':download_girls()代码运行效果如下:

相关文章:
Python分享之 Spider
一、网络爬虫 网络爬虫又被称为网络蜘蛛,我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python,会有大量和…...

Golang项目中如何轻松实现私有仓库pkg包的引入
在企业内部创建一个公共的Golang模块工程可以帮助提高代码复用性和开发效率。本文将从如何创建一个公共的Golang工程开始,指导你一步步创建它、并引入到你的工程中。 1、公共模块规范 下面是一个简单的步骤指南来创建这样一个公共模块项目。 创建版本控制仓库&am…...
Python项目实战:基于napari的3D可视化(点云+slice)
文章目录 一、napari 简介二、napari 安装与更新三、napari【巨巨巨大的一个BUG】四、napari 使用指南4.1、菜单栏(File View Plugins Window Help)4.2、Window:layer list(参数详解)4.3、Window:layer…...

go的gin和gorm框架实现切换身份的接口
使用go的gin和gorm框架实现切换身份的接口,接收前端发送的JSON对象,查询数据库并更新,返回前端信息 接收前端发来的JSON对象,包含由openid和登陆状态组成的一个string和要切换的身份码int型 后端接收后判断要切换的身份是否低于该…...
仓库库存管理难点在哪?有哪些仓库库存管理软件?
仓库库存管理常见的难点有:库存数据混乱、库存成本较高、库存积压严重等问题 使用仓库管理软件,企业可以更好地管理库存、优化供应链、提高操作效率,并基于准确的数据进行决策和规划,从而解决许多仓库库存管理中的难题。 一、仓库…...
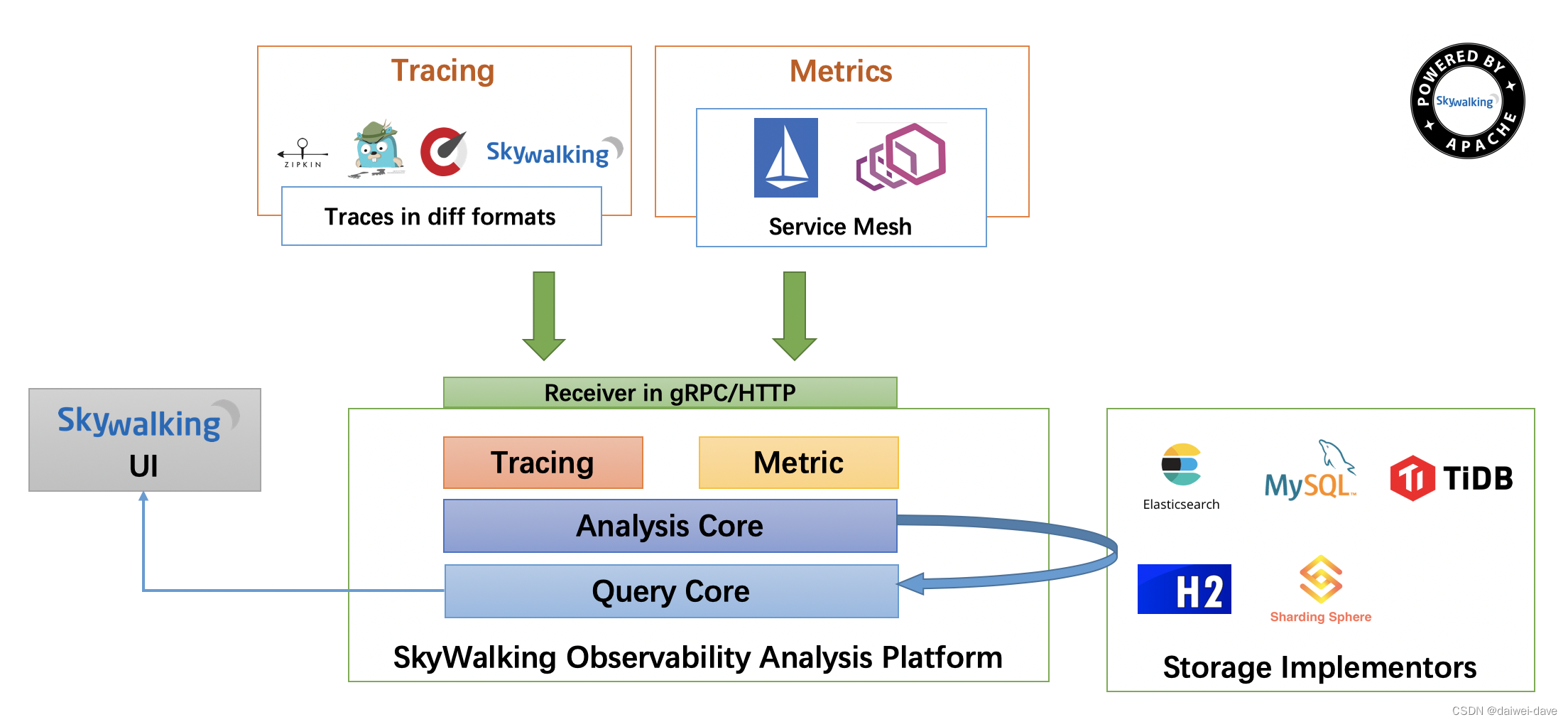
服务链路追踪
一、基础概念 1.背景 对于一个大型的几十个、几百个微服务构成的微服务架构系统,通常会遇到下面一些问题,比如: 如何串联整个调用链路,快速定位问题?如何理清各个微服务之间的依赖关系?如何进行各个微服…...

macOS - 安装使用 libvirt、virsh
文章目录 关于 libvirt使用安装启动服务virsh 交互模式virsh 帮助命令 关于 libvirt libvirt 官网: https://libvirt.org/gitlab : https://gitlab.com/libvirt/libvirtgithub : https://github.com/libvirt/libvirt 只读,gitlab 的镜像 libvirt是一套…...
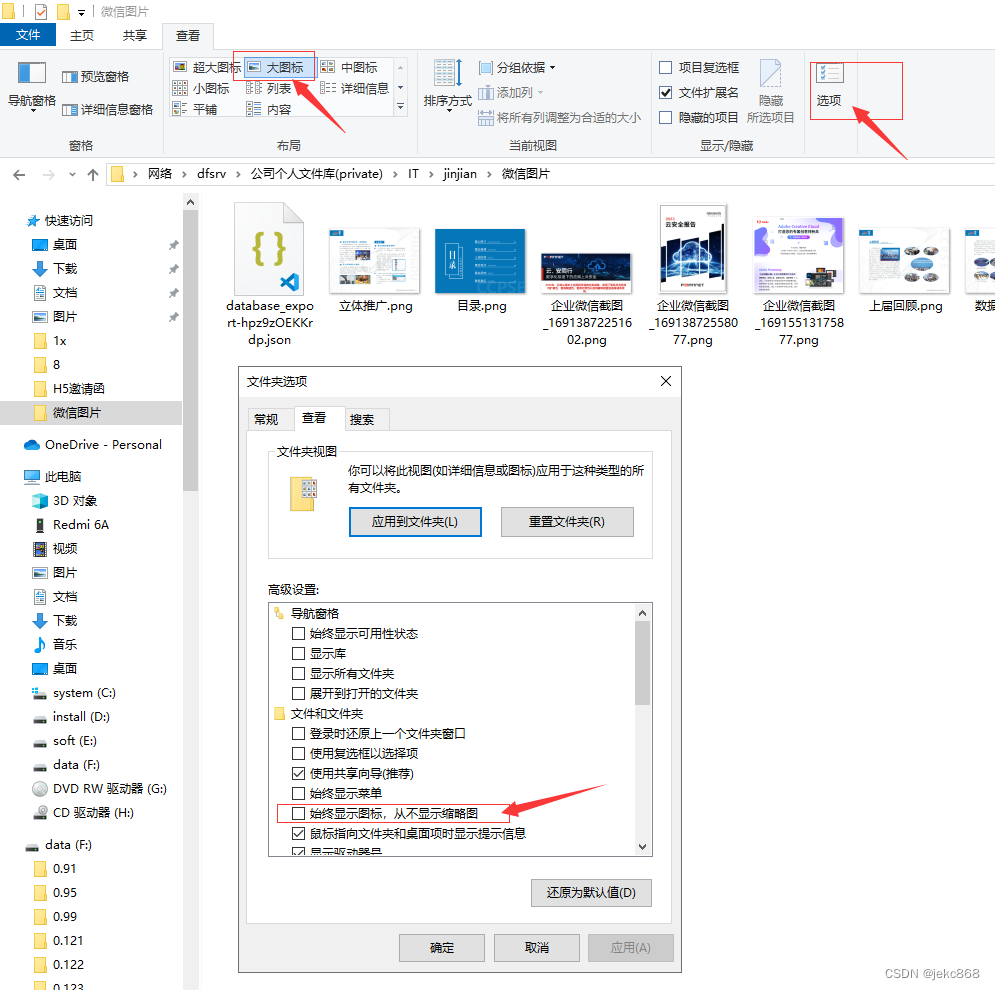
Windows Server 2019设置使用照片查看器查看图片的设置方法
1、使用winR快捷键快速打开运行,输入regedit打开注册表: 2、在注册表中找到:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Photo Viewer\Capabilities\FileAssociations 3、在右侧新建字符串项: 4、例如新建两项.jpg 和.png值…...
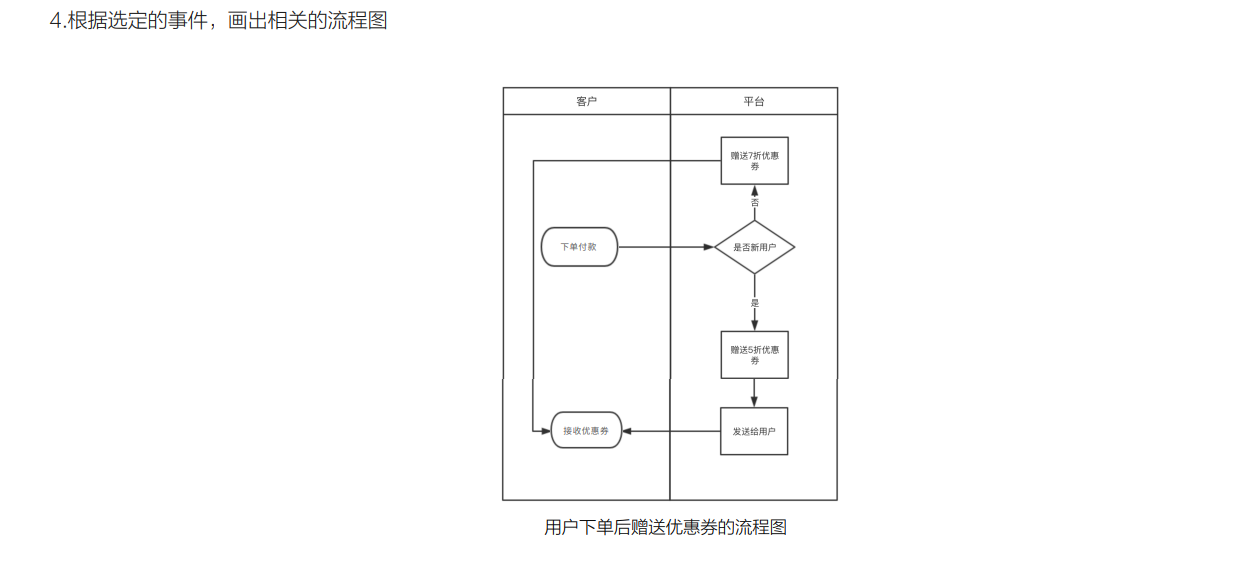
【需求输出】流程图输出
文章目录 1、什么是流程图2、绘制流程图的工具和基本要素3、流程图的分类和应用场景4、如何根据具体场景输出流程图 1、什么是流程图 2、绘制流程图的工具和基本要素 3、流程图的分类和应用场景 4、如何根据具体场景输出流程图...
opencv+ffmpeg+QOpenGLWidget开发的音视频播放器demo
前言 本篇文档的demo包含了 1.使用OpenCV对图像进行处理,对图像进行置灰,旋转,抠图,高斯模糊,中值滤波,部分区域清除置黑,背景移除,边缘检测等操作;2.单纯使用opencv播放…...

stable-diffusion-webui 的模型更新
shared.py和sd_models.py中 shared.py: options_templates.update(options_section((sd, "Stable Diffusion"), {"sd_model_checkpoint": OptionInfo(None, "Stable Diffusion checkpoint", gr.Dropdown, lambda: {"choices": list_…...

Gin模板语法
Gin模板语法 文章目录 <center> Gin模板语法前提提醒Gin框架启动服务器模板解析模板渲染遇到不同目录下相同的文件如何加载和渲染自定义函数加载静态文件 前提提醒 由于有了前面template包的基础,所以该笔记不再过多详细分析 Gin框架启动服务器 语法: r:gin.Default()/…...
Go http.Handle和http.HandleFunc的路由问题
Golang的net/http包提供了原生的http服务,其中http.Handle和http.HandleFunc是两个重要的路由函数。 1. 函数介绍 http.HandleFunc和http.Handle的函数原型如下,其中DefaultServeMux是http包提供的一个默认的路由选择器。 func HandleFunc(pattern st…...

如何使用Kali Linux进行渗透测试?
1. 渗透测试简介 渗透测试是通过模拟恶意攻击,评估系统、应用或网络的安全性的过程。Kali Linux为渗透测试人员提供了丰富的工具和资源,用于发现漏洞、弱点和安全风险。 2. 使用Kali Linux进行渗透测试的步骤 以下是使用Kali Linux进行渗透测试的基本…...
简单易用且高效的跨平台开发工具:Xojo 2023 for Mac
Xojo for Mac是Mac平台上一个跨平台的针对桌面、Web、移动和Raspberry Pi的快速应用程序开发软件。与其他多平台开发工具相比,Xojo for Mac为开发人员提供了显着的生产率提高。 Xojo for Mac具有拖放功能,使您能够快速创建用户界面设计,然后…...

HIVE SQL实现分组字符串拼接concat
在Mysql中可以通过group_concat()函数实现分组字符串拼接,在HIVE SQL中可以使用concat_ws()collect_set()/collect_list()函数实现相同的效果。 实例: abc2014B92015A82014A102015B72014B6 1.concat_wscollect_list 非去重拼接 select a ,concat_ws(-…...

【问心篇】渴望、热情和选择
加班太严重完全没有时间学习,怎么办? 我真的不算聪明的人,但是,我对学习真的是有渴望的。说得好听一点,我希望自己在不停地成长,不辜负生活在这个信息化大变革的时代。说得不好的一点,就是我从…...

【贪心】CF1841 D
Codeforces 题意: 思路: 首先模拟一下样例 并没有发现什么 那么就去考虑特殊情况,看看有没有什么启发 考虑一个大区间包含所有小区间的情形,这种情况就是在这么多区间中找出两个区间 换句话说,这么多区间组成一个…...
移动端预览指定链接的pdf文件流
场景 直接展示外部系统返回的获取文件流时出现了跨域问题: 解决办法 1. 外部系统返回的请求头中调整(但是其他系统不会给你改的) 2. 我们系统后台获取文件流并转为新的文件流提供给前端 /** 获取传入url文件流 */ GetMapping("/get…...

【Go 基础篇】Go语言字符类型:解析字符的本质与应用
介绍 字符类型是计算机编程中用于表示文本和字符的数据类型,是构建字符串的基本单位。在Go语言(Golang)中,字符类型具有独特的特点和表示方式,包括Unicode编码、字符字面值以及字符操作。本篇博客将深入探讨Go语言中的…...

量子电路优化:GSI方法在NISQ时代的应用
1. 量子电路优化的核心挑战与创新思路在当前的NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机面临着几个关键瓶颈:量子比特的相干时间有限、门操作存在误差、以及量子比特之间的连接受限。这些硬件限制使得量子电路的深度…...

8051仿真器OMF转SIG格式的实战指南
1. Signum 8051 仿真器符号转换器使用指南在嵌入式开发领域,Signum Systems 的 8051 仿真器是一个常用的调试工具。很多开发者在使用 Vision 开发环境时,经常遇到需要将链接器生成的绝对目标模块(OMF)转换为仿真器专用格式的需求。本文将详细介绍这个转换…...
)
模拟几种数据融合协作频谱感知技术在认知无线电应用中性能研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解
鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解 前言 在 HarmonyOS 6.0 应用开发中,社交类页面的核心挑战在于如何高效展示附近社群、兴趣标签和活动信息。本文将以“同城兴趣圈”应用的主页面为例,深入解析如何在鸿蒙平台上构建社交发现…...

创业公司如何利用 Taotoken 统一管理多个 AI 模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司如何利用 Taotoken 统一管理多个 AI 模型服务 对于资源有限的创业团队而言,快速验证产品想法、迭代功能是生存…...
)
企业级Sora 2 API接入终极 checklist:23项必检项(含AWS/Azure/GCP三云环境差异对照表)
更多请点击: https://intelliparadigm.com 第一章:企业级Sora 2 API接入终极 checklist:23项必检项(含AWS/Azure/GCP三云环境差异对照表) 接入企业级 Sora 2 API 前,必须完成覆盖身份认证、网络策略、合规…...

HDLxGraph:图数据库与LLM在硬件设计中的应用
1. HDLxGraph:当硬件设计遇上图数据库与LLM 在芯片设计领域,硬件描述语言(HDL)如Verilog和VHDL是工程师们将电路构想转化为可执行代码的核心工具。然而,随着现代芯片设计复杂度的爆炸式增长,一个中等规模的…...

效率直接起飞 2026 最新!降AIGC工具测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

我用 DuckDB + Python 搭了个全自动日报系统:68 行代码,7 个踩坑实录
# 我用 DuckDB Python 搭了个全自动日报系统:68 行代码,7 个踩坑实录> 总周期:3 天业余时间(每天下班 2 小时) > 总成本:≈ 服务器 29/月(已有) > 技术栈:Duck…...

TDengine Tag 设计哲学与 Schema 变更机制
2.数据模型 > 04 Tag 设计哲学与 Schema 变更机制 — 静态属性建模与在线结构演进 适用版本:TDengine v3.x(v3.3.x / v3.4.x) | 最后更新:2026-05-16 概述 Tag(标签)是 TDengine 数据模型中区别于传统…...