kafka集成篇
kafka的Java客户端
生产者
1.引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.6.3</version></dependency>
2.生产者发送消息的基本实现
/*** 消息的发送⽅*/
public class MyProducer {private final static String TOPIC_NAME = "my-replicated-topic";public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094");// 把发送的key从字符串序列化为字节数组props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// 把发送消息value从字符串序列化为字节数组props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());RecordMetadata metadata = null;try (Producer<String, String> producer = new KafkaProducer<>(props)) {Order order = new Order(1L, 99.9D);// 未指定发送分区,具体发送的分区计算公式:hash(key)%partitionNumProducerRecord<String, String> producerRecord = newProducerRecord<>(TOPIC_NAME, order.getOrderId().toString(), JSON.toJSONString(order));// 等待消息发送成功的同步阻塞⽅法metadata = producer.send(producerRecord).get();} catch (InterruptedException | ExecutionException e) {throw new RuntimeException(e);} finally {if (metadata != null) {// =====阻塞=======System.out.println("同步⽅式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" +metadata.offset());}}}
}
3.发送消息到指定分区

4.发送消息未指定分区
发送消息未指定分区,会通过业务key的hash运算,算出消息往哪个分区上发
// 未指定发送分区,具体发送的分区计算公式:hash(key)%partitionNum
ProducerRecord<String, String> producerRecord = newProducerRecord<>(TOPIC_NAME, order.getOrderId().toString(), JSON.toJSONString(order));
5.同步发送消息
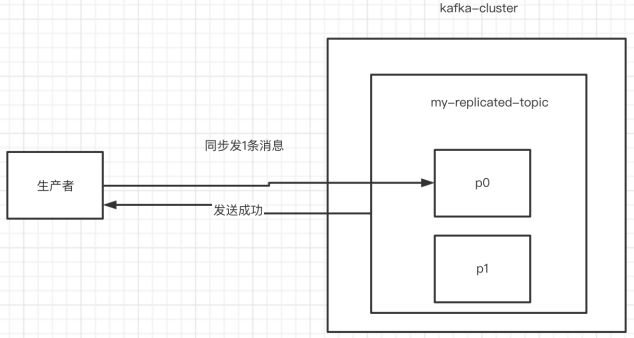
如果生产者发送消息没有收到ack,生产者会阻塞,阻塞到3s的时间,如果还没有收到消息,会进行重试。重试的次数3次。
RecordMetadata metadata = producer.send(producerRecord).get();System.out.println("同步⽅式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());
6.异步发送消息
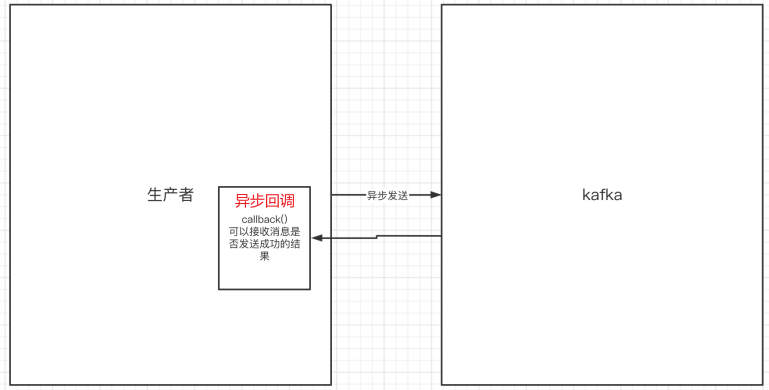
异步发送,生产者发送完消息后就可以执行之后的业务,broker在收到消息后异步调用生产者提供的callback回调方法。
// 异步发送消息 Callback回调接口producer.send(producerRecord, new Callback() {// 异步回调方法@Overridepublic void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {System.err.println("发送消息失败:" +e.getMessage());}if (metadata != null) {System.out.println("异步⽅式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());}}});System.out.println("处理之后的逻辑~");
输出结果:

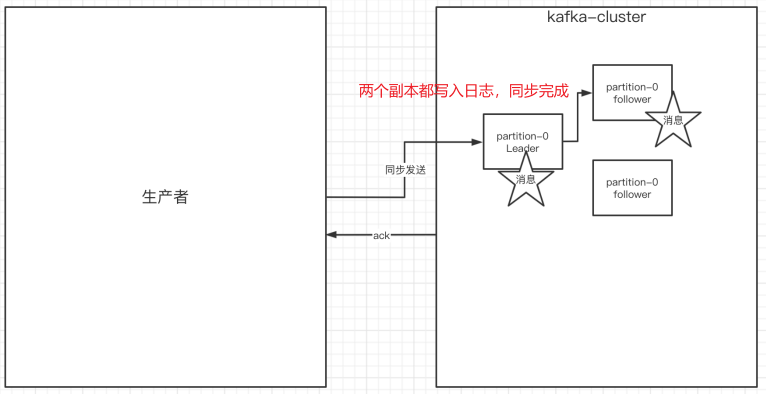
7.生产者中的ack的配置
在同步发消息的场景下:生产者发送消息到broker上后,ack会有3种不同的选择:
ack = 0:kafka-cluster不需要任何的broker收到消息,就立即返回ack给生产者就可以继续发送下一条消息,效率是最高的但最容易丢消息ack=1(默认):多副本之间的leader已经收到消息,并把消息写⼊到本地的log中,才会返回ack给生产者,性能和安全性是最均衡的(这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失)ack=-1/all:需要等待 min.insync.replicas(默认为1,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志才会返回ack给生产者,这种策略会保证只要有⼀个备份存活就不会丢失数据。这种方式最安全但性能最差。(⼀般除非是金融级别,或跟钱打交道的场景才会使用这种配置)
code:
props.put(ProducerConfig.ACKS_CONFIG, "1");
关于ack和重试(如果没有收到ack,就开启重试)的配置
- 发送会默认会重试3次,每次间隔100ms
props.put(ProducerConfig.ACKS_CONFIG, "1");/*发送失败会重试,默认重试间隔100ms,【重试能保证消息发送的可靠性,但是也可能造成消息重复发送】,⽐如⽹络抖动,所以【需要在接收者那边做好消息接收的幂等性处理】*/props.put(ProducerConfig.RETRIES_CONFIG, 3);// 重试间隔设置props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
8.关于消息发送的缓冲区
发送的消息会先进入到本地缓冲区(32mb),kakfa会跑⼀个线程,该线程去缓冲区中取16k的数据,发送到kafka,如果到10毫秒数据没取满16k,也会发送⼀次。
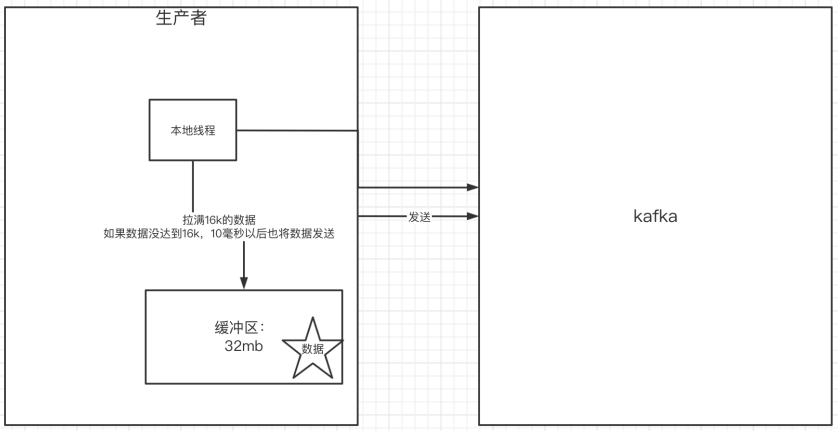
- kafka默认会创建一个消息缓冲区,用来存放要发送的消息,缓冲区是32m
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
- kafka本地线程会去缓冲区中⼀次拉16k的数据,发送到broker
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
- 如果线程拉不到16k的数据,间隔10ms也会将已拉到的数据发到broker
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
消费者
1.消费者消费消息的基本实现
public class MyConsumer {private final static String TOPIC_NAME = "my-replicated-topic";private final static String CONSUMER_GROUP_NAME = "testGroup";public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094");// 消费分组名props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());// 1.创建⼀个消费者的客户端try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {// 2.消费者订阅主题列表consumer.subscribe(Collections.singletonList(TOPIC_NAME));while (true) {/** 3.poll()API 是拉取消息的⻓轮询*/ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {// 4.操作消息System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n ", record.partition(), record.offset(), record.key(), record.value());}}} catch (Exception e) {throw new RuntimeException(e);}}
}
2.消费者自动提交和手动提交offset
1)提交的内容
消费者无论是自动提交还是手动提交,都需要把所属的消费组+消费的某个主题+消费的某个分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题里面。
2)自动提交
消费者poll消息下来以后就会自动提交offset
// 是否自动提交offset,默认就是true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
注意:自动提交会丢消息。因为消费者在消费前提交offset,有可能提交完后还没消费时消费者挂了。于是下⼀个消费者会从已提交的offset的下一个位置开始消费消息。之前未被消费的消息就丢失掉了。
3)手动提交
需要把自动提交的配置改成false
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
手动提交又分成了两种:
- 手动同步提交
在消费完消息后调用同步提交的方法,当集群返回ack前⼀直阻塞,返回ack后表示提交成功,执行之后的逻辑
while (true) {/** poll()API 是拉取消息的⻓轮询*/ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {// 操作消息System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n ", record.partition(), record.offset(), record.key(), record.value());}// 所有的消息已消费完if (records.count() > 0) {// 有消息// ⼿动同步提交offset,当前线程会阻塞直到offset提交成功// 【⼀般使⽤同步提交】,因为提交之后⼀般也没有什么逻辑代码了consumer.commitSync();// =======阻塞=== 提交成功}}
- 手动异步提交
在消息消费完后提交,不需要等到集群ack,直接执行之后的逻辑,可以设置⼀个回调方法,供集群调用
while (true) {/** poll()API 是拉取消息的⻓轮询*/ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {// 操作消息System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n ", record.partition(), record.offset(), record.key(), record.value());}// 所有的消息已消费完if (records.count() > 0) {// 有消息// ⼿动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后⾯的程序逻辑consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition,OffsetAndMetadata> offsets, Exception exception) {if (exception != null) {System.err.println("Commit failed for " + offsets);System.err.println("Commit failed exception: " + exception.getMessage());}}});}}
3.长轮询poll消息(消费者拉取消息)
-
消费者建立了与broker之间的长连接,开始poll消息
-
默认情况下,消费者一次会poll500条消息
// ⼀次poll最⼤拉取消息的条数,可以根据消费速度的快慢来设置
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
- 代码中设置了长轮询的时间是1000毫秒
while (true) {/** poll()API 是拉取消息的⻓轮询*/ConsumerRecords<String, String> records =consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.printf("收到消息:partition = %d,offset = %d, key = %s, value = %s%n ", record.partition(), record.offset(), record.key(), record.value());}}
- 意味着:
- 如果⼀次poll到500条,就直接执行for循环
- 如果这⼀次没有poll到500条。且时间在1秒内,那么长轮询继续poll,要么到500条,要么到1s,执行后续for循环
- 如果多次poll都没达到500条,且1秒时间到了,那么直接执行for循环
- 如果两次poll的间隔超过30s(poll时间短但是消费时间长,消费者消费可能会达到30s左右),集群会认为该消费者的消费能力过 弱,该消费者被踢出消费组,触发rebalance机制,rebalance机制会造成性能开销。
可以通过设置参数, 让⼀次poll的消息条数少⼀点,避免触发rebalance损耗性能
// ⼀次poll最⼤拉取消息的条数,可以根据消费速度的快慢来设置props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);// 如果两次poll的时间如果超出了30s的时间间隔,kafka会认为其消费能⼒过弱,将其踢出消费组。将分区分配给其他消费者。-rebalanceprops.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
4.消费者的健康状态检查
消费者每隔1s向kafka集群发送心跳,集群发现如果有超过10s没有续约的消费者,将被踢出消费组,触发该消费组的rebalance机制,将该分区交给消费组里的其他消费者进行消费。
// consumer给broker发送心跳的间隔时间 1s一次
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
// kafka如果超过10秒没有收到消费者的心跳,则会把消费者踢出消费组,进⾏rebalance,把分区分配给其他消费者。
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
5.指定分区和偏移量、时间消费
- 指定分区消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
- 从头消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
- 指定offset消费
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);
- 指定时间消费
根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition中找到该offset之后的消息开始消费。
// topic对应所有分区
List<PartitionInfo> topicPartitions = consumer.partitionsFor(TOPIC_NAME);
// 从1小时前开始消费
long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {map.put(new TopicPartition(TOPIC_NAME, par.partition()), fetchDataTime);
}
Map<TopicPartition, OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry : parMap.entrySet()) {TopicPartition key = entry.getKey();OffsetAndTimestamp value = entry.getValue();if (key == null || value == null) continue;long offset = value.offset();System.out.println("partition-" + key.partition() +"|offset-" + offset);System.out.println();//根据消费⾥的timestamp确定offsetconsumer.assign(Arrays.asList(key));consumer.seek(key, offset);
}
6.新消费组的消费offset规则
新消费组中的消费者在启动以后,默认会从当前分区的最后⼀条消息的offset+1开始消费(消费新消息)。可以通过以下的设置,让新的消费者第⼀次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)
-
Latest:默认的,消费新消息
-
earliest:第⼀次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1),这个需要区别于consumer.seekToBeginning(每次都从头开始消费)
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
SpringBoot集成kafka
1.引入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
2.配置文件
server:port: 8080
spring:kafka:bootstrap-servers: 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094producer: # 生产者retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送batch-size: 16384 # 每次拉取多少数据发送broker buffer-memory: 33554432 # 本地缓冲区大小acks: 1# 指定消息key和消息体的编解码⽅式key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: default-groupenable-auto-commit: falseauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializermax-poll-records: 500listener:# 当每⼀条记录被消费者监听器(ListenerConsumer)处理之后提交# RECORD# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交# BATCH# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交# TIME# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交# COUNT# TIME | COUNT 有⼀个条件满足时提交# COUNT_TIME# 当每⼀批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交# MANUAL# 【手动调用Acknowledgment.acknowledge()后立即提交,⼀般使用这种】# MANUAL_IMMEDIATEack-mode: MANUAL_IMMEDIATE3.消息生产者
发送消息到指定topic
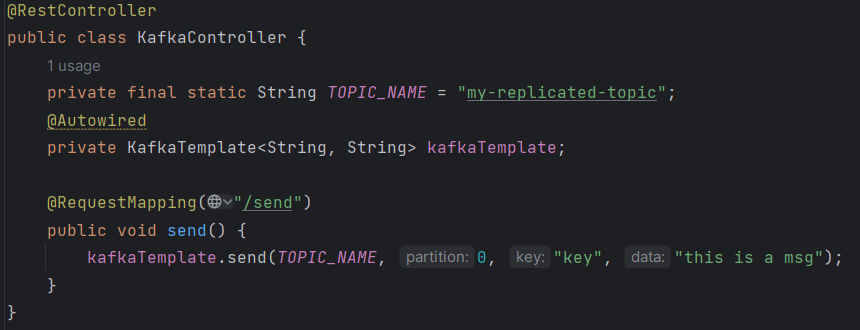
4.消息消费者
设置消费组,消费指定topic
@Component
public class MyConsumer {@KafkaListener(topics = "my-replicated-topic", groupId = "MyGroup1")public void listenGroup(ConsumerRecord<String, String> record,Acknowledgment ack) {String value = record.value();System.out.println(record);System.out.println(value);//⼿动提交offsetack.acknowledge();}
}
5.消费者中配置消费主题、分区和偏移量
设置消费组、多topic、指定分区、指定偏移量消费及设置消费者个数
@KafkaListener(groupId = "testGroup", topicPartitions = {@TopicPartition(topic = "topic1", partitions = {"0", "1"}),@TopicPartition(topic = "topic2", partitions = "0",partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))}, concurrency = "3")// concurrency:同消费组中消费者个数,就是并发消费数,建议小于等于分区总数public void listenGroupPro(ConsumerRecord<String, String> record,Acknowledgment ack) {String value = record.value();System.out.println(value);System.out.println(record);//⼿动提交offsetack.acknowledge();}
相关文章:
kafka集成篇
kafka的Java客户端 生产者 1.引入依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.6.3</version></dependency>2.生产者发送消息的基本实现 /*** 消息的发送⽅*/ …...

go-安装部署
一、安装go 详细安装方式可以查看官网 # 下载 wget https://golang.google.cn/dl/go1.21.0.linux-amd64.tar.gz # 解压缩 tar -xzf go1.21.0.linux-amd64.tar.gz # 迁移目录 mv go /usr/local # 配置环境变量 export PATH$PATH:/usr/local/go/bin # 检查go的版本 go version有…...

vue项目的实用性总结
1、mockjs 基本使用 ★ 安装:npm i mockjs。 在src/mock/index.js内容如下: import Mock from mockjs //制订拦截规则 Mock.mock(http://www.0313.com,get,你好啊)记得在main.js中引入一下,让其参与整个项目的运行。 只要发出去的是get类型…...
IOC容器
DI(依赖注入):DI(Dependency Injection)是一种实现松耦合和可测试性的软件设计模式。它的核心思想是将依赖关系的创建与管理交给外部容器,使得对象之间只依赖于接口而不直接依赖于具体实现类。通过依赖注入…...
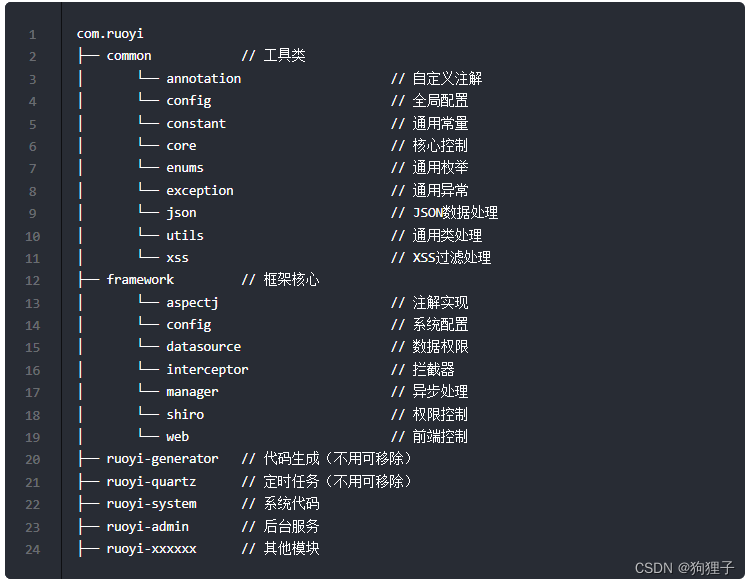
若依框架浅浅介绍
由若依官网所给介绍可知 1、文件结构介绍 在ruoyi-admin的pom.xml文件中引入了ruoyi-framework、ruoyi-quartz和ruoyi-generatior模块,在ruoyi-framework的pom.xml文件中引入了ruoyi-system模块。 2、技术栈介绍 前端:Vue、Element UI后端:…...
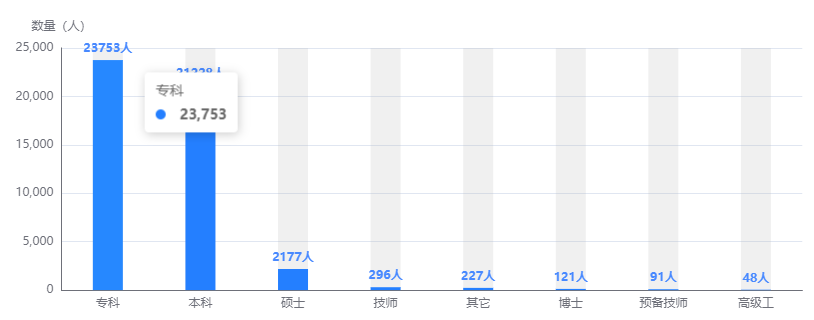
echarts 柱状图-折线图-饼图的基础使用
上图示例图表展示相关配置: var myChart echarts.init(this.$refs.firstMain);myChart.setOption({legend: { // 图例设置top: "15%",type: "scroll",orient: "vertical",//图例列表的布局朝向。left: "right",pageIconCo…...

mac电脑 node 基本操作命令
1. 查看node的版本 node -v2. 查看可安装的node版本 sudo npm view node versions3. 安装指定版本的node sudo n 18.9.04. 安装最新版本node sudo n latest5. 安装最新稳定版 sudo n stable6. 清楚node缓存 sudo npm cache clean -f7. 列举已经安装的node版本 n ls 8. 在…...
Hlang社区项目说明
文章目录 前言Hlang社区技术前端后端 前言 Hello,欢迎来到本专栏,那么这也是第一次做这种类型的专栏,如有不做多多指教。那么在这里我要隆重介绍的就是这个Hlang这个项目。 首先,这里我要说明的是,我们的这个项目其实是分为两个…...

RTC实验
一、RTC简介 RTC(Real Time Clock)即实时时钟,它是一个可以为系统提供精确的时间基准的元器件,RTC一般采用精度较高的晶振作为时钟源,有些RTC为了在主电源掉电时还可以工作,需要外加电池供电BCD码,四位二进制表示一位…...

C#多线程报错:The destination thread no longer exists.
WinForm,C#多线程报错: System.ComponentModel.InvalidAsynchronousStateException: An error occurred invoking the method. The destination thread no longer exists. 研究一番,找到了原因: 有问题的写法: ne…...
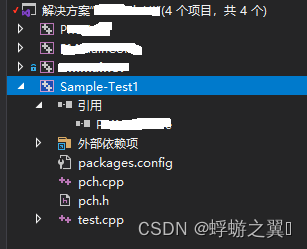
使用 Visual Studio GoogleTest编写 C/C++ 单元测试——入门篇
入门教程 Visual Studio 新建 GoogleTest项目,一路选默认参数 pch.h #pragma once#include "gtest/gtest.h"int add(int a, int b);pch.cpp #include "pch.h"int add(int a, int b) {return a b; }test.cpp #include "pch.h"TES…...

Linux下TA_Lib安装失败的问题处理
Linux下TA_Lib安装失败的问题处理 TA_Lib是python的量化指标库,其中包含了很多150多种量化指标 ,量化分析中经常使用。 This is a Python wrapper for TA-LIB based on Cython instead of SWIG. From the homepage: TA-Lib is widely used by trading …...

egg.js企业级web框架
egg与express、koa的区别 三者皆为node.js web框架,但: express适合做个人项目,灵活性太高;egg是基于koa封装的企业级框架,奉行约定优于配置,按照一套统一的约定进行应用开发,减少开发学习成本…...

小说网站第二章-关于文章的上传的实现
简述 因为最近比较忙,所以只有时间把以前的东西整理一下。前端方面,我使用了既存md5框架语法来保存数据,原谅我展示没找到好的方法。后端的话,我使用nodemongodb来保存数据。下面我就来简单介绍一下我的东西。 前端的实现 前端的…...

Java面试题01
1、以下不属于oracle的逻辑结构的是?答案:B A.段 B.数据文件 C.表空间 D.区 2、构造函数何时被调用?答案:A A.创建对象时 B.使用对象变量时 C.调用对象方法时 D.类定义时 3、下列排序…...
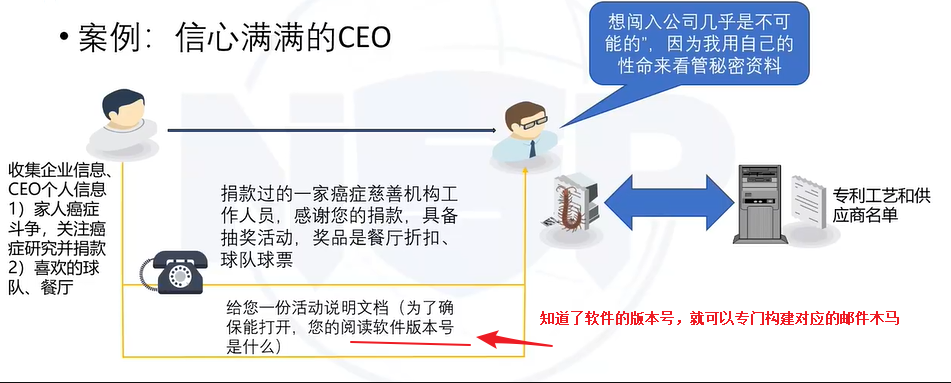
6.3 社会工程学攻击
数据参考:CISP官方 目录 社会工程学攻击概念社会工程学攻击利用的人性 “弱点”典型社会工程学攻击方式社会工程学攻击防护 一、社会工程学攻击概念 什么是社会工程学攻击 也被称为 "社交工程学" 攻击利用人性弱点 (本能反应、贪婪、易于信任等) 进…...

typeScript 之 Map
工具: PlayGround 源码: GitHub TypeScript Map简介 Map是ES6引入的一种新的数据结构, 它是一只用于存储**键值对(key-value)**的集合。 let map new Map(); let map_1: Map<string, number> new Map(); let map_2: Map<string…...

Apache Doris 入门教程29:文件管理器
文件管理器 Doris 中的一些功能需要使用一些用户自定义的文件。比如用于访问外部数据源的公钥、密钥文件、证书文件等等。文件管理器提供这样一个功能,能够让用户预先上传这些文件并保存在 Doris 系统中,然后可以在其他命令中引用或访问。 名词解释 …...

【佳佳怪文献分享】MVFusion: 利用语义对齐的多视角 3D 物体检测雷达和相机融合
标题:MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion 作者:Zizhang Wu , Guilian Chen , Yuanzhu Gan , Lei Wang , Jian Pu 来源:2023 IEEE International Conference on Robotics and Automat…...
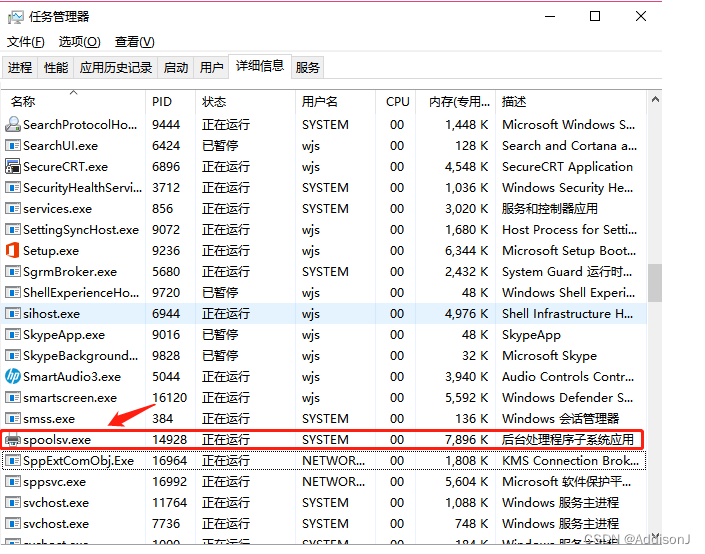
word 应用 打不开 显示一直是正在启动中
word打开来显示一直正在启动中,其他调用word的应用也打不开,网上查了下以后进程关闭spoolsv.exe,就可以正常打开word了...

C51编译器浮点数支持与嵌入式优化实践
1. C51编译器对浮点数的支持解析作为一名在嵌入式领域摸爬滚打多年的老工程师,我深知在8位单片机上进行浮点运算的痛点。最近有同行问我关于Keil C51编译器对浮点数的支持情况,这让我想起自己早年从PL/M-51转向C51时遇到的类似困惑。本文将结合官方文档和…...

hls::stream作为高层次设计中最总要的建模
template<typename __STREAM_T__> class stream{ protected://保护类型std::string _name;//hls::stream的命名,用于做标记使用std::deque<__STREAM_T__> _data;//队列public://对外接口stream(){//无参构造函数static unsigned _counter 1;std::strin…...

AutoGen 框架深度使用指南
AutoGen 框架深度使用指南:从零搭建多智能体协作系统 1. 引入与连接:你为什么需要AutoGen? 1.1 开场:每个开发者都遇到过的痛点 你有没有过这样的经历:用ChatGPT写了一段Python数据分析代码,复制到本地运行报错,再把报错信息粘贴回去让它改,来回折腾5、6次才跑通;要…...

测试工程师必知的数据库知识:这4个数据库技能,测试必备
在软件开发的全生命周期中,数据库是支撑所有业务逻辑运转的核心骨架——用户的每一次点击、每一笔交易、每一条信息的展示,最终都会转化为数据库中数据的增删改查。对于软件测试工程师而言,数据库知识早已不是面试中的加分项,而是…...

代码优化的10个技巧:让你的代码既高效又优雅
对于软件测试从业者而言,编写高质量的测试代码是保障测试效率、提升测试可靠性的核心基础。无论是自动化测试脚本、测试工具开发还是测试框架搭建,臃肿、低效、可读性差的代码不仅会拖慢测试执行速度,还会增加缺陷排查的难度,提升…...

Wannakey:无需支付赎金,从内存中恢复WannaCry加密文件
Wannakey:无需支付赎金,从内存中恢复WannaCry加密文件 【免费下载链接】wannakey Wannacry in-memory key recovery 项目地址: https://gitcode.com/gh_mirrors/wa/wannakey Wannakey是一款专为WannaCry勒索软件受害者设计的内存密钥恢复工具&…...

Qt5 super module网络编程指南:WebSocket、HTTP、MQTT通信实现
Qt5 super module网络编程指南:WebSocket、HTTP、MQTT通信实现 【免费下载链接】qt5 Qt5 super module 项目地址: https://gitcode.com/gh_mirrors/qt/qt5 Qt5 super module是一个功能强大的跨平台应用程序开发框架,提供了丰富的网络编程功能&…...

AI Agent 运行时革命:Session-as-Event-Log 架构解析
1. 这不是新赛道,是 runtime 层的“操作系统时刻”来了你有没有试过让一个 AI 代理连续工作四十分钟?不是闲聊,而是真正在查资料、调 API、写代码、改文档——一环扣一环地推进一个复杂任务。我去年就搭过这么一套系统,用的是当时…...

破解安卓设备标识获取难题:Android_CN_OAID的全栈兼容解决方案
破解安卓设备标识获取难题:Android_CN_OAID的全栈兼容解决方案 【免费下载链接】Android_CN_OAID 安卓设备唯一标识解决方案,可替代移动安全联盟(MSA)统一 SDK 闭源方案。包括国内手机厂商的开放匿名标识(OAID…...

Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界
Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek Spek是一款功能强大的开源音频频谱分析工具,能够将复杂的音频信号转换为直观的彩…...