如何使用索引加速 SQL 查询 [Python 版]
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑器的3D应用场景
假设您正在筛选一本书的页面。而且您希望更快地找到所需的信息。你是怎么做到的?好吧,您可能会查找术语索引,然后跳转到引用特定术语的页面。SQL 中的索引的工作方式与书籍中的索引类似。
在大多数实际系统中,您将针对具有大量行(例如数百万行)的数据库表运行查询。需要全表扫描所有行以检索结果的查询将非常慢。如果您知道必须经常基于某些列查询信息,则可以在这些列上创建数据库索引。这将大大加快查询速度。
那么我们今天会学到什么呢?我们将学习使用 sqlite3 模块在 Python 中连接和查询 SQLite 数据库。我们还将学习如何添加索引,并了解它如何提高性能。
要按照本教程编写代码,您应该在工作环境中安装 Python 3.7+ 和 SQLite。
注意:本教程中的示例和示例输出适用于 Ubuntu LTS 3.10 上的 Python 3.3 和 SQLite37(版本 2.22.04)。
在 Python 中连接到数据库
我们将使用内置的 sqlite3 模块。在开始运行查询之前,我们需要:
- 连接到数据库
- 创建数据库游标以运行查询
若要连接到数据库,我们将使用
来自 sqlite3 模块的 connect() 函数。建立连接后,我们可以调用连接对象来创建数据库游标,如下所示:cursor()
import sqlite3# connect to the db
db_conn = sqlite3.connect('people_db.db')
db_cursor = db_conn.cursor()在这里,我们尝试连接到数据库
people_db.如果数据库不存在,运行上面的代码片段将为我们创建 sqlite 数据库。
创建表并插入记录
现在,我们将在数据库中创建一个表,并用记录填充它。
让我们在数据库中创建一个名为 people 的表,其中包含以下字段:people_db
- 名字
- 电子邮件
- 工作
# main.py
...
# create table
db_cursor.execute('''CREATE TABLE people (id INTEGER PRIMARY KEY,name TEXT,email TEXT,job TEXT)''')...# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()使用伪造器生成合成数据
我们现在必须在表中插入记录。为此,我们将使用 Faker——一个用于合成数据生成的 Python 包——可通过 pip 安装:
$ pip install faker安装faker后,可以将类导入到Python脚本中:Faker
# main.py
...
from faker import Faker
...下一步是生成记录并将其插入人员表。为了让我们知道索引如何加快查询速度,让我们插入大量记录。在这里,我们将插入 100K 条记录;将变量设置为 100000。num_records
然后,我们执行以下操作:
- 实例化一个对象并设置种子,以便我们获得可重现性。
Fakerfake - 使用名字和姓氏获取名称字符串 - 通过调用对象和对象。
first_name()last_name()fake - 通过调用生成假域。
domain_name() - 使用名字和姓氏以及域生成电子邮件字段。
- 使用 获取每个单独记录的作业。
job()
我们生成记录并将其插入到表中:people
# create and insert records
fake = Faker() # be sure to import: from faker import Faker
Faker.seed(42)num_records = 100000for _ in range(num_records):first = fake.first_name()last = fake.last_name()name = f"{first} {last}"domain = fake.domain_name()email = f"{first}.{last}@{domain}"job = fake.job()db_cursor.execute('INSERT INTO people (name, email, job) VALUES (?,?,?)', (name,email,job))# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()
现在,main.py 文件具有以下代码:
# main.py
# imports
import sqlite3
from faker import Faker# connect to the db
db_conn = sqlite3.connect('people_db.db')
db_cursor = db_conn.cursor()# create table
db_cursor.execute('''CREATE TABLE people (id INTEGER PRIMARY KEY,name TEXT,email TEXT,job TEXT)''')# create and insert records
fake = Faker()
Faker.seed(42)num_records = 100000for _ in range(num_records):first = fake.first_name()last = fake.last_name()name = f"{first} {last}"domain = fake.domain_name()email = f"{first}.{last}@{domain}"job = fake.job()db_cursor.execute('INSERT INTO people (name, email, job) VALUES (?,?,?)', (name,email,job))# commit the transaction and close the cursor and db connection
db_conn.commit()
db_cursor.close()
db_conn.close()运行此脚本一次,以使用记录数填充表。num_records
查询数据库
现在我们有了包含 100K 条记录的表,让我们对表运行一个示例查询。people
让我们运行一个查询来:
- 获取职位名称为“产品经理”的记录的名称和电子邮件,以及
- 将查询结果限制为 10 条记录。
我们将使用 time 模块中的默认计时器来获取查询的大致执行时间。
# sample_query.pyimport sqlite3
import timedb_conn = sqlite3.connect("people_db.db")
db_cursor = db_conn.cursor()t1 = time.perf_counter_ns()db_cursor.execute("SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;")res = db_cursor.fetchall()
t2 = time.perf_counter_ns()print(res)
print(f"Query time without index: {(t2-t1)/1000} us")下面是输出:
Output >>
[("Tina Woods", "Tina.Woods@smith.com"),("Toni Jackson", "Toni.Jackson@underwood.com"),("Lisa Miller", "Lisa.Miller@solis-west.info"),("Katherine Guerrero", "Katherine.Guerrero@schmidt-price.org"),("Michelle Lane", "Michelle.Lane@carr-hardy.com"),("Jane Johnson", "Jane.Johnson@graham.com"),("Matthew Odom", "Matthew.Odom@willis.biz"),("Isaac Daniel", "Isaac.Daniel@peck.com"),("Jay Byrd", "Jay.Byrd@bailey.info"),("Thomas Kirby", "Thomas.Kirby@west.com"),
]Query time without index: 448.275 us您还可以通过在命令行运行来调用 SQLite 命令行客户端:sqlite3 db_name
$ sqlite3 people_db.db
SQLite version 3.37.2 2022-01-06 13:25:41
Enter ".help" for usage hints.要获取索引列表,您可以运行:.index
sqlite> .index由于当前没有索引,因此不会列出任何索引。
您还可以像这样检查查询计划:
sqlite> EXPLAIN QUERY PLAN SELECT name, email FROM people WHERE job='Product Manager' LIMIT 10;
QUERY PLAN
`--SCAN people这里的查询计划是扫描所有效率低下的行。
在特定列上创建索引
若要在特定列上创建数据库索引,可以使用以下语法:
CREATE INDEX index-name on table (column(s))假设我们需要经常查找具有特定职位的个人的记录。在作业列上创建索引会有所帮助:people_job_index
# create_index.pyimport time
import sqlite3db_conn = sqlite3.connect('people_db.db')db_cursor =db_conn.cursor()t1 = time.perf_counter_ns()db_cursor.execute("CREATE INDEX people_job_index ON people (job)")t2 = time.perf_counter_ns()db_conn.commit()print(f"Time to create index: {(t2 - t1)/1000} us")Output >>
Time to create index: 338298.6 us尽管创建索引需要这么长时间,但这是一次性操作。运行多个查询时,您仍将获得显著的加速。
现在,如果您在 SQLite 命令行客户端上运行,您将获得:.index
sqlite> .index
people_job_index使用索引查询数据库
如果您现在查看查询计划,您应该能够看到我们现在使用作业列上的索引搜索表:peoplepeople_job_index
sqlite> EXPLAIN QUERY PLAN SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;
QUERY PLAN
`--SEARCH people USING INDEX people_job_index (job=?)您可以重新运行sample_query.py。仅修改语句并查看查询现在运行需要多长时间:print()
# sample_query.pyimport sqlite3
import timedb_conn = sqlite3.connect("people_db.db")
db_cursor = db_conn.cursor()t1 = time.perf_counter_ns()db_cursor.execute("SELECT name, email FROM people WHERE job='Product manager' LIMIT 10;")res = db_cursor.fetchall()
t2 = time.perf_counter_ns()print(res)
print(f"Query time with index: {(t2-t1)/1000} us")下面是输出:
Output >>
[("Tina Woods", "Tina.Woods@smith.com"),("Toni Jackson", "Toni.Jackson@underwood.com"),("Lisa Miller", "Lisa.Miller@solis-west.info"),("Katherine Guerrero", "Katherine.Guerrero@schmidt-price.org"),("Michelle Lane", "Michelle.Lane@carr-hardy.com"),("Jane Johnson", "Jane.Johnson@graham.com"),("Matthew Odom", "Matthew.Odom@willis.biz"),("Isaac Daniel", "Isaac.Daniel@peck.com"),("Jay Byrd", "Jay.Byrd@bailey.info"),("Thomas Kirby", "Thomas.Kirby@west.com"),
]Query time with index: 167.179 us我们看到查询现在大约需要 167.179 微秒来执行。
性能改进
对于我们的示例查询,使用 index 进行查询的速度大约快 2.68 倍。我们在执行时间中获得了 62.71% 的百分比加速。
您还可以尝试运行更多查询:涉及对作业列进行筛选并查看性能改进的查询。
另请注意:由于我们仅在作业列上创建了索引,因此,如果您运行的查询涉及其他列,则查询的运行速度不会比没有索引时快。
总结和后续步骤
我希望本指南能帮助您了解在频繁查询的列上创建数据库索引如何显著加快查询速度。这是对数据库索引的介绍。您还可以创建多列索引、同一列的多个索引等等。
原文链接:如何使用索引加速 SQL 查询 [Python 版] (mvrlink.com)
相关文章:

如何使用索引加速 SQL 查询 [Python 版]
推荐:使用 NSDT场景编辑器助你快速搭建可二次编辑器的3D应用场景 假设您正在筛选一本书的页面。而且您希望更快地找到所需的信息。你是怎么做到的?好吧,您可能会查找术语索引,然后跳转到引用特定术语的页面。SQL 中的索引的工作方…...

Oracle 开发篇+Java通过DRCP访问Oracle数据库
标签:DRCP、Database Resident Connection Pooling、数据库驻留连接池释义:DRCP(全称Database Resident Connection Pooling)数据库驻留连接池(Oracle自己的数据库连接池技术) ★ Oracle开启并配置DRCP sq…...
在安装 ONLYOFFICE 协作空间社区版时如何使用额外脚本参数
ONLYOFFICE 协作空间社区版是免费的文档中心工具,可帮助您将用户与文档聚合至同一处,提高协作效率。 ONLYOFFICE 协作空间主要功能 使用 ONLYOFFICE 协作空间,您可以: 邀请他人,协作和沟通完成工作创建协作房间&…...

ChatGPT在智能家居控制和环境管理中的应用如何?
智能家居控制和环境管理是近年来在科技领域迅速发展的重要领域之一。智能家居技术通过将物联网、人工智能和自动化技术相结合,实现了家居设备的智能化、自动化控制和远程管理。ChatGPT作为强大的自然语言处理模型,在智能家居控制和环境管理方面具有广泛的…...
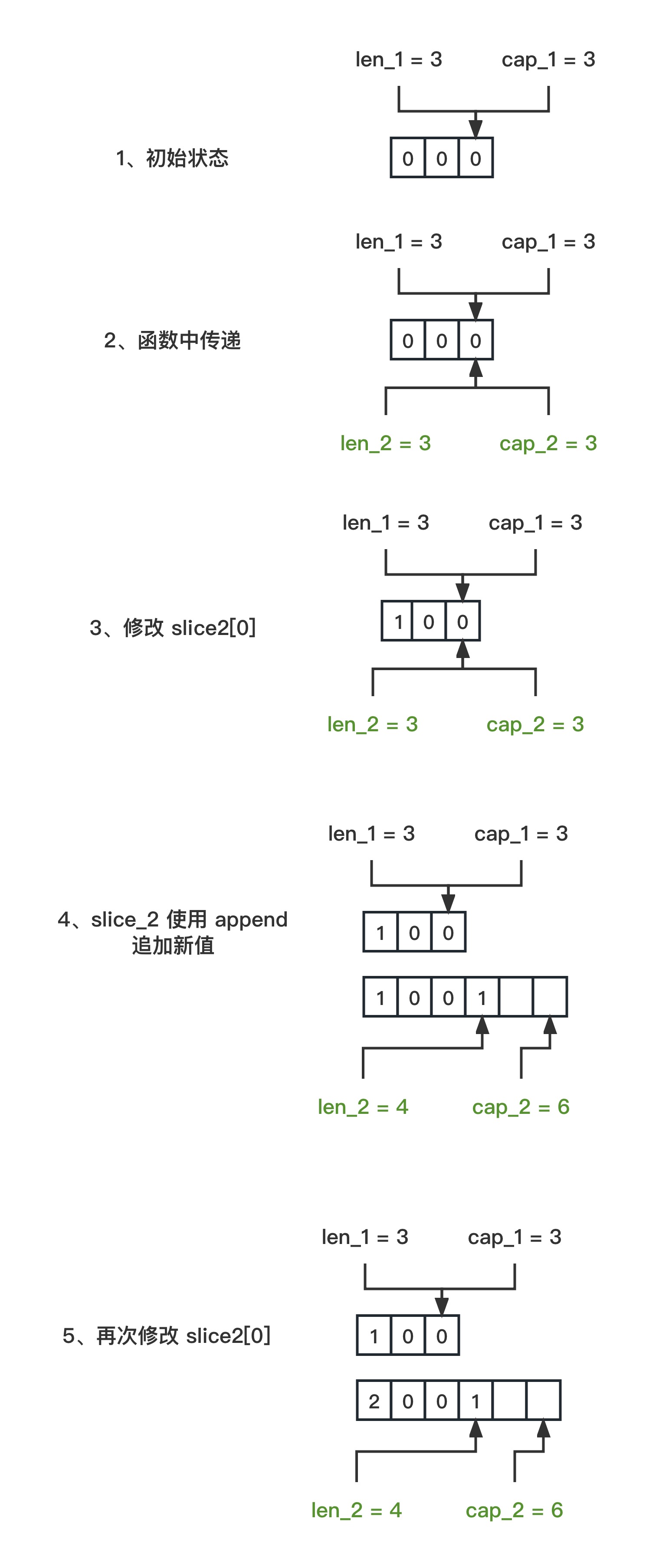
理解 Go 中的切片:append 操作的深入分析(篇2)
理解 Go 语言中 slice 的性质对于编程非常有益。下面,我将通过代码示例来解释切片在不同函数之间传递并执行 append 操作时的具体表现。 本篇为第 2 篇,当切片的容量 cap 不够时 func main() {// slice1 当前长度为 3,容量大小也为 3slice1 :…...

GPT-4 如何为我编写测试
ChatGPT — 每个人都在谈论它,每个人都有自己的观点,玩起来很有趣,但我们不是在这里玩— 我想展示一些实际用途,可以帮助您节省时间并提高效率。 我在本文中使用GPT-4 动机 我们以前都见过这样的情况——代码覆盖率不断下降的项目——部署起来越来越可怕,而且像朝鲜一样…...
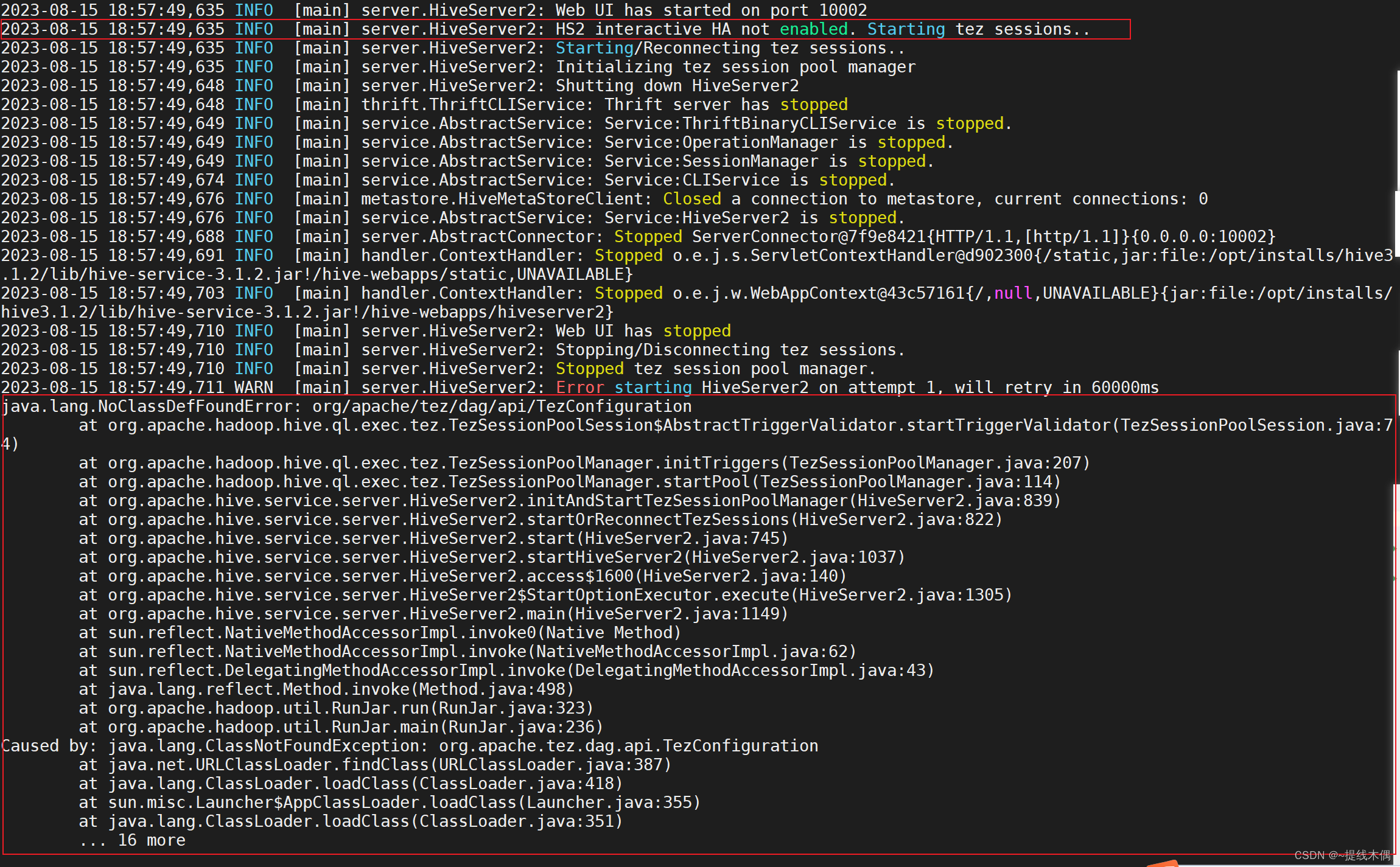
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration
错误: java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfigurationat org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolSession$AbstractTriggerValidator.startTriggerValidator(TezSessionPoolSession.java:74)at org.apache.hadoop.hive.ql.e…...

19、SQL注入之SQLMAP绕过WAF
目录 逻辑层1、逻辑问题2、性能问题 白名单方式一:IP白名单方式二:静态资源方式三:url白名单方式四: 爬虫白名单 sqlmap在测试漏洞的时候,选择了no,它就不会去测试其它的了,我们一般选择yes,为了…...

Redis对象类型和结构、内存回收、对象共享
对象类型和结构 在Redis中,无论是键key还是值value都是一个对象,每次对Redis数据库创建一个新的键值对时,就至少会创建两个对象。 常见的对象类型有: 字符串列表哈希集合有序集合 这些对象在Redis中统一用一个结构体redisObjec…...

标准模板库STL——容器适配器-stack/queue/priority_queue
目录 容器适配器的理解 容器适配器的实现与使用 三类容器适配器 基本概述 示例代码 容器适配器的理解 容器适配器对底层容器进行封装,不具备自己的数据结构 容器适配器的方法全都由底层容器实现,不支持迭代器 容器适配器的实现与使用 // 容器适配器…...
)
Golang实现完整聊天室(内附源码)
项目github地址: 由于我们项目的需要,我就研究了一下关于websocket的相关内容,去实现一个聊天室的功能。 经过几天的探索,现在使用Gin框架实现了一个完整的聊天室消息实时通知系统。有什么不完善的地方还请大佬指正。 用到的技术…...
WSL2 ubuntu子系统OpenCV调用本机摄像头的RTSP视频流做开发测试
文章目录 前言一、Ubuntu安装opencv库二、启动 Windows 本机的 RTSP 视频流下载解压 EasyDarwin查看本机摄像头设备开始推流 三、在ubuntu 终端编写代码创建目录及文件创建CMakeLists.txt文件启动 cmake 配置并构建 四、结果展示启动图形界面在图形界面打开终端找到 rtsp_demo运…...
20230814让惠普(HP)锐14 新AMD锐龙电脑不联网进WIN11进系统
20230814让惠普(HP)锐14 新AMD锐龙电脑不联网进WIN11进系统 2023/8/14 17:19 win11系统无法跳过联网 https://www.xpwin7.com/jiaocheng/28499.html Win11开机联网跳过不了怎么办?Win11开机联网跳过不了解决方法 Win11开机联网跳过不了怎么办?Win11开机…...

基于ScrollView的下拉刷新
基于ScrollView的下拉刷新 组件使用 组件 import React, {useState} from react; import {ScrollView, RefreshControl, Platform} from react-native;const RefreshComponent ({children, onRefresh, onScroll}) > {const [refreshing, setRefreshing] useState(false);…...
强训第31天
选择 传输层叫段 网络层叫包 链路层叫帧 A 2^16-2 C D C 70都没收到,确认号代表你该从这个号开始发给我了,所以发70而不是71 B D C 248&123120 OSI 物理层 数据链路层 网络层 传输层 会话层 表示层 应用层 C 记一下304读取浏览器缓存 502错误网关 编…...

什么是Java中的策略模式?
Java中的策略模式是一种行为设计模式,它允许您在不改变客户端代码的情况下,在运行时动态地切换行为。这是一种非常有用的模式,因为它允许您在运行时根据需要更改算法或行为。 策略模式通常涉及到一个或多个策略类,每个策略类都实…...

【Visual Studio Code】--- Win11 安装 VS Code 超详细
Win11 安装 VS Code 超详细 概述一、下载 Vscode二、安装 Vscode 概述 一个好的文章能够帮助开发者完成更便捷、更快速的开发。书山有路勤为径,学海无涯苦作舟。我是秋知叶i、期望每一个阅读了我的文章的开发者都能够有所成长。 一、下载 Vscode Vscode官网 二、…...
每天一道leetcode:797. 所有可能的路径(图论中等深度优先遍历)
今日份题目: 给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序) graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节…...
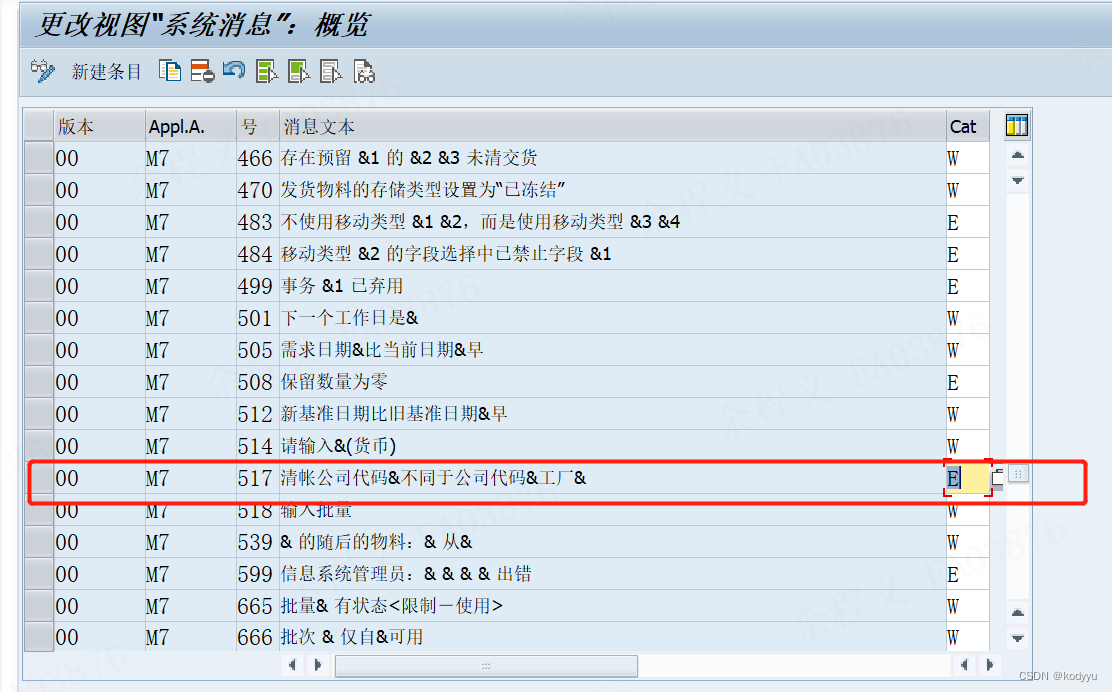
创建预留成本中心与指定工厂不一致
创建预留成本中心与指定工厂不一致 这种情况SAP会警告提示,可以强制通过。 如果公司不允许跨公司领料,可以将消息号 M7517的类型从W改为为E tcode:OMCQ SPRO->物料管理->库存管理和实际库存->定义系统消息的属性->系统信息设置...

SCF金融公链新加坡启动会 创新驱动未来
新加坡迎来一场引人瞩目的金融科技盛会,SCF金融公链启动会于2023年8月13日盛大举行。这一受瞩目的活动将为金融科技领域注入新的活力,并为广大投资者、合作伙伴以及关注区块链发展的人士提供一个难得的交流平台。 在SCF金融公链启动会上, Wil…...

Ubuntu18.04 配置SNPE并将ONNX模型转为DLC
文章目录0.前提条件1.ONNX下载安装2.SNPE下载3.安装SNPE相关依赖4.设置环境变量5.将ONNX模型转为DLC0.前提条件 已安装好Anaconda和Python3.10 1.ONNX下载安装 ONNX官方链接: https://github.com/onnx/onnx#installation 根据官方指导,使用Conda进行安…...

Windows热键冲突终结者:Hotkey Detective一键定位占用程序
Windows热键冲突终结者:Hotkey Detective一键定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

如何在3分钟内将HTML完美转换为Word文档:html-to-docx终极指南
如何在3分钟内将HTML完美转换为Word文档:html-to-docx终极指南 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 你是否曾经需要将网页内容转换为专业的Word文档,却发现格式完全…...

AI教材编写攻略:低查重AI工具实测,轻松生成25万字优质教材!
AI教材写作工具助力教学资源创作 在撰写教材的过程中,资料的支持是必不可少的,但传统的资料整合方式已经无法满足当前的需求。以前,我们需要从各个渠道,比如课标文件、学术文章和教学实例,去花费几天时间筛选出有价值…...

DataRoom开源大屏设计器:零代码打造专业数据可视化大屏的终极指南
DataRoom开源大屏设计器:零代码打造专业数据可视化大屏的终极指南 【免费下载链接】DataRoom 🔥基于SpringBoot、MyBatisPlus、ElementUI、G2Plot、Echarts等技术栈的大屏设计器,具备目录管理、DashBoard设计、预览能力,支持MySQL…...

Godot原生强化学习集成:零Python实现AI训练与部署
1. 这不是又一个“Hello World”式教程:为什么GodotRL的组合值得你花10分钟认真看我第一次在Godot Asset Library里点开那个标着“Reinforcement Learning Agent”的插件时,心里是带着怀疑的——毕竟过去三年里,我试过七种不同方式把强化学习…...

Godot RL Agents实战:游戏开发者可用的轻量强化学习落地方案
1. 这不是“又一个强化学习教程”,而是给游戏开发者准备的RL落地切口你有没有过这样的经历:在GitHub上看到一个标着“Godot RL”的仓库,点进去发现README里全是PyTorch张量形状、Gymnasium环境注册、PPO超参数表格,再往下翻是几行…...
部署步骤 小白避坑手册)
2026 最新 OpenClaw(小龙虾)部署步骤 小白避坑手册
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工(2026 最新版) ✨ 前言 2026 年爆火的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭 “本…...

终极ANI-RSS界面定制指南:打造专业级追番体验
终极ANI-RSS界面定制指南:打造专业级追番体验 【免费下载链接】ani-rss 基于RSS自动追番、订阅、下载、刮削、洗版 项目地址: https://gitcode.com/gh_mirrors/an/ani-rss ANI-RSS作为一款基于RSS的自动追番、订阅、下载工具,为动漫爱好者提供了强…...

告别手动敲变量!用Python脚本批量处理施耐德Control Expert变量表
用Python脚本解放双手:高效处理施耐德Control Expert变量表全攻略 在工业自动化领域,施耐德的Control Expert(原Unity Pro)是处理中高端PLC编程的主流软件。对于经常需要管理成百上千个变量的工程师来说,手动操作不仅耗…...