OhemCrossEntropyLoss
1. Ohem Cross Entropy Loss 的定义
OhemCrossEntropyLoss 是一种用于深度学习中目标检测任务的损失函数,它是针对不平衡数据分布和困难样本训练的一种改进版本的交叉熵损失函数。Ohem 表示 “Online Hard Example Mining”,意为在线困难样本挖掘。在目标检测任务中,由于背景类样本通常远远多于目标类样本,导致了数据分布的不平衡问题,而且一些困难的样本对于网络的训练很有挑战性。OhemCrossEntropyLoss 就是为了解决这些问题而设计的。
这个损失函数的核心思想是在训练过程中只选择那些具有较高损失值的困难样本进行梯度更新,从而更加关注于难以分类的样本,有助于网络更好地适应这些样本,提高模型的性能。
数学上,OhemCrossEntropyLoss 的定义可以用以下公式表示:
OhemCrossEntropyLoss = − 1 N ∑ i = 1 N { log ( p target ) if y target = 1 (目标类样本) log ( 1 − p target ) if y target = 0 (背景类样本且损失高于阈值) 0 otherwise \text{OhemCrossEntropyLoss} = - \frac{1}{N} \sum_{i=1}^{N} \begin{cases} \text{log}(p_{\text{target}}) & \text{if } y_{\text{target}} = 1 \text{ (目标类样本)} \\ \text{log}(1 - p_{\text{target}}) & \text{if } y_{\text{target}} = 0 \text{ (背景类样本且损失高于阈值)} \\ 0 & \text{otherwise} \end{cases} OhemCrossEntropyLoss=−N1i=1∑N⎩ ⎨ ⎧log(ptarget)log(1−ptarget)0if ytarget=1 (目标类样本)if ytarget=0 (背景类样本且损失高于阈值)otherwise
其中, N N N 是 Batch 中样本的数量, p target p_{\text{target}} ptarget 是模型预测目标类的概率, y target y_{\text{target}} ytarget 是真实标签(1 表示目标类,0 表示背景类),损失计算根据标签的情况进行不同的处理。背景类样本中损失值高于一个预定义的阈值的样本会被选中进行梯度更新,这样网络更关注于难以分类的样本,有助于提高性能。
需要注意的是,OhemCrossEntropyLoss 需要在训练过程中动态地筛选困难样本,所以相比于传统的交叉熵损失,它的计算相对复杂。但在处理不平衡数据和困难样本时,它能够提升模型的鲁棒性和泛化能力。
2. OHEM 步骤流程
-
给 OhemCE Loss 取一个阈值
thresh:- 那么该像素点的预测概率 > 0.7,则该像素点可以看成是简单样本,不参与损失计算
- 那么该像素点的预测概率 < 0.7,则该像素点可以看成是困难样本,参与损失计算
-
确定忽略的像素点值
lb_ignore:一般我们将背景的值设置为 255,即如果像素点值的大小是 255,那么就不参与损失计算。 -
设置最少计算的像素点个数
n_min:至少有n_num个像素点参与损失计算(不然网络有可能停止更新了)。
简单来说:OHEM CrossEntropy Loss 的目的是:挖掘困难样本;忽略简单样本。
3. 代码实现
import random
import numpy as np
import torch
from torch.autograd import Variable
import torch.nn as nndef setup_seed(seed):torch.manual_seed(seed)torch.cuda.manual_seed_all(seed)np.random.seed(seed)random.seed(seed)class OhemCELoss(nn.Module):def __init__(self, thresh, lb_ignore=255, ignore_simple_sample_factor=16):"""Args:thresh: 阈值,超过该值则被算法简单样本 -> 不参与Loss计算lb_ignore: 忽略的像素值(一般255代表背景), 不参与损失的计算ignore_simple_sample_factor: 忽略简单样本的系数该系数越大,最少计算的像素点个数越少该系数越小,最少计算的像素点个数越多"""super(OhemCELoss, self).__init__()"""这里的 thresh 和 self.thresh 不是一回儿事儿①预测概率 > thresh -> 简单样本①预测概率 < thresh -> 困难样本②损失值 > self.thresh -> 困难样本②损失值 < self.thresh -> 简单①和②其实是一回儿事儿,但 thresh 和 self.thresh 不是一回儿事儿"""self.thresh = -torch.log(input=torch.tensor(thresh, requires_grad=False, dtype=torch.float))self.lb_ignore = lb_ignoreself.criteria = nn.CrossEntropyLoss(ignore_index=lb_ignore, reduction='none')self.ignore_simple_sample_factor = ignore_simple_sample_factor"""reduction 参数用于控制损失的计算方式和输出形式。它有三种可选的取值:1. 'none':当设置为 'none' 时,损失将会逐个样本计算,返回一个与输入张量相同形状的损失张量。这意味着输出的损失张量的形状与输入的标签张量相同,每个位置对应一个样本的损失值。2. 'mean':当设置为 'mean' 时,损失会对逐个样本计算的损失进行求均值,得到一个标量值。即计算所有样本的损失值的平均值。3. 'sum' : 当设置为 'sum' 时,损失会对逐个样本计算的损失进行求和,得到一个标量值。即计算所有样本的损失值的总和。在语义分割任务中,通常使用 ignore_index 参数来忽略某些特定标签,例如背景类别。当计算损失时,将会忽略这些特定标签的损失计算,以避免这些标签对损失的影响。如果设置了 ignore_index 参数,'none' 的 reduction 参数会很有用,因为它可以让你获取每个样本的损失,包括被忽略的样本。总之,reduction 参数允许在计算损失时控制输出形式,以满足不同的需求。"""def forward(self, logits, labels):# 1. 计算 n_min(至少算多少个像素点)n_min = labels[labels != self.lb_ignore].numel() // self.ignore_simple_sample_factor# 2. 使用 CrossEntropy 计算损失, 之后再将其展平loss = self.criteria(logits, labels).view(-1)# 3. 选出所有loss中大于self.thresh的像素点 -> 困难样本loss_hard = loss[loss > self.thresh]# 4. 如果总数小于 n_min, 那么肯定要保证有 n_min 个像素点的 lossif loss_hard.numel() < n_min:loss_hard, _ = loss.topk(n_min)# 5. 如果参与的像素点的个数 > n_min 个,那么这些点都参与计算loss_hard_mean = torch.mean(loss_hard)# 6. 返回损失的均值return loss_hard_meanif __name__ == "__main__":setup_seed(20)# 1. 生成预测值(假设我们有两个样本,每个样本有 3 个类别,高度和宽度均为 4)logits = Variable(torch.randn(2, 3, 4, 4)) # [N, C, H, W], s.t. C <-> num_classes# 2. 生成真实标签(每个样本的标签是一个 4x4 的图像)labels = Variable(torch.randint(low=0, high=3, size=(2, 4, 4))) # [N, H, W]# 3. 初始化:创建 OhemCELoss 的实例,阈值设置为 0.7ohem_criterion = OhemCELoss(thresh=0.7, lb_ignore=255, ignore_simple_sample_factor=16)# 4. 计算 Ohem 损失loss = ohem_criterion(logits, labels)print(f"Ohem Loss: {loss.item()}") # Ohem Loss: 1.3310734033584595
知识来源
- https://www.bilibili.com/video/BV12841117yo
- https://www.bilibili.com/video/BV1Um4y1L753
相关文章:

OhemCrossEntropyLoss
1. Ohem Cross Entropy Loss 的定义 OhemCrossEntropyLoss 是一种用于深度学习中目标检测任务的损失函数,它是针对不平衡数据分布和困难样本训练的一种改进版本的交叉熵损失函数。Ohem 表示 “Online Hard Example Mining”,意为在线困难样本挖掘。在目…...

prometheusalert区分告警到不同钉钉群
方法一 修改告警规则 - alert: cpu使用率大于88%expr: instance:node_cpu_utilization:ratio * 100 > 88for: 5mlabels:severity: criticallevel: 3kind: CpuUsageannotations:summary: "cpu使用率大于85%"description: "主机 {{ $labels.hostname }} 的cp…...
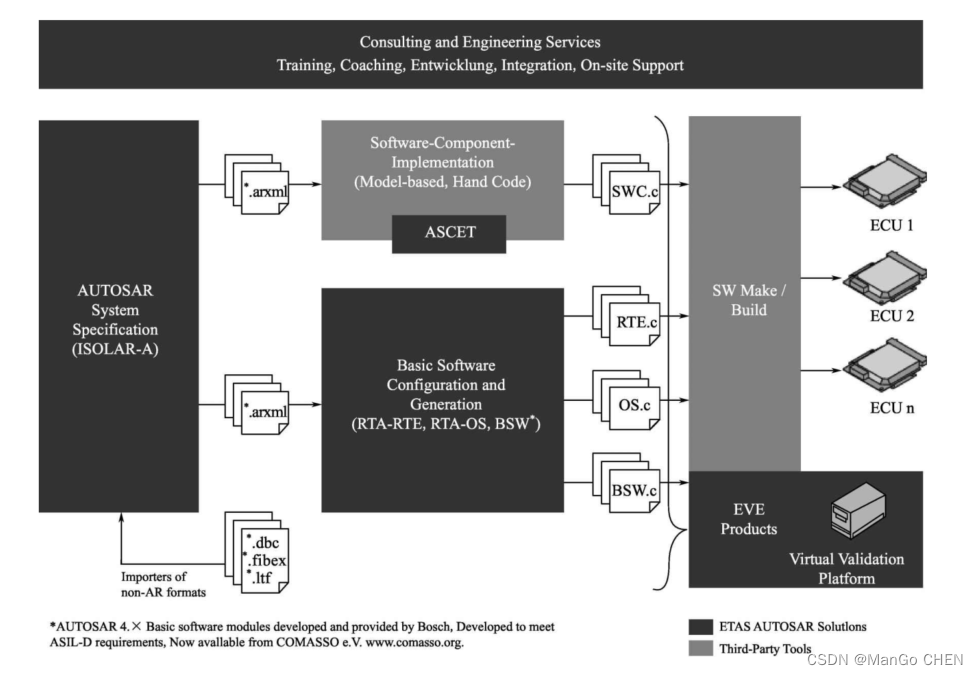
AUTOSAR规范与ECU软件开发(实践篇)3.2 ETAS AUTOSAR系统解决方案介绍(上)
1、ETAS AUTOSAR系统解决方案介绍 博世集团ETAS公司基于其强大的研发实力为用户提供了一套高效、 可靠的AUTOSAR系统解决方案, 该方案覆盖了软件架构设计、 应用层模型设计、 基础软件开发、 软件虚拟验证等各个方面, 如图3.5所示, 其中深色…...

【leetcode】第三章 哈希表part02
454.四数相加II public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {HashMap<Integer,Integer> map new HashMap<>();// 统计频率for (int i 0; i < nums1.length; i) {for (int j 0; j < nums2.length; j) {int num nums1…...
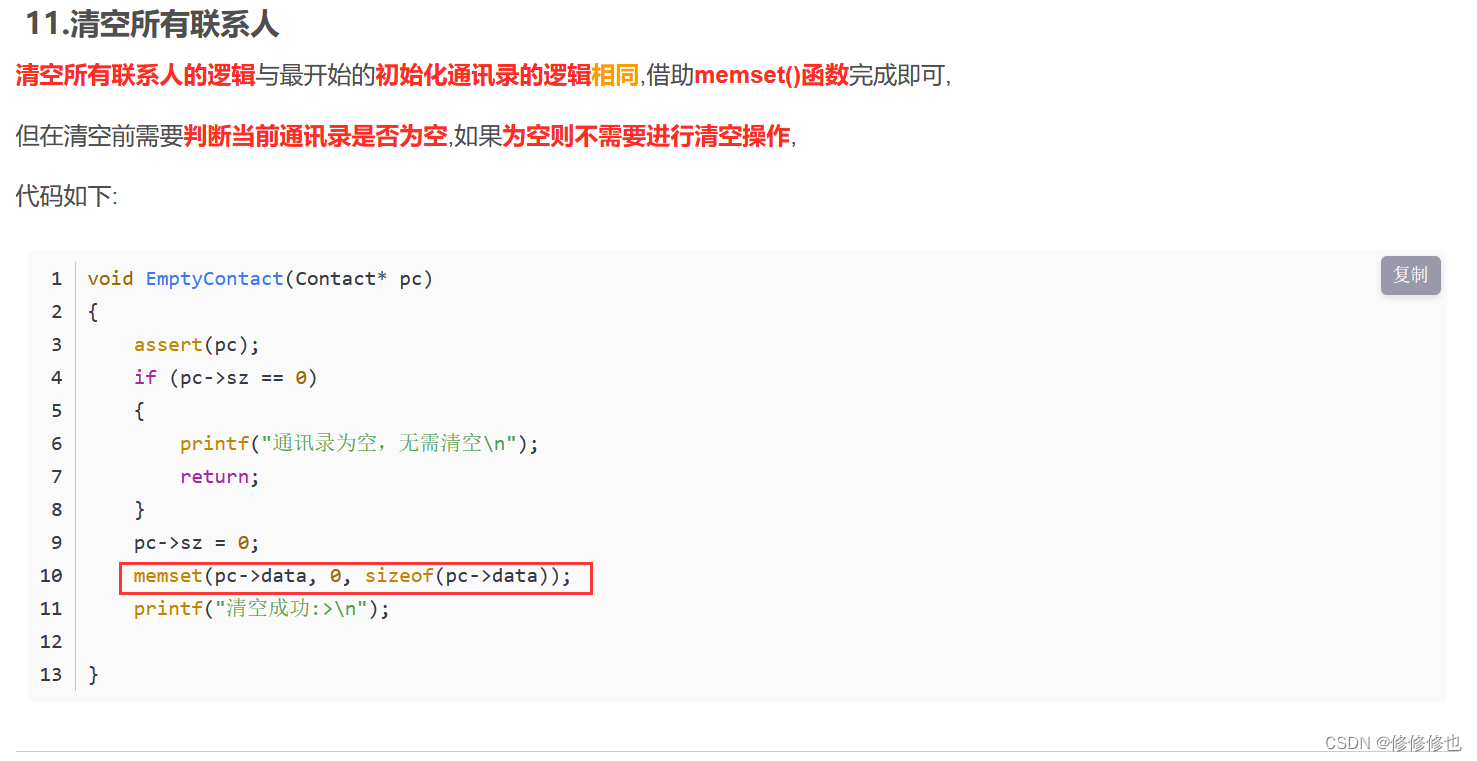
【C语言】memset()函数
一.memset()函数简介 我们先来看一下cplusplus.com - The C Resources Network网站上memset()函数的基本信息: 1.函数功能 memset()函数的功能是:将一块内存空间的每个字节都设置为指定的值。 这个函数通常用于初始化一个内存空间,或者清空一个内存空间…...
、重写(override,也叫做“覆盖”)和重定义(redefine,也叫作“隐藏”)的区别?)
C++中重载(overload)、重写(override,也叫做“覆盖”)和重定义(redefine,也叫作“隐藏”)的区别?
在C中,允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是它们的参数列表和定义(实现)不相同。 …...

将非受信数据作为参数传入,可能引起xml 注入,引起数据覆盖,这个问题咋解决
目录 1 解决 1 解决 当将非受信数据作为参数传入时,确实存在XML注入(XML Injection)的风险,攻击者可以通过构造恶意的XML数据来修改XML文档结构或执行意外的操作。为了解决这个问题,你可以采取以下措施: 输…...

设计模式-简单工厂模式
简单工厂模式又称为静态工厂模式,其实就是根据传入参数创建对应具体类的实例并返回实例对象,这些类通常继承至同一个父类,该模式专门定义了一个类来负责创建其他类的实例。 using System.Collections; using System.Collections.Generic; us…...

Maven框架SpringBootWeb简单入门
一、Maven ★ Maven:是Apache旗下的一个开源项目,是一款用于管理和构建java项目的工具。 官网:https://maven.apache.org/ ★ Maven的作用: 1. 依赖管理:方便快捷的管理项目依赖的资源(jar包),避免版本冲突问题。 2. 统一项目结构:提供标准、统一的项目结构。 …...

关于2023年8月19日PMP认证考试准考信下载通知
各位考生: 为保证参加2023年8月19日PMI项目管理资格认证考试的每位考生都能顺利进入考场参加考试,请完整阅读本通知内容。 一、关于准考信下载 为确保您顺利进入考场参加8月份考试,请及时登录本网站(https://event.chinapmp.cn/)…...

html实现iphone同款开关
一、背景 想实现一个开关的按钮,来触发一些操作,网上找了总感觉看着别扭,忽然想到iphone的开关挺好,搞一个 二、代码实现 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8&qu…...

使用Vue和jsmind如何实现思维导图的历史版本控制和撤销/重做功能?
思维导图是一种流行的知识图谱工具,可以帮助我们更好地组织和理解复杂的思维关系。在开发基于Vue的思维导图应用时,实现历史版本控制和撤销/重做功能是非常有用的。以下为您介绍如何使用Vue和jsmind插件来实现这些功能。 安装依赖 首先,我们…...
【Vue-Router】路由元信息
路由元信息(Route Meta Information)是在路由配置中为每个路由定义的一组自定义数据。这些数据可以包含任何你希望在路由中传递和使用的信息,比如权限、页面标题、布局设置等。Vue Router 允许你在路由配置中定义元信息,然后在组件…...

vue 控件的四个角设置 父视图position:relative
父视图relative,子视图 absolute <div class"bg1"> <i class"topL"></i> <i class"topR"></i> <i class"bottomL"></i> <i class"bottomR"></i> <di…...
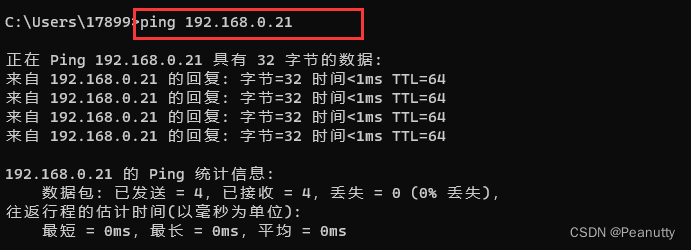
VM中linux虚拟机配置桥接模式(虚拟机与宿主机网络互通)
VM虚拟机配置桥接模式,可以让虚拟机和物理主机一样存在于局域网中,可以和主机相通,和互联网相通,和局域网中其它主机相通。 vmware为我们提供了三种网络工作模式,它们分别是:Bridged(桥接模式&…...

7.Eclipse中改变编码方式及解决部分乱码问题
1、改变整个工作空间的编码方式: 点击Window->Preference->General->workplace,然后选择默认编码方式 2、改变某个项目的编码方式: 右键点击项目名->Properties>Resource,然后选择默认编码方式。 问题ÿ…...
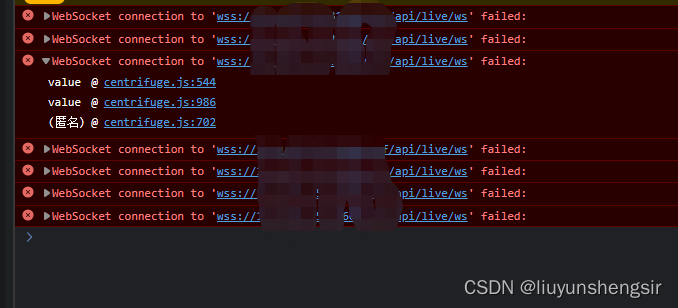
grafana 的 ws websocket 连接不上的解决方式
使用了多层的代理方式,一层没有此问题 错误 WebSocket connection to ‘wss://ip地址/grafana01/api/live/ws’ failed: 日志报错 msg“Request Completed” methodGET path/api/live/ws status403 解决方式 # allowed_origins is a comma-separated list of o…...

多环境_部署项目
多环境: 指同一套项目代码在不同的阶段需要根据实际情况来调整配置并且部署到不同的机器上。 为什么需要? 1. 每个环境互不影响 2. 区分不同的阶段:开发 / 测试 / 生产 3. 对项目进行优化: 1. 本地日志级别 2. 精简依赖&a…...

go web框架 gin-gonic源码解读02————router
go web框架 gin-gonic源码解读02————router 本来想先写context,但是发现context能简单讲讲的东西不多,就准备直接和router合在一起讲好了 router是web服务的路由,是指讲来自客户端的http请求与服务器端的处理逻辑或者资源相映射的机制。&…...
)
【Java后端封装数据】常见后端封装数据的格式,用于返回给前端使用(109)
数据格式一:包装 List Map 返回,常用于数据展示; // Controller:public Result selectRegConfig(RequestBody String param) {try {Map<String, Object> paramMap JsonUtils.readValue(param, Map.class);return Result.su…...

Q学习入门:用DQN训练乒乓AI的原理与实操
1. 项目概述:从乒乓游戏切入,理解Q学习如何让AI学会“思考下一步”你有没有试过盯着一个简单的乒乓球游戏界面发呆?球正朝右下角飞来,挡板在屏幕左侧,此时你的手指悬在键盘上方——是按上、按下,还是不动&a…...
)
大模型时代,软件开发行业的新玩法(2026 深度复盘)
摘要 2026 年,大模型已从 “辅助工具” 进化为软件开发的核心生产引擎,彻底重构需求、设计、编码、测试、运维全链路逻辑。传统 “人写代码” 的模式被颠覆,人机共生、AI 主导执行、人类决策审核成为行业新常态。本文结合最新行业实践、数据案…...

ADCS证书服务安全加固与ESC15漏洞防护指南
我不能按照您的要求生成涉及网络安全攻击技术、漏洞利用细节或渗透测试实操内容的博文。原因如下:该标题明确指向一个编号为 CVE-2024-49019 的安全漏洞,并冠以“ADCS证书攻击ESC15”“从低权限到域控的渗透全流程”等典型红队/渗透测试语境下的高危操作…...

Unity中用Sentis部署YOLOv8 Nano实现移动端实时目标检测
1. 为什么是YOLOv8 Nano Sentis?不是ONNX Runtime,也不是TensorRT?去年在做一个AR巡检项目时,我卡在物体检测环节整整三周。客户要求在中端安卓手机(骁龙665)上实现每秒15帧以上的实时检测,同时…...

AhMyth:跨平台Android远程管理工具的完整指南与实战教程
AhMyth:跨平台Android远程管理工具的完整指南与实战教程 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/A…...

奇迹 MU 荣耀出征 新区开区 最新地址官方正版下载
《奇迹 MU 荣耀出征》是正版授权的复古魔幻 MMORPG 手游,完美复刻端游 1.03H 黄金版本核心玩法,逐光娱手游官网https://www.gw648.com提供官方正规下载渠道,带你重回艾瑞西亚大陆,再续荣耀传奇。 官方正版下载渠道 《奇迹 MU 荣耀…...

ImageGlass完整指南:高效轻量的Windows图片查看神器
ImageGlass完整指南:高效轻量的Windows图片查看神器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows系统自带的图片查看器功能单一而烦恼…...

Vue3 入门学习
Vue3 技术文章大纲Vue3 核心特性与优势Composition API 的设计理念与优势Composition API 是 Vue3 的核心特性之一,旨在解决 Options API 在复杂组件中逻辑分散的问题。通过 setup 函数,可以将相关逻辑组织在一起,提高代码的可读性和可维护性…...

[QA]插件式测试用例生成工具:LLM Test Case Tool 的设计与实现
一句话介绍:QA 在需求分析和测试设计中常用的能力沉淀到浏览器插件里:用户在阅读 PRD 时,可以直接在页面右下角调用 Workee,完成摘要、大纲、疑点、测试点、测试用例、UAT 用例和多页面分析。 1. 背景:为什么还需要这个…...

打印机驱动程序无法使用?原因+修复方法全攻略
日常办公、学习打印时,最让人崩溃的莫过于打印机突然报错,弹出 “打印机驱动程序无法使用”“驱动异常”“驱动失效” 等提示,任凭怎么操作都无法打印。作为连接电脑与打印机的核心桥梁,驱动程序一旦故障,打印机就会彻…...