深度学习实战基础案例——卷积神经网络(CNN)基于SqueezeNet的眼疾识别|第1例
文章目录
- 前言
- 一、数据准备
- 1.1 数据集介绍
- 1.2 数据集文件结构
- 二、项目实战
- 2.1 数据标签划分
- 2.2 数据预处理
- 2.3 构建模型
- 2.4 开始训练
- 2.5 结果可视化
- 三、数据集个体预测
前言
SqueezeNet是一种轻量且高效的CNN模型,它参数比AlexNet少50倍,但模型性能(accuracy)与AlexNet接近。顾名思义,Squeeze的中文意思是压缩和挤压的意思,所以我们通过算法的名字就可以猜想到,该算法一定是通过压缩模型来降低模型参数量的。当然任何算法的改进都是在原先的基础上提升精度或者降低模型参数,因此该算法的主要目的就是在于降低模型参数量的同时保持模型精度。
我的环境:
- 基础环境:python3.7
- 编译器:pycharm
- 深度学习框架:pytorch
- 数据集代码获取:链接(提取码:2357 )
一、数据准备
本案例使用的数据集是眼疾识别数据集iChallenge-PM。
1.1 数据集介绍
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
- training.zip:包含训练中的图片和标签
- validation.zip:包含验证集的图片
- valid_gt.zip:包含验证集的标签
该数据集是从AI Studio平台中下载的,具体信息如下:

1.2 数据集文件结构
数据集中共有三个压缩文件,分别是:
- training.zip
├── PALM-Training400
│ ├── PALM-Training400.zip
│ │ ├── H0002.jpg
│ │ └── ...
│ ├── PALM-Training400-Annotation-D&F.zip
│ │ └── ...
│ └── PALM-Training400-Annotation-Lession.zip└── ...
- valid_gt.zip:标记的位置 里面的PM_Lable_and_Fovea_Location.xlsx就是标记文件
├── PALM-Validation-GT
│ ├── Lession_Masks
│ │ └── ...
│ ├── Disc_Masks
│ │ └── ...
│ └── PM_Lable_and_Fovea_Location.xlsx- validation.zip:测试数据集
├── PALM-Validation
│ ├── V0001.jpg
│ ├── V0002.jpg
│ └── ...二、项目实战
项目结构如下:
2.1 数据标签划分
该眼疾数据集格式有点复杂,这里我对数据集进行了自己的处理,将训练集和验证集写入txt文本里面,分别对应它的图片路径和标签。
import os
import pandas as pd
# 将训练集划分标签
train_dataset = r"F:\SqueezeNet\data\PALM-Training400\PALM-Training400"
train_list = []
label_list = []train_filenames = os.listdir(train_dataset)for name in train_filenames:filepath = os.path.join(train_dataset, name)train_list.append(filepath)if name[0] == 'N' or name[0] == 'H':label = 0label_list.append(label)elif name[0] == 'P':label = 1label_list.append(label)else:raise('Error dataset!')with open('F:/SqueezeNet/train.txt', 'w', encoding='UTF-8') as f:i = 0for train_img in train_list:f.write(str(train_img) + ' ' +str(label_list[i]))i += 1f.write('\n')
# 将验证集划分标签
valid_dataset = r"F:\SqueezeNet\data\PALM-Validation400"
valid_filenames = os.listdir(valid_dataset)
valid_label = r"F:\SqueezeNet\data\PALM-Validation-GT\PM_Label_and_Fovea_Location.xlsx"
data = pd.read_excel(valid_label)
valid_data = data[['imgName', 'Label']].values.tolist()with open('F:/SqueezeNet/valid.txt', 'w', encoding='UTF-8') as f:for valid_img in valid_data:f.write(str(valid_dataset) + '/' + valid_img[0] + ' ' + str(valid_img[1]))f.write('\n')
2.2 数据预处理
这里采用到的数据预处理,主要有调整图像大小、随机翻转、归一化等。
import os.path
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import transformstransform_BZ = transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5]
)class LoadData(Dataset):def __init__(self, txt_path, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flagself.train_tf = transforms.Compose([transforms.Resize(224), # 调整图像大小为224x224transforms.RandomHorizontalFlip(), # 随机左右翻转图像transforms.RandomVerticalFlip(), # 随机上下翻转图像transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transform_BZ # 执行某些复杂变换操作])self.val_tf = transforms.Compose([transforms.Resize(224), # 调整图像大小为224x224transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transform_BZ # 执行某些复杂变换操作])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))return imgs_infodef padding_black(self, img):w, h = img.sizescale = 224. / max(w, h)img_fg = img.resize([int(x) for x in [w * scale, h * scale]])size_fg = img_fg.sizesize_bg = 224img_bg = Image.new("RGB", (size_bg, size_bg))img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,(size_bg - size_fg[1]) // 2))img = img_bgreturn imgdef __getitem__(self, index):img_path, label = self.imgs_info[index]img_path = os.path.join('', img_path)img = Image.open(img_path)img = img.convert("RGB")img = self.padding_black(img)if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)
2.3 构建模型
import torch
import torch.nn as nn
import torch.nn.init as initclass Fire(nn.Module):def __init__(self, inplanes, squeeze_planes,expand1x1_planes, expand3x3_planes):super(Fire, self).__init__()self.inplanes = inplanesself.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)self.squeeze_activation = nn.ReLU(inplace=True)self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,kernel_size=1)self.expand1x1_activation = nn.ReLU(inplace=True)self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,kernel_size=3, padding=1)self.expand3x3_activation = nn.ReLU(inplace=True)def forward(self, x):x = self.squeeze_activation(self.squeeze(x))return torch.cat([self.expand1x1_activation(self.expand1x1(x)),self.expand3x3_activation(self.expand3x3(x))], 1)class SqueezeNet(nn.Module):def __init__(self, version='1_0', num_classes=1000):super(SqueezeNet, self).__init__()self.num_classes = num_classesif version == '1_0':self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(96, 16, 64, 64),Fire(128, 16, 64, 64),Fire(128, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 32, 128, 128),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(512, 64, 256, 256),)elif version == '1_1':self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(64, 16, 64, 64),Fire(128, 16, 64, 64),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(128, 32, 128, 128),Fire(256, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),Fire(512, 64, 256, 256),)else:# FIXME: Is this needed? SqueezeNet should only be called from the# FIXME: squeezenet1_x() functions# FIXME: This checking is not done for the other modelsraise ValueError("Unsupported SqueezeNet version {version}:""1_0 or 1_1 expected".format(version=version))# Final convolution is initialized differently from the restfinal_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)self.classifier = nn.Sequential(nn.Dropout(p=0.5),final_conv,nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)))for m in self.modules():if isinstance(m, nn.Conv2d):if m is final_conv:init.normal_(m.weight, mean=0.0, std=0.01)else:init.kaiming_uniform_(m.weight)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):x = self.features(x)x = self.classifier(x)return torch.flatten(x, 1)2.4 开始训练
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from model import SqueezeNet
import torchsummary
from dataloader import LoadData
import copydevice = "cuda:0" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = SqueezeNet(num_classes=2).to(device)
# print(model)
#print(torchsummary.summary(model, (3, 224, 224), 1))# 加载训练集和验证集
train_data = LoadData(r"F:\SqueezeNet\train.txt", True)
train_dl = torch.utils.data.DataLoader(train_data, batch_size=16, pin_memory=True,shuffle=True, num_workers=0)
test_data = LoadData(r"F:\SqueezeNet\valid.txt", True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=16, pin_memory=True,shuffle=True, num_workers=0)# 编写训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)print('num_batches:', num_batches)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss# 编写验证函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss# 开始训练epochs = 20train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标loss_function = nn.CrossEntropyLoss() # 定义损失函数
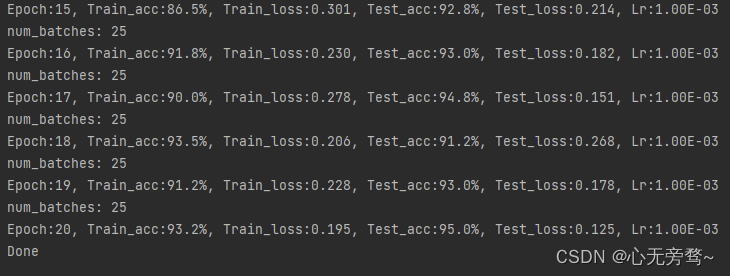
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 定义Adam优化器for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_function, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_function)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,epoch_test_acc * 100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)print('Done')
2.5 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Test Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Test Loss')
plt.show()
可视化结果如下:
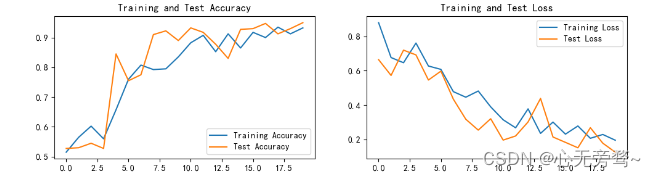
可以自行调整学习率以及batch_size,这里我的超参数并没有调整。
三、数据集个体预测
import matplotlib.pyplot as plt
from PIL import Image
from torchvision.transforms import transforms
from model import SqueezeNet
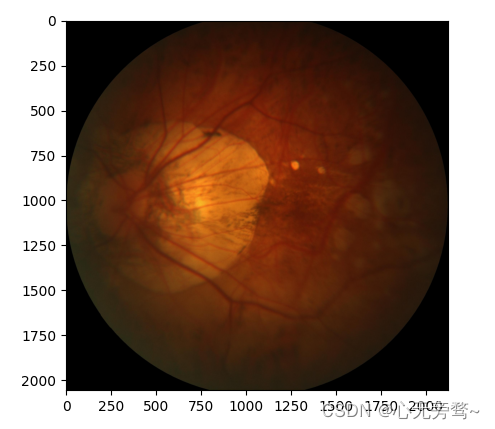
import torchdata_transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((224, 224)),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])img = Image.open("F:\SqueezeNet\data\PALM-Validation400\V0008.jpg")
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
name = ['非病理性近视', '病理性近视']
model_weight_path = r"F:\SqueezeNet\best_model.pth"
model = SqueezeNet(num_classes=2)
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():output = torch.squeeze(model(img))predict = torch.softmax(output, dim=0)# 获得最大可能性索引predict_cla = torch.argmax(predict).numpy()print('索引为', predict_cla)
print('预测结果为:{},置信度为: {}'.format(name[predict_cla], predict[predict_cla].item()))
plt.show()
索引为 1
预测结果为:病理性近视,置信度为: 0.9768268465995789
更详细的请看paddle版本的实现:深度学习实战基础案例——卷积神经网络(CNN)基于SqueezeNet的眼疾识别
相关文章:
深度学习实战基础案例——卷积神经网络(CNN)基于SqueezeNet的眼疾识别|第1例
文章目录 前言一、数据准备1.1 数据集介绍1.2 数据集文件结构 二、项目实战2.1 数据标签划分2.2 数据预处理2.3 构建模型2.4 开始训练2.5 结果可视化 三、数据集个体预测 前言 SqueezeNet是一种轻量且高效的CNN模型,它参数比AlexNet少50倍,但模型性能&a…...
麦肯锡发布《2023年度科技报告》!
在经历了 2022 年技术投资和人才的动荡之后,2023 年上半年,人们对技术促进商业和社会进步的潜力重新燃起了热情。生成式人工智能(Generative AI)在这一复兴过程中功不可没,但它只是众多进步中的一个,可以推…...
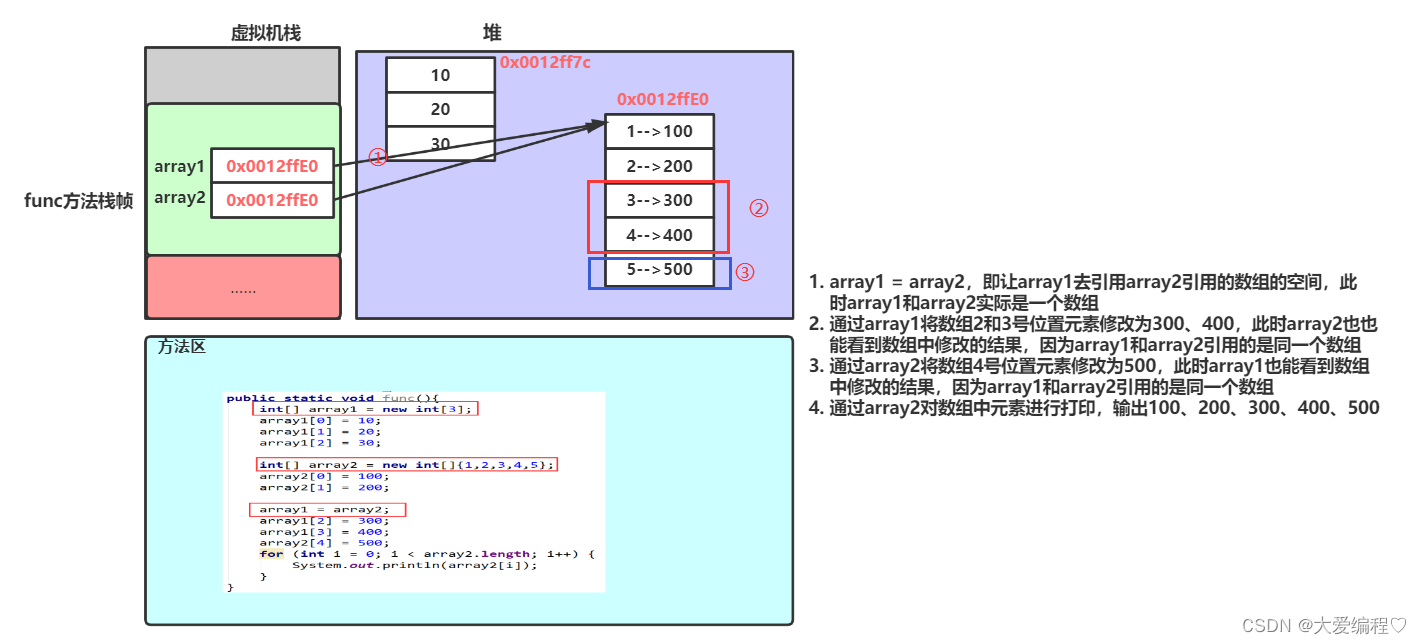
JAVASE---数组的定义与使用
数组的基本概念 什么是数组 数组是具有相同类型元素的集合,在内存中连续存储。 1. 数组中存放的元素其类型相同 2. 数组的空间是连在一起的 3. 每个空间有自己的编号,起始位置的编号为0,即数组的下标 数组的创建及初始化 数组的创建 T[…...
211、仿真-基于51单片机土壤湿度智能盆栽灌溉报警Proteus仿真设计(程序+Proteus仿真+配套资料等)
毕设帮助、开题指导、技术解答(有偿)见文未 目录 一、硬件设计 二、设计功能 三、Proteus仿真图 四、程序源码 资料包括: 需要完整的资料可以点击下面的名片加下我,找我要资源压缩包的百度网盘下载地址及提取码。 方案选择 单片机的选择 方案一&am…...

记录TensorRT8.5.0安装
1.下载网址NVIDIA TensorRT 8.x Download | NVIDIA Developer TensorRT不同的版本依赖于不同的cuda版本和cudnn版本。根据自己电脑的cuda版本和cudnn版本来决定要下载哪个TensorRT版本 查看cudnn版本 cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 cat /usr/l…...

flutter ListView 滚动到最后一个items位置
flutter 想要实现一个listview初始化时和数据变化后显示到列表的最末,简单地说就是像聊天窗或者是日志输出那样的情景。 要在Flutter中实现在初始化时和数据变化后将ListView自动定位到最后一个item的位置,你可以使用ScrollController来控制滚动位置&am…...

WMS:SurfaceView绘制显示
WMS:SurfaceView绘制显示 1、SurfaceView控件使用1.1 Choreographer接受VSync信号1.2 自定义SurfaceView1.3 结果 2、SurfaceView获取画布并显示2.1 SurfaceHolder.lockCanvas()2.2 SurfaceHolder.unlockCanvasAndPost(Canvas canvas) 1、SurfaceView控件使用 1.1 Choreograph…...
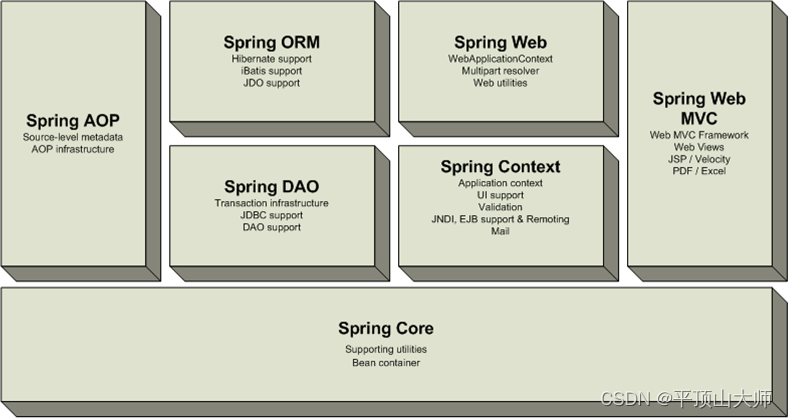
【Spring系列篇--关于IOC的详解】
目录 面试经典题目: 1. 什么是spring?你对Spring的理解?简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。 2.什么是IoC?你对IoC的理解?IoC的重要性?将实例化对象的权利从程序员…...

__ob__: Observer 后缀的数组的取值方式
开发中,经常从接口、父组件中,拿到数组然后给新的数组使用, 但是,有时候会发现带有 __ob__: Observer 后缀的数组,对这种数组来说,你是无法取到这个数组的值的, 而且,离谱的是consol…...

时序预测 | MATLAB实现WOA-CNN-BiLSTM鲸鱼算法优化卷积双向长短期记忆神经网络时间序列预测
时序预测 | MATLAB实现WOA-CNN-BiLSTM鲸鱼算法优化卷积双向长短期记忆神经网络时间序列预测 目录 时序预测 | MATLAB实现WOA-CNN-BiLSTM鲸鱼算法优化卷积双向长短期记忆神经网络时间序列预测预测效果基本介绍程序设计学习总结参考资料 预测效果 基本介绍 时序预测 | MATLAB实现…...

Java基础知识点
Java是一种高级计算机语言,是可以编写跨平台应用软件、完全面向对象的程序设计语言。 2、Java划分为三个技术平台:Java SE、Java EE、Java ME Java SE是桌面应用,Java EE是web应用,平台企业版,Java ME是手机应用&#…...
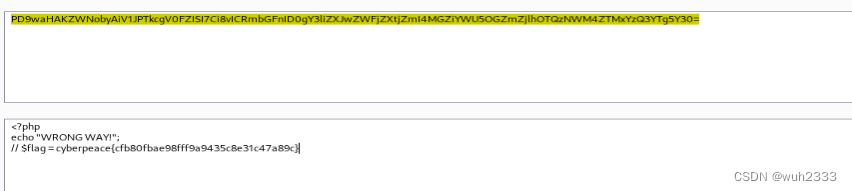
攻防世界-web-fileclude
1. 题目描述 打开链接,可以看到如下代码: 代码意思很简单,让我们传递两个参数,一个file1,一个file2,如果file2的内容为hello ctf,那么就可以在代码中include file1 2. 思路分析 这道题显然是…...
【100天精通python】Day36:GUI界面编程_高级功能操作和示例
专栏导读 专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html 一、GUI 高级功能 1 自定义主题和样式 自定义主题和样式可以让你的GUI应用程序在外观方面更加出色。在使用Tkinter时,你可以使用ttkthemes库来应用不同的主题和样式。…...

无涯教程-Perl - sub函数
描述 此函数定义一个新的子例程。上面显示的参数遵循以下规则- NAME是子例程的名称。可以在有或没有原型规范的情况下预先声明命名的子例程(没有关联的代码块)。 匿名子例程必须具有定义。 PROTO定义了函数的原型,调用该函数以验证提供的参数时将使用该原型。 ATTRS为解析…...
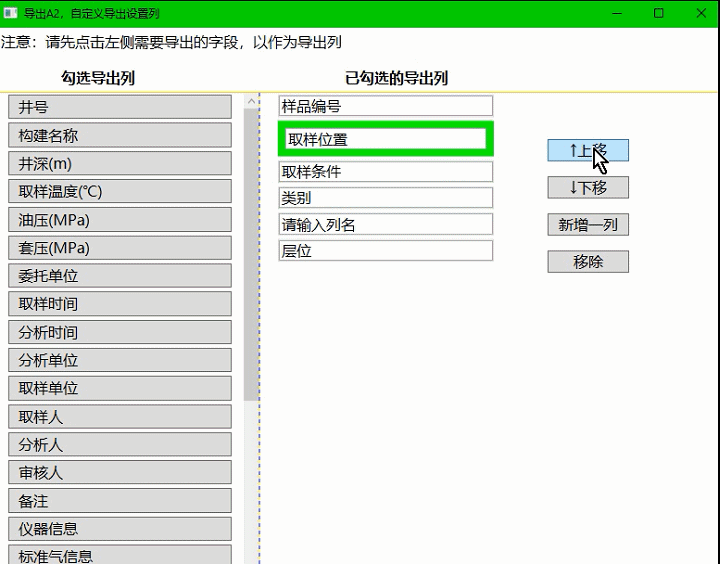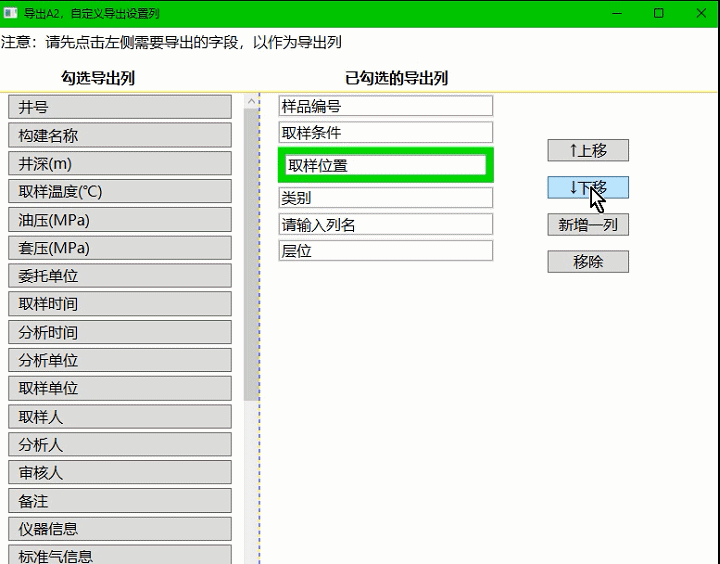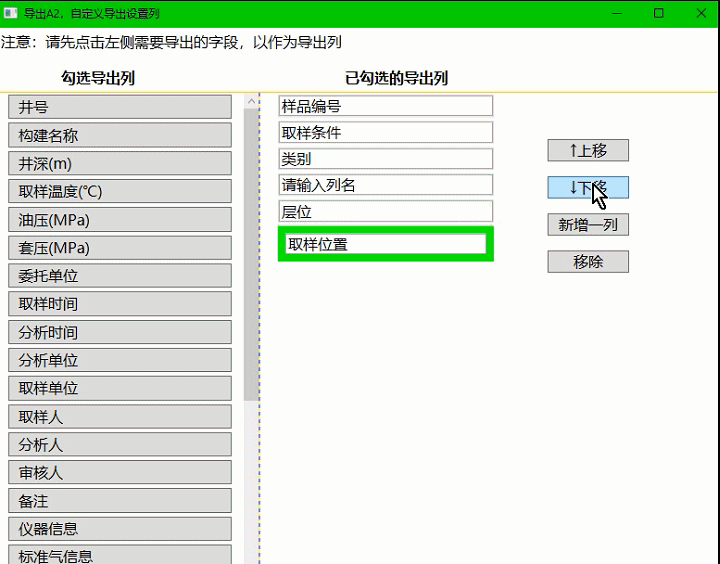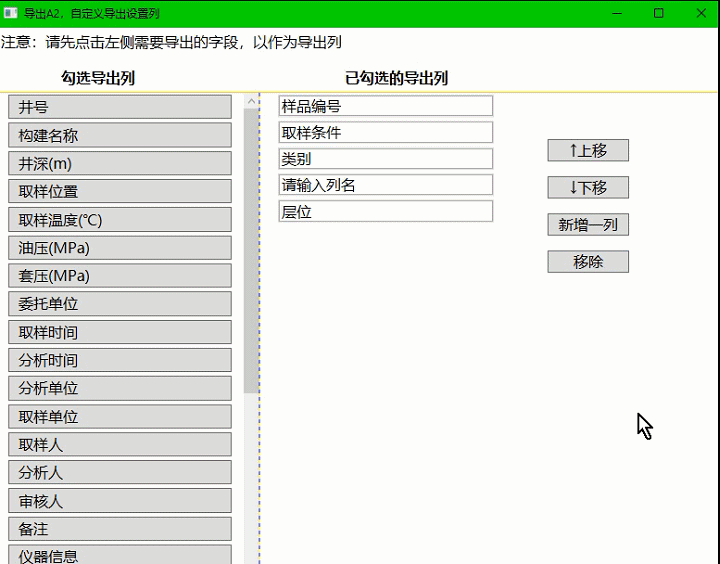
wpf控件上移下移,调整子集控件显示顺序
页面代码: <!-- 导出A2,自定义导出设置列,添加时间:2023-8-9 14:14:18,作者:whl; --><Window x:Class="WpfSnqkGasAnalysis.WindowGasExportA2"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http:/…...
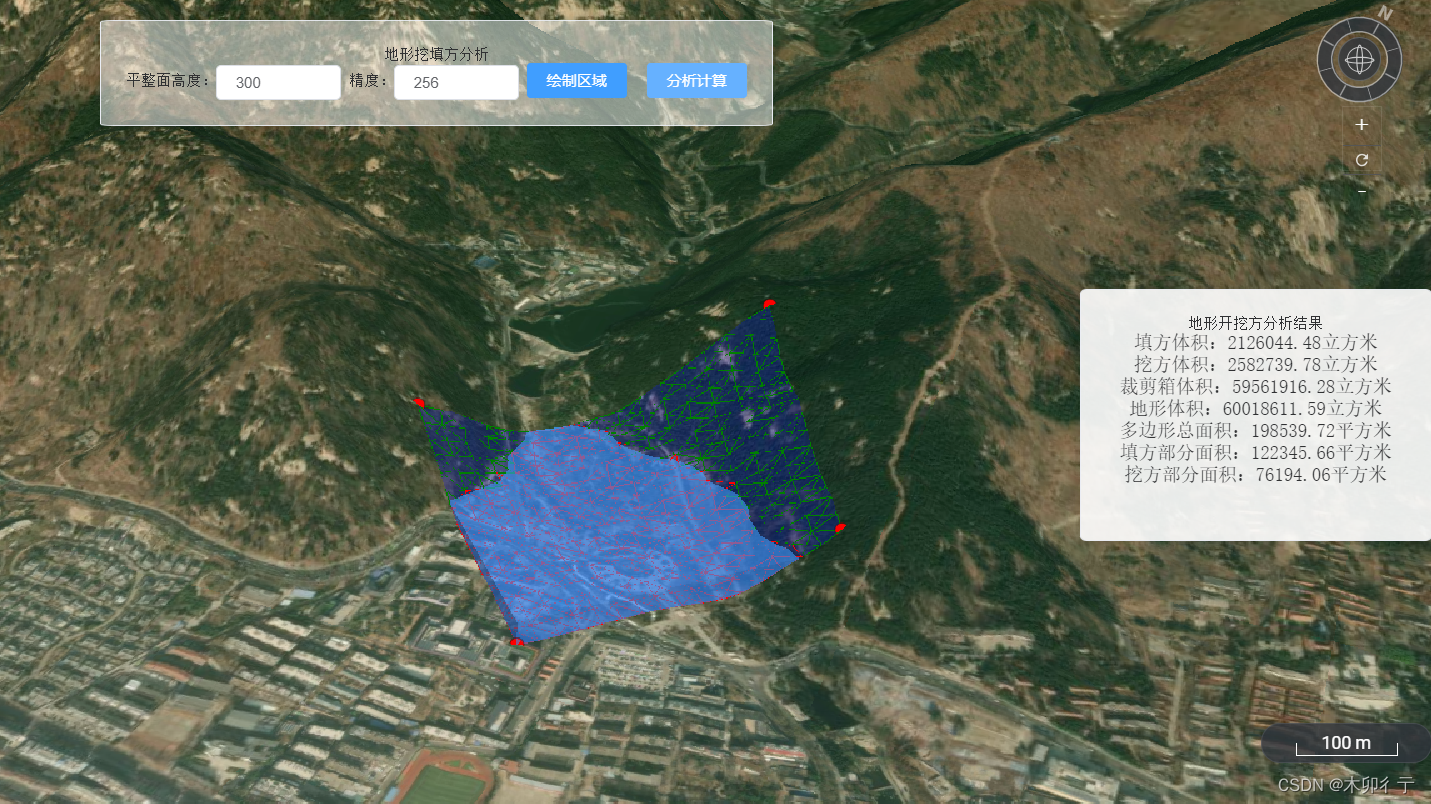
cesium学习记录08-鼠标绘制多边形
上一篇学习了实体的一些基础知识,这一篇来学习鼠标绘制实体多边形的实现 一、方法一: 1,结果显示 贴地: 不贴地: 2,方法全部代码: 主方法: /*** 绘制多边形* param {Object} op…...

rocketMq启动broker报错找不到或无法加载主类 Files\Java\jdk1.8.0_171\lib\dt.jar;C:\Program]
假如弹出提示框提示‘错误: 找不到或无法加载主类 xxxxxx’。 1.打开runbroker.cmd 将"%CLASSPATH%"加上英文双引号,切勿别加中文双引号 2.打开runserver.cmd 同理 将"%CLASSPATH%"加上英文双引号,切勿别加中文双引号 3.正常执行即…...

Linux touch 命令指南大全
1. 概述 在本教程中,我们将学习touch命令。简而言之,这个命令允许我们更新文件或目录的最后修改时间和最后访问时间。 因此,我们将重点关注如何使用该命令及其各种选项。 请注意,我们使用 Bash 测试了此处显示的所有命令;但是,它们应该与任何兼容 POSIX 的 shell 一起使…...
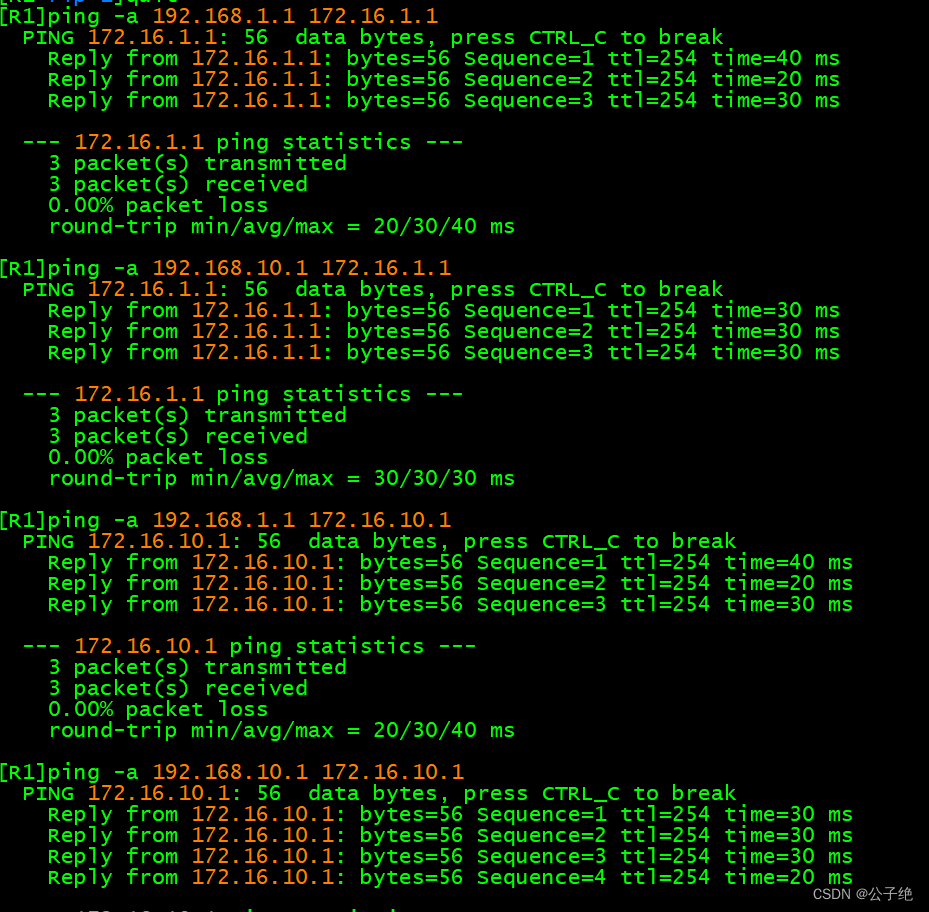
华为网络篇 RIPv2的基础配置-25
难度 1复杂度1 目录 一、实验原理 1.1 RIP的版本 1.2 RIP的路由更新方式 1.3 RIP的计时器 1.4 RIP的防环机制 二、实验拓扑 三、实验步骤 四、实验过程 总结 一、实验原理 RIP(Routing Information Protocol,路由信息协议)&am…...
fastadmin 下拉多级分类
要实现下图效果 一、先创建数据表 二、在目标的controll中引入use fast\Tree; public function _initialize() {parent::_initialize();$this->model new \app\admin\model\zxdc\Categorys;$tree Tree::instance();$tree->init(collection($this->model->order(…...

基于光伏出力不确定性的梯级水光互补系统短期优化调度模型及Matlab代码复现研究报告
1023-(文章复现)梯级水光互补系统最大化可消纳电量期望短期优化调度模型matlab代码 参考资料《梯级水光互补系统最大化可消纳电量期望短期优化调度模型》 文中考虑光伏出力不确定性,以整体可消纳电量期望最大为目标,提出了梯级水光互补系统的短期优化调度…...

Nanbeige 4.1-3B赋能微信小程序:打造智能客服对话机器人
Nanbeige 4.1-3B赋能微信小程序:打造智能客服对话机器人 最近在帮一个做电商的朋友琢磨怎么优化他们的客服系统。他们每天要处理大量重复的咨询,比如“什么时候发货”、“怎么退换货”,人工客服忙得团团转,用户还得排队等。这让我…...

RWKV7-1.5B-G1A入门实战:手把手教你写文案、做总结、玩对话
RWKV7-1.5B-G1A入门实战:手把手教你写文案、做总结、玩对话 1. 认识RWKV7-1.5B-G1A RWKV7-1.5B-G1A是一个基于RWKV-7架构的多语言文本生成模型,特别适合处理基础问答、文案续写、简短总结和轻量中文对话任务。这个1.5B参数的模型在保持良好生成质量的同…...

什么时候会触发FullGC
面试 1、老年代空间不足。应该让对象在年轻代多存活一段时间,不要创建过大的对象及数组。 2、元空间满了。说明此时,系统中要加载的类、反射的类和调用的方法较多。 3、MinorGC执行后晋升到老年代的平均大小大于老年代的剩余空间。...

大数据产品实战:用户画像系统的设计与实现
大数据产品实战:用户画像系统的设计与实现 关键词:用户画像、标签体系、大数据平台、精准营销、数据挖掘 摘要:用户画像系统是大数据时代企业实现“以用户为中心”运营的核心工具,它通过给用户“贴标签”的方式,将复杂的用户行为转化为可量化、可分析的数字特征。本文将从…...

OpenClaw技能扩展指南:为GLM-4.7-Flash添加自定义功能
OpenClaw技能扩展指南:为GLM-4.7-Flash添加自定义功能 1. 为什么需要自定义技能 去年冬天,当我第一次尝试用OpenClaw自动整理电脑上的照片时,发现现有的技能库无法满足我的特殊需求——按照拍摄地点和人物自动分类。这让我意识到࿰…...

LeetCode 153. 旋转排序数组找最小值:二分最优思路
LeetCode中等难度的经典题目——153. 寻找旋转排序数组中的最小值。这道题的核心考点是「二分查找」,难点在于如何利用“旋转排序数组”的特性,在O(log n)时间复杂度内找到最小值,也是面试中常考的二分变形题。 一、题目解读:读懂…...

别再为IP冲突头疼!YOLOv5+海康威视摄像头组网与实时检测的完整避坑指南
工业视觉组网实战:YOLOv5与海康威视摄像头的智能协同方案 在智能制造与安防监控领域,将AI算法与专业摄像设备结合已成为技术标配。但当工程师真正着手部署时,往往会陷入网络配置的泥潭——IP冲突导致设备失联、RTSP流媒体断断续续、多网卡环…...

CI/CD 流水线性能优化:从构建到部署
CI/CD 流水线性能优化:从构建到部署 前言 哥们,别整那些花里胡哨的理论。今天直接上硬菜——我在大厂一线优化 CI/CD 流水线性能的真实经验总结。作为一个白天写前端、晚上打鼓的硬核工程师,我对效率的追求就像对鼓点节奏的把控一样严格。 背…...

VOOHU沃虎xJLSemi景略:智造时代通信基石-以太网接口PHY芯片
随着智能制造和工业物联网的高速发展,工业通信正朝着高速化、智能化的方向迈进。工业自动化设备需要实时、高效地传输大量数据,以实现精准控制和协同作业。 工业以太网现场总线凭借其高速率、高可靠性、兼容性强等优势成为工业通信的主流选择࿰…...