【kubernetes系列】Kubernetes之Kubelet运行机制和状态更新机制
Kubelet运行机制
Kubelet是Kubernetes中的一个重要组件,在每个 Node 节点上都会启动 kubelet 服务。 该服务主要用于处理 Master 节点下发到本节点的任务,管理 Pod及Pod 中的容器。每个kubelet 进程会在 API Server 上注册节点自身信息,定期向 Master 节点汇报节点资源的使用情况 , 并通过cAdvisor 监控容器和节点资源。在本文中,我们将分析Kubelet的运行机制。
Kubelet的工作流程
每个节点上的kubelet启动后,它的工作流程可以分为以下几个步骤:
-
获取Pod列表:Kubelet(watch机制监视)会从Master节点获取节点上的Pod列表。Master节点会将Pod列表发送给Kubelet,并告诉Kubelet哪些Pod需要在该节点上运行。
-
创建Pod:如果Kubelet发现节点上没有某个Pod的容器在运行,它会根据Pod的定义创建容器。Kubelet会根据Pod的定义创建一个Pod Sandbox,然后在Pod Sandbox中创建容器。
-
监控容器状态:Kubelet会定期检查容器的状态,并将状态报告给Master节点。如果容器出现故障,Kubelet会尝试重启容器。如果重启失败,Kubelet会将容器标记为失败,并将状态报告给Master节点。
-
清理容器:如果Kubelet发现某个容器已经被删除,它会将该容器从节点上清理掉。
Kubelet的相关配置
Kubelet的配置文件可以放在多个配置文件中,具体看部署方式。可能是/etc/kubernetes/kubelet.conf、/usr/lib/systemd/system/kubelet.service、/var/lib/kubelet/config.yaml。很多默认配置都可以不用修改,主要的配置包括以下几个方面:
-
节点名称:Kubelet需要知道节点的名称,以便向Master节点注册自己。
-
Pod网络:Kubelet需要知道Pod网络的配置,以便能够正确地创建Pod Sandbox和容器。
-
容器运行时:Kubelet需要知道容器运行时的一些参数,以便能够满足业务需要。
-
资源限制:Kubelet需要知道节点的资源限制,以便能够正确地调度Pod,与优化相关。
Kubelet 状态更新机制
当 Kubernetes 中 Node 节点出现状态异常的情况下,节点上的 Pod 会被重新调度到其他节点上去,但是有的时候我们会发现节点 Down 掉以后,Pod 并不会立即触发重新调度,这实际上就是和 Kubelet 的状态更新机制密切相关的,Kubernetes 提供了一些参数配置来触发重新调度到node时间,下面我们来分析下 Kubelet 状态更新的基本流程。
默认情况下,正常的行为如下:
- kubelet 自身会定期更新状态到 apiserver,更新周期由--node-status-update-frequency参数指定,默认值是10s
- Kubernetes Controller Manager定期的检查kubelet状态,该参数由–-node-monitor-period参数指定,默认值5s
- Kubernetes Controller Manager对kubelet状态更新有一个容忍值,如果kubelet在这个容忍值内更新状态,那么Kubernetes Controller Manager认为kubelet状态有效。具体为:
- 当 node 失联一段时间后,kubernetes 判定 node 为notready 状态,这段时长通过 –node-monitor-grace-period 参数配置,默认为40s
- 当 node 失联一段时间后,kubernetes 判定 node 为unhealthy 状态,这段时长通过 –node-startup-grace-period 参数配置,默认为1m
- 当 node 失联一段时间后,kubernetes 开始删除原 node 上的 pod,这段时长是通过–pod-eviction-timeout 参数配置,默认为5m
- Kubernetes Controller Manager和kubelet异步工作,这意味着延迟可能包含网络延迟,API Server延迟,etcd延迟,节点负载等引起的延迟,所以如果设置--node-status-update-frequency参数为5秒时,那么当etcd无法将数据提交到仲裁节点时,它可能会在etcd中等待6-7秒甚至更长才能被呈现
失败情况
- kubelet将尝试发送nodeStatusUpdateRetry ,当前nodeStatusUpdateRetry在kubelet.go.中设置为5次
- kubelet将使用 tryUpdateNodeStatus方法发送状态.kubelet使用golang的http.Client()方法,但是没指定超时时长,因此当在apiserver过载时TCP连接会造成一些问题.
- 因此,这里尝试使用nodeStatusUpdateRetry 乘以 --node-status-update-frequency的值设置node状态.
- 在同时Kubernetes Controller Manager每隔--node-monitor-period设置的时间检查nodeStatusUpdateRetry设置的次数,经过--node-monitor-grace-period设定的时间将认为node不健康,通过在 kube-apiserver组件中设置--default-not-ready-toleration-seconds & --default-unreachable-toleration-seconds 这两个默认的容忍参数。Kubernetes 会自动为每个 pod 添加一个默认容忍配置,默认容忍限制为60s。在添加这两个参数后需要重新部署所有 Pod 以确保将容忍添加到所有 Pod 中。除了使用kube-apiserver的参数使其对所有 pod 进行全局更改之外你还可以指定为 pod 设置忍驱逐时间。
- 同时Kube-Proxy watch API server,一旦pod被删除,那么集群中所有kube-proxy将更新其节点上的iptables规则,移除相应的endpoint,这使得请求无法被发送到故障节点的pod
实际应用
默认的配置(参数所属组件)
| 参数 | 值 | 组件 |
|---|---|---|
| --node-status-update-frequency | 10s | kubelet |
| --node-monitor-period | 5s | controller manager |
| --node-monitor-grace-period | 40s | controller manager |
快速更新和快速响应
| 参数 | 值 | 组件 |
|---|---|---|
| --node-status-update-frequency | 4s | kubelet |
| --node-monitor-period | 2s | controller manager |
| --node-monitor-grace-period | 20s | controller manager |
如果--node-status-update-frequency设置为4s(默认为10s)。 --node-monitor-period设置为2s(默认为5s)。--node-monitor-grace-period设置20s(默认为40s)。--default-not-ready-toleration-seconds & --default-unreachable-toleration-seconds 设置为30(默认为 300 秒)。注意,这两个值应该是表示秒数的整数。
在这种情况下,Pod 将在 50s 后被驱逐,因为节点将在 20s 后被视为Down掉了,--default-not-ready-toleration-seconds 或者 --default-unreachable-toleration-seconds 在 30s 之后开始删除Pod。但是,这种情况会给 etcd 产生很大的开销,因为每个节点都会每 2s 更新一次状态。
如果环境有1000个节点,那么每分钟将有30000次节点更新操作,这可能需要大型 etcd 容器甚至是 etcd 的专用节点。
如果我们计算尝试次数,则除法将给出5,但实际上每次尝试的 nodeStatusUpdateRetry 尝试将从3到5。 由于所有组件的延迟,尝试总次数将在15到25之间变化。
中等更新和平均响应
| 参数 | 值 | 组件 |
|---|---|---|
| --node-status-update-frequency | 20s | kubelet |
| --node-monitor-period | 5s | controller manager |
| --node-monitor-grace-period | 2m | controller manager |
我们设置--node-status-update-frequency设置为20s。--node-monitor-grace-period设置为2m,并将 --default-not-ready-toleration-seconds 和 --default-unreachable-toleration-seconds设置为60s。这种场景下会 20s 更新一次 node 状态,Kubernetes Controller Manager 对 kubelet检测,在2分钟内进行 6 * 5 = 30 次尝试如果没有更新节点状态。1m后它将驱逐所有 pod。那么将在一分钟后驱逐所有pod总共耗时3分钟。
此处情况适用于中等环境,因为1000个节点每分钟需要对etcd进行3000次更新。
低更新和慢响应
| 参数 | 值 | 组件 |
|---|---|---|
| --node-status-update-frequency | 1m | kubelet |
| --node-monitor-period | 5s | controller manager |
| --node-monitor-grace-period | 5m | controller manager |
如果--node-status-update-frequency设置为1m。 --node-monitor-grace-period设置为5m,并将 --default-not-ready-toleration-seconds 和 --default-unreachable-toleration-seconds设置为60s。在这种情况下kubelet将在每分钟上报状态,5分钟内kubelet没有更新节点状态Kubernetes Controller Manager将节点设置为不健康,在一分钟后开始驱逐所有pod总共耗时6分钟。
总结
Kubelet是Kubernetes中的一个重要组件,它负责管理节点上的容器和Pod,并与Master节点进行通信。Kubelet的工作流程包括获取Pod列表、创建Pod、监控容器状态和清理容器。Kubelet的配置包括节点名称、Pod网络、容器运行时和资源限制。
计算公式
驱逐时间 =( --node-monitor-grace-period + --default-not-ready-toleration-seconds 或 --default-unreachable-toleration-seconds)
可以有不同的配置组合,满足自己实际的使用情况。
更多关于kubernetes的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:

【kubernetes系列】Kubernetes之Kubelet运行机制和状态更新机制
Kubelet运行机制 Kubelet是Kubernetes中的一个重要组件,在每个 Node 节点上都会启动 kubelet 服务。 该服务主要用于处理 Master 节点下发到本节点的任务,管理 Pod及Pod 中的容器。每个kubelet 进程会在 API Server 上注册节点自身信息,定期…...

(学习笔记-进程管理)怎么避免死锁?
死锁的概念 在多线程编程中,我们为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。 那…...
)
【golang】链表(List)
List实现了一个双向链表,而Element则代表了链表中元素的结构。 可以把自己生成的Element类型值传给链表吗? 首先来看List的四种方法。 MoveBefore方法和MoveAfter方法,它们分别用于把给定的元素移动到另一个元素的前面和后面。 MoveToFro…...

android平台的语音聊天助手源码
目录 1 android平台的语音聊天助手源码 1.1 //js处理工具类 1.1.1 openImage 1.2 LoadWebDetails android平台的语音聊天助手源码package com.shrimp.xiaoweirobot.net; import java.util.ArrayList;...

Python读取Word统计词频输出到Excel
1.安装依赖的包 "# 读取docx\n", "!pip install python-docx\n", "!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx\n", "# 中英文分词\n", "!pip install jieba\n", "!pi…...

windows docker mysql8.0 挂载配置文件不生效的问题
原因 mysql 8.0 遇到sql_modeonly_full_group_by的问题,于是就自定义my.cnf 去掉only_full_group_by,修改my.cnf 文件后,进行映射启动 docker run 命令 docker run -p 3306:3306 --privilegedtrue --restartalways -d --name axsc-mysql -…...

openGauss学习笔记-42 openGauss 高级数据管理-触发器
文章目录 openGauss学习笔记-42 openGauss 高级数据管理-触发器42.1 语法格式42.2 参数说明42.3 示例 openGauss学习笔记-42 openGauss 高级数据管理-触发器 触发器会在指定的数据库事件发生时自动执行函数。 42.1 语法格式 创建触发器 CREATE TRIGGER trigger_name { BEFORE…...
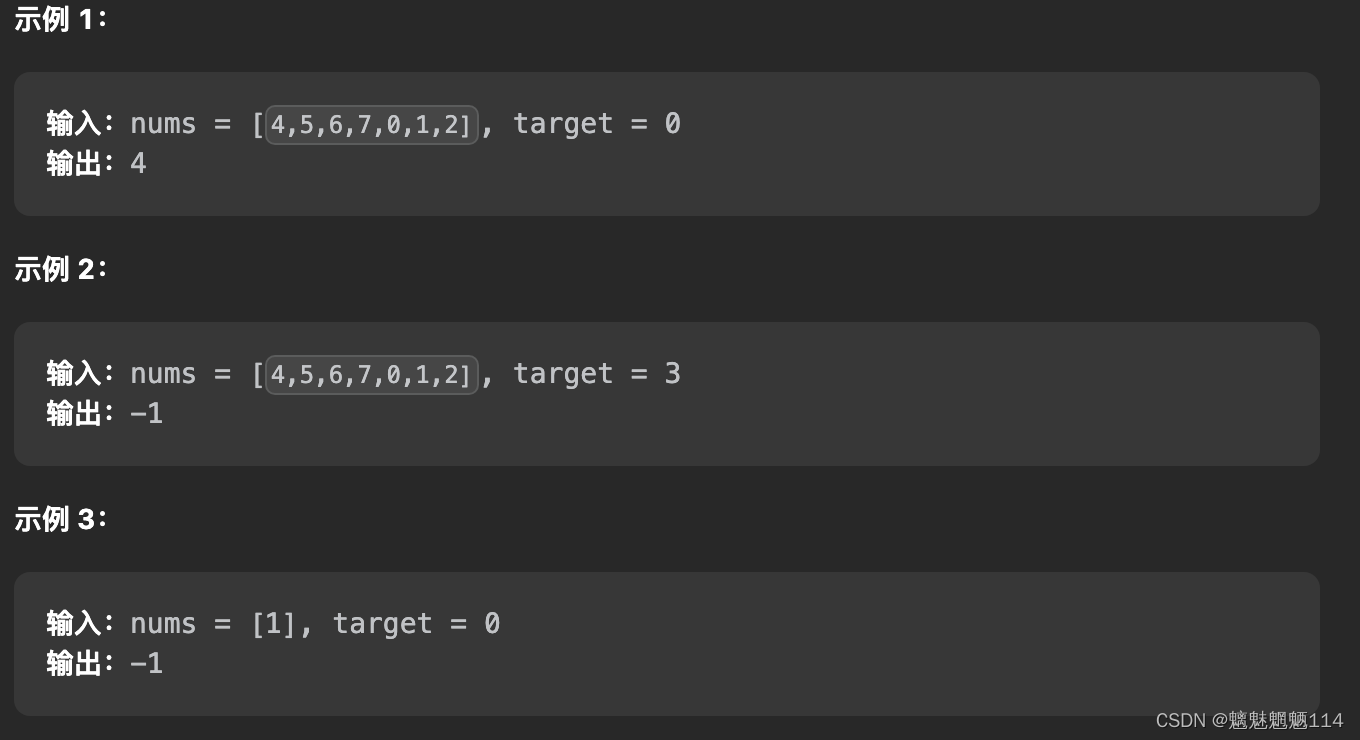
Leetcode33 搜索旋转排序数组
题解: /*** 旋转排序数组可分为N1 N2两个部分,如:[4,5,6,7,1,2,3],N1为[4,5,6,7],N2为[1,2,3]** 必然满足以下两个条件:* 1. N1和N2都是分别递增的;* 2. N1中的所有元素大于N2中的所有元素;** …...

docker 第一章
目录 1.安装 docker 2.镜像、容器 3.总结 1.安装 docker 2.镜像、容器 3.总结 容器在 linux 上的本机运行,与其他容器共享主机的内核。它运行的是一个独立的进程,不占用其他任何可执行文件的内存,非常轻量级。...

注册中心 —— SpringCloud Netflix Eureka
Eureka 简介 Eureka 是一个基于 REST 的服务发现组件,SpringCloud 将它集成在其子项目 spring-cloud-netflix 中,以实现 SpringCloud 的服务注册与发现,同时提供了负载均衡、故障转移等能力,目前 Eureka2.0 已经不再维护…...

2023年国赛数学建模思路 - 案例:异常检测
文章目录 赛题思路一、简介 -- 关于异常检测异常检测监督学习 二、异常检测算法2. 箱线图分析3. 基于距离/密度4. 基于划分思想 建模资料 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 一、简介 – 关于异常…...
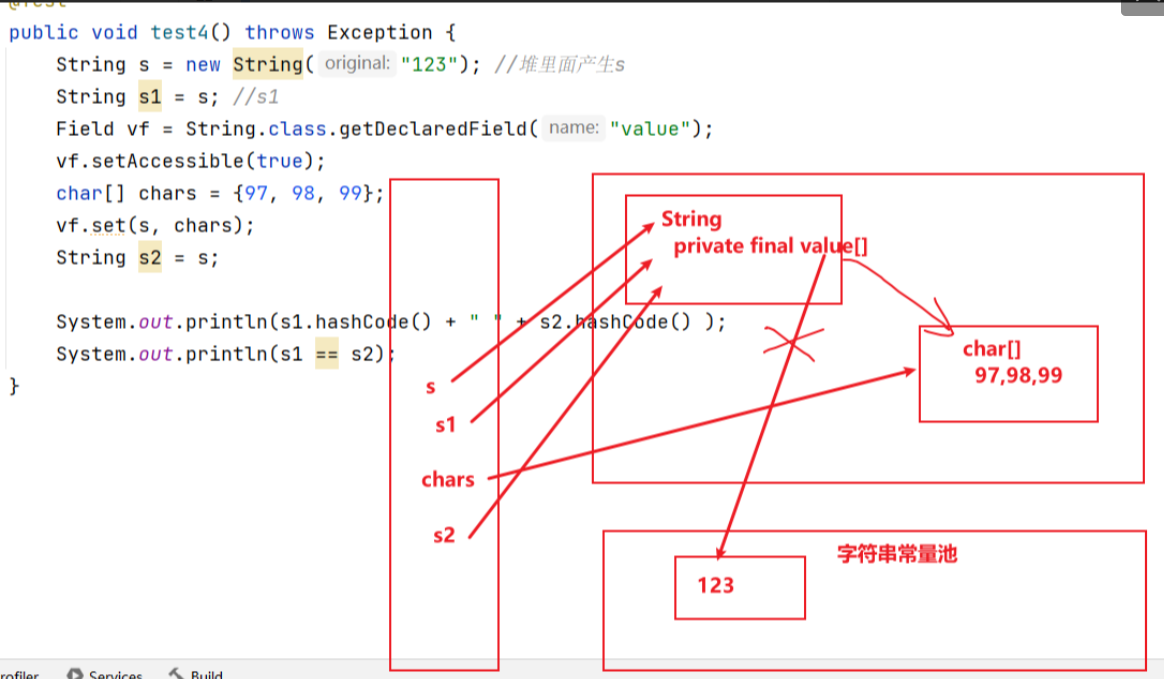
⛳ Java 反射
目录 ⛳ Java 反射🎨 一、反射概述**🎃 使用反射的前提条件: **🎲 类正常加载过程如下图:反射优缺点:🧸 Java反射机制提供的功能: **🥅 反射主要API** 🏭 二、反射的使用Ἲ…...

Android 13 像Settings一样开启关闭深色模式
一.背景 由于客户定制的Settings需要开启关闭深色模式,所以需要自己调用开启关闭深色模式 二.前提条件 首先应用肯定要是系统应用,并且导入framework.jar包,具体可以参考: Android 应用自动开启辅助(无障碍)功能并使用辅助(无障碍)功能_android 自动开启无障碍服务_龚礼鹏…...

微服务实战项目-学成在线-项目优化(redis缓存优化)
微服务实战项目-学成在线-项目优化(redis缓存优化) 1 优化需求 视频播放页面用户未登录也可以访问,当用户观看试学课程时需要请求服务端查询数据,接口如下: 1、根据课程id查询课程信息。 2、根据文件id查询视频信息。 这些接口在用户未认…...
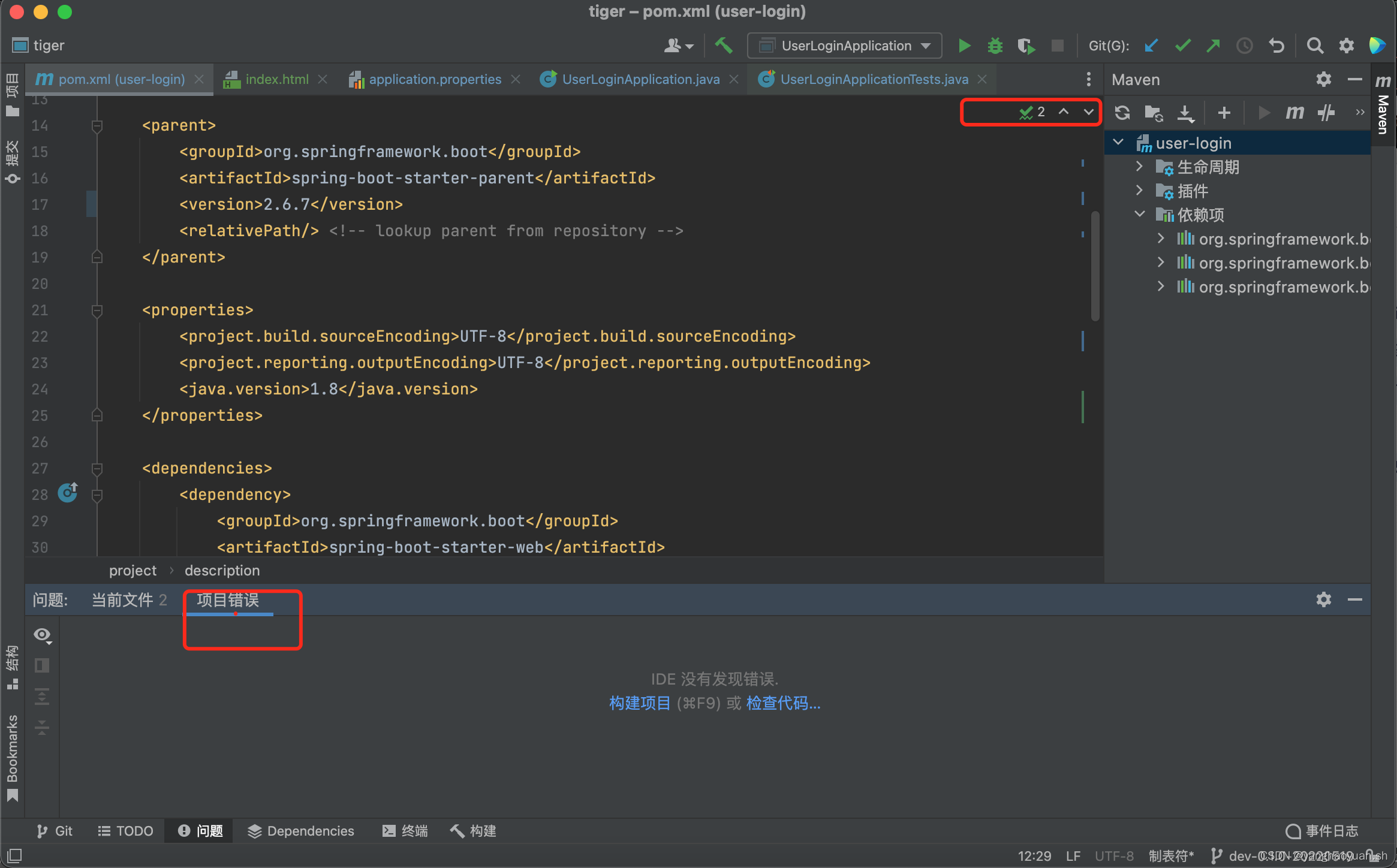
IDEA 找不到项目 ‘org.springframework.boot:spring-boot-starter-parent:3.1.2‘
找不到项目 ‘org.springframework.boot:spring-boot-starter-parent:2.6.7’ 这个问题主要是因为ide的缓存导致的,我们直接清理缓存并重启ide 重启之后ide会对pom文件进行编排索引完成之后问题就没有了...

thinkphp开发的在线学习培训考试模拟考试做题练习系统带商城功能证书管理课程系统
thinkphp开发的在线学习培训考试模拟考试做题练习系统带商城功能证书管理课程系统 1、做题界面 2、前端UI的展示 3、带商城购物功能...

Android 应用冷启动优化
冷启动相关概念 应用启动概念 冷启动:首次打开app或者app彻底销毁后再次打开app(开关机后),这也是我们进行启动速度优化的主要方向。热启动:应用运行中按home键再打开应用。温启动:介于两者之间ÿ…...

538页21万字数字政府智慧政务大数据云平台项目建设方案WORD
导读:原文《538页21万字数字政府智慧政务大数据云平台项目建设方案WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 根据业务的不同属性,…...
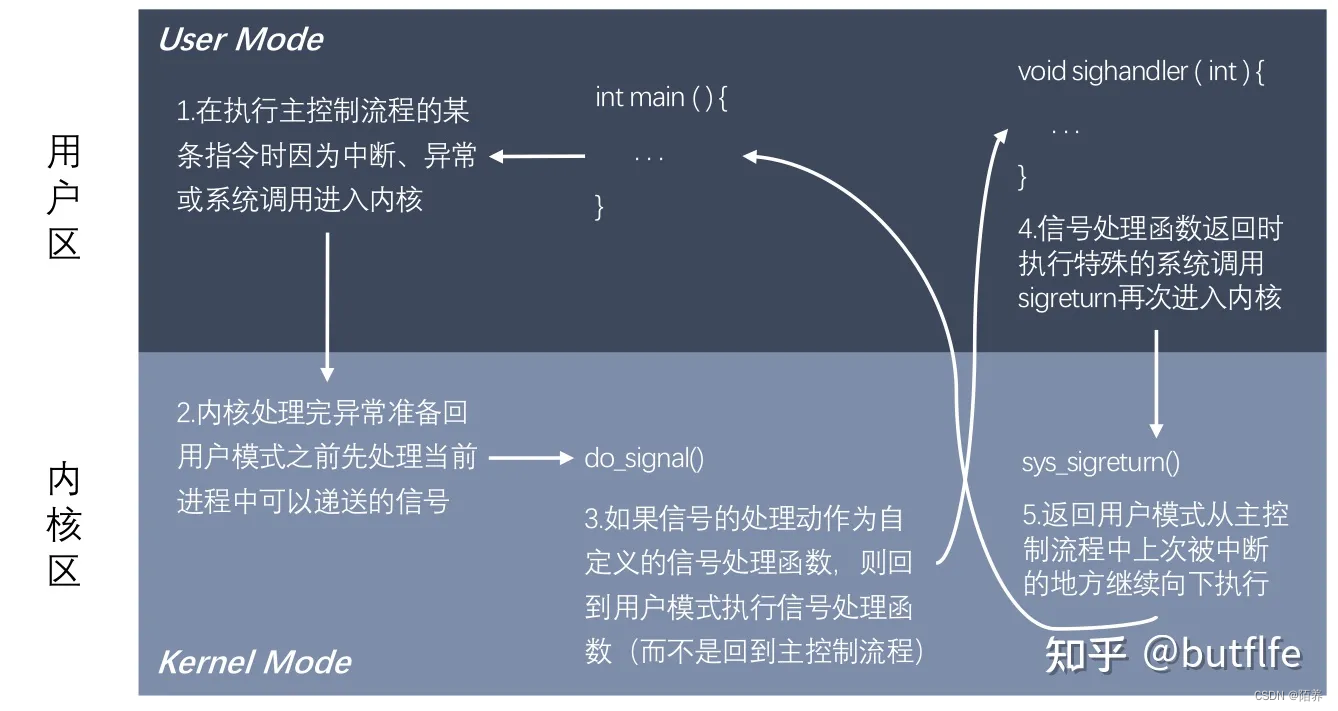
进程间通信——信号
信号的概念 信号是 Linux进程间通信的最古老的方式之一,是事件发生时对进程的通知机制,有时也称之为软件中断,它是在软件层次上对中断机制的一种模拟,是一种异步通信的方式。信号可以导致一个正在运行的进程被另一个正在运行的异…...

PAT 1039 Course List for Student
个人学习记录,代码难免不尽人意。 Zhejiang University has 40000 students and provides 2500 courses. Now given the student name lists of all the courses, you are supposed to output the registered course list for each student who comes for a query. …...

英特尔马来西亚六厂布局:先进封装如何重塑半导体制造与供应链
1. 项目概述:从一则新闻到半导体制造的全球拼图前几天,行业里不少朋友都在转一条消息,说英特尔在马来西亚的封装产能布局又有新动作,计划要搞到六座工厂的规模。乍一看,这好像就是个普通的海外建厂新闻,但如…...

Unity问题记录
一个物体在Scene窗口看不见,Game窗口能看见。选中它时,打开Gizmos也看不见身上碰撞体的线框。也无法被射线检测到。换成其他Mesh:Open Asset In Context正常显示:把它Revert回预制体,还是不显示。Ctrl D复制一个&#…...
)
保姆级避坑指南:在Ubuntu 18.04上从零搭建PX4仿真环境(ROS Melodic + Gazebo 9)
从零避坑:Ubuntu 18.04下PX4仿真环境全链路搭建实战 当无人机开发者第一次接触PX4生态时,往往会被复杂的工具链和隐蔽的环境依赖所困扰。本文将以"问题驱动"的方式,拆解ROS Melodic Gazebo 9 PX4组合环境搭建中的12个典型陷阱&am…...

解决Claude Code频繁封号问题转向Taotoken稳定服务的配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号问题转向Taotoken稳定服务的配置指南 如果你在使用 Claude Code 时遇到了账号不稳定或 Token 额度受限的问…...

NIPAP:开源IP地址管理平台如何实现企业级网络规划效率提升300%
NIPAP:开源IP地址管理平台如何实现企业级网络规划效率提升300% 【免费下载链接】NIPAP Neat IP Address Planner - NIPAP is the best open source IPAM in the known universe, challenging classical IP address management (IPAM) systems in many areas. 项目…...

离线语音模块在塔扇智能化中的集成与应用实践
1. 项目概述:当塔扇“听懂”你的话 家里的塔式风扇,你是不是也经常遇到这样的场景:晚上躺在床上,风扇对着吹有点冷,想调小一档或者关掉,结果发现遥控器不知道被塞到哪个沙发缝里了,只能挣扎着爬…...

工业多串口通信实战:基于EM9170的8串口方案设计与优化
1. 项目概述:为什么8串口在今天依然重要?在物联网、工业自动化、智能楼宇这些领域里摸爬滚打久了,你会发现一个有趣的现象:那些看似“古老”的通信接口,生命力往往比我们想象的要顽强得多。串口,或者说RS-2…...

SSD1306 OLED屏幕驱动全攻略:从Arduino到CircuitPython实战
1. 项目概述如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定遇到过一个问题:怎么把程序运行的状态、传感器的数据或者一些简单的交互界面直观地展示出来?用串口监视器看数据流当然可以,但不够“酷”,也不够便…...

Loop窗口管理:5个高效工作流提升你的Mac生产力
Loop窗口管理:5个高效工作流提升你的Mac生产力 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop Loop是一款为macOS设计的优雅窗口管理工具,通过径向菜单、快捷键绑定和智能窗口操…...
)
心理学实验小白必看:用E-Prime 3.0从零设计你的第一个Stroop任务(附完整流程)
心理学实验入门:用E-Prime 3.0构建专业级Stroop实验全指南 第一次打开E-Prime时,满屏的控件和属性面板可能让你感到无从下手——这几乎是每个心理学研究生的必经之路。作为认知心理学最经典的实验范式之一,Stroop任务不仅能验证注意与自动加…...