chatglm2-6b模型在9n-triton中部署并集成至langchain实践 | 京东云技术团队
一.前言
近期, ChatGLM-6B 的第二代版本ChatGLM2-6B已经正式发布,引入了如下新特性:
①. 基座模型升级,性能更强大,在中文C-Eval榜单中,以51.7分位列第6;
②. 支持8K-32k的上下文;
③. 推理性能提升了42%;
④. 对学术研究完全开放,允许申请商用授权。
目前大多数部署方案采用的是fastapi+uvicorn+transformers,这种方式适合快速运行一些demo,在生产环境中使用还是推荐使用专门的深度学习推理服务框架,如Triton。本文将介绍我利用集团9n-triton工具部署ChatGLM2-6B过程中踩过的一些坑,希望可以为有部署需求的同学提供一些帮助。
二.硬件要求
部署的硬件要求可以参考如下:
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
我部署了2个pod,每个pod的资源:CPU(4核)、内存(30G)、1张P40显卡(显存24G)。
三.部署实践
Triton默认支持的PyTorch模型格式为TorchScript,由于ChatGLM2-6B模型转换成TorchScript格式会报错,本文将以Python Backend的方式进行部署。
1. 模型目录结构
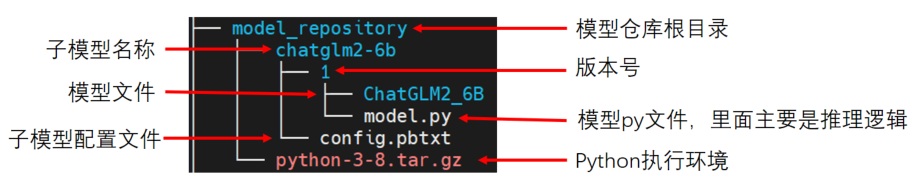
9N-Triton使用集成模型,如上图所示模型仓库(model_repository), 它内部可以包含一个或多个子模型(如chatglm2-6b)。下面对各个部分进行展开介绍:
2. python执行环境
该部分为模型推理时需要的相关python依赖包,可以使用conda-pack将conda虚拟环境打包,如python-3-8.tar.gz。如对打包conda环境不熟悉的,可以参考 https://conda.github.io/conda-pack/。然后在config.pbtxt中配置执行环境路径:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/../python-3-8.tar.gz"}
}在当前示例中,$ T R I T O N _ M O D E L _ D I R E C T O R Y = " TRITON\_MODEL\_DIRECTORY=" TRITON_MODEL_DIRECTORY="pwd/model_repository/chatglm2-6b"。
注意:当前python执行环境为所有子模型共享,如果想给不同子模型指定不同的执行环境,则应该将tar.gz文件放在子模型目录下,如下所示:
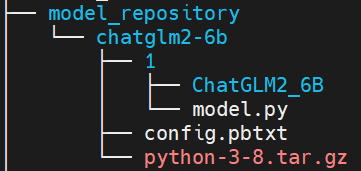
同时,在config.pbtxt中配置执行环境路径如下:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/python-3-8.tar.gz"}
}3. 模型配置文件
模型仓库库中的每个模型都必须包含一个模型配置文件config.pbtxt,用于指定平台和或后端属性、max_batch_size 属性以及模型的输入和输出张量等。ChatGLM2-6B的配置文件可以参考如下:
name: "chatglm2-6b" // 必填,模型名,需与该子模型的文件夹名字相同
backend: "python" // 必填,模型所使用的后端引擎max_batch_size: 0 // 模型每次请求最大的批数据量,张量shape由max_batch_size和dims组合指定,对于 max_batch_size 大于 0 的模型,完整形状形成为 [ -1 ] + dims。 对于 max_batch_size 等于 0 的模型,完整形状形成为 dims。
input [ // 必填,输入定义{name: "prompt" //必填,名称data_type: TYPE_STRING //必填,数据类型dims: [ -1 ] //必填,数据维度,-1 表示可变维度},{name: "history"data_type: TYPE_STRINGdims: [ -1 ]},{name: "temperature"data_type: TYPE_STRINGdims: [ -1 ]},{name: "max_token"data_type: TYPE_STRINGdims: [ -1 ]},{name: "history_len"data_type: TYPE_STRINGdims: [ -1 ]}
]
output [ //必填,输出定义{name: "response"data_type: TYPE_STRINGdims: [ -1 ]},{name: "history"data_type: TYPE_STRINGdims: [ -1 ]}
]
parameters: { //指定python执行环境key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/../python-3-8.tar.gz"}
}
instance_group [ //模型实例组{ count: 1 //实例数量kind: KIND_GPU //实例类型gpus: [ 0 ] //指定实例可用的GPU索引}
]其中必填项为最小模型配置,模型配置文件更多信息可以参考: https://github.com/triton-inference-server/server/blob/r22.04/docs/model_configuration.md
4. 自定义python backend
主要需要实现model.py 中提供的三个接口:
①. initialize: 初始化该Python模型时会进行调用,一般执行获取输出信息及创建模型的操作
②. execute: python模型接收请求时的执行函数;
③. finalize: 删除模型时会进行调用;
如果有 n 个模型实例,那么会调用 n 次initialize 和 finalize这两个函数。
ChatGLM2-6B的model.py文件可以参考如下:
import os
# 设置显存空闲block最大分割阈值
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:32'
# 设置work目录os.environ['TRANSFORMERS_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"
os.environ['HF_MODULES_CACHE'] = os.path.dirname(os.path.abspath(__file__))+"/work/"import json# triton_python_backend_utils is available in every Triton Python model. You
# need to use this module to create inference requests and responses. It also
# contains some utility functions for extracting information from model_config
# and converting Triton input/output types to numpy types.
import triton_python_backend_utils as pb_utils
import sys
import gc
import time
import logging
import torch
from transformers import AutoTokenizer, AutoModel
import numpy as npgc.collect()
torch.cuda.empty_cache()logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',level=logging.INFO)class TritonPythonModel:"""Your Python model must use the same class name. Every Python modelthat is created must have "TritonPythonModel" as the class name."""def initialize(self, args):"""`initialize` is called only once when the model is being loaded.Implementing `initialize` function is optional. This function allowsthe model to intialize any state associated with this model.Parameters----------args : dictBoth keys and values are strings. The dictionary keys and values are:* model_config: A JSON string containing the model configuration* model_instance_kind: A string containing model instance kind* model_instance_device_id: A string containing model instance device ID* model_repository: Model repository path* model_version: Model version* model_name: Model name"""# You must parse model_config. JSON string is not parsed hereself.model_config = json.loads(args['model_config'])output_response_config = pb_utils.get_output_config_by_name(self.model_config, "response")output_history_config = pb_utils.get_output_config_by_name(self.model_config, "history")# Convert Triton types to numpy typesself.output_response_dtype = pb_utils.triton_string_to_numpy(output_response_config['data_type'])self.output_history_dtype = pb_utils.triton_string_to_numpy(output_history_config['data_type'])ChatGLM_path = os.path.dirname(os.path.abspath(__file__))+"/ChatGLM2_6B"self.tokenizer = AutoTokenizer.from_pretrained(ChatGLM_path, trust_remote_code=True)model = AutoModel.from_pretrained(ChatGLM_path,torch_dtype=torch.bfloat16,trust_remote_code=True).half().cuda()self.model = model.eval()logging.info("model init success")def execute(self, requests):"""`execute` MUST be implemented in every Python model. `execute`function receives a list of pb_utils.InferenceRequest as the onlyargument. This function is called when an inference request is madefor this model. Depending on the batching configuration (e.g. DynamicBatching) used, `requests` may contain multiple requests. EveryPython model, must create one pb_utils.InferenceResponse for everypb_utils.InferenceRequest in `requests`. If there is an error, you canset the error argument when creating a pb_utils.InferenceResponseParameters----------requests : listA list of pb_utils.InferenceRequestReturns-------listA list of pb_utils.InferenceResponse. The length of this list mustbe the same as `requests`"""output_response_dtype = self.output_response_dtypeoutput_history_dtype = self.output_history_dtype# output_dtype = self.output_dtyperesponses = []# Every Python backend must iterate over everyone of the requests# and create a pb_utils.InferenceResponse for each of them.for request in requests:prompt = pb_utils.get_input_tensor_by_name(request, "prompt").as_numpy()[0]prompt = prompt.decode('utf-8')history_origin = pb_utils.get_input_tensor_by_name(request, "history").as_numpy()if len(history_origin) > 0:history = np.array([item.decode('utf-8') for item in history_origin]).reshape((-1,2)).tolist()else:history = []temperature = pb_utils.get_input_tensor_by_name(request, "temperature").as_numpy()[0]temperature = float(temperature.decode('utf-8'))max_token = pb_utils.get_input_tensor_by_name(request, "max_token").as_numpy()[0]max_token = int(max_token.decode('utf-8'))history_len = pb_utils.get_input_tensor_by_name(request, "history_len").as_numpy()[0]history_len = int(history_len.decode('utf-8'))# 日志输出传入信息in_log_info = {"in_prompt":prompt,"in_history":history,"in_temperature":temperature,"in_max_token":max_token,"in_history_len":history_len}logging.info(in_log_info)response,history = self.model.chat(self.tokenizer,prompt,history=history[-history_len:] if history_len > 0 else [],max_length=max_token,temperature=temperature)# 日志输出处理后的信息out_log_info = {"out_response":response,"out_history":history}logging.info(out_log_info)response = np.array(response)history = np.array(history)response_output_tensor = pb_utils.Tensor("response",response.astype(self.output_response_dtype))history_output_tensor = pb_utils.Tensor("history",history.astype(self.output_history_dtype))final_inference_response = pb_utils.InferenceResponse(output_tensors=[response_output_tensor,history_output_tensor])responses.append(final_inference_response)# Create InferenceResponse. You can set an error here in case# there was a problem with handling this inference request.# Below is an example of how you can set errors in inference# response:## pb_utils.InferenceResponse(# output_tensors=..., TritonError("An error occured"))# You should return a list of pb_utils.InferenceResponse. Length# of this list must match the length of `requests` list.return responsesdef finalize(self):"""`finalize` is called only once when the model is being unloaded.Implementing `finalize` function is OPTIONAL. This function allowsthe model to perform any necessary clean ups before exit."""print('Cleaning up...')5. 部署测试
① 选择9n-triton-devel-gpu-v0.3镜像创建notebook测试实例;
② 把模型放在/9n-triton-devel/model_repository目录下,模型目录结构参考3.1;
③ 进入/9n-triton-devel/server/目录,拉取最新版本的bin并解压:wget http://storage.jd.local/com.bamboo.server.product/7196560/9n_predictor_server.tgz
④ 修改/9n-triton-devel/server/start.sh 为如下:
mkdir logs
\rm -rf /9n-triton-devel/server/logs/*
\rm -rf /tmp/python_env_*
export LD_LIBRARY_PATH=/9n-triton-devel/server/lib/:$LD_LIBRARY_PATH
nohup ./bin/9n_predictor_server --flagfile=./conf/server.gflags 2>&1 >/dev/null &
sleep 2
pid=`ps x |grep "9n_predictor_server" | grep -v "grep" | grep -v "ldd" | grep -v "stat" | awk '{print $1}'`
echo $pid⑤ 运行 /9n-triton-devel/server/start.sh 脚本
⑥ 检查服务启动成功(ChatGLM2-6B模型启动,差不多13分钟左右)
方法1:查看8010端口是否启动:netstat -natp | grep 8010
方法2:查看日志:cat /9n-triton-devel/server/logs/predictor_core.INFO
⑦ 编写python grpc client访问测试服务脚本,放于/9n-triton-devel/client/目录下,访问端口为8010,ip为127.0.0.1,可以参考如下:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import sys
sys.path.append('./base')
from multi_backend_client import MultiBackendClient
import triton_python_backend_utils as python_backend_utils
import multi_backend_message_pb2import time
import argparse
import io
import os
import numpy as np
import json
import structdef print_result(response, batch_size ):print("outputs len:" + str(len(response.outputs)))if (response.error_code == 0):print("response : ", response)print(f'res shape: {response.outputs[0].shape}')res = python_backend_utils.deserialize_bytes_tensor(response.raw_output_contents[0])for i in res:print(i.decode())print(f'history shape: {response.outputs[1].shape}')history = python_backend_utils.deserialize_bytes_tensor(response.raw_output_contents[1])for i in history:print(i.decode())def send_one_request(sender, request_pb, batch_size):succ, response = sender.send_req(request_pb)if succ:print_result(response, batch_size)else:print('send_one_request fail ', response)def send_request(ip, port, temperature, max_token, history_len, batch_size=1, send_cnt=1):request_sender = MultiBackendClient(ip, port)request = multi_backend_message_pb2.ModelInferRequest()request.model_name = "chatglm2-6b"# 输入占位input0 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input0.name = "prompt"input0.datatype = "BYTES"input0.shape.extend([1])input1 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input1.name = "history"input1.datatype = "BYTES"input1.shape.extend([-1])input2 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input2.name = "temperature"input2.datatype = "BYTES"input2.shape.extend([1])input3 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input3.name = "max_token"input3.datatype = "BYTES"input3.shape.extend([1])input4 = multi_backend_message_pb2.ModelInferRequest().InferInputTensor()input4.name = "history_len"input4.datatype = "BYTES"input4.shape.extend([1])query = '请给出一个具体示例'input0.contents.bytes_contents.append(bytes(query, encoding="utf8"))request.inputs.extend([input0])history_origin = np.array([['你知道鸡兔同笼问题么', '鸡兔同笼问题是一个经典的数学问题,涉及到基本的代数方程和解题方法。问题描述为:在一个笼子里面,有若干只鸡和兔子,已知它们的总数和总腿数,问鸡和兔子的数量各是多少?\n\n解法如下:假设鸡的数量为x,兔子的数量为y,则总腿数为2x+4y。根据题意,可以列出方程组:\n\nx + y = 总数\n2x + 4y = 总腿数\n\n通过解方程组,可以求得x和y的值,从而确定鸡和兔子的数量。']]).reshape((-1,))history = [bytes(item, encoding="utf8") for item in history_origin]input1.contents.bytes_contents.extend(history)request.inputs.extend([input1])input2.contents.bytes_contents.append(bytes(temperature, encoding="utf8"))request.inputs.extend([input2])input3.contents.bytes_contents.append(bytes(max_token, encoding="utf8"))request.inputs.extend([input3])input4.contents.bytes_contents.append(bytes(history_len, encoding="utf8"))request.inputs.extend([input4])# 输出占位output_tensor0 = multi_backend_message_pb2.ModelInferRequest().InferRequestedOutputTensor()output_tensor0.name = "response"request.outputs.extend([output_tensor0])output_tensor1 = multi_backend_message_pb2.ModelInferRequest().InferRequestedOutputTensor()output_tensor1.name = "history"request.outputs.extend([output_tensor1])min_ms = 0max_ms = 0avg_ms = 0for i in range(send_cnt):start = time.time_ns()send_one_request(request_sender, request, batch_size)cost = (time.time_ns()-start)/1000000print ("idx:%d cost ms:%d" % (i, cost))if cost > max_ms:max_ms = costif cost < min_ms or min_ms==0:min_ms = costavg_ms += costavg_ms /= send_cntprint("cnt=%d max=%dms min=%dms avg=%dms" % (send_cnt, max_ms, min_ms, avg_ms))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument( '-ip', '--ip_address', help = 'ip address', default='127.0.0.1', required=False)parser.add_argument( '-p', '--port', help = 'port', default='8010', required=False)parser.add_argument( '-t', '--temperature', help = 'temperature', default='0.01', required=False)parser.add_argument( '-m', '--max_token', help = 'max_token', default='16000', required=False)parser.add_argument( '-hl', '--history_len', help = 'history_len', default='10', required=False)parser.add_argument( '-b', '--batch_size', help = 'batch size', default=1, required=False, type = int)parser.add_argument( '-c', '--send_count', help = 'send count', default=1, required=False, type = int)args = parser.parse_args()send_request(args.ip_address, args.port, args.temperature, args.max_token, args.history_len, args.batch_size, args.send_count)通用predictor请求格式可以参考: https://github.com/kserve/kserve/blob/master/docs/predict-api/v2/grpc_predict_v2.proto
6. 模型部署
九数算法中台提供了两种部署模型服务方式,分别为界面部署和SDK部署。利用界面中的模型部署只支持JSF协议接口,若要提供JSF服务接口,则可以参考 http://easyalgo.jd.com/help/%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97/%E6%A8%A1%E5%9E%8B%E8%AE%A1%E7%AE%97/%E6%A8%A1%E5%9E%8B%E9%83%A8%E7%BD%B2.html 直接部署。
由于我后续需要将ChatGLM2-6B模型集成至langchain中使用,所以对外提供http协议接口比较便利,经与算法中台同学请教后使用SDK方式部署可以满足。由于界面部署和SDK部署目前研发没有对齐,用界面部署时直接可以使用3.1中的模型结构,使用SDK部署则需要调整模型结构如下:
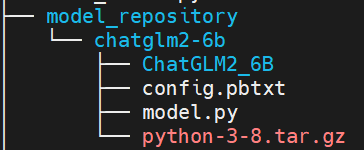
同时需要在config.pbtxt中将执行环境路径设置如下:
parameters: {key: "EXECUTION_ENV_PATH",value: {string_value: "$$TRITON_MODEL_DIRECTORY/1/python-3-8.tar.gz"}
}模型部署代码可以参考如下:
from das.triton.model import TritonModelmodel = TritonModel("chatglm2-6b")predictor = model.deploy(path="$pwd/model_repository/chatglm2-6b", # 模型文件所在的目录protocol='http',endpoint = "9n-das-serving-lf2.jd.local",cpu=4,memory=30,use_gpu=True, # 根据是否需要gpu加速推理来配置override = True,instances=2)四.集成至langchain
使用langchain可以快速基于LLM模型开发一些应用。使用LLMs模块封装ChatGLM2-6B,请求我们的模型服务,主要实现_call函数,可以参考如下代码:
import json
import time
import base64
import struct
import requests
import numpy as np
from pathlib import Path
from abc import ABC, abstractmethod
from langchain.llms.base import LLM
from langchain.llms import OpenAI
from langchain.llms.utils import enforce_stop_tokens
from typing import Dict, List, Optional, Tuple, Union, Mapping, Anyimport warnings
warnings.filterwarnings("ignore")class ChatGLM(LLM):max_token = 32000temperature = 0.01history_len = 10url = ""def __init__(self):super(ChatGLM, self).__init__()@propertydef _llm_type(self):return "ChatGLM2-6B"@propertydef _history_len(self) -> int:return self.history_len@propertydef _max_token(self) -> int:return self.max_token@propertydef _temperature(self) -> float:return self.temperaturedef _deserialize_bytes_tensor(self, encoded_tensor):"""Deserializes an encoded bytes tensor into annumpy array of dtype of python objectsParameters----------encoded_tensor : bytesThe encoded bytes tensor where each elementhas its length in first 4 bytes followed bythe contentReturns-------string_tensor : np.arrayThe 1-D numpy array of type object containing thedeserialized bytes in 'C' order."""strs = list()offset = 0val_buf = encoded_tensorwhile offset < len(val_buf):l = struct.unpack_from("<I", val_buf, offset)[0]offset += 4sb = struct.unpack_from("<{}s".format(l), val_buf, offset)[0]offset += lstrs.append(sb)return (np.array(strs, dtype=np.object_))@classmethoddef _infer(cls, url, query, history, temperature, max_token, history_len):query = base64.b64encode(query.encode('utf-8')).decode('utf-8')history_origin = np.asarray(history).reshape((-1,))history = [base64.b64encode(item.encode('utf-8')).decode('utf-8') for item in history_origin]temperature = base64.b64encode(temperature.encode('utf-8')).decode('utf-8')max_token = base64.b64encode(max_token.encode('utf-8')).decode('utf-8')history_len = base64.b64encode(history_len.encode('utf-8')).decode('utf-8')data = {"model_name": "chatglm2-6b","inputs": [{"name": "prompt", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [query]}},{"name": "history", "datatype": "BYTES", "shape": [-1], "contents": {"bytes_contents": history}},{"name": "temperature", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [temperature]}},{"name": "max_token", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [max_token]}},{"name": "history_len", "datatype": "BYTES", "shape": [1], "contents": {"bytes_contents": [history_len]}}],"outputs": [{"name": "response"},{"name": "history"}]}response = requests.post(url = url, data = json.dumps(data, ensure_ascii=True), headers = {"Content_Type": "application/json"}, timeout=120)return response def _call(self, query: str, history: List[List[str]] =[], stop: Optional[List[str]] =None):temperature = str(self.temperature)max_token = str(self.max_token)history_len = str(self.history_len)url = self.urlresponse = self._infer(url, query, history, temperature, max_token, history_len)if response.status_code!=200:return "查询结果错误"if stop is not None:response = enforce_stop_tokens(response, stop)result = json.loads(response.text)# 处理responseres = base64.b64decode(result['raw_output_contents'][0].encode('utf-8'))res_response = self._deserialize_bytes_tensor(res)[0].decode()return res_responsedef chat(self, query: str, history: List[List[str]] =[], stop: Optional[List[str]] =None):temperature = str(self.temperature)max_token = str(self.max_token)history_len = str(self.history_len)url = self.urlresponse = self._infer(url, query, history, temperature, max_token, history_len)if response.status_code!=200:return "查询结果错误"if stop is not None:response = enforce_stop_tokens(response, stop)result = json.loads(response.text)# 处理responseres = base64.b64decode(result['raw_output_contents'][0].encode('utf-8'))res_response = self._deserialize_bytes_tensor(res)[0].decode()# 处理historyhistory_shape = result['outputs'][1]["shape"]history_enc = base64.b64decode(result['raw_output_contents'][1].encode('utf-8'))res_history = np.array([i.decode() for i in self._deserialize_bytes_tensor(history_enc)]).reshape(history_shape).tolist()return res_response, res_history@propertydef _identifying_params(self) -> Mapping[str, Any]:"""Get the identifying parameters."""_param_dict = {"url": self.url}return _param_dict注意:模型服务调用url等于在模型部署页面调用信息URL后加上" MutilBackendService/Predict "
五.总结
本文详细介绍了在集团9n-triton工具上部署ChatGLM2-6B过程,希望可以为有部署需求的同学提供一些帮助。
作者:京东保险 赵风龙
来源:京东云开发者社区 转载请注明出处
相关文章:
chatglm2-6b模型在9n-triton中部署并集成至langchain实践 | 京东云技术团队
一.前言 近期, ChatGLM-6B 的第二代版本ChatGLM2-6B已经正式发布,引入了如下新特性: ①. 基座模型升级,性能更强大,在中文C-Eval榜单中,以51.7分位列第6; ②. 支持8K-32k的上下文;…...

Shell编程之正则表达式(非常详细)
正则表达式 1.通配符和正则表达式的区别2.基本正则表达式2.1 元字符 (字符匹配)2.2 表示匹配次数2.4 位置锚定2.5 分组 和 或者 3.扩展正则表达式4.部分文本处理工具4.1 tr 命令4.2 cut命令4.3 sort命令4.4 uniq命令 1.通配符和正则表达式的区别 通配符一般用于文件…...
RNN模型简单理解和CNN区别
目录 神经网络:水平方向延伸,数据不具有关联性 RNN:在神经网络的基础上加上了时间顺序,语义理解 RNN: 训练中采用梯度下降,反向传播 长短期记忆模型 输出关系:1 toN,N to N 单入…...
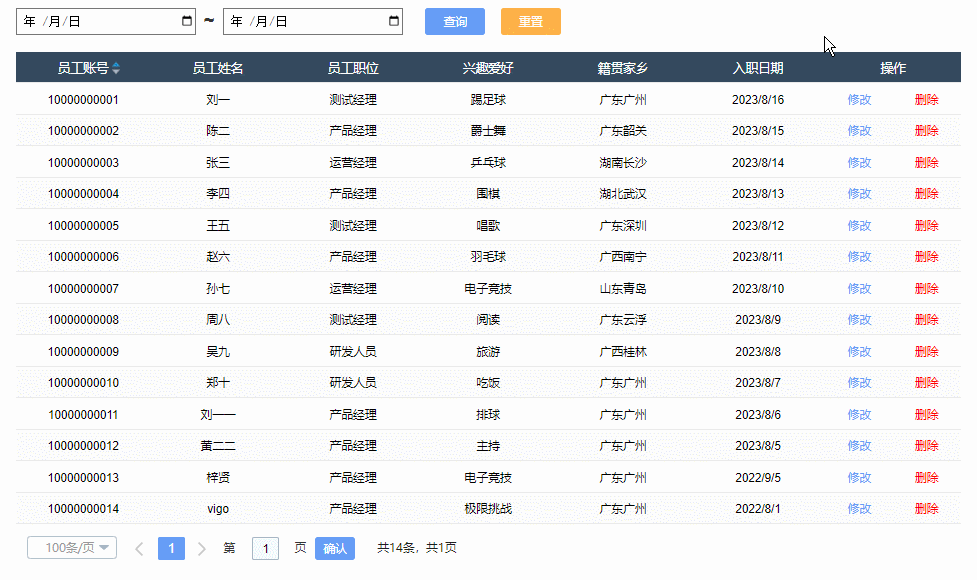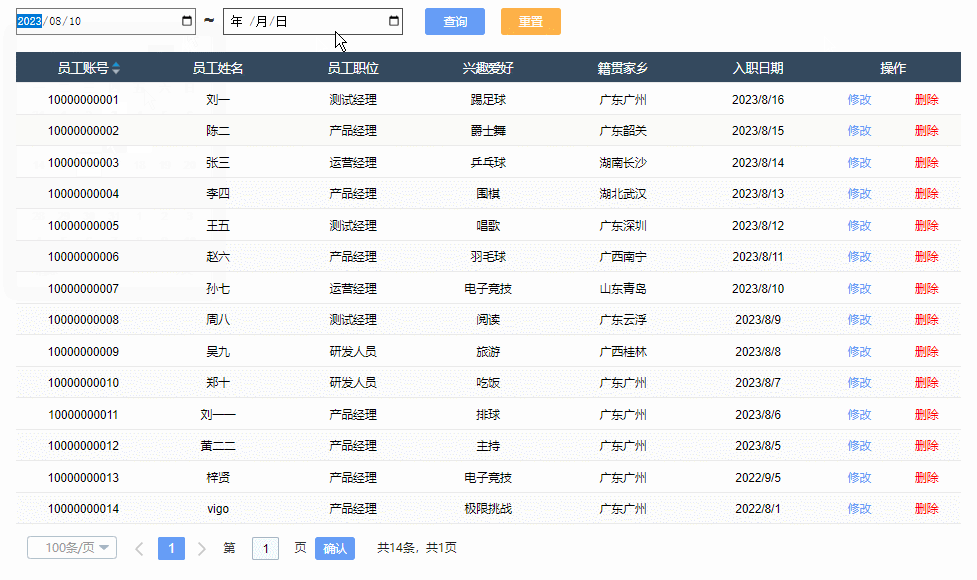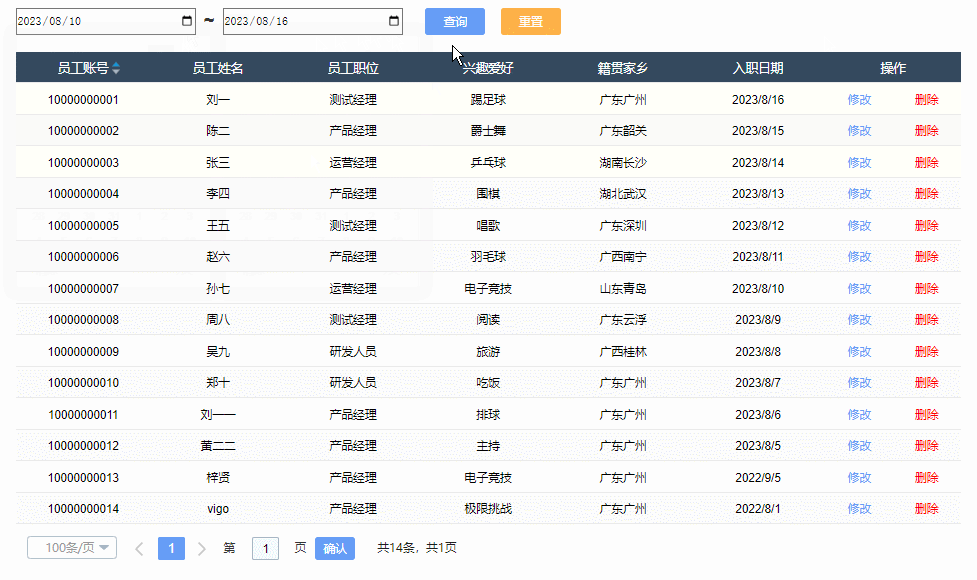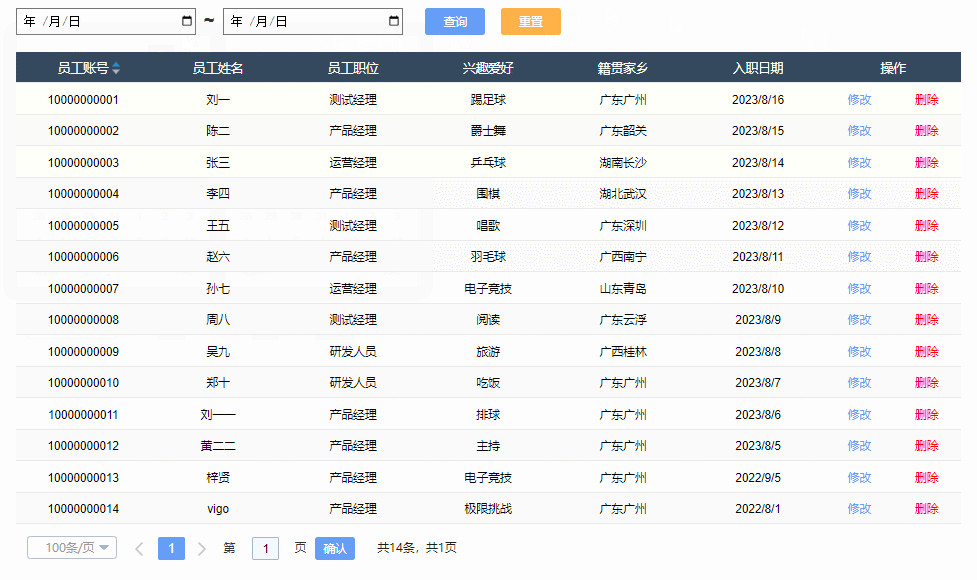
【Axure高保真原型】JS日期选择器筛选中继器表格
今天和大家分享JS日期选择器筛选中继器表格的原型模板,通过调用浏览器的日期选择器,所以可以获取真实的日历效果,具体包括哪一年二月份有29天,几号对应星期几,都是真实的,获取日期值后,通过交互…...

android bp脚本
一。android大约从7.0开始引入 .bp文件代替以前的.mk文件,用于帮助android项目的编译配置文件。 二。mk文件转化为bp文件,可以使用下面命令转化,注意命令中>,这是写入文件。androidmk是android源码自带的工具,他可…...
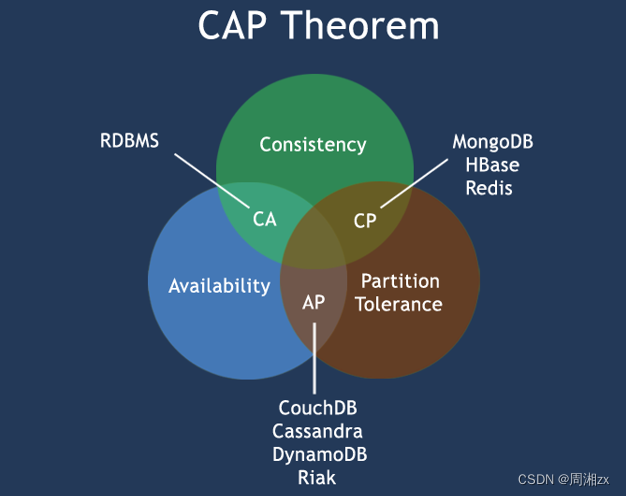
Redis 数据库 NoSQL
目录 一、NoSQL 二、为什么会出现NoSQL技术 三、NoSQL的类别 键值(Key-Value)存储数据库 列存储数据库 文档型数据库 图形(Graph)数据库 四、NoSQL适应场景 五、在分布式数据库中CAP原理 1、CAP 2、BASE 一、NoSQL NoS…...

RN 项目异常问题整理
常见问题 无法找到 CardStackStyleInterpolator StackViewStyleInterpolator 这个方法集来代替 CardStackStyleInterpolator的,这个方法集的路径也需要注意一下,在2.12.1版本之前, 该文件在react-navigation/src/views/StackView/中…...

STM8编程[TIM1多路PWM输出选项字节(Option Byte)操作和IO复用]
TIM1多路PWM输出选项字节(Option Byte)操作和IO复用 本文摘录于:https://blog.csdn.net/freeape/article/details/47008033只是做学习备份之用,绝无抄袭之意,有疑惑请联系本人! 代码上要使用TIME1输出3路PWM,代码如下: void tim…...
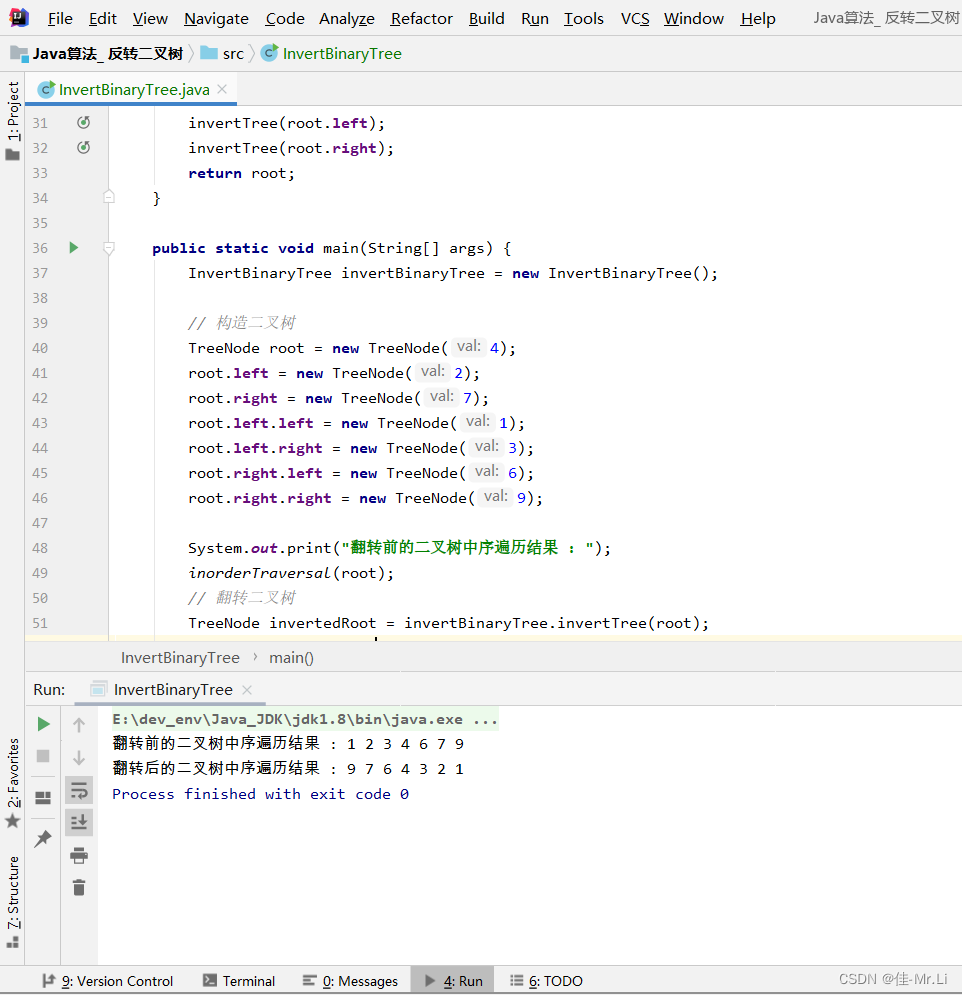
Java算法_ 反转二叉树(LeetCode_Hot100)
题目描述:给你一棵二叉树的根节点 ,翻转这棵二叉树,并返回其根节点。root。 获得更多?算法思路:代码文档,算法解析的私得。 运行效果 完整代码 /*** 2 * Author: LJJ* 3 * Date: 2023/8/16 13:18* 4*/public class In…...
)
C/C++ 标准模版库STL(持续更新版)
标准模版库STL 目录 算法库 栈 队列 向量 映射 列表 双向链表 集合 Iterator 送代器 <algorithm> 算法库 max, min 用于找出一组值中的最大值和最小值 swap 用于交换两个变量的值 sort 用于对一个范围内的元素进行排序 lower_bound, upper_bound 用于在已排序的容器…...
ARM(实验二)
uart4.h #ifndef __H__ #define __H__#include "stm32mp1xx_rcc.h" #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_uart.h"//RCC/GPIO/UART4章节初始化 void hal_uart4_init();//发送一个字符函数 void hal_put_char(const char str);//发…...

由“美”出发 听艺术家林曦关于美育与智慧的探讨
不久前,林曦老师与我们的老朋友「十点读书」进行了一次线上直播,有关林曦老师十余年的书法教学,和传统美育的心得,以及因此诞生的新书《无用之美》。 这一次的直播,由“美”的主题出发,延伸出美育…...

Serial与Parallel GC之间的不同之处是什么?
Serial GC(串行垃圾回收器)和Parallel GC(并行垃圾回收器)都是Java虚拟机(JVM)中用于进行垃圾回收的两种基本算法。它们在性能、资源利用和回收效率等方面存在一些不同之处。下面是它们之间的详细比较: 1.工作方式 Serial GC:它是一种单线程的垃圾回收器…...
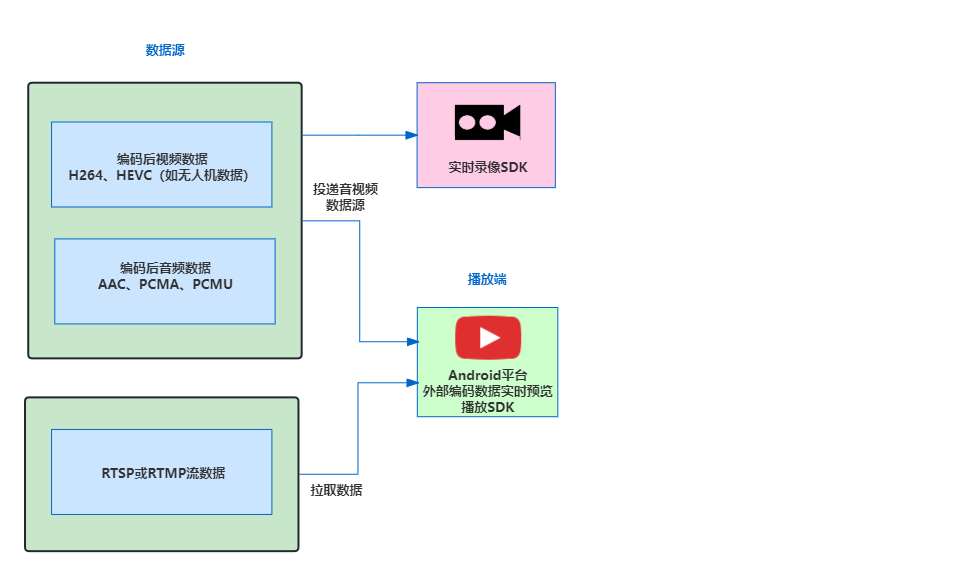
GB28181设备接入侧如何对接外部编码后音视频数据并实现预览播放
技术背景 我们在对接GB28181设备接入模块的时候,遇到这样的技术诉求,好多开发者期望能提供编码后(H.264/H.265、AAC/PCMA)数据对接,确保外部采集设备,比如无人机类似回调过来的数据,直接通过模…...
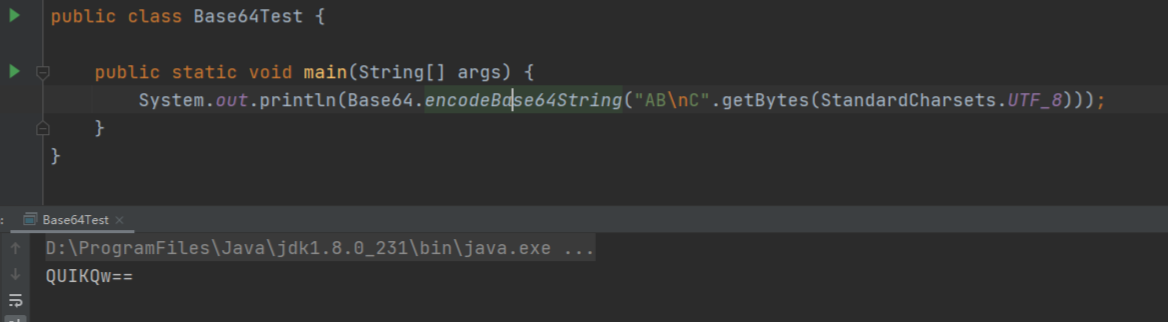
【java】为什么文件上传要转成Base64?
文章目录 1 前言2 multipart/form-data上传3 Base64上传3.1 Base64编码原理3.2 Base64编码的作用 4 总结 1 前言 最近在开发中遇到文件上传采用Base64的方式上传,记得以前刚开始学http上传文件的时候,都是通过content-type为multipart/form-data方式直接…...
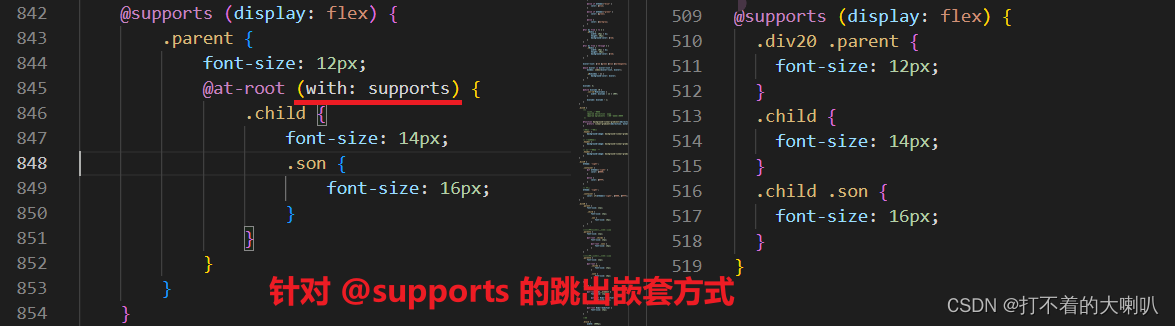
SCSS 学习笔记 和 vscode下载live sass compiler插件配置
1、下载livelive sass compiler插件并配置 // 在 已有代码 下面 添加下面 代码,一般刚刚下载打开最后一行是:// "liveSassCompile.settings.autoprefix": [],// 所以直接 把下面复制进去保存就行"liveSassCompile.settings.autoprefix&qu…...

CSS中的字体属性有哪些值,并分别描述它们的作用。
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ font-style⭐ font-weight⭐ font-size⭐ font-family⭐ font-variant⭐ line-height⭐ letter-spacing⭐ word-spacing⭐ font⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专…...
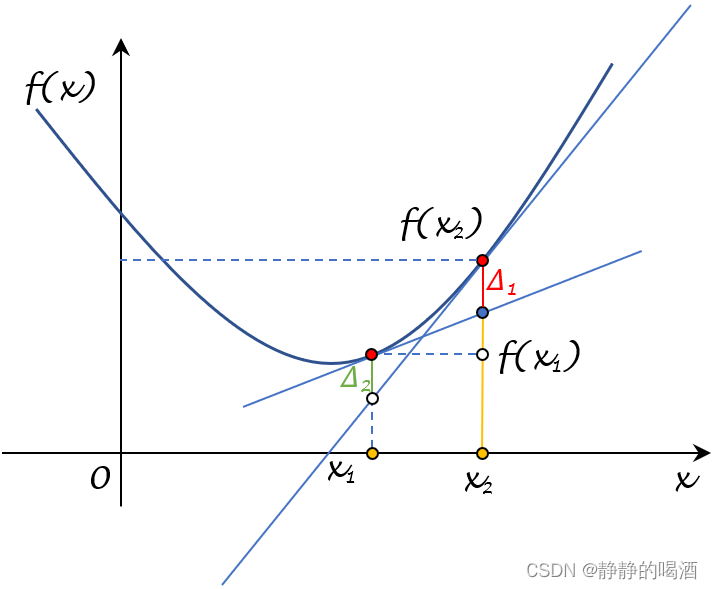
机器学习笔记之优化算法(十五)Baillon Haddad Theorem简单认识
机器学习笔记之优化算法——Baillon Haddad Theorem简单认识 引言 Baillon Haddad Theorem \text{Baillon Haddad Theorem} Baillon Haddad Theorem简单认识证明过程证明:条件 1 ⇒ 1 \Rightarrow 1⇒ 条件 2 2 2证明:条件 3 ⇒ 3 \Rightarrow 3⇒条件 1…...

HighTec工程用命令行编译
当工程中含有太多模型生成的代码的时候,如果修改了一部分代码,HighTec自带的编译器编译时间会非常的慢,有的需要半个小时甚至一个小时,这是因为每次修改之后HighTec都会从头重新检索更新,太浪费时间了,于是…...
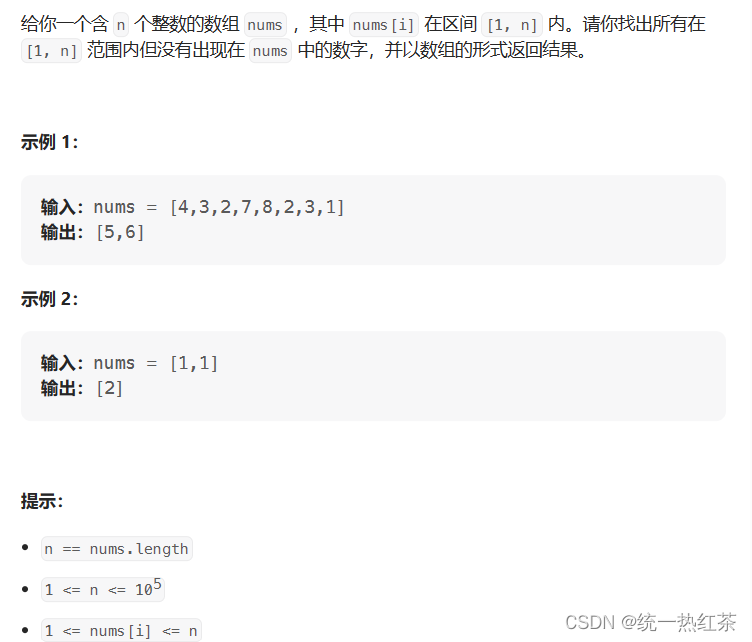
【C语言】每日一题(找到所有数组中消失的数字)
找到所有数组中消失的数字,链接奉上。 这里简单说一下,因为还没有接触到动态内存,数据结构,所以知识有限,也是尽力而为,结合题库的评论区找到了适合我的解法,以后有机会,会补上各种…...

智能识别整理会议内容,让开会后怎么列待办更清晰更省事
作为经常跑客户、开会议的销售,此前我常被整理沟通内容、梳理待办的工作困扰,不仅耗时久,还容易漏记客户需求、搞错时间节点。结合大半年的实测体验,整理出一套AI整理方法,能快速清晰梳理待办,节省大量时间…...

基于LLM的代码仓库智能分析:RepoMap-AI实现架构可视化与认知图谱
1. 项目概述:当AI成为你的代码库“活地图”最近在折腾一个老旧的Java项目,里面模块套模块,依赖关系复杂得像一团乱麻。想找个特定的工具类,得在十几个包里翻来覆去地搜;想理清某个核心服务的调用链路,光靠I…...

中国500万医生的新AI:顶刊独家联手,卷的就是证据源
金磊 发自 杭州量子位 | 公众号 QbitAI很反差。明明是一场AI的发布会,台下却坐满了医学界的大佬们:有北大、清华的,有浙江、上海的,甚至医学顶刊BMJ集团的主编都来围观了……△图片由AI生成为啥会这样?因为阿里健康正式…...

STM32 FSMC/FMC接口详解:地址映射、时序配置与实战优化
1. 项目概述:深入理解STM32的FSMC/FMC接口在嵌入式开发中,尤其是涉及大屏显示、高速数据采集或复杂外部设备交互的项目里,我们常常会遇到一个绕不开的“硬骨头”——如何让STM32单片机高效、稳定地与外部并行存储器或设备通信。这时ÿ…...
:auto_ptr的缺陷与unique_ptr)
【c++面向对象编程】第30篇:RAII与智能指针(一):auto_ptr的缺陷与unique_ptr
目录 一、一个手动管理的痛点 二、RAII 核心思想 三、auto_ptr:C98 的尝试与缺陷 auto_ptr 的核心缺陷 四、unique_ptr:真正的独占式智能指针 基本用法 常用成员函数 五、unique_ptr 与数组 六、自定义删除器 七、make_unique(C14&a…...

Rust嵌入式开发实战:开源机械爪控制库openclaw-rs架构解析与应用
1. 项目概述:当Rust遇上开源机械爪最近在逛GitHub的时候,偶然发现了一个挺有意思的项目——neul-labs/openclaw-rs。光看名字,你大概能猜到它是个用Rust语言写的、跟机械爪(Claw)相关的开源项目。没错,这正…...

数控编程软件|PowerMill 2026全流程下载安装教程
相信大家不会感到陌生,PowerMill是一款功能强大且专业的计算机辅助制造(CAM)软件工具,专注于复杂零件的数控(CNC)加工编程,尤其适用于模具、航空航天、汽车制造等高精度、高复杂度…...

如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题
如何通过DriverStore Explorer解决Windows驱动管理的三大核心难题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 作为一名系统管理员或技术爱好者,你是否曾面临这样的困境&…...

图像超分新SOTA:DAT模型凭什么在效果和效率上双赢?深入对比SwinIR、EDSR等经典方案
DAT模型:图像超分辨率领域的效率与效果平衡术 当一张模糊的老照片在算法处理后突然变得清晰可辨时,这种"魔法"背后是图像超分辨率技术的精妙演化。在这个领域,Transformer架构近年来展现出惊人的潜力,却也面临着计算复…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...