【李沐】3.2线性回归从0开始实现
%matplotlib inline
import random
import torch
from d2l import torch as d2l
1、生成数据集:
看最后的效果,用正态分布弄了一些噪音
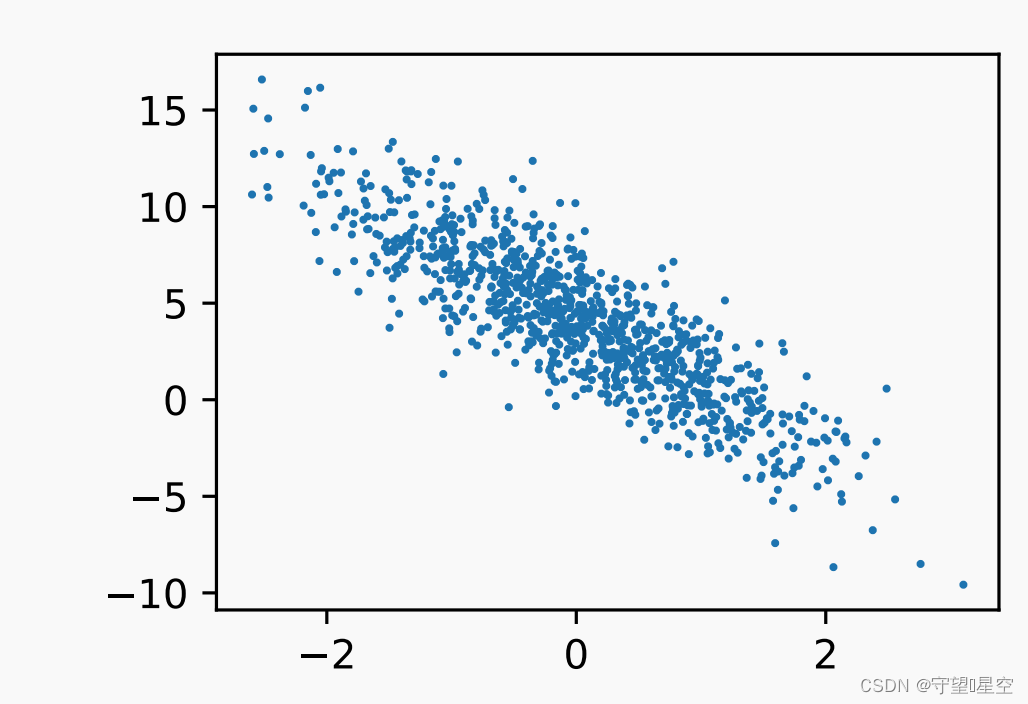
上面这个具体实现可以看书,又想了想还是上代码把:
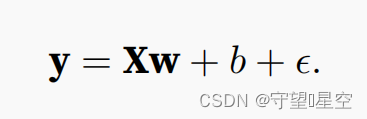
按照上面生成噪声,其中最后那个代表服从正态分布的噪声
def synthetic_data(w, b, num_examples): # 定义函数 synthetic_data,接受权重 w、偏差 b 和样本数量 num_examples 作为参数"""生成 y = Xw + b + 噪声 的合成数据集"""# 生成一个形状为 (num_examples, len(w)) 的特征矩阵 X,其中的元素是从均值为 0、标准差为 1 的正态分布中随机采样得到X = torch.normal(0, 1, (num_examples, len(w)))# 计算目标值 y,通过将特征矩阵 X 与权重 w 相乘,然后加上偏差 b,模拟线性回归的预测过程y = torch.matmul(X, w) + b# 给目标值 y 添加一个小的随机噪声,以模拟真实数据中的噪声。噪声从均值为 0、标准差为 0.01 的正态分布中随机采样得到y += torch.normal(0, 0.01, y.shape)# 返回特征矩阵 X 和目标值 y(将目标值 y 重塑为列向量的形式)return X, y.reshape((-1, 1)
# 定义真实的权重 true_w 为 [2, -3.4]
true_w = torch.tensor([2, -3.4])# 定义真实的偏差 true_b 为 4.2
true_b = 4.2# 调用 synthetic_data 函数生成合成数据集,传入真实的权重 true_w、偏差 true_b 和样本数量 1000
# 这将返回特征矩阵 features 和目标值 labels
features, labels = synthetic_data(true_w, true_b, 1000)2、读取数据集
注意一般情况下要打乱。
下面函数的作用是该函数接收批量⼤⼩、特征矩阵和标签向量作为输⼊,⽣成⼤⼩为batch_size的⼩批量。每个⼩批量包含⼀组特征和标签。
def data_iter(batch_size, features, labels):num_examples = len(features) # 获取样本数量indices = list(range(num_examples)) # 创建一个样本索引列表,表示样本的顺序# 将样本索引列表随机打乱,以便随机读取样本,没有特定的顺序random.shuffle(indices)# 通过循环每次取出一个批次大小的样本for i in range(0, num_examples, batch_size):# 计算当前批次的样本索引范围,确保不超出总样本数量batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])# 通过索引获取对应的特征和标签,然后通过 yield 返回这个批次的数据# yield 使得函数可以作为迭代器使用,在每次迭代时产生一个新的批次数据yield features[batch_indices], labels[batch_indices]3、初始化模型参数
第一步:前面两行代码,,我
们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,并将偏置初始化为0。
计算梯度使用2.5节引入的自动微分
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
4、定义模型
这里注意b是一个标量和向量相加,咋办?
前面说过向量的广播机制,就相当于是加到每一个上面
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
5、定义损失函数
y.reshape(y_hat.shape))啥意思?
y_hat是真实值,这里的意思是弄成和y_hat相同的大小
def squared_loss(y_hat, y): #@save
"""均⽅损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
6、优化算法
问:这里的参数是啥参数?params
更新完的参数不用返回吗?
为什么需要梯度清零?
def sgd(params, lr, batch_size): # 定义函数 sgd,接受参数 params、学习率 lr 和批次大小 batch_size"""小批量随机梯度下降"""with torch.no_grad(): # 使用 torch.no_grad() 来关闭梯度跟踪,以减少内存消耗for param in params: # 遍历模型参数列表param -= lr * param.grad / batch_size # 更新参数:参数 = 参数 - 学习率 * 参数梯度 / 批次大小param.grad.zero_() # 清零参数的梯度,以便下一轮梯度计算7、训练
问:反向传播是为了干啥?
是为了计算梯度,那梯度是啥呢
梯度是参数更快收敛的方向(就是向量)
优化方法是干啥的?
优化方法就是根据上面传过来的梯度,计算参数更新
所以,这几章看完后需要梳理深度学习的整个过程,以及每块有哪些方法,这些方法的特点和用那种方法更好
问(1)每个epoch训练多少数据?
整个训练集
(2)损失函数是啥?
损失函数是用来计算真实值域预测值之间的距离,当然是距离越小越好,可以拿均方误差想一下
(3)l.sum().backward()是啥意思?
看注释,补充:.backward() 方法用于执行自动求导,计算总的损失值对于模型参数的梯度。这将会构建计算图并沿着图的反向传播路径计算梯度。
(4)但是上面所说的梯度保存在哪里呢?
w.grad 和 b.grad 中
(5)但是sgd中也没有用到w.grad 啊?
用到了,param 可以是 w 或者 b,而 param.grad 则是相应参数的梯度。
(6)新问题:train_l = loss(net(features, w, b), labels)不是在前面已经计算过损失函数了吗?为啥在这里还需要计算?
前面计算损失函数是间断性的,目的是更新模型参数。
后面仍然计算的目的是根据更新完的参数对模型在整个训练集上与真实标签的差距做一个评估。
lr = 0.03 # 设置学习率为 0.03,控制每次参数更新的步幅num_epochs = 3 # 设置训练的轮次(迭代次数)为 3,即遍历整个数据集的次数net = linreg # 定义模型 net,通常表示线性回归模型loss = squared_loss # 定义损失函数 loss,通常为均方损失函数,用于衡量预测值与真实值之间的差距
for epoch in range(num_epochs): # 迭代 num_epochs 轮,进行训练for X, y in data_iter(batch_size, features, labels): # 遍历数据集的每个批次l = loss(net(X, w, b), y) # 计算当前批次的损失值 l,表示预测值与真实值之间的差距# 因为 l 的形状是 (batch_size, 1),而不是一个标量。将 l 中的所有元素加起来,# 并计算关于 [w, b] 的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数,执行随机梯度下降算法with torch.no_grad():train_l = loss(net(features, w, b), labels) # 在整个训练集上计算损失值# 打印当前迭代轮次和训练损失值的均值print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
8、练习中的问题
- 如果我们将权重初始化为零,会发⽣什么。算法仍然有效吗?
无效,为啥?因为,不同的X输入是相同的输出
相关文章:
【李沐】3.2线性回归从0开始实现
%matplotlib inline import random import torch from d2l import torch as d2l1、生成数据集: 看最后的效果,用正态分布弄了一些噪音 上面这个具体实现可以看书,又想了想还是上代码把: 按照上面生成噪声,其中最后那…...
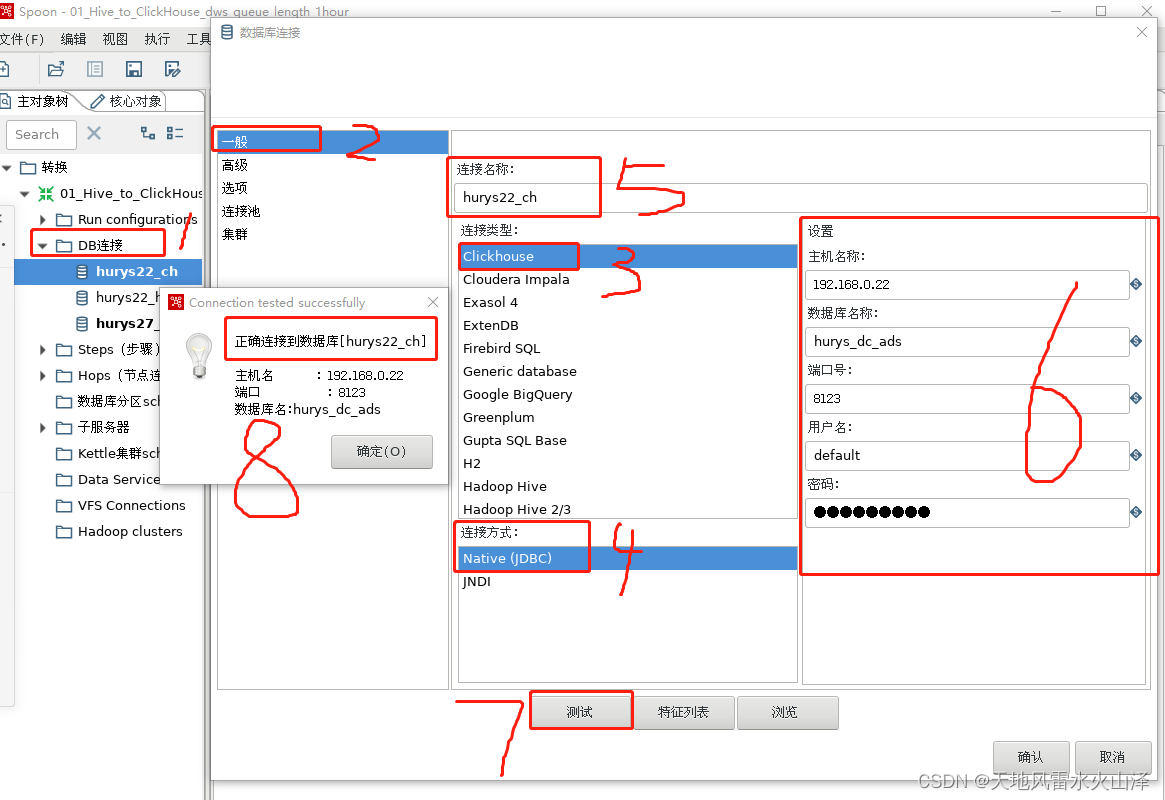
一百五十六、Kettle——Linux上安装的Kettle9.3连接ClickHouse数据库(亲测,附流程截图)
一、目标 kettle9.3在Linux上安装好后,需要与ClickHouse数据库建立连接 二、前提准备 (一)在Linux已经安装好kettle并可以启动kettle (二)已知kettle和ClickHouse版本 1、kettle版本是9.3 2、ClickHouse版本是21…...
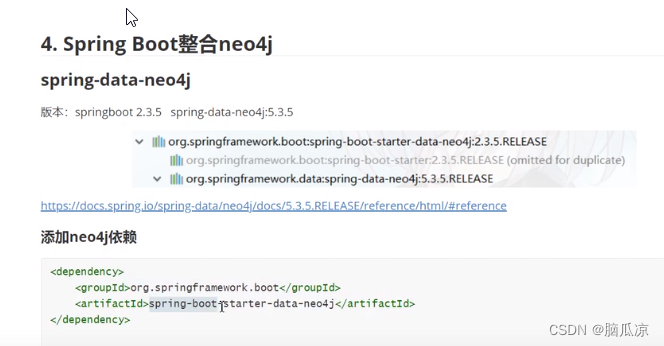
图数据库_Neo4j和SpringBoot整合使用_创建节点_删除节点_创建关系_使用CQL操作图谱---Neo4j图数据库工作笔记0009
首先需要引入依赖 springboot提供了一个spring data neo4j来操作 neo4j 可以看到它的架构 这个是下载下来的jar包来看看 有很多cypher对吧 可以看到就是通过封装的驱动来操作graph database 然后开始弄一下 首先添加依赖...
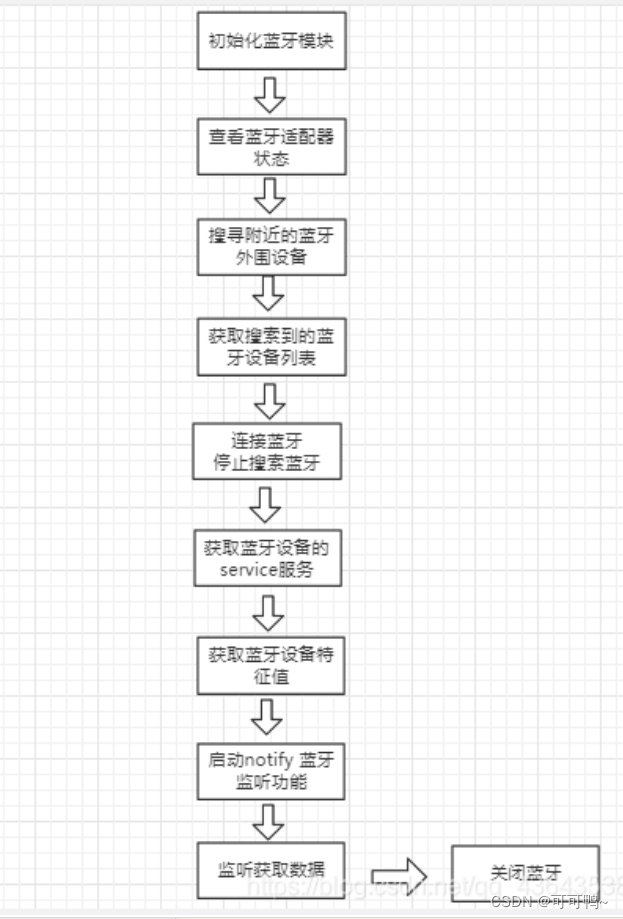
Uniapp连接蓝牙设备
一、效果图 二、流程图 三、实现 UI <uni-list><uni-list :border="true"><!-- 显示圆形头像 -->...

linux切换到root用户:su root和sudo su命令的区别
前言 工作过程中遇到需要切换到root用户下去执行命令 方法1:工作中常会选择这个方法 利用su root命令 临时获取root用户权限,工作目录不变 好处:不需要知道root用户的密码,直接输入普通用户的密码即可 方法2 利用sudo su命…...
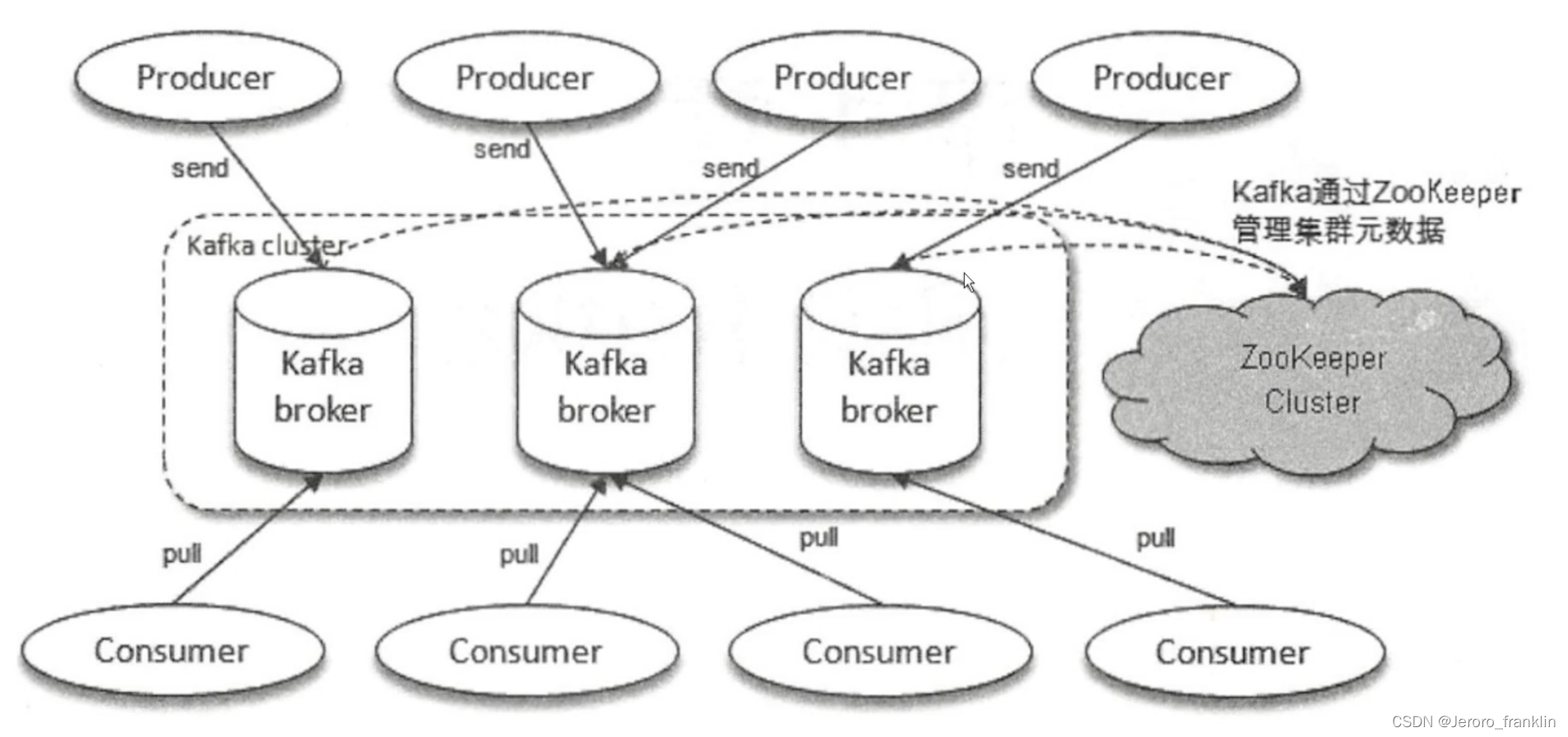
kafka-- kafka集群 架构模型职责分派讲解
一、 kafka集群 架构模型职责分派讲解 生产者将消息发送到相应的Topic,而消费者通过从Topic拉取消息来消费 Kafka奇数个节点消费者consumer会将消息拉去过来生产者producer会将消息发送出去数据管理 放在zookeeper...
)
Effective C++条款07——为多态基类声明virtual析构函数(构造/析构/赋值运算)
有许多种做法可以记录时间,因此,设计一个TimeKeeper base class和一些derived classes 作为不同的计时方法,相当合情合理: class TimeKeeper { public:TimeKeeper();~TimeKeeper();// ... };class AtomicClock: public TimeKeepe…...
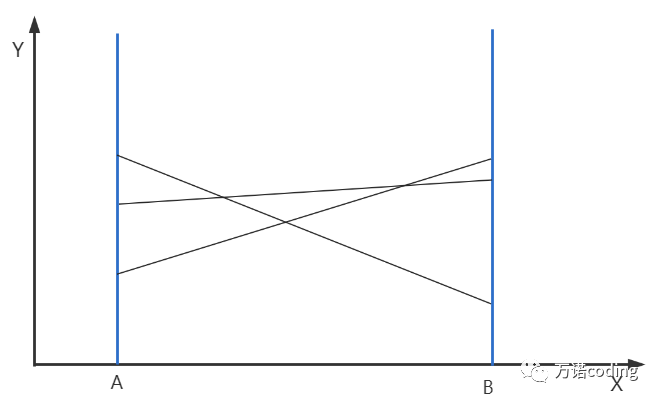
用友Java后端笔试2023-8-5
计算被直线划分区域 在笛卡尔坐标系,存在区域[A,B],被不同线划分成多块小的区域,简单起见,假设这些不同线都直线并且不存在三条直线相交于一点的情况。 img 那么,如何快速计算某个时刻,在 X 坐标轴上[ A,…...
idea2023 springboot2.7.5+mybatis+jsp 初学单表增删改查
创建项目 因为2.7.14使用量较少,特更改spring-boot为2.7.5版本 配置端口号 打开Sm01Application类,右键运行启动项目,或者按照如下箭头启动 启动后,控制台提示如下信息表示成功 此刻在浏览器中输入:http://lo…...
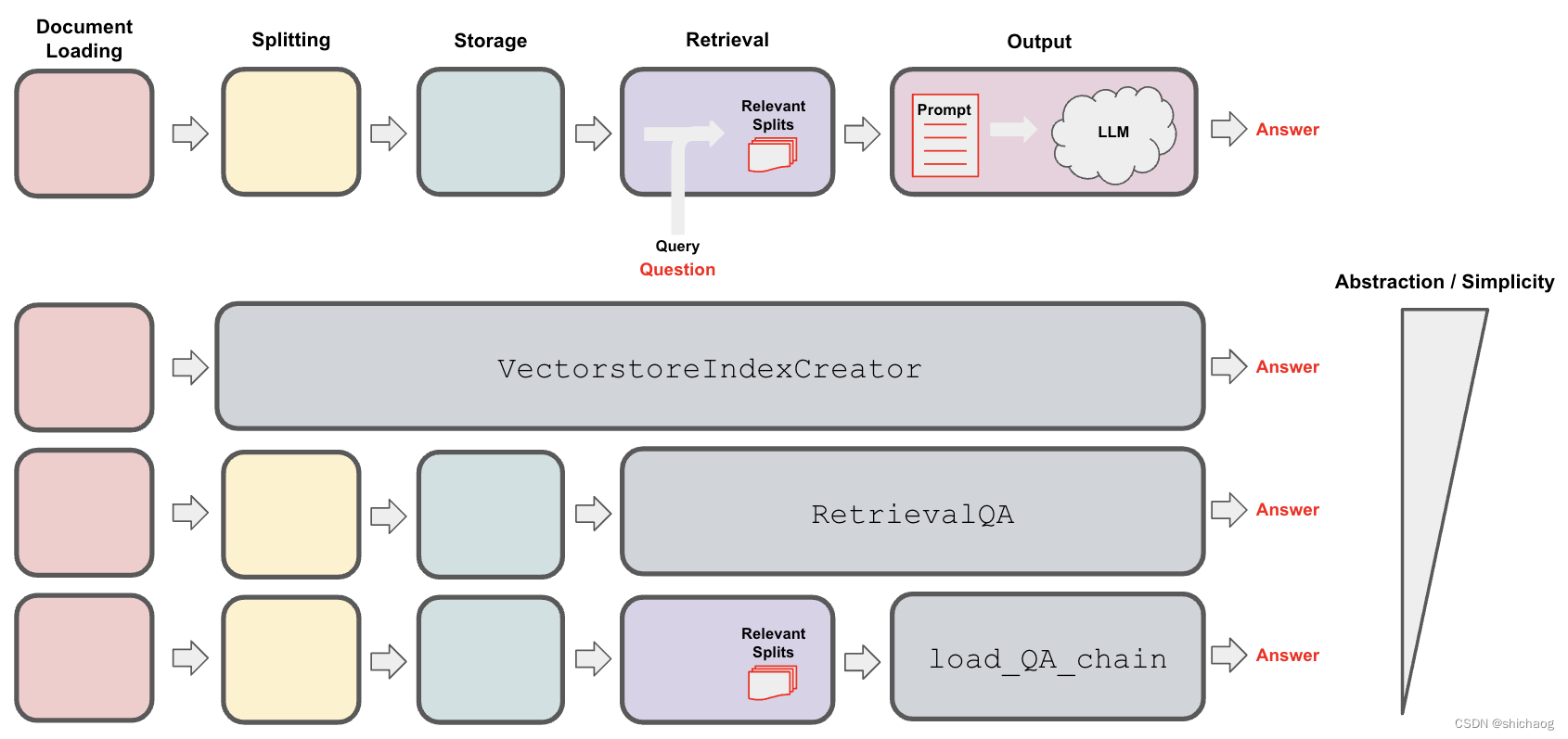
大语言模型之四-LlaMA-2从模型到应用
最近开源大语言模型LlaMA-2火出圈,从huggingface的Open LLM Leaderboard开源大语言模型排行榜可以看到LlaMA-2还是非常有潜力的开源商用大语言模型之一,相比InstructGPT,LlaMA-2在数据质量、培训技术、能力评估、安全评估和责任发布方面进行了…...
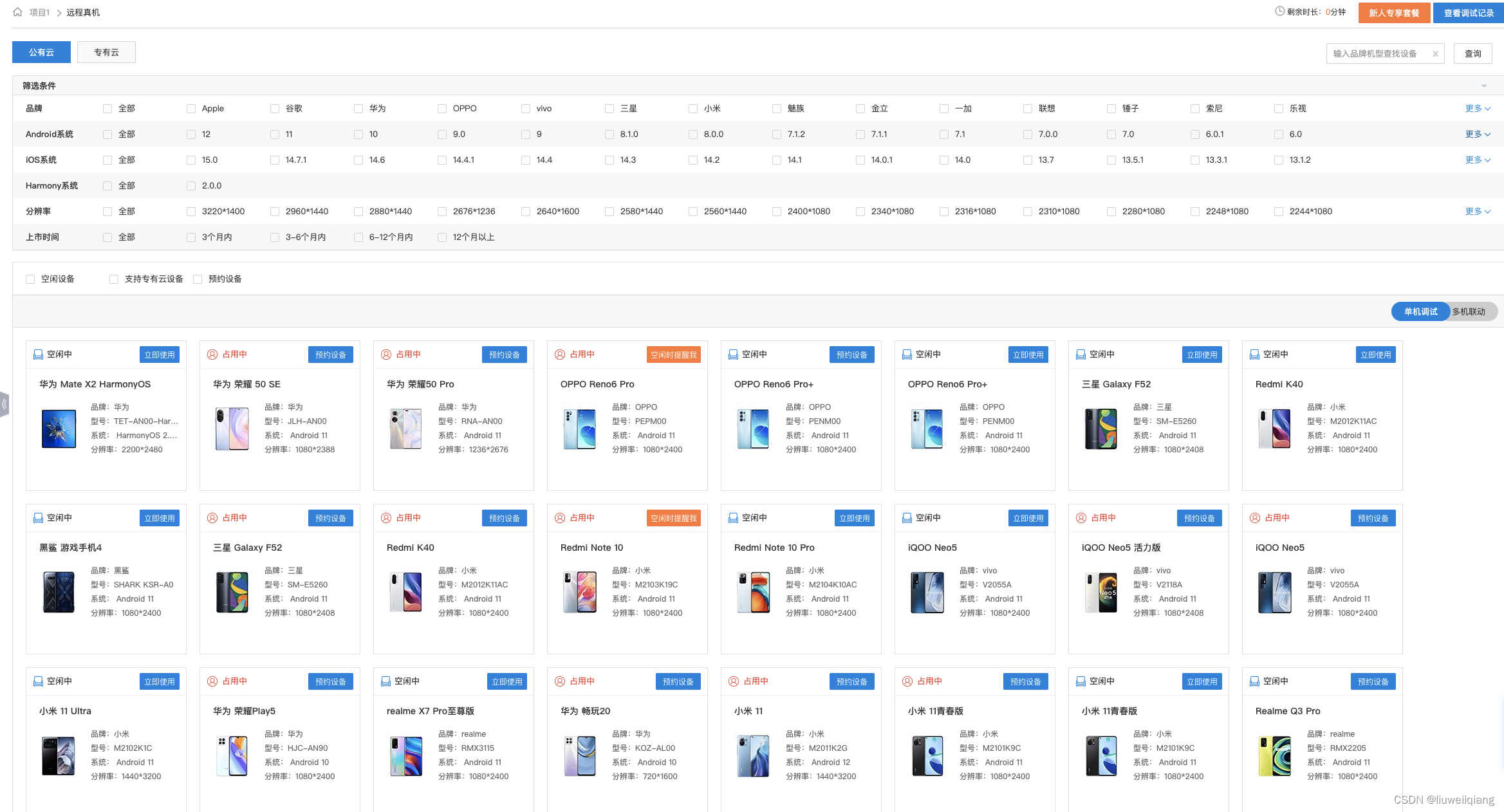
Android 远程真机调研
背景 现有的安卓测试机器较少,很难满足 SDK 的兼容性测试及线上问题(特殊机型)验证,基于真机成本较高且数量较多的前提下,可以考虑使用云测平台上的机器进行验证,因此需要针对各云测平台进行调研、比较。 …...
)
B. 攻防演练 (2021CCPC女生赛)
题意: 给出一个长度为n的字符,字符是前m个小写字母,有q个询问,每次询问一个最短子序列的长度满足不是[l,r]内任意一个子序列 思路: [l,r]中子序列可以看成是从[l,r]中的某个位置开始,跳到下一个字符的位…...
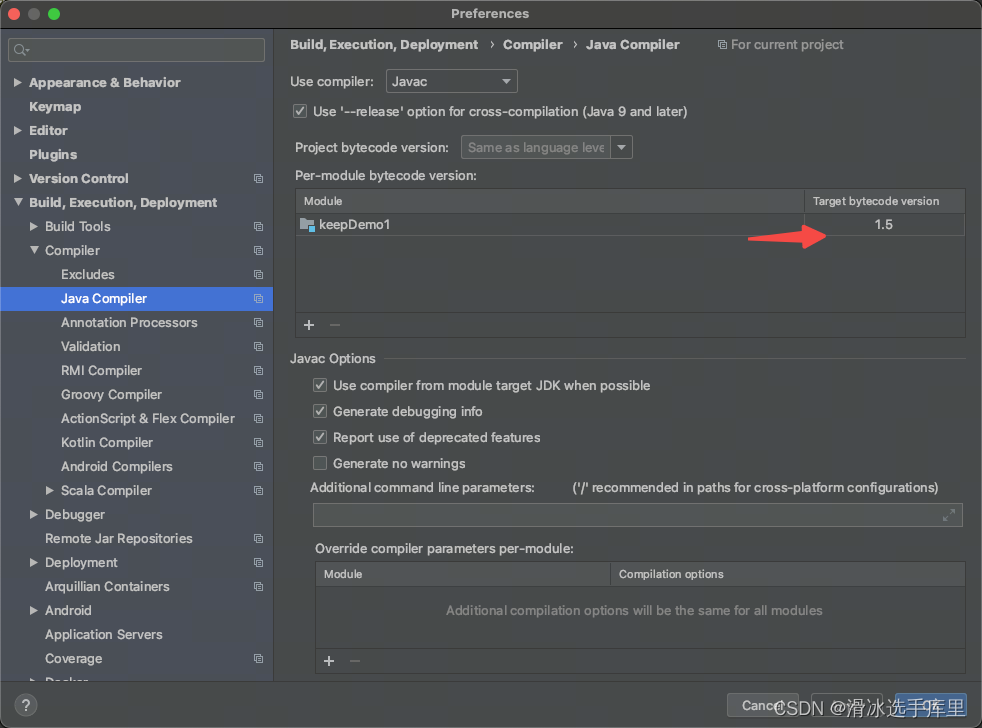
MAC环境,在IDEA执行报错java: -source 1.5 中不支持 diamond 运算符
Error:(41, 51) java: -source 1.5 中不支持 diamond 运算符 (请使用 -source 7 或更高版本以启用 diamond 运算符) 进入设置 修改java版本 pom文件中加入 <plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin&l…...
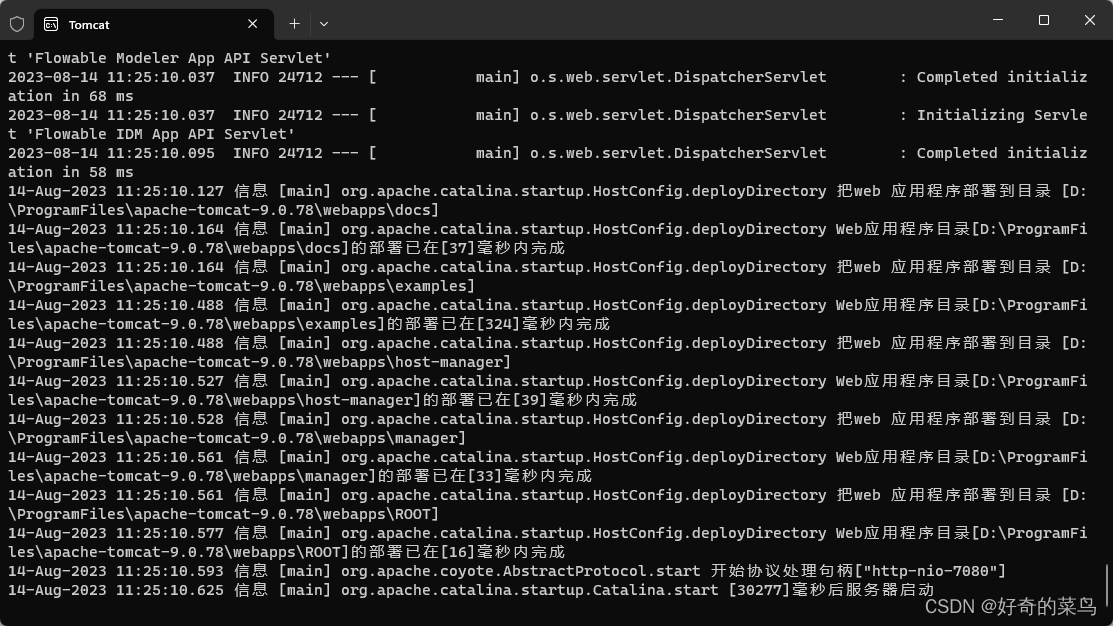
Tomcat日志中文乱码
修改安装目录下的日志配置 D:\ProgramFiles\apache-tomcat-9.0.78\conf\logging.properties java.util.logging.ConsoleHandler.encoding GBK...
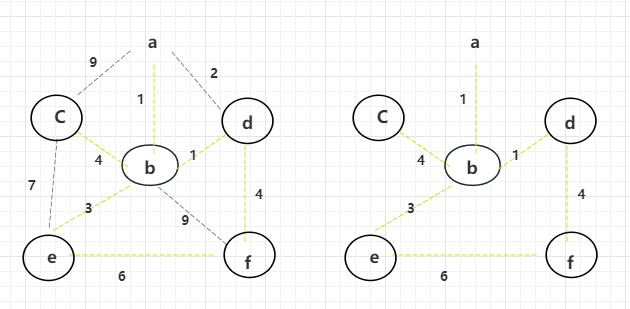
最小生成树 — Prim算法
同Kruskal算法一样,Prim算法也是最小生成树的算法,但与Kruskal算法有较大的差别。 Prim算法整体是通过“解锁” “选中”的方式,点 -> 边 -> 点 -> 边。 因为是最小生成树,所以针对的也是无向图,所以可以随意…...

如何使用PHP Smarty模板进行AJAX交互?
首先,我们要明白,AJAX是一种在无需刷新整个页面的情况下,与服务器进行通信的技术。这对于改善用户体验来说,是个大宝贝。而PHP Smarty模板则是PHP的一种模板引擎,它使得设计和开发人员能够更好地分离逻辑和显示。 现在…...
nginx反向代理、负载均衡
修改nginx.conf的配置 upstream nginx_boot{# 30s内检查心跳发送两次包,未回复就代表该机器宕机,请求分发权重比为1:2server 192.168.87.143 weight100 max_fails2 fail_timeout30s; server 192.168.87.1 weight200 max_fails2 fail_timeout30s;# 这里的…...
React Native文本添加下划线
import { StyleSheet } from react-nativeconst styles StyleSheet.create({mExchangeCopyText: {fontWeight: bold, color: #1677ff, textDecorationLine: underline} })export default styles...

微服务-Nacos(配置管理)
配置更改热更新 在Nacos中添加配置信息: 在弹出表单中填写配置信息: 配置获取的步骤如下: 1.引入Nacos的配置管理客户端依赖(A、B服务): <!--nacos的配置管理依赖--><dependency><groupId&…...

UML图绘制 -- 类图
1.类图的画法 类 整体是个矩形,第一层类名,第二层属性,第三层方法。 :public- : private# : protected空格: 默认的default 对应的类写法。 public class Student {public String name;public Integer age;protected I…...

基于TRRS Trinkey的辅助技术设备开发:从接口转换到可编程交互
1. 项目概述:当辅助技术遇上可编程硬件如果你接触过辅助技术(Assistive Technology, AT),或者身边有朋友需要借助特殊设备与数字世界交互,你可能会发现,市面上很多现成的开关、控制器要么功能单一ÿ…...

RMSNorm:均方根归一化总结
RMSNorm:均方根归一化总结 1. RMSNorm 是什么? RMSNorm 的全称是 Root Mean Square Normalization,中文可以叫:均方根归一化它是 Transformer 大模型中常用的一种归一化方法,例如 LLaMA、Qwen、DeepSeek、Gemma 等模型…...

成都口碑好的特斯拉专修公司有哪些
在成都,如果你是特斯拉车主,寻找一家靠谱的专修公司是非常重要的。今天就给大家推荐一家口碑极佳的特斯拉专修公司——TBA特斯拉专修(成都三业店),也就是成都市三业汽车服务有限责任公司。下面从多个方面来看看它的优势…...

“梦想、汗水、坚持”2026 SNH48 GROUP年度青春盛典5月30日正式启动
“十三而砺,向新而行。”中国大型青春女团SNH48 GROUP运营方上海丝芭文化传媒集团有限公司即日宣布:2026 SNH48 GROUP第十三届年度青春盛典大型系列活动将于5月30日正式启动,本届年度青春盛典颁奖典礼暨汇报演唱会定档8月8日,落地…...

开源智能告警聚合路由引擎:从原理到实战部署
1. 项目概述:一个开源的智能告警聚合与路由引擎如果你和我一样,长期负责线上系统的稳定性,那你一定对“告警风暴”和“告警疲劳”这两个词深恶痛绝。想象一下这样的场景:凌晨三点,一个核心服务的某个实例因为网络抖动重…...
)
保姆级拆解:用代码和图示彻底搞懂YOLOv7的Backbone与Head(附ELAN模块详解)
保姆级拆解:用代码和图示彻底搞懂YOLOv7的Backbone与Head(附ELAN模块详解) 在计算机视觉领域,目标检测一直是热门研究方向。YOLO系列作为其中的佼佼者,以其高效和准确著称。YOLOv7作为该系列的最新成员,在速…...

构建AI智能体调度平台:从微服务架构到工程实践
1. 项目概述:一个面向智能体的“Airbnb”式调度平台最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家把模型、工具链、工作流都搭好了,但真要让多个智能体协同工作,或者把智能…...

智能语义分块:chunkhound如何解决RAG应用中的文档处理难题
1. 项目概述:从“分块”到“猎犬”的智能进化如果你在数据处理的深海里游过泳,尤其是处理过那些动辄几十上百GB的文本、代码或日志文件,那你一定对“分块”(Chunking)这个概念又爱又恨。爱的是,它是我们处理…...

LT6110远程电压补偿技术原理与应用
1. 远程负载电压补偿技术解析在工业自动化、数据中心等分布式供电系统中,工程师们经常面临一个经典难题:当电源与负载之间存在较长距离时,导线电阻导致的电压下降会显著影响负载端的供电质量。这种现象的本质是欧姆定律(VIR&#…...

ToyKind-World:基于Python的ECS架构多智能体模拟框架构建指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ToyKind-World”。光看这个名字,你可能会觉得有点抽象,是玩具世界?还是某种模拟器?点进去一看,发现它其实是一个用Python构建的、高度可配…...