redis实战-缓存数据解决缓存与数据库数据一致性
缓存的定义
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。防止过高的数据访问猛冲系统,导致其操作线程无法及时处理信息而瘫痪,这在实际开发中对企业讲,对产品口碑,用户评价都是致命的;所以企业非常重视缓存技术,redis作为最常用的缓存中间件,也是面试的高频考点。
使用缓存的目的
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力。实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存,系统是几乎撑不住的,所以企业会大量运用到缓存技术。
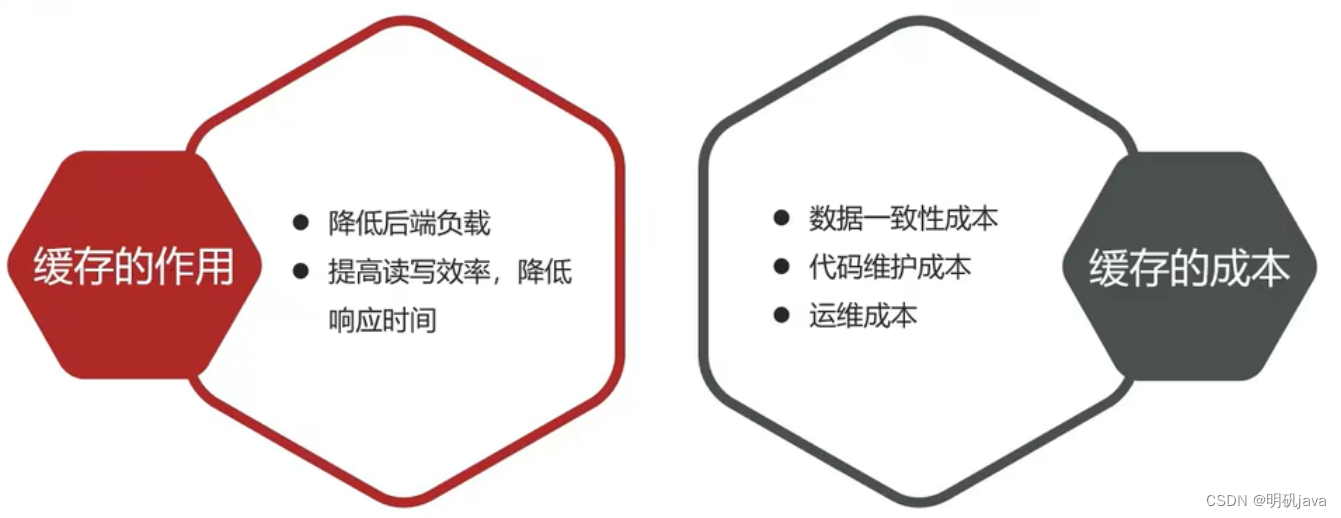
如何使用缓存
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
浏览器缓存:主要是存在于浏览器端的缓存
应用层缓存:可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
数据库缓存:在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
CPU缓存:当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
缓存商铺信息
商铺信息接口具有很高的并发量,查询数据不能每次都从数据库查询,要将商铺数据缓存到redis中,来应对高并发
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {//这里是直接查询数据库return shopService.queryById(id);
}
缓存模型和思路
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
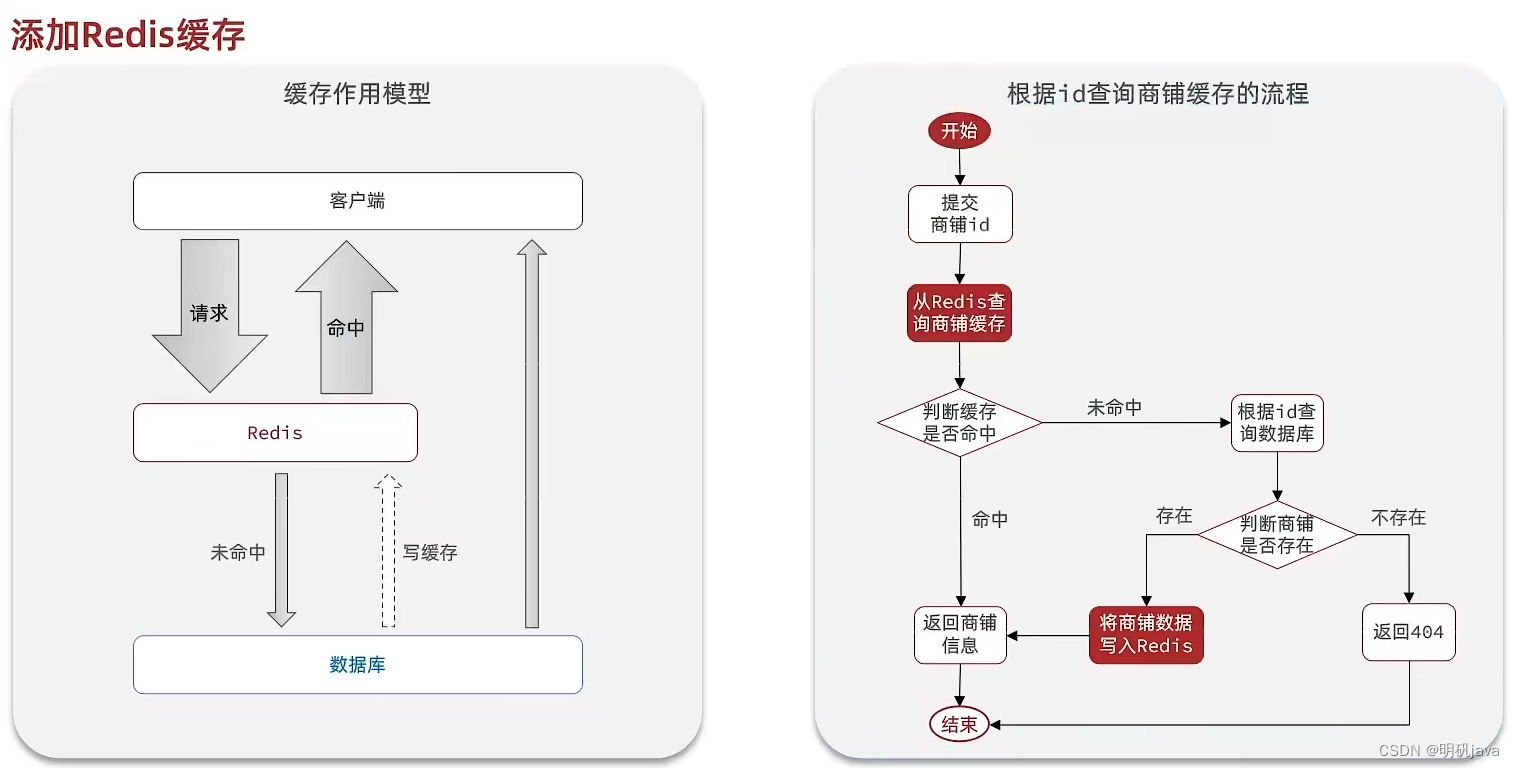
代码实现
注意此时缓存数据不设置过期时间,为了减轻数据库压力,缓存应该常驻在内存中,但也会带来一个那就是缓存数据与数据库数据不一致的问题,这就引出了缓冲更新策略这一问题
@Overridepublic Result queryById(Long id) {//根据业务代码组装keyString key = CACHE_SHOP_KEY + id;//从redis中获取商铺信息String shopJson = stringRedisTemplate.opsForValue().get(key);if (StrUtil.isNotBlank(shopJson)) {//将json转化为shop对象直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}Shop shop = getById(id);if (shop == null) {return Result.fail("店铺不存在");}//将数据库查询的数据写入缓存stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));//返回return Result.ok(shop);缓存更新策略
更新策略主要根据业务来选择,在本项目中采用的是主动更新+超时剔除的更新策略,超时剔除主要是作为保底的更新策略,保证缓存在没有触发主动更新的情况下,每隔一段时间就会清理缓存
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题

数据库缓存数据不一致解决方案
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等;怎么解决呢?有如下几种方案
Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
使用方案二增加了系统复杂度,不利于调用者排查有关问题,方案三会有一系列线程安全,造成数据库缓存不一致的情况,经过综合考虑选用人工编码的方式较为稳妥
人工编码步骤
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存,(如果是更新数据库的同时,更新缓存,会有太多更新动作,无法保证性能)
- 在单体系统中,将缓存与数据库操作放在一个事务,保证更新数据库成功时,缓存也要添加成功,即保证两个操作同时成功或失败
-
先操作数据库,再删除缓存,在多线程的情况下,操作数据库的时间要比操作redis缓存的时间多得多,出现数据库写完,缓存失效的可能性较小
实现商铺和缓存与数据库双写一致
- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
- 根据id修改店铺时,先修改数据库,再删除缓存
添加缓存时设置redis缓存时添加过期时间
@Overridepublic Result queryById(Long id) {//根据业务代码组装keyString key = CACHE_SHOP_KEY + id;//从redis中获取商铺信息String shopJson = stringRedisTemplate.opsForValue().get(key);if (StrUtil.isNotBlank(shopJson)) {//将json转化为shop对象直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}Shop shop = getById(id);if (shop == null) {return Result.fail("店铺不存在");}//将数据库查询的数据写入缓存,并设置过期时间stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30L,TimeUnit.MINUTES);//返回return Result.ok(shop);}我们确定了采用删除策略,来解决双写问题,当我们修改了数据之后,然后把缓存中的数据进行删除,查询时发现缓存中没有数据,则会从mysql中加载最新的数据,从而避免数据库和缓存不一致的问题,此方法需要加@Transactional注解来声明事务
@Transactional
@Override
public Result update(Shop shop) {Long id = shop.getId();//判断id是否为空,因为可以绕过前端直接发送请求,此步必须判断if (id == null) {return Result.fail("店铺id不能为空");}//更新数据库updateById(shop);//删除缓存stringRedisTemplate.delete(CACHE_SHOP_KEY + id);return Result.ok();
}相关文章:
redis实战-缓存数据解决缓存与数据库数据一致性
缓存的定义 缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。防止过高的数据访问猛冲系统,导致其操作线程无法及时处理信息而瘫痪,这在实际开发中对企业讲,对产品口碑,用户评价都是致命的;所以企业非常重视缓存…...

【排序】选择排序
文章目录 选择排序时间复杂度空间复杂度稳定性 代码 选择排序 以从小到大为例进行说明。 选择排序就是定义出一个最小值下标,然后遍历整个剩下的数组选择出最小的放进最小值下标的位置。 时间复杂度 O(N) 遍历一次即可 空间复杂度 O(1) 稳定性 不稳定 代码 p…...

深入浅出Pytorch函数——torch.nn.init.trunc_normal_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

探索高级UI、源码解析与性能优化,了解开源框架及Flutter,助力Java和Kotlin筑基,揭秘NDK的魅力!
课程链接: 链接: https://pan.baidu.com/s/13cR0Ip6lzgFoz0rcmgYGZA?pwdy7hp 提取码: y7hp 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v4的分享 课程介绍: 📚【01】Java筑基:全方位指…...

国外服务器怎么有效降低延迟
国外服务器怎么有效降低延迟?在全球化网络环境下,越来越多的企业和个人选择使用国外服务器来托管网站、应用程序或数据。然而,由于地理位置、网络连接等因素,使用国外服务器时可能会遇到延迟较高的问题。高延迟不仅影响用户体验,…...
AI百度文心一言大语言模型接入使用(中国版ChatGPT)
百度文心一言接入使用(中国版ChatGPT) 一、百度文心一言API二、使用步骤1、接口2、请求参数3、请求参数示例4、接口 返回示例 三、 如何获取appKey和uid1、申请appKey:2、获取appKey和uid 四、重要说明 一、百度文心一言API 基于百度文心一言语言大模型…...
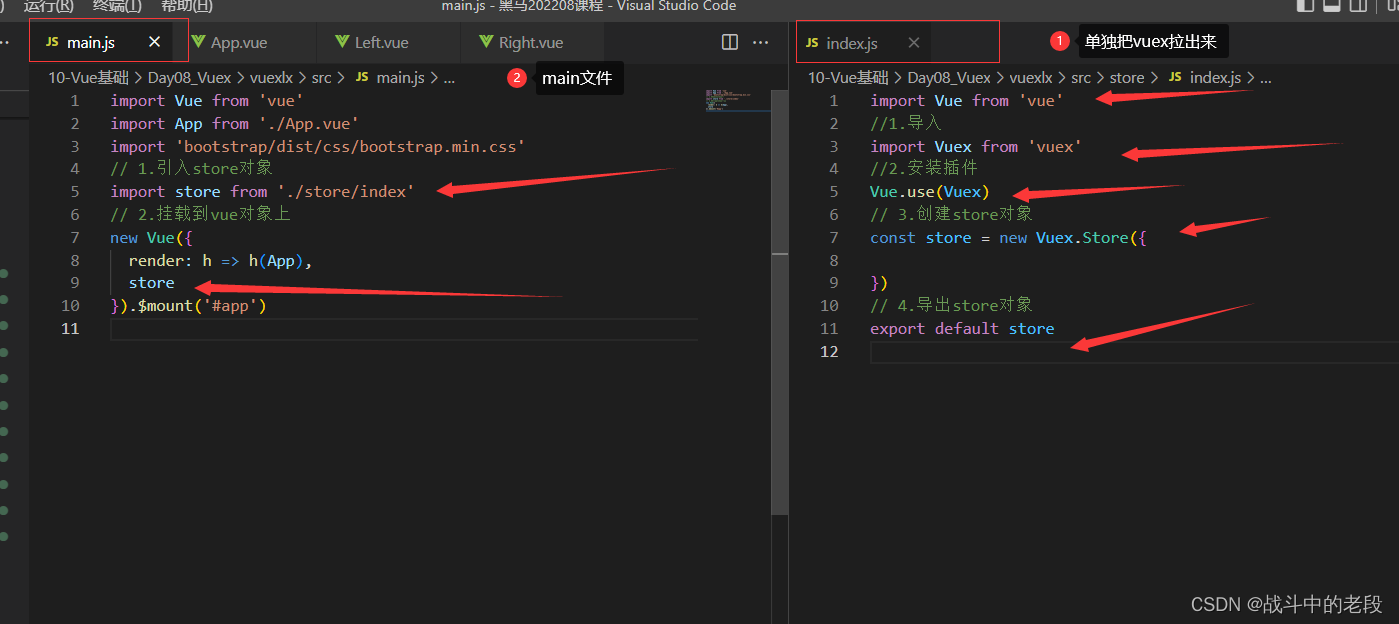
vue 安装并配置vuex
1.安装vuex命令:npm i vuex3.6.2 2.全局配置 在main文件里边导入-安装-挂载 main.js页面配置的 import Vue from vue import App from ./App.vue import Vuex from vuex//导入 Vue.use(Vuex)//安装插件 // 创建store对象 const store new Vuex.Store({ }) // 挂载到vue对象上…...
有一种新型病毒在 3Ds Max 环境中传播,如何避免?
3ds Max渲染慢,可以使用渲云渲染农场: 渲云渲染农场解决本地渲染慢、电脑配置不足、紧急项目渲染等问题,可批量渲染,批量出结果,速度快,效率高。 此外3dmax支持的CG MAGIC插件专业版正式上线,…...

基于Java/springboot铁路物流数据平台的设计与实现
摘要 随着科学技术的飞速发展,社会的方方面面、各行各业都在努力与现代的先进技术接轨,通过科技手段来提高自身的优势,铁路物流数据平台当然也不能排除在外,从文档信息、铁路设计的统计和分析,在过程中会产生大量的、各…...

比较杂的html元素
abbr 表示缩写 time 踢动给浏览器或搜索引擎阅读的事件;看着没什么效果 b 以前是一个无语义元素,主要用于加粗字体,有了css之后,加粗就不需要b元素了。 现在作为提醒注意(Bring Attention To)元素&…...

Docker基本管理
前言一、Docker简介1.1 什么是docker1.2 docker的logo及其含义1.3 docker的设计宗旨1.4 容器的优点1.5 容器和虚拟机的区别1.6 docker容器的两个重要技术1.7 docker的核心概念 二、安装 Docker三、Docker 镜像操作1、搜索镜像2、获取镜像3、查看镜像信息4、查看下载的镜像文件信…...
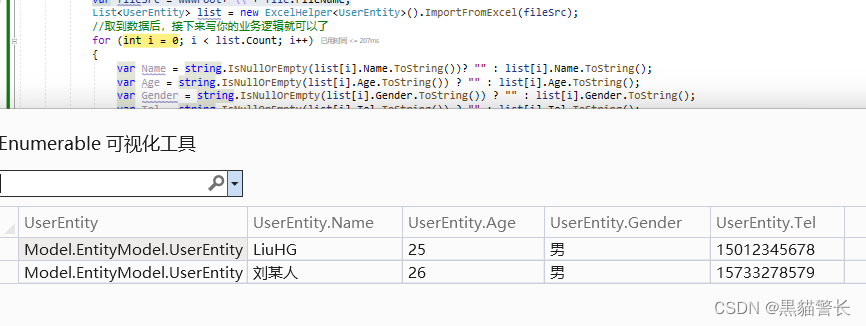
.NET Core6.0使用NPOI导入导出Excel
一、使用NPOI导出Excel //引入NPOI包 HTML <input type"button" class"layui-btn layui-btn-blue2 layui-btn-sm" id"ExportExcel" onclick"ExportExcel()" value"导出" />JS //导出Excelfunction ExportExcel() {…...
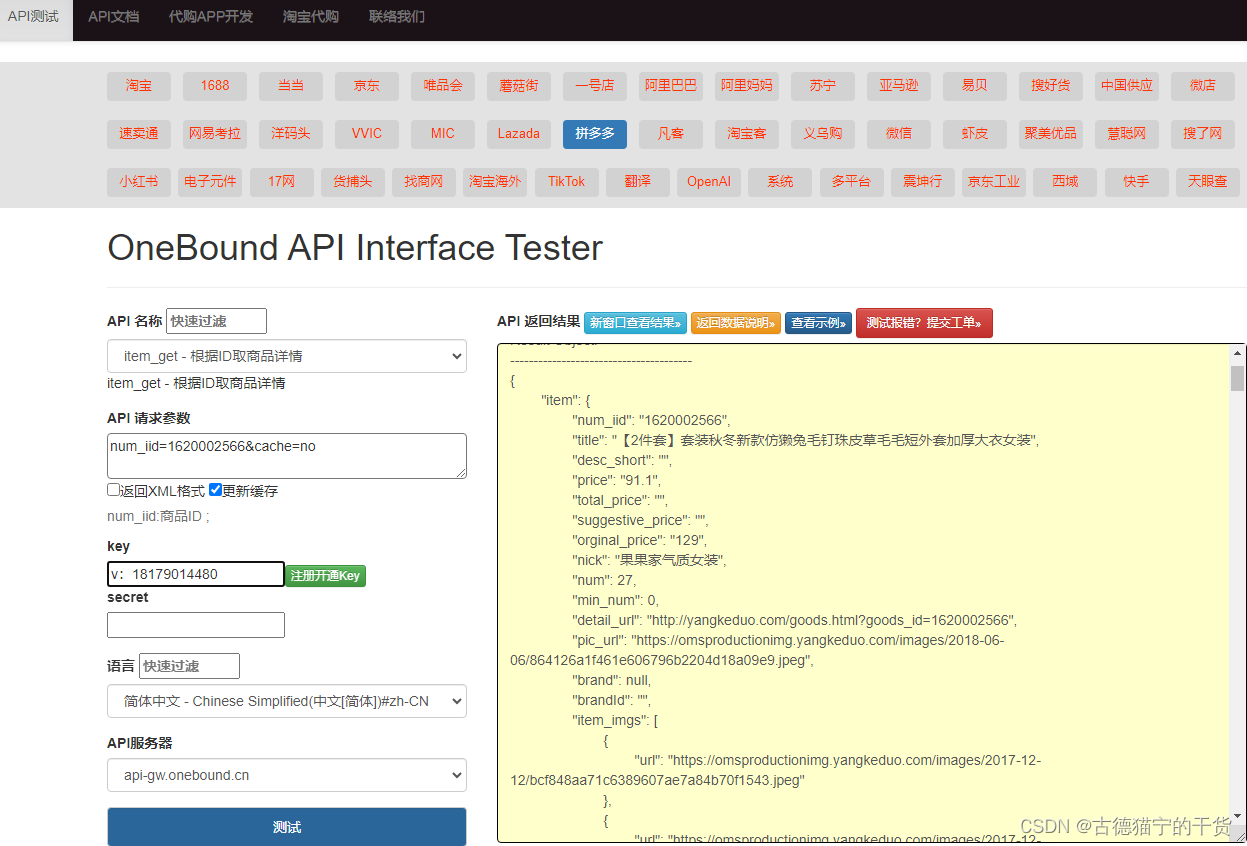
用API接口获取数据的好处有哪些,电商小白看过来!
API接口获取数据有以下几个好处: 1. 数据的实时性:通过API接口获取数据可以实时获取最新的数据,保证数据的及时性。这对于需要及时更新数据的应用非常重要,比如股票行情、天气预报等。 2. 数据的准确性:通过API接口获…...
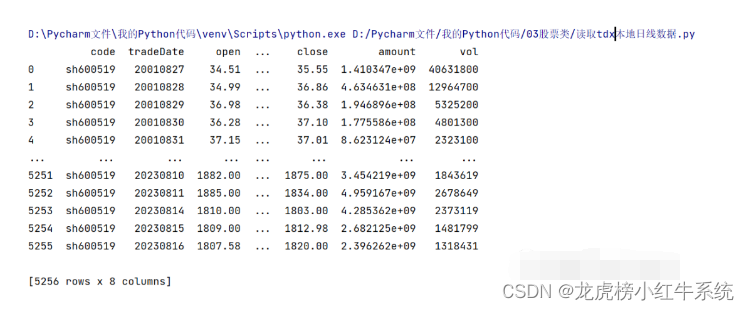
使用struct解析通达信本地Lday日线数据
★★★★★博文原创不易,我的博文不需要打赏,也不需要知识付费,可以白嫖学习编程小技巧,喜欢的老铁可以多多帮忙点赞,小红牛在此表示感谢。★★★★★ 在Python中,struct模块提供了二进制数据的打包和解包…...

浅谈早期基于模板匹配的OCR的原理
基于模板匹配的概念是一种早期的字符识别方法,它基于事先准备好的字符模板库来与待识别字符进行比较和匹配。其原理如下: 1. 字符模板库准备:首先,针对每个可能出现的字符,制作一个对应的字符模板。这些模板可以手工创…...

第6章 分布式文件存储
mini商城第6章 分布式文件存储 一、课题 分布式文件存储 二、回顾 1、理解Oauth2.0的功能作模式 2、实现mini商城项目的权限登录 三、目标 1、了解文件存储系统的概念 2、了解常用文件服务器的区别 3、掌握Minio的应用 四、内容 第1章 MinIO简介 官...
Spring(四):Spring Boot 的创建和使用
关于Spring之前说到,Spring只是思想(核心是IOC、DI和AOP),而具体的如何实现呢?那就是由Spring Boot 来实现,Spring Boot究竟是个啥呢? 什么是Spring Boot,为什么要学Spring Boot Sp…...
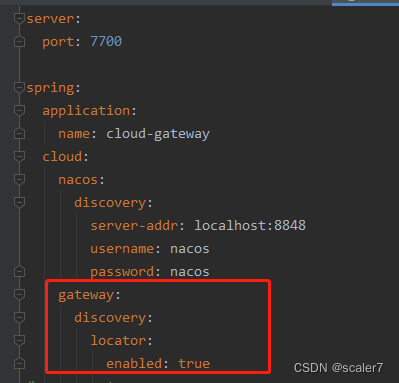
SpringCloud Gateway:status: 503 error: Service Unavailable
使用SpringCloud Gateway路由请求时,出现如下错误 yml配置如下: 可能的一种原因是:yml配置了gateway.discovery.locator.enabledtrue,此时gateway会使用负载均衡模式路由请求,但是SpringCloud Alibaba删除了Ribbon的…...
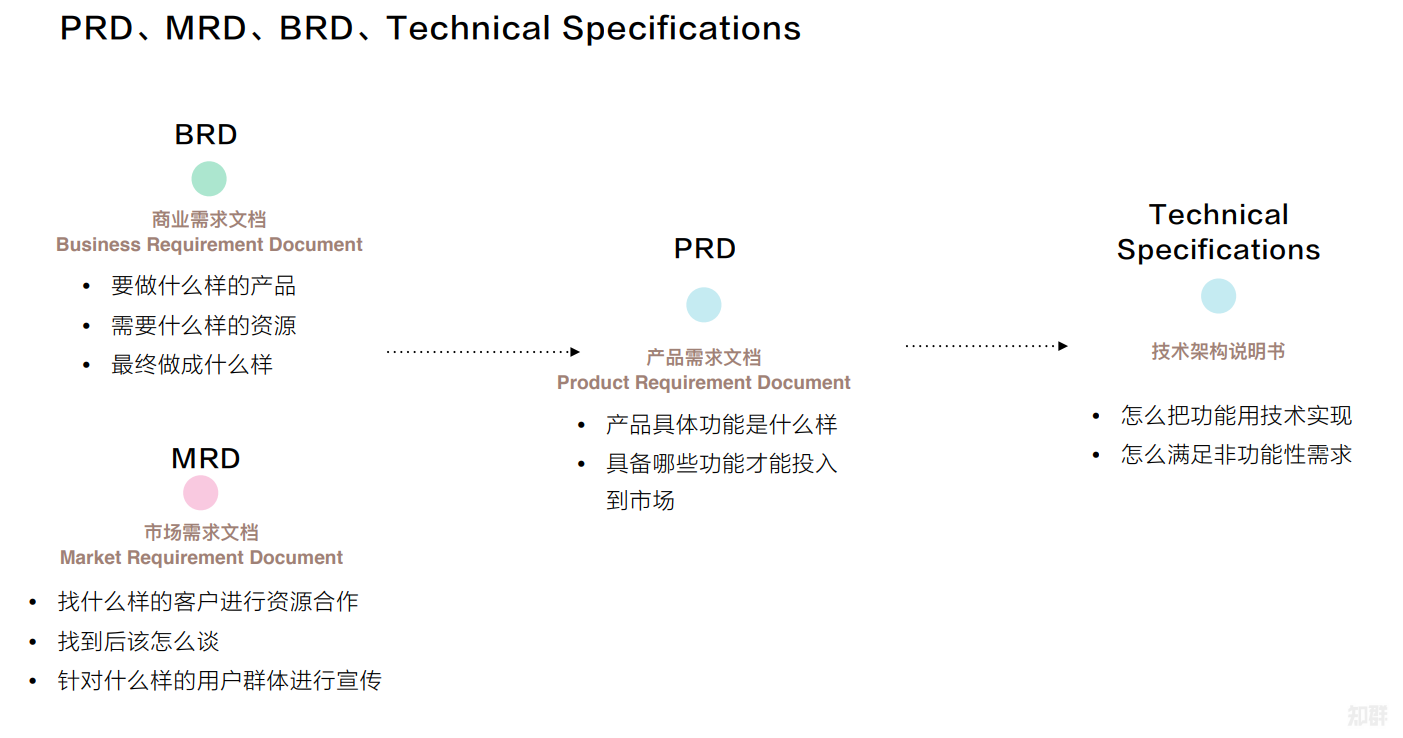
【产品规划】功能需求说明书概述
文章目录 1、瀑布流方法论简介2、产品需求文档(PRD)简介3、产品需求文档的基本要素4、编写产品需求文档5、优秀产品需求文档的特点6、与产品需求文档相似的其他文档 1、瀑布流方法论简介 2、产品需求文档(PRD)简介 3、产品需求文档…...
shell连接ubuntu
当使用aws的私钥连接时,老是弹出输入私钥密码,但是根本没有设置过密码,随便输入后,又提示该私钥无密码... 很早就使用过aws的ubuntu,这个问题也很早就遇到过,但是每次遇到都要各种找找找...索性这次记下来算了 此处用FinalShell连接为例 首先现在Putty连接工具: 点击官方下载 …...

如何用DownKyi实现B站视频自由:5个实用场景与解决方案
如何用DownKyi实现B站视频自由:5个实用场景与解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#…...

Lumberjack 暗色主题:提升开发效率的配色方案与多平台配置指南
1. 项目概述:一个为开发者打造的暗色系主题 如果你和我一样,每天有超过一半的时间都泡在代码编辑器里,那么一个顺眼的主题就不仅仅是“好看”而已,它直接关系到你的工作效率和眼睛的舒适度。今天要聊的这个项目, Drru…...

MCP图像生成服务器:在IDE中无缝集成AI绘图,提升开发与设计效率
1. 项目概述:一个能“听懂人话”的智能图像生成服务器 如果你和我一样,经常在 Cursor、Claude Code 这类 AI 编程工具里写代码、做设计,那你肯定遇到过这样的场景:脑子里有个很棒的视觉创意,比如“一个赛博朋克风格的…...

高性能零依赖Vue3跑马灯组件:企业级动态内容展示解决方案
高性能零依赖Vue3跑马灯组件:企业级动态内容展示解决方案 【免费下载链接】vue3-marquee A simple marquee component with ZERO dependencies for Vue 3. 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-marquee Vue3-Marquee是一个专为Vue 3设计的零依…...

2026最权威的五大降AI率网站横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于当下学术研究的语境里,AI论文工具有着强大功能,可全面涵盖文献梳理…...

别再死记硬背了!用PyTorch和TensorFlow动手实现池化层,5分钟搞懂Max Pooling和Average Pooling的区别
用PyTorch和TensorFlow实战池化层:5分钟可视化Max与Average Pooling差异 刚接触深度学习的开发者常被各种理论概念困扰,尤其是池化层这类看似简单却暗藏玄机的操作。与其死记硬背定义,不如打开Jupyter Notebook,用PyTorch和Tensor…...

FPGA加速的医疗影像深度学习分类系统实现14.5μs超低延迟
1. 项目背景与核心挑战在医疗影像分析领域,淋巴细胞亚群(如T4、T8和B细胞)的快速准确分类对疾病诊断和治疗监测至关重要。传统方法依赖荧光标记和人工镜检,存在操作复杂、成本高昂且主观性强的问题。我们团队开发的基于明场显微镜…...

工程师如何从错误中学习:测试测量实战与思维跃迁
1. 项目概述:为什么“错误”是工程师的必修课在测试测量这个行当里摸爬滚打了十几年,我经手过的示波器、信号源、数据采集卡不计其数,也带过不少刚入行的新人。我发现一个挺有意思的现象:学校里成绩拔尖、理论扎实的学生ÿ…...

5大实战技巧:深度掌握PyQt6桌面应用开发
5大实战技巧:深度掌握PyQt6桌面应用开发 【免费下载链接】PyQt-Chinese-tutorial PyQt6中文教程 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Chinese-tutorial 在Python生态中,PyQt6作为最强大的GUI开发框架,为开发者提供了创…...

边缘计算安全:保护边缘环境的安全
边缘计算安全:保护边缘环境的安全 一、边缘计算安全概述 1.1 边缘计算安全的定义 边缘计算安全是指保护边缘计算环境中的数据、设备和应用的安全。它包括边缘节点的安全、网络安全、数据安全和应用安全等方面。 1.2 边缘计算安全的价值 数据保护:保护边缘…...