Mysql的索引详解
零. 索引类型概述
1. 实际开发中使用的索引种类
- 主键索引
- 唯一索引
- 普通索引
- 联合索引
- 全文索引
- 空间索引
2. 索引的格式类型
- BTree类型
- Hash类型
- FullText类型(全文索引)
- RTree类型(空间索引)
MySQL的索引方法,主要包括BTREE和HASH。
顾名思义,BTREE方法,就是通过构建B+树的方法来组织索引结构;而HASH方法,就是通过构建哈希表的方法来组织索引结构。
3. 以索引数据存储方式划分
- 聚集索引
- 非聚集索引
4. 以技巧划分
- 覆盖索引
- 前缀索引
也有人把聚集索引叫做聚簇索引
一、索引介绍
索引是一种数据结构,索引的作用主要是为了提高检索效率,添加一个索引需要选择一个字段作为索引依据
索引数据格式主要有两种
- Hash
- B+Tree
在实际开发中,其实用的最多的是B+Tree数据类型,因为hash数据格式是不支持范围查询的,而基于二叉树数据结构的B+Tree可以支持范围查询(注:B+Tree是B树的进化版)
拓展
(1)Mysql索引为什么使用B+Tree数据结构?
从计算机原理出发,是因为索引本身消耗就很大,不可能全部储存到内存中,因此索引往往索引文件的形式存储在磁盘上,那这样话,磁盘IO效率就会起决定性的作用。
(2)全文索引和空间索引是什么?
二、索引类型
1、普通索引
普通索引是最基本的索引,也是最常用的索引,创建只是为了提高查询效率,值可以为空,没有任何限制
alter table 表名 add index 索引名(添加索引的字段)
2、唯一索引
唯一索引和普通索引类似,值也可以为空,唯一区别是添加的字段是唯一性,列值不允许重复
alter table 表名 add unique 索引名(添加索引的字段)
3、主键索引
主键索引是一种特殊的唯一索引, 值不允许为空 和 列值不允许重复,且一张表只允许有一个主键索引
alter table 表名 add primary key (添加索引的字段)
4、联合索引
联合索引,顾名思义,就是多个索引联合在一起组成的一种索引类型。
//索引名可以是index_xx_xx
alter table 表名 add index 索引名(索引1,索引2,索引3)
5. 关于联合索引的拓展
(1)最左前缀匹配原则
建立联合索引时会遵循最左匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
例如🌰
在user表中为 name、address、phone 三个字段添加联合索引
ALTER TABLE user ADD INDEX index_three(name,address,phoen)
下面三条sql语句都能命中索引
SELCET * FROM user WHERE address =’ 北京’ AND phone = ‘12345’ AND name = ‘张三’;SELCET * FROM user WHERE name = ‘张三’ AND address = ‘北京’;SELCET * FROM user WHERE name = ‘张三’;
这三条sql语句都会匹配联合索引,按顺序是 (name,address,phone) 、(name,address) 、(name),其实使用联合索引时可以不用按照建索引时候的顺序,如使用and条件,因为执行sql语句时,MYSQL的优化器会自动帮我们调整where条件中的顺序,但是,使用联合索引必须使用建索引的第一个字段name,即最左边的字段,否则索引无效,如下:
SELCET * FROM user WHERE address = ‘北京’;SELCET * FROM user WHERE address = ‘北京’’ AND phone = ‘12345’ ;以上联合索引都会失效,可以总结一句话:用到最左边的字段,就算成功
(2)联合主键索引
上面说到了主键索引,其实主键也可以由多个字段组成
🌰借丁奇大佬的例子
DBA 小吕在入职新公司的时候,就发现自己接手维护的库里面,有这么一个表,表结构定义类似这样的:
CREATE TABLE `user` ('a' int(11) NOT NULL,'b' int(11) NOT NULL,'c' int(11) NOT NULL,'d' int(11) NOT NULL,PRIMARY KEY ('a','b'),KEY 'c' ('c'),KEY 'ca' ('c','a'),KEY 'cb' ('c','b')
) ENGINE=InnoDB;
公司的同事告诉他说,由于历史原因,这个表需要 a、b 做联合主键,这个小吕理解了。但是,学过本章内容的小吕又纳闷了,既然主键包含了 a、b 这两个字段,那意味着单独在字段 c 上创建一个索引,就已经包含了三个字段了呀,为什么要创建“ca”、“cb”这两个索引?同事告诉他,是因为他们的业务里面有这样的两种语句:
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1;
对于一般不太了解索引数据结构的人来说,会觉得上面的建的索引是没有问题的,但实际上面有一个错误,索引 “ca” 是多余的。
这是为什么?查询 where c = N order by a 难道不需要 “ca” 索引吗?
答案是需要的,不过需要明白的是,索引C是普通索引,C索引树上存放的是联合主键 (ab)的值,所以C索引树叶节点存放的值是(cab),根据最左前缀原则,就没必要再建(ca)索引了。但是(cb)索引还是需要的,在cb索引中,实际上是(cba)。
使用到了最左前缀原则和聚集索引相关的知识点
三、聚集索引和非聚集索引
1、非聚集索引
索引和表数据分开存储,就是非聚集索引(也有叫二级索引或辅助索引)。
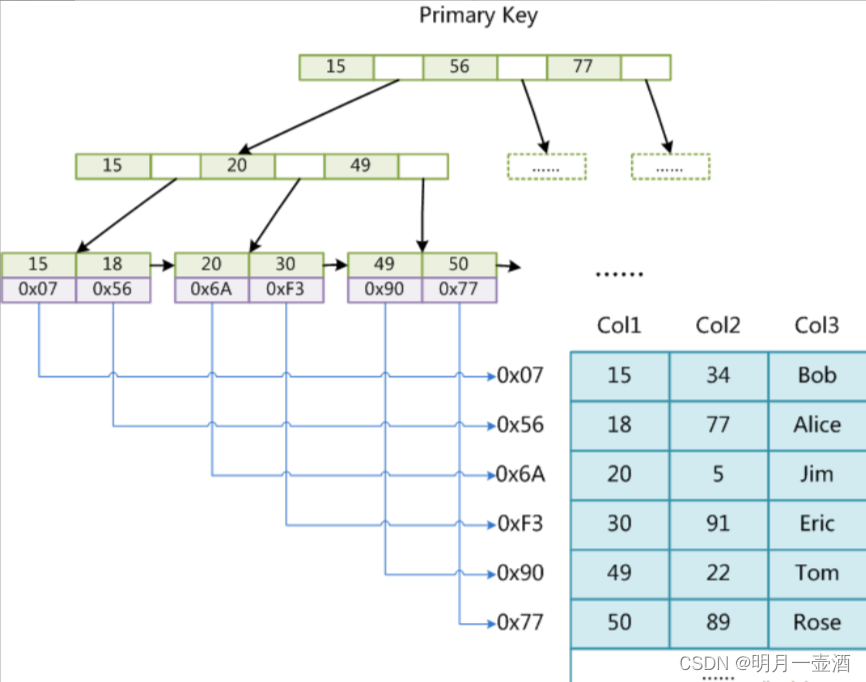
非聚集索引一般就是指MyIsam引擎的索引,因为MyIsam引擎的索引和数据是分开储存的,如下图显示,MyIsam的索引B+Tree下data域储存的是数据地址,每次查询索引时,都是先从索引树上获取数据地址,在通过地址获取对应的数据 。所以,MyIsam表会有三个文件,分别是索引文件、表结构文件、数据文件。
2、聚集索引
索引和表数据存储在一起,就是聚集索引。
以InnoDB引擎举例,InnoDB引擎的主键是和表数据存储在一起,每个树节点储存每行一行的数据。如果有看过InnoDB引擎的表文件,就会发现,其实InnoDB表数据文件就是主索引文件,如下图的Innodb表数据二叉树显示,B+Tree数结构的主键索引,每个树节点主键下的data域,都是存放对应该主键的行数据。所以,InnoBD表数据文件本身就是一个B+树文件。InnoBD表一共有两个文件,分别是索引文件、表结构文件。
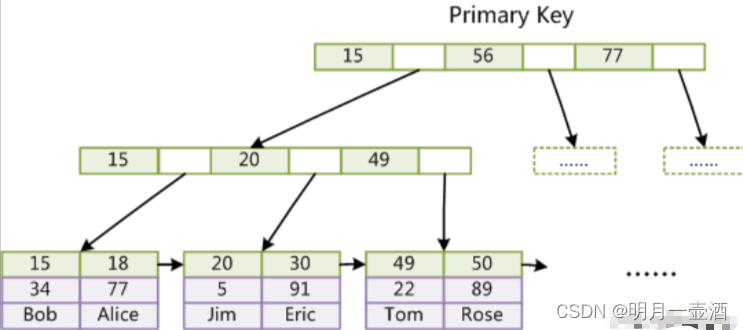
需要注意,InnoDB引擎除了主键索引,其他的索引的data域都是存主键索引的值,使用辅助查询时,是先通过辅助索引获取到主键,在通过主键获取主键索引B+树里的data域里的数据。总结:Innodb引擎表主键索引树叶节点存储:每行的数据;辅助索引树叶节点存的是:字段值和主键值。
3、实际开发聚集索引的不同
🌰先建个Innodb引擎的user表,表中有两个索引,一个是主键索引(聚集索引)ID,和另一个普通索引(非聚集索引)index_cardId 身份证ID
CREATE TABLE `user` ( `ID` INT NOT NULL AUTO_INCREMENT, `cardId` VARCHAR(50) NOT NULL, `name` VARCHAR(20) NOT NULL,`age` VARCHAR(10) NOT NULL,PRIMARY KEY (`ID`),KEY 'index_cardId' ('cardId') USING BTREE
)engine=InnoDB;
假如有一条语句:
SELECT * FROM user WHERE ID = 100;
即用主键的查询方式,搜索了ID这个索引的B+树,只需直接从这颗B+树中找到对应的ID获取到对应行的数据就可以。
如果用 index_cardId 普通索引查询:
SELECT * FROM user WHERE cardId = ‘43212341234’;
则需要搜索可 index_cardId 这个索引树,从index_cardId 这颗索引树上获取到主键索引的值,在通过值从主键索引的B+树上获取对应的数据,也就是说,非主键索引的查询需要多扫描了一棵索引树,这个过程我们称为回表
所以,在实际开发中,我们应尽量使用主键查询
四、覆盖索引
首先要明白,索引的使用过程,假如查询一条sql语句:
select col1 from test where col1=1;假如test表有1000W条数据,在col1字段建了一个普通索引,然后sql查询时,会通过col1索引筛选出符合条件的200W条数据,而且能在col1索引上获取col1字段的数据,无需回表查询,直接返回,这就是覆盖索引。
反之,如果在上面的sql语句查询的字段在加一个col2字段
select col1,col2 from test where col1=1;即使col1索引获取col1字段的值,但是因为没有col2字段的值,所以还需要回表查询,再获取200W条数据字段col2的值,才返回。那这样就不是覆盖索引了。
实际开发中覆盖索引的价值
实际开发中,优化查询的时候是否回表,是优化的重要目标,所以使用索引的时候,应该尽量使sql语句可以从索引中获取到需要的数据,例如上面的例子,可以增加col2字段的索引,这样就可以避免回表查询。
但是,如果查询的字段很多,难道就建很多的索引吗?
要知道,索引也是有开销的,首先,索引是以空间换取时间的,如果索引建的越多,占用的磁盘空间就越多,其次,每次对数据库进行写操作,索引也会进行相应的更新,也会影响数据库写操作的效率,总的来说,浪费了很多服务器的资源,所以索引需要合理的使用,以上的例子为例,我们可以建(co1,col2)的联合索引,这样查询的时候就可以通过(col1,col2)联合直接获取col1和col2字段的数据,直接返回。
覆盖索引是优化索引的重要方式之一
课外拓展-前缀索引
🌰举个例子,先建个表
CREATE TABLE `user` ( `ID` INT NOT NULL AUTO_INCREMENT, `Name` VARCHAR(50) NOT NULL, `City` VARCHAR(50) NOT NULL, `Age` INT NOT NULL, PRIMARY KEY (`ID`)
);
为了加快查询速度,我们给这个表加一个联合索引
ALTER TABLE user ADD INDEX 'name_city_name' (Name(10),City,Age)仔细看就会发现在Name字段加了10长度限制,这就是前缀索引。Name字段长度是50,为什么用10呢?因为一般情况下名字长度不会超过10,这样不仅加快索引查询速度,还会减少索引文件的大小提高更新数据的效率。
五、索引使用建议
-
对较小的数据列使用索引
上面有提到过,索引文件会存储数据,所以选择数据量少的字段使用索引可以节省不必要的磁盘空间和内存的消耗 -
对 where、on、group by、order by 使用索引
-
对较长的字符串使用前缀索引
-
不要创建过多索引
-
多使用联合索引
在阿里云开发手册里,有一条要求是建表索引第一优先是使用联合索引。主要有一下原因:(1)减少开销
例如,建立一个联合索引(col1,col2,col3),实际相当于建(col1),(col2),(col3)三个索引。索引并不建的越多越好,每次对数据库进行写操作的时候,都需要对索引进行更新,所以建一个合理联合索引,可以节省数据库写和磁盘空间的开销。(2)覆盖索引
建了一个联合索引(col1,col2,col3),假如查询sql:select col1,col2,col3 from test where col1=1 and col2=2 ,那么数据库可以通过索引直接获取到数据,无需回表查询,减少了io操作。所以在实际开中,多使用联合索引以达到覆盖索引的效果,是很有效的优化手段之一。(3)增加查询效率
索引的利用效率更高,假如数据表有1000W条数据,有一条sql查询语句:select * from test where col1=1 and col2=2 and col3=3 ,假设可以通过每个索引查询条件筛选10%的数据第一种,如果只有一个普通索引col1,只能通过索引筛选出1000W * 10%=100W 条数据,然后在回表查找符合 col2 = 2 和 col3 =3 的数据,这样结果是回表扫描100W条数据。
第二种,如果是一个联合索引 (col1,col2,col3),能通过索引筛选出 1000W*10%*10%*10% = 1W 条数据,然后在回表查找表其他字段数据,效率的差别可想而知。
六、索引使用的要避免的坑
- 隐式转换问题(索引字段类型使用不准确,mysql会自动转换字段类型,从而导致索引失效)
- 对索引进行计算 (例如 age + 10 = 30 )
- 对索引使用函数运算 ( 例如 LEFT(
date,4) ) - 正则表达式不使用索引(例如模糊查询%xx ,注意, xx% 是走索引的)
- or条件必须全部字段建立索引(少使用 or 条件)
七、索引的弊端
不要盲目的创建索引,只为查询操作频繁的列创建索引,创建索引会使查询操作变得更加快速,但是会降低增加、删除、更新操作的速度,因为执行这些操作的同时会对索引文件进行重新排序或更新。但是,在互联网应用中,查询的语句远远大于DML的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引。
相关文章:
Mysql的索引详解
零. 索引类型概述 1. 实际开发中使用的索引种类 主键索引唯一索引普通索引联合索引全文索引空间索引 2. 索引的格式类型 BTree类型Hash类型FullText类型(全文索引)RTree类型(空间索引) MySQL 的索引方法,主要包括 BTREE 和 HASH。 顾名思…...

.netcore windows app启动webserver
创建controller: using Microsoft.AspNetCore.Mvc; using Microsoft.Extensions.Logging; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Text.Json.Serialization; using System.Threading.Tasks;namespace MyWorker.…...
泰迪大数据挖掘建模平台功能特色介绍
大数据挖掘建模平台面相高校、企业级别用户快速进行数据处理的建模工具。 大数据挖掘建模平台介绍 平台底层算法基于R语言、Python、Spark等引擎,使用JAVA语言开发,采用 B/S 结构,用户无需下载客户端,可直接通过浏览器进行…...

【问题】java序列化,什么时候使用
文章目录 是什么为什么如何做流操作 注事事项 是什么 把对象转换为字节序列的过程称为对象的序列化。 把字节序列恢复为对象的过程称为对象的反序列化。 对象的序列化主要有两种用途: 1)把对象的字节序列永久地保存到硬盘上,通常存放在一…...
【最新可用】VMware中ubuntu与主机window之间使用共享文件夹传输大文件
一、VMware设置共享文件夹 (1)虚拟机关机情况下,创建一个共享文件夹 (2)ubuntu中挂载共享文件夹 1、如果之前已经挂载 hgfs,先取消挂载 sudo umount /mnt/hgfs2、重新使用以下命令挂载 sudo /usr/bin/vmh…...
A. Two Semiknights Meet
题目描述 可知走法为中国象棋中的象的走法 解题思路 利用结构体来存储两个 K K K的位置 x , y x,y x,y,因为两个 K K K同时走,所以会出现两种情况 相向而行,两者距离减少 相反而行,两者距离不变 我们完全可以不考虑格子是好…...

〔011〕Stable Diffusion 之 解决绘制多人或面部很小的人物时面部崩坏问题 篇
✨ 目录 🎈 脸部崩坏🎈 下载脸部修复插件🎈 启用脸部修复插件🎈 插件生成效果🎈 插件功能详解🎈 脸部崩坏 相信很多人在画图时候,特别是画 有多个人物 图片或者 人物在图片中很小 的时候,都会很容易出现面部崩坏的问题这是由于神经网络无法完全捕捉人脸的微妙细节…...

在ubuntu+cpolar+rabbitMQ环境下,实现mq服务端远程访问
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...

Vue elementui 实现表格selection的默认勾选,翻页记录勾选状态
需求:当弹出一个列表页数据,对其进行筛选选择。 列表更新,填充已选数据 主要使用toggleRowSelection 代码如下: <el-table v-loading"loading" :data"drugList" selection-change"handleSelection…...

CloudCompare——统计滤波
目录 1.统计滤波2.软件实现3.完整操作4.算法源码5.相关代码 本文由CSDN点云侠原创,CloudCompare——统计滤波,爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 1.统计滤波 算法原理见:PCL 统计滤波器…...
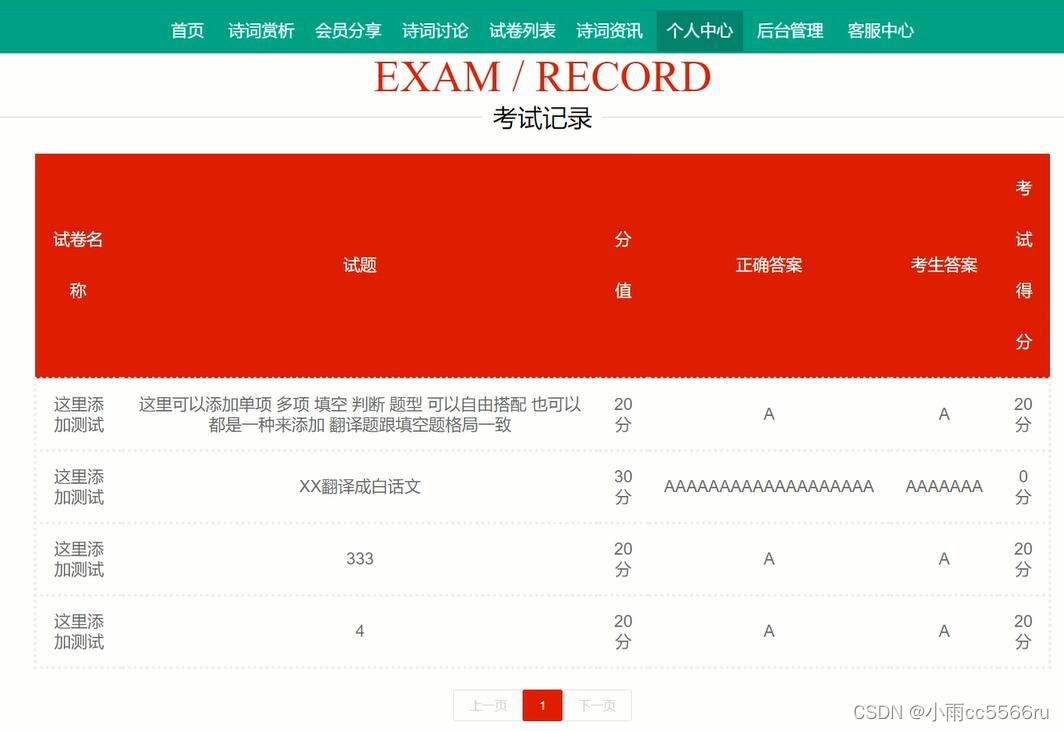
nodejs+vue古诗词在线测试管理系统
一开始,本文就对系统内谈到的基本知识,从整体上进行了描述,并在此基础上进行了系统分析。为了能够使本系统较好、较为完善的被设计实现出来,就必须先进行分析调查。基于之前相关的基础,在功能上,对新系统进…...

174-地下城游戏
题目 恶魔们抓住了公主并将她关在了地下城 dungeon 的 右下角 。地下城是由 m x n 个房间组成的二维网格。我们英勇的骑士最初被安置在 左上角 的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。 骑士的初始健康点数为一个正整数。如果他的健康点数在某一时刻…...

Linux定时任务crontab
常用命令 crontab -e 进入定时脚本,编辑后保存即立即生效 crontab -l 查看用户定时脚本 tail -f /var/log/cron 查看执行日志 service crond status 查看定时器运行状态 service crond restart 重启定时器 定时任务不执行原因 定时任务设置的格式正确,手…...

golang字符串切片去重
函数的功能是从输入的字符串切片中去除重复的元素,并返回去重后的结果。具体的实现逻辑如下: 创建一个空的结果切片result,用于存储去重后的字符串。创建一个临时的maptempMap,用于存放不重复的字符串。map的键是字符串࿰…...

git如何检查和修改忽略文件和忽略规则
查询忽略规则 使用命令行:git status --ignored,进行查询, 例: $ git status --ignored On branch develop Your branch is up to date with origin/develop.Ignored files:(use "git add -f <file>..." to inc…...

Android AppCompatActivity标题栏操作
使用 AndroidStudio 新建的工程默认用 AppCompatActivity ,是带标题栏的。 记录下 修改标题栏名称 和 隐藏标题栏 的方法。 修改标题栏名称 Override protected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R…...

解决conda activate报错
解决方法 source ~/anaconda3/bin/activate或 source ~/miniconda3/bin/activate然后就可以使用 conda activate xxx环境了 问题解析 请参考github:https://github.com/conda/conda/issues/7980...
)
FreeMarker--表达式和运算符的用法(全面/有示例)
原文网址:FreeMarker--表达式和运算符的用法(全面/有示例)_IT利刃出鞘的博客-CSDN博客 简介 本文介绍FreeMarker的表达式和运算符的用法。 表达式是FreeMarker的核心功能。表达式放置在插值语法(${...})之中时,表明需要输出表达…...
)
设计模式 -- 策略模式(传统面向对象与JavaScript 的对比实现)
设计模式 – 策略模式(传统面向对象与JavaScript 的对比实现) 文章目录 设计模式 -- 策略模式(传统面向对象与JavaScript 的对比实现)使用策略模式计算年终奖初级实现缺点 使用组合函数重构代码缺点 使用策略模式重构代码传统的面…...

非常详细的 Ceph 介绍、原理、架构
1. Ceph架构简介及使用场景介绍 1.1 Ceph简介 Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。 Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...
)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码)
别再只会addItem了!QT QComboBox的5个高级用法与实战场景(含完整代码) 在QT开发中,QComboBox可能是最容易被低估的控件之一。很多开发者仅仅把它当作一个简单的下拉选择框,用addItem()填充几个静态选项就草草了事。但实…...

win10打印机不能共享报0x0000011b/0x00000709修复工具合集分享 ,亲测解决Windows打印机共享报错问题
先说说我的情况。公司大概十几个人,两台共享打印机,一台接在Win10的台式机上,一台接在Win11的笔记本上。本来用着一直正常,去年开始,陆陆续续有同事反映连不上打印机。 最常见的报错就是0x00000709,还有0x…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

国家级数据仓库构建:从爬取到应用的全流程实践指南
1. 项目概述与核心价值最近在整理一个数据项目时,我偶然发现了一个名为“national_data”的仓库,作者是Ddhjx。这个项目名听起来平平无奇,但点进去之后,我发现它远不止是一个简单的数据集合。它本质上是一个结构化的、持续更新的国…...

软银携手DeltaX建储能基地,2027年量产应对AI算力电力挑战
软银与DeltaX合作:储能系统建设的新布局品玩5月12日消息,据The Elec报道,软银集团选定韩国初创公司DeltaX,负责在日本大阪建设数据中心储能系统(ESS)的开发与制造。双方计划于今年下半年在大阪堺市原夏普工…...

别再傻傻分不清了!舵机、步进、无刷、永磁同步,这四种电机到底怎么选?
机器人开发者必读:四大电机选型实战指南 当你在深夜调试机器人关节时,是否曾被电机的异常啸叫声惊醒?三年前我参与四足机器人项目时,就因选错电机类型导致整机功耗超标。本文将用真实项目经验,帮你避开电机选型的那些坑…...

3分钟快速上手:91160-cli医疗预约自动化助手完整指南
3分钟快速上手:91160-cli医疗预约自动化助手完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预约设计…...

5个Zutilo技巧让你成为Zotero文献管理高手
5个Zutilo技巧让你成为Zotero文献管理高手 【免费下载链接】Zutilo Zotero plugin providing some additional editing features 项目地址: https://gitcode.com/gh_mirrors/zu/Zutilo 还在为Zotero的批量操作烦恼吗?每天面对成百上千的文献条目,…...

AI智能体构建实战:从架构设计到工程落地的关键挑战与解决方案
1. 项目概述:揭开AI智能体构建的隐秘面纱 “构建AI智能体”,这听起来像是当下最酷、最前沿的技术话题。无论是科技新闻还是行业论坛,你都能看到无数关于智能体如何自动化工作流、理解复杂指令、甚至自主决策的激动人心的讨论。然而࿰…...