opencv 进阶10-人脸识别原理说明及示例-cv2.CascadeClassifier.detectMultiScale()
人脸识别是指程序对输入的人脸图像进行判断,并识别出其对应的人的过程。人脸识别程 序像我们人类一样,“看到”一张人脸后就能够分辨出这个人是家人、朋友还是明星。
当然,要实现人脸识别,首先要判断当前图像内是否出现了人脸,也即人脸检测。只有检 测到图像中出现了人脸,才能根据人脸判断这个人到底是谁。
人脸检测
当我们预测的是离散值时,进行的是“分类”。例如,预测一个孩子能否成为一名优秀的运动员,其实就是看他是被划分为“好苗子”还是“普通孩子”的分类。对于只涉及两个类别的“二分类”任务,我们通常将其中一个类称为“正类”(正样本),另一个类称为“负类”(反类、负样本)。
例如,在人脸检测中,主要任务是构造能够区分包含人脸实例和不包含人脸实例的分类器。这些实例被称为“正类”(包含人脸图像)和“负类”(不包含人脸图像)。
本节介绍分类器的基本构造方法,以及如何调用OpenCV中训练好的分类器实现人脸检测。
基本原理
OpenCV 提供了三种不同的训练好的级联分类器,下面简单介绍其中涉及的一些概念。
- 级联分类器
通常情况下,分类器需要对多个图像特征进行识别。例如,识别一个动物到底是狗(正类)还是其他动物(负类),我们可能需要根据多个条件进行判断,这样比较下来是非常烦琐的。
但是,如果首先就比较它们有几条腿:
- 有“四条腿”的动物被判断为“可能为狗”,并对此范围内的对象继续进行分析和判断。
- 没有“四条腿”的动物直接被否决,即不可能为狗。
这样,仅仅比较腿的数目,根据这个特征就能排除样本集中大量的负类(例如鸡、鸭、鹅等不是狗的其他动物实例)。级联分类器就是基于这种思路,将多个简单的分类器按照一定的顺序级联而成的。
级联分类器的基本原理如图 23-1 所示。
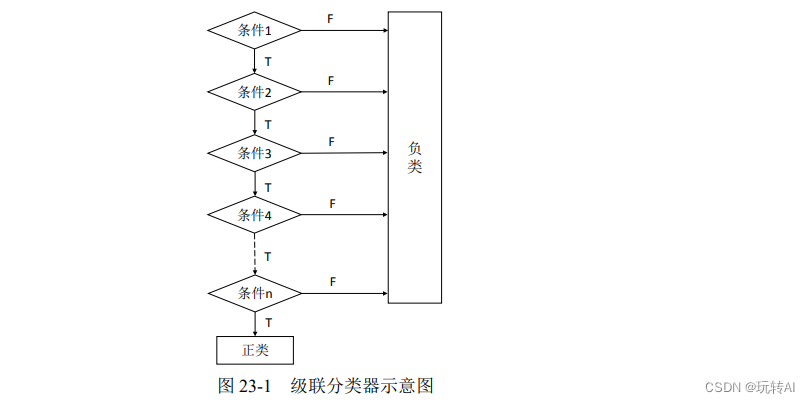
级联分类器的优势是,在开始阶段仅进行非常简单的判断,就能够排除明显不符合要求的实例。在开始阶段被排除的负类,不再参与后续分类,这样能极大地提高后面分类的速度。这有点像我们经常收到的骗子短信,大多数人通常一眼就能识别出这些短信是骗人的,也不可能上当受骗。骗子们随机大量发送大多数人明显不会上当受骗的短信,这种做法虽然看起来非常蠢,但总还是会有人上当。这些短信,在最开始的阶段经过简单的筛选过滤就能够将完全不可能上当的人排除在外。不回复短信的人,是不可能上当的;而回复短信的人,才是目标人群。
这样,骗子轻易地就识别并找到了目标人群,能够更专注地“服务”于他们的“最终目标人群”(不断地进行短信互动),从而有效地避免了与“非目标人群”(不回复短信的人群)发生进一
步的接触而“浪费”时间和精力。
OpenCV 提供了用于训练级联分类器的工具,也提供了训练好的用于人脸定位的级联分类器,都可以作为现成的资源使用。
- Haar级联分类器
OpenCV 提供了已经训练好的 Haar 级联分类器用于人脸定位。Haar 级联分类器的实现,经过了以下漫长的历史:
-
首先,有学者提出了使用 Haar 特征用于人脸检测,但是此时 Haar 特征的运算量超级大,这个方案并不实用。
-
接下来,有学者提出了简化 Haar 特征的方法,让使用 Haar 特征检测人脸的运算变得简单易行,同时提出了使用级联分类器提高分类效率。
-
后来,又有学者提出用于改进 Haar 的类 Haar 方案,为人脸定义了更多特征,进一步提高了人脸检测的效率。
下面用一个简单的例子来叙述上述方案。假设有两幅 4×4 大小的图像,如图 23-2 所示。
针对这两幅图像,我们可以通过简单的计算来判断它们在左右关系这个维度是否具有相关性。
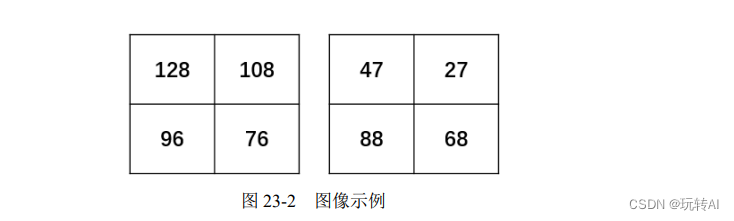
’用两幅图像左侧像素值之和减去右侧像素值之和:
- 针对左图,sum(左侧像素) - sum(右侧像素) = (128+96) - (108+76) = 40
- 针对右图,sum(左侧像素) - sum(右侧像素) = (47+88) - (27+68) = 40
这两幅图像中,“左侧像素值之和”减去“右侧像素值之和”都是 40。所以,可以认为在“左侧像素值之和”减去“右侧像素值之和”这个角度,这两幅图像具有一定的相关性。
进一步扩展,我们可以从更多的角度考虑图像的特征。学者 Papageorgiou 等人提出了如图23-3 所示的 Haar 特征,这些特征包含垂直特征、水平特征和对角特征。他们利用这些特征分
别实现了行人检测(Pedestrian Detection Using Wavelet Templates)和人脸检测(A GeneralFramework For Object Detection)。

Haar 特征反映的是图像的灰度变化,它将像素划分为模块后求差值。Haar 特征用黑白两种矩形框组合成特征模板,在特征模板内,用白色矩形像素块的像素和减去黑色矩形像素块的像素和来表示该模板的特征。
经过上述处理后,人脸部的一些特征就可以使用矩形框的差值简单地表示了。比如,眼睛的颜色比脸颊的颜色要深,鼻梁两侧的颜色比鼻梁的颜色深,唇部的颜色比唇部周围的颜色深。
关于 Harr 特征中的矩形框,有如下 3 个变量。
- 矩形位置:矩形框要逐像素地划过(遍历)整个图像获取每个位置的差值。
- 矩形大小:矩形的大小可以根据需要做任意调整。
- 矩形类型:包含垂直、水平、对角等不同类型。
上述 3 个变量保证了能够细致全面地获取图像的特征信息。但是,变量的个数越多,特征的数量也会越多。
例如,仅一个 24×24 大小的检测窗口内的特征数量就接近 20 万个。由于计算量过大,该方案并不实用,除非有人提出能够简化特征的方案。
后来,Viola 和 Jones 两位学者在论文 Rapid Object Detection Using A Boosted Cascade OfSimple Features 和 Robust Real-time Face Detection 中提出了使用积分图像快速计算 Haar 特征的方法。他们提出通过构造“积分图(Integral Image)”,让 Haar 特征能够通过查表法和有限次简单运算快速获取,极大地减少了运算量。同时,在这两篇文章中,他们提出了通过构造级联分类器让不符合条件的背景图像(负样本)被快速地抛弃,从而能够将算力运用在可能包含人脸的对象上。
为了进一步提高效率,Lienhart 和 Maydt 两位学者,在论文 An Extended Set Of Haar-LikeFeatures For Rapid Object Detection 中提出对 Haar 特征库进行扩展。他们将 Haar 特征进一步划分为如图 23-4 所示的 4 类:
- 4 个边特征。
- 8 个线特征。
- 2 个中心点特征。
- 1 个对角特征。
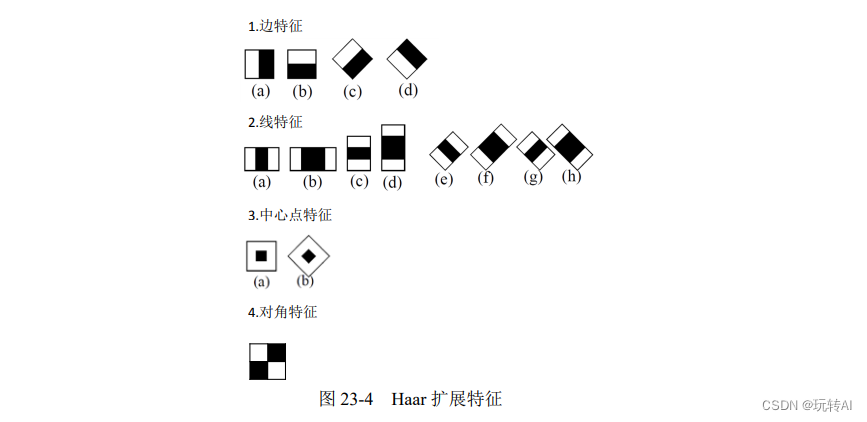
Lienhart 和 Maydt 两位学者认为在实际使用中,对角特征(见图 23-4 底部)和线特征中的“e”和“g”(见图 23-4 的第 2 行,(e)图和(g)图)是相近的,因此通常情况下无须重复计算。
同时,该论文还给出了计算 Haar 特征数的方法、快速计算方法,以及级联分类器的构造方法等内容。
OpenCV 在上述研究的基础上,实现了将 Haar 级联分类器用于人脸部特征的定位。我们可以直接调用 OpenCV 自带的 Haar 级联特征分类器来实现人脸定位。
级联分类器的使用
在 OpenCV
1.边特征
2.线特征
3.中心点特征
4.对角特征中,有一些训练好的级联分类器供用户使用。这些分类器可以用来检测人脸、脸部特征(眼睛、
鼻子)、人类和其他物体。这些级联分类器以 XML 文件的形式存放在 OpenCV 源文件的 data 目录下,加载不同级联分类器的 XML 文件就可以实现对不同对象的检测。
下载地址
https://github.com/opencv/opencv/tree/4.x/data/haarcascades
OpenCV 自带的级联分类器存储在 OpenCV 根文件夹的 data 文件夹下。该文件夹包含三个子文件夹:haarcascades、hogcascades、lbpcascades,里面分别存储的是 Harr 级联分类器、HOG级联分类器、LBP 级联分类器。
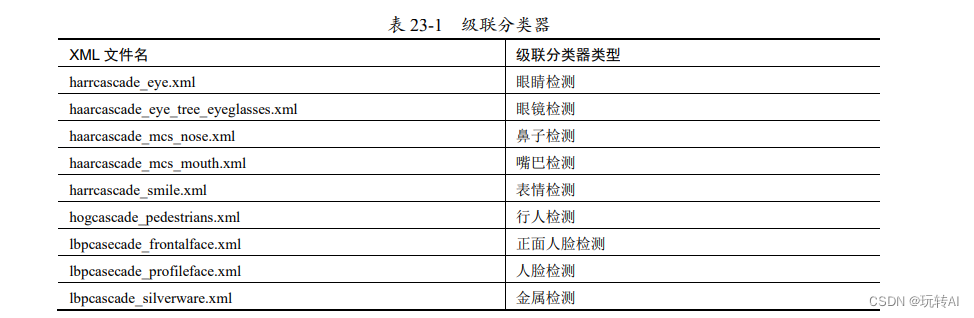
其中,Harr 级联分类器多达 20 多种(随着版本更新还会继续增加),提供了对多种对象的检测功能。部分级联分类器如表 23-1 所示。
加载级联分类器的语法格式为:
<CascadeClassifier object> = cv2.CascadeClassifier( filename )
式中,filename 是分类器的路径和名称。
下面的代码是一个调用实例:
faceCascade =
cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
使用级联分类器时需要注意:如果你是通过在anaconda中使用pip的方式安装的OpenCV,则无法直接获取级联分类器的 XML 文件。可以通过以下两种方式获取需要的级联分类器 XML
文件:
- 安装 OpenCV 后,在其安装目录下的 data 文件夹内查找 XML 文件。
- 直接在网络上找到相应 XML 文件,下载并使用。
同样,如果使用 opencv_createsamples.exe 和 opencv_traincascade.exe,也需要采用上述方式获取 XML 文件。
cv2.CascadeClassifier.detectMultiScale() 函数介绍
在 OpenCV 中,人脸检测使用的是 cv2.CascadeClassifier.detectMultiScale()函数,它可以检
测出图片中所有的人脸。该函数由分类器对象调用,其语法格式为:
objects = cv2.CascadeClassifier.detectMultiScale( image[,
scaleFactor[, minNeighbors[, flags[, minSize[, maxSize]]]]] )
式中各个参数及返回值的含义为:
- image:待检测图像,通常为灰度图像。
- scaleFactor:表示在前后两次相继的扫描中,搜索窗口的缩放比例。
- minNeighbors:表示构成检测目标的相邻矩形的最小个数。默认情况下,该值为 3,意味着有 3 个以上的检测标记存在时,才认为人脸存在。如果希望提高检测的准确率,可以将该值设置得更大,但同时可能会让一些人脸无法被检测到。
- flags:该参数通常被省略。在使用低版本 OpenCV(OpenCV 1.X 版本)时,它可能会被设置为 CV_HAAR_DO_CANNY_PRUNING,表示使用 Canny 边缘检测器来拒绝一些区域。
- minSize:目标的最小尺寸,小于这个尺寸的目标将被忽略。
- maxSize:目标的最大尺寸,大于这个尺寸的目标将被忽略。
- objects:返回值,目标对象的矩形框向量组。
示例:使用函数 cv2.CascadeClassifier.detectMultiScale()检测一幅图像内的人脸
原图:

import cv2
# 读取待检测的图像
image = cv2.imread('face\\face3.jpg')
# 获取 XML 文件,加载人脸检测器
faceCascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 色彩转换,转换为灰度图像
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# 调用函数 detectMultiScale
faces = faceCascade.detectMultiScale(gray,scaleFactor = 1.15,minNeighbors = 5,minSize = (5,5)
)
print(faces)
# 打印输出的测试结果
print("发现{0}个人脸!".format(len(faces)))
# 逐个标注人脸
for(x,y,w,h) in faces:cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2) #矩形标注
# 显示结果
cv2.imshow("dect",image)
# 保存检测结果
cv2.imwrite("re.jpg",image)
cv2.waitKey(0)
运行结果:
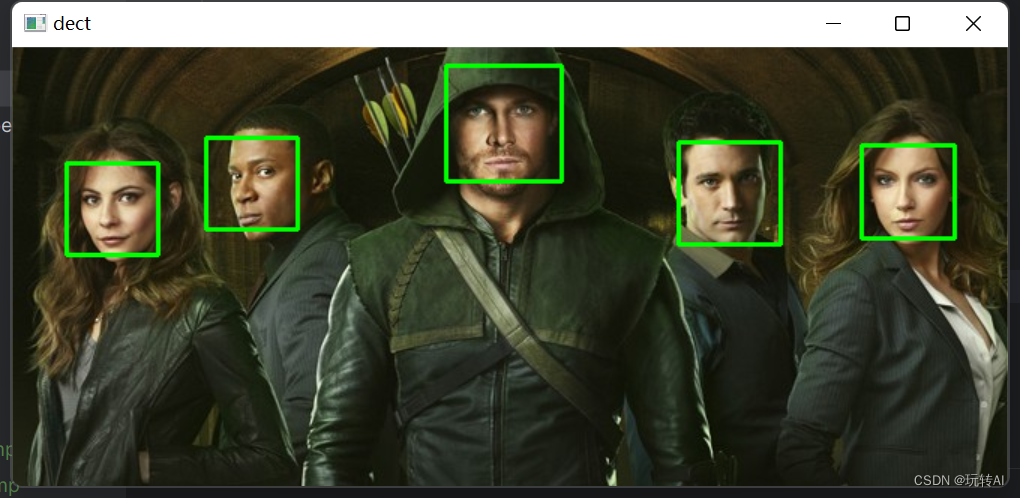
同时,在控制台会显示检测到的人脸的具体位置信息及个数,具体结果如下:
[[129 59 61 61]
[ 35 76 62 62]
[565 65 61 61]
[443 62 71 71]
[290 13 77 77]]
发现 5 个人脸!
相关文章:
opencv 进阶10-人脸识别原理说明及示例-cv2.CascadeClassifier.detectMultiScale()
人脸识别是指程序对输入的人脸图像进行判断,并识别出其对应的人的过程。人脸识别程 序像我们人类一样,“看到”一张人脸后就能够分辨出这个人是家人、朋友还是明星。 当然,要实现人脸识别,首先要判断当前图像内是否出现了人脸&…...

〔013〕Stable Diffusion 之 图片自动评分和不健康内容过滤器 篇
✨ 目录 🎈 下载咖啡美学评价插件🎈 咖啡美学评价使用🎈 不健康内容过滤器插件🎈 下载咖啡美学评价插件 想让系统帮你的图片作品打分评价,可以下载咖啡美学自动评价插件插件地址:https://github.com/p1atdev/stable-diffusion-webui-cafe-aesthetic也可以通过扩展列表…...

6.RocketMQ之消费索引文件ConsumeQueue
功能:作为CommitLog文件的索引文件。 本文着重分析为consumequeue/topic/queueId目录下的索引文件。 1.ConsumeQueueStore public class ConsumeQueueStore {protected final ConcurrentMap<String>, ConcurrentMap<Integer>, ConsumeQueueInterface…...
Appium-移动端自动测试框架,如何入门?
Appium是一个开源跨平台移动应用自动化测试框架。 既然只是想学习下Appium如何入门,那么我们就直奔主题。文章结构如下: 1、为什么要使用Appium? 2、如何搭建Appium工具环境?(超详细) 3、通过demo演示Appium的使用 4、Appium如何…...
复数混频器、零中频架构和高级算法开发
文章里讲解了关于射频IQ调制器、零中频架构相关的原理及技术,全都是干货!其实好多同行对软件无线电的原理、IQ调制、镜像抑制都是一知半解,知其然不知其所以然。好好研读这篇文章,相信会让你有种恍然大悟的感觉。 RF工程常被视为…...
Web 拦截器-interceptor
拦截器是一种动态拦截方法调用的机制,类似于过滤器,是Spring框架提出的,用来动态拦截控制器方法的执行。 其作用是拦截请求,在指定方法调用前后,根据业务执行预设代码。 实现步骤 1.定义拦截器,实现Handl…...

Java进阶(4)——结合类加载JVM的过程理解创建对象的几种方式:new,反射Class,克隆clone(拷贝),序列化反序列化
目录 引出类什么时候被加载JVM中创建对象几种方式1.new 看到new : new Book()2.反射 Class.forName(“包名.类名”)如何获取Class对象【反射的基础】案例:连接数据库方法 3.克隆(拷贝)clone浅拷贝深拷贝案例 序列化和反序列化对象流-把对象存…...
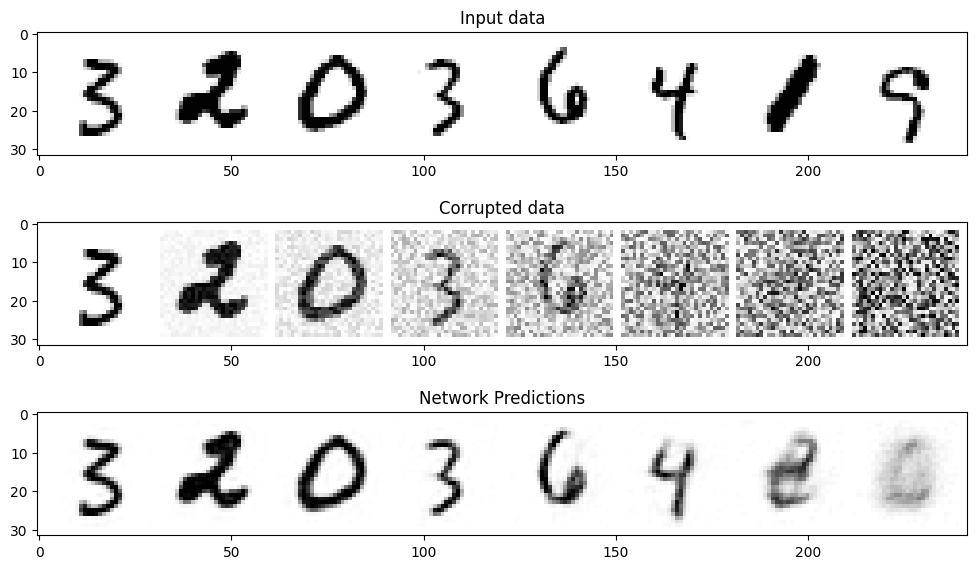
扩散模型实战(四):从零构建扩散模型
推荐阅读列表: 扩散模型实战(一):基本原理介绍 扩散模型实战(二):扩散模型的发展 扩散模型实战(三):扩散模型的应用 本文以MNIST数据集为例,从…...

YOLOv5、YOLOv8改进:S2注意力机制
目录 1.简介 2.YOLOv5改进 2.1增加以下S2-MLPv2.yaml文件 2.2common.py配置 2.3yolo.py配置 1.简介 S2-MLPv2注意力机制 最近,出现了基于 MLP 的视觉主干。与 CNN 和视觉Transformer相比,基于 MLP 的视觉架构具有较少的归纳偏差,在图像识…...
LeetCode 542. 01 Matrix【多源BFS】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
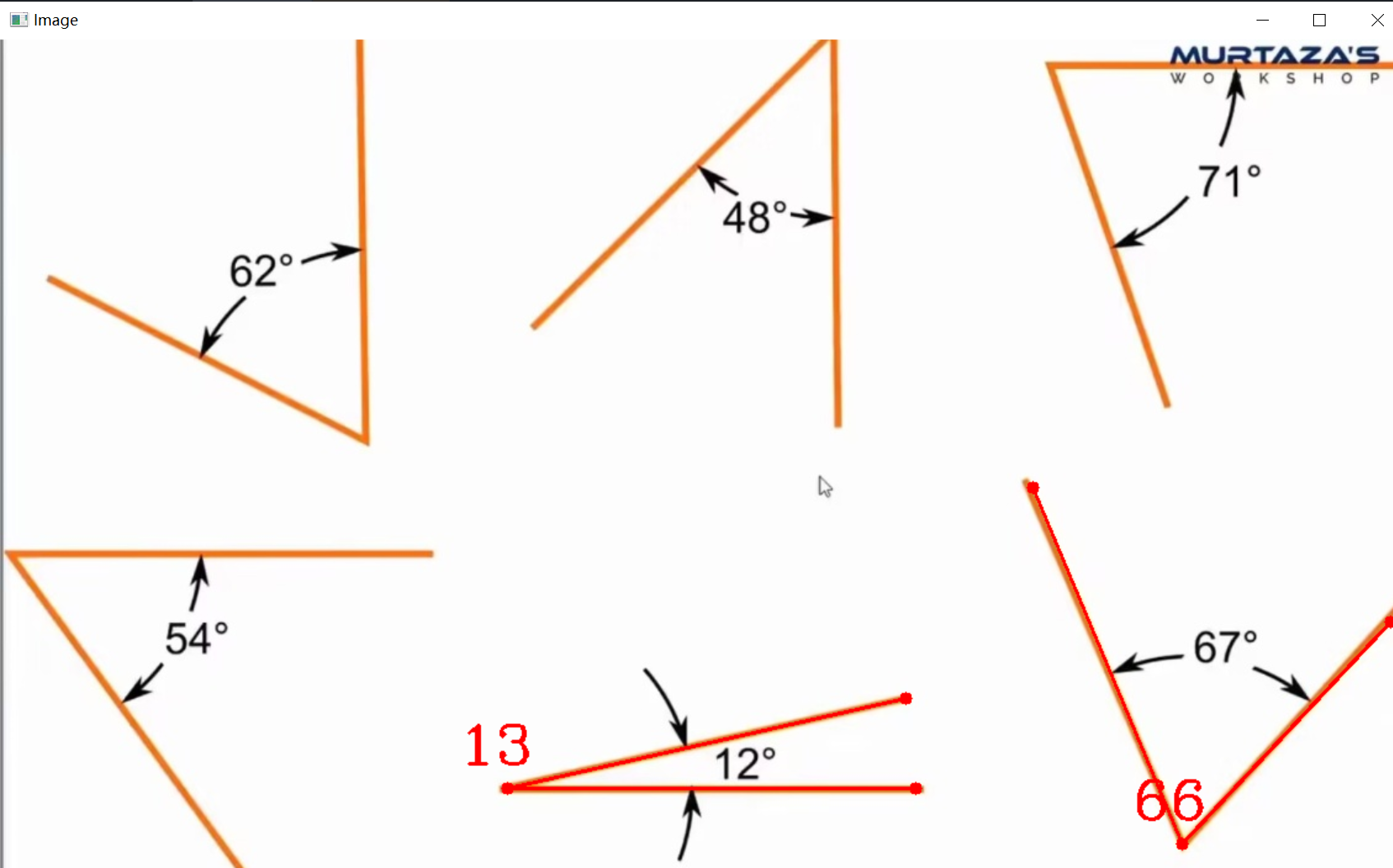
使用open cv进行角度测量
使用open cv进行角度测量 用了一点初中数学的知识,准确度,跟鼠标点的准不准有关系,话不多说直接上代码 import cv2 import mathpath "test.jpg" img cv2.imread(path) pointsList []def mousePoint(event, x, y, flags, param…...

java 线程池实现多线程处理list数据
newFixedThreadPool线程池实现多线程 List<PackageAgreementEntity> entityList new CopyOnWriteArrayList<>();//多线程 10个线程//int threadNum 10;int listSize 300;List<List<PackageAgreementDto>> splitData Lists.partition(packageAgre…...
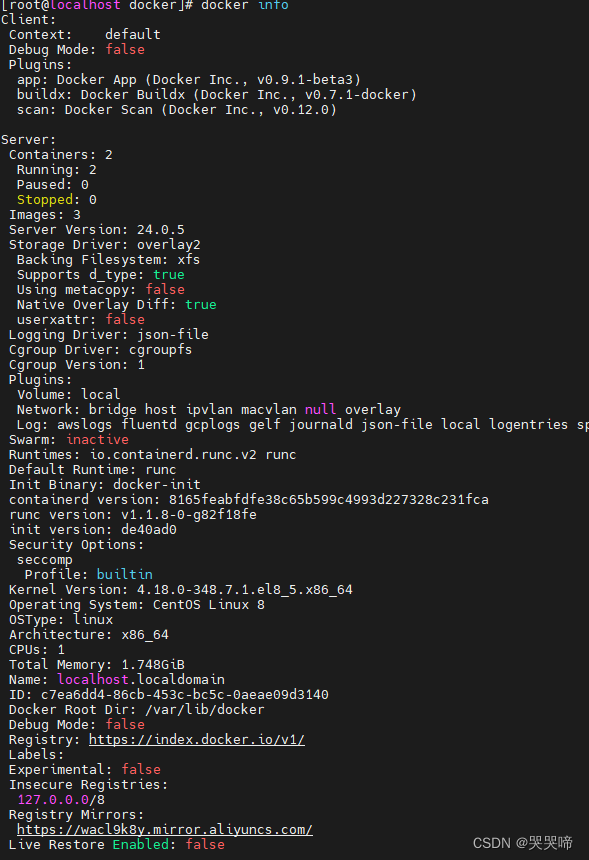
Centos安装Docker
Centos安装 Docker 从 2017 年 3 月开始 docker 在原来的基础上分为两个分支版本: Docker CE 和 Docker EE。 Docker CE 即社区免费版,Docker EE 即企业版,强调安全,但需付费使用。 本文介绍 Docker CE 的安装使用。 移除旧的版本&#x…...

Unity启动项目无反应的解决
文章首发见博客:https://mwhls.top/4803.html。 无图/格式错误/后续更新请见首发页。 更多更新请到mwhls.top查看 欢迎留言提问或批评建议,私信不回。 摘要:通过退还并重新载入许可证以解决Unity项目启动无反应问题。 场景 Unity Hub启动项目…...

2.3 opensbi: riscv: opensbi源码解析
文章目录 3. sbi_init()函数4. init_coldboot()函数4.1 sbi_scratch_init()函数4.2 sbi_domain_init()函数4.3 sbi_scratch_alloc_offset()函数4.4 sbi_hsm_init()函数4.5 sbi_platform_early_init()函数3. sbi_init()函数 函数位置:lib/sbi/sbi_init.c函数参数:scratch为每个…...
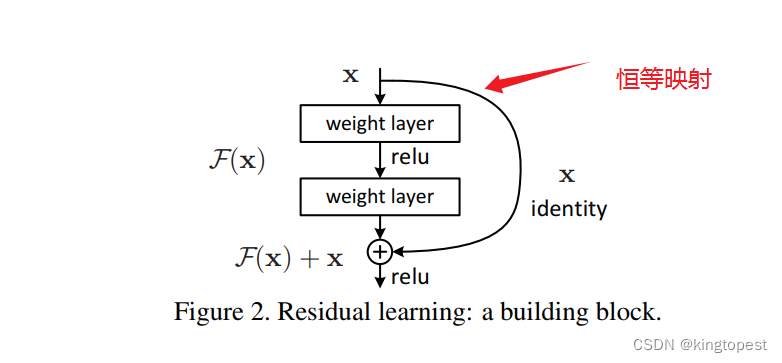
点破ResNet残差网络的精髓
卷积神经网络在实际训练过程中,不可避免会遇到一个问题:随着网络层数的增加,模型会发生退化。 换句话说,并不是网络层数越多越好,为什么会这样? 不是说网络越深,提取的特征越多ÿ…...
Ubuntu服务器service版本初始化
下载 下载路径 官网:https://cn.ubuntu.com/ 下载路径:https://cn.ubuntu.com/download 服务器:https://cn.ubuntu.com/download/server/step1 点击下载(22.04.3):https://cn.ubuntu.com/download/server…...
re学习(33)攻防世界-secret-galaxy-300(脑洞题)
下载压缩包: 下载链接:https://adworld.xctf.org.cn/challenges/list 参考文章:攻防世界逆向高手题之secret-galaxy-300_沐一 林的博客-CSDN博客 发现这只是三个同一类型文件的三个不同版本而已,一个windows32位exe࿰…...
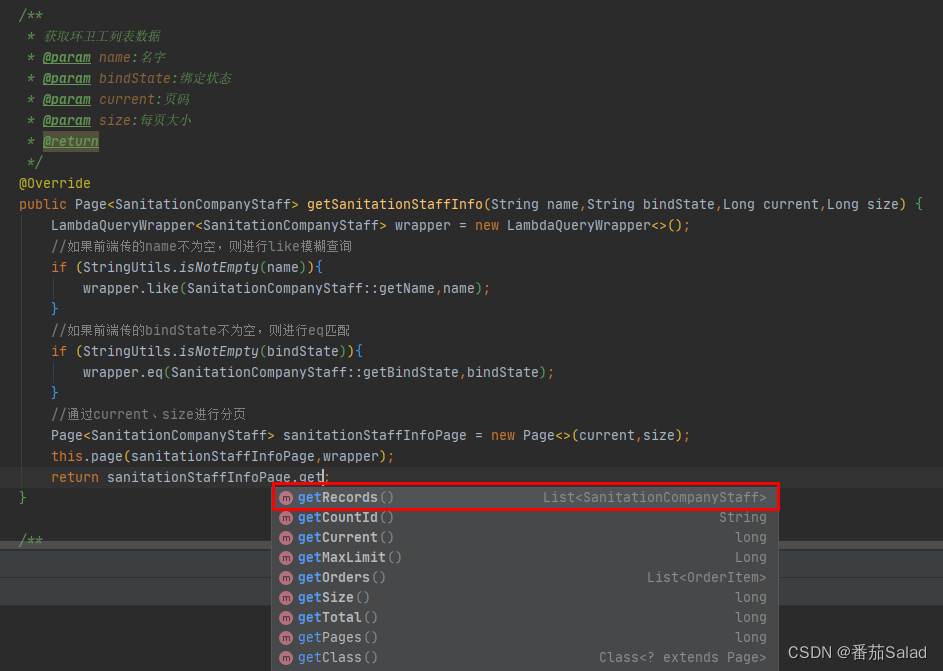
Mybatis Plus中使用LambdaQueryWrapper进行分页以及模糊查询对比传统XML方式进行分页
传统的XML分页以及模糊查询操作 传统的XML方式只能使用limit以及offset进行分页,通过判断name和bindState是否为空,不为空则拼接条件。 List<SanitationCompanyStaff> getSanitationStaffInfo(Param("name") String name,Param("bi…...

vue中push和resolve的区别
import { useRouter } from vue-router;const routeuseRouter()route.push({path:/test,query:{name:1}})import { useRouter } from vue-router;const routeuseRouter()const urlroute.resolve({path:/test,query:{name:1}})window.open(url.href)比较上述代码会发现,resolve能…...

如何用Obsidian主页插件打造你的专属数字工作台?
如何用Obsidian主页插件打造你的专属数字工作台? 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否厌倦了每次打…...
:从参数解析到多维张量展平实战)
nn.Flatten():从参数解析到多维张量展平实战
1. 理解nn.Flatten()的核心作用 当你第一次接触深度学习框架中的nn.Flatten()时,可能会觉得这个函数简单到不需要解释——不就是把多维数据压平吗?但真正用起来就会发现,里面的门道比想象中多得多。我在实际项目中就遇到过因为错误理解展平维…...

给每个 Agent 装上专属工具集:Multi-Agent 权限隔离的三种设计模式一次讲透
我第一次写多 Agent 系统时犯过一个错误:把所有工具塞进一个 tools 数组,然后把这个数组挂给每个 Agent。结果上线后发现:负责写文章摘要的 Agent,有时候莫名其妙地调用了删除接口;负责检索资料的 Agent,偶…...

家庭网络技术演进:从CES看有线与无线技术的融合与竞争
1. 家庭网络技术演进:从CES看有线与无线的融合与竞争每年一月的拉斯维加斯,CES(国际消费电子展)都是科技行业的风向标。对于像我这样长期关注网络技术的从业者来说,CES不仅是新产品的秀场,更是观察底层技术…...

《心核驱动:基于本质定义的AI性格自进化架构》
前言:拒绝表面调参,直击AI性格本质当前市面上的AI性格定制,大多停留在“表层调参”阶段——试图通过调整温度、Top-p等概率参数来模拟情感,结果往往顾此失彼,要么机械生硬,要么逻辑崩塌。真正的智能性格&am…...

Docker 学习笔记:镜像分发、容器运行与资源限制
Docker 学习笔记:镜像分发、容器运行与资源限制本笔记续接上一部分,涵盖镜像命名与分发、容器的核心操作、底层技术(cgroup/namespace)以及 CPU/内存资源限制。所有案例代码均经验证,直接可用。8. 镜像命名与分发最佳实…...

FcμR识别IgM复杂机制的揭示:解锁人体免疫早期应答之谜
一、引言免疫系统是机体抵御病原体入侵、维持内环境稳定的关键防线。在免疫应答过程中,不同类型的免疫球蛋白发挥着独特的作用。其中,IgM作为人体五类免疫球蛋白之一,在免疫应答早期起着至关重要的作用。而Fc受体作为免疫系统中的重要组成部分…...

AI智能体安全防护:ClawGuard主动防御系统架构与实战部署
1. 项目概述:为AI智能体构建一道主动防御的“防火墙”在AI智能体(AI Agent)技术快速普及的今天,我们正面临一个全新的安全挑战。想象一下,你精心调教的AI助手,能够自主浏览网页、调用API、执行命令…...

KeyboardChatterBlocker:拯救老旧机械键盘的免费开源防连击工具
KeyboardChatterBlocker:拯救老旧机械键盘的免费开源防连击工具 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 你是否遇到过…...

Ninja构建系统实战:手写BUILD.ninja为你的Python/Go小工具加速
Ninja构建系统实战:手写BUILD.ninja为你的Python/Go小工具加速 在快速迭代的现代开发中,构建流程的效率往往成为瓶颈。当你的Python脚本需要打包成可执行文件,Go模块需要交叉编译,同时还要处理资源文件复制、依赖下载等一系列任务…...