PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(12)——数据增强
- 0. 前言
- 1. 图像增强
- 1.1 仿射变换
- 1.2 亮度修改
- 1.3 添加噪音
- 1.4 联合使用多个增强方法
- 2. 对批图像执行图像增强
- 3. 利用数据增强训练模型
- 小结
- 系列链接
0. 前言
数据增强是指通过对原始数据进行一系列变换和处理,生成更多、更丰富的训练样本的技术方法。数据增强在机器学习和深度学习领域中被广泛应用,它可以有效地解决数据不足的问题,提高模型的泛化能力和鲁棒性。我们已经了解了卷积神经网络 (Convolutional Neural Network, CNN) 有助于解决图像平移问题,但如果平移的范围过大同样可能影响模型的性能。在本节中,我们将学习如何使用数据增强确保模型能够得到正确的预测结果,即使图像移动较大范围。
1. 图像增强
数据增强的目的是通过对原始数据进行合理的变换,生成新的样本,使得这些样本在保持原始类别标签不变的情况下,尽可能涵盖更多的数据特征和变化情况。在计算机视觉领域,对于给定的图像,即使我们平移,旋转或缩放图像,图像的标签也将保持不变。
基于上述原理,数据增强是从给定的图像集中创建更多图像的一种方法,即通过旋转,平移或缩放它们并将它们映射到原始图像的标签,以扩充数据集。通过随机平移输入图像并将它们传递给网络来训练神经网络,相同的图像将在不同批次中作为不同的图像处理,因为在每个批次中具有不同的平移量。我们已经了解了图像平移对模型预测准确性的影响。但是,在现实世界中,我们可能会遇到其他多种图像变换的情况:
- 图像旋转
- 图像缩放
- 图片翻转
- 图像剪切
- 图像中存在噪点
- 图像亮度较低/高
如果不考虑以上情况,训练出的神经网络并不会得到准确的预测结果。图像增强根据给定图像创建更多图像,通过旋转、平移、缩放、添加噪声和亮度等修改原始图像,此外,可以使用不同的参数指定图像的变化程度(例如,某个图像的平移可以是 +10 像素,也可以是 -5 像素)。imgaug 库中的 augmenters 类可以用于实现数据增强,常用的数据增强技术如下:
- 仿射变换
- 亮度修改
- 添加噪音
PyTorch 中同样包含图像增强管道 torchvision.transforms。但是,imgaug 包含更多选项,且易于解释数据增强功能,可以使用 pip 命令安装 imgaug 库:
pip install imgaug
1.1 仿射变换
仿射变换包括平移、旋转、缩放和剪切图像,可以使用 augmenters 类中的 Affine 方法执行仿射变换。Affine 方法中包含以下重要参数:
scale:要对图像进行的缩放量translate_percent: 将平移量指定为图像高度和宽度的百分比translate_px:将平移量指定为绝对像素数rotate:要在图像上完成的旋转量shear:要在图像的一部分上完成的旋转量
(1) 从 Fashion-MNIST 数据集中获取随机图像:
import imgaug
import imgaug.augmenters as iaa
print(imgaug.__version__)
# 0.4.0from torchvision import datasets
import torch
data_folder = './data/FMNIST'
fmnist = datasets.FashionMNIST(data_folder, download=True, train=True)tr_images = fmnist.data
tr_targets = fmnist.targetsimport matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'def to_numpy(tensor):return tensor.cpu().detach().numpy()plt.imshow(tr_images[0], cmap='gray')
plt.title('Original image')
plt.show()

(2) 定义用于执行缩放的对象 aug:
aug = iaa.Affine(scale=2)
(3) 指定使用 aug 对象中的 augment_image 方法执行图像增强,并进行绘制:
plt.imshow(aug.augment_image(to_numpy(tr_images[0])))
plt.title('Scaled image')
plt.show()

在以上输出中,图像已被放大,但由于图像的输出形状没有改变,因此会从原始图像中删除一部分像素。
(4) 使用 translate_px 参数执行图像平移:
aug = iaa.Affine(translate_px=10)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Translated image by 10 pixels (right and bottom)')
plt.show()

在以上输出中,x 轴和 y 轴都平移了 10 个像素。如果两个轴上平移不同的像素量,则必须指定在每个轴上的平移量:
aug = iaa.Affine(translate_px={'x':10,'y':2})
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Translation of 10 pixels \nacross columns and 2 pixels over rows')
plt.show()

在以上输出结果中,在 translate_px 参数中使用字典指定 x 和 y 轴的平移量,图像在 x 轴上平移了更多像素。
(5) 观察旋转和剪切对图像增强的影响:
plt.figure(figsize=(20,20))
plt.subplot(151)
plt.imshow(tr_images[0], cmap='gray')
plt.title('Original image')
plt.subplot(152)
aug = iaa.Affine(scale=2)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Scaled image')
plt.subplot(153)
aug = iaa.Affine(translate_px={'x':10,'y':2})
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Translation of 10 pixels across \ncolumns and 2 pixels over rows')
plt.subplot(154)
aug = iaa.Affine(rotate=30)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image \nby 30 degrees')
plt.subplot(155)
aug = iaa.Affine(shear=30)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Shear of image \nby 30 degrees')
plt.show()

在以上输出中,可以看到某些像素在转换后从图像中被裁剪掉。接下来,我们利用 Affine 方法中的 fit_output 参数确保图像不因裁剪丢失信息。默认情况下,fit_output 设置为 False,将 fit_output 指定为 True 时,观察在缩放、平移、旋转和剪切图像时,输出图像的变化:
plt.figure(figsize=(20,20))
plt.subplot(151)
plt.imshow(tr_images[0], cmap='gray')
plt.title('Original image')
plt.subplot(152)
aug = iaa.Affine(scale=2, fit_output=True)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Scaled image')
plt.subplot(153)
aug = iaa.Affine(translate_px={'x':10,'y':2}, fit_output=True)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Translation of 10 pixels across \ncolumns and 2 pixels over rows')
plt.subplot(154)
aug = iaa.Affine(rotate=30, fit_output=True)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image \nby 30 degrees')
plt.subplot(155)
aug = iaa.Affine(shear=30, fit_output=True)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Shear of image \nby 30 degrees')
plt.show()

可以看到原始图像没有被裁剪,并且会增加图像的大小以进行完整显示。当增强图像的大小增加时,我们需要清楚如何填充不属于原始图像的新像素。
当 fit_output 为 True 时,使用 cval 参数指定创建的新像素的像素值。在以上代码中,cval 填充了默认值 0,即黑色像素,接下来,将 cval 参数改为 255,即白色像素,观察输出结果:
aug = iaa.Affine(rotate=30, fit_output=True, cval=255)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by 30 degrees')
plt.show()

此外,可以使用不同的模式来填充新创建的像素的值,mode 参数的可选值如下:
constant:使用恒定值填充edge:用输入的边缘值填充symmetric:用沿输入边缘的反射填充reflect:用反射向量填充wrap:用沿轴的向量填充
将 cval 设置为 0 并使用不同 mode 参数:
plt.figure(figsize=(20,20))
plt.subplot(151)
aug = iaa.Affine(rotate=30, fit_output=True, cval=0, mode='constant')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by \n30 degrees with constant mode')
plt.subplot(152)
aug = iaa.Affine(rotate=30, fit_output=True, cval=0, mode='edge')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by 30 degrees \n with edge mode')
plt.subplot(153)
aug = iaa.Affine(rotate=30, fit_output=True, cval=0, mode='symmetric')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by \n30 degrees with symmetric mode')
plt.subplot(154)
aug = iaa.Affine(rotate=30, fit_output=True, cval=0, mode='reflect')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by 30 degrees \n with reflect mode')
plt.subplot(155)
aug = iaa.Affine(rotate=30, fit_output=True, cval=0, mode='wrap')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.title('Rotation of image by \n30 degrees with wrap mode')
plt.show()

在执行数据增强时,很难指定图像需要旋转的确切角度,通常提供图像将旋转的范围:
plt.figure(figsize=(20,20))
plt.subplot(141)
aug = iaa.Affine(rotate=(-45,45), fit_output=True, cval=0, mode='constant')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.subplot(142)
aug = iaa.Affine(rotate=(-45,45), fit_output=True, cval=0, mode='constant')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.subplot(143)
aug = iaa.Affine(rotate=(-45,45), fit_output=True, cval=0, mode='constant')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.subplot(144)
aug = iaa.Affine(rotate=(-45,45), fit_output=True, cval=0, mode='constant')
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray')
plt.show()

在以上输出中,由于根据旋转的上限和下限指定了可能的旋转角度范围,相同的图像在不同的迭代中旋转角度不同。同样,我们可以在平移或缩放图像时引入随机化增强。
1.2 亮度修改
由于图像中的照明条件不同,背景和前景之间的差异有时并不明显。如果在训练模型时背景的像素值始终为 0,前景的像素值始终为 255,而预测图像的背景像素值为 20,前景像素值为 220,则预测很可能并不正确。乘法( Multiply )和线性对比度( Linearcontrast) 是两种不同的增强技术,可以解决照明条件不同的问题。
Multiply 方法将每个像素值乘以指定的值,例如将图像中的每个像素值乘以 0.5 后输出:
aug = iaa.Multiply(0.5)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Pixels multiplied by 0.5')
plt.show()

Linearcontrast 根据以下公式调整每个像素值:
127 + α × ( x i − 127 ) 127+\alpha \times(x_i-127) 127+α×(xi−127)
其中, x i x_i xi 表示像素值,当 α α α 等于 1 时,像素值保持不变,当 α α α 小于 1 时,高像素值减少,低像素值增加。观察对输出图像的影响:
aug = iaa.LinearContrast(0.5)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Pixel contrast by 0.5')
plt.show()

可以看到,使用 Linearcontrast 方法,图像中的背景变得更加明亮,而前景像素的强度降低了。
使用 GaussianBlur 方法模糊图像以模拟真实场景(图像可能由于运动而模糊):
aug = iaa.GaussianBlur(sigma=1)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Gaussian blurring of image\n with a sigma of 1')
plt.show()

可以看到图像非常模糊,并且随着 sigma 值的增加,图像也会变得更加模糊。
1.3 添加噪音
在现实世界的场景中,可能会在图像中包含噪点,Dropout 和 SaltAndPepper 是用于模拟图像噪声的两种主要方法:
aug = iaa.Dropout(p=0.2)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Random 20% pixel dropout')
plt.show()aug = iaa.SaltAndPepper(0.2)
plt.imshow(aug.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Random 20% salt and pepper noise')
plt.show()

可以看到 Dropout 方法随机丢弃了一定数量的像素,即将它们的像素值转换为 0,而 SaltAndPepper 方法则在图像中随机添加白色和黑色的像素。
1.4 联合使用多个增强方法
在现实世界的场景中,我们必须综合使用尽可能多的增强方法。在本节中,我们将了解图像增强的 Sequential 方式,
在 Sequential 方法中可以使用需要执行的增强方法来构造图像增强。如果只考虑旋转和 Dropout 来增强图像,Sequential 对象如下所示:
seq = iaa.Sequential([iaa.Dropout(p=0.2,),iaa.Affine(rotate=(-30,30))], random_order= True)
在以上代码中,指定两种增强方法,并且使用 random_order 参数,指示采用随机顺序执行两种增强方法:
plt.imshow(seq.augment_image(to_numpy(tr_images[0])), cmap='gray',vmin = 0, vmax = 255)
plt.title('Image augmented using a \nrandom orderof the two augmentations')
plt.show()

2. 对批图像执行图像增强
为了最大限度的提高模型性能,需要同一图像在不同迭代中执行不同的增强。如果我们在 __init__ 方法中定义了一个增强管道,则只需要对输入图像集执行一次增强,这意味着在不同的迭代中不会有不同的增强;如果增强是在 __getitem__ 方法中,会对每个图像执行一组不同的增强,对每个图像执行一次增强。如果每次对一批图像而不是一次对一个图像执行增强,可以提高算法执行效率,接下来,我们对比以下两种方案:
- 一次对一张图像执行增强,得到
32张图像 - 一次对一批图像执行增强,得到
32张图像
为了了解在这两种情况下执行图像增强所需的时间,利用 Fashion-MNIST 数据集的训练图像中的前 32 张图像。
(1) 获取训练数据集中的前 32 张图像:
from torchvision import datasets
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import timedata_folder = './data/FMNIST'
fmnist = datasets.FashionMNIST(data_folder, download=True, train=True)tr_images = fmnist.data
tr_targets = fmnist.targetsdef to_numpy(tensor):return tensor.cpu().detach().numpy()
(2) 指定要对图像执行的增强:
from imgaug import augmenters as iaa
aug = iaa.Sequential([iaa.Affine(translate_px={'x':(-10,10)}, mode='constant'),])
接下来,介绍如何在 Dataset 类中扩充数据,有两种方法来扩充数据:
- 每次增强一批数据中的一张图像
- 一次性增强一批数据中的所有图像
增强批数据中的 32 张图像,一次一张
使用 augment_image 方法,计算增强批数据中的 32 张图像(一次增强一张)所需的时间:
start = time.time()
for i in range(32):aug.augment_image(to_numpy(tr_images[i]))
print('total times: ', time.time()-start)
增强 32 张图像大约需要 33 毫秒。
一次性增强批数据中的 32 张图像
使用 augment_images 方法,计算一次性增强 32 张图像所需的时间:
start = time.time()
x = aug.augment_images(to_numpy(tr_images[:32]))
print('total times: ', time.time()-start)
对一批图像执行增强大约需要 12 毫秒。
因此,最佳实践是在一批图像之上执行增强,而不是一次增强一个图像,augment_images 方法的输出是一个 numpy 数组。但是,之前使用的 Dataset 类在 __getitem__ 方法中一次提供一张图像的索引。因此,需要创建一个新函数 collate_fn,使我们能够对一批图像执行操作。
(3) 定义 Dataset 类,将输入图像、类别和增强对象作为初始化器:
class FMNISTDataset(Dataset):def __init__(self, x, y, aug=None):self.x, self.y = x, yself.aug = augdef __getitem__(self, ix):x, y = self.x[ix], self.y[ix]return x, ydef __len__(self):return len(self.x)
(4) 定义 collate_fn 函数,将批数据作为输入:
def collate_fn(self, batch):
将批图像及其类别分成两个不同的变量:
ims, classes = list(zip(*batch))
如果提供了增强对象,则执行数据增强,因为我们只需要对训练数据执行增强,而验证数据无需执行增强:
# transform a batch of images at onceif self.aug:ims=self.aug.augment_images(images=list(map(to_numpy,list(ims))))
在以上代码中,使用 augment_images 方法,以便可以一次性处理一批图像。
创建图像张量,并通过将数据除以 255 来缩放数据:
ims = torch.tensor(ims)[:,None,:,:].to(device)/255.classes = torch.tensor(classes).to(device)return ims, classes
一般来说,当我们需要执行复杂计算时,会利用 collate_fn 方法,这是因为一次性对一批图像执行计算比一次执行一个图像要快得多。
(5) 为了利用 collate_fn 方法,在创建 DataLoader 时使用一个新参数。
首先,创建 train 对象:
train = FMNISTDataset(tr_images, tr_targets, aug=aug)
接下来,定义 DataLoader 以及对象的 collate_fn 方法:
trn_dl = DataLoader(train, batch_size=64,collate_fn=train.collate_fn, shuffle=True)
最后,训练模型,通过利用 collate_fn 方法,可以更快地训练模型。
3. 利用数据增强训练模型
接下来,我们使用增强数据训练模型,观察数据增强对模型训练的影响。
(1) 导入相关库和数据集:
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'data_folder = './data/FMNIST'
fmnist = datasets.FashionMNIST(data_folder, download=True, train=True)tr_images = fmnist.data
tr_targets = fmnist.targetsval_fmnist = datasets.FashionMNIST(data_folder, download=True, train=False)
val_images = val_fmnist.data
val_targets = val_fmnist.targets
(2) 创建数据集类,用于随机平移图像执行数据增强:
定义数据增强管道:
from imgaug import augmenters as iaa
aug = iaa.Sequential([iaa.Affine(translate_px={'x':(-10,10)},mode='constant'),])
定义数据集类:
def to_numpy(tensor):return tensor.numpy()class FMNISTDataset(Dataset):def __init__(self, x, y, aug=None):self.x, self.y = x, yself.aug = augdef __getitem__(self, ix):x, y = self.x[ix], self.y[ix]return x, ydef __len__(self):return len(self.x)def collate_fn(self, batch):'logic to modify a batch of images'ims, classes = list(zip(*batch))# transform a batch of images at onceif self.aug:ims=self.aug.augment_images(images=list(map(to_numpy,list(ims))))ims = torch.tensor(ims)[:,None,:,:].to(device)/255.classes = torch.tensor(classes).to(device)return ims, classes
在以上代码中,利用 collate_fn 方法来指定要对批图像执行增强。
(3) 定义模型架构:
from torch.optim import SGD, Adam
def get_model():model = nn.Sequential(nn.Conv2d(1, 64, kernel_size=3),nn.MaxPool2d(2),nn.ReLU(),nn.Conv2d(64, 128, kernel_size=3),nn.MaxPool2d(2),nn.ReLU(),nn.Flatten(),nn.Linear(3200, 256),nn.ReLU(),nn.Linear(256, 10)).to(device)loss_fn = nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=1e-3)return model, loss_fn, optimizer
(4) 定义 train_batch 函数以在批数据上训练模型:
def train_batch(x, y, model, optimizer, loss_fn):prediction = model(x)batch_loss = loss_fn(prediction, y)batch_loss.backward()optimizer.step()optimizer.zero_grad()return batch_loss.item()
(5) 定义 get_data 函数获取训练和验证 DataLoaders:
def get_data():train = FMNISTDataset(tr_images, tr_targets, aug=aug)'notice the collate_fn argument'trn_dl = DataLoader(train, batch_size=64,collate_fn=train.collate_fn, shuffle=True)val = FMNISTDataset(val_images, val_targets)val_dl = DataLoader(val, batch_size=len(val_images),collate_fn=val.collate_fn, shuffle=True)return trn_dl, val_dl
(6) 指定训练和验证 DataLoaders 并获取模型对象、损失函数和优化器:
trn_dl, val_dl = get_data()
model, loss_fn, optimizer = get_model()
(7) 训练模型:
for epoch in range(10):print(epoch)for ix, batch in enumerate(iter(trn_dl)):x, y = batchbatch_loss = train_batch(x, y, model, optimizer, loss_fn)
(8) 在平移图像上测试模型:
preds = []
ix = 24150
for px in range(-5,6):img = tr_images[ix]/255.img = img.view(28, 28)plt.subplot(1, 11, px+6)img2 = np.roll(img, px, axis=1)img3 = torch.Tensor(img2).view(-1,1,28,28).to(device)np_output = model(img3).cpu().detach().numpy()pred = np.exp(np_output)/np.sum(np.exp(np_output))preds.append(pred)plt.imshow(img2)plt.title(fmnist.classes[pred[0].argmax()])plt.show()

绘制模型关于平移图形的预测类别变化:
import seaborn as sns
fig, ax = plt.subplots(1,1, figsize=(12,10))
plt.title('Probability of each class for various translations')
sns.heatmap(np.array(preds).reshape(11,10), annot=True, ax=ax, fmt='.2f', xticklabels=fmnist.classes, yticklabels=[str(i)+str(' pixels') for i in range(-5,6)], cmap='gray')
plt.show()

可以看到,当我们预测各种平移图像时,模型能够以极高的置信度预测图像的正确类别。
小结
数据增强是一种有效的提升模型性能的方法,通过扩充训练数据集和增加数据的多样性,可以提高模型的泛化能力和鲁棒性。在实际应用中,可以根据需求选择适当的数据增强方法,并进行合理的参数设置,以获得更好的训练效果。imgaug 是一个用于机器学习中图像增强的 Python 库,它支持多种增强技术,能够轻松组合这些技术,且有丰富的文档支持,能满足大多数的数据增强的需求。本节中,介绍了图像增强的基本概念,并使用 imgaug 介绍了常见的图像增强技术,通过实验表明使用图像增强能够显著提高神经网络模型性能。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
相关文章:
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(12)——数据增强 0. 前言1. 图像增强1.1 仿射变换1.2 亮度修改1.3 添加噪音1.4 联合使用多个增强方法 2. 对批图像执行图像增强3. 利用数据增强训练模型小结系列链接 0. 前言 数据增强是指通过对原始数据进行一系列变换和处理&…...
SpringCloud Ribbon中的7种负载均衡策略
SpringCloud Ribbon中的7种负载均衡策略 Ribbon 介绍负载均衡设置7种负载均衡策略1.轮询策略2.权重策略3.随机策略4.最小连接数策略5.重试策略6.可用性敏感策略7.区域敏感策略 总结 负载均衡通器常有两种实现手段,一种是服务端负载均衡器,另一种是客户端…...
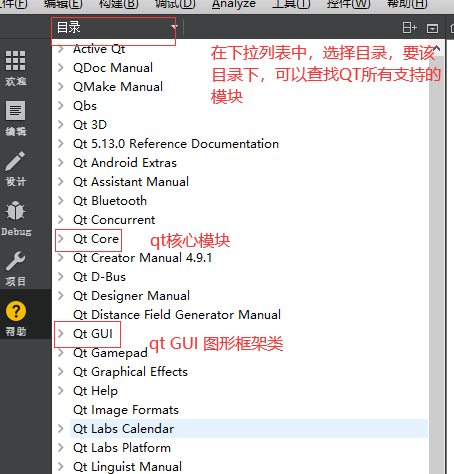
04 qt功能类、对话框类和文件操作
一 QT中时间和日期 时间 ---- QTime日期 ---- QDate对于Qt而言,在实际的开发过程中, 1)开发者可能知道所要使用的类 ---- >帮助手册 —>索引 -->直接输入类名进行查找 2)开发者可能不知道所要使用的类,只知道开发需求文档 ----> 帮助 手册,按下图操作: 1 …...
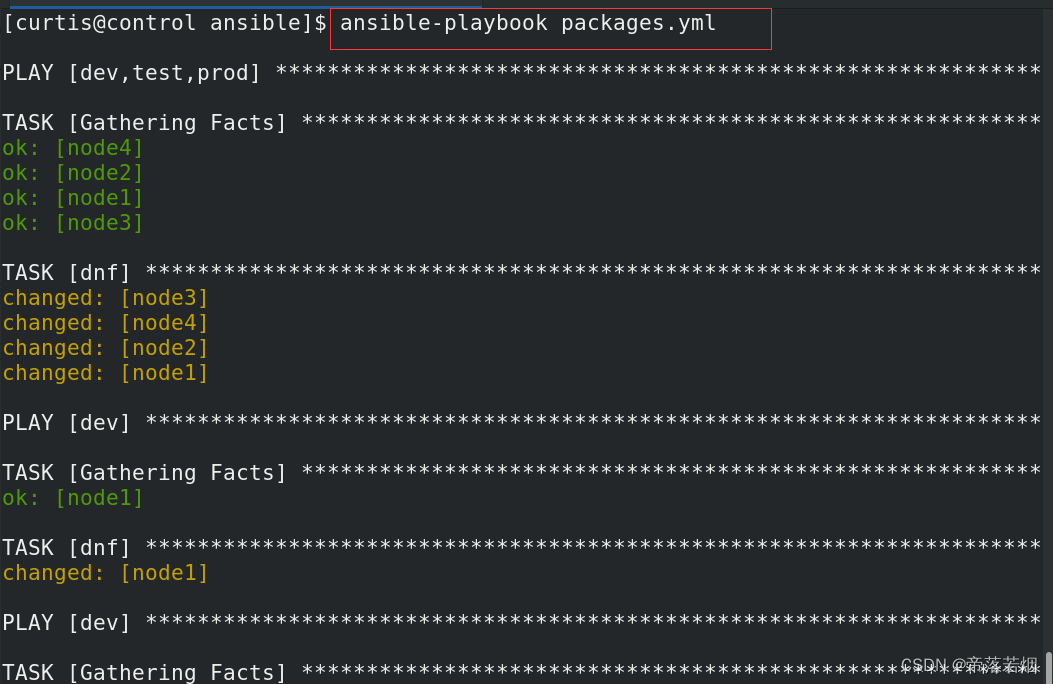
安装软件包
安装软件包 创建一个名为 /home/curtis/ansible/packages.yml 的 playbook : 将 php 和 mariadb 软件包安装到 dev、test 和 prod 主机组中的主机上 将 RPM Development Tools 软件包组安装到 dev 主机组中的主机上 将 dev 主机组中主机上的所有软件包更新为最新版本 vim packa…...

玩转单元测试之gmock
引言 前文我们学习了gtest相关的使用,单靠gtest,有些场景仍然无法进行测试,因此就诞生了gmock。 gmock快速入门 在引入gtest时,gmock也同样引入了,因此只需要在编译时加上合适的编译选项即可,注意不同版…...

POI与EasyExcel--写Excel
简单写入 03和07版的简单写入注意事项: 1. 对象不同:03对应HSSFWorkbook,07对应XSSFWorkbook 2. 文件后缀不同:03对应xls,07对应xlsx package com.zrf;import org.apache.poi.hssf.usermodel.HSSFWorkbook; import …...
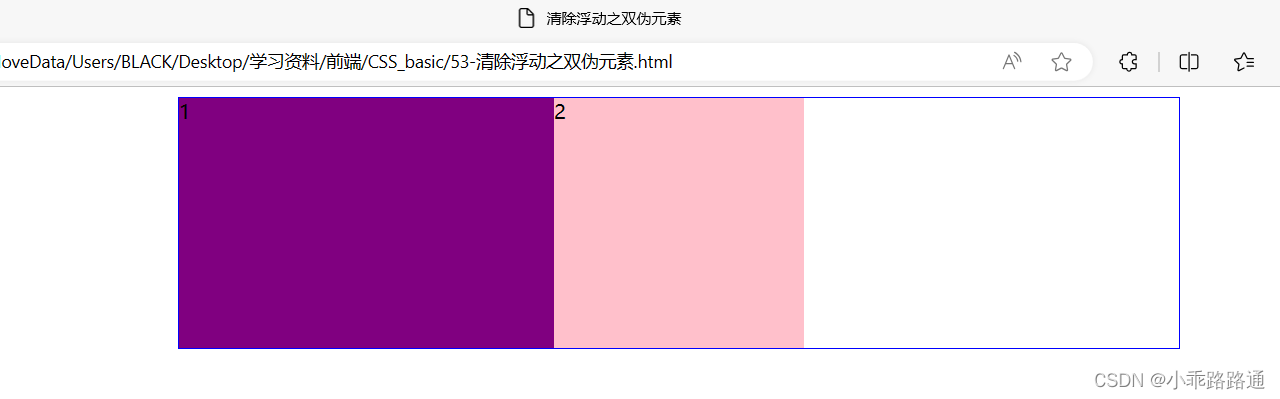
7. CSS(四)
目录 一、浮动 (一)传统网页布局的三种方式 (二)标准流(普通流/文档流) (三)为什么需要浮动? (四)什么是浮动 (五)浮…...

uni-app 集成推送
研究了几天,终于是打通了uni-app的推送,本文主要针对的是App端的推送开发过程,分为在线推送和离线推送。我们使用uni-app官方推荐的uni-push2.0。官方文档 准备工作:开通uni-push功能 勾选uniPush2.0点击"配置"填写表单…...

Spring Boot+Redis 实现消息队列实践示例
Spring BootRedis 实现一个轻量级的消息队列 文章目录 Spring BootRedis 实现一个轻量级的消息队列0.前言1.基础介绍2.步骤2.1. 引入依赖2.2. 配置文件2.3. 核心源码 4.总结答疑 5.参考文档6. Redis从入门到精通系列文章 0.前言 本文将介绍如何利用Spring Boot与Redis结合实现…...
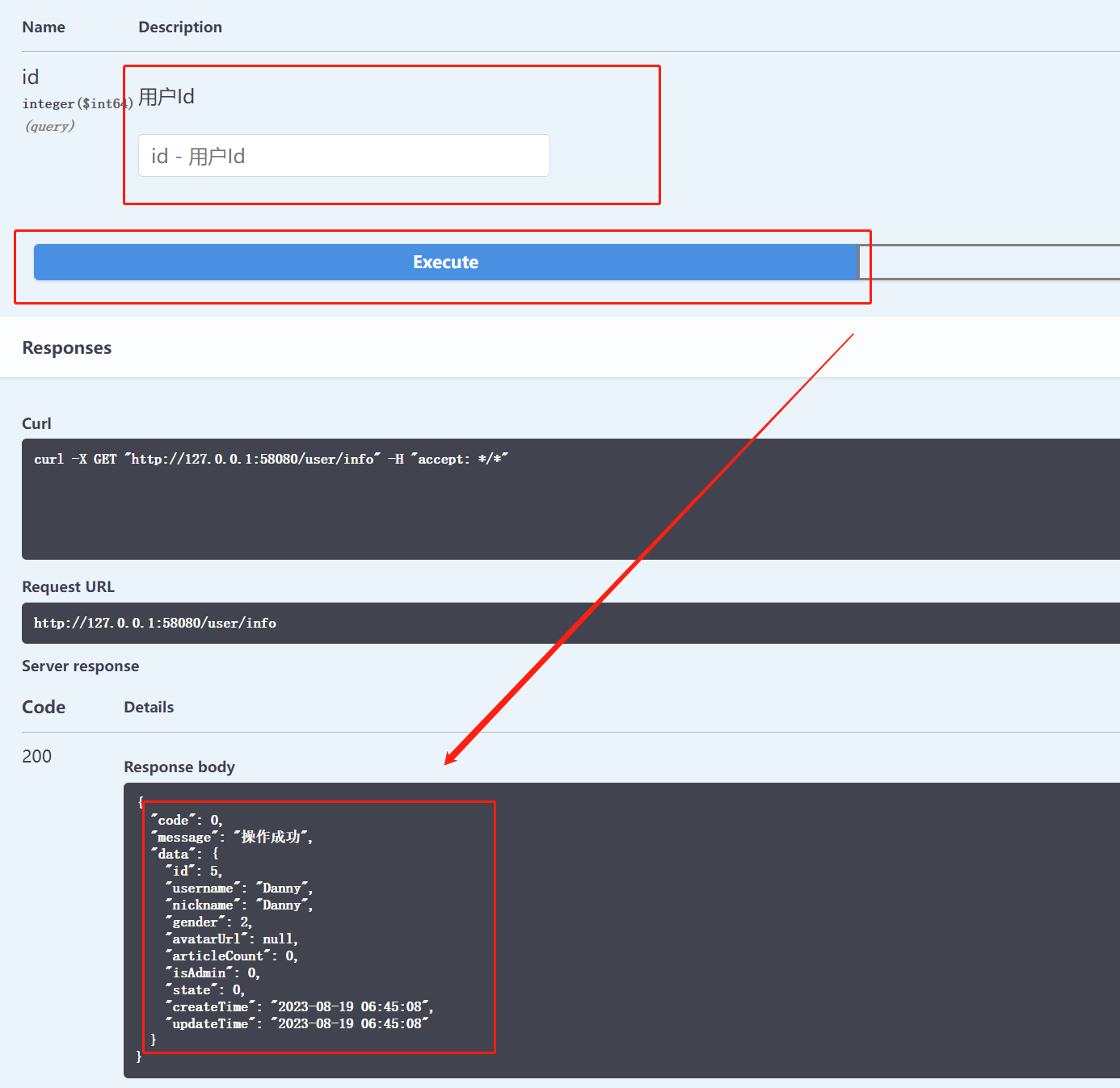
11. 实现业务功能--获取用户信息
目录 1. 实现 Controller 2. 单体测试 3. 修复返回值存在的缺陷 3.1 用户的隐私数据:密码的密文和盐不能显示 3.2 将值为 null 的字段可以进行过滤 3.3 时间的格式需要进行处理,如 yyyy-mmmm-ddd HH:mm:ss 3.4 data 属性没有返回 4. 实现前端页…...
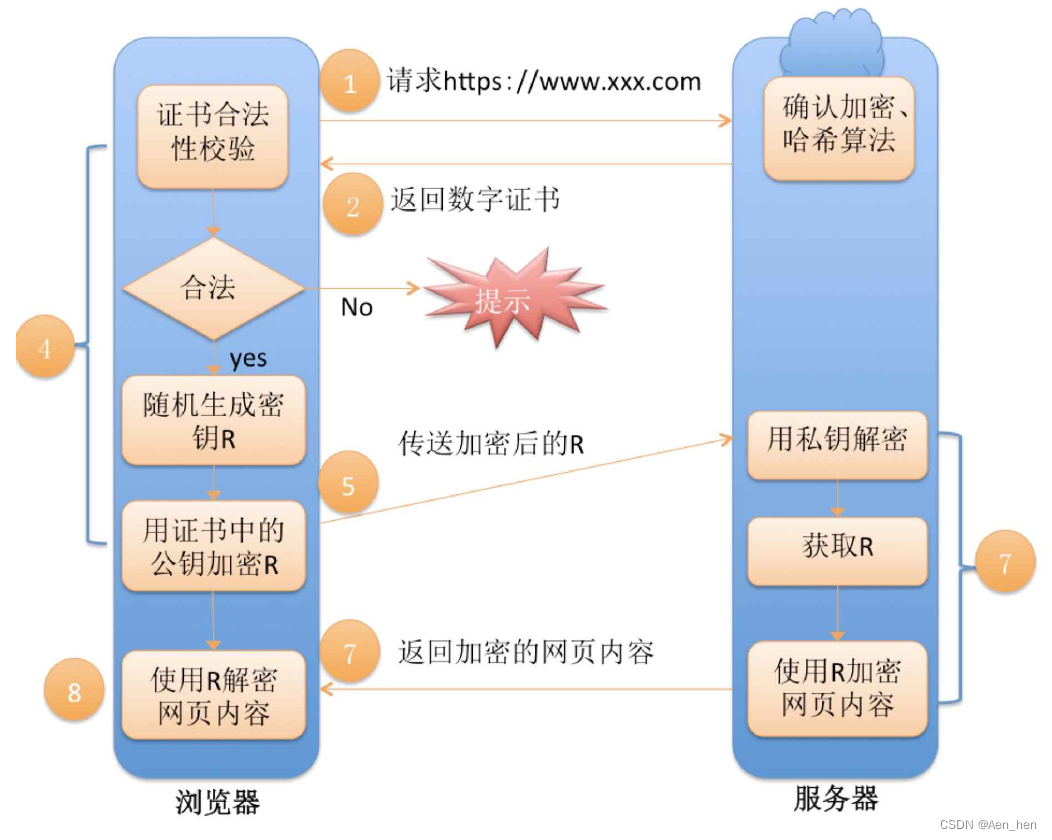
HTTPS
HTTPS是什么 HTTPS 属于应用层协议,其原理是通过SSL/TLS协议在HTTP和TCP之间插入一层安全机制。通过SSL/TLS握手过程,客户端和服务器协商出一个对称密钥,用于后续的数据加密和解密,从而保证数据的机密性和完整性。 为什么会需要…...

spring详解
spring是于2003年兴起的一款轻量级的,非侵入式的IOC和AOP的一站式的java开发框架,为简化企业级应用开发而生。 轻量级的:指的是spring核心功能的jar包不大。 非侵入式的:业务代码不需要继承或实现spring中任何的类或接口 IOC&…...

香港服务器备案会通过吗?
对于企业或个人来说,合规备案是网络运营的基本要求,也是保护自身权益的重要举措。以下内容围绕备案展开话题,希望为您解开疑惑。 香港服务器备案会通过吗? 目前,香港服务器无法备案,这是由于国内管理规定的限制…...

乐鑫推出 ESP ZeroCode 控制台
乐鑫科技 ESP ZeroCode 控制台是一个网页应用,用户只需点击鼠标,描述想要创建的产品类型、功能及其硬件配置,即可按照自身需求,快速生成符合 Matter 认证的固件,并在硬件上进行试用。试用过程中,如有任何不…...

从NLP到聊天机器人
一、说明 今天,当打电话给银行或其他公司时,听到电话另一端的机器人向你打招呼是很常见的:“你好,我是你的数字助理。请问你的问题。是的,机器人现在不仅可以说人类语言,还可以用人类语言与用户互动。这是由…...
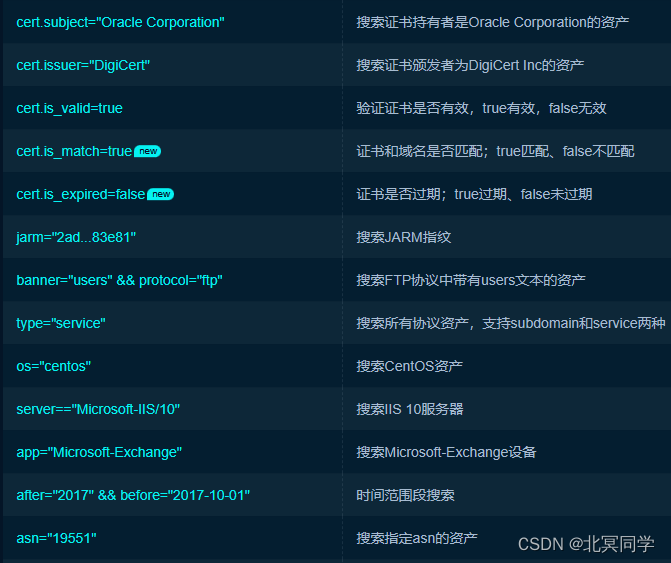
相关搜索引擎常用搜索语法(Google hacking语法和FOFA语法)
一:Google Hack语法 Google Hacking原指利用Google搜索引擎搜索信息来进行入侵的技术和行为,现指利用各种搜索引擎并使用一些高级的搜索语法来搜索信息。既利用搜索引擎强大的搜索功能,在在浩瀚的互联网中搜索到我们需要的信息。 ࿰…...

Mysql查询
第三章:select 语句 SELECT employees.employee_id,employees.department_id FROM employees WHERE employees.employee_id176; DESC departments;SELECT * FROM departments;第四章:运算符使用 SELECT employees.last_name,employees.salary FROM em…...

解决http下navigator.clipboard为undefined问题
开发环境下使用navigator.clipboard进行复制操作,打包部署到服务器上后,发现该功能显示为undefined;查相关资料后,发现clipboard只有在安全域名下才可以访问(https、localhost),在http域名下只能得到undefined…...

mysql之host is blocked问题
程序上线一段时间之后,更新程序总是遇到这个问题 每次都是重启几次程序,或者执行 flush hosts; 毕竟指标不治本,抽出时间决定分析一下问题,查阅了几篇博客。(感谢这几位大佬) https://blog.51cto.com/u_…...

每日一题:2337 移动片段得到字符串
给你两个字符串 start 和 target ,长度均为 n 。每个字符串 仅 由字符 L、R 和 _ 组成,其中: 字符 L 和 R 表示片段,其中片段 L 只有在其左侧直接存在一个 空位 时才能向 左 移动,而片段 R 只有在其右侧直接存在一个 …...

用PLC控制Labview自动运行
博图软件设置注意数据位正确下图为Labview读取CSV文件的位置测试数据如下图所示实现方法:在1分支内创建好条件,当PLC心跳为True那么就去跑True里面的流程(CSM框架)...

Pega Helm Charts:Kubernetes上自动化部署Pega平台的完整指南
1. 项目概述与核心价值如果你正在或即将在Kubernetes上部署Pega Platform,那么pegasystems/pega-helm-charts这个项目绝对是你绕不开的“官方说明书”和“自动化工具箱”。简单来说,这是Pega官方维护的一套Helm Chart,专门用于将Pega Platfor…...

YOLO26改进| downsample |网络深层多分支互补鲁棒下采样模块
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 本文给大家带来的教程是将YOLO26的下采样替换为DRFD来提取特征。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修…...

3步精通UE4SS游戏Mod开发:从注入到实战完全指南
3步精通UE4SS游戏Mod开发:从注入到实战完全指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE…...

《凰标》:写给所有被资本轻视的创作者@凤凰标志
——写给所有不被看见的创作者没有流量即是无用, 没有热度即是不值, 没有商业变现能力即是小众累赘。在资本主导的文娱评价体系里,这条偏见像一道隐形天花板,横亘在每一个草根创作者的头顶。一、被算法淹没的匠心 他们怀揣赤诚热爱…...

MGRE实验报告
一.实验概述实验名称:MGRE实验实验目的:掌握 PPP 协议的 PAP/CHAP 认证与 HDLC 封装配置,理解不同广域网链路协议的工作机制与认证流程。实现 MGRE 环境(R1 为 Hub)与 GRE 环境的部署,理解点到多点 VPN 与点…...

航拍UAV电力电缆巡检检测数据集_数据集第10027期
航拍UAV电力电缆巡检检测数据集_数据集第10027期 项目简介 面向无人机电力巡检场景的开源目标检测数据集,聚焦电力电缆识别任务,可用于电力线检测、植被与电力线安全距离监测等场景,助力电力巡检智能化。 数据集核心信息 数据规模:…...

图像识别与目标检测:从概念到实战的全面解析
1. 项目概述:从“认脸”到“找茬”的认知跃迁在计算机视觉这个行当里干了十几年,我见过太多刚入行的朋友,甚至是一些有经验的开发者,对“图像识别”和“目标检测”这两个词傻傻分不清楚。经常有人拿着一个“识别猫狗”的需求过来&…...

正点原子 STM32MP257 同构多核架构下的 ADC 电压采集与处理应用开发实战
在嵌入式系统中,ADC模拟电压的读取是常见的需求。如何高效、并发、且可控地完成数据采集与处理?本篇文章通过双线程分别绑定在 Linux 系统的不同 CPU 核心上,采集 /sys/bus/iio 接口的 ADC 原始值与缩放系数 scale,并在另一个核上…...

Network-AI:解决多智能体协作竞态与状态冲突的协调层
1. 项目概述:Network-AI,一个解决多智能体“内讧”的协调器如果你正在用LangChain、CrewAI或者AutoGen构建AI智能体应用,大概率遇到过这样的场景:你部署了两个智能体,一个负责分析数据,一个负责生成报告。它…...