记录几个Hudi Flink使用问题及解决方法
前言
如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下
版本
- Flink 1.15.4
- Hudi 0.13.0
流写
流写Hudi,必须要开启Checkpoint,这个我在之前的文章:Flink SQL Checkpoint 学习总结提到过。
如果不设置Checkpoint,不会生成commit,感觉像是卡住一样,具体表现为只生成.commit.requested和.inflight,然后不写文件、不生成.commit也不报错,对于新手来说很费劲,很难找到解决方法。
索引
hudi-flink 仅支持两种索引:FLINK_STATE和BUCKET,默认FLINK_STATE。
最开始使用hudi是用的spark,hudi-spark支持
BLOOM索引,hudi java client也支持BLOOM索引,所以认为hudi-flink也支持BLOOM索引,但其实不支持,而且官网并没有相关的文档说明,可以从下面这段代码中看出来
Pipelines.hoodieStreamWrite
public static DataStream<Object> hoodieStreamWrite(Configuration conf, DataStream<HoodieRecord> dataStream) {// 如果是`BUCKET`索引if (OptionsResolver.isBucketIndexType(conf)) {WriteOperatorFactory<HoodieRecord> operatorFactory = BucketStreamWriteOperator.getFactory(conf);int bucketNum = conf.getInteger(FlinkOptions.BUCKET_INDEX_NUM_BUCKETS);String indexKeyFields = conf.getString(FlinkOptions.INDEX_KEY_FIELD);BucketIndexPartitioner<HoodieKey> partitioner = new BucketIndexPartitioner<>(bucketNum, indexKeyFields);return dataStream.partitionCustom(partitioner, HoodieRecord::getKey).transform(opName("bucket_write", conf), TypeInformation.of(Object.class), operatorFactory).uid(opUID("bucket_write", conf)).setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS));} else {// 否则按`FLINK_STATE`索引的逻辑WriteOperatorFactory<HoodieRecord> operatorFactory = StreamWriteOperator.getFactory(conf);return dataStream// Key-by record key, to avoid multiple subtasks write to a bucket at the same time.keyBy(HoodieRecord::getRecordKey).transform("bucket_assigner",TypeInformation.of(HoodieRecord.class),new KeyedProcessOperator<>(new BucketAssignFunction<>(conf))).uid(opUID("bucket_assigner", conf)).setParallelism(conf.getInteger(FlinkOptions.BUCKET_ASSIGN_TASKS))// shuffle by fileId(bucket id).keyBy(record -> record.getCurrentLocation().getFileId()).transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFactory).uid(opUID("stream_write", conf)).setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS));}}
FLINK_STATE 重复问题
如果使用默认的FLINK_STATE索引,在upsert时可能会有重复问题。(之前使用BLOOM索引时不会有这个问题)
问题复现
先写一部分数据作为历史数据到Hudi表,然后再写相同的数据到这个表,最后count表发现数据量变多,也就是有重复数据。
主要参数:
set parallelism.default=12;
set taskmanager.numberOfTaskSlots=2;'write.operation'='upsert',
'write.tasks'='11',
'table.type'='COPY_ON_WRITE',
场景为kafka2hudi,kafka数据量200w,没有重复,设置并发的主要目的是为了将数据打散分布在不同的文件里,这样更容易复现问题。(因为如果只有一个历史文件时,很难复现)
第一次任务跑完表数据量为200w,第二次跑完表数据量大于200w,证明数据重复。
重复原因
index state:保存在state中的主键和文件ID的对应关系
重复的原因为FLINK_STATE将主键和文件ID的对应关系保存在state中,当新启动一个任务时,index state需要重新建立,而默认情况下不会包含历史文件的index state,只会建立新数据的index state,所以对于没有历史文件的新表是不会有重复问题的。(对于有历史文件的表,如果从checkpoint恢复也不会有重复问题,因为从checkpoint恢复时,也恢复了之前历史文件的index state)
解决方法
通过参数index.bootstrap.enabled解决,默认为false,当为true时,写hudi任务启动时会先引导(加载)历史文件的index state
'index.bootstrap.enabled'='true'
除了重复问题,
FLINK_STATE因为将index保存在state中,所以随着数据量的增加,state越来越大。这样对于数据量特别大的表,对内存的要求也会很高,所以会遇到内存不足OOM的问题。 所以建议对于大表,还是选择使用BUCKET索引。
增量数据,‘index.bootstrap.enabled’='false’时的checkpoint记录,checkpoint大小开始很小,然后逐渐增加

增量数据,‘index.bootstrap.enabled’='true’时的checkpoint记录,checkpoint大小开始和结束差不多大

BUCKET INDEX
BUCKET索引需要根据表数据量大小设定好桶数(hoodie.bucket.index.num.buckets),但是默认情况下不能动态调整bucket数量。
另外可以通过参数hoodie.index.bucket.engine将其值设为CONSISTENT_HASHING,通过一致性哈希实现动态调整bucket数量,但是仅支持MOR表,我还没有试过这个功能,大家可以通过官网:https://hudi.apache.org/docs/configurations/了解相关参数自行测试。
hoodie.index.bucket.engine | SIMPLE (Optional) | org.apache.hudi.index.HoodieIndex$BucketIndexEngineType: Determines the type of bucketing or hashing to use when
hoodie.index.typeis set toBUCKET. SIMPLE(default): Uses a fixed number of buckets for file groups which cannot shrink or expand. This works for both COW and MOR tables. CONSISTENT_HASHING: Supports dynamic number of buckets with bucket resizing to properly size each bucket. This solves potential data skew problem where one bucket can be significantly larger than others in SIMPLE engine type. This only works with MOR tables.Config Param: BUCKET_INDEX_ENGINE_TYPESince Version: 0.11.0
BUCKET索引主要参数:
'index.type' = 'BUCKET', -- flink只支持两种index,默认FLINK_STATE index,FLINK_STATE index对于数据量比较大的情况会因为tm内存不足导致GC OOM
'hoodie.bucket.index.num.buckets' = '16', -- 桶数
注意,
index.type是flink客户端独有的,和公共的不一样(使用公共参数不生效),没有前缀hoodie.,而桶数配置项是hudi公共参数,对于flink客户端哪些用公共参数哪些用flink独有的参数,官方文档并没有提供,需要自己在类org.apache.hudi.configuration.FlinkOptions查看,该类中的参数为flink重写的独有参数,没有的话则需要使用公共参数
insert转upsert问题
对于BUCKET如果先insert一部分历史数据,再upsert增量数据时,默认参数配置会抛出如下异常:
(复现此问题只需要批写一条数据即可)
Caused by: java.lang.NumberFormatException: For input string: "4ff32a41"at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)at java.lang.Integer.parseInt(Integer.java:580)at java.lang.Integer.parseInt(Integer.java:615)at org.apache.hudi.index.bucket.BucketIdentifier.bucketIdFromFileId(BucketIdentifier.java:79)at org.apache.hudi.sink.bucket.BucketStreamWriteFunction.lambda$bootstrapIndexIfNeed$1(BucketStreamWriteFunction.java:162)at java.util.stream.ForEachOps$ForEachOp$OfRef.accept(ForEachOps.java:184)at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)at org.apache.hudi.sink.bucket.BucketStreamWriteFunction.bootstrapIndexIfNeed(BucketStreamWriteFunction.java:160)at org.apache.hudi.sink.bucket.BucketStreamWriteFunction.processElement(BucketStreamWriteFunction.java:112)at org.apache.flink.streaming.api.operators.ProcessOperator.processElement(ProcessOperator.java:66)at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)
原因是:默认参数下,insert时没有按照bucket索引的逻辑写文件,而upsert是按照bucket逻辑写文件的,bucket索引写的文件名前缀都带有桶号,不是bucket索引写的文件名没有桶号,所以upsert时会尝试解析insert写的历史文件的桶号,导致解析失败。
非bucket索引逻辑写的文件
/tmp/cdc/hudi_sink_insert/4ff32a41-4232-4f47-855a-6364eb1d6ce8-0_0-1-0_20230820210751280.parquet
bucket索引逻辑写的文件
/tmp/cdc/hudi_sink_insert/00000000-82f4-48a5-85e9-2c4bb9679360_0-1-0_20230820211542006.parquet
解决方法
对于实际应用场景是有这种先insert在upsert的需求的,解决方法就是尝试通过配置参数使insert也按照bucket索引的逻辑写数据
主要参数:'write.insert.cluster'='true'
相关参数:
'write.operation'='insert',
'table.type'='COPY_ON_WRITE',
'write.insert.cluster'='true',
'index.type' = 'BUCKET',
我是通过阅读源码发现这个参数可以使insert按照
bucket逻辑写数据的
对应的源码在HoodieTableSink.getSinkRuntimeProvider,我在上篇文章Hudi Flink SQL源码调试学习(一)中分析了写hudi时是如何调用到这个方法的,感兴趣得可以看一下。
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {return (DataStreamSinkProviderAdapter) dataStream -> {// setup configurationlong ckpTimeout = dataStream.getExecutionEnvironment().getCheckpointConfig().getCheckpointTimeout();conf.setLong(FlinkOptions.WRITE_COMMIT_ACK_TIMEOUT, ckpTimeout);// set up default parallelismOptionsInference.setupSinkTasks(conf, dataStream.getExecutionConfig().getParallelism());RowType rowType = (RowType) schema.toSinkRowDataType().notNull().getLogicalType();// bulk_insert modefinal String writeOperation = this.conf.get(FlinkOptions.OPERATION);if (WriteOperationType.fromValue(writeOperation) == WriteOperationType.BULK_INSERT) {return Pipelines.bulkInsert(conf, rowType, dataStream);}// Append modeif (OptionsResolver.isAppendMode(conf)) {DataStream<Object> pipeline = Pipelines.append(conf, rowType, dataStream, context.isBounded());if (OptionsResolver.needsAsyncClustering(conf)) {return Pipelines.cluster(conf, rowType, pipeline);} else {return Pipelines.dummySink(pipeline);}}DataStream<Object> pipeline;// bootstrapfinal DataStream<HoodieRecord> hoodieRecordDataStream =Pipelines.bootstrap(conf, rowType, dataStream, context.isBounded(), overwrite);// write pipelinepipeline = Pipelines.hoodieStreamWrite(conf, hoodieRecordDataStream);// compactionif (OptionsResolver.needsAsyncCompaction(conf)) {// use synchronous compaction for bounded source.if (context.isBounded()) {conf.setBoolean(FlinkOptions.COMPACTION_ASYNC_ENABLED, false);}return Pipelines.compact(conf, pipeline);} else {return Pipelines.clean(conf, pipeline);}};}
我们在上面的代码中可以发现,当是append模式时会走单独的写逻辑,不是append模式时,才会走下面的Pipelines.hoodieStreamWrite,那么就需要看一下append模式的判断逻辑
OptionsResolver.isAppendMode(conf)
public static boolean isAppendMode(Configuration conf) {// 1. inline clustering is supported for COW table;// 2. async clustering is supported for both COW and MOR tablereturn isCowTable(conf) && isInsertOperation(conf) && !conf.getBoolean(FlinkOptions.INSERT_CLUSTER)|| needsScheduleClustering(conf);}
对于cow表insert时,默认参数的情况needsScheduleClustering(conf)返回false,而!conf.getBoolean(FlinkOptions.INSERT_CLUSTER)返回true,所以只需要让!conf.getBoolean(FlinkOptions.INSERT_CLUSTER)返回false就可以跳过append模式的逻辑了,也就是上面的 'write.insert.cluster'='true'。(每个版本的源码不太一样,所以对于其他版本,可能这个参数并不能解决该问题)
Hive查询异常
记录一个Hive SQL查询Hudi表的异常
异常信息
Caused by: java.lang.ClassCastException: org.apache.hadoop.io.ArrayWritable cannot be cast to org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatchat org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.deliverVectorizedRowBatch(VectorMapOperator.java:803)at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:845)... 20 morejava.lang.ClassCastException: org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch cannot be cast to org.apache.hadoop.io.ArrayWritablejava.lang.ClassCastException: org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch cannot be cast to org.apache.hadoop.io.ArrayWritable
异常复现
找一个hudi mor表的rt表,执行count语句(有人反馈聚合函数也会出现此异常)
解决方法
set hive.vectorized.execution.enabled=false; (我验证的这一个参数就可以了)
set hive.vectorized.execution.reduce.enabled=false;(不确定此参数是否必须)
相关阅读
- Flink SQL Checkpoint 学习总结
- Hudi Flink SQL源码调试学习(一)
- Flink SQL操作Hudi并同步Hive使用总结
相关文章:
记录几个Hudi Flink使用问题及解决方法
前言 如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下 版本 Flink 1.15.4Hudi 0.13.0 流写 流写…...
Go:测试框架GoConvey 简介
快速开始 GoConvey是一个完全兼容官方Go Test的测试框架,一般来说这种第三方库都比官方的功能要强大、更加易于使用、开发效率更高,闲话少说,先看一个example: package utils import (. "github.com/smartystreets/goconvey…...
JavaWeb-特殊文件(propertis与XML)
目录 Properties文件 一.properties介绍 二.properties使用 三.解决中文乱码问题 XML文件 一.XML介绍 二.XML文件的语法规则 三.XML的使用 Properties文件 一.properties介绍 1.什么是properties文件 Properties文件是一种常用的配置文件格式,用于存储键值…...
ffmpeg合并mp4视频文件
下载ffmpeg Download FFmpeg 2配置环境 右键此电脑-》属性-》高级系统设置 环境变量-》path 解压上面ffmpeg压缩包,找到bin目录,复制完整路径,添加到path环境变量中 测试ffmpeg ffmpeg合并MP4文件 创建一个文本文件,例如inpu…...

ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks使用分析
ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks使用分析 1 ATF的下载链接2 ATF BL1/BL2 ufs_read_blocks/ufs_write_blocks处理流程2.1 ATF BL1/BL2 ufs_read_blocks2.2 ATF BL1/BL2 ufs_write_blocks 3 UFS System Model4 ufs_read_blocks/ufs_write_blocks详细分析4.1 ufs_re…...
Elasticsearch(十二)搜索---搜索匹配功能③--布尔查询及filter查询原理
一、前言 本节主要学习ES匹配查询中的布尔查询以及布尔查询中比较特殊的filter查询及其原理。 复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。 布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些…...
解决Windows下的docker desktop无法启动问题
以管理员权限运行cmd 报错: docker: error during connect: Post http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.40/containers/create: open //./pipe/docker_engine: The system cannot find the file specified. In the default daemon configuration on Windows,…...
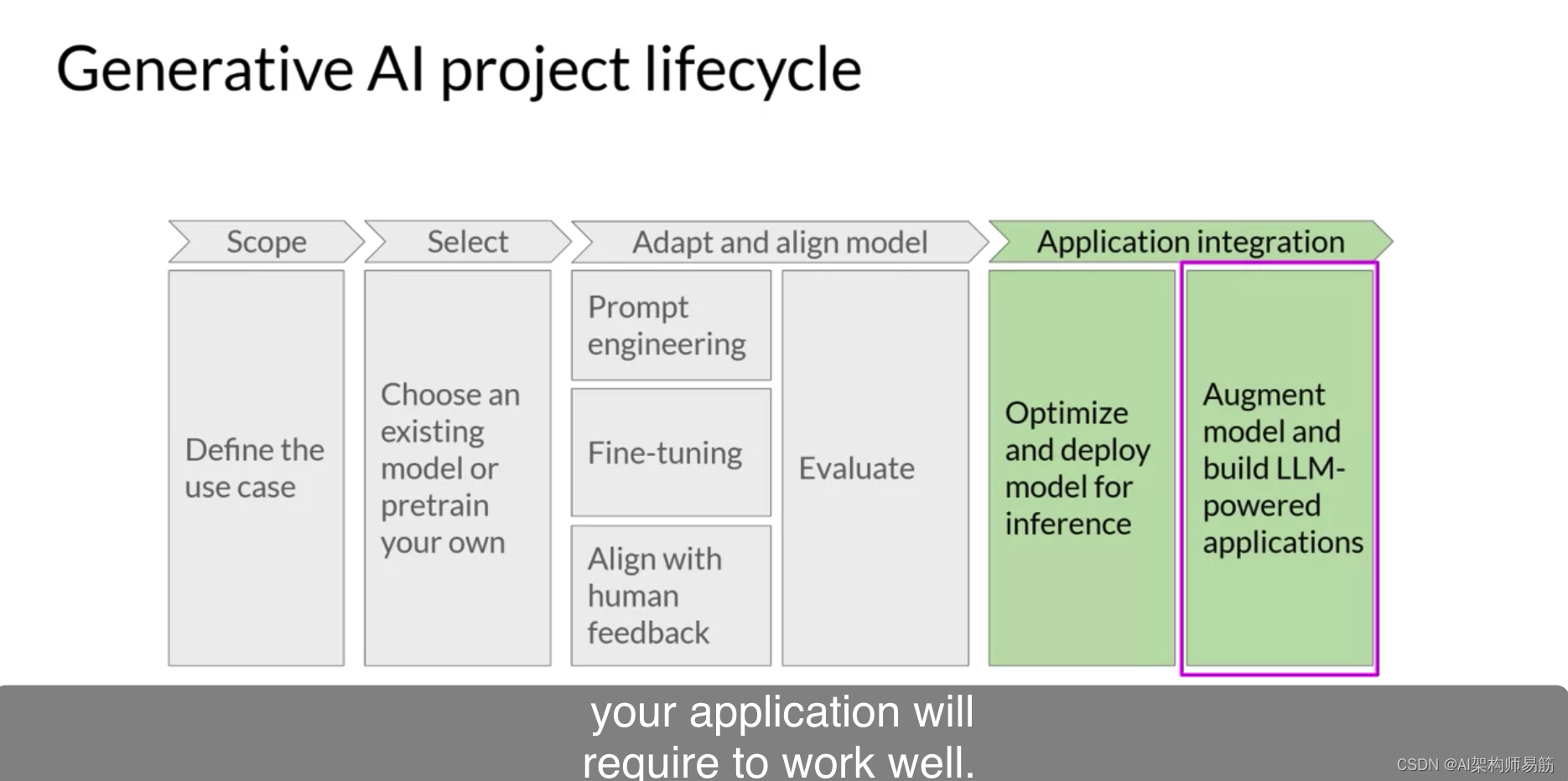
LLM生成式 AI 项目生命周期Generative AI project lifecycle
在本课程的其余部分中,您将学习开发和部署LLM驱动应用所需的技巧。在这个视频中,您将了解一个能帮助您完成此工作的生成式AI项目生命周期。此框架列出了从构思到启动项目所需的任务。到课程结束时,您应该对您需要做的重要决策、可能遇到的困难…...

java高并发系列 - 第13天:JUC中的Condition对象
java高并发系列 - 第13天:JUC中的Condition对象 java高并发系列第13篇文章 本文内容 synchronized中实现线程等待和唤醒Condition简介及常用方法介绍及相关示例使用Condition实现生产者消费者使用Condition实现同步阻塞队列Object对象中的wait(),notify()方法,用于线程等待…...

【TTY子系统】printf与printk深入驱动解析
tty子系统解析 tty子系统是一个庞大且复杂,也是内核维护者所头大的子系统。 At a first glance, the TTY layer wouldn’t seem like it should be all that challenging. It is, after all, just a simple char device which is charged with transferring byte-o…...

无涯教程-PHP - 全局变量函数
全局变量 与局部变量相反,可以在程序的任何部分访问全局变量。通过将关键字 GLOBAL 放置在应被识别为全局变量的前面,可以很方便地实现这一目标。 <?php$somevar15;function addit() {GLOBAL $somevar;$somevar;print "Somevar is $somevar";}addit(); ?> …...
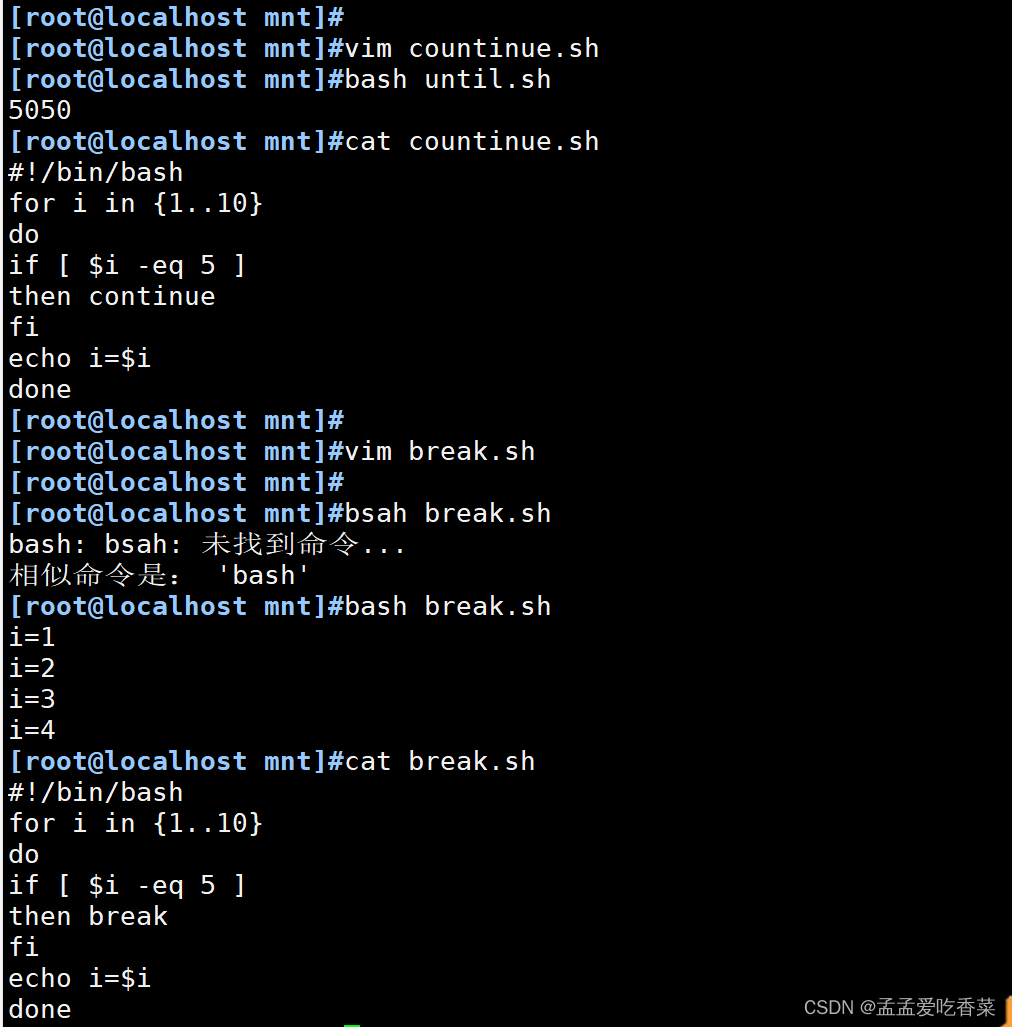
shell脚本之循环语句
循环语句 循环含义 将某代码段重复运行多次,通常有进入循环的条件和退出循环的条件 for循环语句 一般知道循环次数使用for循环 第一类 格式1: for名称 in 取值次数;do;done; 格式2: for 名称 in {取值列表} do done# 打印20次 for i i…...

派森 #P122. 峰值查找
描述 给定一个长度为n的列表nums,请你找到峰值并返回其索引。数组可能包含多个峰值,在这种情况下,返回任何一个所在位置即可。 (1)峰值元素是指其值严格大于左右相邻值的元素。严格大于即不能有等于; &…...

基础网络详解4--HTTP CookieSession 思考
一、cookie技术思考 一台多用户浏览器发起了三笔请求,将某款产品放入购物车中,A一次,选择了篮球;B两次,第一次选了足球,第二次选了钢笔。如何确认选择篮球、足球、钢笔的请求属于谁呢?如果不确认…...

14. 利用Canvas自制时钟组件
1. 说明 在自定义时钟组件时,使用到的基本控件主要是Canvas,在绘制相关元素时有两种方式:一种时在同一个canvas中绘制所有的部件元素,这样需要不断的对画笔和画布的属性进行保存和恢复,容易混乱;另一种就是…...
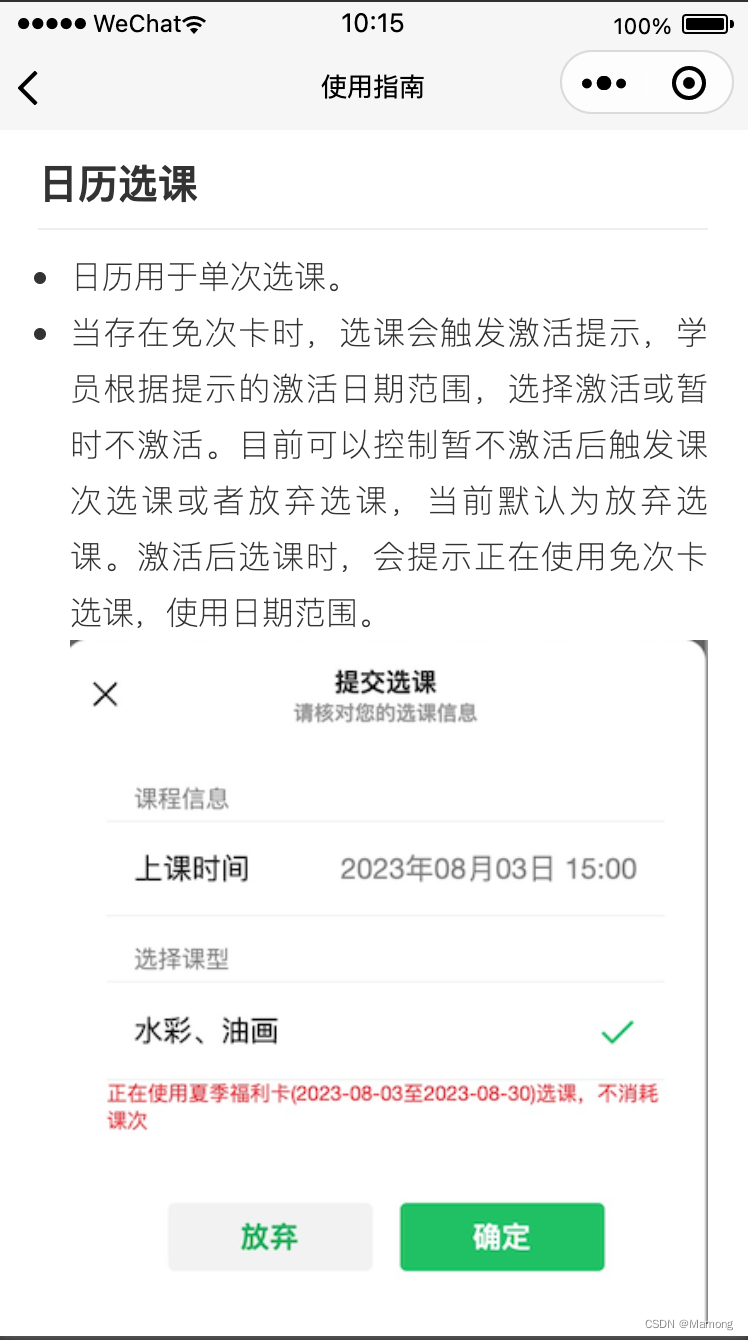
微信小程序使用云存储和Markdown开发页面
最近想在一个小程序里加入一个使用指南的页面,考虑到数据存储和减少页面的开发工作量,决定尝试在云存储里上传Markdown文件,微信小程序端负责解析和渲染。小程序端使用到一个库Towxml。 Towxml Towxml是一个可将HTML、Markdown转为微信小程…...
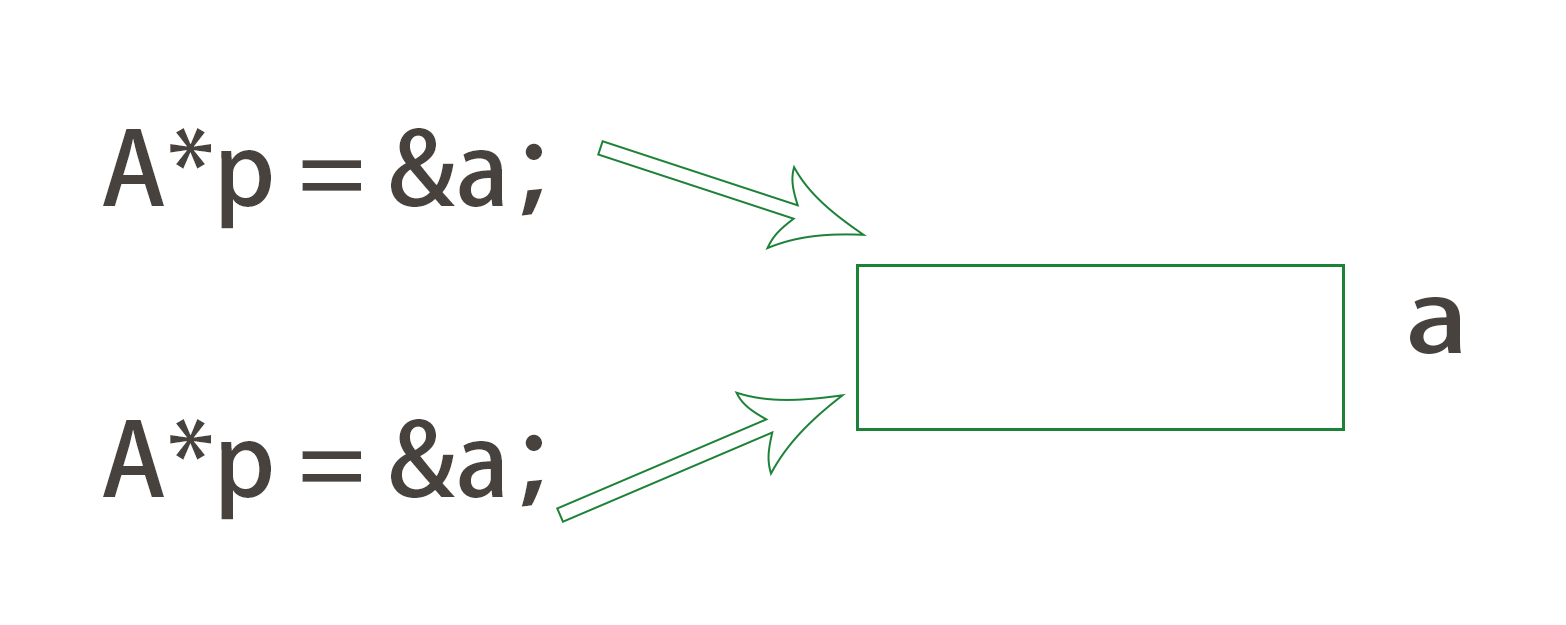
【C++】运算符重载 | 赋值运算符重载
Ⅰ. 运算符重载 引入 ❓什么叫运算符重载? 就是:运用函数,将现有的运算符重新定义,使其能满足各种自定义类型的运算。 回想一下,我们以前运算的对象是不是都是int、char这种内置类型? 那我们自定义的“…...
Python学习 -- 类对象从创建到常用函数
在Python编程中,类是一种强大的工具,用于创建具有共同属性和行为的对象。本篇博客将详细介绍Python中类和对象的创建,类的属性和方法,以及一些常用的类函数,通过丰富的代码例子来帮助读者深入理解。 一、类和对象的创…...
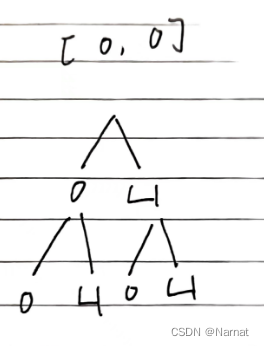
数组分割(2023省蓝桥杯)n种讨论 JAVA
目录 1、题目描述:2、前言:3、动态规划(bug):3、递归 剪枝(超时):4、数学(正解): 1、题目描述: 小蓝有一个长度为 N 的数组 A [A0, A1,…, AN−…...
很好的启用window10专业版系统自带的远程桌面
启用window10专业版系统自带的远程桌面 文章目录 启用window10专业版系统自带的远程桌面前言1.找到远程桌面的开关2. 找到“应用”项目3. 打开需要远程操作的电脑远程桌面功能 总结 前言 Windows操作系统作为应用最广泛的个人电脑操作系统,在我们身边几乎随处可见。…...

Turbo模式突然失效?紧急修复指南:5分钟定位API网关超时、区域节点降级、token配额劫持三大隐性故障
更多请点击: https://intelliparadigm.com 第一章:Turbo模式突然失效?紧急修复指南:5分钟定位API网关超时、区域节点降级、token配额劫持三大隐性故障 Turbo模式并非原子性开关,其状态依赖于网关层、区域服务健康度与…...

如何在Windows上安装安卓应用?APK安装器完整指南
如何在Windows上安装安卓应用?APK安装器完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想要在Windows电脑上直接运行安卓应用,却不想安…...

高性能鼠标跟随动画实现:从基础原理到mouse-follower库实战
1. 项目概述:一个丝滑的鼠标跟随器最近在重构一个个人作品集网站,想在交互细节上增加一些趣味性和现代感。一个常见的想法是:让鼠标光标不再是那个单调的箭头或小手,而是变成一个自定义的、带有动效的图形,并且这个图形…...
如何用BallonsTranslator在15分钟内完成专业级漫画翻译?终极免费解决方案
如何用BallonsTranslator在15分钟内完成专业级漫画翻译?终极免费解决方案 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning …...

从开发工程师到产品经理,转型成功的5个关键因素
在软件行业的生态系统中,开发工程师与产品经理如同两条紧密交织的脉络,共同支撑着产品从概念到落地的全生命周期。对于软件测试从业者而言,观察这两种角色的转型路径,不仅能为自身职业发展提供多元视角,更能深刻理解产…...

ggshield API集成指南:如何将秘密检测融入现有系统
ggshield API集成指南:如何将秘密检测融入现有系统 【免费下载链接】ggshield Detect and validate 500 types of hardcoded secrets with advanced checks. Use it as a pre-commit hook, GitHub Action, or CLI for proactive secret detection and security. 项…...

ARM调试器AXD核心功能与定时刷新机制详解
1. ARM调试器AXD核心功能解析ARM调试器AXD作为嵌入式开发领域的专业调试工具,其核心价值在于为开发者提供对ARM架构处理器(如Cortex-M系列)的深度调试能力。不同于通用调试工具,AXD针对ARM处理器特性进行了专门优化,特…...

Luma 视频生成 API 集成指南
随着人工智能的广泛应用,AI 程序逐渐在各个领域流行开来。从最初的写作、医疗教育,到如今的视频生成,AI 正在渗透人们工作和生活的方方面面。 Luma 是一个专业的高质量视频生成平台,用户只需上传素材,便可以根据不同的…...

医学影像三维可视化的开源利器:MRIcroGL如何解决临床科研痛点?
医学影像三维可视化的开源利器:MRIcroGL如何解决临床科研痛点? 【免费下载链接】MRIcroGL v1.2 GLSL volume rendering. Able to view NIfTI, DICOM, MGH, MHD, NRRD, AFNI format images. 项目地址: https://gitcode.com/gh_mirrors/mr/MRIcroGL …...

文档播客化最后窗口期!NotebookLM v2.3新增音频锚点功能,不升级将永久丢失时间戳同步能力
更多请点击: https://intelliparadigm.com 第一章:文档播客化的时代必然性与NotebookLM v2.3战略定位 当知识消费从线性阅读转向多模态沉浸,文档不再静默——它开始“说话”。NotebookLM v2.3 的发布并非功能迭代,而是一次范式迁…...