1. HBase中文学习手册之揭开Hbase的神秘面纱
揭开Hbase的神秘面纱
- 1.1 欢迎使用 Apache Hbase
- 1.1.1 什么是 Hbase?
- 1.1.2 Hbase的前世今生
- 1.1.3 HBase的技术选型?
- 1.1.3.1 不适合使用 HBase的场景
- 1.1.3.2 适合使用 HBase的场景
- 1.1.4 HBase的特点
- 1.1.4.1 HBase的优点
- 1.1.4.2 HBase的缺点
- 1.1.5 HBase设计架构
- 1.2 附录
- 1.2.1功能模块与职责详情
- 1.2.2 HBase中的基本概念
- 1.2.3 本文中涉及的思维导图原件下载
1.1 欢迎使用 Apache Hbase
1.1.1 什么是 Hbase?
- Apache HBase 是 Hadoop 数据库,一种分布式,可扩展的大数据存储。
1.1.2 Hbase的前世今生
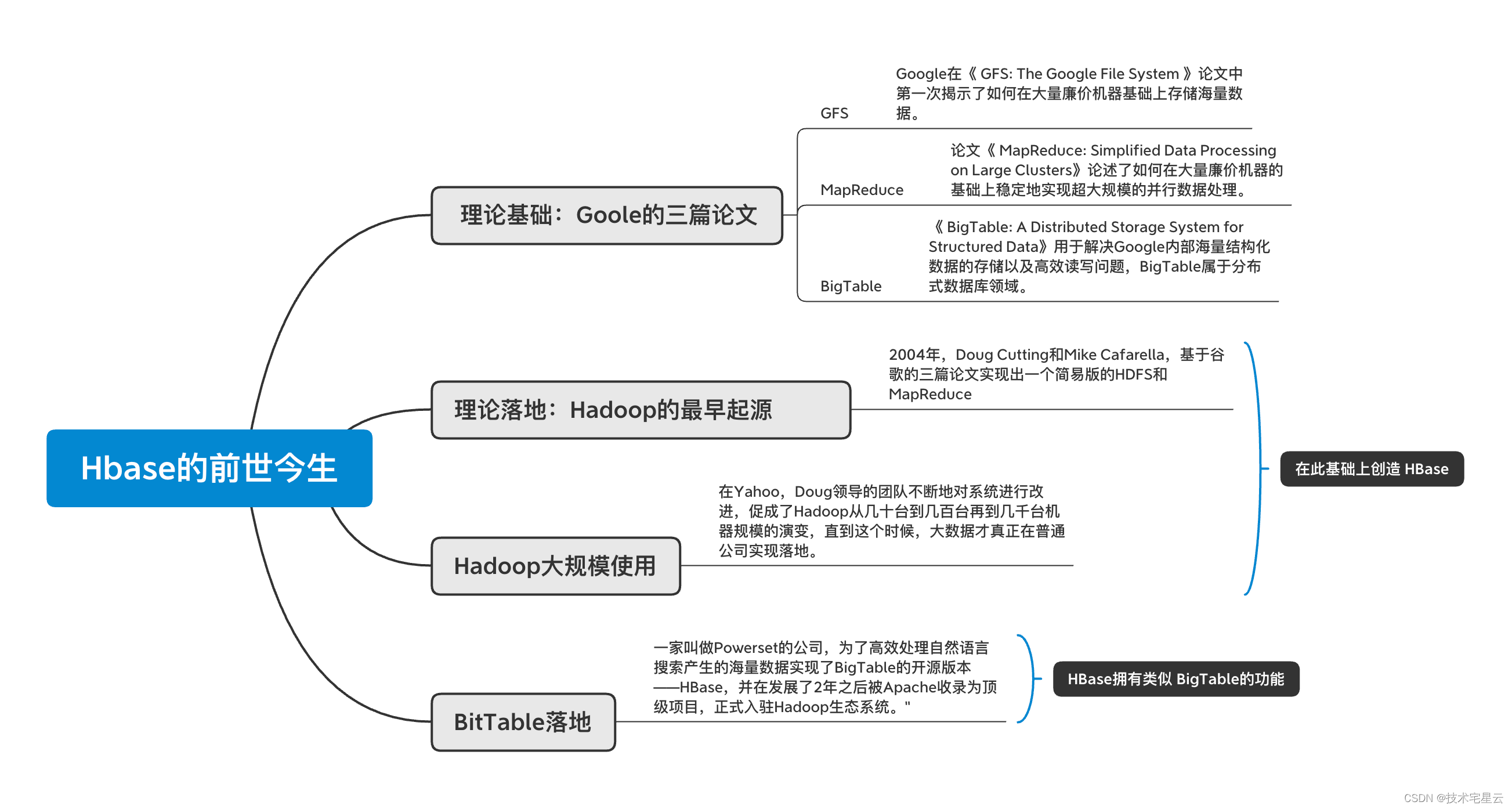
- Apache HBase 是一个开源、分布式、版本化、非关系数据库, 模仿了 Google 的Bigtable: Chang等人的结构化数据分布式存储系统。
- Apache HBase 在 Hadoop 和 HDFS 之上提供类似 Bigtable 的功能,正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样,
Google在当年发布了风靡一时的“三篇论文”——GFS、MapReduce、BigTable。
- 《 GFS: The Google File System 》
- Google在GFS该论文中第一次揭示了如何在大量廉价机器基础上存储海量数据。
- 《 MapReduce: Simplified Data Processing on Large Clusters》
- 论文论述了如何在大量廉价机器的基础上稳定地实现超大规模的并行数据处理。
- 《 BigTable: A Distributed Storage System for Structured Data》
- 用于解决Google内部海量结构化数据的存储以及高效读写问题,BigTable属于分布式数据库领域。
Google的三篇论文论证了在大量廉价机器上存储、处理海量数据(结构化数据、非结构化数据)是可行的,然而并没有给出开源方案。
2004年,Doug Cutting和Mike Cafarella在为他们的搜索引擎爬虫(Nutch)实现分布式架构的时候看到了Google的GFS论文以及MapReduce论文。
他们在之后的几个月里按照论文实现出一个简易版的HDFS和MapReduce,这也就是Hadoop的最早起源。
最初这个简易系统确实可以稳定地运行在几十台机器上,但是没有经过大规模使用的系统谈不上完美。
所幸他们收到了Yahoo的橄榄枝。
在Yahoo,Doug领导的团队不断地对系统进行改进,促成了Hadoop从几十台到几百台再到几千台机器规模的演变,直到这个时候,大数据才真正在普通公司实现落地。
一家叫做Powerset的公司,为了高效处理自然语言搜索产生的海量数据实现了BigTable的开源版本——HBase,并在发展了2年之后被Apache收录为顶级项目,正式入驻Hadoop生态系统。”
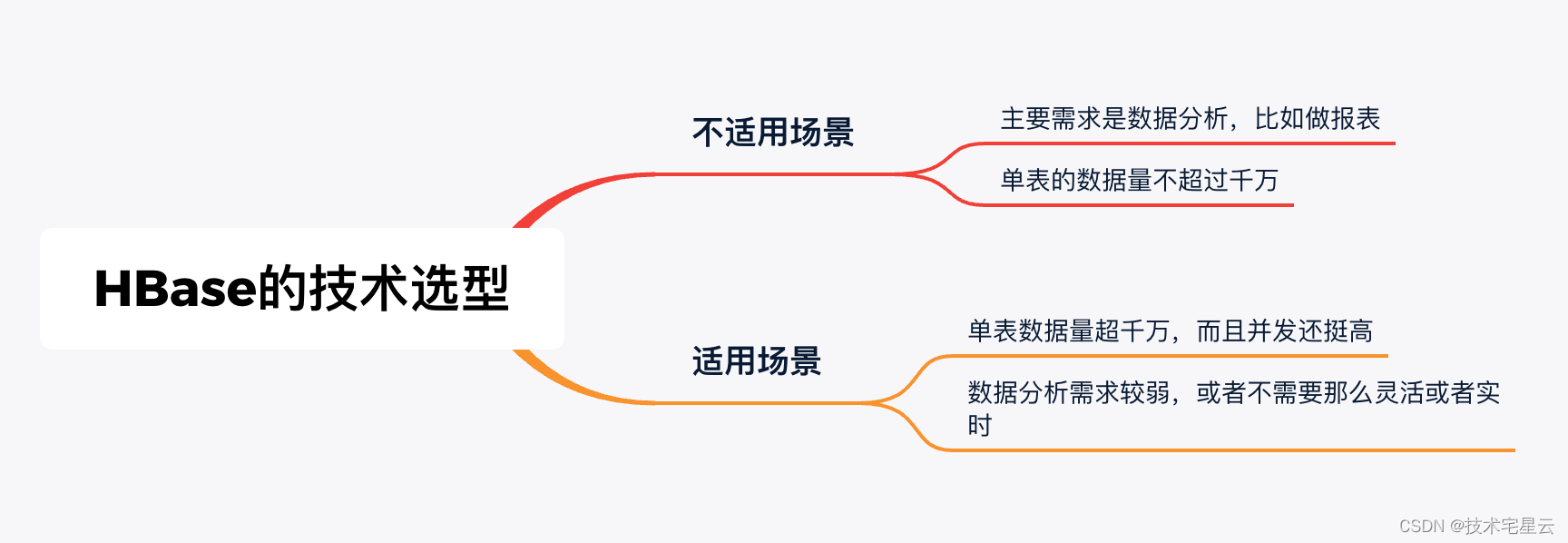
1.1.3 HBase的技术选型?
那么当企业有什么业务场景下的时候,可以尝试使用 Apache Hbase呢?
- 当我们需要对大数据进行随机,实时读/写访问时,可以使用 Apache Hbase.
- 该项目的目标是在商用硬件集群之上托管非常大的表(数十亿行 X 数百万列)。
- Apache HBase 是一个开源、分布式、版本化、非关系数据库,模仿了 Google 的Bigtable: Chang 等人的结构化数据分布式存储系统。
- 正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样,Apache HBase 在 Hadoop 和 HDFS 之上提供类似 Bigtable 的功能。
1.1.3.1 不适合使用 HBase的场景
当你的情况大体上符合以下任意一种的时候:
- 主要需求是数据分析,比如做报表。
- 单表数据量不超过千万。
请不要使用HBase,使用MySQL或者Oracle之类的产品可以让你的脑细胞免受折磨。
1.1.3.2 适合使用 HBase的场景
当你的情况是:
- 单表数据量超千万,而且并发还挺高。
- 数据分析需求较弱,或者不需要那么灵活或者实时。请使用HBase,它不会让你失望的。
请使用HBase,它不会让你失望的。
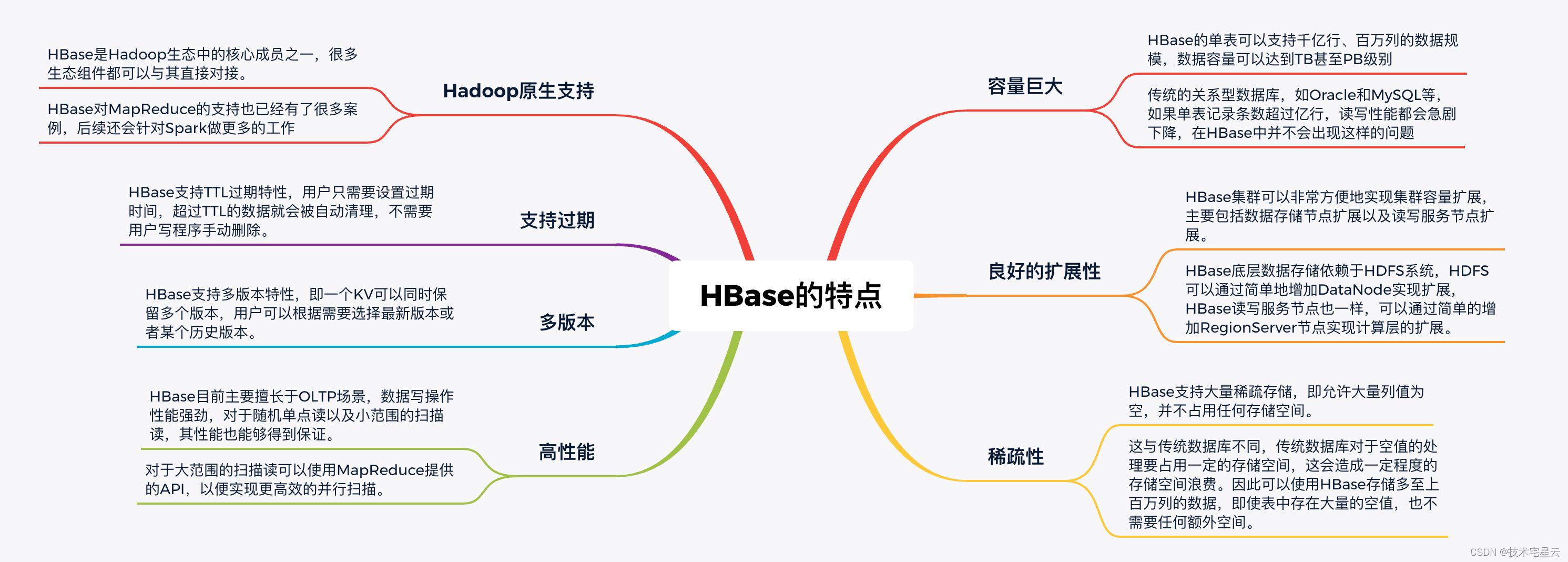
1.1.4 HBase的特点
- 线性和模块化的可扩展性。
- 读写严格一致。
- 自动且可配置的表分片
- RegionServer 之间的自动故障转移支持。
- 用于使用 Apache HBase 表支持 Hadoop MapReduce 作业的便捷基类。
- 易于使用 Java API 进行客户端访问。
- 用于实时查询的块缓存和布隆过滤器。
- 通过服务器端过滤器下推查询谓词
- Thrift 网关和支持 XML、Protobuf 和二进制数据编码选项的 REST-ful Web 服务
- 基于 jruby (JIRB) 的可扩展 shell
- 支持通过 Hadoop 指标子系统将指标导出到文件或 Ganglia; 或通过 JMX
1.1.4.1 HBase的优点
与其他数据库相比,HBase在系统设计以及实际实践中有很多独特的优点。
- 容量巨大:HBase的单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至PB级别。传统的关系型数据库,如Oracle和MySQL等,如果单表记录条数超过亿行,读写性能都会急剧下降,在HBase中并不会出现这样的问题。
- 良好的可扩展性:HBase集群可以非常方便地实现集群容量扩展,主要包括数据存储节点扩展以及读写服务节点扩展。HBase底层数据存储依赖于HDFS系统,HDFS可以通过简单地增加DataNode实现扩展,HBase读写服务节点也一样,可以通过简单的增加RegionServer节点实现计算层的扩展。
- 稀疏性:HBase支持大量稀疏存储,即允许大量列值为空,并不占用任何存储空间。这与传统数据库不同,传统数据库对于空值的处理要占用一定的存储空间,这会造成一定程度的存储空间浪费。因此可以使用HBase存储多至上百万列的数据,即使表中存在大量的空值,也不需要任何额外空间。
- 高性能:HBase目前主要擅长于OLTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
- 多版本:HBase支持多版本特性,即一个KV可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
- 支持过期:HBase支持TTL过期特性,用户只需要设置过期时间,超过TTL的数据就会被自动清理,不需要用户写程序手动删除。
- Hadoop原生支持:HBase是Hadoop生态中的核心成员之一,很多生态组件都可以与其直接对接。HBase数据存储依赖于HDFS,这样的架构可以带来很多好处,比如用户可以直接绕过HBase系统操作HDFS文件,高效地完成数据扫描或者数据导入工作;再比如可以利用HDFS提供的多级存储特性(Archival Storage Feature),根据业务的重要程度将HBase进行分级存储,重要的业务放到SSD,不重要的业务放到HDD。或者用户可以设置归档时间,进而将最近的数据放在SSD,将归档数据文件放在HDD。另外,HBase对MapReduce的支持也已经有了很多案例,后续还会针对Spark做更多的工作。
1.1.4.2 HBase的缺点
任何一个系统都不会完美,HBase也一样。HBase不能适用于所有应用场景,例如:
- HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
- HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对HBase实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用Phoenix提供的二级索引功能。
- HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。
可以看到,HBase系统本身虽然不擅长某些工作领域,但是借助于Hadoop强大的生态圈,用户只需要在其上架设Phoenix组件、Spark组件或者其他第三方组件,就可以有效地协同工作。
1.1.5 HBase设计架构
- HBase体系结构借鉴了BigTable论文,是典型的Master-Slave模型。
- 系统中有一个管理集群的Master节点以及大量实际服务用户读写的RegionServer节点。
- 除此之外,HBase中所有数据最终都存储在HDFS系统中,这与BigTable实际数据存储在GFS中相对应;系统中还有一个ZooKeeper节点,协助Master对集群进行管理。
HBase体系结构如图1-6所示。
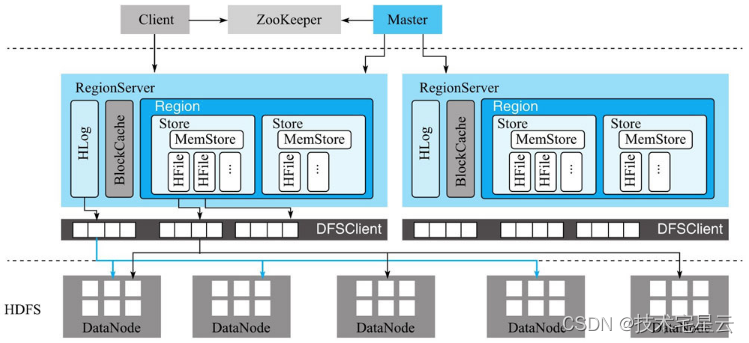
- 从HBase的部署架构上来说,HBase有两种服务器:Master服务器和RegionServer服务器。
- 一般一个HBase集群有一个Master服务器和几个RegionServer服务器。
- 每个模块的职责功能:
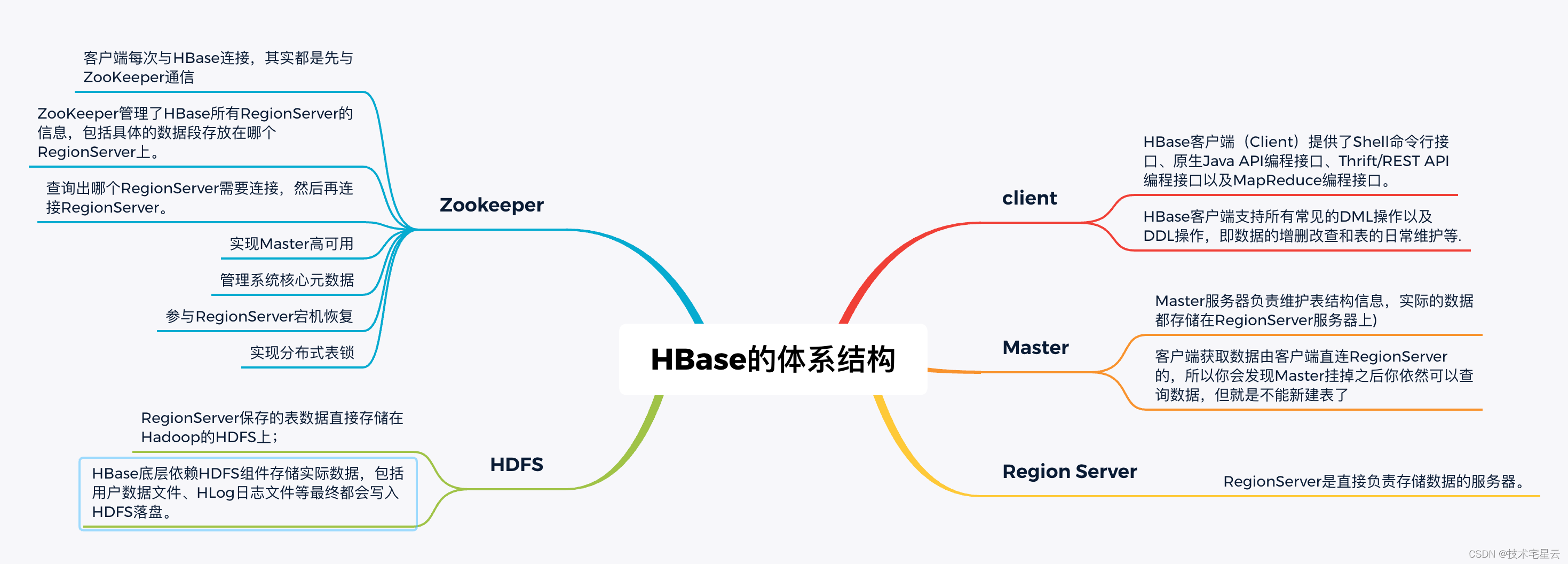
- Client
- HBase客户端(Client)提供了Shell命令行接口、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口。
- HBase客户端支持所有常见的DML操作以及DDL操作,即数据的增删改查和表的日常维护等.
- Master
- Master服务器负责维护表结构信息,实际的数据都存储在RegionServer服务器上)
- 客户端获取数据由客户端直连RegionServer的,所以你会发现Master挂掉之后你依然可以查询数据,但就是不能新建表了
- RegionServer
- RegionServer是直接负责存储数据的服务器。
- HDFS
- RegionServer保存的表数据直接存储在Hadoop的HDFS上;
- HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。
- Zookeeper:
- 客户端每次与HBase连接,其实都是先与ZooKeeper通信
- ZooKeeper管理了HBase所有RegionServer的信息,包括具体的数据段存放在哪个RegionServer上。
- 查询出哪个RegionServer需要连接,然后再连接RegionServer。
- 实现Master高可用
- 管理系统核心元数据
- 参与RegionServer宕机恢复
- 实现分布式表锁
1.2 附录
1.2.1功能模块与职责详情
| 功能模块 | 功能职责 |
|---|---|
| Client(HBase客户端) | HBase客户端(Client)提供了Shell命令行接口、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口。HBase客户端支持所有常见的DML操作以及DDL操作,即数据的增删改查和表的日常维护等。其中Thrift/REST API主要用于支持非Java的上层业务需求,MapReduce接口主要用于批量数据导入以及批量数据读取。HBase客户端访问数据行之前,首先需要通过元数据表定位目标数据所在RegionServer,之后才会发送请求到该RegionServer。同时这些元数据会被缓存在客户端本地,以方便之后的请求访问。如果集群RegionServer发生宕机或者执行了负载均衡等,从而导致数据分片发生迁移,客户端需要重新请求最新的元数据并缓存在本地。 |
| Zookeeper | ZooKeeper(ZK)也是Apache Hadoop的一个顶级项目,基于Google的Chubby开源实现,主要用于协调管理分布式应用程序。在HBase系统中,ZooKeeper扮演着非常重要的角色。•实现Master高可用:通常情况下系统中只有一个Master工作,一旦Active Master由于异常宕机,ZooKeeper会检测到该宕机事件,并通过一定机制选举出新的Master,保证系统正常运转。•管理系统核心元数据:比如,管理当前系统中正常工作的RegionServer集合,保存系统元数据表hbase:meta所在的RegionServer地址等。•参与RegionServer宕机恢复:ZooKeeper通过心跳可以感知到RegionServer是否宕机,并在宕机后通知Master进行宕机处理。•实现分布式表锁:HBase中对一张表进行各种管理操作(比如alter操作)需要先加表锁,防止其他用户对同一张表进行管理操作,造成表状态不一致。和其他RDBMS表不同,HBase中的表通常都是分布式存储,ZooKeeper可以通过特定机制实现分布式表锁 |
| Master | ZooKeeper(ZK)也是Apache Hadoop的一个顶级项目,基于Google的Chubby开源实现,主要用于协调管理分布式应用程序。在HBase系统中,ZooKeeper扮演着非常重要的角色。•实现Master高可用:通常情况下系统中只有一个Master工作,一旦Active Master由于异常宕机,ZooKeeper会检测到该宕机事件,并通过一定机制选举出新的Master,保证系统正常运转。•管理系统核心元数据:比如,管理当前系统中正常工作的RegionServer集合,保存系统元数据表hbase:meta所在的RegionServer地址等。•参与RegionServer宕机恢复:ZooKeeper通过心跳可以感知到RegionServer是否宕机,并在宕机后通知Master进行宕机处理。•实现分布式表锁:HBase中对一张表进行各种管理操作(比如alter操作)需要先加表锁,防止其他用户对同一张表进行管理操作,造成表状态不一致。和其他RDBMS表不同,HBase中的表通常都是分布式存储,ZooKeeper可以通过特定机制实现分布式表锁 |
| RegionServer | RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。• WAL(HLog):HLog在HBase中有两个核心作用——其一,用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复;其二,用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。• BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和时间局部性原理,前者表示最近将读取的KV数据很可能与当前读取到的KV数据在地址上是邻近的,缓存单位是Block(块)而不是单个KV就可以实现空间局部性;后者表示一个KV数据正在被访问,那么近期它还可能再次被访问。当前BlockCache主要有两种实现——LRUBlockCache和BucketCache,前者实现相对简单,而后者在GC优化方面有明显的提升。• Region:数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(column family)的个数,多少个列簇就有多少个Store。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据f lush成一个HFile文件。显然,随着数据不断写入,HFile文件会越来越多,当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件 |
| Master | ZooKeeper(ZK)也是Apache Hadoop的一个顶级项目,基于Google的Chubby开源实现,主要用于协调管理分布式应用程序。在HBase系统中,ZooKeeper扮演着非常重要的角色。•实现Master高可用:通常情况下系统中只有一个Master工作,一旦Active Master由于异常宕机,ZooKeeper会检测到该宕机事件,并通过一定机制选举出新的Master,保证系统正常运转。•管理系统核心元数据:比如,管理当前系统中正常工作的RegionServer集合,保存系统元数据表hbase:meta所在的RegionServer地址等。•参与RegionServer宕机恢复:ZooKeeper通过心跳可以感知到RegionServer是否宕机,并在宕机后通知Master进行宕机处理。•实现分布式表锁:HBase中对一张表进行各种管理操作(比如alter操作)需要先加表锁,防止其他用户对同一张表进行管理操作,造成表状态不一致。和其他RDBMS表不同,HBase中的表通常都是分布式存储,ZooKeeper可以通过特定机制实现分布式表锁 |
| HDFS | HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。HDFS是Hadoop生态圈内最成熟的组件之一,数据默认三副本存储策略可以有效保证数据的高可靠性。HBase内部封装了一个名为DFSClient的HDFS客户端组件,负责对HDFS的实际数据进行读写访问。 |
1.2.2 HBase中的基本概念
| 基本概念 | 解释 |
|---|---|
| table | 表,一个表包含多行数据。 |
| row | 行,一行数据包含一个唯一标识rowkey、多个column以及对应的值。在HBase中,一张表中所有row都按照rowkey的字典序由小到大排序 |
| column | 列,与关系型数据库中的列不同,HBase中的column由column family(列簇)以及qualif ier(列名)两部分组成,两者中间使用":"相连。比如contents:html,其中contents为列簇,html为列簇下具体的一列。column family在表创建的时候需要指定,用户不能随意增减。一个column family下可以设置任意多个qualif ier,因此可以理解为HBase中的列可以动态增加,理论上甚至可以扩展到上百万列。 |
| timestamp | 时间戳,每个cell在写入HBase的时候都会默认分配一个时间戳作为该cell的版本,当然,用户也可以在写入的时候自带时间戳。HBase支持多版本特性,即同一rowkey、column下可以有多个value存在,这些value使用timestamp作为版本号,版本越大,表示数据越新。 |
1.2.3 本文中涉及的思维导图原件下载
- 点击下载 揭开HBase的神秘面纱思维导图原件
相关文章:
1. HBase中文学习手册之揭开Hbase的神秘面纱
揭开Hbase的神秘面纱 1.1 欢迎使用 Apache Hbase1.1.1 什么是 Hbase?1.1.2 Hbase的前世今生1.1.3 HBase的技术选型?1.1.3.1 不适合使用 HBase的场景1.1.3.2 适合使用 HBase的场景 1.1.4 HBase的特点1.1.4.1 HBase的优点1.1.4.2 HBase的缺点 1.1.5 HBase设计架构 1.…...
[线程/C++]线程同(异)步和原子变量
文章目录 1.线程的使用1.1 函数构造1.2 公共成员函数1.2.1 get_id()1.2.2 join()2.2.3 detach()2.2.5 joinable()2.2.6 operator 1.3 静态函数1.4 call_once 2. this_thread 命名空间2.1 get_id()2.2 sleep_for()2.3 sleep_until()2.4 yield() 3. 线程同步之互斥锁3.1 std:mute…...

全球网络加速器GA和内容分发网络CDN,哪个更适合您的组织使用?
对互联网用户来说,提供最佳的用户体验至关重要:网页加载时间过长、视频播放断断续续以及服务忽然中断等问题都足以在瞬间失去客户。因此可以帮助提高您的网站或APP提高加载性能的解决方案就至关重要:全球网络加速器和CDN就是其中的两种解决方…...
蓝凌OA custom.jsp 任意文件读取
曾子曰:“慎终追远,民德归厚矣。” 漏洞复现 访问漏洞url: 出现漏洞的文件为 custom.jsp,构造payload: /sys/ui/extend/varkind/custom.jsp var{"body":{"file":"file:///etc/passwd&q…...
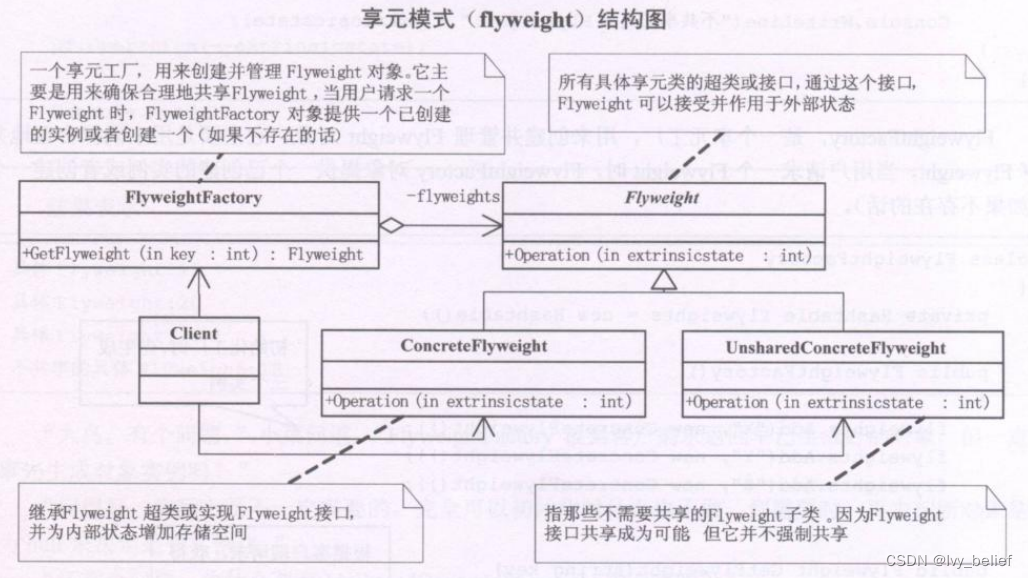
(二)结构型模式:7、享元模式(Flyweight Pattern)(C++实例)
目录 1、享元模式(Flyweight Pattern)含义 2、享元模式的UML图学习 3、享元模式的应用场景 4、享元模式的优缺点 5、C实现享元模式的简单实例 1、享元模式(Flyweight Pattern)含义 享元模式(Flyweight)…...

laravel 多次查询请求,下次请求清除上次请求的where 条件
在Laravel中,可以使用where方法来添加查询条件,但是每次添加where条件时,都会在查询构造器中持久化这些条件,直到你手动重置它们。所以,如果你想在下一次查询中清除上次查询的where条件,有以下几种选择&…...

C++根据如下使用类MyDate的程序,写出类MyDate的定义,MyDate中有三个数据成员:年year,月month,日day完成以下要求
题目: 根据如下使用类MyDate的程序,写出类MyDate的定义,MyDate中有三个数据成员: 年year,月month,日day int year,month,day; void main() { MyDate d1, d2; d1.set(2015, 12, 31); d2.set(d1); d1.…...
微盟集团中报增长稳健 重点发力智慧零售AI赛道
零售数字化进程已从渠道构建走向了用户的深度运营。粗放式用户运营体系无法适应“基于用户增长所需配套的精细化运营能力”,所以需要有个体、群体、个性化、自动化运营——即在对的时候、以对的方式、把对的内容推给用户。 出品|产业家 2023年已经过半,经济复苏成为…...
模板方法模式)
设计模式(7)模板方法模式
一、定义: 定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式。 //模板方法抽象类 public abstract class AbstractClass {//模板方法publ…...

2308C++协程流程9
参考 #include <协程> #include "简异中.cpp" //用来中文定义的.元<类 T>构 P;元<类 T>构 任务{用 承诺型P<T>;任务()默认;动 符号 协待()常 无异{构 等待器{极 直接协()常 无异{中 p.是准备好();}协柄 挂起协(协柄<>o)常 无异{p.连续…...

基于学习交流社区的自动化测试实现
一 项目介绍 项目名称 项目名称: 学习交流社区 项目介绍 项目介绍: 学习交流社区是一个基于Spring的前后端分离的在线论坛系统。使用了MySQL数据库来存储相关信息,项目完成后使用Xshell将其部署到云服务器上。 前端页面: 前端共由…...

2023-08-21力扣每日一题
链接: 2337. 移动片段得到字符串 题意: L可以和左边的_交换,R可以和右边的_交换,求判断A是否能通过交换(不限次数)变成B 解: 观察可知,如果存在RL,一定不能交换出LR,…...

对象存储服务-MinIO基本集成
是什么 MinIO 是一个高性能的分布式对象存储服务,适合存储非结构化数据,如图片,音频,视频,日志等。对象文件最大可以达到5TB。 安装启动 mkdir -p /usr/local/minio cd /usr/local/minio# 下载安装包 wget https:/…...

Yarn介绍及快速安装 - Debian/Ubuntu Linux
1.Yarn介绍 Yarn 是一个用于管理 JavaScript 包的快速、可靠和安全的包管理器。它是由 Facebook、Google、Exponent 和 Tilde 团队共同开发的,旨在提供比 npm 更快速、可靠的包管理体验。 以下是 Yarn 的一些主要特点和优势: 快速安装:Yarn…...
】第10課 中国の生活に慣れるかどうか少し心配です)
【新日语(2)】第10課 中国の生活に慣れるかどうか少し心配です
第10課 中国の生活に慣れるかどうか少し心配です 注释: ~かどうか:“是否”。 练习A 一、例句 田中さんは鈴木さんに、30分ぐらい遅れると言いました。 田中先生告诉铃木先生,他会迟到大约30分钟。 注释: &…...

Python 网页解析初级篇:BeautifulSoup库的入门使用
在Python的网络爬虫中,网页解析是一项重要的技术。而在众多的网页解析库中,BeautifulSoup库凭借其简单易用而广受欢迎。在本篇文章中,我们将学习BeautifulSoup库的基本用法。 一、BeautifulSoup的安装与基本使用 首先,我们需要使…...

Spring Schedular 定时任务
大家好 , 我是苏麟 , 今天带来定时任务的实现 . Spring网站 : 入门 |计划任务 (spring.io) 什么是定时任务 通过时间表达式来进行调度和执行的一类任务被称为定时任务 定时任务实现 1.Spring Schedule (Spring boot 默认整合了) 2.Quartz(独立于Spring 存在的定时任务框架…...

营业额统计
营业额统计 # 题目描述 Tiger 最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况。 Tiger 拿出了公司的账本,账本上记录了公司成立以来每天的营业额。分析营业情况是一项相当复杂的工作。由于节假日&…...

使用lodash的throttle函数会触发两次
当使用lodash的throttle函数时会触发两次,分别在最开始和最后。 严格来说不算是bug,因为官方文档写的很清楚。throttle函数其实有三个参数: _.throttle(func, [wait0], [options]) func: 要节流的函数 wait: 等待时间 options: 选项 op…...

如何使用CSS实现一个瀑布流布局?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用CSS实现瀑布流布局⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚刚…...

告别手动调试!用西门子STEP7组态软件,5分钟搞定步进电机多段速与正反转控制逻辑
西门子STEP7高效编程:5步构建步进电机智能控制系统 在工业自动化现场,调试步进电机控制逻辑往往是耗时费力的工作——传统方法需要反复修改硬件接线和梯形图程序,每次速度切换或方向调整都可能引发意外停机。而西门子STEP7组态软件提供的结构…...

LPA分层审核指标是什么?读懂LPA分层审核指标才能评估审核有效性
在工厂的质量管理体系运行中,LPA(分层过程审核)是确保标准作业落地、问题及时发现和整改的有力工具。但很多企业推行LPA后,仅仅关注有没有做审核,却忽略了审核做得怎么样。结果,审核表填了一大摞࿰…...

Perplexity接入知网文献搜索的5大避坑指南:实测发现92%研究者正在浪费87%检索时间
更多请点击: https://intelliparadigm.com 第一章:Perplexity接入知网文献搜索的底层逻辑与认知重构 Perplexity 作为基于大语言模型的实时问答引擎,其核心能力并非仅依赖于内部参数化知识,而是通过动态检索增强生成(…...
)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用) 想象一下:你的游戏场景中,炽热的岩浆在地表缓缓流动,水面泛起涟漪般的波纹,或是能量屏障表面流淌着神秘…...
)
C# + OpenCVSharp实战:搞定工业零件旋转角度匹配(附完整源码)
C# OpenCVSharp工业视觉实战:高精度旋转零件匹配的工程化实现 在自动化生产线中,零件定位的准确性直接关系到装配质量和生产效率。当数以千计的金属零件以随机角度通过传送带时,传统的人工检测或固定角度的模板匹配方法往往束手无策。某汽车…...

暗黑破坏神2存档编辑器d2s-editor:架构深度解析与实战应用指南
暗黑破坏神2存档编辑器d2s-editor:架构深度解析与实战应用指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 在暗黑破坏神2的深度游戏体验中,玩家常常面临角色build测试、装备获取耗时、游戏进度调整等…...

【免费下载】 探索双面神技:STM32G474的USB跨界应用
探索双面神技:STM32G474的USB跨界应用 在物联网与嵌入式开发的世界里,寻找一款能兼顾数据传输与控制沟通的神器是每个开发者的心头好。今天,我们就来揭秘这样一个宝藏项目——STM32G474实现USB的MSCCDC组合功能,它巧妙地将STM32G4…...
)
PTA天梯赛L2-007家庭房产题解:用C++并查集+结构体搞定复杂家庭关系统计(附完整代码)
PTA天梯赛L2-007家庭房产题解:C并查集与结构体的高效应用 在算法竞赛中,处理复杂关系网络是常见挑战。PTA天梯赛L2-007"家庭房产"题目正是这类问题的典型代表,要求选手统计每个家庭的人口、房产套数和人均面积。这道题看似简单&am…...

接入Taotoken多模型路由后服务端响应稳定性提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken多模型路由后服务端响应稳定性提升感受 1. 背景:生产环境对AI服务稳定性的需求 在构建依赖大模型API的生…...
的底层逻辑)
从TSMC 256bit eFuse宏单元入手,搞懂芯片冗余修复(Repair)的底层逻辑
从TSMC 256bit eFuse宏单元入手,搞懂芯片冗余修复(Repair)的底层逻辑 在半导体制造领域,芯片良率始终是决定生产成本和市场竞争力的关键因素。随着工艺节点不断微缩,单个晶圆上集成的晶体管数量呈指数级增长࿰…...