计算机竞赛 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录
- 0 前言
- 2 垃圾短信/邮件 分类算法 原理
- 2.1 常用的分类器 - 贝叶斯分类器
- 3 数据集介绍
- 4 数据预处理
- 5 特征提取
- 6 训练分类器
- 7 综合测试结果
- 8 其他模型方法
- 9 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 垃圾邮件(短信)分类算法实现 机器学习 深度学习
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
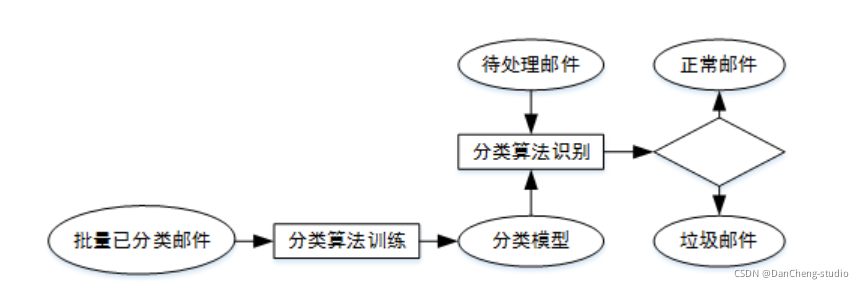
2 垃圾短信/邮件 分类算法 原理
垃圾邮件内容往往是广告或者虚假信息,甚至是电脑病毒、情色、反动等不良信息,大量垃圾邮件的存在不仅会给人们带来困扰,还会造成网络资源的浪费;
网络舆情是社会舆情的一种表现形式,网络舆情具有形成迅速、影响力大和组织发动优势强等特点,网络舆情的好坏极大地影响着社会的稳定,通过提高舆情分析能力有效获取发布舆论的性质,避免负面舆论的不良影响是互联网面临的严肃课题。
将邮件分为垃圾邮件(有害信息)和正常邮件,网络舆论分为负面舆论(有害信息)和正面舆论,那么,无论是垃圾邮件过滤还是网络舆情分析,都可看作是短文本的二分类问题。
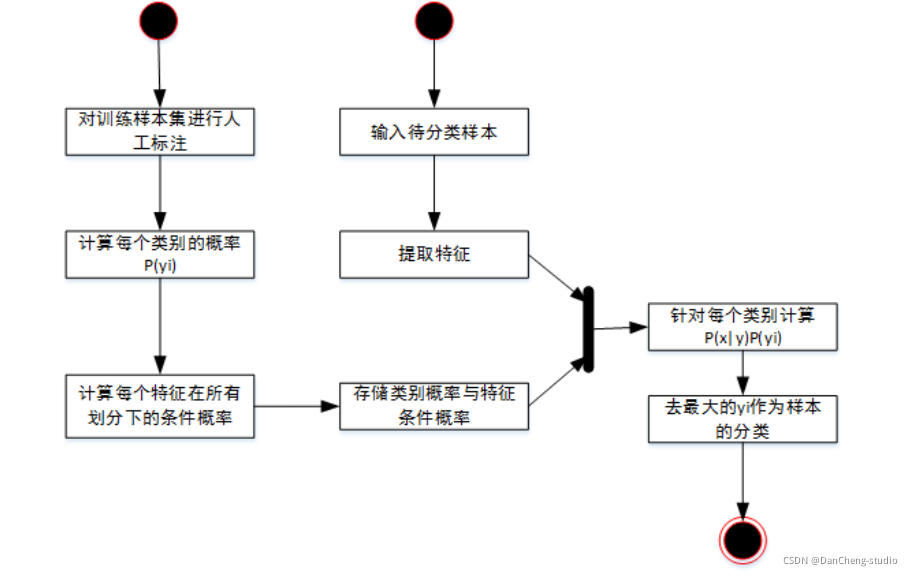
2.1 常用的分类器 - 贝叶斯分类器
贝叶斯算法解决概率论中的一个典型问题:一号箱子放有红色球和白色球各 20 个,二号箱子放油白色球 10 个,红色球 30
个。现在随机挑选一个箱子,取出来一个球的颜色是红色的,请问这个球来自一号箱子的概率是多少?
利用贝叶斯算法识别垃圾邮件基于同样道理,根据已经分类的基本信息获得一组特征值的概率(如:“茶叶”这个词出现在垃圾邮件中的概率和非垃圾邮件中的概率),就得到分类模型,然后对待处理信息提取特征值,结合分类模型,判断其分类。
贝叶斯公式:
P(B|A)=P(A|B)*P(B)/P(A)
P(B|A)=当条件 A 发生时,B 的概率是多少。代入:当球是红色时,来自一号箱的概率是多少?
P(A|B)=当选择一号箱时,取出红色球的概率。
P(B)=一号箱的概率。
P(A)=取出红球的概率。
代入垃圾邮件识别:
P(B|A)=当包含"茶叶"这个单词时,是垃圾邮件的概率是多少?
P(A|B)=当邮件是垃圾邮件时,包含“茶叶”这个单词的概率是多少?
P(B)=垃圾邮件总概率。
P(A)=“茶叶”在所有特征值中出现的概率。
3 数据集介绍
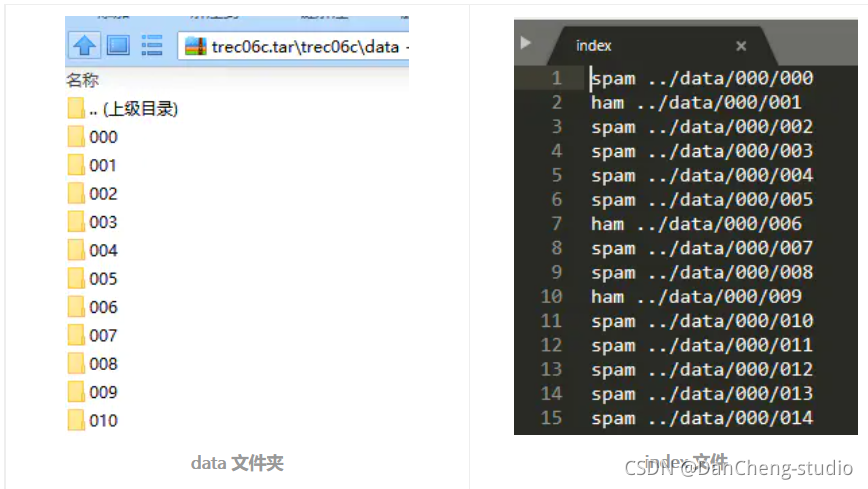
使用中文邮件数据集:丹成学长自己采集,通过爬虫以及人工筛选。
数据集“data” 文件夹中,包含,“full” 文件夹和 “delay” 文件夹。
“data” 文件夹里面包含多个二级文件夹,二级文件夹里面才是垃圾邮件文本,一个文本代表一份邮件。“full” 文件夹里有一个 index
文件,该文件记录的是各邮件文本的标签。
数据集可视化:
4 数据预处理
这一步将分别提取邮件样本和样本标签到一个单独文件中,顺便去掉邮件的非中文字符,将邮件分好词。
邮件大致内容如下图:
每一个邮件样本,除了邮件文本外,还包含其他信息,如发件人邮箱、收件人邮箱等。因为我是想把垃圾邮件分类简单地作为一个文本分类任务来解决,所以这里就忽略了这些信息。
用递归的方法读取所有目录里的邮件样本,用 jieba 分好词后写入到一个文本中,一行文本代表一个邮件样本:
import re
import jieba
import codecs
import os
# 去掉非中文字符
def clean_str(string):string = re.sub(r"[^\u4e00-\u9fff]", " ", string)string = re.sub(r"\s{2,}", " ", string)return string.strip()def get_data_in_a_file(original_path, save_path='all_email.txt'):files = os.listdir(original_path)for file in files:if os.path.isdir(original_path + '/' + file):get_data_in_a_file(original_path + '/' + file, save_path=save_path)else:email = ''# 注意要用 'ignore',不然会报错f = codecs.open(original_path + '/' + file, 'r', 'gbk', errors='ignore')# lines = f.readlines()for line in f:line = clean_str(line)email += linef.close()"""发现在递归过程中使用 'a' 模式一个个写入文件比 在递归完后一次性用 'w' 模式写入文件快很多"""f = open(save_path, 'a', encoding='utf8')email = [word for word in jieba.cut(email) if word.strip() != '']f.write(' '.join(email) + '\n')print('Storing emails in a file ...')
get_data_in_a_file('data', save_path='all_email.txt')
print('Store emails finished !')
然后将样本标签写入单独的文件中,0 代表垃圾邮件,1 代表非垃圾邮件。代码如下:
def get_label_in_a_file(original_path, save_path='all_email.txt'):f = open(original_path, 'r')label_list = []for line in f:# spamif line[0] == 's':label_list.append('0')# hamelif line[0] == 'h':label_list.append('1')f = open(save_path, 'w', encoding='utf8')f.write('\n'.join(label_list))f.close()print('Storing labels in a file ...')
get_label_in_a_file('index', save_path='label.txt')
print('Store labels finished !')
5 特征提取
将文本型数据转化为数值型数据,本文使用的是 TF-IDF 方法。
TF-IDF 是词频-逆向文档频率(Term-Frequency,Inverse Document Frequency)。公式如下:

在所有文档中,一个词的 IDF 是一样的,TF 是不一样的。在一个文档中,一个词的 TF 和 IDF
越高,说明该词在该文档中出现得多,在其他文档中出现得少。因此,该词对这个文档的重要性较高,可以用来区分这个文档。

import jieba
from sklearn.feature_extraction.text import TfidfVectorizerdef tokenizer_jieba(line):# 结巴分词return [li for li in jieba.cut(line) if li.strip() != '']def tokenizer_space(line):# 按空格分词return [li for li in line.split() if li.strip() != '']def get_data_tf_idf(email_file_name):# 邮件样本已经分好了词,词之间用空格隔开,所以 tokenizer=tokenizer_spacevectoring = TfidfVectorizer(input='content', tokenizer=tokenizer_space, analyzer='word')content = open(email_file_name, 'r', encoding='utf8').readlines()x = vectoring.fit_transform(content)return x, vectoring
6 训练分类器
这里学长简单的给一个逻辑回归分类器的例子
from sklearn.linear_model import LogisticRegression
from sklearn import svm, ensemble, naive_bayes
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as npif __name__ == "__main__":np.random.seed(1)email_file_name = 'all_email.txt'label_file_name = 'label.txt'x, vectoring = get_data_tf_idf(email_file_name)y = get_label_list(label_file_name)# print('x.shape : ', x.shape)# print('y.shape : ', y.shape)# 随机打乱所有样本index = np.arange(len(y)) np.random.shuffle(index)x = x[index]y = y[index]# 划分训练集和测试集x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)clf = svm.LinearSVC()# clf = LogisticRegression()# clf = ensemble.RandomForestClassifier()clf.fit(x_train, y_train)y_pred = clf.predict(x_test)print('classification_report\n', metrics.classification_report(y_test, y_pred, digits=4))print('Accuracy:', metrics.accuracy_score(y_test, y_pred))
7 综合测试结果
测试了2000条数据,使用如下方法:
-
支持向量机 SVM
-
随机数深林
-
逻辑回归
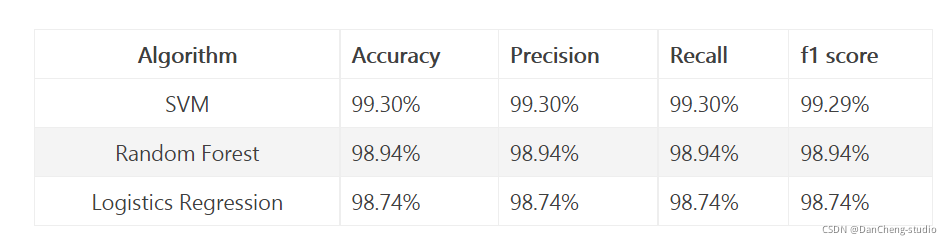
可以看到,2000条数据训练结果,200条测试结果,精度还算高,不过数据较少很难说明问题。
8 其他模型方法
还可以构建深度学习模型
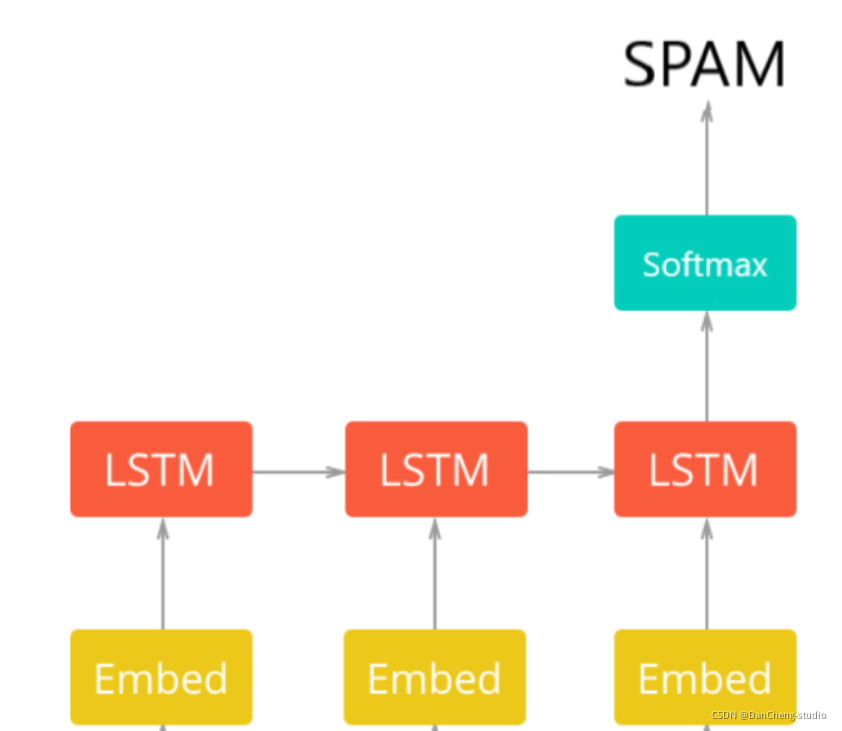
网络架构第一层是预训练的嵌入层,它将每个单词映射到实数的N维向量(EMBEDDING_SIZE对应于该向量的大小,在这种情况下为100)。具有相似含义的两个单词往往具有非常接近的向量。
第二层是带有LSTM单元的递归神经网络。最后,输出层是2个神经元,每个神经元对应于具有softmax激活功能的“垃圾邮件”或“正常邮件”。
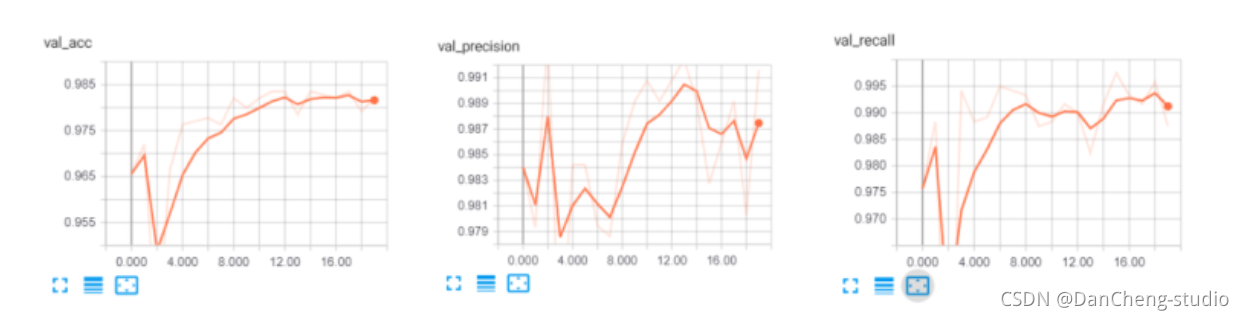
def get_embedding_vectors(tokenizer, dim=100):embedding_index = {}with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:for line in tqdm.tqdm(f, "Reading GloVe"):values = line.split()word = values[0]vectors = np.asarray(values[1:], dtype='float32')embedding_index[word] = vectorsword_index = tokenizer.word_indexembedding_matrix = np.zeros((len(word_index)+1, dim))for word, i in word_index.items():embedding_vector = embedding_index.get(word)if embedding_vector is not None:# words not found will be 0sembedding_matrix[i] = embedding_vectorreturn embedding_matrixdef get_model(tokenizer, lstm_units):"""Constructs the model,Embedding vectors => LSTM => 2 output Fully-Connected neurons with softmax activation"""# get the GloVe embedding vectorsembedding_matrix = get_embedding_vectors(tokenizer)model = Sequential()model.add(Embedding(len(tokenizer.word_index)+1,EMBEDDING_SIZE,weights=[embedding_matrix],trainable=False,input_length=SEQUENCE_LENGTH))model.add(LSTM(lstm_units, recurrent_dropout=0.2))model.add(Dropout(0.3))model.add(Dense(2, activation="softmax"))# compile as rmsprop optimizer# aswell as with recall metricmodel.compile(optimizer="rmsprop", loss="categorical_crossentropy",metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])model.summary()return model训练结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 100) 901300
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 1,018,806
Trainable params: 117,506
Non-trainable params: 901,300
_________________________________________________________________
X_train.shape: (4180, 100)
X_test.shape: (1394, 100)
y_train.shape: (4180, 2)
y_test.shape: (1394, 2)
Train on 4180 samples, validate on 1394 samples
Epoch 1/20
4180/4180 [==============================] - 9s 2ms/step - loss: 0.1712 - acc: 0.9325 - precision: 0.9524 - recall: 0.9708 - val_loss: 0.1023 - val_acc: 0.9656 - val_precision: 0.9840 - val_recall: 0.9758Epoch 00001: val_loss improved from inf to 0.10233, saving model to results/spam_classifier_0.10
Epoch 2/20
4180/4180 [==============================] - 8s 2ms/step - loss: 0.0976 - acc: 0.9675 - precision: 0.9765 - recall: 0.9862 - val_loss: 0.0809 - val_acc: 0.9720 - val_precision: 0.9793 - val_recall: 0.9883
9 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录 0 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 垃圾邮件(短信)分类算…...

compositionAPI
面试题:composition api相比于option api有哪些优势? 不同于reactivity api,composition api提供的函数很多是与组件深度绑定的,不能脱离组件而存在。 1. setup // component export default {setup(props, context){// 该函数在…...

vscode配置调试环境-windows系统
1. 下载Vscode 下载网址code.visualstudio.com 2. 安装vscode 直打开下载好的.exe文件进行安装即可 3.安装插件 4下载mingw编译器 4.1下载 下载网址sourceforge.net/projects/mingw-w64/files/ 下拉找到该位置,下载圈中的版本。下载速度有点慢 临时下载地址 htt…...

智慧城市能实现嘛?数字孪生又在其中扮演什么角色?
数字孪生智慧城市是将数字孪生技术与城市智能化相结合的新兴概念,旨在通过实时数字模拟城市运行,优化城市管理与服务,创造更智能、高效、可持续的城市环境。 在智慧城市中,数字孪生技术可以实时收集、分析城市各个方面的数据&…...

【置顶帖】关于博主/关于博客/博客大事记
关于博主 ● 信息安全从业者 ● 注册信息安全认证专家资质 ● CSDN认证业界专家、安全博客专家 、全栈安全领域优质创作者 ● 中国信通院【2021-GOLF IT新治理领导力论坛】演讲嘉宾 ● 安世加【2021-EISS企业信息安全峰会-上海】演讲嘉宾 ● CSDN【2022-隐私计算论坛】演讲嘉宾…...

华为数通方向HCIP-DataCom H12-821题库(单选题:01-20)
第01题 下面关于OSPF邻居关系和邻接关系描述正确的是 A、邻接关系由 OSPF的 DD 报文维护 B、OSPF 路由器在交换 Hello 报文之前必须建立邻接关系 C、邻居关系是从邻接关系中选出的为了交换路由信息而形成的关系 D、并非所有的邻居关系都可以成为邻接关系 答案:D 解析…...

Java【手撕双指针】LeetCode 11. “盛水最多的容器“, 图文详解思路分析 + 代码
文章目录 前言一、盛水最多的容器1, 题目2, 思路分析3, 代码展示 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表…...

vue3——递归组件的使用
该文章是在学习 小满vue3 课程的随堂记录示例均采用 <script setup>,且包含 typescript 的基础用法 一、使用场景 递归组件 的使用场景,如 无限级的菜单 ,接下来就用菜单的例子来学习 二、具体使用 先把菜单的基础内容写出来再说 父…...

【爬虫练习之glidedsky】爬虫-基础1
题目 链接 爬虫的目标很简单,就是拿到想要的数据。 这里有一个网站,里面有一些数字。把这些数字的总和,输入到答案框里面,即可通过本关。 思路 找到调用接口 分析response 代码实现 import re import requestsurl http://www.…...
计算机视觉入门 1)卷积分类器
目录 一、卷积分类器(The Convolutional Classifer)训练分类器 二、【代码示例】汽车卡车图片分类器步骤1. 导入数据步骤2 - 定义预训练模型步骤3 - 连接头部步骤4 - 训练模型 一、卷积分类器(The Convolutional Classifer) 卷积…...
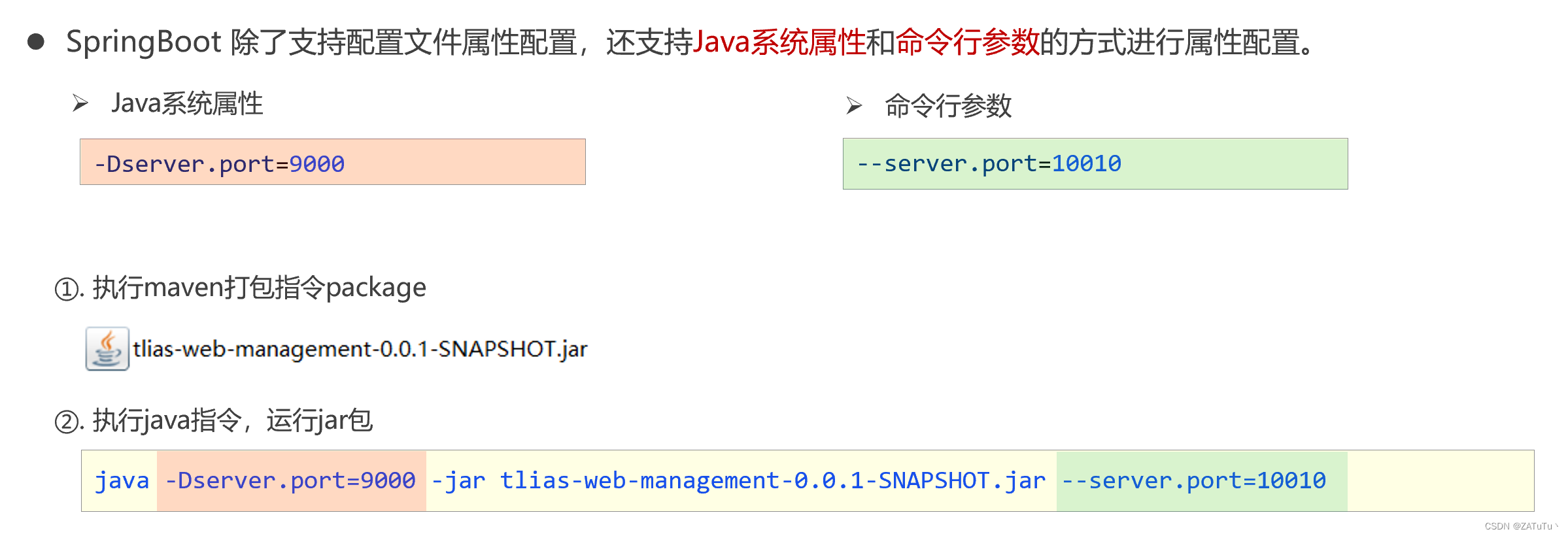
SpringBoot 配置优先级
一般而言,SpringBoot支持配置文件进行配置,即在resources下的application.properties或application.yml。 关于配置优先级而言, application.properties>application.yml>application.yaml 另外JAVA程序程序还支持java系统配置和命令行…...

钢筋的形变屈服度测量
钢筋力学性能检测方法与检测报告《建筑材料检测技术》杨丛慧 建筑形变检测锚点,本身无实质内容。 建筑的倾角和形变检测方法,工程测量学,李章树 毫米级的卫星位移定位 挠度检测。 赛格事件:SHM-Structural Health Monitoring…...
【BASH】回顾与知识点梳理(三十七)
【BASH】回顾与知识点梳理 三十七 三十七. 基础系统设定与备份策略37.1 系统基本设定网络设定 (手动设定与 DHCP 自动取得)手动设定 IP 网络参数(nmcli)自动取得 IP 参数(dhcp)修改主机名(hostnamectl) 37.2 日期与时间设定时区的显示与设定时间的调整用 ntpdate 手动网络校时 …...

智慧农场云养猪平台原来是这样的!
随着数字化和智能化的发展,农业行业也逐渐开始融入互联网技术,其中云养猪平台作为新兴的农业数字化解决方案之一,备受关注。本文将探讨如何开发一款具备专业、思考深度和逻辑性的云养猪平台。 一、前期准备阶段: 1.明确目…...
【3Ds Max】可编辑多边形“边界”层级的简单使用
目录 示例 (1)挤出 (2)插入顶点 (3)切角 (4)利用所选内容创建图形 (5)封口 (6)桥 示例 这里我们首先创建一个长方体ÿ…...

Rancher-RKE2-安装流程
一、什么是rke2? 1.rke2是Rancher的下一代k8s发行版, 二、与rke的不同 1.重要的是,RKE2 不像 RKE1 那样依赖 Docker。RKE1 利用 Docker 来部署和管理控制平面组件以及 Kubernetes 的容器运行时间。RKE2 将控制平面组件作为静态 pod 启动&…...
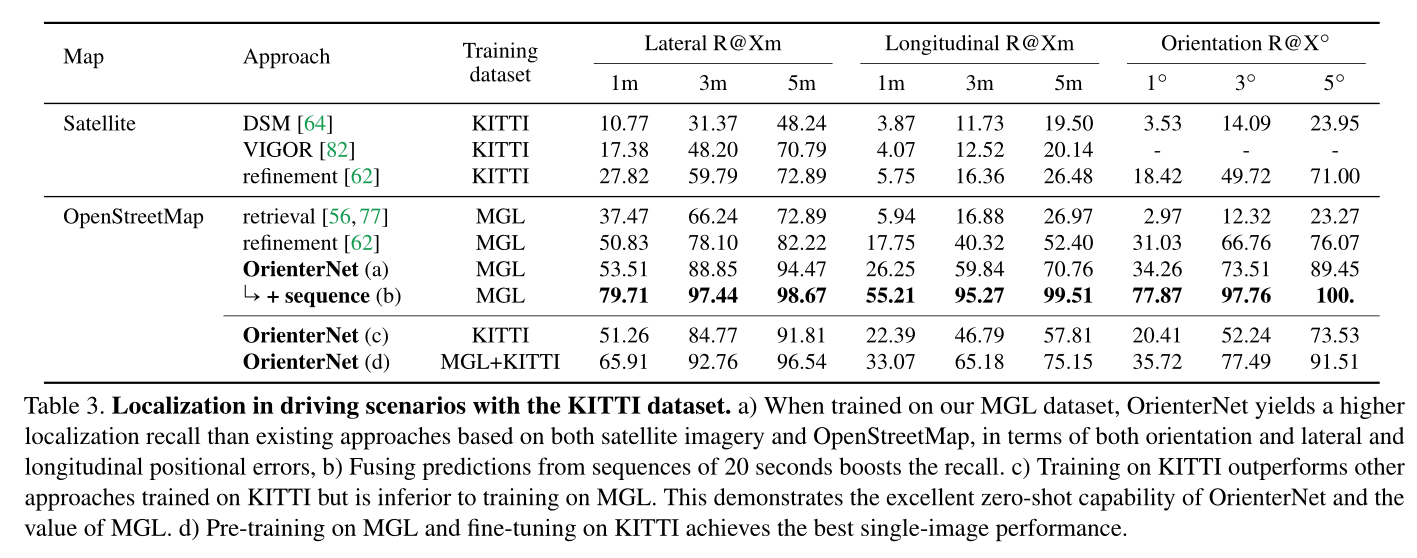
OrienterNet: visual localization in 2D public maps with neural matching 论文阅读
论文信息 题目:OrienterNet: visual localization in 2D public maps with neural matching 作者:Paul-Edouard Sarlin, Daniel DeTone 项目地址:github.com/facebookresearch/OrienterNet 来源:CVPR 时间:…...

iOS导航栏闪屏以及statusBar背景色的更改
1.如果导航栏有卡顿或者闪屏效果出现,多半是因为导航栏背景为透明色所致,可以给导航栏设置主题色,比如已白色为例 self.navigationController.navigationBar.backgroundColor [UIColor whiteColor]; 2.但是即使上述设置后,依然发…...

Centos开启防火墙和端口命令
Centos开启防火墙和端口命令 1. 开启查看关闭firewalld服务状态2. 查看端口是否开放3. 新增开放端口4. 查看开放的端口 1. 开启查看关闭firewalld服务状态 #启动/关闭firewall systemctl start/stop firewalld #查看防火墙状态 systemctl status firewalld #禁用或者启用 syst…...
基于微信小程序的宠物领养平台的设计与实现(Java+spring boot+微信小程序+MySQL)
获取源码或者论文请私信博主 演示视频: 基于微信小程序的宠物领养平台的设计与实现(Javaspring boot微信小程序MySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java…...

YOLOv8 室内行人跌倒数据集信息表
YOLOv8 室内行人跌倒数据集信息表 数据集概述 项目内容数据集名称YOLOv8 室内行人跌倒数据集总图像数量9,262 张应用场景跌倒检测、公共安全监控、老年人护理、智能安防目标类别2 类:stand(站立)、fall(跌倒)标注格式…...
)
C++ 资源操作注意事项(内存、文件、数据库、网络...)
文章目录1. 资源类型2. 资源可变性3. 资源分配策略4. 资源访问权限5. 资源所有权转移6. 资源获取和释放7. 生命周期管理8. 资源有效性检查9. 资源竞争(多线程安全性)10. 资源泄漏防范11. 异常安全性在C中,确保资源的有效和安全管理至关重要。…...
)
黑群晖/白群晖通用!Docker部署DDNS-Go搞定腾讯云域名解析(保姆级避坑指南)
群晖与腾讯云域名解析终极方案:Docker化DDNS-Go实战指南 当你在群晖NAS上尝试配置腾讯云DDNS服务时,是否遇到过"认证失败"的困扰?这个问题尤其困扰黑群晖用户,但即便是白群晖用户也难免遭遇兼容性难题。本文将带你探索…...

为OpenClaw智能体工作流配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为后端模型供应商 对于使用OpenClaw框架构建AI智能体的开发者而言,将后端模型服…...
)
NotebookLM私有知识库安全加固指南(GDPR/等保2.0双合规配置手册,仅限内部技术团队流通)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM私有知识库安全加固概览 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与问答的 AI 工具,其本地化部署或私有知识库场景下,数据驻留、访问控制与内容脱敏…...

IO-Link技术解析:工业自动化通信与LTC2874/LT3669芯片应用
1. IO-Link技术概述:工业自动化的神经末梢在工业4.0的浪潮中,设备间的实时通信如同工厂的神经系统。IO-Link作为这个系统中的"神经末梢",实现了控制层与现场设备间的最后一米连接。这项技术最早由PROFIBUS用户组织在2009年推出&…...

claw-installer:构建自动化部署脚本的工程实践与设计哲学
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫claw-installer。这名字乍一看有点抽象,但如果你对自动化部署、特别是那些需要处理复杂依赖和配置的应用感兴趣,那这个工具很可能就是你一直在找的“瑞士军刀”。简单来说ÿ…...
:92%开发者踩过的5类语音延迟/断连/语义失准陷阱)
ElevenLabs IVR语音制作避坑手册(2024最新版):92%开发者踩过的5类语音延迟/断连/语义失准陷阱
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs IVR语音制作避坑手册导论 在构建高可用、高自然度的智能语音应答(IVR)系统时,ElevenLabs 以其超拟真语音合成能力成为热门选择。然而,其 API …...

中国词元与世界AI元语:模力方舟和口袋龙虾的协同进化
在AI产业从技术突破转向生态竞争的今天,一个核心命题日益凸显:如何让顶尖的AI能力跨越技术鸿沟,真正触达每一个开发者与终端用户?开源中国以“模力方舟”与“口袋龙虾”为双核驱动,构建了一条从底层资源聚合到上层应用…...

苹果果梗检测数据集VOC+YOLO格式1141张2类别有增强
注意数据集大约450张是原图剩余均为增强生成图片数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1141标注数量(xml文件个数):1141…...