【C++】关联式容器——map和set的使用
文章目录
- 一、关联式容器
- 二、键值对
- 三、树形结构的关联式容器
- 1.set
- 2.multiset
- 3.map
- 4.multimap
- 四、题目练习

一、关联式容器
序列式容器📕:已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
关联式容器📕:也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
二、键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
比如📝:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义
SGI-STL中关于键值对的定义 👇
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair(): first(T1()), second(T2()){}pair(const T1& a, const T2& b): first(a), second(b){}
};
三、树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器🔴:树型结构与哈希结构。
树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)
作为其底层结果,容器中的元素是一个有序的序列。
下面,我们一起来看一看这四种关联式容器👇
1.set
\1. set是按照
一定次序存储元素的容器
\2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
\3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
\4. set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
\5. set在底层是用二叉搜索树(红黑树)实现的 ,中序之后自然是有序的,插入元素之后:小的往左边走,大的往右边走,相等则返回false。
set的模板参数列表

T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
Compare:仿函数,set中元素默认按照小于来比较
Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理
set的构造函数
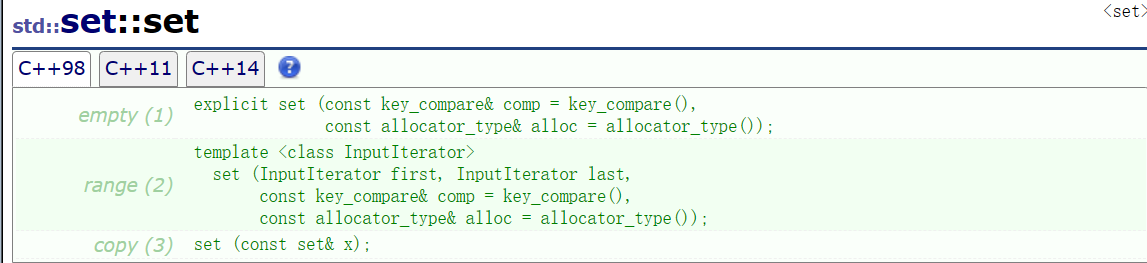
默认构造、迭代器区间构造、拷贝构造(深拷贝):
void test_set()
{int arr[] = { 1,2,3,4,5 };set<int> s;//默认构造set<int> s1(arr, arr + 5);//区间构造set<int> s2(s1);//拷贝构造for (auto e : s1) cout << e << " "; cout << endl;for (auto e : s2) cout << e << " "; cout << endl;}

set的迭代器
| 函数声明 | 功能介绍 |
|---|---|
| iterator begin() \end() | 返回set中起始位置元素的迭代器\返回set中最后一个元素后面的迭代器 |
| const_iterator cbegin()\cend() const | 返回set中起始位置元素的const迭代器\返回set中最后一个元素后面的const迭代器 |
| reverse_iterator rbegin() \rend() | 返回set第一个元素的反向迭代器,即end\返回set最后一个元素下一个位置的反向迭代器,即 rbegin |
| const_reverse_iterator crbegin() \crend() const | 返回set第一个元素的反向const迭代器,即cend\返回set最后一个元素下一个位置的反向const迭代器, 即crbegin |
我们简单来看一看代码把:
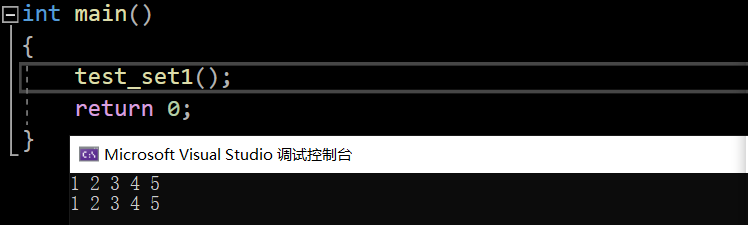
void test_set1()
{set<int> s;s.insert(1);s.insert(2);s.insert(1);s.insert(3);s.insert(4);s.insert(5);//排序+去重for (auto e : s){cout << e << " ";}cout << endl;//set<int>::iterator it = s.begin();auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;}
int main()
{test_set1();return 0;
}
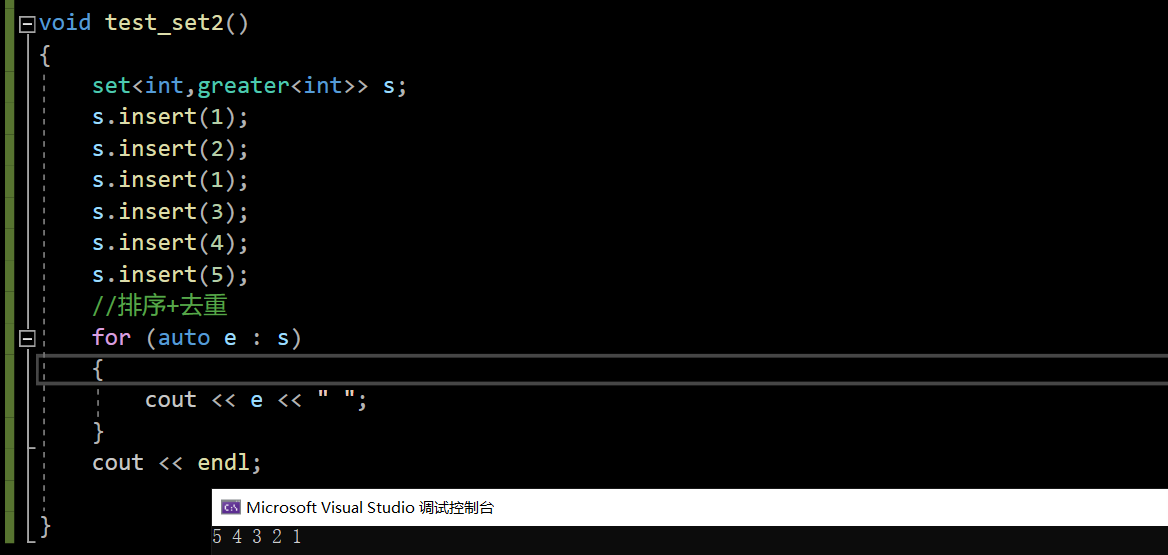
默认是升序,如果是想要降序:使用反向迭代器 仿函数:less👉greater:
set的修改操作
find&&erase
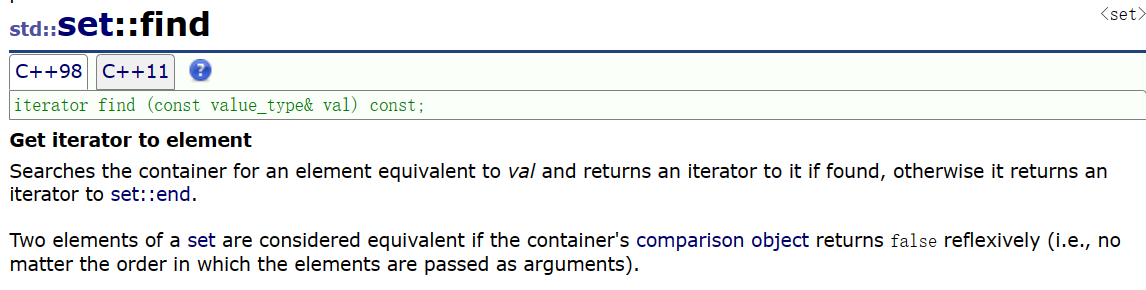

对于find和erase我们都是比较熟悉的了,我们可以直接上手代码的实现:
void test_set3()
{set<int> s;s.insert(1);s.insert(2);s.insert(1);s.insert(3);s.insert(4);s.insert(5);//set<int>::iterator it = s.begin();auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;auto pos = s.find(3);//更快一点点,借助二叉树查找O(logN)//auto pos = find(s.begin(), s.end(), 3);//暴力查找O(N)if (pos != s.end()){s.erase(pos);}s.erase(1);for (auto e : s) cout << e << " ";cout << endl;
}
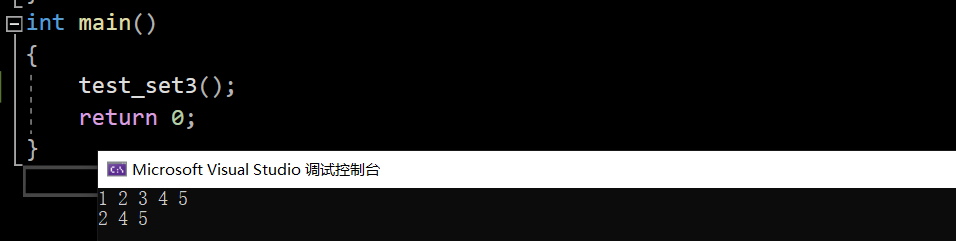
值得一提的是,set还有一个count接口,count:返回个数,可以判断一个值是否存在

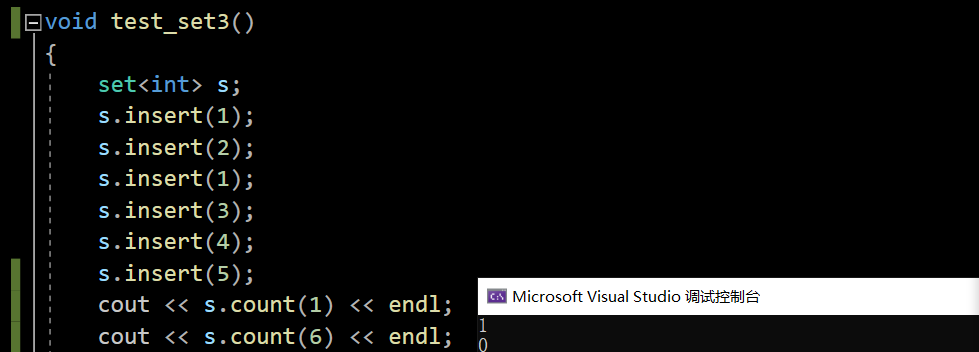
但是count不是为此设计的!是为了和multiset容器保持接口的一致性。
2.multiset
\1. multiset是按照特定顺序存储元素的容器,其中元素是可以
重复的。
\2. 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除。
\3. 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
\4. multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列。
\5. multiset底层结构为二叉搜索树(红黑树)
上面说了这么多的内容,其实就是与set的区别是👉:multiset中的元素可以重复,set是中value是唯一的
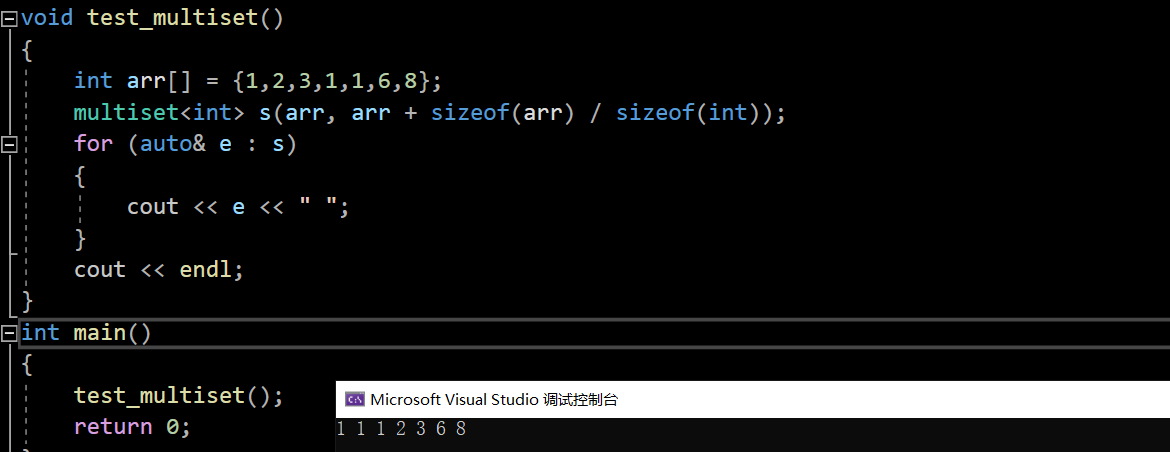
void test_multiset()
{int arr[] = {1,2,3,1,1,6,8};multiset<int> s(arr, arr + sizeof(arr) / sizeof(int));for (auto& e : s){cout << e << " ";}cout << endl;
}
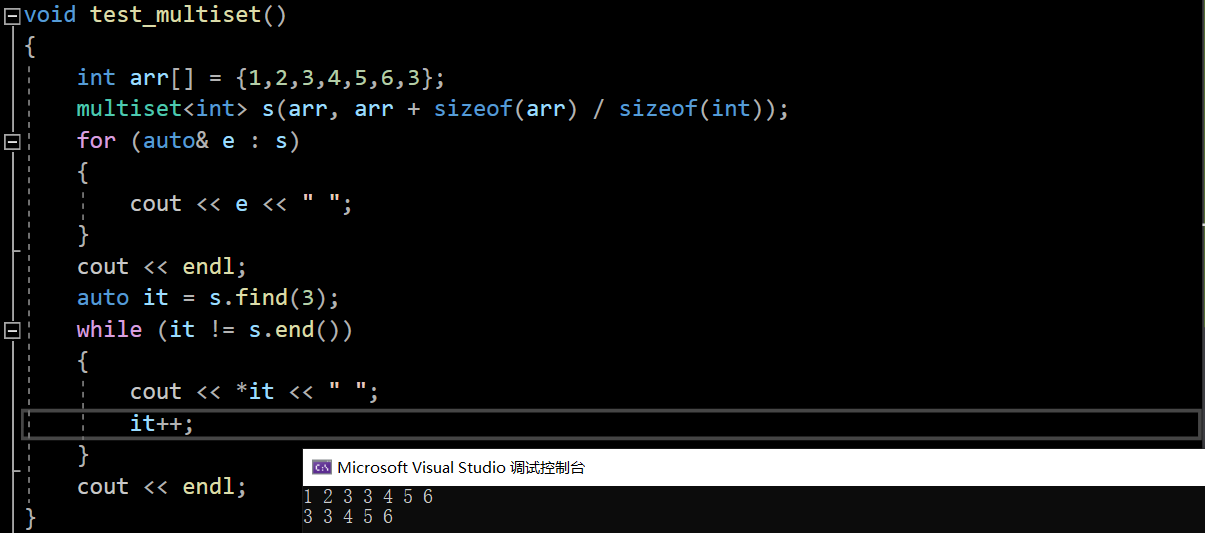
另外,如果有多个值相同,find返回的值是中序的第一个:
void test_multiset()
{int arr[] = {1,2,3,4,5,6,3};multiset<int> s(arr, arr + sizeof(arr) / sizeof(int));for (auto& e : s){cout << e << " ";}cout << endl;auto it = s.find(3);while (it != s.end()){cout << *it << " ";it++;}cout << endl;
}
3.map
\1. map是
关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
\2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:typedef pair value_type;
\3. 在内部,map中的元素总是按照键值key进行比较排序的。
\4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
\5. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
\6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))
map的模板参数

key: 键值对中key的类型
T:键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的空间配置器
map的构造

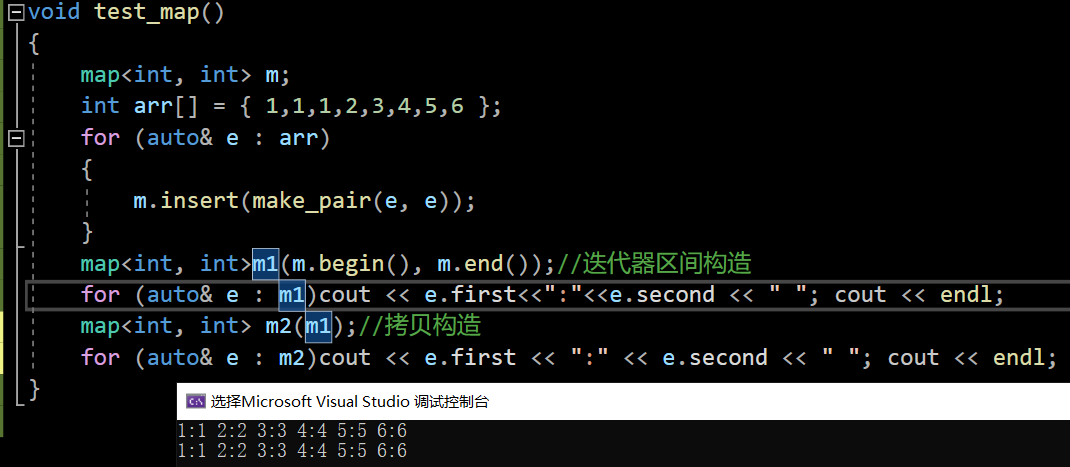
void test_map()
{map<int, int> m;int arr[] = { 1,1,1,2,3,4,5,6 };for (auto& e : arr){m.insert(make_pair(e, e));}map<int, int>m1(m.begin(), m.end());//迭代器区间构造for (auto& e : m1)cout << e.first<<":"<<e.second << " "; cout << endl;map<int, int> m2(m1);//拷贝构造for (auto& e : m2)cout << e.first << ":" << e.second << " "; cout << endl;
}
map的修改
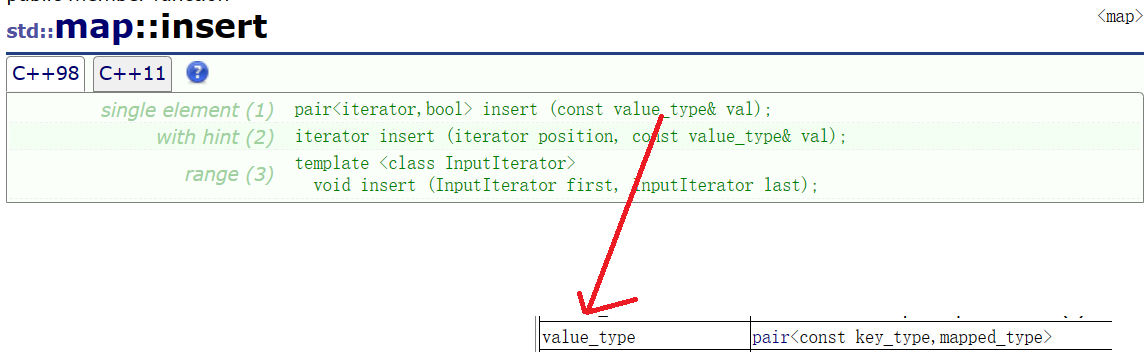
insert插入
void test_map1()
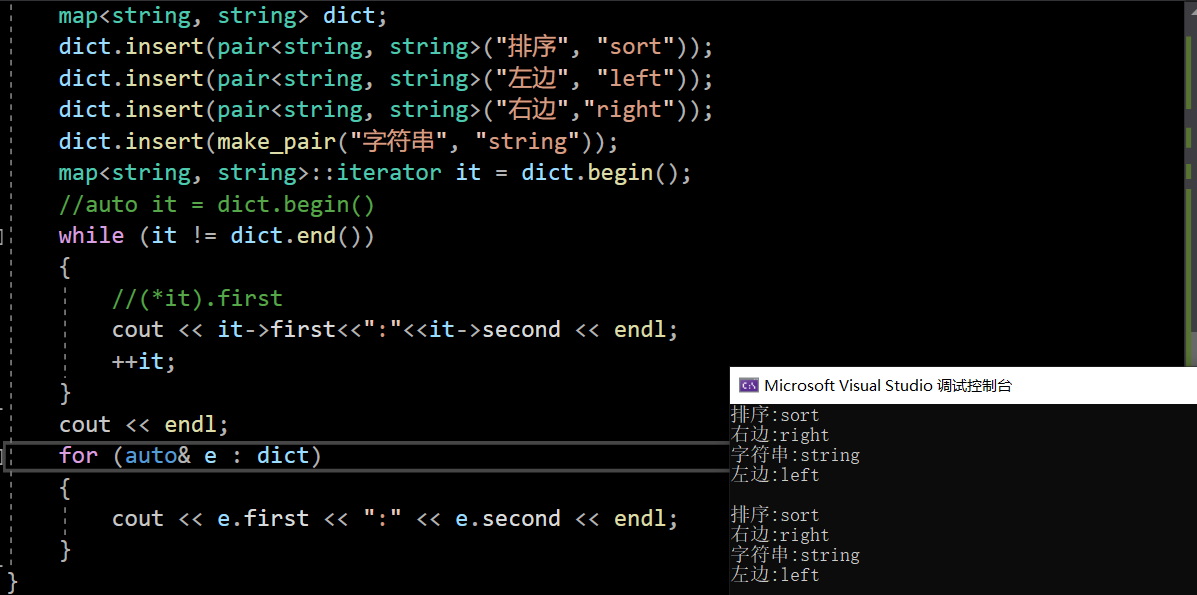
{map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边","right"));dict.insert(make_pair("字符串", "string"));map<string, string>::iterator it = dict.begin();//auto it = dict.begin()while (it != dict.end()){//(*it).firstcout << it->first<<":"<<it->second << endl;++it;}cout << endl;for (auto& e : dict){cout << e.first << ":" << e.second << endl;}
}
make_pair:函数模板,不需要像pair一样显示声明类型,而是通过传参自动推导,相比于typedef更好用一些

统计次数
第一种方法:迭代器
void test_map2()
{//统计水果出现的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){map<string, int>:: iterator it = countMap.find(e);if (it == countMap.end()){countMap.insert(make_pair(e, 1));}else{it->second++;}}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}
}

第二种方法:map[]的使用:
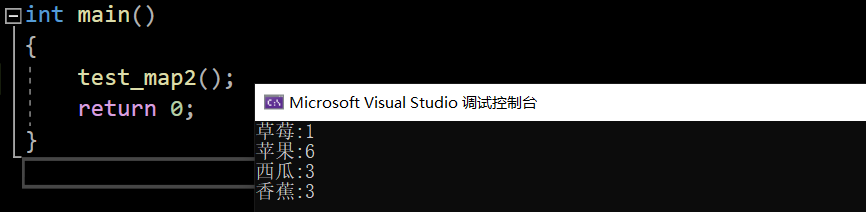
void test_map2()
{//统计水果出现的次数string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}
}
[]有三个功能:1.插入 2.修改 3.查找(给一个key,可以查找在不在,如果不在则可以插入,在的话既可以查找也可以进行修改value)
注意:[]用的时候要小心,不在的话会偷偷给你插入
下面我们来仔细看一看[]:[]实际上调用的是insert,insert有啥好调用的,我们要关注的是insert的返回值
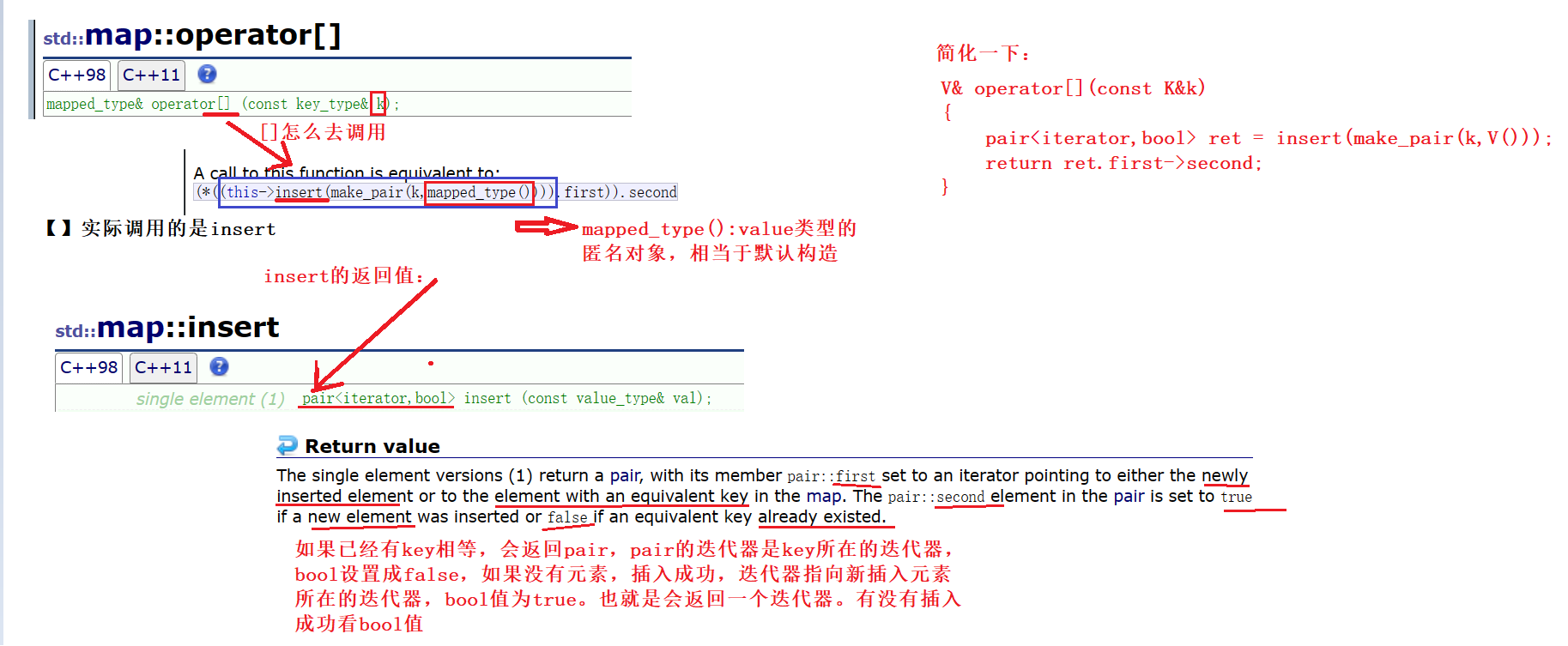
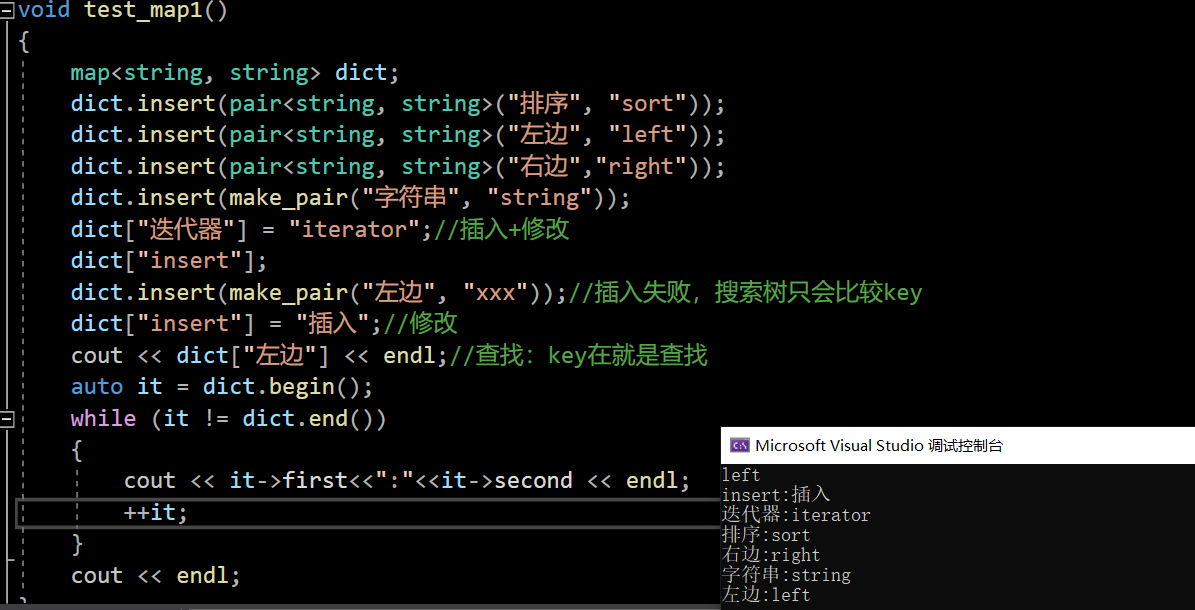
返回second的别名就可以进行修改了。简单运用一下[]把:
void test_map1()
{map<string, string> dict;dict.insert(pair<string, string>("排序", "sort"));dict.insert(pair<string, string>("左边", "left"));dict.insert(pair<string, string>("右边","right"));dict.insert(make_pair("字符串", "string"));dict["迭代器"] = "iterator";//插入+修改dict["insert"];dict.insert(make_pair("左边", "xxx"));//插入失败,搜索树只会比较keydict["insert"] = "插入";//修改cout << dict["左边"] << endl;//查找:key在就是查找auto it = dict.begin();while (it != dict.end()){cout << it->first<<":"<<it->second << endl;++it;}cout << endl;
}
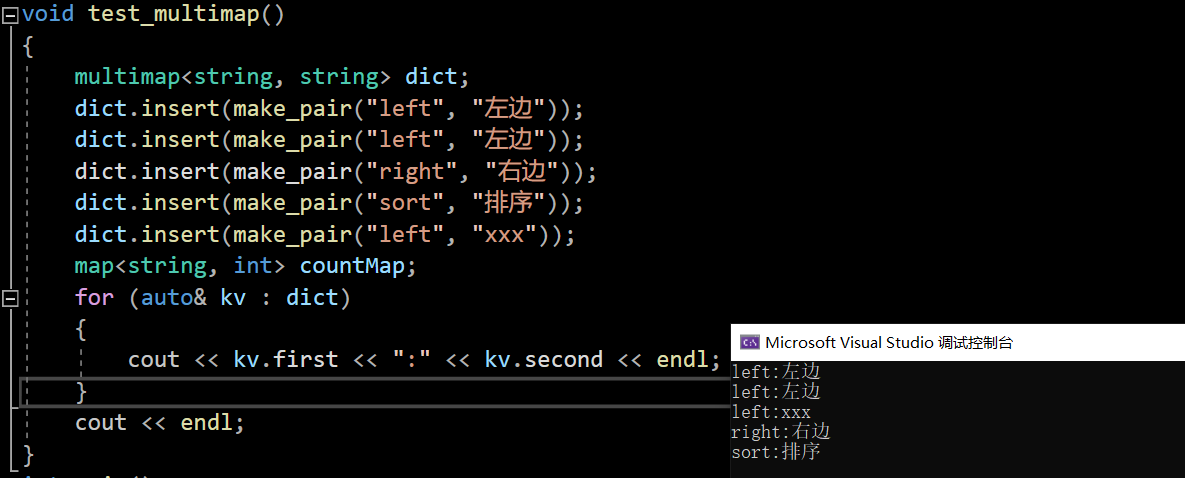
4.multimap
multimap容器与map容器的底层实现以及成员函数的接口都是基本一致,其中多个键值对之间的key是可以重复的
void test_multimap()
{multimap<string, string> dict;dict.insert(make_pair("left", "左边"));dict.insert(make_pair("left", "左边"));dict.insert(make_pair("right", "右边"));dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "xxx"));map<string, int> countMap;for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;
}
multimap并没有[],find()返回中序的第一个,剩下的没什么区别:
void test_multimap()
{multimap<string, string> dict;dict.insert(make_pair("left","左边"));dict.insert(make_pair("right", "右边"));dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "xxx"));map<string, int> countMap;for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;
}
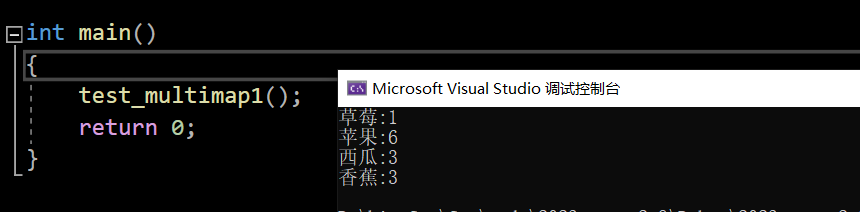
multimap同样是可以统计次数的:
void test_multimap1()
{multimap<string, int> countMap;string arr[] = { "苹果", "西瓜", "香蕉", "草莓", "苹果", "西瓜", "苹果","苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };for (auto& e : arr){auto it = countMap.find(e);if (it == countMap.end()){countMap.insert(make_pair(e, 1));}else{it->second++;}}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}
}
下面做两个题目试一试把👇
四、题目练习
前K个高频单词

给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
class Solution {
public:class greater{public:bool operator()(const pair<string,int>&l,const pair<string,int>& r){return l.second>r.second||(l.second==r.second&&l.first<r.first);}};vector<string> topKFrequent(vector<string>& words, int k) {unordered_map<string,int> countMap;for(auto&e:words) countMap[e]++;priority_queue<pair<string,int>,vector<pair<string,int>>,greater> pq;for(auto it = countMap.begin();it!=countMap.end();it++){pq.push(*it);if(pq.size()>k)pq.pop();}vector<string> ret;ret.resize(k);for(int i = k-1;i>=0;i--){ret[i] = pq.top().first;pq.pop();}return ret;}
};
两个数组的交集

给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序。
利用set的排序+去重特性,然后去进行比对,找出两个数组之间的交集:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//排序+去重set<int> s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());//比对算法逻辑auto it1 = s1.begin();auto it2 = s2.begin();vector<int> ret;while(it1!=s1.end()&&it2!=s2.end()){if(*it1==*it2){ret.push_back(*it1);it1++;it2++;}else if(*it1>*it2){it2++;}else{it1++;}}return ret;}
};
本篇结束…
相关文章:
【C++】关联式容器——map和set的使用
文章目录一、关联式容器二、键值对三、树形结构的关联式容器1.set2.multiset3.map4.multimap四、题目练习一、关联式容器 序列式容器📕:已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为…...

Promise的实现原理
作用:异步问题同步化解决方案,解决回调地狱、链式操作原理: 状态:pending、fufilled reject构造函数传入一个函数,resolve进入then,reject进入catch静态方法:resolve reject all any react ne…...
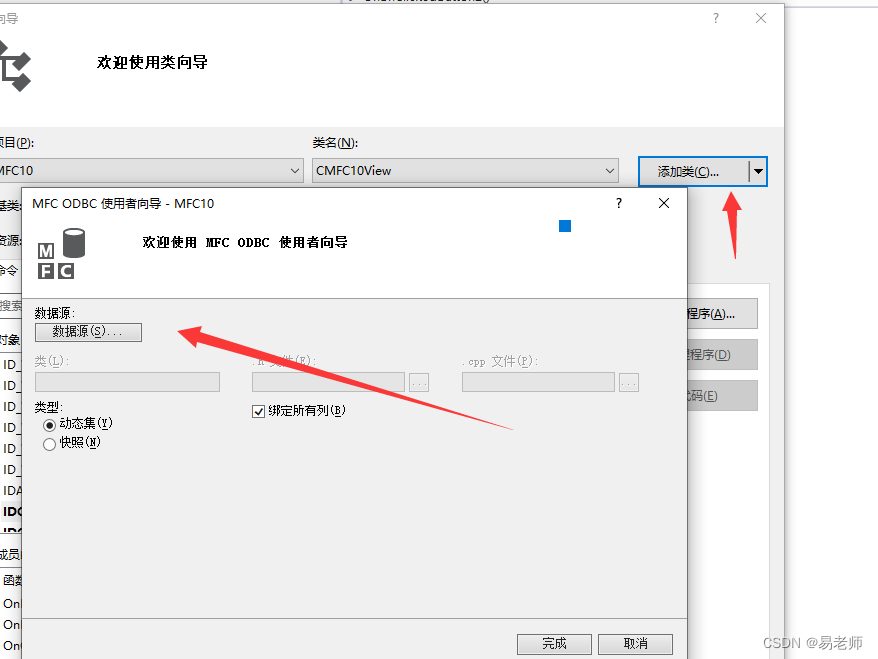
【MFC】数据库操作——ODBC(20)
ODBC:开放式数据库连接,是为解决异构数据库(不同数据库采用的数据存储方法不同)共享而产生的。ODBC API相对来说非常复杂,这里介绍MFC的ODBC类。 添加ODBC用户DSN 首先,在计算机中添加用户DSN:(WIN10下&a…...
旺店通与金蝶云星空对接集成采购入库单接口
旺店通旗舰奇门与金蝶云星空对接集成采购入库单查询连通销售退货新增V1(12-采购入库单集成方案-P)数据源系统:旺店通旗舰奇门旺店通是北京掌上先机网络科技有限公司旗下品牌,国内的零售云服务提供商,基于云计算SaaS服务模式,以体系化解决方案…...
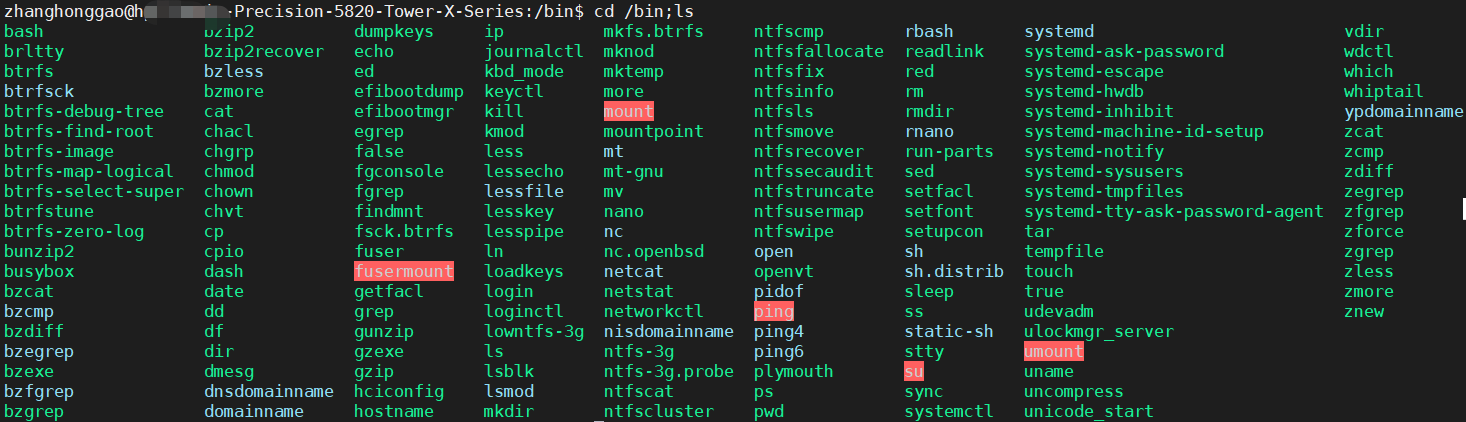
Linux基础-学会使用命令帮助
概述使用 whatis使用 man查看命令程序路径 which总结参考资料概述Linux 命令及其参数繁多,大多数人都是无法记住全部功能和具体参数意思的。在 linux 终端,面对命令不知道怎么用,或不记得命令的拼写及参数时,我们需要求助于系统的…...
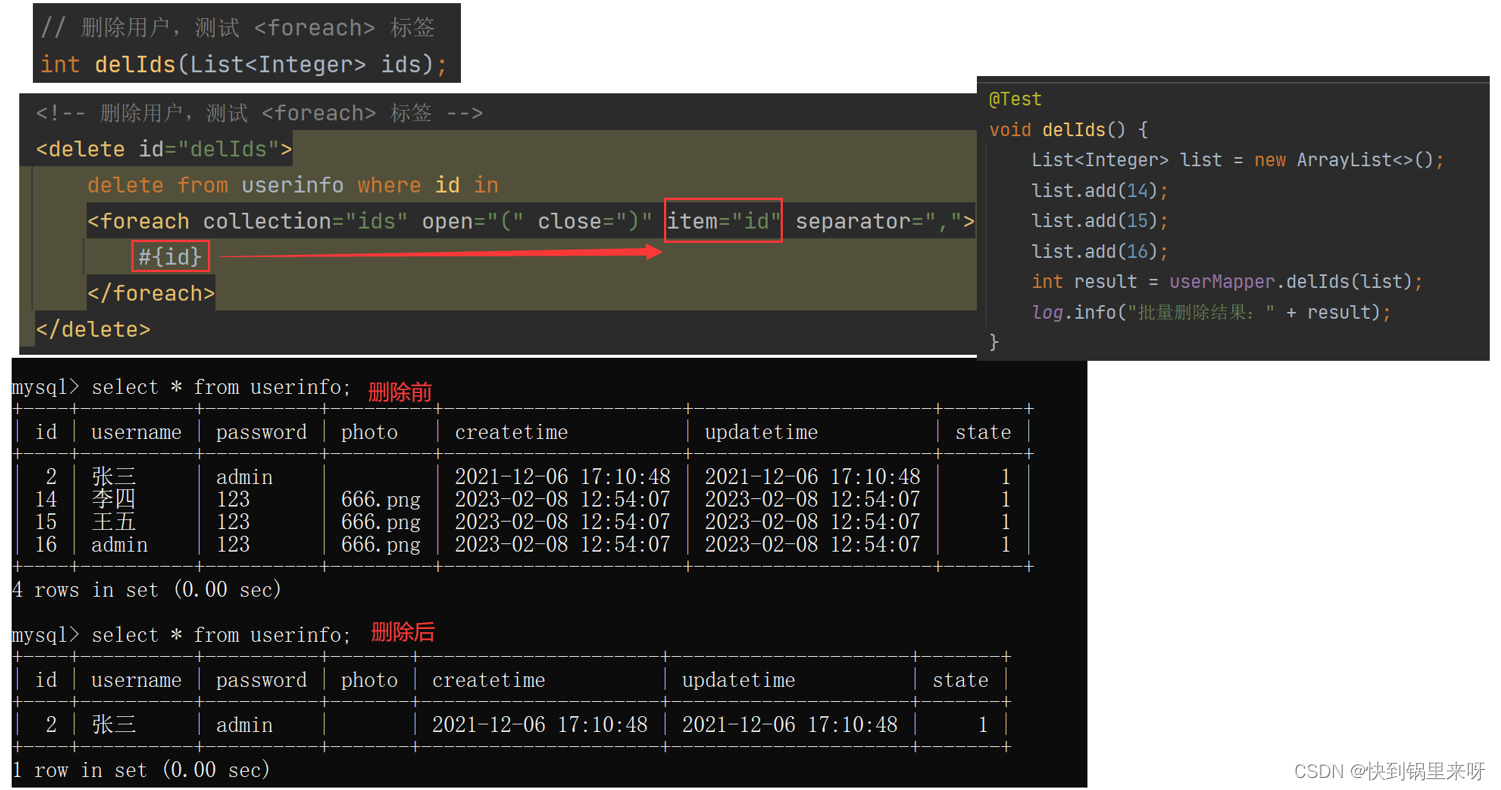
MyBatis 之四(动态SQL之 if、trim、where、set、foreach 标签)
文章目录动态 SQL1. if 标签2. trim 标签3. where 标签4. set 标签5. foreach 标签回顾一下,在上一篇 MyBatis 之三(查询操作 占位符#{} 与 ${}、like查询、resultMap、association、collection)中,学习了针对查询操作的相关知识点…...
 Practice 1006 Sign In and Sign Out)
PAT (Advanced Level) Practice 1006 Sign In and Sign Out
1006 Sign In and Sign Out题目翻译代码分数 25作者 CHEN, Yue单位 浙江大学At the beginning of every day, the first person who signs in the computer room will unlock the door, and the last one who signs out will lock the door. Given the records of signing in’…...

Android入门第64天-MVVM下瀑布流界面的完美实现-使用RecyclerView
前言 网上充满着不完善的基于RecyclerView的瀑布流实现,要么根本是错的、要么就是只知其一不知其二、要么就是一充诉了一堆无用代码、要么用的是古老的MVC设计模式。 一个真正的、用户体验类似于淘宝、抖音的瀑布流怎么实现目前基本为无解。因为本人正好自己空闲时也…...
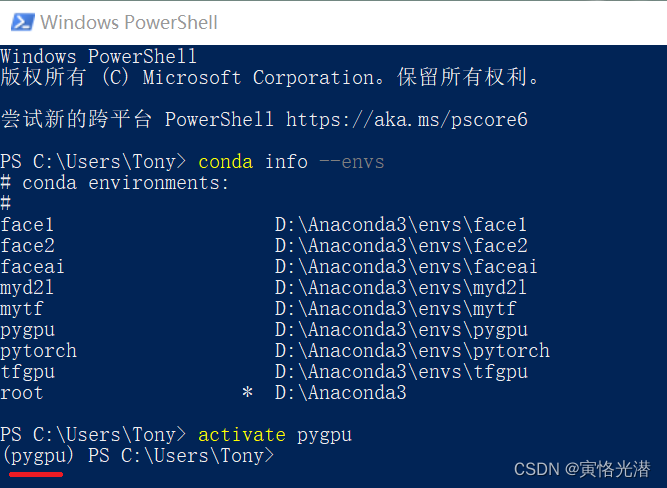
Windows PowerShell中成功进入conda虚拟环境
本人操作系统是Windows10(输入命令cmd或在运运行中输入winver查看)在cmd命令行中大家都很熟悉,很方便进入到指定创建了的虚拟环境中,那么在PowerShell中怎么进入呢?比如在VSCode中的TERMINAL使用的是PowerShell&#x…...

【C++】类与对象理解和学习(中)
专栏放在【C知识总结】,会持续更新,期待支持🌹六大默认成员函数前言每个类中都含有六大默认成员函数,也就是说,即使这个类是个空类,里面什么都没有写,但是编译器依然会自动生成六个默认成员函数…...
大英复习单词和翻译)
每日英语学习(11)大英复习单词和翻译
2023.2.20 单词 1.contemplate 思考、沉思 2.spark 激起 3.venture 冒险 4.stunning 极好的 5.dictate 影响 6.diplomatic 外交的 7.vicious 恶性的 8.premier 首要的 9.endeavor 努力 10.bypass 绕过 11.handicaps 不利因素 12.vulnerable 脆弱的 13.temperament 气质、性格…...

x79主板M.2无法识别固态硬盘
问题描述: 这几天在装电脑,买了块M.2接口固态硬盘。装上去始终无法读取到硬盘,一开始以为是寨板Bios问题不支持M.2的设备。更新了最新的BIOS然后还是没有识别出来,然而将日常用的电脑PM510硬盘装上发现可以识别,而且日常用电脑也…...

配置Tomcat性能优化
配置Tomcat性能优化 📒博客主页: 微笑的段嘉许博客主页 💻微信公众号:微笑的段嘉许 🎉欢迎关注🔎点赞👍收藏⭐留言📝 📌本文由微笑的段嘉许原创! Ǵ…...
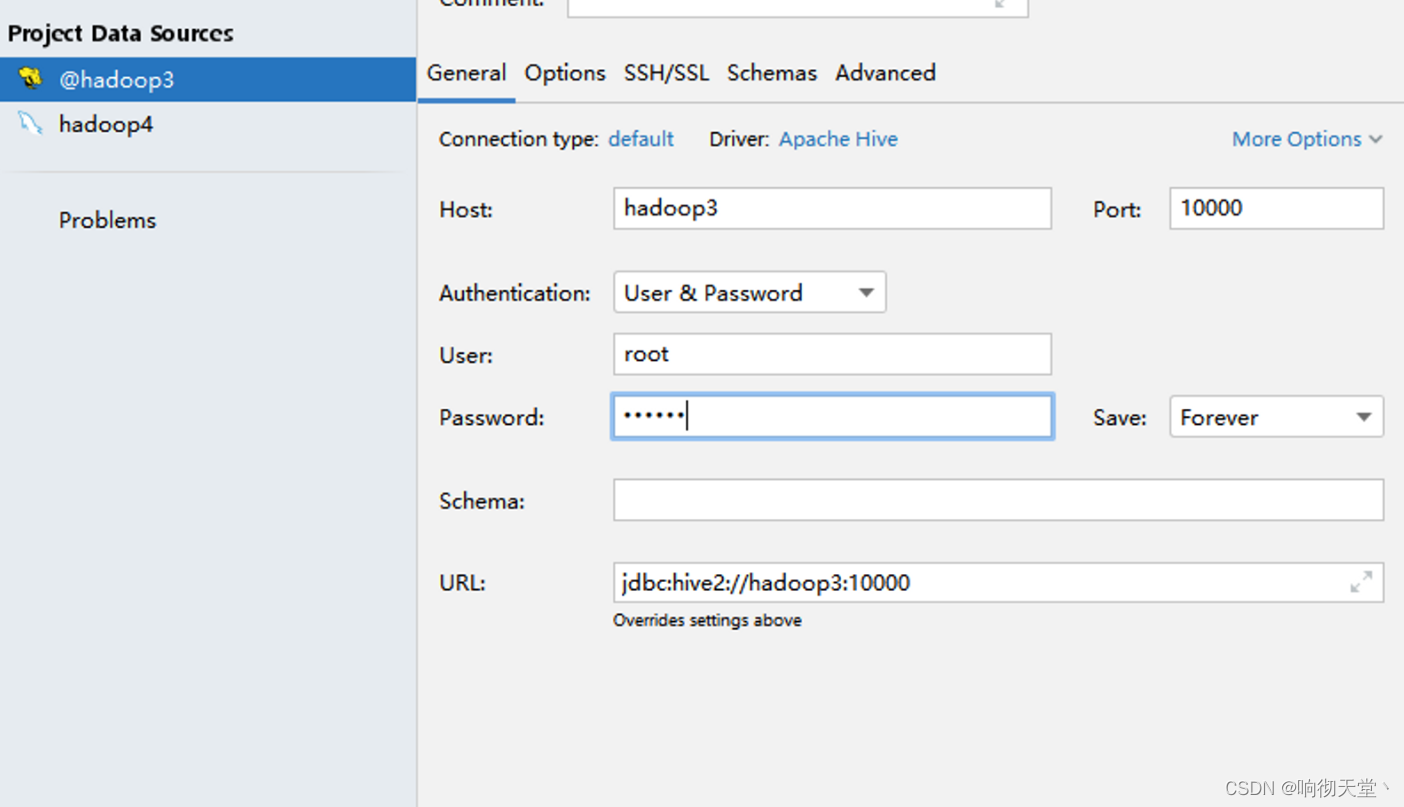
Hive3 安装方式详解,datagrid自定义驱动连接hive
1 Hive的安装方式 hive的安装一共有三种方式:内嵌模式、本地模式、远程模式。 元数据服务(metastore)作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接…...
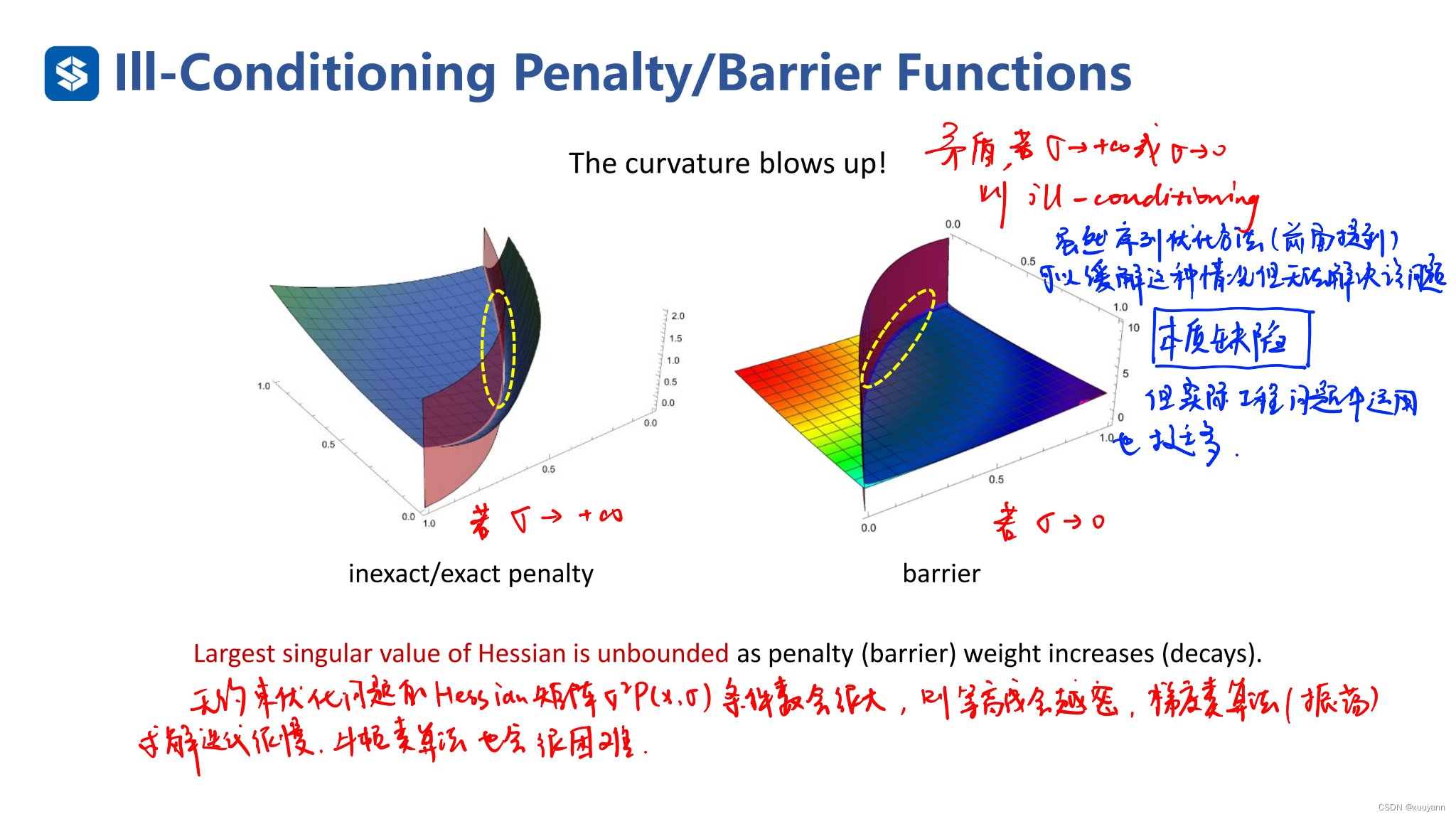
约束优化:约束优化的三种序列无约束优化方法(罚函数法)
文章目录约束优化:约束优化的三种序列无约束优化方法(罚函数法)外点罚函数法L2-罚函数法:非精确算法对于等式约束对于不等式约束L1-罚函数法:精确算法内点罚函数法:障碍函数法参考文献约束优化:…...

你真的会做APP UI自动化测试吗?我敢打赌百分之九十的人都不知道这个思路
目录 前言 一,开发语言选择 二,UI测试框架选择 1,Appium 2,Airtest 3,选择框架 三,单元测试框架选择 四,测试环境搭建 1,测试电脑选择 2,测试手机选择 3&#…...
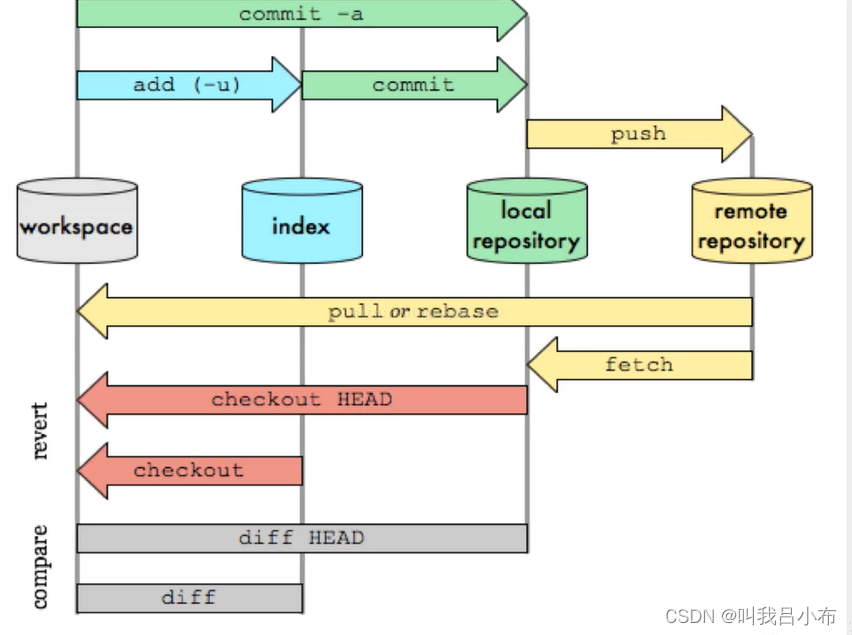
GIT:【基础三】Git工作核心原理
目录 一、Git本地四个工作区域 二、Git提交文件流程 一、Git本地四个工作区域 工作目录(Working Directory):电脑上存放开发代码的地方。暂存区(Stage/Index):用于l临时存放改动的文件,本质上只是一个文件,保存即将提交到文件列…...

【1.12 golang中的指针】
1. 指针 区别于C/C中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。 要搞明白Go语言中的指针需要先知道3个概念:指针地址、指针类型和指针取值。 1.1. Go语言中的指针 Go语言中的函数传参都是值拷贝,当我们想要修改某…...
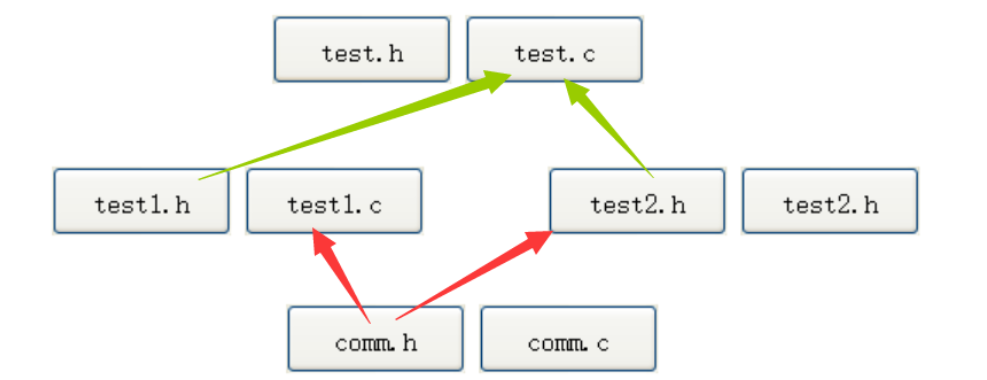
十五.程序环境和预处理
文章目录一.程序翻译环境和执行环境1.ANSI C 标准2.程序的翻译环境和执行环境二.程序编译和链接1.翻译环境2.编译本身的几个阶段3.运行环境三.预处理1.预定义符号2.#define(1)#define定义标识符(2)#define定义宏(3&…...
高并发系统设计之负载均衡
本文已收录至Github,推荐阅读 👉 Java随想录 文章目录DNS负载均衡Nginx负载均衡负载均衡算法负载均衡配置超时配置被动健康检查与主动健康检查LVS/F5Nginx当我们的应用单实例不能支撑用户请求时,此时就需要扩容,从一台服务器扩容到…...

华硕笔记本性能优化新选择:5分钟摆脱Armoury Crate臃肿体验
华硕笔记本性能优化新选择:5分钟摆脱Armoury Crate臃肿体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Stri…...

计算机应届生:简历好看≠能过面试
文章目录 前言一、简历"P图":美颜开过头,见面就翻车二、面试的"黑盒":你以为在考八股文,其实在考思维模型三、项目经历的"坑":你的秒杀系统,可能只是个Hello World四、技术深…...

PID调参不再玄学:用自平衡小车实战,带你搞懂比例、积分、微分到底在干嘛
PID调参实战:用自平衡小车拆解比例、积分、微分的控制艺术 平衡车在桌面上稳稳立住的那一刻,仿佛打破了物理定律——这个看似简单的动作背后,是控制理论中最经典的PID算法在发挥作用。但翻开任何一本自动控制教材,满页的微分方程…...
)
保姆级教程:用Python搞定数美滑块验证码(含DES加密还原与轨迹模拟)
Python实战:数美滑块验证码全流程破解指南 每次看到那个烦人的滑块验证码,是不是都有种想砸键盘的冲动?特别是当你的爬虫程序在数据采集过程中频繁触发数美验证时,整个项目进度可能都会被拖慢。作为爬虫开发者,我们需要…...

Linux内核中的进程调度高级话题
Linux内核中的进程调度高级话题 引言 进程调度是Linux内核中负责分配CPU时间的核心子系统,它决定了系统中各个进程的执行顺序和时间分配。随着系统复杂性的增加和硬件技术的发展,进程调度面临着越来越多的挑战。本文将深入探讨Linux内核中进程调度的高级…...

逆向工程入门:从Hook Cookie到RPC调用,一步步破解zp_stoken生成逻辑
逆向工程实战:解密zp_stoken生成与RPC远程调用技术解析 在当今数据驱动的互联网环境中,理解Web应用的安全机制成为开发者进阶的必修课。本文将带您深入一个典型的前端加密案例——zp_stoken的生成逻辑分析,并展示如何通过RPC技术实现自动化调…...

广州SEO优化服务有哪些
广州SEO优化服务:全面提升网站排名的关键策略 在当前竞争激烈的互联网环境中,广州SEO优化服务显得尤为重要。搜索引擎优化(SEO)不仅能够提高网站在搜索结果中的排名,还能有效地吸引更多的潜在客户。广州SEO优化服务有…...

bilibili-downloader 4K视频解锁工具:突破会员限制的全场景使用指南
bilibili-downloader 4K视频解锁工具:突破会员限制的全场景使用指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 在数字…...

Qwen3.5-9B-AWQ-4bit图文理解入门:5分钟掌握图片上传+中文提问+结果解析
Qwen3.5-9B-AWQ-4bit图文理解入门:5分钟掌握图片上传中文提问结果解析 1. 认识Qwen3.5-9B-AWQ-4bit模型 Qwen3.5-9B-AWQ-4bit是一款强大的多模态AI模型,它能同时理解图片和文字。简单来说,就像是一个能"看懂"图片内容的智能助手。…...

【NOIP】1999真题解析 luogu-P1014 Cantor 表 | GESP三、四级以上可练习
NOIP 1999 普及组真题,主要考察简单的二维矩阵模拟与通过寻找数学规律进行时间复杂度优化。可以用模拟法暴力求解,也能通过总结对角线的排列规律实现高效求解。GESP三、四级以上可练习。题目难度⭐⭐☆☆☆,洛谷难度等级普及−。 luogu-P101…...