【大数据】Hive 中的批量数据导入
Hive 中的批量数据导入
在博客【大数据】Hive 表中插入多条数据 中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将较为全面地介绍几种向 Hive 中批量导入数据的方法。
1.从本地文件系统加载(load)数据
load data [local] inpath '路径' [overwrite] into table 表名 [partition (分区字段=值,…)];
overwrite:表示覆盖表中已有数据,否则表示追加。- 此种加载方式是数据的复制。
(1)创建一张表。
hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';
(2)加载本地文件到 Hive。
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table default.student;
2.从 HDFS 文件系统加载(load)数据
从 HDFS 文件系统向表中加载数据,其实就是一个移动文件的操作,需要提前将数据上传到 HDFS 文件系统。
(1)上传文件到 HDFS(Linux 本地 /opt/module/datas/student.txt 文件传到 /user/victor/hive 目录)。
hive (default)> dfs -put /opt/module/datas/student.txt /user/victor/hive;
(2)从 HDFS 文件系统向表中加载数据。
hive (default)> load data inpath '/user/victor/hive/student.txt' into table default.student;
3.通过 as select 向表中插入数据
hive (default)> create table if not exists student3 as select id, name from student;
4.通过 insert into 向表中插入数据
insert into table test [partition(partcol1=val1, partcol2=val2 ...)] select id,name from student;
insert into:以追加数据的方式插入到表或分区,原有数据不会删除。
insert overwrite table test [partition(partcol1=val1, partcol2=val2 ...)] select id,name from student;
insert overwrite:覆盖表中已存在的数据。
(1)创建一张分区表。
hive (default)> create table student(id string, name string) partitioned by (month string) row format delimited fields terminated by '\t';
(2)基本插入数据。
hive (default)> insert into table student partition(month='201801') values('1004','wangwu');
(3)基本模式插入(根据单张表查询结果)。
hive (default)> insert overwrite table student partition(month='201802') select id, name from student where month='201801';
(4)多插入模式(只需要扫描一遍源表就可以生成多个不相交的输出)。
hive (default)> from studentinsert overwrite table student partition(month='201803')select id, name where month='201801'insert overwrite table student partition(month='201804')select id, name where month='201801';
5.通过 location 的方式
直接将数据文件上传到 location 指定的 HDFS 的目录下;
(1)创建表,并指定在 HDFS 上的位置。
hive (default)> create external table student(id int, name string)row format delimited fields terminated by '\t'location '/user/hive/warehouse/student';
(2)上传数据到 HDFS 上。
hive (default)> dfs -mkdir -p /user/hive/warehouse/student;
hive (default)> dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student;
(3)查询数据。
select * from student;
相关文章:

【大数据】Hive 中的批量数据导入
Hive 中的批量数据导入 在博客【大数据】Hive 表中插入多条数据 中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将较为全面地介绍几种向 H…...
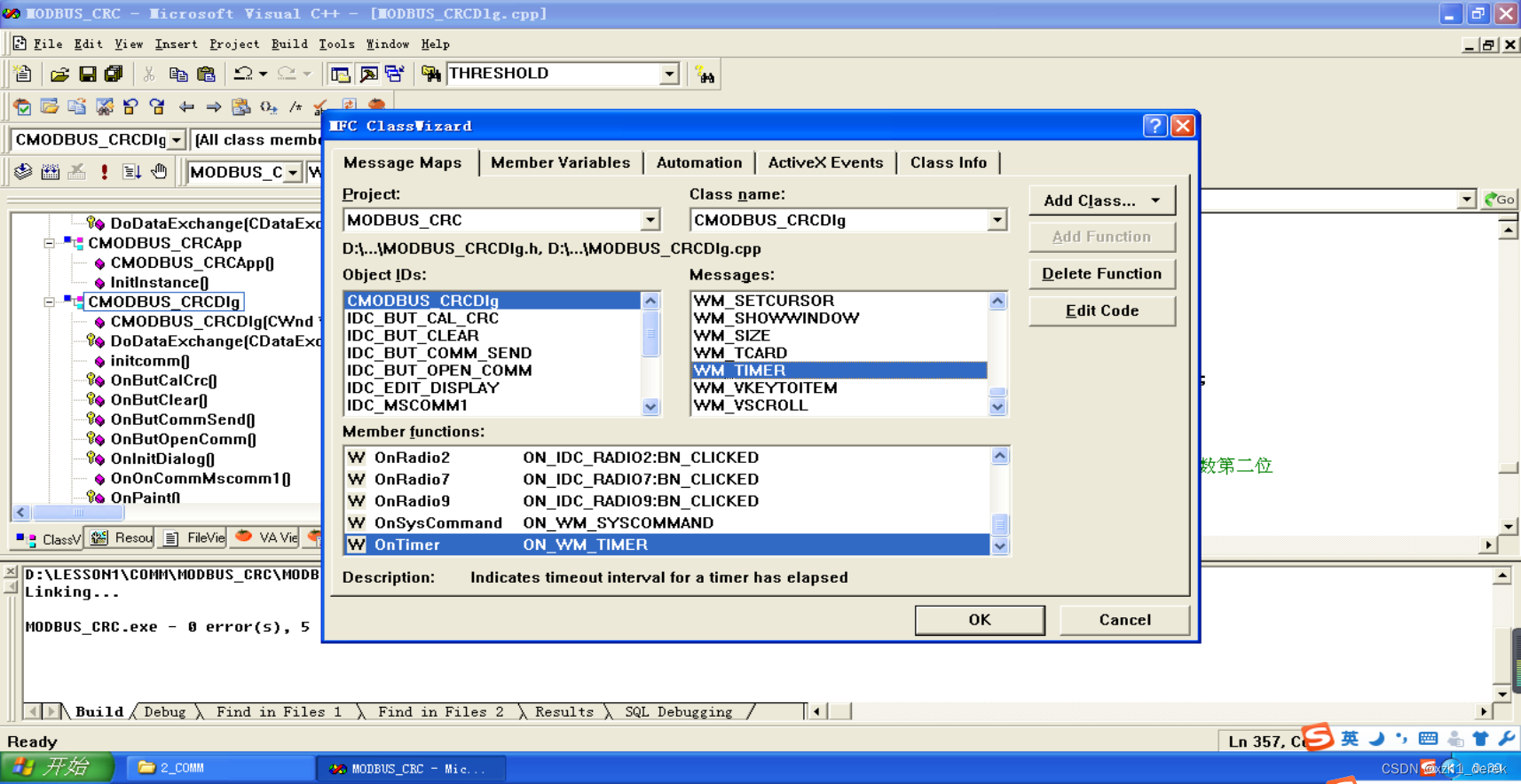
【Modbus通信实验三】数据切片问题
在做两个串口相互通信的实验中,当发送频率快一点时偶尔会遇到以下情景,即一次send中把原数据拆成两份发送,就会导致CRC校验错误。下图中6字节数据拆成42是把SetRThreshold()阈值设为2,当设为1的情况下则会拆成51。 一开始以为是缓…...
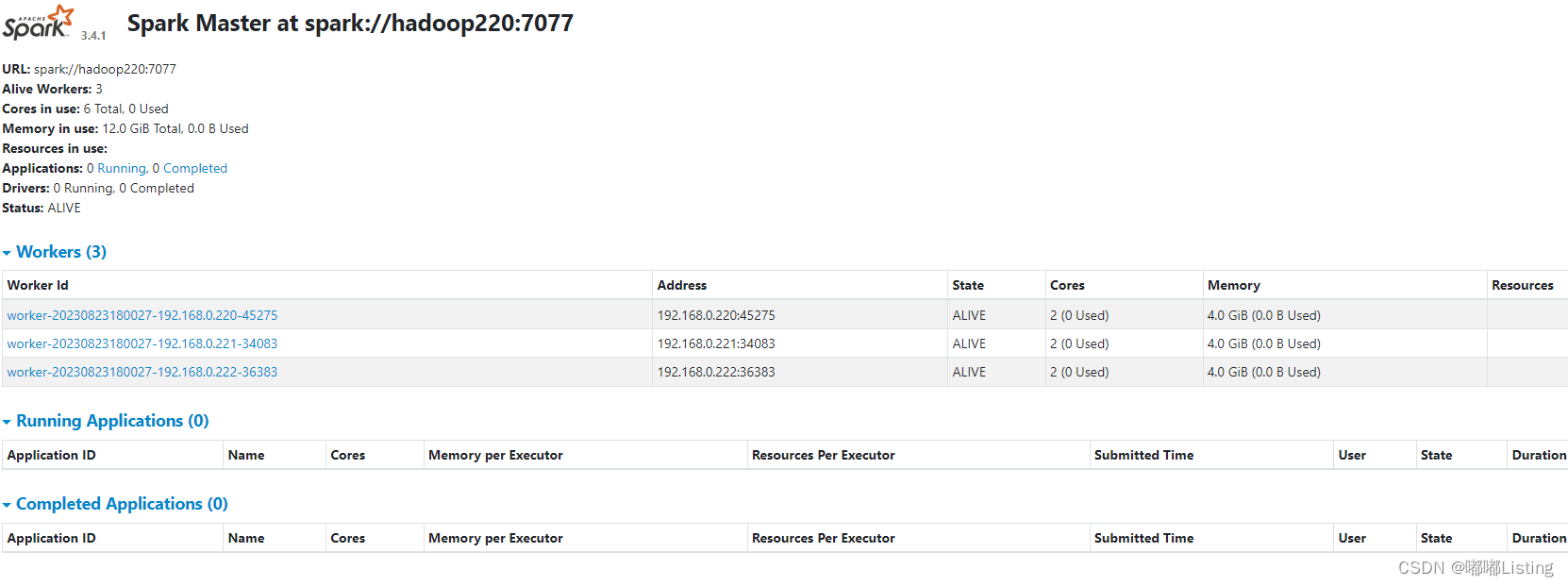
记录《现有docker中安装spark3.4.1》
基础docker环境中存储hadoop3--方便后续查看 参考: 实践: export JAVA_HOME/opt/apache/jdk1.8.0_333 export SPARK_MASTER_IP192.168.0.220 export SPARK_WORKER_MEMORY4g export SPARK_WORKER_CORES2 export SPARK_EXECUTOR_MEMORY4g export HADOOP_H…...

【3ds Max】练习——制作衣柜
目录 步骤 一、制作衣柜顶部 二、制作衣柜门板 三、制作衣柜底部 四、制作柜子腿部 五、制作柜子底板 步骤 一、制作衣柜顶部 1. 首先创建一个平面,然后将图片素材拖入平面 2. 平面大小和图片尺寸比例保持一致 3. 单机鼠标右键,选择对象属性 勾选…...

Spring-MVC的数据响应-19
在访问服务端MVC的时候,这个controller层进行相应操作之后 他要做两件事:页面跳转和返回字符串,在做完这些操作之后,我们一般进行页面展示:排除页面展示之外,有些需求可能直接回写给我们一些数据: 页面跳…...
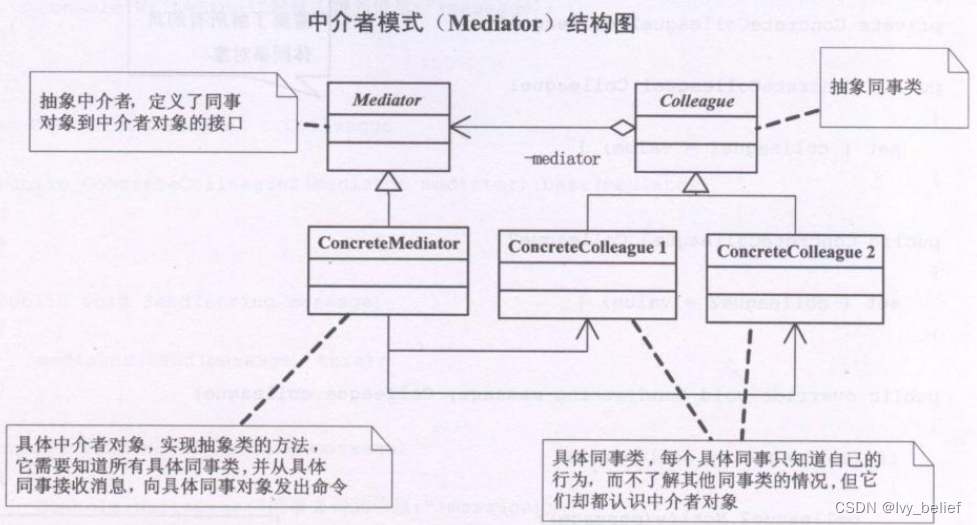
(三)行为模式:5、中介者模式(Mediator Pattern)(C++示例)
目录 1、中介者模式(Mediator Pattern)含义 2、中介者模式的UML图学习 3、中介者模式的应用场景 4、中介者模式的优缺点 (1)优点 (2)缺点 5、C实现中介者模式的实例 1、中介者模式(Media…...

期权是什么?期权的优缺点是什么?
期权是一种合约,有看涨期权和看跌期权两种类型,也就是做多和做空两个方向,走势标的物对应大盘指数,这也是期权与其他金融工具的主要区别之一,可以用于套利,对冲股票和激进下跌的风险,下文介绍期…...

目标检测任务数据集的数据增强中,图像垂直翻转和xml标注文件坐标调整
需求: 数据集的数据增强中,有时需要用到图像垂直翻转的操作,图像垂直翻转后,对应的xml标注文件也需要做坐标的调整。 解决方法: 使用pythonopencvimport xml.etree.ElementTree对图像垂直翻转和xml标…...

html5提供的FileReader是一种异步文件读取文件中的数据
前言:FileReader是一种异步文件读取机制,结合input:file可以很方便的读取本地文件。 input:file 在介绍FileReader之前,先简单介绍input的file类型。 <input type"file" id"file"> input的file类型会渲染为一个按…...

Linux学习记录——이십오 多线程(2)
文章目录 1、理解原生线程库线程局部存储 2、互斥1、并发代码(抢票)2、锁3、互斥锁的实现原理 3、线程封装1、线程本体2、封装锁 4、线程安全5、死锁6、线程同步1、条件变量1、接口2、demo代码 1、理解原生线程库 线程库在物理内存中存在,也…...
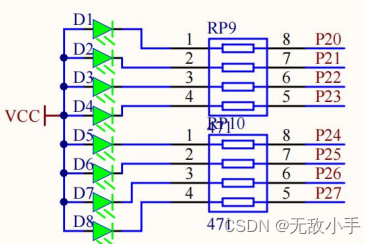
单片机(二)使用位移 让灯亮
一:硬件电路 P2 口: P2.0~ P2.7 是这些 I0 口 LED 阳极接 电源 , P20 口 为低电平 可以让 LED灯 亮 二:软件实现部分 两种 ① 通过循环 来展示从左 到右 #include "reg52.h"#define LED_PORT P2 // 定义单片机的P2端…...

探究代理服务器在网络安全与爬虫中的双重作用
在如今高度互联的世界中,代理服务器已经成为网络安全和爬虫开发的关键工具。本文将深入探讨Socks5代理、IP代理、网络安全、爬虫、HTTP等关键词,以揭示代理服务器在这两个领域中的双重作用,以及如何充分利用这些技术来保障安全和获取数据。 …...
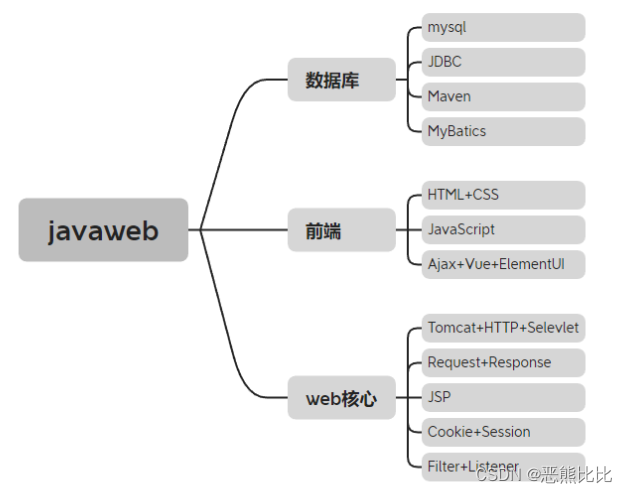
JavaWeb-学习目录
技术栈介绍 文章目录 1.数据库:1.1 Mysql1.2 JDBC1.3 Maven1.4 Mybatis 2.前端2.1 HTMLCSSJS2.2 AjaxVueElementUI 3. Web核心3.1 TomcatHttpServlet3.2 RequestResponse3.3 JSP3.4 CookieSession3.5 FilterListener 1.数据库: 1.1 Mysql mysql&#…...

C语言题目 - 调用qsort函数对数组进行排序
题目 如题 思路 其实没什么难的,只要严格按照 qsort 函数的参数来填充即可,这里要用到函数指针。 qsort 函数的原型如下: void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void *)); 参数说明&…...
Matplotlib学习笔记
Matplotlib数据可视化库 jupyter notebook优势 画图优势,画图与数据展示同时进行。数据展示优势,不需要二次运行,结果数据会保留。 Matplotlib画图工具 专用于开发2D图表以渐进、交互式方式实现数据可视化 常规绘图方法 子图与标注 想要…...

对比flink cdc和canal获取mysql binlog优缺点
Flink CDC和Canal都是用于获取MySQL binlog的工具,但是有以下几点优缺点对比: Flink CDC是一个基于Flink的库,可以直接在Flink中使用,无需额外的组件或服务,而Canal是一个独立的服务,需要单独部署和运行&a…...
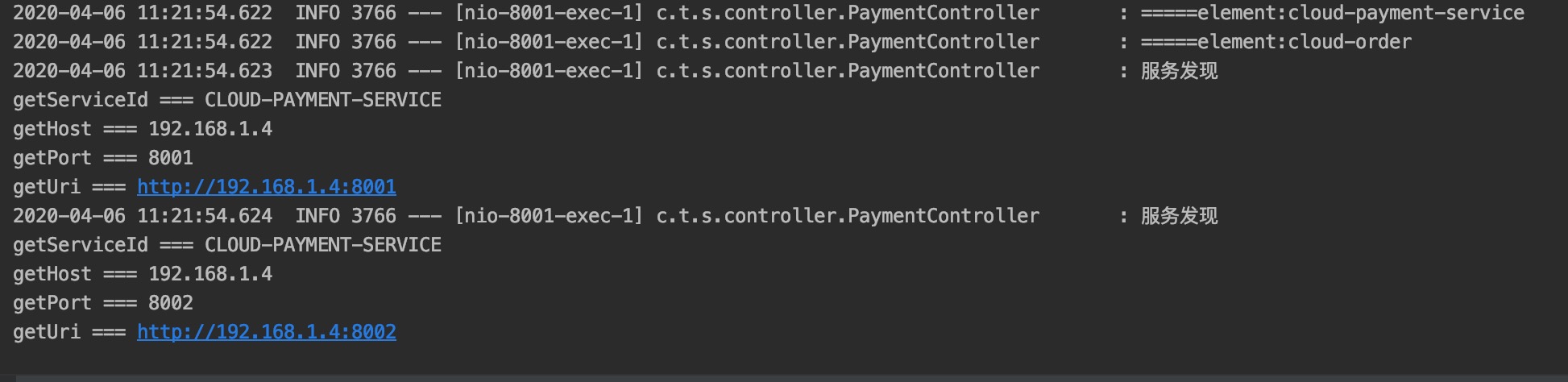
SpringCloud学习笔记(三)_服务提供者集群与服务发现Discovery
服务提供者集群 既然SpringCloud的是微服务结构,那么对于同一种服务,当然不可能只有一个节点,需要部署多个节点 架构图如下: 由上可以看出存在多个同一种服务提供者(Service Provider) 搭建服务提供者集…...
.NET 8 Preview 7 中的 ASP.NET Core 更新
作者:Daniel Roth 排版:Alan Wang .NET 8 Preview 7 现在已经发布,其中包括了对 ASP.NET Core 的许多重要更新。 以下是预览版本中新增功能的摘要: 服务器和中间件 防伪中间件 API 编写 最小 API 的防伪集成 Native AOT 请求委托…...

Ajax+Vue+ElementUI
文章目录 1.Ajax1.1 介绍1.2 Ajax快速入门1.3 案例-用户注册时,检测用户名是否数据库已经存在1.4 Axios1.4.1 Axios快速入门1.4.2 请求别名 1.5 JSON1.5.1 Json的基础语法1.5.2 FastJson的使用5.3.2 Fastjson 使用 2. Vue2.1 介绍2.2 Vue快速入门2.3 Vue常用指令和生…...

python读取pdf、doc、docx、ppt、pptx文件内容
使用python读取文件,其中pdf、docx、pptx可以直接读,.ppt和.doc文件不能直接读,需要转换成.pptx和.docx文件,并且需要区分系统 如果是linux系统,请先安装组件 #doc2docx yum install -y libreoffice-headless yum ins…...

IP2366至为芯支持C口双向快充的140W多串锂电池充放电SOC芯片
英集芯IP2366是一款应用于移动电源、电动工具、智能家居、储能电源等方案的多串锂电池充电SOC芯片。支持高达140W的双向同步升降压充放电,充电电流可达5A。支持2至6节锂电池/磷酸铁锂电池串联,集成PD3.1、QC3.0等多种快充协议。内置14bit ADC,…...

windows构建mamba环境
收集必要的whl文件 在某🐟等平台或者是精密搜索找到以下whl文件 对于3.10 python triton-2.0.0-cp310-cp310-win_amd64.whl causal_conv1d-1.1.1-cp310-cp310-win_amd64.whl mamba_ssm-1.1.3-cp310-cp310-win_amd64.whl 对于3.11 python FuouM/mamba-ssm-windo…...

权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区
更多请点击: https://intelliparadigm.com 第一章:权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区 在企业级部署 Gemini Workspace 时,大量团队遭遇“功能可登录但协作不可用”的隐性故障。根本原因并非 …...

学术生产力革命已来,NotebookLM Agent如何把文献综述时间压缩83%?实测数据首次公开!
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Agent研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度理解与推理的 AI 助手,其内置的 Agent 能力可显著提升学术研究、技术调研与知识整合效率。当启用 Agent 模…...
)
UWB-IMU、UWB定位对比研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

公考备考提分真相:从学员视角解析粉笔讲练测评闭环教学体系
引言在公务员考试备考赛道中,无数考生都面临同一个核心困惑:花费时间和金钱报名培训机构,究竟能不能实现有效提分?不少备考者有过备考失利的经历,也踩过传统公考培训的诸多坑。很多传统课程老师讲课条理清晰、内容丰富…...

首次接入Taotoken时如何通过模型广场测试不同模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次接入Taotoken时如何通过模型广场测试不同模型的响应效果 当你开始使用Taotoken平台,面对众多可选的模型࿰…...

必看!移动岗亭厂家交货及时性测评,日硕科技排名第一!
《【移动岗亭厂家交货及时性】哪家好:专业深度测评排名前五》开篇:定下基调在当今快节奏的商业环境中,移动岗亭的采购方对于厂家的交货及时性愈发重视。及时的交货能够确保项目按时推进,避免不必要的延误和损失。本次测评的目的就…...

Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生
Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下的PL2303串口设备无法正…...

ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件
ncmdumpGUI终极使用教程:轻松解密网易云音乐NCM文件 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的NCM格式文件无法在普通…...