股票预测和使用LSTM(长期-短期-记忆)的预测
一、说明
成功分析和预测后的绘图预测。
LSTM的核心是递归神经网络(RNN)的变体,专门用于解决困扰传统RNN的梯度消失问题。梯度消失问题是指网络中早期层的梯度变得越来越小,阻碍了它们捕获长期依赖性的能力的现象。LSTM 通过整合存储单元、门和精心设计的连接来克服这一限制,使其能够在较长的时间间隔内有选择地保留和传播信息。这种独特的架构使 LSTM 模型能够捕获顺序数据中错综复杂的时间关系,使其特别适合预测时间序列数据,例如股票价格。
二、LSTM记忆网络
要了解更多回合 LSTM ,请访问 :
了解长短期记忆 (LSTM) 算法
LSTM 算法是帮助机器理解和预测复杂数据的强大工具。了解 LSTM 如何适用于机器学习...
让我们来看看我们的股票数据分析和预测。
2.1 导入所需库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import math
from sklearn.metrics import mean_squared_error在这里,我们导入了熊猫,用于绘图的matplotlib,用于预处理的numpy,sklearn用于预处理,尺度调整和误差计算,以及用于模型构建的张量流。
2.2 我移植数据集
您可以在以下 GitHub 存储库中找到我使用的数据集。
GitHub - mwitiderrick/stockprice: Stock Price Prediction 教程的数据和笔记本
股票价格预测教程的数据和笔记本 - GitHub - mwitiderrick/stockprice:数据和笔记本...
github.com
df = pd.read_csv('D:/stockprice-master/NSE-TATAGLOBAL.csv')
df.head()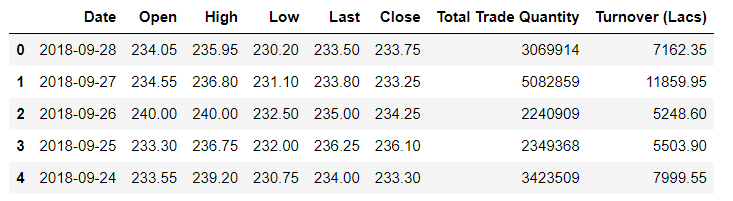
三、数据分析
df2 = df.reset_index()['Close']
plt.plot(df2)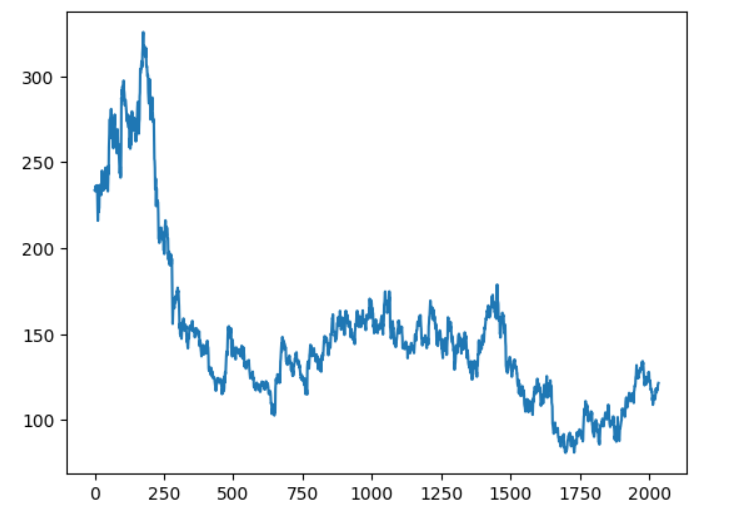
图表显示数据集中的库存流
我们将在收盘价列上进行股票预测。
3.1 数据预处理
scaler = MinMaxScaler()
df2 = scaler.fit_transform(np.array(df2).reshape(-1,1))
df2.shape(2035, 1)
在这里,我们缩小 (0,1) 之间的值。
3.2 训练-测试拆分
train_size = int(len(df2)*0.65)
test_size = len(df2) - train_size
train_data,test_data = df2[0:train_size,:],df2[train_size:len(df2),:1]在这里,我们获取了 65% 的数据用于训练,其余 35% 用于测试。
def create_dataset(dataset, time_step = 1):dataX,dataY = [],[]for i in range(len(dataset)-time_step-1):a = dataset[i:(i+time_step),0]dataX.append(a)dataY.append(dataset[i + time_step,0])return np.array(dataX),np.array(dataY)创建一个函数作为 create_dataset(),它根据我们采取的时间步长将数据集分成 2 个。第一个数据集,即;dataX 将值作为其输入,第二个数据集 dataY 将值作为输出。基本上,它从上述数据集创建一个数据集矩阵。
# calling the create dataset function to split the data into
# input output datasets with time step 100
time_step = 100
X_train,Y_train = create_dataset(train_data,time_step)
X_test,Y_test = create_dataset(test_data,time_step)# checking values
print(X_train.shape)
print(X_train)
print(X_test.shape)
print(Y_test.shape)(1221, 100)
[[0.62418301 0.62214052 0.62622549 ...0.83455882 0.86213235 0.85273693]
[0.62214052 0.62622549 0.63378268 ...0.86213235 0.85273693 0.87111928]
[0.62622549 0.63378268 0.62234477 ...0.85273693 0.87111928 0.84497549]
...
[0.34517974 0.31781046 0.33047386 ...0.2816585 0.27001634 0.26531863]
[0.31781046 0.33047386 0.32128268 ...0.27001634 0.26531863 0.27389706]
[0.33047386 0.32128268 0.34007353 ...0.26531863 0.27389706 0.25347222]](612, 100)(612,)
四、创建和拟合 LSTM 模型
model = Sequential()
model.add(LSTM(50,return_sequences = True,input_shape = (X_train.shape[1],1)))
model.add(LSTM(50,return_sequences = True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss = 'mean_squared_error',optimizer = 'adam')在这里,我们添加了 4 层 LSTM,其中 1 层作为输入层,2 层作为隐藏层,1 层作为输出层作为 Dense。 在前 3 层中,我们取了 50 个神经元和 1 个用于输出。
我们使用亚当优化器编译模型,该优化器将使用均方误差计算损失。
model.summary()
model.fit(X_train,Y_train,validation_data = (X_test,Y_test),epochs = 100,batch_size = 64,verbose = 1)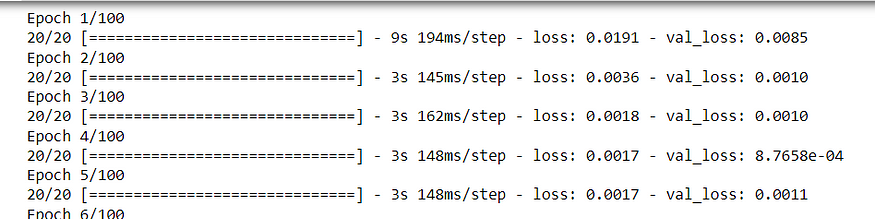

在这里,该模型已经训练了 100 个 epoch,每个 epoch 的批大小为 64。
五、预测和检查性能矩阵
train_predict = model.predict(X_train)
test_predict = model. Predict(X_test)# transform to original form
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)当我们在 0 和 1 中缩小数据集的值时,我们需要再次反转变换,以便在图上获得准确的预测值,因此,这里我们反转两个预测的变换。
现在是计算rmse性能矩阵的时候了。
print(math.sqrt(mean_squared_error(Y_train,train_predict)))
print(math.sqrt(mean_squared_error(Y_test,test_predict)))166.74853517776896
116.51567464682968
在这里,计算的两个值都非常接近,即;差值小于 50,表示模型精度良好。
六 图形绘制
look_back = 100trainPredictPlot = np.empty_like(df2)
trainPredictPlot[:,:] = np.nan
trainPredictPlot[look_back : len(train_predict)+look_back,:] = train_predict回看变量采用当前值后面的值数,即;记住与 LSTM 相同的前 100 个值。在这里,每次绘制图形时,trainPredictionPlot 都会在它们后面取 100 个值并绘制它。绘图从前 100 个值开始,一直到火车预测的长度 + 回溯,即 100。
testPredictPlot = np.empty_like(df2)
testPredictPlot[:,:] = np.nan
testPredictPlot[len(train_predict)+(look_back)*2 + 1 : len(df2) - 1,:] = test_predictTestPredictionPlot 也是如此,但这次它采用Train_predict旁边的值。这里回顾将从火车预测结束的地方开始。
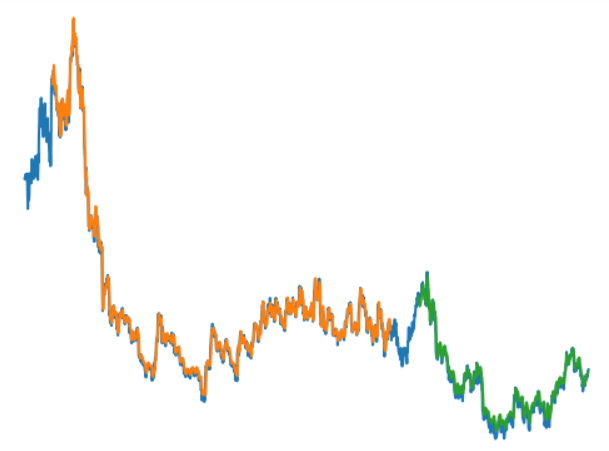
plt.plot(scaler.inverse_transform(df2))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()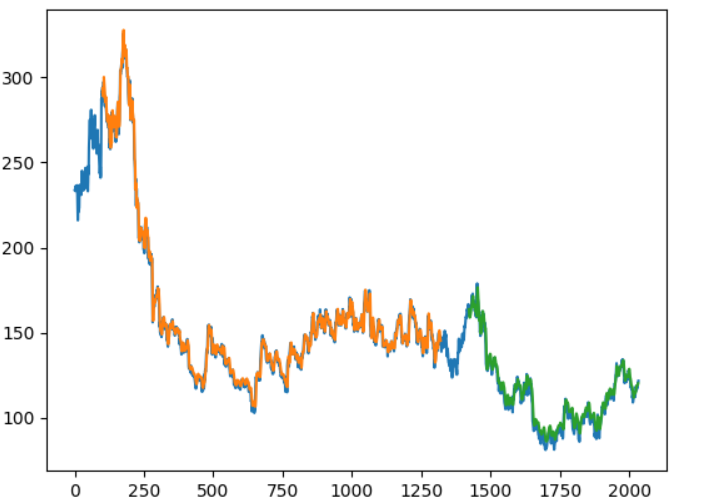
在这里,橙色是TrainPredictionPlot,绿色是TestPredictionPplot,蓝色是实际数据集。因此,我们可以看到我们的模型很好地预测了股票价格。
该模型仅用于学习目的,不建议用于任何未来的投资。普拉吉瓦尔·乔汉
七、结论
总之,利用长期短期记忆(LSTM)进行股票市场预测代表了财务预测领域的重大飞跃。这种基于深度学习力量的创新方法展示了其捕获历史股票市场数据中复杂模式和依赖关系的潜力。通过将LSTM模型纳入投资策略,交易者和投资者可以在驾驭股票市场的不可预测性中获得宝贵的优势。
相关文章:
股票预测和使用LSTM(长期-短期-记忆)的预测
一、说明 准确预测股市走势长期以来一直是投资者和交易员难以实现的目标。虽然多年来出现了无数的策略和模型,但有一种方法最近因其能够捕获历史数据中的复杂模式和依赖关系而获得了显着的关注:长短期记忆(LSTM)。利用深度学习的力…...
Docker搭建个人网盘、私有仓库
1、使用mysql:5.6和 owncloud 镜像,构建一个个人网盘 [rootlocalhost ~]# docker pull mysql:5.6 [rootlocalhost ~]# docker pull owncloud [rootlocalhost ~]# docker run -itd --name mysql --env MYSQL_ROOT_PASSWORD123456 mysql:5.6 [rootlocalhost ~]# doc…...
3种获取OpenStreetMap数据的方法【OSM】
OpenStreetMap 是每个人都可以编辑的世界地图。 这意味着你可以纠正错误、添加新地点,甚至自己为地图做出贡献! 这是一个社区驱动的项目,拥有数百万注册用户。 这是一个社区驱动的项目,旨在在开放许可下向每个人提供所有地理数据。…...
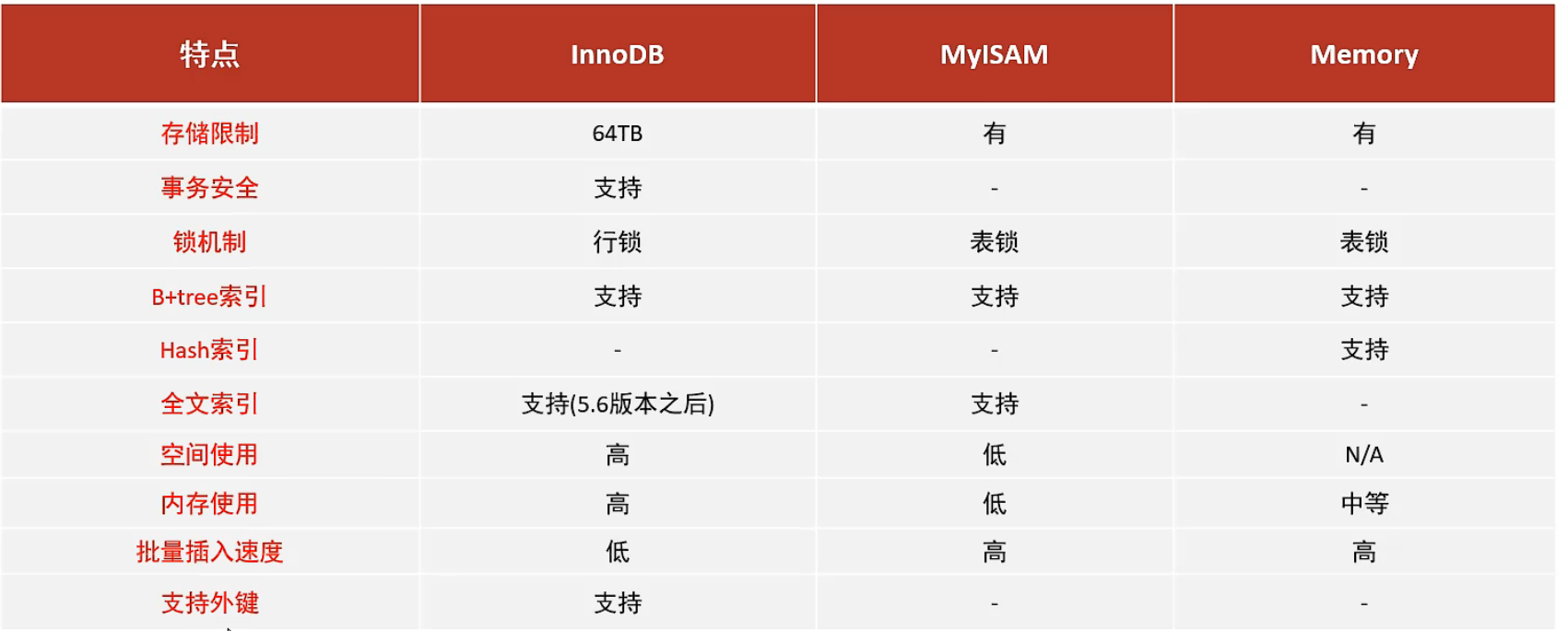
数据处理与统计分析——MySQL与SQL
这里写目录标题 1、初识数据库1.1、什么是数据库1.2、数据库分类1.3、相关概念1.4、MySQL及其安装1.5、基本命令 2、基本命令2.1、操作数据库2.2、数据库的列类型2.3、数据库的字段属性2.4 创建和删除数据库表2.5、数据库存储引擎2.6、修改数据库 3、MySQL数据管理3.1、外键 My…...

OpenCV之特征点匹配
特征点选取 特征点探测方法有goodFeaturesToTrack(),cornerHarris()和SURF()。一般使用goodFeaturesToTrack()就能获得很好的特征点。goodFeaturesToTrack()定义: void goodFeaturesToTrack( InputArray image, OutputArray corners,int maxCorners, double qualit…...

浅谈开关柜绝缘状态检测与故障诊断
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:电力开关柜作为电力系统的关键设备广泛应用于输电配电网络,其运行可靠性直接影响着电力系统供电质量及安全性能。开关柜绝缘状态检测与故障诊断是及时维修、更换和预防绝缘故障的重要技术手段。在阐述开关柜绝…...

Mybatis 动态 SQL
动态 SQL 1. if 标签2. trim 标签3. where 标签4. set 标签5. foreach 标签 1. if 标签 if 标签有很多应用场景, 例如: 在用户进行注册是有些是必填项有些是选填项, 这就会导致前端传入的参数不固定如果还是将参数写死就很难处理, 这时就可以使用 if 标签进行判断 <insert …...

Android studio之 build.gradle配置
在使用Android studio创建项目会出现两个build.gradle: 一. Project项目级别的build.gradle (1)、buildscript{}闭包里是gradle脚本执行所需依赖,分别是对应的maven库和插件。 闭包下包含: 1、repositories闭包 2、d…...
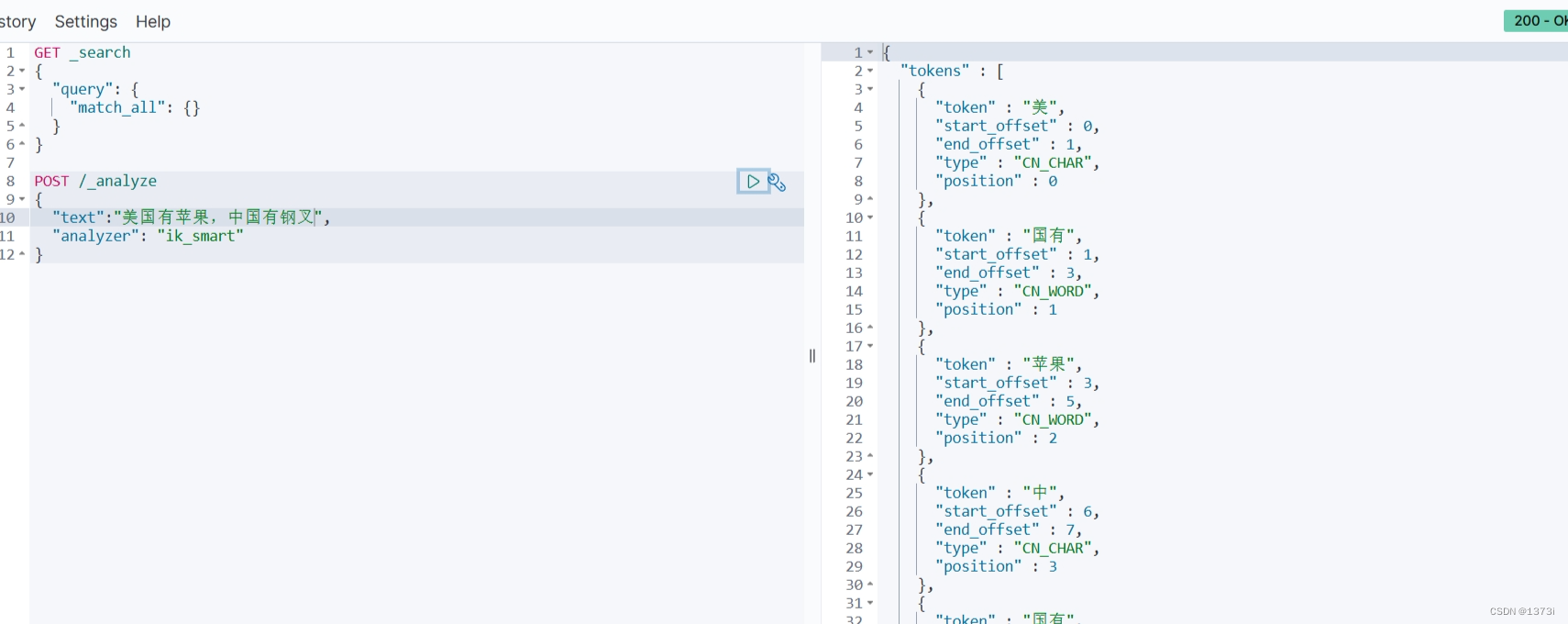
【ElasticSearch】一键安装IK分词器无需其他操作
要注意的时下面命令中的es是我容器的名称,要换成你对应的es容器名 docker exec -it es /bin/bash # 进入容器 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis- ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.1…...

在Ubuntu上启动一个简单的用户登录接口服务
一个简单的用户登录接口 我使用 Python 和 Flask 框架来创建这个接口 首先,确保你已经安装了 Python 和 Flask。如果没有安装,可以通过以下命令在 Ubuntu 上安装: sudo apt update sudo apt install python3 python3-pip pip3 install Fla…...
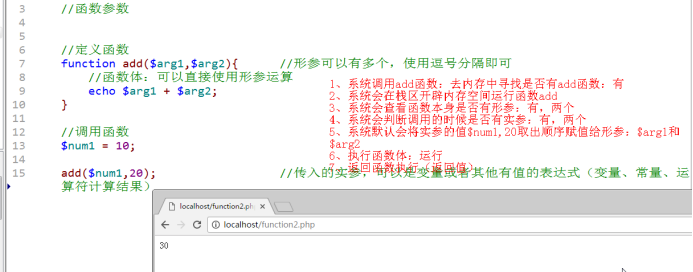
【PHP】函数-作用域可变函数匿名函数闭包常用系统函数
文章目录 函数定义&使用命名规则参数种类默认值引用传递函数返回值return关键字 作用域global关键字静态变量 可变函数匿名函数闭包常用系统函数输出函数时间函数数学函数与函数相关函数 函数 函数:function,是一种语法结构,将实现某一个…...

Python使用pymysql和sqlalchemy访问MySQL的区别
Python使用pymysql和sqlalchemy访问MySQL的区别 1. 两个数据库连接工具的对比 pymysql和sqlalchemy是两个Python中经常用于与MySQL数据库交互的库。都可以连接MySQL数据库,但它们有明显的区别。 (1)特点 pymysql是一个Python模块…...

ubuntu服务器的mysql,更改root密码,并允许远程连接
我只是一个搬运工 更改密码远程连接...

微信小程序【构建npm】使用记录
:: 问题 使用原生微信小程序开发时,通过官方 typescript 模板构建的小程序无法正确执行 构建npm 成功,从而导致我想通过 npm 安装并使用第三方库出现问题 :: 开发环境(可参照) 设备:macOS Ventura 13.0 微信开发者工…...

mybatis入门的环境搭建及快速完成CRUD(增删改查)
又是爱代码的一天 一、MyBatis的介绍 ( 1 ) 背景 MyBatis 的背景可以追溯到 2002 年,当时 Clinton Begin 开发了一个名为 iBATIS 的持久化框架。iBATIS 的目标是简化 JDBC 编程,提供一种更直观、易用的方式来处理数据库操作。 在传统的 JDBC 编程中&…...
《HeadFirst设计模式(第二版)》第九章代码——组合模式
上一章链接: 《HeadFirst设计模式(第二版)》第九章代码——迭代器模式_轩下小酌的博客-CSDN博客 前面说到,当一个菜单里面出现了子菜单的时候,前面的迭代器模式得换成组合模式。 组合模式: 允许将对象组合成树形结构来表现部分-整…...

iOS17 widget Content margin
iOS17小组件有4个新的地方可以放置分别是:Mac桌面、iPad锁屏界面、 iPhone Standby模式、watch的smart stack Transition to content margins iOS17中苹果为widget新增了Content margin, 使widget的内容能够距离边缘有一定的间隙,确保内容显示完整。这…...
(一))
计网第四章(网络层)(一)
前面学习了数据链路层,我们可以实现一个网络的内部通信,可是要把这些网络互连起来形成更大的互连网,就需要用网络层互联设备路由器。而有了路由器的参与,就有不同网络、跨网络的概念诞生。 这时候我想大家也能理解为什么叫网络层…...

【前端】vue3 接入antdv表单校验
1/🍕背景 1、表单校验是非常常见的需求,能够有效的拦截大部分的错误数据,提升效率。 2、快速的给使用者提示和反馈,用户体验感非常好。 3、成熟的表单校验框架,开发效率高,bug少。 最近使用的是vue3antdv的…...

CY3-COOH在蛋白质定位的特点1251915-29-3星戈瑞
欢迎来到星戈瑞荧光stargraydye!小编带您盘点: CY3-COOH是一种橙红色荧光标记试剂,可以用于蛋白质定位研究。**以下是CY3-COOH在蛋白质定位的特点和应用: 细胞定位:**将CY3-COOH标记到特定蛋白质上,可以…...
)
从机器学习转做DFT计算?手把手教你用Python ASE库搞定VASP输入文件(含VC++14安装避坑)
从机器学习转做DFT计算?用Python ASE库高效构建VASP输入文件全指南 当机器学习背景的研究者首次接触第一性原理计算时,往往会被VASP等传统软件的复杂输入文件格式所困扰。POSCAR、INCAR、KPOINTS这些文件的手动编写不仅耗时,还容易出错。本文…...
)
告别混乱!WPF项目如何用ResourceDictionary优雅管理样式和转换器(附完整项目结构)
告别混乱!WPF项目如何用ResourceDictionary优雅管理样式和转换器(附完整项目结构) 当WPF项目从Demo阶段步入正式开发,资源管理往往会成为第一个"拦路虎"。我曾接手过一个中型设备管理系统的UI重构,打开项目时…...

魔兽争霸3终极优化指南:WarcraftHelper 2024免费配置教程
魔兽争霸3终极优化指南:WarcraftHelper 2024免费配置教程 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏《魔兽争霸3》在现…...

5分钟快速上手:XUnity.AutoTranslator游戏实时翻译插件终极指南
5分钟快速上手:XUnity.AutoTranslator游戏实时翻译插件终极指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为语言障碍而无法畅玩海外Unity游戏吗?XUnity.AutoTranslator正…...

从愚人节玩笑到工程实践:四个软硬件结合的创意项目技术拆解
1. 从愚人节玩笑到工程师的创意沙盘每年四月一日,总有些介于荒诞与现实之间的“产品”构想冒出来,在工程师社区里引发一阵会心一笑。但如果你仔细琢磨,会发现这些看似玩笑的点子,往往藏着一丝对技术边界、用户体验乃至市场需求的犀…...

避开BUUCTF《Life on Mars》的思维陷阱:当information_schema查询结果‘不对劲’时,你的排查清单应该有哪些?
破解BUUCTF《Life on Mars》的数据库迷局:当information_schema说谎时的七种侦查策略 在CTF赛场上,SQL注入类题目往往不会按教科书上的剧本发展。当你在BUUCTF《Life on Mars》这道题中执行group_concat(database()) from information_schema.schemata却…...

研究生必备|5款主流文献引用工具深度测评:从课程论文到毕业答辩,哪款能让你省下20小时格式调整时间?
凌晨3点,你盯着Word里200多条参考文献发呆:导师刚通知改用APA格式,而你手动调了一整天的GB/T 7714全得推倒重来。投稿被拒,只因参考文献格式不符合期刊要求。课程论文、小论文、开题报告、毕业大论文……每一次都是格式地狱。本文…...

AI智能体记忆系统设计:分层架构与向量化检索实战
1. 项目概述:一个为AI智能体设计的记忆系统最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的痛点:如何让这些智能体拥有“记忆”?不是那种简单的对话历史记录,而是更接近人类工作记忆和…...

Windows系统mfc140.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题
ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地…...