C++基础Ⅱ变量
目录儿
- 4 变量
- 4.1 原始数据类型
- 字符 char
- 整型 short
- 整型 int
- 整型 long
- 整型 long long
- 单精度浮点型 float
- 双精度浮点型 double
- 布尔型 bool
- 4.2 sizeof 关键字
- 5 指针和引用
4 变量
4.1 原始数据类型
原始数据类型是构建C++程序的最基础数据类型
所有数据都是基于这些原始数据类型来存储的
后面各种第三库的包装类型、或是自定义的数据类型,其底层都是这些原始数据类型。
字符 char
char 类型用于(在一定范围内)存储整型数据(表面上是存储字符)
char 类型数据一般占据 1 byte / 8 bit,具体大小由编译器决定
char variable_name = 65;
char variable_name = 'A';如果不作显示声明,char类型数据默认是有符号的:signed
当然,我们可以显示地把一个char数据声明为无符号整型:unsigned
但是一般不会这么做,因为没有意义
我们定义char类型基本都是用于存储字符,字符对应的编码都是正的整型数据
unsigned char variable_name; // 不推荐
一般而言
char类型是用来表示存储的数据是一个字符数据,所以cout打印char类型数据的时候会把存储的整型根据编码表转成对应的字符进行输出。
整型 short
short 类型数据一般占据 2 byte / 16 bit,具体大小由编译器决定
short variable_name = 65;
short variable_name = 'A';
如果不作显示声明,short类型数据默认是有符号的:signed
当然,我们可以显示地把一个short数据声明为无符号整型:unsigned
unsigned short variable_name;
整型 int
int 类型用于(在一定范围内)存储整型数据
int 类型数据一般占据 4 byte / 32bit,具体大小由编译器决定
int variable_name = 65;
int variable_name = 'A';
如果不作显示声明,int类型数据默认是有符号的:signed
当然,我们可以显示地把一个int数据声明为无符号整型:unsigned
unsigned int variable_name;
整型 long
long 类型用于(在一定范围内)存储整型数据
long 类型数据一般占据 4 byte / 32 bit,具体大小由编译器决定
long variable_name = 65;
long variable_name = 'A';
如果不作显示声明,long类型数据默认是有符号的:signed
当然,我们可以显示地把一个long数据声明为无符号整型:unsigned
unsigned long variable_name;
整型 long long
long long 类型用于(在一定范围内)存储整型数据
long long 类型数据一般占据 8 byte / 64 bit,具体大小由编译器决定
long long variable_name = 65;
long long variable_name = 'A';
如果不作显示声明,long long类型数据默认是有符号的:signed
当然,我们可以显示地把一个long long数据声明为无符号整型:unsigned
unsigned long long variable_name;
单精度浮点型 float
float 类型用于(在一定范围内)存储浮点数据
float 类型数据一般占据 4 byte / 32 bit,具体大小由编译器决定
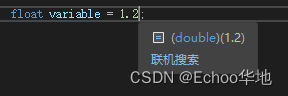
float variable_name = 1.2f;
给
float类型的变量赋值时需要加上一个f/F,否则编译器会把这个浮点数当成double处理:
加了f/F就向编译器说明这是个float类型的数据:
双精度浮点型 double
double 类型用于(在一定范围内)存储浮点数据
double 类型数据一般占据 8 byte / 64 bit,具体大小由编译器决定
double variable_name = 1.2;
布尔型 bool
bool 类型用于代表ture/false
bool 类型数据一般占据 1 byte / 8 bit
bool variable_name = true;b
将bool类型的数据打印输出时以0代表false
以其他非0数字,通常是1代表true,具体取决编译器
其实
bool类型的数据只占用了1bit,但为什么它确需要占据1byte这么多呢?
原因是内存寻址的时候是以byte为最小单元的,因此最小的数据类型只能小到1byte,哪怕它实际用到的内存大小比1byte小!
4.2 sizeof 关键字
sizeof关键字可以获取某个变量,或者具体的数据类型所占据的字节数
int main() {float flo_var = 1.2f;int int_var = 5654;std::cout << sizeof(flo_var) << std::endl; // 4std::cout << sizeof int_var << std::endl; // 4std::cout << sizeof(double) << std::endl; // 8std::cin.get();
}
不同版本的编译器对加不加
()要求可能不同,但是规范而言最好加上sizeof(xxx)
5 指针和引用
有了原始数据类型之后,我们可以把这些原始数据类型转换成指针或引用
比如现在有一个bool类型的变量
bool bool_var = false;
转成成指针
bool* bool_var = false;
转换成引用
bool& bool_var = false;
相关文章:
C++基础Ⅱ变量
目录儿 4 变量4.1 原始数据类型字符 char整型 short整型 int整型 long整型 long long单精度浮点型 float双精度浮点型 double布尔型 bool 4.2 sizeof 关键字 5 指针和引用 4 变量 4.1 原始数据类型 原始数据类型是构建C程序的最基础数据类型 所有数据都是基于这些原始数据类型…...

Linux管理SpringBoot应用shell脚本实现
Liunx系统如何部署和管理SpringBoot项目应用呢?最简单的方法就是写个shell脚本。 Spring Boot是Java的一个流行框架,用于开发企业级应用程序。下面我们将学习如何在Linux服务器上部署Spring Boot应用,并通过一个脚本实现启动、停止、重启等操…...

一篇搞懂浏览器的工作原理(万字详解)
摘要 本文是学习极客时间上的课程,进而整理出的浏览器工作原理。 第一部分:浏览器的进程和线程 (1)进程和线程的区别? 在浏览器中,各个进程负责处理自己的事情,而不同的进程中,也…...
)
C语言调用python训练的机器学习模型(项目需求轻体量)
问题描述 机器学习模型基本上都是python下的实现与使用,有关C如何调用训练好的模型或是C实现模型的相关教程相对较少 同时,项目需求整个模型大小尽可能小,大概在几十Kb 由于是表格类型的数据,因此主要考虑树模型 一般而言&#…...

get和post请求的区别以及post请求的url参数问题
1.主要区别 1.GET请求方法有以下几个特点: 默认的请求方法;GET请求通常用于获取信息,所以应该是安全的、幂等的;请求数据表现在URL上,以名称/值的形式发送。对请求的长度有限制;在IE和Opera等浏览器会产生…...

android NullPointerException externalCacheDir
先看代码: fun Context.getMyCacheDir(): String {return externalCacheDir!!.absolutePath "/my_cache" }如上代码,在某些手机可能会出现crash。 原因详细阅读api,注意他有一个大大的注解Nullable: Nullablepublic a…...
设计模式-过滤器模式(使用案例)
过滤器模式(Filter Pattern)或标准模式(Criteria Pattern)是一种设计模式,这种模式允许开发人员使用不同的标准来过滤一组对象,通过逻辑运算以解耦的方式把它们连接起来。这种类型的设计模式属于结构型模式…...
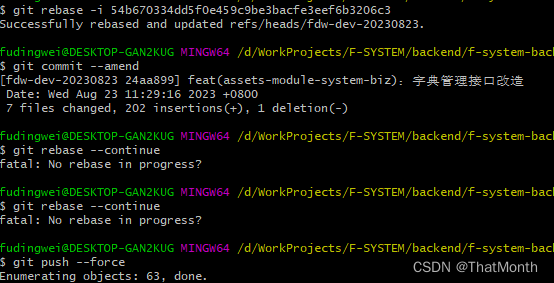
成功解决修改已经push到远程git仓库的commit message
1.使用 Git 命令行进入要修改的项目目录。 2.运行 git log 命令查看提交历史,找到要修改的提交的哈希值(commit hash)。 3.运行 git rebase -i <commit hash> 命令,将 <commit hash> 替换为要修改的提交的哈希值。这将…...

Ubuntu18.04 交叉编译openssl-1.1.1
源码下载地址: openssl 此处使用的是openssl-1.1.1-pre5.tar.gz 解压: $tar -zxvf openssl-1.1.1-pre5.tar.gz $cd openssl-1.1.1-pre5/ 执行配置生成Makefile: $./config no-asm shared --prefix$PWD/__install 或者 $./config no-asm shared no-…...

七夕学算法
目录 P1031 [NOIP2002 提高组] 均分纸牌 原题链接 : 题面 : 思路 : 代码 : P1036 [NOIP2002 普及组] 选数 原题链接 : 题面 : 思路 : 代码 : P1060 [NOIP2006 普及组] 开心的金明 原题链接 : 题面 : 思路 : 01背包例题 : 代码 : P1100 高低位交换 原题…...
)
在C++中利用rapidjson实现Python中的字典(Dict)
python 中的dict如下: Dicts = {"Stain":{"ResultType": "Physics","Results": [{"Key": "KeyPoints","Title": "瑕疵区域","Unit": "","Value": stainlist…...
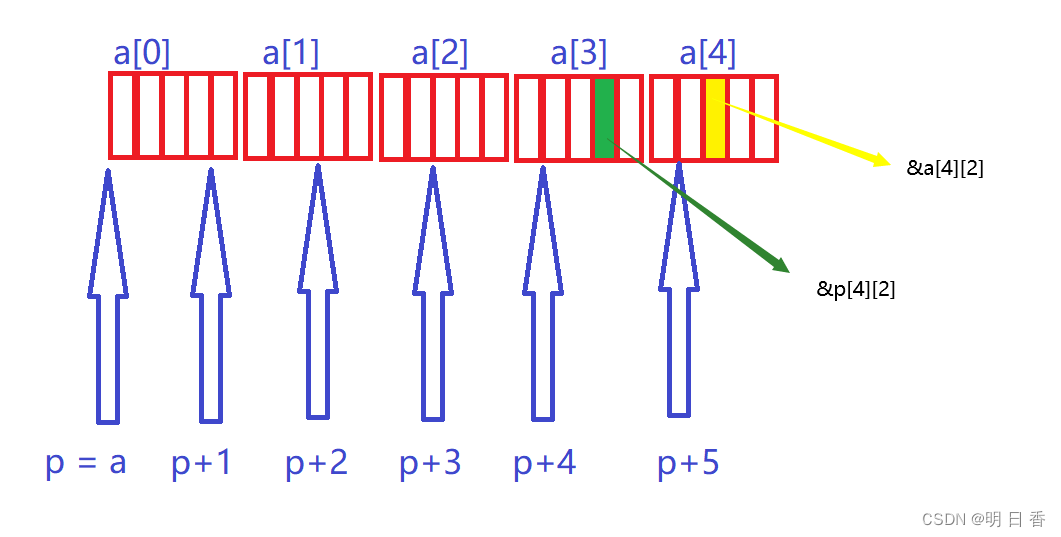
数组和指针练习(3)
题目: int main() { int a[5][5]; int(*p)[4]; p a; printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0; } 思路分析: int(*p)[4]; 定义了指针变量p是一个数组指针,且该数组指…...

如何用树莓派Pico针对IoT编程?
目录 一、Raspberry Pi Pico 系列和功能 二、Raspberry Pi Pico 的替代方案 三、对 Raspberry Pi Pico 进行编程 硬件 软件 第 1 步:连接计算机 第 2 步:在 Pico 上安装 MicroPython 第 3 步:为 Thonny 设置解释器 第 4 步ÿ…...
【填坑向】MySQL常见报错及处理系列(ERROR! The server quit without updating PID file)
本系列其他文章 【填坑向】MySQL常见报错及处理系列(Communications link failure & Access denied for user ‘root‘‘localhost‘)_AQin1012的博客-CSDN博客翻一下大致的意思就是默认会按照如下的顺序读取配置文件,我上面贴出的配置文…...

如何处理MySQL自增ID用完
检查当前自增ID的最大值:你可以使用以下SQL查询语句来获取当前最大的自增ID值: SELECT MAX(id) FROM your_table;假设你的表名为 your_table 和自增ID列名为 id。 确定使用的自增ID类型:根据当前最大值来判断你使用的自增ID类型。如果当前…...

Docker 安装教程【菜鸟级】
文章目录 前言1.安装及环境1.1.Linux安装1.2.Windows安装 2.初识Docker2.1.进入docker2.2.命令行基本操作 Docker实例Docker安装Centos使用启动、关闭、删除容器将主机中的文件放入容器中的方式查看容器日志 前言 1.安装及环境 1.1.Linux安装 1.2.Windows安装 2.初识Docker…...

centos7.9 用docker安装mysql8.0
一.安装docker 切换到root1.安装依赖包 $ yum install -y yum-utils2.registry更换阿里源 $ yum-config-manager \--add-repo \https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo$ sed -i s/download.docker.com/mirrors.aliyun.com\/docker-ce/g /etc/yum.…...
)
JVM和消息队列面经(自用)
JVM和消息队列面试八股文,自用。 Minor GC、Young GC、Full GC、Old GC、Major GC、Mixed GC 一文搞懂 - 知乎 32 道 JVM 面试题总结(含答案解析和思维导图) - 知乎 百度安全验证 JVM面经汇总_所幸你是例外的博客-CSDN博客 38道精品JVM面…...

四、pikachu之文件包含
文章目录 1、文件包含漏洞概述1.1 文件包含漏洞1.2 相关函数1.3 文件包含漏洞分类 2、File Inclusion(local)3、File Inclusion(remote) 1、文件包含漏洞概述 1.1 文件包含漏洞 文件包含漏洞:在web后台开发中,程序员往往为了提高效率以及让代码看起来更…...

【SVN内网穿透】远程访问Linux SVN服务
文章目录 前言1. Ubuntu安装SVN服务2. 修改配置文件2.1 修改svnserve.conf文件2.2 修改passwd文件2.3 修改authz文件 3. 启动svn服务4. 内网穿透4.1 安装cpolar内网穿透4.2 创建隧道映射本地端口 5. 测试公网访问6. 配置固定公网TCP端口地址6.1 保留一个固定的公网TCP端口地址6…...

RAG vs LoRA:AI产品选型困境终结者!产品经理必看的技术选型指南
本文深入剖析了AI产品开发中RAG与LoRA技术的选型困境,指出两者并非竞争关系,而是基于不同场景的产品判断失误。文章从概念解析入手,通过生动类比区分了RAG(知识库增强)与LoRA(模型微调)的核心差…...

TensorFlow GPU内存分配失败怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 TensorFlow GPU内存分配失败的终极解决方案:一招避坑指南 目录 TensorFlow GPU内存分配失败的终极解决方案࿱…...

模型切换总报错?Trae 在模块四迁移中解决 3 类兼容性问题的配置要点
1. 模型切换总报错?不是模型的问题,是配置没对齐上下文契约 我在三个中型项目里反复遇到同一个现象:刚切完模型,Trae 就在右下角弹出红色提示——“Context initialization failed” 或 “Model adapter mismatch: expected Claude-3-haiku, got DeepSeek-VL-4”。不是模型…...

从NUCLEO板载调试器到独立ST-LINK:打造高效STM32开发环境
1. 为什么需要独立ST-LINK调试器? 很多STM32开发者刚开始接触NUCLEO开发板时,都会发现板子上自带了一个ST-LINK调试器。这个设计本来是为了方便初学者快速上手,但随着项目复杂度提升,你会发现这个板载调试器存在不少限制。比如每次…...

别再硬着头皮写测试了!用Mockito 4.x搞定Spring Boot单元测试的5个真实场景
告别低效测试:Mockito 4.x在Spring Boot中的5个实战技巧 在Java开发领域,单元测试是保证代码质量的重要环节,但面对Spring Boot这样功能强大的框架,测试工作常常变得复杂而低效。依赖注入、数据库交互、外部服务调用等因素让测试代…...

告别SAP GUI!Notepad++配置ABAP语法高亮,离线查看代码更高效
告别SAP GUI!Notepad配置ABAP语法高亮,离线查看代码更高效 对于ABAP开发者而言,代码阅读和分析是日常工作中不可或缺的部分。然而,传统的SAP GUI环境并非总是最便捷的选择——无论是通勤途中、客户现场无系统访问权限,…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成步骤解析
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan集成步骤解析。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

告别传统编程:用AI语音命令5倍速开发Godot游戏
告别传统编程:用AI语音命令5倍速开发Godot游戏 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 还在为复杂的…...

别再只盯着时序图了!FPGA驱动AD7606的8通道同步采样,这3个实战细节才是关键
FPGA驱动AD7606的8通道同步采样:工程师必备的3个实战优化技巧 在工业自动化、电力监测等高精度数据采集领域,AD7606凭借其8通道同步采样和16位分辨率成为热门选择。然而在实际项目中,许多工程师发现,按照数据手册搭建的系统往往达…...

拯救吃灰的MT7921网卡:保姆级教程,在Ubuntu 22.04上为联想拯救者系列驱动Wi-Fi
拯救吃灰的MT7921网卡:联想拯救者Ubuntu 22.04无线驱动全攻略 当联想拯救者Y9000P/R7000P等2021款笔记本遇上Ubuntu 22.04,那块被诟病已久的MT7921无线网卡往往成为最大的绊脚石。不同于Windows下的即插即用,Linux环境需要精准的内核版本与固…...