centos7安装hadoop 单机版
1.解压
(1)将hadoop压缩包复制到/opt/software路径下

(2)解压hadoop到/opt/module目录下
[root@kb135 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
![]()
(3)修改hadoop属主和属组
[root@kb135 module]# chown -R root:root ./hadoop-3.1.3/

2.配置环境变量
[root@kb135 module]# vim /etc/profile
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

修改完之后[root@kb135 module]# source /etc/profile
3.在hadoop目录创建data目录
[root@kb135 module]# cd ./hadoop-3.1.3/
创建目录data
[root@kb135 hadoop-3.1.3]# mkdir ./data

4.修改配置文件
进入/opt/module/hadoop-3.1.3/etc/hadoop目录,查看目录下的文件,配置几个必要的文件

(1)配置core-site.xml
[root@kb135 hadoop]# vim ./core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://kb135:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131073</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>

(2)配置hadoop-env.sh
[root@kb135 hadoop]# vim ./hadoop-env.sh
修改第54行
export JAVA_HOME=/opt/module/jdk1.8.0_381
![]()
(3)配置hdfs-site.xml
[root@kb135 hadoop]# vim ./hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-3.1.3/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data/dfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>

(4)配置mapred-site.xml
[root@kb135 hadoop]# vim ./mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>kb135:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>kb135:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*</value>
</property>
</configuration>

(5)配置yarn-site.xml
[root@kb135 hadoop]# vim ./yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>20000</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>kb135:8040</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>kb135:8050</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>kb135:8042</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/module/hadoop-3.1.3/yarndata/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/module/hadoop-3.1.3/yarndata/log</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>

(6)配置workers
[root@kb135 hadoop]# vim ./workers
修改为kb135

5.初始化hadoop
进入/opt/module/hadoop-3.1.3/bin路径
[root@kb135 bin]# hadoop namenode -format
6.设置免密登录
[root@kb135 ~]# ssh-keygen -t rsa -P ""
[root@kb135 ~]# cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
[root@kb135 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub -p22 root@kb135
7.启动hadoop
[root@kb135 ~]# start-all.sh
查看进程
[root@kb135 ~]# jps

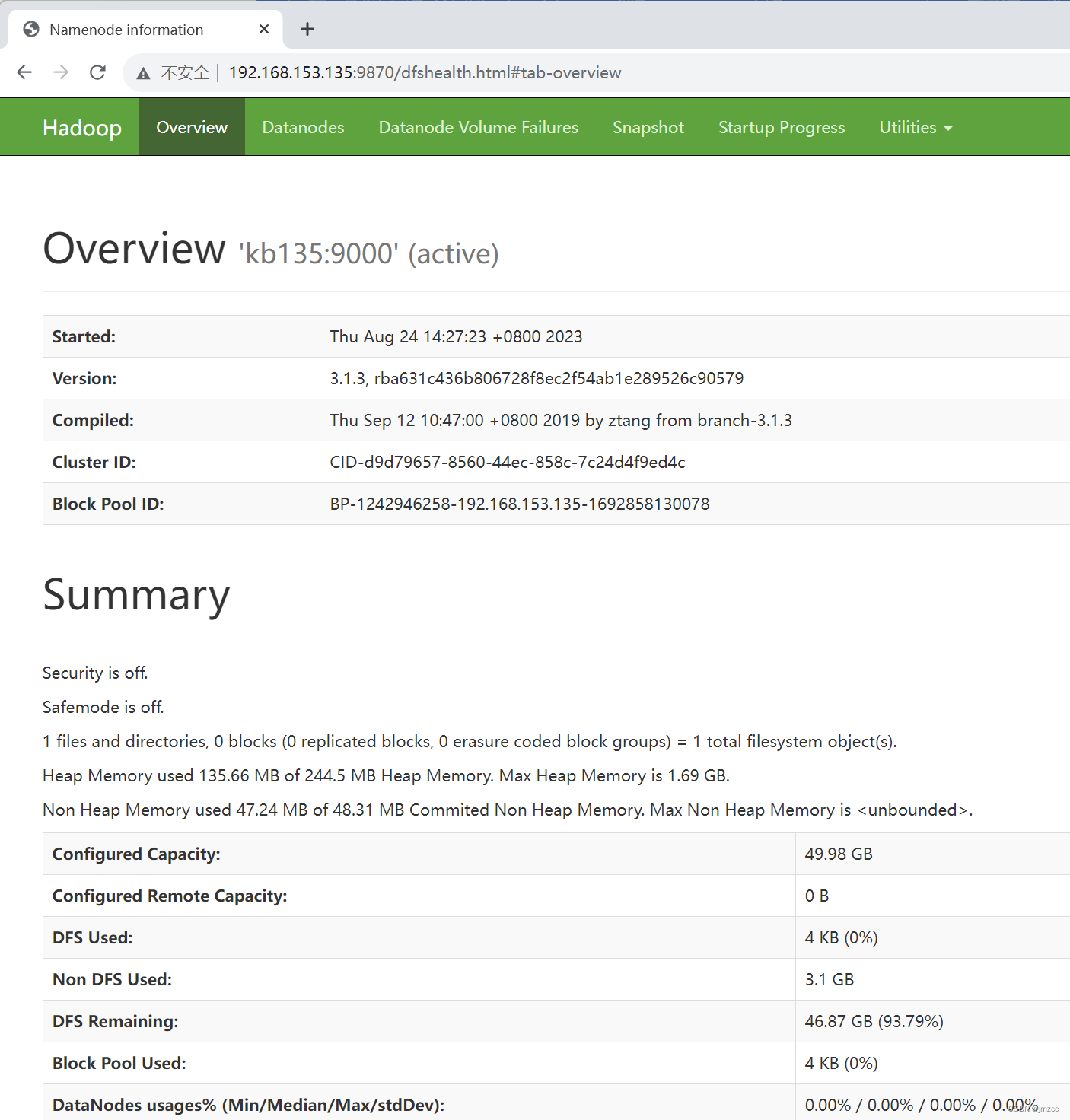
8.测试
网页中输入网址:http://192.168.142.135:9870/
相关文章:
centos7安装hadoop 单机版
1.解压 (1)将hadoop压缩包复制到/opt/software路径下 (2)解压hadoop到/opt/module目录下 [rootkb135 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ (3)修改hadoop属主和属组 [rootkb135 m…...

村口的人家排放污水,污水浸染了整个村子,怎么办
从前有一个很不错的村子里,村子里有很多户人家,随着生活水平越来越好,房子也修起来了,柏油马路也宽敞了,大家进出村子,都要走那条马路,要不就出不去。 目录 1. 修厕所 2. 村口的日家 3. 告诉…...

算法leetcode|72. 编辑距离(rust重拳出击)
文章目录 72. 编辑距离:样例 1:样例 2:提示: 分析:题解:rust:二维数组(易懂)滚动数组(更加优化的内存空间) go:c:python&a…...

实训笔记8.21
8.21笔记 8.21笔记一、Hive数据仓库技术的基本概念和组成1.1 Hive的组成架构1.1.1 Hive的客户端(1)Hive的命令行客户端 hive命令(2)Hive的JDBC的客户端(Java API)hive的JDBC客户端又有多种使用方式 &#x…...

robust distortion-free watermarks for language models
本文是LLM系列文章,针对《robust distortion-free watermarks for language models》的翻译。 语言模的鲁棒无失真水印 摘要1 引言2 方法和理论分析3 实验结果4 讨论 摘要 我们提出了一种从自回归语言模型中在文本中植入水印的方法,该方法对扰动具有鲁…...
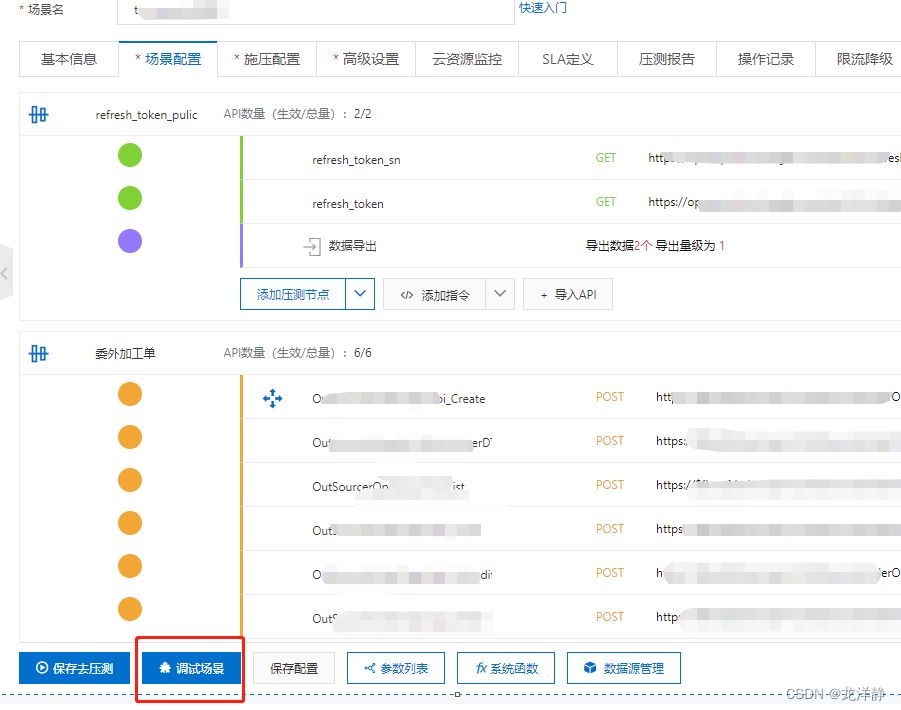
PTS性能测试工具-使用记录
因为PTS使用是要收费的,所以文中会有大量图片记录,为我自己以后工作中,可能会再次使用PTS做个参照,以免时间长,容易忘记~ 目录 一、创建场景 二、填写一个压测节点 1、填写节点基本信息 2、Body / Header填写 …...
【boost网络库从青铜到王者】第六篇:asio网络编程中的socket异步读(接收)写(发送)
文章目录 1、简介2、异步写 void AsyncWriteSomeToSocketErr(const std::string& buffer)3、异步写void AsyncWriteSomeToSocket(const std::string& buffer)4、异步写void AsyncSendToSocket(const std::string& buffer)5、异步读void AsyncReadSomeToSocket(cons…...

django sqlite3操作和manage.py功能介绍
参考链接:https://www.cnblogs.com/csd97/p/8432715.html manage.py 常用命令_python manage.py_追逐&梦想的博客-CSDN博客 python django操作sqlite3_django sqlite_浪子仙迹的博客-CSDN博客...

【SQL语句】SQL编写规范
简介 本文编写原因主要来于XC迁移过程中修改SQL语句时,发现大部分修改均源自于项目SQL编写不规范,以此文档做以总结。 注:此文档覆盖不甚全面,大体只围绕迁移遇到的修改而展开。 正文 1、【字段引号】 列名、表名如无特殊情况…...
)
后端项目开发:工具类封装(序列化、反射)
1.整合Jackson 根据《阿里巴巴开发规范》,包名使用单数,类名可以使用复数。 所以generic-common创建util包和utils工具类 很多时候我们需要将接收到的json数据转换为对象,或者将对象转为json存储。这时候我们需要编写用于json转换的工具类。…...

软件测试技术分享丨遇到bug怎么分析?
为什么定位问题如此重要? 可以明确一个问题是不是真的“bug” 很多时候,我们找到了问题的原因,结果发现这根本不是bug。原因明确,误报就会降低 多个系统交互,可以明确指出是哪个系统的缺陷,防止“踢皮球…...

LeetCode无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: s “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串是 “…...

17.2.2 【Linux】通过systemctl观察系统上所有的服务
使用 systemctl list-unit-files 会将系统上所有的服务通通列出来~而不像 list-units 仅以 unit 分类作大致的说明。 至于 STATE 状态就是前两个小节谈到的开机是否会载入的那个状态项目。主要有 enabled / disabled / mask / static 等等。 假设我不想要知道这么多…...

Redis扩容机制与一致性哈希算法解析
在分布式系统设计中,Redis是一个备受欢迎的内存数据库,而一致性哈希算法则是分布式系统中常用的数据分片和负载均衡技术。本文将深入探讨Redis的扩容机制以及一致性哈希算法的原理,同时提供示例代码以帮助读者更好地理解这两个重要概念。 推…...
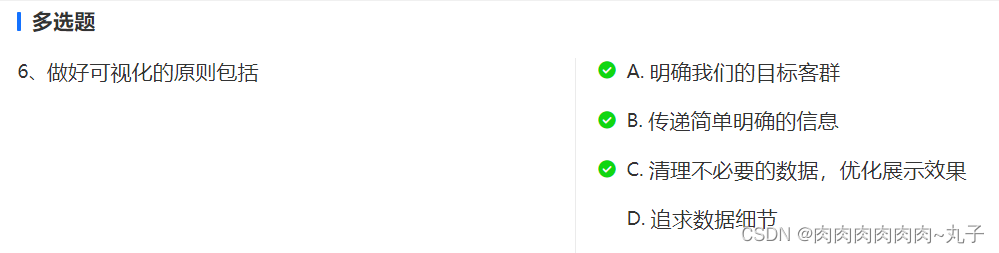
BDA初级分析——可视化基础
一、可视化的作用 数据可视化——利用各种图形方式更加直观地呈现数据的过程 可视化的作用 1、更快地理解数据,找出数据的规律和异常 2、讲出数据背后的故事,辅助做出业务决策 3、给非专业人士提供数据探索的能力 数据分析问题如何通过可视化呈现&am…...
边缘计算节点BEC典型实践:如何快速上手PC-Farm服务器?
百度智能云边缘计算节点BEC(Baidu Edge Computing)基于运营商边缘节点和网络构建,一站式提供靠近终端用户的弹性计算资源。边缘计算节点在海外覆盖五大洲,在国内覆盖全国七大区、三大运营商。BEC通过就近计算和处理,大…...

python自动把内容发表到wordpress完整示例及错误解答
要实现 Python 自动将内容发布到 WordPress,可以使用 Python 的 wordpress_xmlrpc 库,该库提供了使用 WordPress XML-RPC API 进行内容发布和管理的功能。 需要安装一下第三方库:wordpress_xmlrpc! pip install python_wordpress_xmlrpc 下面是一个简单的示例代码,可以实…...
【javaweb】学习日记Day6 - Mysql 数据库 DDL DML DQL
之前学习过的SQL语句笔记总结戳这里→【数据库原理与应用 - 第六章】T-SQL 在SQL Server的使用_Roye_ack的博客-CSDN博客 目录 一、概述 1、如何安装及配置路径Mysql? 2、SQL分类 二、DDL 数据定义 1、数据库操作 2、IDEA内置数据库使用 (1&…...

如何利用SFTP如何实现更安全的远程文件传输 ——【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 文章目录 1. 安装openSSH1.1 安装SSH1.2 启动ssh 2. 安装cpolar2.1 配置termux服务 3. 远程SFTP连接配置3.1 查看生成的随机公…...

枚举和反射
枚举 枚举 枚举是一种特殊的类,它可以有自己的属性、方法和构造方法。 两种枚举的方法 自定义枚举 a.将构造器私有化,防止外部直接new b.去掉set方法,防止属性被修改 c.在内部直接创建固定的对象 通过类名直接去访问 关键字枚举 用…...

MATLAB仿真GPS调制和捕获
一,中频数据捕获: 当捕获通道状态空闲时,启动中频数据存储,此时根据当前要捕获的卫星的来选择射频通道,并将相应的载波频率和码频率写入寄存器中,使能存储操作;当一次捕获运算完成之后,需要重新存储中频数据。 卫星选择:初始化时,将所有卫星设置为待捕获状态,用一…...
)
NotebookLM赋能社科研究(从文献综述到理论建模的闭环实践)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM赋能社科研究(从文献综述到理论建模的闭环实践) NotebookLM 是 Google 推出的面向研究者的 AI 原生笔记工具,其核心能力在于对用户上传的 PDF、TXT 等本地…...

出库篇:仓库里的货往哪去?——WMS出库方式全解析,物流新人必读
仓库里的货往哪去?——WMS出库方式全解析,物流新人必读 摘要:货品有进必有出。上一期我们聊了WMS中货品的四大来源(采购、生产、退货、调拨入库),这一期我们来看看货品是怎么“出”去的——销售出库、采购退…...

命令行集成AI代码审查:基于Gemini的Git工作流自动化实践
1. 项目概述:当命令行遇上代码审查在开发者的日常工作中,代码审查是保证代码质量、促进知识共享的关键环节。然而,传统的代码审查流程往往伴随着频繁的上下文切换:你需要离开终端,打开浏览器,登录代码托管平…...

LLM应用开发资源导航:从Awesome List到实战项目构建
1. 项目概述:当“Awesome”遇见LLM应用如果你最近在GitHub上逛过,或者对大型语言模型(LLM)的应用开发感兴趣,那么“Shubhamsaboo/awesome-llm-apps”这个仓库大概率已经躺在你的浏览器书签或者GitHub星标列表里了。它不…...

SISSO 终极指南:数据驱动建模的强大工具
SISSO 终极指南:数据驱动建模的强大工具 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO SISSO…...

如何自动化监控线上问题
要实现线上问题的自动化监控,不能仅停留在工具的堆砌,而需要从体系规划、数据采集、智能告警、动态诊断到流程规范进行全盘设计。以下是基于行业最佳实践的自动化监控构建指南:一、 体系规划与监控点梳理构建自动化监控的第一步是明确“监控什…...

NVIDIA开发环境自动化构建:从CUDA、cuDNN版本对齐到可复现环境管理
1. 项目概述:一个面向开发者的NVIDIA环境构建工具最近在折腾一些AI相关的本地实验,发现配置一个稳定、高效的NVIDIA开发环境,尤其是CUDA、cuDNN这些核心组件的版本对齐,真是一件让人头疼的事情。相信很多做机器学习、深度学习或者…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

硬件身份伪装终极指南:3分钟掌握EASY-HWID-SPOOFER的深度伪装技术
硬件身份伪装终极指南:3分钟掌握EASY-HWID-SPOOFER的深度伪装技术 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 你是否曾经遇到过这样的情况:刚买的软件因…...