【草稿】关于文本句子分割(中文+英文)以及向量处理
获取文本
主函数 Main
# -*- encoding: utf-8 -*-
# @Author: SWHL
# @Contact: liekkaskono@163.com
from pathlib import Path
from typing import Dict, List, Unionimport filetypefrom ..utils import logger
from .image_loader import ImageLoader
from .office_loader import OfficeLoader
from .pdf_loader import PDFLoader
from .txt_loader import TXTLoaderINPUT_TYPE = Union[str, Path]class FileLoader:def __init__(self) -> None:self.file_map = {"office": ["docx", "doc", "ppt", "pptx", "xlsx", "xlx"],"image": ["jpg", "png", "bmp", "tif", "jpeg"],"txt": ["txt", "md"],"pdf": ["pdf"],}self.img_loader = ImageLoader()self.office_loader = OfficeLoader()self.pdf_loader = PDFLoader()self.txt_loader = TXTLoader()def __call__(self, file_path: INPUT_TYPE) -> Dict[str, List[str]]:all_content = {}file_list = self.get_file_list(file_path)for file_path in file_list:file_name = file_path.nameif file_path.suffix[1:] in self.file_map["txt"]:content = self.txt_loader(file_path)all_content[file_name] = contentcontinuefile_type = self.which_type(file_path)if file_type in self.file_map["office"]:content = self.office_loader(file_path)elif file_type in self.file_map["pdf"]:content = self.pdf_loader(file_path)elif file_type in self.file_map["image"]:content = self.img_loader(file_path)else:logger.warning("%s does not support.", file_path)continueall_content[file_name] = contentreturn all_contentdef get_file_list(self, file_path: INPUT_TYPE):if not isinstance(file_path, Path):file_path = Path(file_path)if file_path.is_dir():return file_path.rglob("*.*")return [file_path]@staticmethoddef which_type(content: Union[bytes, str, Path]) -> str:kind = filetype.guess(content)if kind is None:raise TypeError(f"The type of {content} does not support.")return kind.extensiondef sorted_by_suffix(self, file_list: List[str]) -> Dict[str, str]:sorted_res = {k: [] for k in self.file_map}for file_path in file_list:if file_path.suffix[1:] in self.file_map["txt"]:sorted_res["txt"].append(file_path)continuefile_type = self.which_type(file_path)if file_type in self.file_map["office"]:sorted_res["office"].append(file_path)continueif file_type in self.file_map["pdf"]:sorted_res["pdf"].append(file_path)continueif file_type in self.file_map["image"]:sorted_res["image"].append(file_path)continuereturn sorted_res
PDF文本
# -*- encoding: utf-8 -*-
# @Author: SWHL
# @Contact: liekkaskono@163.com
from pathlib import Path
from typing import List, Unionfrom rapidocr_pdf import PDFExtracterfrom ..text_splitter.chinese_text_splitter import ChineseTextSplitterclass PDFLoader:def __init__(self,):self.extracter = PDFExtracter()self.splitter = ChineseTextSplitter(pdf=True)def __call__(self, pdf_path: Union[str, Path]) -> List[str]:contents = self.extracter(pdf_path)split_contents = [self.splitter.split_text(v[1]) for v in contents]return sum(split_contents, [])
TXT 文本
# -*- encoding: utf-8 -*-
# @Author: SWHL
# @Contact: liekkaskono@163.com
from pathlib import Path
from typing import List, Unionfrom ..text_splitter.chinese_text_splitter import ChineseTextSplitter
from ..utils.utils import read_txtclass TXTLoader:def __init__(self) -> None:self.splitter = ChineseTextSplitter()def __call__(self, txt_path: Union[str, Path]) -> List[str]:contents = read_txt(txt_path)split_contents = [self.splitter.split_text(v) for v in contents]return sum(split_contents, [])
Office 文本
# -*- encoding: utf-8 -*-
# @Author: SWHL
# @Contact: liekkaskono@163.com
from pathlib import Path
from typing import Unionfrom extract_office_content import ExtractOfficeContentfrom ..text_splitter.chinese_text_splitter import ChineseTextSplitterclass OfficeLoader:def __init__(self) -> None:self.extracter = ExtractOfficeContent()self.splitter = ChineseTextSplitter()def __call__(self, office_path: Union[str, Path]) -> str:contents = self.extracter(office_path)split_contents = [self.splitter.split_text(v) for v in contents]return sum(split_contents, [])
文本处理
文本处理一:分割文本成句子
split_text1 方法:这个方法用于分句操作,尤其针对 PDF 格式的文本。它使用正则表达式和字符串操作来将输入的文本划分成句子。具体步骤包括:
- 根据换行情况去除多余的换行符和空白字符。
- 通过正则表达式 sent_sep_pattern 将文本划分为句子。
- 对于划分出的每个元素(句子),进行适当的处理并添加到 sent_list 列表中,以得到划分后的句子列表。
def split_text1(self, text: str) -> List[str]:if self.pdf:text = re.sub(r"\n{3,}", "\n", text)text = re.sub("\s", " ", text)text = text.replace("\n\n", "")sent_sep_pattern = re.compile('([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;# 正则表达式用于识别句子中的断句标点和引号,并在这些位置进行句子的分割sent_list = []for ele in sent_sep_pattern.split(text):ele = ele.strip()if sent_sep_pattern.match(ele) and sent_list:sent_list[-1] += eleelif ele:sent_list.append(ele)return sent_list
split_text 方法:这个方法用于分句操作,包括针对各种标点符号和断句规则的处理。具体步骤包括:
根据 pdf 标志对输入文本进行预处理,去除多余的换行和空白。
使用正则表达式将文本按照断句标点分割为句子,并进行适当的处理。
针对单字符断句符、英文省略号、中文省略号、双引号等情况进行断句处理。
去除文本末尾多余的空白字符。
将文本按行划分,并去除空行。
对每行文本进行进一步处理,如果句子长度超过指定的 sentence_size,则进行递归式的断句操作。
def split_text(self, text: str) -> List[str]: ##此处需要进一步优化逻辑if self.pdf:text = re.sub(r"\n{3,}", r"\n", text)text = re.sub("\s", " ", text)text = re.sub("\n\n", "", text)text = re.sub(r"([;;.!?。!?\?])([^”’])", r"\1\n\2", text) # 单字符断句符text = re.sub(r'(\.{6})([^"’”」』])', r"\1\n\2", text) # 英文省略号text = re.sub(r'(\…{2})([^"’”」』])', r"\1\n\2", text) # 中文省略号text = re.sub(r'([;;!?。!?\?]["’”」』]{0,2})([^;;!?,。!?\?])', r"\1\n\2", text)# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号text = text.rstrip() # 段尾如果有多余的\n就去掉它# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。ls = [i for i in text.split("\n") if i]for ele in ls:if len(ele) > self.sentence_size:ele1 = re.sub(r'([,,.]["’”」』]{0,2})([^,,.])', r"\1\n\2", ele)ele1_ls = ele1.split("\n")for ele_ele1 in ele1_ls:if len(ele_ele1) > self.sentence_size:ele_ele2 = re.sub(r'([\n]{1,}| {2,}["’”」』]{0,2})([^\s])', r"\1\n\2", ele_ele1)ele2_ls = ele_ele2.split("\n")for ele_ele2 in ele2_ls:if len(ele_ele2) > self.sentence_size:ele_ele3 = re.sub('( ["’”」』]{0,2})([^ ])', r"\1\n\2", ele_ele2)ele2_id = ele2_ls.index(ele_ele2)ele2_ls = (ele2_ls[:ele2_id]+ [i for i in ele_ele3.split("\n") if i]+ ele2_ls[ele2_id + 1 :])ele_id = ele1_ls.index(ele_ele1)ele1_ls = (ele1_ls[:ele_id]+ [i for i in ele2_ls if i]+ ele1_ls[ele_id + 1 :])id = ls.index(ele)ls = ls[:id] + [i.strip() for i in ele1_ls if i] + ls[id + 1 :]return ls
文本处理二:向量化
-
adapt_array 和 convert_array 函数:这两个函数分别用于将 NumPy 数组转换为二进制数据,以便存储到 SQLite 数据库中,以及将存储在数据库中的二进制数据转换回 NumPy 数组。
-
DBUtils 类:这个类用于与 SQLite 数据库进行交互,主要用于存储和检索向量化的文本数据。以下是类的主要部分:
- init 方法:构造方法用于初始化类的实例。它接受一个参数 db_path,表示数据库文件的路径。在初始化时,它创建一个数据库连接并创建一个名为 embedding_texts 的表,用于存储文本数据的嵌入、文件名和文本内容。
- connect_db 方法:这个方法用于建立数据库连接。它会创建一个连接并返回连接对象和游标对象,以便执行数据库操作。
- load_vectors 方法:这个方法用于加载数据库中的向量数据。它执行查询操作,获取所有向量的文件名、嵌入和文本内容,并创建一个 Faiss 搜索索引,以便进行相似性搜索。
- count_vectors 方法:这个方法用于获取数据库中的向量数量。
- search_local 方法:这个方法用于在数据库中进行相似性搜索。它接受一个查询向量 embedding_query 和 top_k 参数,返回相似的文本内容和搜索耗时。
- insert 方法:这个方法用于将嵌入的文本数据插入到数据库中。它接受文件名、嵌入和文本列表,将数据插入到数据库表中。
- 其他方法:get_files 方法用于获取所有文件名;enter 和 exit 方法用于处理上下文管理器。
- 总之,DBUtils 类是一个用于与 SQLite 数据库交互的工具类,用于存储和检索向量化的文本数据。它可以用于构建文本检索系统等应用。请注意,代码中使用了 faiss 库来进行快速相似性搜索。
# -*- encoding: utf-8 -*-
# @Author: SWHL
# @Contact: liekkaskono@163.com
import io
import sqlite3
import time
from typing import Dict, List, Optionalimport faiss
import numpy as npfrom ..utils.logger import logger# adapt_array 和 convert_array 函数:这两个函数分别用于将 NumPy 数组转换为二进制数据,以便存储到 SQLite 数据库中,以及将存储在数据库中的二进制数据转换回 NumPy 数组。def adapt_array(arr):out = io.BytesIO()np.save(out, arr)out.seek(0)return sqlite3.Binary(out.read())def convert_array(text):out = io.BytesIO(text)out.seek(0)return np.load(out, allow_pickle=True)sqlite3.register_adapter(np.ndarray, adapt_array)
sqlite3.register_converter("array", convert_array)class DBUtils:def __init__(self,db_path: str,) -> None:self.db_path = db_pathself.table_name = "embedding_texts"self.vector_nums = 0self.max_prompt_length = 4096self.connect_db()def connect_db(self,):con = sqlite3.connect(self.db_path, detect_types=sqlite3.PARSE_DECLTYPES)cur = con.cursor()cur.execute(f"create table if not exists {self.table_name} (id integer primary key autoincrement, file_name TEXT, embeddings array UNIQUE, texts TEXT)")return cur, condef load_vectors(self,):cur, _ = self.connect_db()cur.execute(f"select file_name, embeddings, texts from {self.table_name}")all_vectors = cur.fetchall()self.file_names = np.vstack([v[0] for v in all_vectors]).squeeze()all_embeddings = np.vstack([v[1] for v in all_vectors])self.all_texts = np.vstack([v[2] for v in all_vectors]).squeeze()self.search_index = faiss.IndexFlatL2(all_embeddings.shape[1])self.search_index.add(all_embeddings)self.vector_nums = len(all_vectors)def count_vectors(self,):cur, _ = self.connect_db()cur.execute(f"select file_name from {self.table_name}")all_vectors = cur.fetchall()return len(all_vectors)def search_local(self,embedding_query: np.ndarray,top_k: int = 5,) -> Optional[Dict[str, List[str]]]:s = time.perf_counter()cur_vector_nums = self.count_vectors()if cur_vector_nums <= 1:return None, 0if cur_vector_nums != self.vector_nums:self.load_vectors()_, I = self.search_index.search(embedding_query, top_k)top_index = I.squeeze().tolist()search_contents = self.all_texts[top_index]file_names = [self.file_names[idx] for idx in top_index]dup_file_names = list(set(file_names))dup_file_names.sort(key=file_names.index)search_res = {v: [] for v in dup_file_names}for file_name, content in zip(file_names, search_contents):search_res[file_name].append(content)elapse = time.perf_counter() - sreturn search_res, elapsedef insert(self, file_name: str, embeddings: np.ndarray, texts: List):cur, con = self.connect_db()file_names = [file_name] * len(embeddings)t1 = time.perf_counter()insert_sql = f"insert or ignore into {self.table_name} (file_name, embeddings, texts) values (?, ?, ?)"cur.executemany(insert_sql, list(zip(file_names, embeddings, texts)))elapse = time.perf_counter() - t1logger.info(f"Insert {len(embeddings)} data, total is {len(embeddings)}, cost: {elapse:4f}s")con.commit()def get_files(self):cur, _ = self.connect_db()search_sql = f"select distinct file_name from {self.table_name}"cur.execute(search_sql)search_res = cur.fetchall()search_res = [v[0] for v in search_res]return search_resdef __enter__(self):return selfdef __exit__(self, *a):self.cur.close()self.con.close()
补充说明 Faiss
Faiss(Facebook AI Similarity Search)是一个由 Facebook AI Research 开发的用于高效相似性搜索的库。它主要用于处理大规模高维向量数据,例如文本嵌入、图像特征等。Faiss 提供了一系列优化的算法和数据结构,能够在大型数据集中快速进行相似性搜索,找到与给定查询向量最相似的数据点。
在文本嵌入或图像特征检索等应用中,常常需要找到与给定查询向量最接近的嵌入向量。这是一项计算密集型任务,特别是在高维空间中。Faiss 通过使用各种索引结构(如平面索引、多索引等)以及高度优化的搜索算法(如倒排索引、乘积量化、哈希等)来加速这些相似性搜索操作。
具体而言,Faiss 为用户提供了一些核心组件:
- 索引结构:Faiss 支持多种索引结构,如平面索引、倒排索引、多索引等。这些结构有助于在不同情况下加速搜索操作。
- 相似性度量:Faiss 支持多种相似性度量方法,如 L2 距离(欧氏距离)、内积等,可以根据具体应用选择适当的度量方式。
- 搜索算法:Faiss 实现了多种高效的搜索算法,例如 K 最近邻搜索、范围搜索等。这些算法基于索引结构,能够在大规模数据集中迅速找到相似的数据点。
在上述代码示例中,self.search_index 表示 Faiss 的搜索索引,self.search_index.add(all_embeddings) 将嵌入向量添加到索引中,从而建立索引以加速相似性搜索。
总之,Faiss 提供了强大的工具和算法,用于处理大规模高维向量数据的相似性搜索,这在文本检索、图像搜索等应用中非常有用。
关于 Faiss
在 Faiss 中,一般的工作流程是首先进行聚类,然后构建索引,最后执行查询。具体来说,顺序是这样的:
聚类(Clustering):首先,你需要将你的数据集进行聚类,通常使用 k-means 或其他聚类算法。这一步的目的是将数据划分成若干个聚类中心,每个聚类中心代表一个虚拟的向量,而不是实际的数据向量。
构建索引(Indexing):一旦聚类完成,对于每个聚类中心,Faiss 会构建一个索引结构,如 k-d 树或多叉树。这些索引结构将帮助加速后续的近似搜索操作。这个阶段实际上是在为每个聚类中心创建一个能够快速定位附近向量的数据结构。
查询(Querying):一旦索引构建完成,你可以使用查询向量来寻找最接近的近邻。Faiss 会使用之前构建的索引结构来定位可能包含相似向量的聚类中心,然后在这些聚类中心的附近搜索实际的近邻向量,最终返回近似的最近邻结果。
因此,聚类是在数据预处理阶段,构建索引是在为每个聚类中心创建索引结构,而查询是在实际搜索阶段。这样的顺序可以显著提高搜索的效率,特别是在处理大规模数据集时。
相关文章:
以及向量处理)
【草稿】关于文本句子分割(中文+英文)以及向量处理
获取文本 主函数 Main # -*- encoding: utf-8 -*- # Author: SWHL # Contact: liekkaskono163.com from pathlib import Path from typing import Dict, List, Unionimport filetypefrom ..utils import logger from .image_loader import ImageLoader from .office_loader i…...
【瑞吉外卖】所遇问题及解决方法
太菜了实习之余瑞吉外卖补充一下基础知识(,不然真啥也不会了。 请输入正确的手机号! 是因为我测试了我的手机号,爆红,以为方法有错。但其实是前端代码检查手机号是否符合规范的语句有点()啊啊…...

【Hugo入门】基础用法
检查Hugo是否安装 hugo version显示所有可用命令 hugo help显示指定命令的可用子命令,例如查询server的所有子命令 hugo server --help建立你的网站,cd进入你的项目根目录运行 hugo默认发布内容到自动创建的public文件夹。 覆盖hugo或hugo server的默…...

Java实现一个简单的图书管理系统(内有源码)
简介 哈喽哈喽大家好啊,之前作者也是讲了Java不少的知识点了,为了巩固之前的知识点再为了让我们深入Java面向对象这一基本特性,就让我们完成一个图书管理系统的小项目吧。 项目简介:通过管理员和普通用户的两种操作界面࿰…...
网络安全等级保护2.0
等保介绍 信息系统运维安全管理规定(范文)| 资料 等保测评是为了符合国家法律发挥的需求,而不是安全认证(ISO) 一般情况没有高危安全风险一般可以通过,但若发现高位安全风险则一票否决 二级两年一次 三…...
【sql】MongoDB 增删改查 高级用法
【sql】MongoDB 增删改查 高级用法 相关使用文档 MongoDB Query API — MongoDB Manual https://www.mongodb.com/docs/manual/reference/sql-comparison //增 //新增数据2种方式 db.msg.save({"name":"springboot😀"}); db.msg.insert({&qu…...

怎么做才能有效更新和优化产品手册文档
更新和优化产品手册文档是确保用户获得准确和最新信息的重要步骤。如果不及时地更新和优化信息,很容易导致我们的产品有滞后性,不能满足客户最新的需求。所以looklook总结了一些相关内容,以下是一些建议来更新和优化产品手册文档:…...

#P0867. 小武老师的烤全羊
问题描述 小武老师特别喜欢吃烤全羊,小武老师吃烤全羊很特别,为什么特别呢?因为他有 1010 种配料(芥末、孜然等),每种配料可以放 11 到 33 克,任意烤全羊的美味程度为所有配料质量之和。 现在&…...
视频汇聚/视频云存储/视频监控管理平台EasyCVR提升网络稳定小tips来啦!
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...

C 语言学习
数组的指针 在c中,几乎所以使用数组名的表达式中,数组名的值是一个指针常量,也就是数组 第 一个元素的地址。注意这个值是指针常量,不是变量。 int a[10]{ ….....}; int *q; q&a[0] ; <>…...

TCP网络连接异常情况的处理
在网络连接中,经常会出现一些意外情况,导致TCP连接不能正常工作,对于这些意外情况,TCP内部有自己的解决方法 一.进程崩溃 在网络通讯时可能会出现进程突然崩溃的情况,当进程崩溃后进程就没了,就会导致进程…...

单片机之从C语言基础到专家编程 - 4 C语言基础 - 4.10语句
1 表达式语句 表达式语句由表达式加上分号“;”组成。其一般形式为: 表达式; 执行表达式语句就是计算表达式的值。例如 caa; 2 函数调用语句 由函数名、实际参数加上分号“;”组成。其一般形式为: 函数名(实际参数表); 例如 printf(“Hello !”);…...

Windows 通过服务名称搜索软件启动路径启动软件
文章目录 Windows 通过服务名称搜索软件启动路径启动软件 Windows 通过服务名称搜索软件启动路径启动软件 注意:QQ管家和360安全,正常情况下使用 taskkill 无法停止,因为在安全设置中有个“自保护”,正常情况下会默认勾选上&#…...
如何更高效的写出更健全的代码,一篇文章教会你如何拥有一个良好的代码风格
前言:在平常的写代码的过程中,或多或少的遇到很多奇怪的 bug ,尤其是一些大的程序,明明上一部分都是好好的,写下一块的时候突然多几百个 bug 的情况,然后这一块写完了后编译的时候直接傻眼了,看…...
Java如何调用接口API并返回数据(两种方法)
Java如何调用接口API并返回数据(两种方法) java处理请求接口后返回的json数据-直接处理json字符串 处理思路: 将返回的数据接收到一个String对象中(有时候需要自己选择性的取舍接收) 再将string转换为JSONObject对象 …...
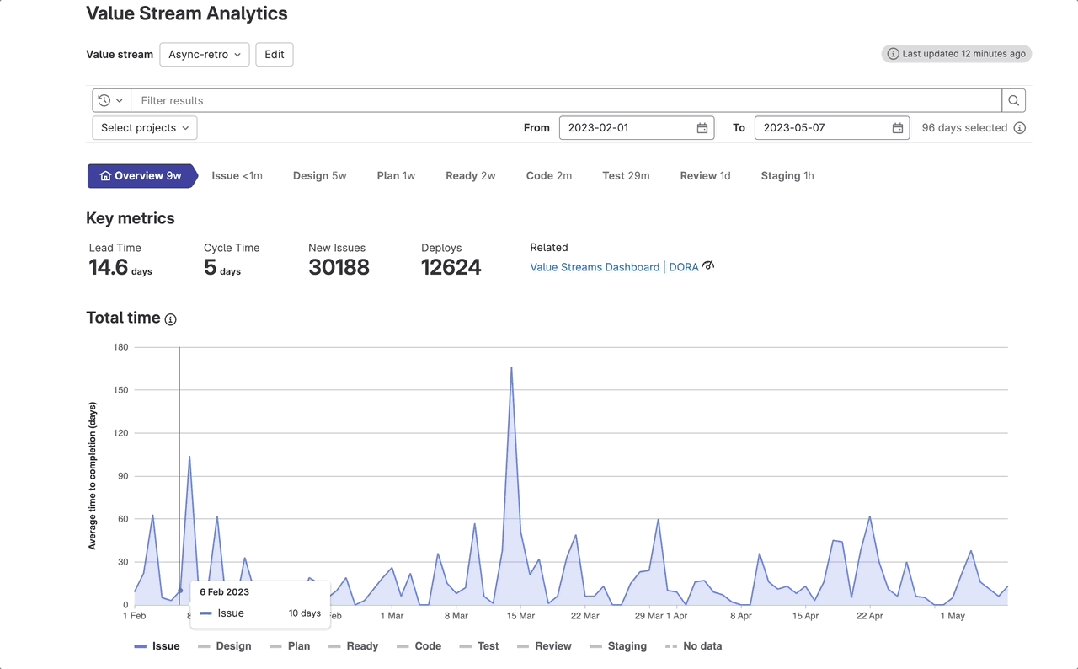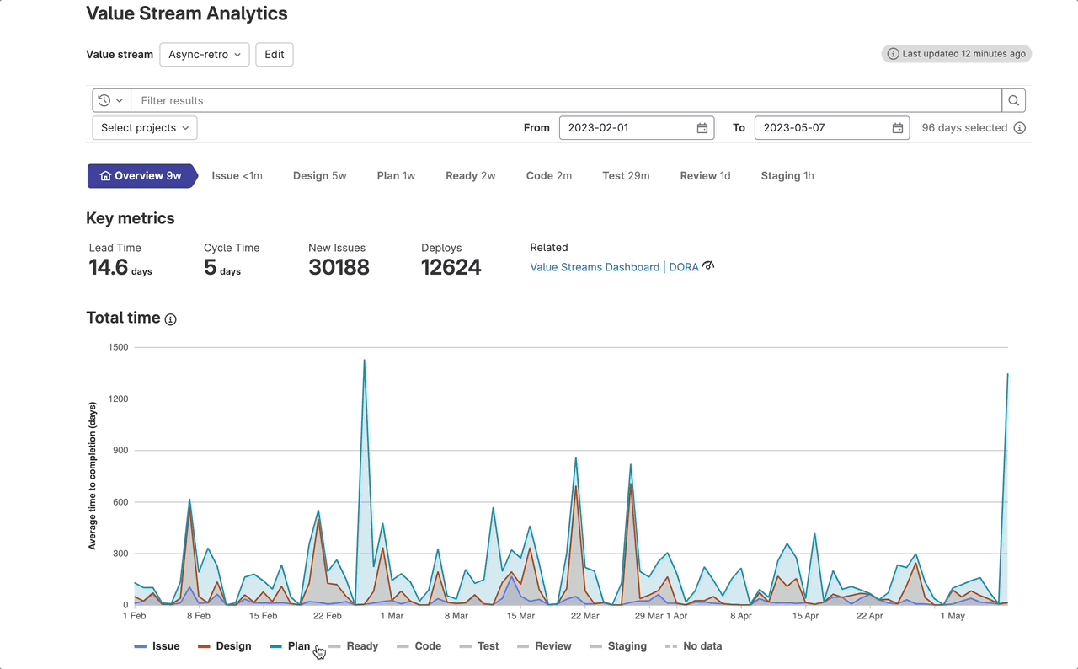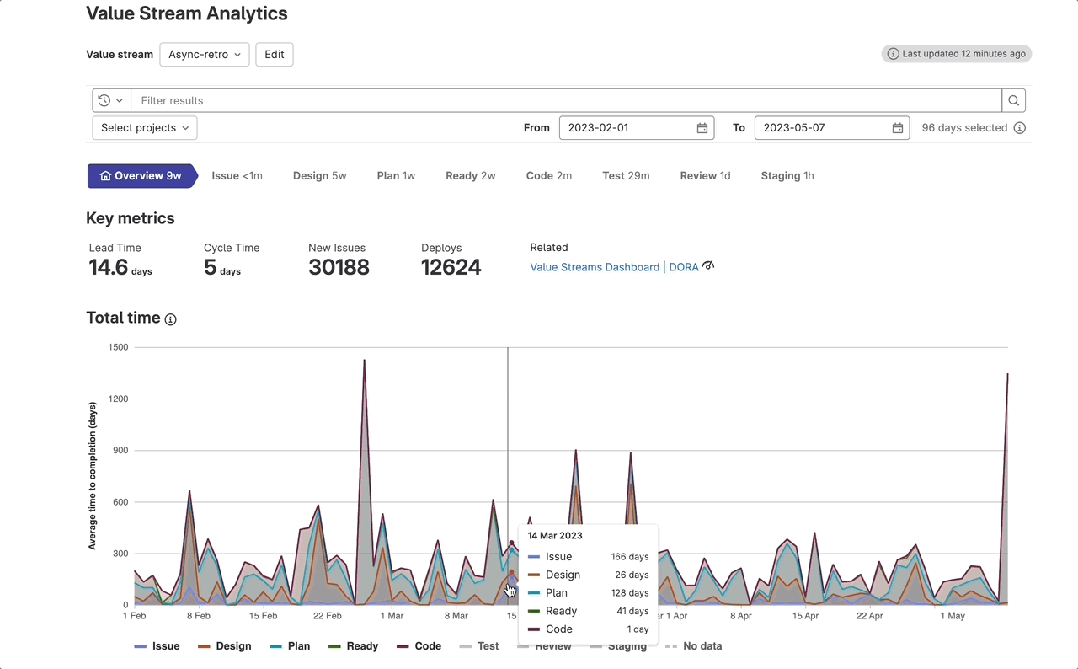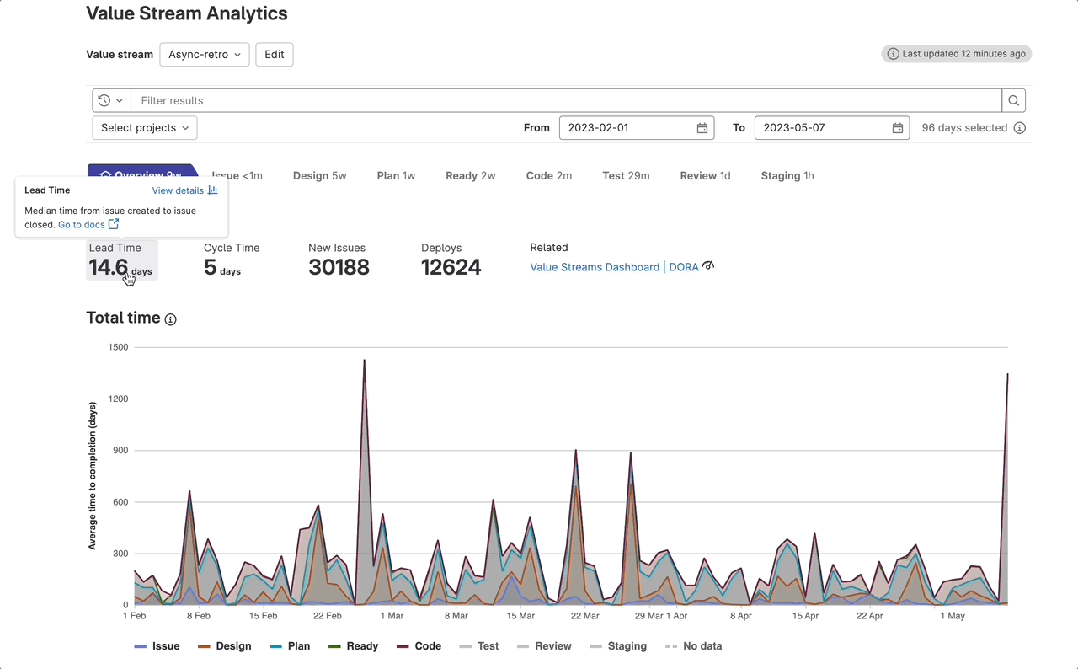
极狐GitLab 价值流管理之「总时间图」使用指南
本文来源:about.gitlab.com 作者:Haim Snir 译者:极狐(GitLab) 市场部内容团队 对于软件研发管理者来说,了解在整个研发过程中时间都耗费在了哪些地方,是进行交付价值优化的关键洞察。GitLab / 极狐GitLab 新的价值流分…...

Mybatis入门和环境搭建
文章目录 一. Mybatis的简介1. 什么是ORM?2. 什么是持久层?3. Mybatis的作用 二. Mybatis环境搭建1. 搭建一个数据库2. 创建maven项目并导入相关依赖3. Mybatis相关插件安装4. Mybatis.cfg.xml核心配置文件 三. 基于ssm逆向工程的使用1. 配置generatorConfig.xml2.…...
React 全栈体系(二)
第二章 React面向组件编程 一、基本理解和使用 1. 使用React开发者工具调试 2. 效果 2.1 函数式组件 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>1_函数式组件</title> </head> &l…...
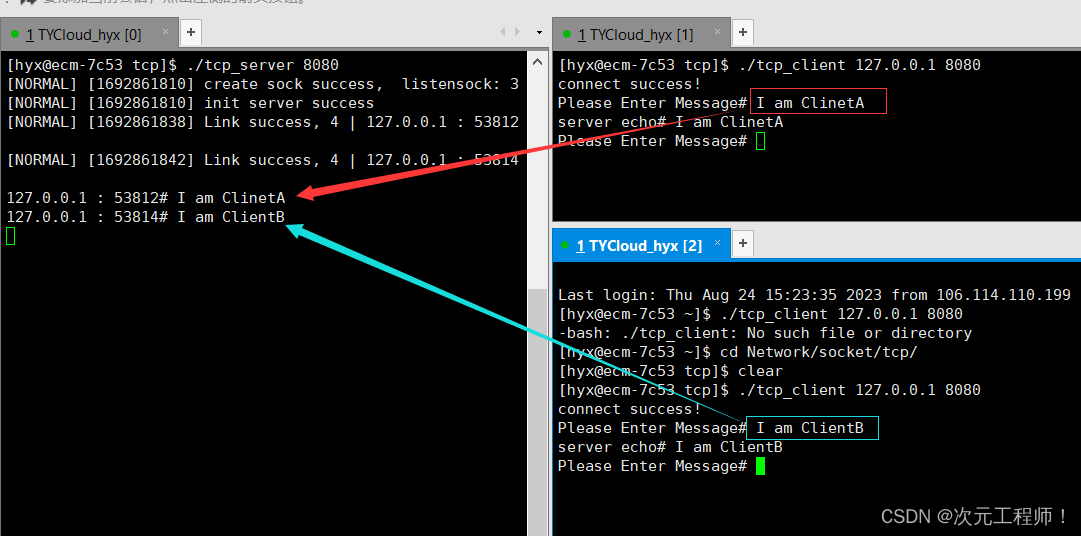
【Linux】socket编程(二)
目录 前言 TCP通信流程 TCP通信的代码实现 tcp_server.hpp编写 tcp_server.cc服务端的编写 tcp_client.cc客户端的编写 整体代码 前言 上一章我们主要讲解了UDP之间的通信,本章我们将来讲述如何使用TCP来进行网络间通信,主要是使用socket API进…...

七大出海赛道解读,亚马逊云科技为行业客户量身打造解决方案
伴随全球化带来的新机遇和国内市场的进一步趋于饱和,近几年,中国企业出海快速升温,成为了新的创业风口和企业的第二增长曲线。从范围上看,出海市场由近及远,逐步扩张。从传统的东南亚市场,到成熟的北美、欧…...

Mastercard开源AI代理工具包:用智能代理重塑支付集成开发体验
1. 项目概述:当开发者遇上Mastercard,一个工具包如何重塑支付集成体验如果你是一名开发者,正在为你的电商平台、SaaS服务或者任何需要处理在线支付的应用程序集成支付功能,那么你大概率绕不开与Mastercard这类全球支付网络的交互。…...

从机房搬服务器到写代码上云:一个传统运维的十年转型路,我如何成了SRE?
从物理机到云原生:一位技术人的十年转型实战笔记 运维行业的变革速度远超许多人想象。十年前,我还在机房亲手插拔网线、用KVM切换器调试服务器;如今,我的日常工作已经变成了编写自动化部署脚本和设计分布式系统监控方案。这不是简…...

【MATLAB】基于MATLAB的图像加密传输平台【GUI+源码+项目说明】
【MATLAB】基于MATLAB的图像加密传输平台【GUI源码项目说明】 一、项目介绍 数字图像具有数据量大、像素间相关性强、视觉冗余度高的特点, 传统的字节级加密 (如 AES) 直接作用于图像比特流虽能保密, 但无法破坏图像在空间域的统计特征. 本项目采用 “Arnold 置乱 明文相关 Lo…...

基于I2C总线与ATtiny85的RGB LCD时钟:在5个GPIO上实现多设备驱动
1. 项目概述:当微型控制器遇上彩色显示屏几年前,我在为一个智能花盆项目寻找显示方案时遇到了一个经典难题:手头的Adafruit Trinket(基于ATtiny85)只有5个可用GPIO,而一个能显示温湿度、时间的16x2字符LCD屏…...

【紧急预警】传统文献管理正被淘汰!农科院最新评估:未集成NotebookLM的课题组结题延迟平均达4.8个月
更多请点击: https://codechina.net 第一章:NotebookLM农业科学研究的范式革命 传统农业科研长期依赖人工文献综述、田间数据手工录入与孤立模型验证,知识整合效率低、跨尺度分析能力弱。NotebookLM 以“文档即计算单元”的设计理念切入&…...
)
别再手动启动了!分享一个我自用的RocketMQ Dashboard一键启动脚本(附源码解析)
解放双手:RocketMQ集群智能启动方案与Dashboard深度优化指南 1. 运维自动化的必要性 每次重启服务器后,面对需要依次启动NameServer、Broker和Dashboard的繁琐流程,相信不少RocketMQ使用者都经历过这样的痛苦:忘记启动某个组件导致…...

AI-Git-Narrator:基于LLM的Git提交历史自动化分析与文档生成工具
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫AI-Git-Narrator。简单来说,它就像一个能“看懂”你代码提交历史的AI解说员。每次你往Git仓库里推送代码,它都能自动分析你这次提交到底改了啥,然后用自然语言生成一段清…...

游戏大世界别再只盯着算法了!聊聊Houdini PCG管线搭建中那些让人头大的‘流程债’
游戏大世界开发中的Houdini PCG管线:如何规避"流程债"陷阱 当技术美术团队第一次将Houdini引入游戏大世界项目时,往往会被其强大的程序化生成能力所震撼——地形自动生成、植被智能分布、建筑群快速布局,这些传统上需要数周手工完成…...

魔兽争霸III终极兼容性增强插件:5大核心功能解决现代系统兼容问题
魔兽争霸III终极兼容性增强插件:5大核心功能解决现代系统兼容问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸…...

编写程序统计职场上下级沟通频率,工作执行效果数据,搭建高效沟通模式,减少指令传达偏差工作失误。
构建一个职场上下级沟通频率与工作执行效果分析的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在任何组织中,上下级沟通质量直接决定执行效率:- 上级布置任务 → 下级理解并执行 → 反馈结…...