归一化的作用,sklearn 安装
目录
归一化的作用:
应用场景说明
sklearn
准备工作
sklearn 安装
sklearn 上手
线性回归实战
归一化的作用:
-
归一化后加快了梯度下降求最优解的速度;
-
归一化有可能提高精度(如KNN)
应用场景说明
1)概率模型不需要归一化,因为这种模型不关心变量的取值,而是关心变量的分布和变量之间的条件概率;
2)SVM、线性回归之类的最优化问题需要归一化,是否归一化主要在于是否关心变量取值;
3)神经网络需要标准化处理,一般变量的取值在-1到1之间,这样做是为了弱化某些变量的值较大而对模型产生影响。一般神经网络中的隐藏层采用tanh激活函数比sigmod激活函数要好些,因为tanh双曲正切函数的取值[-1,1]之间,均值为0.
4)在K近邻算法中,如果不对解释变量进行标准化,那么具有小数量级的解释变量的影响就会微乎其微。
sklearn
是集成了最常用的机器学习模型的 Python 库,使用起来非常轻松简单,有着广泛的应用。sklearn 全称 scikit-learn,其中scikit表示SciPy Toolkit,因为它依赖于SciPy库。learn则表示机器学习。
官网地址:https://scikit-learn.org/stable/
中文文档:https://www.sklearncn.cn/

Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
1.分类:是指识别给定对象的所属类别,属于监督学习的范畴,最常见的应用场景包括垃圾邮件检测和图像识别等。
目前Scikit-learn已经实现的算法包括:支持向量机(SVM),最近邻,逻辑回归,随机森林,决策树以及多层感知器(MLP)神经网络等等。 需要指出的是,由于Scikit-learn本身不支持深度学习,也不支持GPU加速,因此这里对于MLP的实现并不适合于处理大规模问题。
2.回归:是指预测与给定对象相关联的连续值属性,最常见的应用场景包括预测药物反应和预测股票价格等。目前Scikit-learn已经实现的算法包括:支持向量回归(SVR),脊回归,Lasso回归,弹性网络(Elastic Net),最小角回归(LARS),贝叶斯回归,以及各种不同的鲁棒回归算法等。可以看到,这里实现的回归算法几乎涵盖了所有开发者的需求范围,而且更重要的是,Scikit-learn还针对每种算法都提供了简单明了的用例参考。
3.聚类:是指自动识别具有相似属性的给定对象,并将其分组为集合,属于无监督学习的范畴,最常见的应用场景包括顾客细分和试验结果分组。目前Scikit-learn已经实现的算法包括:K-均值聚类,谱聚类,均值偏移,分层聚类,DBSCAN聚类等。
4.数据降维:是指使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
5.模型选择:是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:格点搜索,交叉验证和各种针对预测误差评估的度量函数。
6.数据预处理:是指数据的特征提取和归一化,是机器学习过程中的第一个也是最重要的一个环节。这里归一化是指将输入数据转换为具有零均值和单位权方差的新变量,但因为大多数时候都做不到精确等于零,因此会设置一个可接受的范围,一般都要求落在0-1之间。而特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。需要特别注意的是,这里的特征提取与上文在数据降维中提到的特征选择非常不同。特征选择是指通过去除不变、协变或其他统计上不重要的特征量来改进机器学习的一种方法。
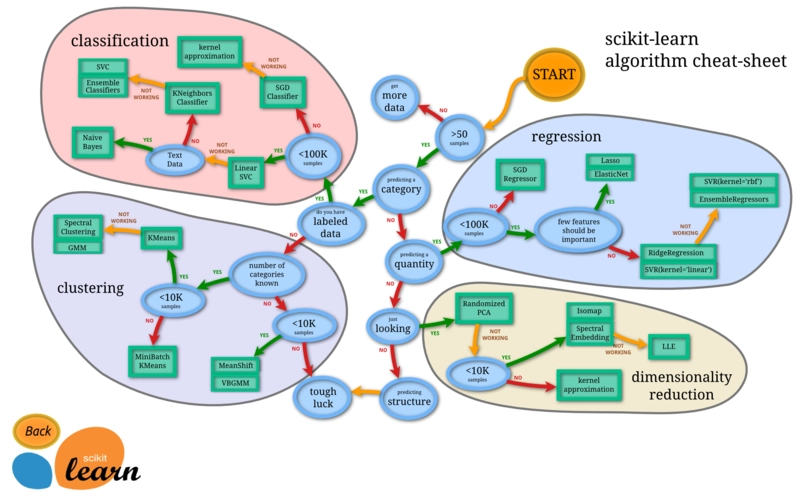
总结来说,Scikit-learn实现了一整套用于数据降维,模型选择,特征提取和归一化的完整算法/模块,虽然缺少按步骤操作的参考教程,但Scikit-learn针对每个算法和模块都提供了丰富的参考样例和详细的说明文档。
准备工作
任何一个工具箱都不是独立存在的,scikit-learn 是基于 Python 语言,建立在 NumPy ,SciPy 和 matplotlib 上。在上手sklearn之前,建议掌握的原理或工具有:
-
机器学习算法原理。
-
PyCharm IDE 或者 Jupyter Notebook。
-
Python的基本语法和Python中的面向对象的概念与操作。
-
Numpy的基本数据结构和操作方法(加减乘除、排序、查找、矩阵的计算等)。
-
Pandas读写数据的方法,举个例子,读csv文件中的数据,用Pandas也就一句data = pandas.read_csv('data.csv')。
-
Matplotlib 绘图工具,满足我们对基本的数据结果的各种展示需求。
sklearn 安装
scikit-learn 安装非常简单:
使用 pip
pip install -U scikit-learn
或者 conda:
conda install scikit-learn
如果你还没有Python和Anaconda或者PyCharm,可以参考这篇文章
sklearn 上手
学习sklearn最好的方式,就是在实践中学习,让我们来看看用sklearn实现线性回归的例子。线性回归的公式非常简单:

处于实际应用的角度,我们其实只关心两个问题:如何根据现有的数据算出线性回归模型的参数?参数求出之后我们怎么用它来预测?
sklearn 官网很直接地给出了这样一段代码:
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
# y = 1 * x_0 + 2 * x_1 + 3
y = np.dot(X, np.array([1, 2])) + 3
reg = LinearRegression().fit(X, y)reg.coef_
# array([1., 2.])
reg.intercept_
# 3.0000...
reg.predict(np.array([[3, 5]]))
# array([16.])

Xarray([[1, 1],[1, 2],[2, 2],[2, 3]])
yarray([ 6, 8, 9, 11])
这里注意下,X 是一个 5×2 的数组(和矩阵稍有不同,但形状完全一样),而y是一个一维的数组。由此可见,我们要用来拟合的数据,其输入变量必须是列向量,而输出的这个变量则相对自由(注意,这也是sklearn相对比较坑的一点;官方的说法是为了节省内存开销,但如果熟悉Matlab、R等相对更加专业的计算类程序的人容易觉得不适应)。
那么明白了这一点,我们要输入怎样的数据就完全明确了。那么如果我们想换上自己的数据不外乎也就是把 X 和 y 按照同样的格式输入即可。
-
第6行,首先是直接调用LinearRegression类的方法fit(X,y),直接实例化了一个线性回归模型,并且用上面生成的数据进行了拟合。
看到这里就能够明白了,原来只需要把数据按照格式输入,就可以完成模型的拟合。事实上这段代码也可以改成以下形式:
reg = LinearRegression()
reg.fit(X, y)
因为fit()方法返回值其实是模型本身self的一个实例(也就是返回了它自己,这个 LinearRegression对象),所以在初始化reg之后只需要直接调用fit(),它自己对应的系数值(属性)就被成功赋值。这种写法更为推荐,因为它虽然看起来多出一行,但整个运行的机制则显得更加清晰。
-
第9和11行是系数和偏差值的展示。上面提到,注释中已经说明了数据就是由方程 生成的,而这时我们看到系数值分别等于
1,2而偏差值是3,和理论模型完全一致。 -
第13行,此时它调用了
LinearRegression类的predict()方法。那么显然,这个方法就是利用拟合好的线性回归模型来计算新输入值对应的输出值。这里新输入值仍然和拟合时的格式保持一致。
那么小结一下,根据官方文档,要拟合一个线性回归模型并且预测出新值的话,其实只需要进行四个步骤:
-
格式化数据,输入为n*d的数组,其中n表示数据的个数,d是维度;输出值是一维数组
-
初始化模型LinearReregression()
-
拟合fit(X,y)
-
预测predict(X_test)
线性回归实战
实战案例中使用了diabetes数据集。该数据集包括442位糖尿病患者的生理数据及一年以后的病情发展情况。共442个样本,每个样本有十个特征,分别是 [‘age’, ‘sex’, ‘bmi’, ‘bp’, ‘s1’, ‘s2’, ‘s3’, ‘s4’, ‘s5’, ‘s6’],对应年龄、性别、体质指数、平均血压、S1~S6一年后疾病级数指标。Targets为一年后患疾病的定量指标,值在25到346之间。
本节我们将通过糖尿病患者的体重bmi,预测糖尿病患者接下来病情发展的情况。在实际应用中,可以根据预测模型,提前预知患者的病情发展,从而提前做好应对措施,改善患者的病情。
# 导入必要的工具箱
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score# 导入糖尿病数据集
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]# 取第三列bmi的值# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]# Create linear regression object
regr = linear_model.LinearRegression()# fit()函数拟合
regr.fit(diabetes_X_train, diabetes_y_train)# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)# The coefficients 输出回归系数
print("Coefficients: \n", regr.coef_)
# The mean squared error
print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
# The coefficient of determination: 1 is perfect prediction 决定系数,越接近1越好
print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred))# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color="black")
plt.plot(diabetes_X_test, diabetes_y_pred, color="blue", linewidth=3)plt.xticks(())
plt.yticks(())plt.show()
# print输出评价指标
Coefficients:[938.23786125]
Mean squared error: 2548.07
Coefficient of determination: 0.47
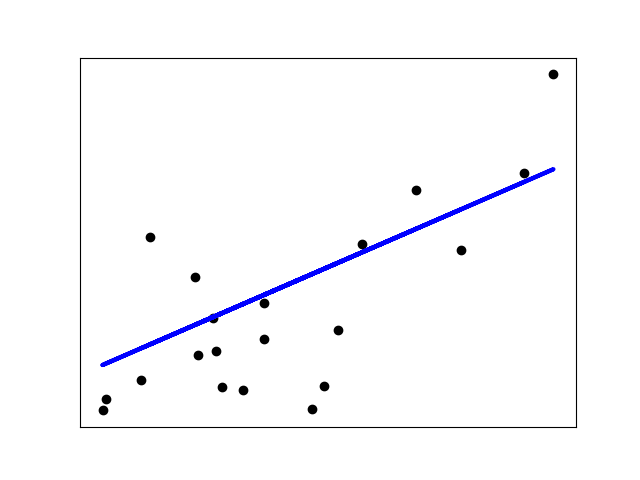
通过模型可以看出,随着体重指标的增加,病情的级数也在增加,因此可以预测某位患者接下来一年内病情将会如何发展。当然,通过多变量分析我们可以得到更好的模型。
相关文章:
归一化的作用,sklearn 安装
目录 归一化的作用: 应用场景说明 sklearn 准备工作 sklearn 安装 sklearn 上手 线性回归实战 归一化的作用: 归一化后加快了梯度下降求最优解的速度; 归一化有可能提高精度(如KNN) 应用场景说明 1)概率模型不需要归一化ÿ…...

半导体企业如何进行跨网数据传输,又能保护核心数据安全?
为了保护设计文档、代码文件等内部核心数据,集成电路半导体企业一般会将内部隔离成多个网络,比如研发网、办公网、生产网、测试网等。常规采取的网络隔离手段如下: 1、云桌面隔离:一方面实现数据不落地,终端数据安全有…...
lvs-DR模式:
lvs-DR数据包流向分析 客户端发送请求到 Director Server(负载均衡器),请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP)到达内核空间。 Director Server 和 Real Server 在同一个网络中,数据通过二层数据链路…...
Delphi 开发手持机(android)打印机通用开发流程(举一反三)
目录 一、场景说明 二、厂家应提供的SDK文件 三、操作步骤: 1. 导出Delphi需要且能使用的接口文件: 2. 创建FMX Delphi项目,将上一步生成的接口文件(V510.Interfaces.pas)引入: 3. 将jarsdk.jar 包加入到 libs中…...

nodejs替换模版中${}的内容
要在js中想要替换替换模板中的${},可以使用字符串的replace()方法结合正则表达式或者函数来实现替换操作。 以下是两种常见的替换方式: 使用正则表达式: 方法一: const template "Hello, ${name}! Today is ${day}."…...
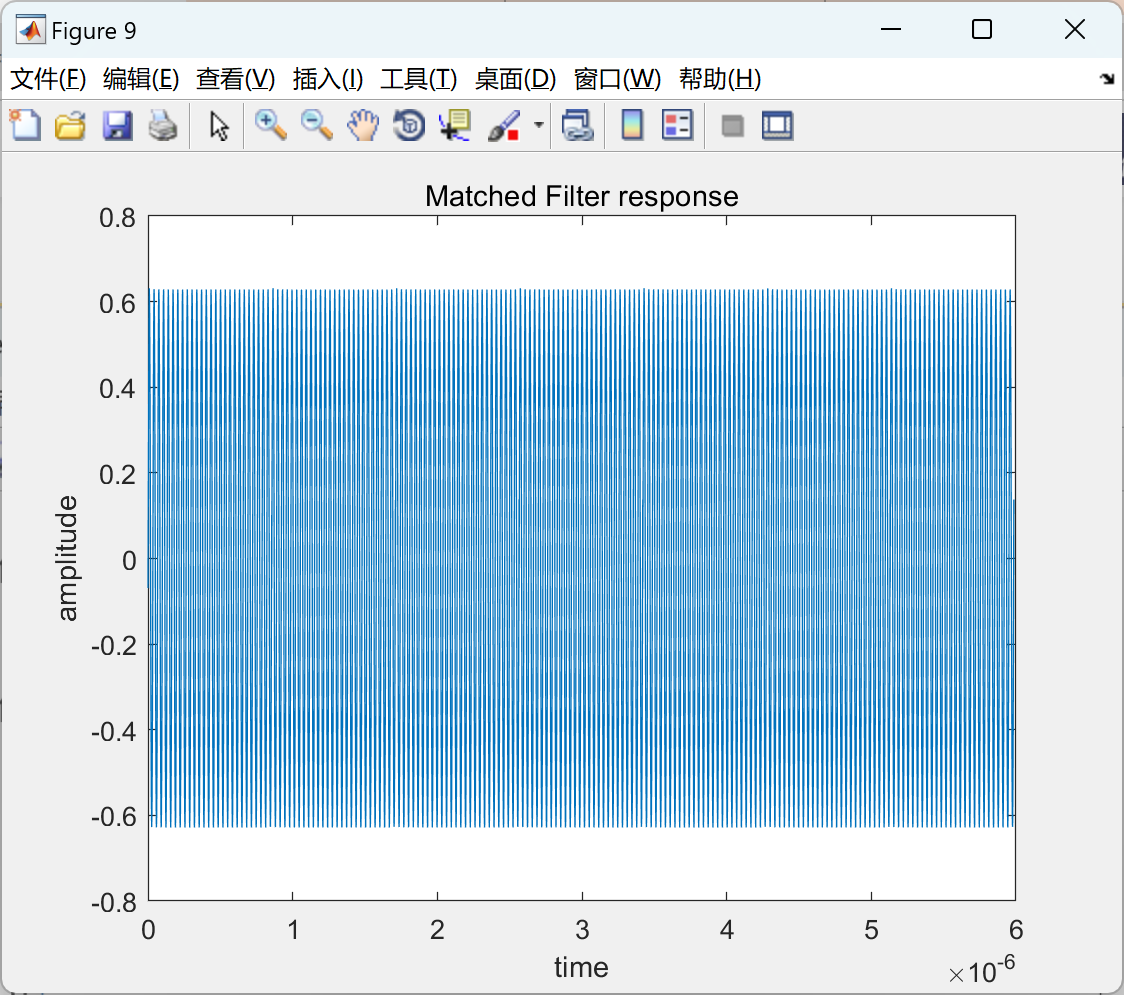
【快速傅里叶变换(fft)和逆快速傅里叶变换】生成雷达接收到的经过多普勒频移的脉冲雷达信号(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
嵌入式学习之linux
今天,主要对linux文件操作原理进行了学习,主要学习的内容就是对linux文件操作原理进行理解。写的代码如下:...

自动驾驶合成数据科普一:不做真实数据的“颠覆者”,做“杠杆”
前言: 在7月底的一篇文章中,九章智驾提到,数据闭环能力是自动驾驶下半场的“入场券”,这一观点在行业内引起了广泛共鸣。 在数据闭环体系中,仿真技术无疑是非常关键的一环。仿真的起点是数据,而数据又分为真…...
云服务器 宝塔(每次更新)
su root 输入密码 使用 root 权限 /etc/init.d/bt default 获取宝塔登录 位置和账号密码。进入宝塔 删除数据库 删除php前端站点 删除PM2后端项目 前端更改完配置打包dist文件 后端更改完配置项目打包 数据库结构导出 导入数据库 配置 PM2 后端 安装依赖...
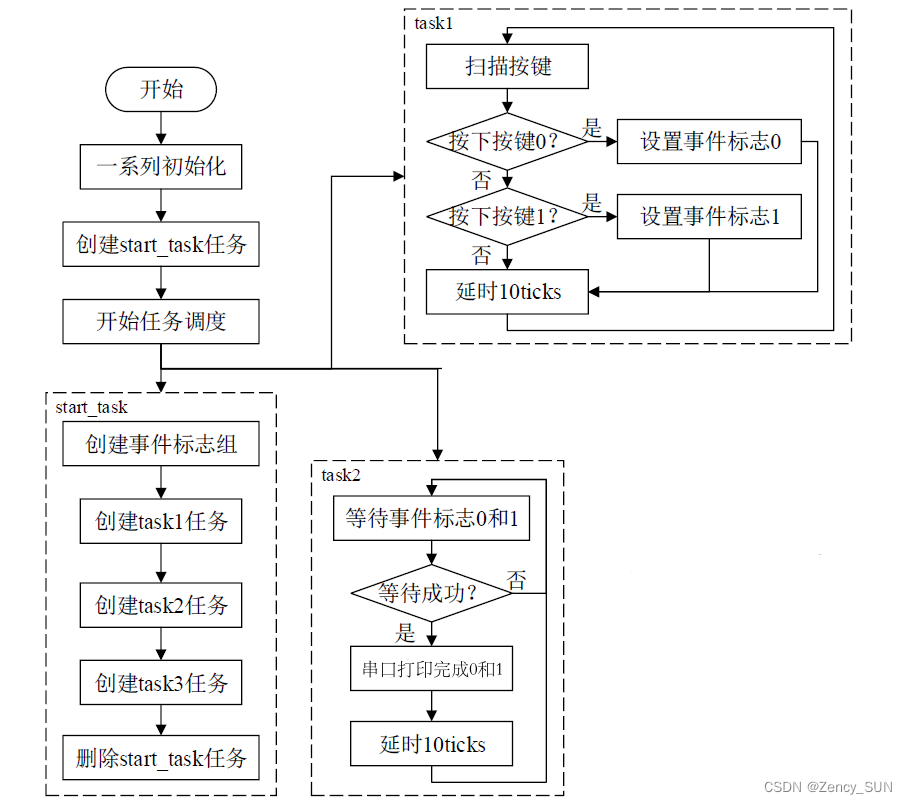
【学习FreeRTOS】第16章——FreeRTOS事件标志组
1.事件标志组简介 事件标志位:用一个位,来表示事件是否发生 事件标志组是一组事件标志位的集合, 可以简单的理解事件标志组,就是一个整数。 事件标志组的特点: 它的每一个位表示一个事件(高8位不算&…...

Echarts 柱状图的 itemStyle的normal中label如何format?
在 Echarts 中,可以通过设置 formatter 属性来对柱状图的标签进行自定义格式化。例如: itemStyle: {normal: {label: {show: true,formatter: function(params) {return params.value.toFixed(2); // 将标签内容保留两位小数}}} } 在上面的例子中&…...

我的笔记:数据体系规则
1、中台数据体系特征 覆盖全域数据:数据集中建设,覆盖所有业务过程数据; 结构层次清晰:纵向数据分层,横向主题域,业务过程划分,让整个层析结构清晰易理解; 数据准确一致:…...

苍穹外卖 day2 反向代理和负载均衡
一 前端发送的请求,是如何请求到后端服务 前端请求地址:http://localhost/api/employee/login 路径并不匹配 后端接口地址:http://localhost:8080/admin/employee/login 二 查找前端接口 在这个页面上点击f12 后转到networ验证࿰…...

【SpringBoot】SpringBoot完整实现电子商务系统
一个完整的电子商务系统需要涉及到前台展示、后台管理、商品管理、订单管理、用户管理等各方面。这里提供一个简单的实现示例,供参考。 前端代码 前端使用Vue框架,以下是部分代码示例: 商品列表页: <template><div>…...
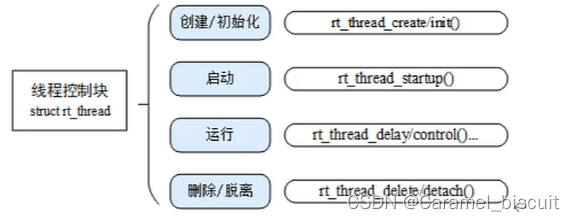
RT-Thread 线程管理(学习二)
线程相关操作 线程相关的操作包括:创建/初始化、启动、运行、删除/脱离。 动态线程与静态线程的区别:动态线程是系统自动从动态内存堆上分配栈空间与线程句柄(初始化heap之后才能使用create创建动态线程),静态线程是…...

ESP32应用教程(1)— VL53L3CX距离传感器
文章目录 前言 1 产品概述 1.1 技术规格 1.2 系统框图 1.3 设备引脚分布 2 工作流程 2.1 系统功能描述 2.2 状态机描述 2.3 测距模式说明 3 控制接口 3.1 设备地址 3.2 IC写1个字节数据 3.3 IC读1个字节数据 3.4 IC写多个字节数据 3.5 IC读多个字节数据 3.6 IC…...

Redis从基础到进阶篇(一)
目录 一、了解NoSql 1.1 什么是Nosql 1.2 为什么要使用NoSql 1.3 NoSql数据库的优势 1.4 常见的NoSql产品 1.5 各产品的区别 二、Redis介绍 2.1什么是Redis 2.2 Redis优势 2.3 Redis应用场景 2.4 Redis下载 三、Linux下安装Redis 3.1 环境准备 3.2 Redis的…...

postgresql的基本使用
添加字段 ALTER TABLE AAF_SYS_PARAM ADD REFER_ID VARCHAR(64); ALTER TABLE AAF_SYS_PARAM ADD OPTION_JSON VARCHAR(3000);COMMENT ON COLUMN AAF_SYS_PARAM.REFER_ID IS 关联节点ID; COMMENT ON COLUMN AAF_SYS_PARAM.OPTION_JSON IS 选择项枚举json; 修改字段 ALTER T…...
)
ABC 258 G Triangle(bitset 优化)
ABC 258 G Triangle(bitset 优化) ABC 258 G Triangle 大意:给出一个邻接矩阵 ,用来记录两两元素间是否连接 , 计算其中三元环的数目。 思路: 不妨先想暴力解法 for(int i 1 ; i < n ; i ){for(int j i 1 ; j < n ;…...
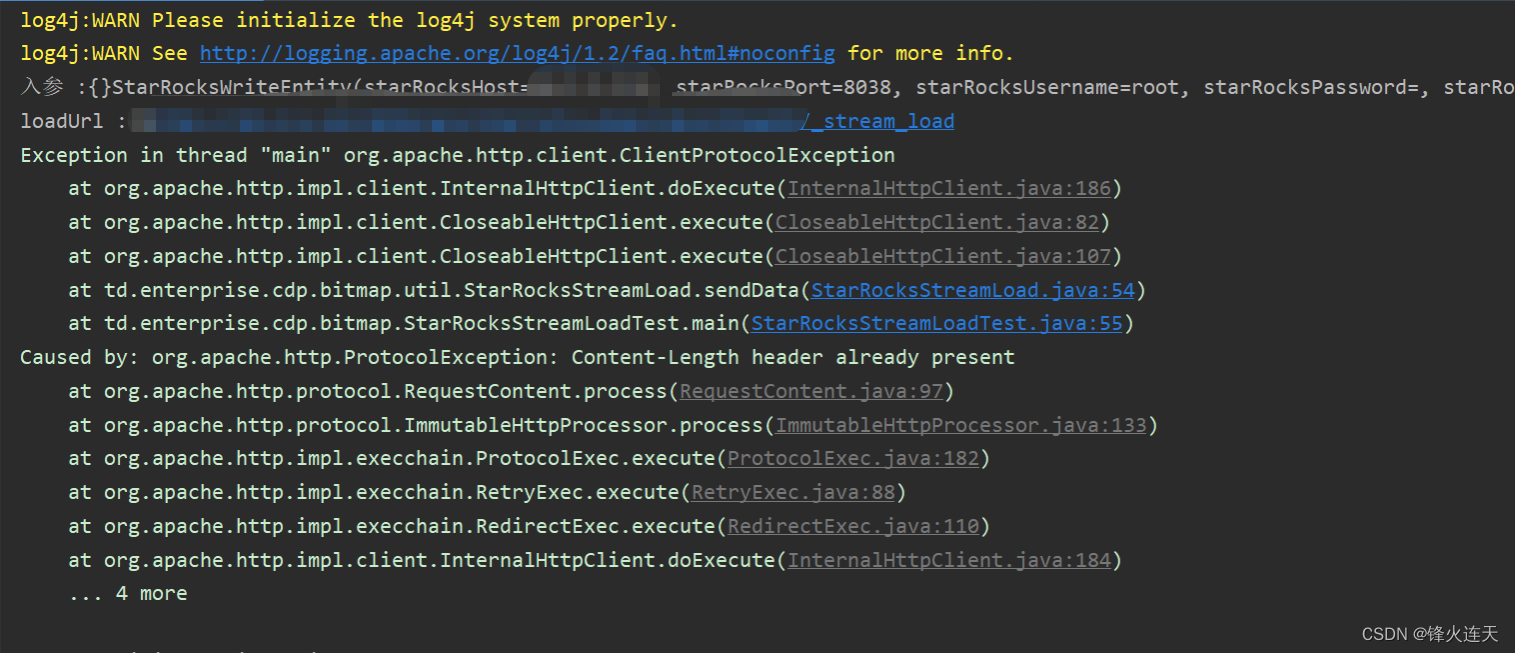
使用StreamLold写入 Starrocks报错:Caused by org
问题描述 使用StreamLoad写入Starrocks报错,报这个错误:Caused by: org.apache.http.ProtocolException: Content-Length header already present 代码案例 引入依赖 <!-- Starrocks使用StreamLoad发送Http请求 --><dependency><groupId>or…...

JeecgBoot 低代码平台:协同工作与 Flowable 流程审批,如何选?
JeecgBoot 低代码平台两模块引困惑很多团队在接入 JeecgBoot 低代码平台后,面对 "协同工作" 和 "Flowable 流程审批" 两个模块时常常陷入困惑:两个都是处理审批流程的,到底用哪个?能混着用吗?设计…...

日语语音识别终极指南:5个技巧让Faster-Whisper-GUI准确率提升300%
日语语音识别终极指南:5个技巧让Faster-Whisper-GUI准确率提升300% 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI 想要在本地高效处理日语音频转写和字幕生成吗&am…...

JavaScript自动化PPT生成解决方案:PptxGenJS高效实践指南
JavaScript自动化PPT生成解决方案:PptxGenJS高效实践指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 在当今数…...

这几家有机膨润土厂家口碑稳定,你选对了吗?
在工业与新材料领域,有机膨润土作为一种关键的功能性添加剂,正从“幕后”走向“台前”。无论是涂料、油墨的流变控制,还是钻井液、润滑脂的耐温需求,又或是农药、兽药的载体优化,它的身影无处不在。然而,面…...

# 040、实战项目五:多 Agent 协作系统 —— 项目经理、开发者、测试者角色模拟
从一次凌晨三点的事故说起 去年做智能客服系统重构,我犯了个低级错误——让单个Agent既写代码又自测。结果上线当天,它把“用户退款”的SQL写成了DELETE FROM orders WHERE status‘refund’,还自信满满地标注“测试通过”。凌晨三点被运维电…...

不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响
不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响 在模拟集成电路设计中,电阻作为最基本的无源元件之一,其版图实现往往被初学者视为简单的金属连线问题。然而,当设计从原理图转向物理实现时ÿ…...

L298N驱动模块进阶玩法:用Arduino实现直流电机的软启动、缓停与速度曲线控制
L298N驱动模块进阶玩法:用Arduino实现直流电机的软启动、缓停与速度曲线控制 在创客和嵌入式开发领域,直流电机的控制是基础但至关重要的技能。大多数初学者会从简单的正反转和调速开始,但当项目需要更精细的运动控制时,粗暴的启…...

i.MX6ULL LCD驱动适配实战:从设备树到时序调试全解析
1. 项目概述与核心价值最近在搞一个基于i.MX6ULL的工控HMI项目,屏幕显示是绕不开的一环。市面上很多教程要么只讲Framebuffer应用,要么直接给个现成的设备树文件让你照着改,至于里面的参数怎么来的、屏幕初始化序列怎么配,往往一笔…...

STM32 ADC实战避坑:轮询、中断、DMA到底怎么选?我的项目血泪经验
STM32 ADC实战避坑:轮询、中断、DMA到底怎么选?我的项目血泪经验 在嵌入式开发中,ADC(模数转换器)是连接模拟世界与数字世界的关键桥梁。无论是电池电压监测、环境光传感还是工业控制中的各种模拟量采集,AD…...

游戏手柄延迟检测:为什么你的操作总是慢半拍?
游戏手柄延迟检测:为什么你的操作总是慢半拍? 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 你有没有在玩竞技游戏时,明明按下了按键&am…...