知识图谱Neo4j安装到实践全过程

前言:Hello大家好,我是Dream。 在本次实战中,我们将一起完成知识图谱Neo4j安装到实践全过程,探索其中的关系和属性。知识图谱是一种以三元组形式存储的数据结构,由实体、关系和属性组成,能够帮助我们更好地理解和分析复杂的知识关系,一起来看看吧~
一、语义网络写入图形数据库
实验目的
(1)了解向数据库中写入语义网络的方法。
(2)简单使用Neo4j呈现语义网络。
实验要求
本次实验后,能理解语义网络的 节点(Node)和关系(Relationship) 在数据库中是如何呈现的。
实验原理
将一个事实用语义网络表示,首先要找出它的节点,再描述它与其他节点的关系,最后用Python 写入数据库中。
实验准备
1.安装JDK
下载neo4j之前,首先要安装JDK。
1.1 下载
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html
JDK版本的选择一定要恰当,建议jdk1.8 比较稳定 版本太高或者太低都可能导致后续的neo4j无法使用。
以下是安装路径:
1.2 配置环境变量
安装好JDK之后就要开始配置环境变量了。 配置环境变量的步骤如下:
在开始处直接搜索环境变量,打开后会出现如下界面,然后点击右下角处环境变量:
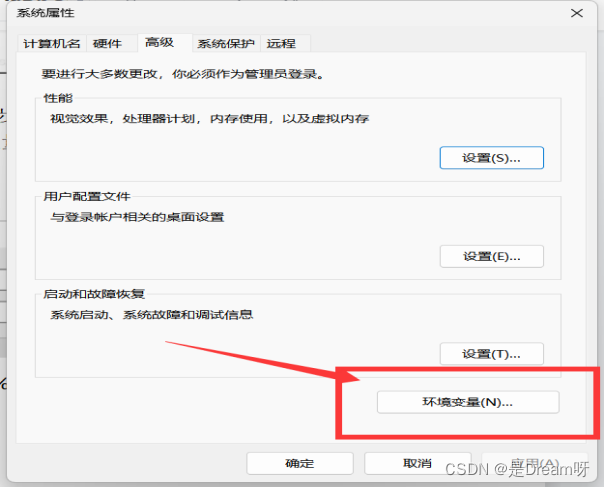
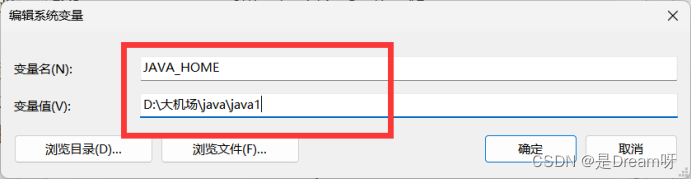
在下方的系统变量区域,新建环境变量,命名为JAVA_HOME,变量值设置为刚才JAVA的安装路径,我这里是D:\大机场\java\java1。
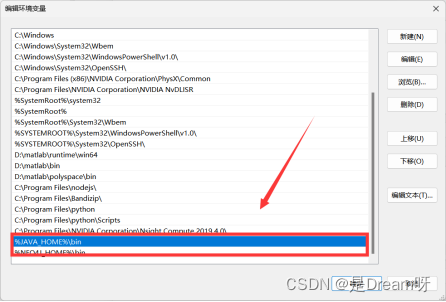
编辑系统变量区的Path,点击新建,然后输入 %JAVA_HOME%\bin
打开命令提示符CMD(WIN+R,输入cmd),输入 java -version,若提示Java的版本信息,则证明环境变量配置成功:
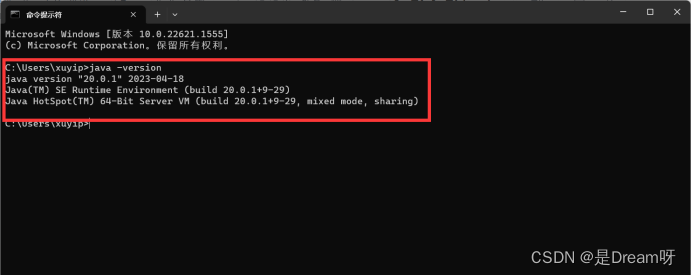
2. 安装neo4j
安装好JDK之后,就可以安装neo4j了。
2.1 下载
官方下载链接:https://neo4j.com/download-center/#community
在这里,我下载的是neo4j社区版5.8.0。
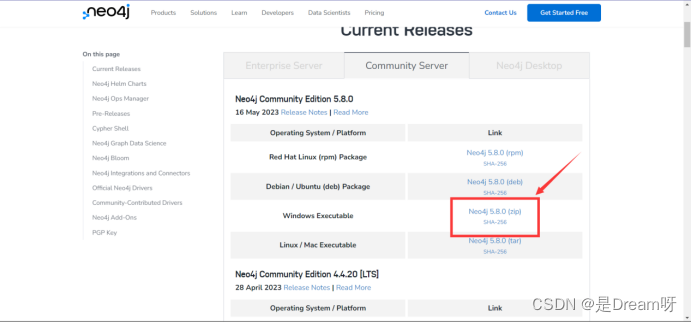
下载好之后,直接解压到合适的路径就可以了,无需安装:
2.2 配置环境变量
接下来要配置环境变量了,与刚才JAVA环境变量的配置方法极为相似,因此在这里只进行简单描述。
在系统变量区域,新建环境变量,命名为NEO4J_HOME,变量值设置为刚才neo4j的安装路径,我这里是D:\大机场\neo4j\neo4j1。
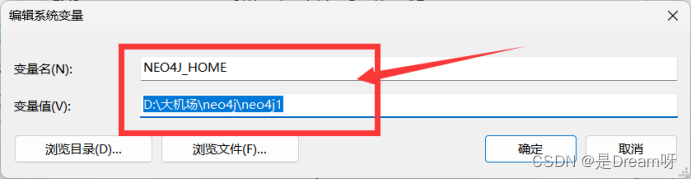
编辑系统变量区的Path,点击新建,然后输入 %NEO4J_HOME%\bin,最后,点击确定进行保存就可以了。
3. 启动neo4j
以管理员身份运行cmd。
然后,在命令行处输入neo4j.bat console
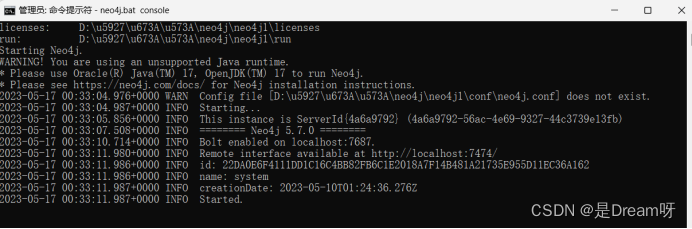
如出现此界面,则证明neo4j启动成功。
在浏览器中输入界面中给出的网址http://localhost:7474/,则会显示如下界面。
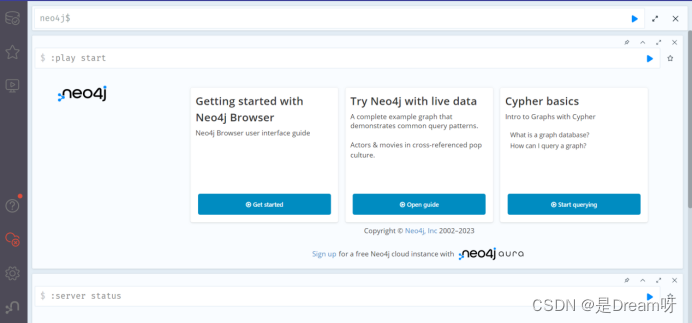
默认的用户名和密码均为neo4j。
至此,neo4j安装完毕~
实验步骤
1.从neomodel包导入类。
from neomodel import StructuredNode, StringProperty, RelationshipTo, RelationshipFrom, config
2.连接Neo4j图形数据库。
config.DATABASE URL= 'bolt://neo4i:neo4ialocalhost:7687'
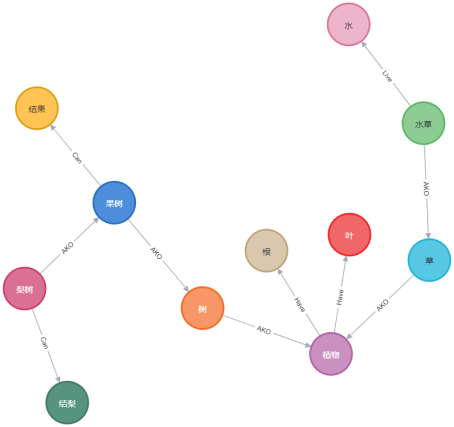
即将要构造的事实为“树和草都是植物。树和草都有叶和根。水早是早,且生长在水中。果树是树,日会结里、烈树是里树的一种,它会结梨”。
3.编写节点类。
植物、树、草、叶、根、水草、水、果树、结果、梨树、结架赵些节点英继承自StructuredNode类,包括节点属性和连接关系。
class Plant(StructuredNode):name = StringProperty(unique_index=True)has1 = RelationshipFrom("Tree", "AKO")has2 = RelationshipFrom('Grass', 'AKO')have1 =RelationshipTo('Leaf', 'Have')have2 = RelationshipTo('Root', 'Have')
class Tree(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Plant', 'AKO')have = RelationshipFrom('Fruiter', 'AKO')
class Grass(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Plant' , 'AKO')has = RelationshipFrom('Waterweeds', 'AKO')
class Leaf(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Plant', 'Have')
class Root(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Plant', 'Have')
class Waterweeds(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Grass' , 'AKO')live = RelationshipTo('Water', 'Live')
class Water(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Waterweeds', 'Live')class Fruiter(StructuredNode):name = StringProperty(unique_index=True)ako = RelationshipTo('Tree', 'AKO')can = RelationshipTo('Bear', 'Can')have = RelationshipFrom('Pear','AKO')class Bear(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Fruiter' , 'Can')class Pear(StructuredNode):name = StringProperty(unique_index = True)ako = RelationshipTo('Fruiter', 'AKO')can = RelationshipTo('BearPear', 'Can')class BearPear(StructuredNode):name = StringProperty(unique_index=True)have = RelationshipFrom('Pear', 'Can')plant =Plant(name="植物").save()
tree = Tree(name="树").save()
grass = Grass(name="草" ).save()
leaf = Leaf(name= "叶" ).save()
root = Ro
4.根据类生成实例。
leaf = Leaf(name= "叶" ).save()
root = Root(name="根").save()
waterweeds = Waterweeds(name="水草").save()
water = Water(name="水" ).save()
fruiter = Fruiter(name="果树").save()
bear = Bear(name="结果").save()
pear = Pear(name="梨树").save()
bearpear = BearPear(name="结梨").save()
5.创建实例之间的连接关系。
pear.ako.connect(fruiter)
pear.can.connect(bearpear)
fruiter.ako.connect(tree)
fruiter.can.connect(bear)
waterweeds.ako.connect(grass)
waterweeds.live.connect(water)
plant.have1.connect(leaf)
plant.have2.connect(root)
tree.ako.connect(plant)
grass.ako.connect(plant)
实验结果
二、水浒传知识图谱构建
启动neo4j
以管理员身份运行cmd,
在命令行处输入neo4j.bat console
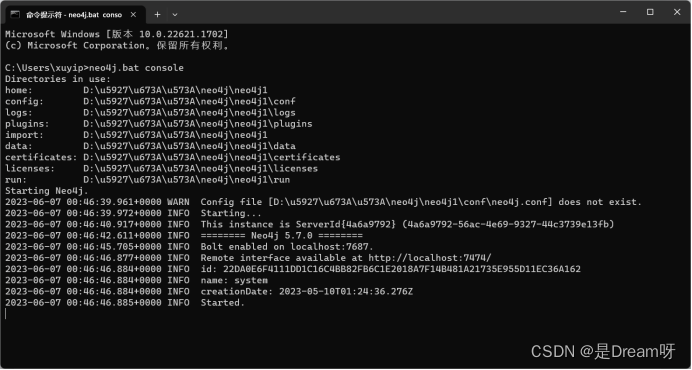
如出现此界面,则neo4j启动成功
在浏览器中输入界面中给出的网址http://localhost:7474/,即可打开neo4j的可视化界面。
打开jupyter notebook
1.进入 jupyter notebook:
在命令行中输入"jupyter notebook"命令并回车后,会自动跳转到jupyter notebook的工作区页面。这样,我们就可以开始进行知识图谱的构建了。
2.数据集下载
数据集:triples.csv
链接:https://pan.baidu.com/s/19vrJ1vkEf2lgchBkF8OALQ?pwd=gn8o
提取码:gn8o
数据说明:构建知识图谱需要把数据处理成三元组<实体1,关系,实体2>或<实体,属性,属性值>的形式,每个三元组(triples)可看成是由subject(主语)、predicate(谓语)和object(宾语)组成。知识图谱中的三元组主要包含两种,一种是关系三元组relation triples,另一种是属性三元组attribute triples,relation triples中的subject和object均是实体,而predicate通常被称为关系。attribute triples中的subject是实体,而object则是取值(value),该值通常是一个数值或者文本,其predicate通常称为属性。
数据又分为非结构化数据(例如:文本、文档、图片等),半结构化文本(如:日志文件、XML文档、JSON文档等)和结构化数据,本实验使用的数据集是结构化的三元组数据,无需做额外处理,可以直接使用。
3.安装第三方库
为了能够顺利进行知识图谱构建,我们需要安装一些必要的第三方库:
- 安装py2neo库:用于与neo4j图数据库进行交互。
- 安装pyahocorasick,numpy和pandas库:用于处理数据集和进行相关操作。
!pip install py2neo pyahocorasick numpy pandas
!pip install pytest-cov==2. 0
!pip install pytest-filter-subpackage==0. 1
!pip install typed ast== 1. 4. 0
4.导包
在jupyter notebook中,我们需要导入一些必要的库来进行知识图谱的构建。在代码开始的地方加入以下代码即可:
import py2neo
from py2neo import Graph,Node,Relationship,NodeMatcher
5.连接图数据库
为了能够与neo4j图数据库进行交互,我们需要先连接到该数据库。接下来,我们可以使用以下代码来连接图数据库:
auth的值分别为neo4j登录时的账号和密码,一定要使用安装时更改之后的密码,否则无法连接到图数据库。
g=Graph("neo4j://localhost:7687", auth=("neo4j", "mima"))
6.图谱构建
import csv
with open(r"D:\PycharmProjects\知识表示\triples.csv",'r', encoding='utf-8') as f:reader=csv.reader(f)for item in reader:if reader.line_num==1:continueprint('当前行数:',reader.line_num,"当前内容:",item)start_node=Node("Person" ,name=item[0])end_node=Node("Person", name=item[1])relation=Relationship(start_node,item[3],end_node)g.merge(start_node,"Person", "name")g. merge(end_node,"Person","name")g.merge(relation,"Person","name")
这段代码将逐行读取数据集文件,并将每行数据转换为三元组的形式进行图谱构建。
运行代码后,可以在控制台上看到当前行数和对应的内容。
结果显示:
结果显示:
运行成功后,我们可以在neo4j的可视化界面中查看已经构建好的知识图谱。

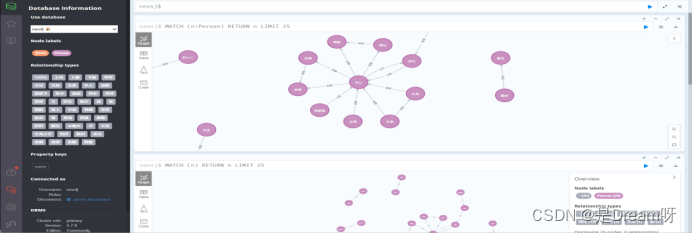
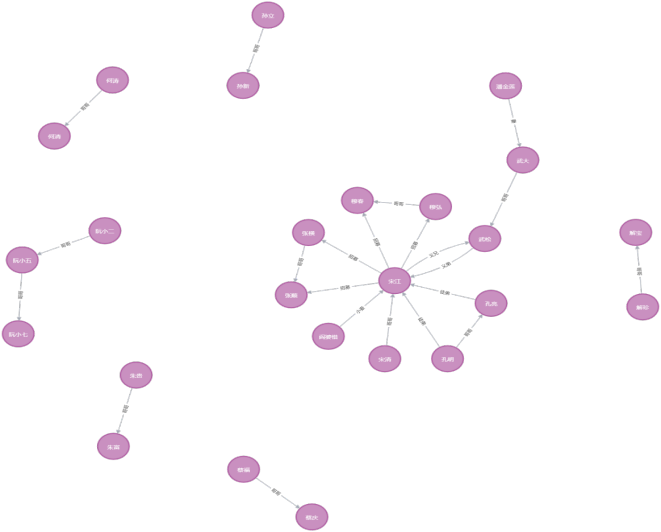
图谱可视化结果
我们可以在neo4j的可视化界面中,通过查询相关节点和关系,来查看已经构建好的水浒传知识图谱的可视化结果。
在界面中输入相应的Cypher查询语句即可。
相关文章:
知识图谱Neo4j安装到实践全过程
前言: Hello大家好,我是Dream。 在本次实战中,我们将一起完成知识图谱Neo4j安装到实践全过程,探索其中的关系和属性。知识图谱是一种以三元组形式存储的数据结构,由实体、关系和属性组成,能够帮助我们更好地…...
贪心算法:简单而高效的优化策略
在计算机科学中,贪心算法是一种简单而高效的优化策略,用于解决许多组合优化问题。虽然它并不适用于所有问题,但在一些特定情况下,贪心算法能够产生近似最优解,而且计算成本较低。在本文中,我们将深入探讨贪…...

一生一芯6——ubuntu rpm软件安装
ubuntu不支持rpm,需要将rpm软件安装包转成deb进行安装 安装alien sudo apt-get install alien格式转换 sudo alien xxx.rpm 在目录下会生成deb的安装包 软件安装 sudo dpkg -i xxx_amd64.deb 安装完成...

Python练习 函数取列表最小数
练习2:构造一个功能函数,可以解决如下问题: 要求如下: 1,任意输入一个列表,函数可以打印出列表中最小的那个数, 例:输入: 23,56,67,4,17,9 最小数是 :4 方法一: #内置函…...

五种重要的 AI 编程语言
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景 简而言之:决定从哪种语言开始可能会令人生畏。 不用担心!本文将解释 AI 中使用的最流行编程语言背后的基础知识,并帮助您决定首先学习哪种语言。对于每种语言,我们将…...
【linux】2 make/Makefile和gitee
文章目录 一、Linux项目自动化构建工具-make/Makefile1.1 背景1.2 实例代码1.3 原理1.4 项目清理 二、linux下第一个小程序-进度条2.1 行缓冲区2.2 进度条 三、git以及gitee总结 ヾ(๑╹◡╹)ノ" 人总要为过去的懒惰而付出代价ヾ(๑╹◡╹)ノ" 一…...
)
db-gpt安装指南(docker版本)
1 下载源码 下载v0.3.5的源码,截止今天(20230823)建议安装这个“稳定”版本。 2 构建镜像 依照自己硬件环境,看看是否要调整一下启动参数。 bash docker/build_all_images.sh \ --base-image nvidia/cuda:11.7.1-devel-ubuntu…...

「Java」《深度解析Java Stream流的优雅数据处理》
《深度解析Java Stream流的优雅数据处理》 一、引言1.1 背景1.2 Stream流的意义 二、Stream流的基本概念2.1 什么是Stream流2.2 Stream与传统集合的对比 三、创建Stream流3.1 通过集合创建Stream3.2 使用Arrays和Stream.of创建Stream3.3 从文件和网络流创建Stream 四、 中间操作…...
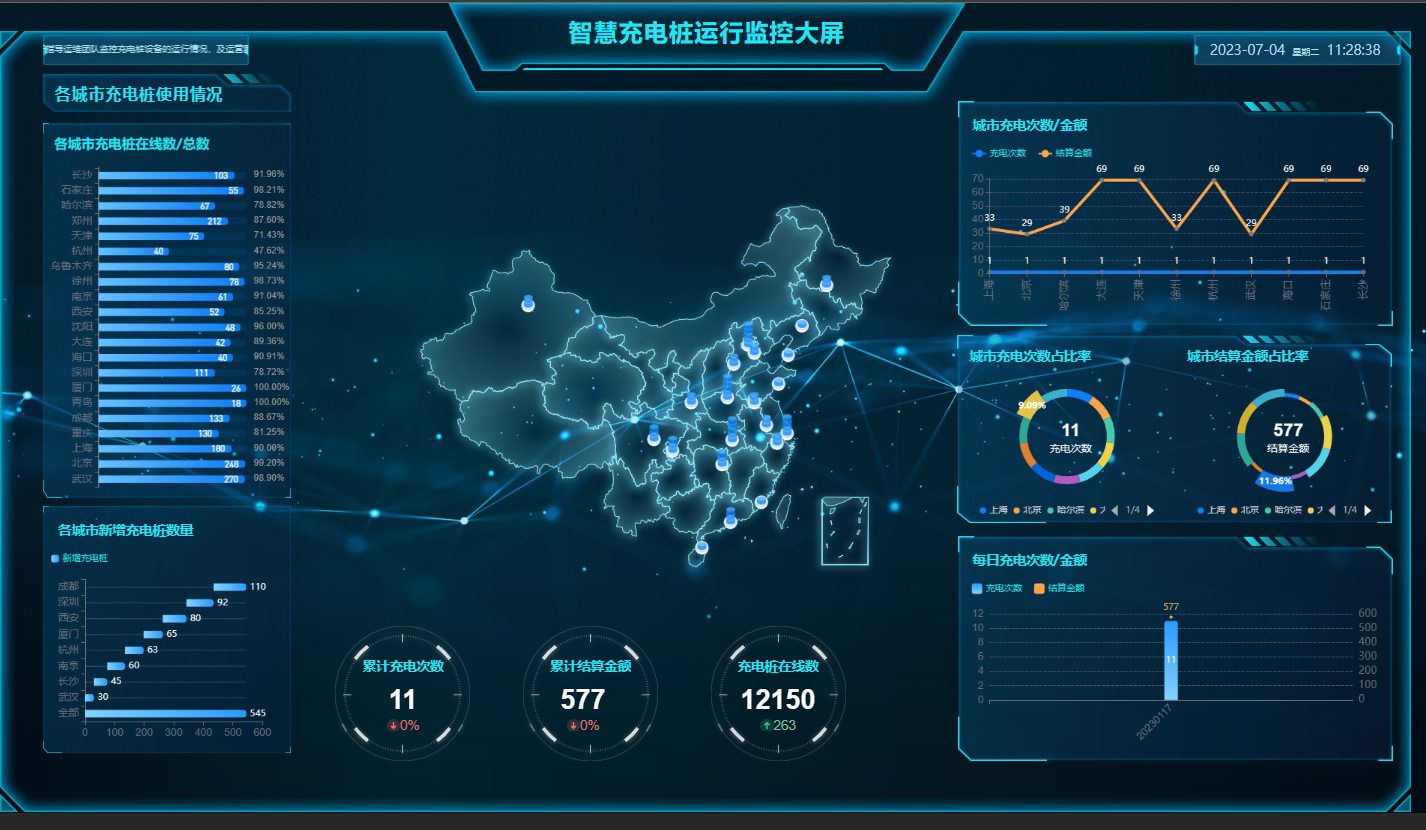
【云驻共创】华为云之手把手教你搭建IoT物联网应用充电桩实时监控大屏
文章目录 前言1.什么是充电桩2.什么是IOT3.什么是端、边、云、应用协同4.什么是Astro轻应用 一、玩转lOT动态实时大屏(线下实际操作)1.Astro轻应用说明1.1 场景说明1.2 资费说明1.3 整体流程 2.操作步骤2.1 开通设备接入服务2.2 创建产品2.3 注册设备2.4…...

Hadoop分布式计算与资源调度:打开专业江湖的魔幻之门
文章目录 版权声明一 分布式计算概述1.1 分布式计算1.2 分布式(数据)计算模式1.3 小结 二 MapReduce概述2.1 分布式计算框架 - MapReduce2.2 MapReduce执行原理2.3 小结 三 YARN概述3.1 YARN & MapReduce3.2 资源调度3.3 程序的资源调度3.4 YARN的资…...
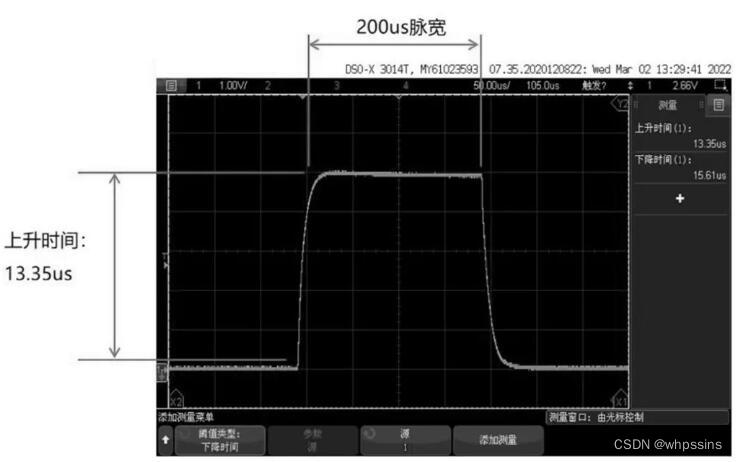
为什么叫源表?源表是如何四象限工作的?
为何称呼为源表? “源”为电压源和电流源,“表”为测量表; “源表”即指一种可作为四象限的电压源或电流源提供精确的电压或电流,同时可同步测量电流值或电压值的测量仪表。(恒流源时测电压,恒压源时测电…...

云原生周刊:Kubernetes v1.28 正式发布 | 2023.8.21
开源项目推荐 kurt 一个 Kubernetes 插件,可提供 Kubernetes 集群中重启内容的上下文信息。 Kubean Kubean 是一个基于 kubespray 的 Kubernetes 集群生命周期管理工具。 k8sgpt k8sgpt 是一款用简单的英语扫描 Kubernetes 集群、诊断和分流问题的工具。 它将…...
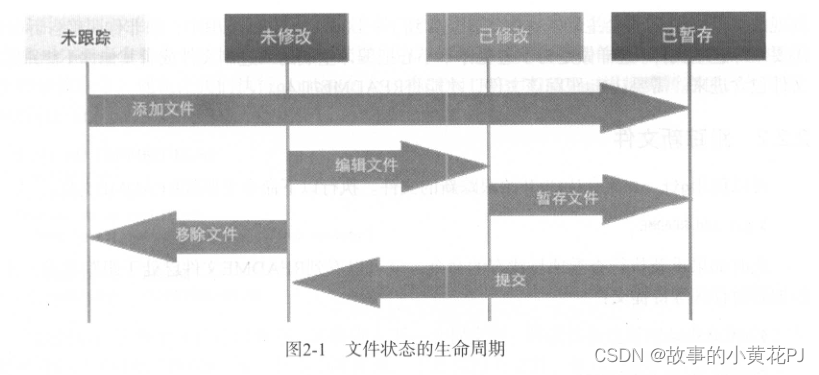
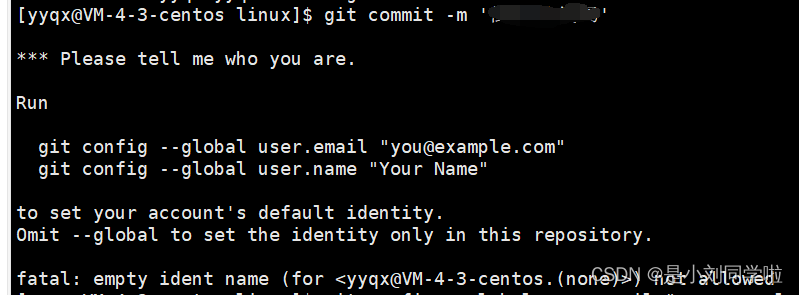
Git基础——基本的 Git本地操作
本文涵盖了你在使用Git的绝大多数时间里会用到的所有基础命令。学完之后,你应该能够配置并初始化Git仓库、开始或停止跟踪文件、暂存或者提交更改。我们也会讲授如何让Git忽略某些文件和文件模式,如何简单快速地撤销错误操作,如何浏览项目版本…...

PythonJS逆向解密——实现翻译软件+语音播报
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 环境使用: python 3.8 pycharm 模块使用: requests --> pip install requests execjs --> pip install PyExecJS ttkbootstrap --> pip install ttkbootstrap pyttsx3 --> pip install pyttsx3 第三…...

gPRC与SpringBoot整合教程
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
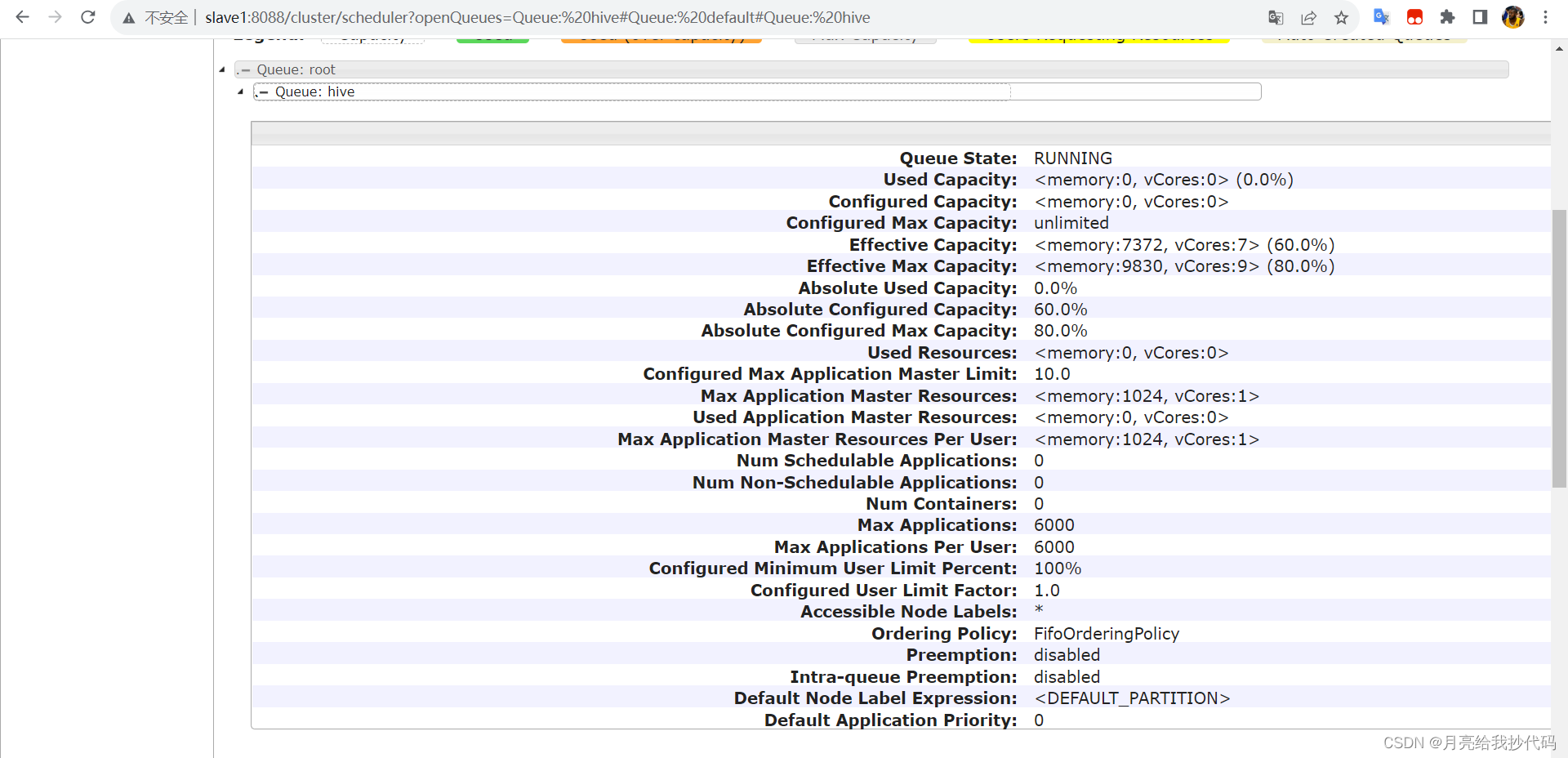
Hadoop Yarn 配置多队列的容量调度器
文章目录 配置多队列的容量调度器多队列查看 配置多队列的容量调度器 首先,我们进入 Hadoop 的配置文件目录中($HADOOP_HOME/etc/hadoop); 然后通过编辑容量调度器配置文件 capacity-scheduler.xml 来配置多队列的形式。 默认只…...

c语言练习题28:杨氏矩阵
杨氏矩阵 从左到右增加 从上到下增加 思路: 代码: #include<stdio.h> int findNum(int(*arr)[3], int x, int y, int k) {int i 0;int j y - 1;while (i<x&&j>0) {if (arr[i][j] > k) {j--;}else if (arr[i][j] < k) {i;…...

梳理系统学习R语言1-R语言实战-使用ggplot进行高阶绘图
以下为书中代码,会添加一些理解 library("ggplot2") ggplot(datamtcars,aes(xwt,ympg))geom_point()geom_point(pch17,color"blue",size2)geom_smooth(method"lm",color"red",linetype2)labs(title"Automobile Data&…...
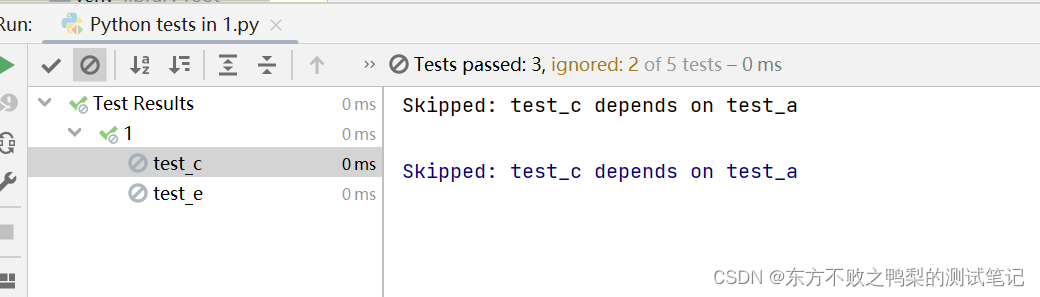
测试框架pytest教程(2)-用例依赖库-pytest-dependency
对于 pytest 的用例依赖管理,可以使用 pytest-dependency 插件。该插件提供了更多的依赖管理功能,使你能够更灵活地定义和控制测试用例之间的依赖关系。 Using pytest-dependency — pytest-dependency 0.5.1 documentation 安装 pytest-dependency 插…...

electron软件安装时,默认选择为全部用户安装
后续可能会用electron开发一些工具,包括不限于快速生成个人小程序、开发辅助学习的交互式软件、帮助运维同学一键部署的简易版CICD工具等等。 开发进度,取决于我懒惰的程度。 不过不嫌弃的同学还是可以先关注一波小程序,真的发布工具了&…...

从PyTorch到边缘设备:手把手教你用OpenVINO优化YOLOv5模型并在Jetson Orin上部署
从PyTorch到边缘设备:OpenVINO优化YOLOv5模型与Jetson Orin部署实战 在工业质检、智慧零售等实时场景中,将YOLOv5这类目标检测模型部署到Jetson Orin等边缘设备时,开发者常面临三大挑战:模型体积臃肿导致内存不足、计算资源有限影…...

从继电器到MOS管:电源控制电路选型实战与仿真验证
1. 继电器与MOS管:电源控制的双面选择 第一次接触电源控制电路时,我像大多数新手一样纠结:到底该用继电器还是MOS管?这个问题困扰了我整整两周,直到在某个深夜调试电路时,继电器"咔嗒"的机械声突…...

别再混着用了!详解Nginx 1.25.1中独立的http2指令与listen指令的拆分逻辑
Nginx配置演进:从listen指令到独立http2指令的技术深析 当你在Nginx 1.25.1的日志中发现the "listen ... http2" directive is deprecated警告时,这不仅仅是一个简单的语法变更通知。它标志着Nginx在协议支持架构上的一次重要演进,…...

ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程
ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否为ThinkPad笔记本的风扇噪音而烦恼ÿ…...

ToastFish:如何在Windows通知栏中偷偷背单词的终极指南
ToastFish:如何在Windows通知栏中偷偷背单词的终极指南 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish 你是否曾经在忙碌的工作间隙想要学习英语,却又担心被同事或老板…...

DLSS Swapper:免费开源的游戏性能优化终极解决方案
DLSS Swapper:免费开源的游戏性能优化终极解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的免费开源工具,它能够智能管理、下载和替换游戏中的DL…...

如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南
如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾为制作歌词时间轴而烦恼&#x…...

实战指南:AI调用成本降71%——利用“推理路由”告别大模型胡乱开销
大多数 AI 应用在刚开始时,都会在代码中硬编码一个模型。对于原型开发来说,这运行得很好,但一旦单个端点需要处理多个复杂的任务类别,这种模式就会分崩崩离析。分类、紧急程度评分、面向客户的草稿以及长篇总结,这些任…...
深度解析:如何让你的飞控代码轻松跑在不同芯片上?)
ArduPilot硬件抽象层(HAL)深度解析:如何让你的飞控代码轻松跑在不同芯片上?
ArduPilot硬件抽象层(HAL)深度解析:跨平台飞控开发实战指南 当开发者尝试将ArduPilot移植到一块全新的飞控板时,最常遇到的挑战莫过于如何让同一套控制算法在不同硬件架构上无缝运行。这正是硬件抽象层(HAL)设计的精妙之处——它如同一位技艺高超的翻译官…...

Lusca CSP策略完全指南:构建安全的内容安全策略
Lusca CSP策略完全指南:构建安全的内容安全策略 【免费下载链接】lusca Application security for express apps. 项目地址: https://gitcode.com/gh_mirrors/lu/lusca Lusca是一款专为Express应用打造的安全中间件,提供了全面的内容安全策略&…...