C++ STL 标准模板库
C++ STL 标准模板库
标准容器
顺序容器
vector
vector 向量容器
底层数据结构:动态开辟的数组,每次以原来空间大小的2倍进行扩容。采用allocator进行空间开辟和释放,对象创建和析构的分离。具体如C++模板学习笔记中简要实现C++中的vector。
增加:push_back、insert。
删除:pop_back、erase。
查询:operator[]、iterator、find、for-each。注意连续insert和erase中出现的迭代器失效问题。
其他:size、empty、reserve(预留空间)、resize(扩容)、swap(两个容器进行元素替换)。
reserve函数是给容器预留空间,并不会进行容器填充,容器的空间元素大小size为原来的大小。
resize函数是给容器开辟指定大小的内存空间,会对容器中的值进行添加,如果容器内部的元素是int,那么默认添加的元素为0,容器的空间元素大小size为扩容后的大小。
deque
deque 双端队列机制
#define MAP_SIZE=2; #define QUE_SIZE=4096/sizeof(T);
底层数据结构是一个动态开辟的二维数组(类似于邻接表),一维数组从2开始,以2倍的方式进行扩容,每次扩容后,原来的第二维数组,从第一维数组的下标oldsize/2开始存放,上下行都预留相同的空行,方便deque首尾元素的添加。
增加:push_back、push_front、insert
删除:pop_back、pop_front、erase
查询:iterator(连续erase和insert考虑容器失效问题)
deque底层内存是不是连续的?并不是,deque的底层是动态开辟的二维数组,第二维上是连续的,第一维上是不连续的。
list
list 链表容器
底层数据结构是双向循环链表 pre-data-next
增加:push_back、push_front、insert
删除:pop_back、pop_front、erase
查询:iterator(连续erase和insert考虑容器失效问题)
vector和deque的区别
可以从以下角度进行分析:
- 底层数据结构。vector是连续的动态数组;deque是第二维连续的动态二维数组。
- 前中后插入的时间复杂度。vector前中后插入的时间分别是O(n)/O(n)/O(1),deque前中后插入的时间复杂度分别是O(1)/O(n)/O(1)。
- 对内存的使用效率。vector必须是连续的空间,而deque只需要第二维上是连续的就行。
- 中间进行insert或者erase,vector效率稍微高一点,因为vector底层内存是连续的,deque因为空间是不连续的,会涉及内存转化等情况。
vector和list的区别
可以从以下角度进行分析:
- 底层数据结构。vector是连续的数组;list的双向循环链表。
- 查找和增加、删除的时间复杂度。vector的增加和删除O(n),查询O(n),随机访问O(1);链表的增加和删除O(1)(可能需要涉及搜索时间,具体情况具体分析),查询O(n),随机访问O(n)。
容器适配器
适配器的基本概念:
1、适配器底层没有自己的数据结构,它是另外一个容器的封装,它的方法全部由底层依赖的容器进行实现。
2、没有实现自己的迭代器。
自定义实现的stack容器:
#include<iostream>
#include<deque>
using namespace std;template<typename T,typename Container=deque<T>>
class Stack
{
public:void push(T &val) { con.push_back(val); }void pop() { con.pop_back(); }T top() const { return con.back(); }private:Container con;
};
容器适配器主要有stack、queue、priority_queue。
stack
主要方法有:push、pop、top、empty、size等
主要特点:先进后出
采用deque实现
queue
主要方法有:push、pop、front、back、empty、size等
主要特点:先进先出
采用deque实现
priority_queue
主要方法和stack的方法一致:push、pop、top、empty、size等
主要特点:和queue的不同在于,优先级高的先出队,并不是先进先出。
采用vector实现
为什么stack和queue都采用deque实现?
- vector初始内存效率很低,默认是0-1-2-4-8- ···-2^n,而deque一开始就是4096/sizeof(T)。
- queue需要支持头尾插入,所以采用deque效率高。
- vector需要大量的连续的内存空间,而deque只需要分段的内存,当存在大量数据时,deque效率会高一点。
为什么priority_queue采用vector实现?
- priority_queue的是一种大根堆的结构,一般情况下都是在一段连续的空间或者内存上进行保存。而deque在一维上不是连续的,所以就会导致很难存储大根堆树。
关联容器
常用方法:insert(val)、iterator、erase(iterator)、erase(key)。还有find的方法,查找对应的元素。
无序关联容器
哈希链式表,增删查的时间复杂度为O(1),也需要注意迭代器失效的问题。set是无序的。
unordered_set
不会存储key值重复的元素
unordered_multiset
会存储key值重复的元素
unordered_set<int> set1;
for (int i = 0; i < 20;++i)
{set1.insert(rand() % 100 + 1);
}
cout << "size:" << set1.size() << endl;
cout << "count 15:" << set1.count(15) << endl;for (int i = 0; i < 50;i++)
{set1.insert(i);
}
auto it1 = set1.begin();
for (; it1 != set1.end();++it1)
{cout << *it1 << " ";
}
cout << endl;
unorder_map
不允许key重复,如果插入过程中会出现key重复情况,那么就会对原来key对应的value的进行替换。
unorder_multimap
允许key可以重复。
map的operator[]重载函数存在一个情况,在查询时key存在的情况下返回value,不存在的情况下会自动创建一个key和value(默认为空)。
有序关联容器
红黑树,增删查时间复杂度为O(log2n),采用树进行存储
set
multiset
map
multimap
迭代器
迭代器iterator,一般容器内部都包含了iterator。
iterator:普通正向迭代器。一般是begin()/end()。
const_iterator:常量正向迭代器,返回值只能使用,不能修改。operator*操作符重载返回的是常量 const T& operator*。
reverse_iterator:反向迭代器。和前面两个迭代器不同的是,一般是rbegin()/rend()。
const_reverse_iterator:常量反向迭代器。
#include<iostream>
#include<vector>
using namespace std;int main()
{vector<int> v = {2, 3, 4, 6, 9, 8, 4, 2, 4, 5};auto it = v.begin();for (; it != v.end();++it){cout << *it << " ";// *it = 10;//普通正向迭代器可以修改其值}cout << endl;vector<int>::const_iterator c_it = v.begin();for (; c_it != v.end(); ++c_it){cout << *c_it << " ";// *c_it = 10;//常量正向迭代器无法修改其值}cout << endl;vector<int>::reverse_iterator r_it = v.rbegin();//获取最后一个元素的迭代器for (; r_it != v.rend();++r_it){cout << *r_it << " ";// *r_it = 10;//可以修改其值}cout << endl;vector<int>::const_reverse_iterator cr_it = v.rbegin();for (; cr_it != v.rend();++cr_it){cout << *cr_it << " ";}cout << endl;return 0;
}
函数对象
通过函数指针调用函数,是没有办法内联的,效率很低,因为有函数调用的开销
C++的函数对象,实现了operator()操作符重载
通过函数对象调用operator(),可以省略函数调用的开销,比通过函数指针调用函数(不能用内敛调用),效率更高。
函数对象是用类生成的,所以可以添加许多相关的成员变量,用来记录函数对象调用使用的更多信息。
函数调用类似于C语言的函数指针。
using关键字,对函数更改名字,类似于as方法。
#include<iostream>
using namespace std;template <typename T>
class greater2
{public:bool operator()(T&x,T&y)//二元函数对象{return x > y;}
};
template<typename T>
bool greater1(T&x,T&y)
{return x > y;
}
template<typename T,typename Compare>
bool compare(T x,T y,Compare comp)
{//Compare其实就是调用的对象或者函数实现内部功能return comp(x, y);
}
int main()
{//函数调用实现comparecout << compare<int>(10, 20, greater1<int>) << endl;//对象调用实现comparecout << compare<char>('a', 'c', greater2<char>()) << endl;return 0;
}
泛型算法
C++泛型算法都放在#include<algorithm>头文件内部。常见的泛型算法有sort、find、find_if、count、for_each、binary_search等
泛型算法的特点:
- 泛型算法的参数接收的都是迭代器。
- 泛型算法的参数还可以接收函数对象(C语言函数指针)。
int arr[] = {10, 20, 30, 34, 21, 12, 35, 32, 11, 22};
vector<int> vec(arr, arr + sizeof(arr) / sizeof(arr[0]));for(auto i:vec)
{cout << i << " ";
}
cout << endl;sort(vec.begin(), vec.end());for (auto i : vec)
{cout << i << " ";
}
cout << endl;if(binary_search(vec.begin(), vec.end(), 22))
{cout << "22 is existed" << endl;
}
else
{cout << "22 isn't existed" << endl;
}//传入函数对象greater,改变容器的排序方式的比较方式
sort(vec.begin(), vec.end(), greater<int>());
for (auto i : vec)
{cout << i << " ";
}
cout << endl;
绑定器 + 二元函数对象 -> 一元函数对象
绑定器存在C++的#include<functional>头文件中。
bind1st:把二元函数对象的operator()的第一个形参进行绑定起来。
bind2nd:把二元函数对象的operator()的第二个形参进行绑定起来。
//find_if是查找一个元素,需要一个一元函数对象
//查找第一个小于31的元素,并将其插入到其前面,greate a>b a=31
auto it2 = find_if(vec.begin(), vec.end(), bind1st(greater<int>(),31));
vec.insert(it2, 31);for (auto i : vec)
{cout << i << " ";
}
cout << endl;//在第一个小于19的前面插入19 a<b b=19
auto it3 = find_if(vec.begin(), vec.end(), bind2nd(less<int>(), 19));
vec.insert(it3, 19);for (auto i : vec)
{cout << i << " ";
}
cout << endl;
lambda表达式,类似于函数对象[](形参列表)->函数返回值{函数体}。
相关文章:

C++ STL 标准模板库
C STL 标准模板库 标准容器 顺序容器 vector vector 向量容器 底层数据结构:动态开辟的数组,每次以原来空间大小的2倍进行扩容。采用allocator进行空间开辟和释放,对象创建和析构的分离。具体如C模板学习笔记中简要实现C中的vector。 增…...
C#-集合小例子
目录 背景: 过程: 1.添加1-100数: 2.求和: 3.平均值: 4.代码: 总结: 背景: 往集合里面添加100个数,首先得有ArrayList导入命名空间,这个例子分为3步,1.添加1-100个数2.进行1-100之间的总和3.求总和的平均值&…...

git保存删除的文件
查看pg源码的函数具体内容: https://doxygen.postgresql.org/resowner_8h.html#a7f01c9e9f97849f2859feabd913de1f8 git add 添加了多余文件 git add . 表示当前目录所有文件,不小心就会提交其他文件 git add 如果添加了错误的文件的话 撤销操作 g…...
(下))
【golang】go语句执行规则(goroutine)(下)
怎样才能让主goroutine等待其他goroutine? 上篇文章提到,一旦主 goroutine 中的代码执行完毕,当前的 Go 程序就会结束运行,无论其他的 goroutine 是否已经在运行了。那么,怎样才能做到等其他的 goroutine 运行完毕之后…...

websocket 接收消息无法获取用户id
1.遇到问题 公司项目是基于ruoyi 框架快速搭建开发,使用多线程搜索查询,所以以用户区分任务,保证可以搜索任务和取消搜索,所以我这需要获得用户id,使用 SecurityUtils 共工工具类从请求头获取token,然后解…...

springboot通过sharding-dbc按年、月分片
目录 springboot通过sharding-dbc按年、月分片 1、引入pom依赖 2、application.yml配置 3、分片算法 4、注意事项 1、引入pom依赖 <!--shardingjdbc分片,和Druid不兼容,如果不使用sharding则需要注释--><dependency><groupId>org.…...

基于静电放电算法优化的BP神经网络(预测应用) - 附代码
基于静电放电算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于静电放电算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.静电放电优化BP神经网络2.1 BP神经网络参数设置2.2 静电放电算法应用 4.测试结果:5…...
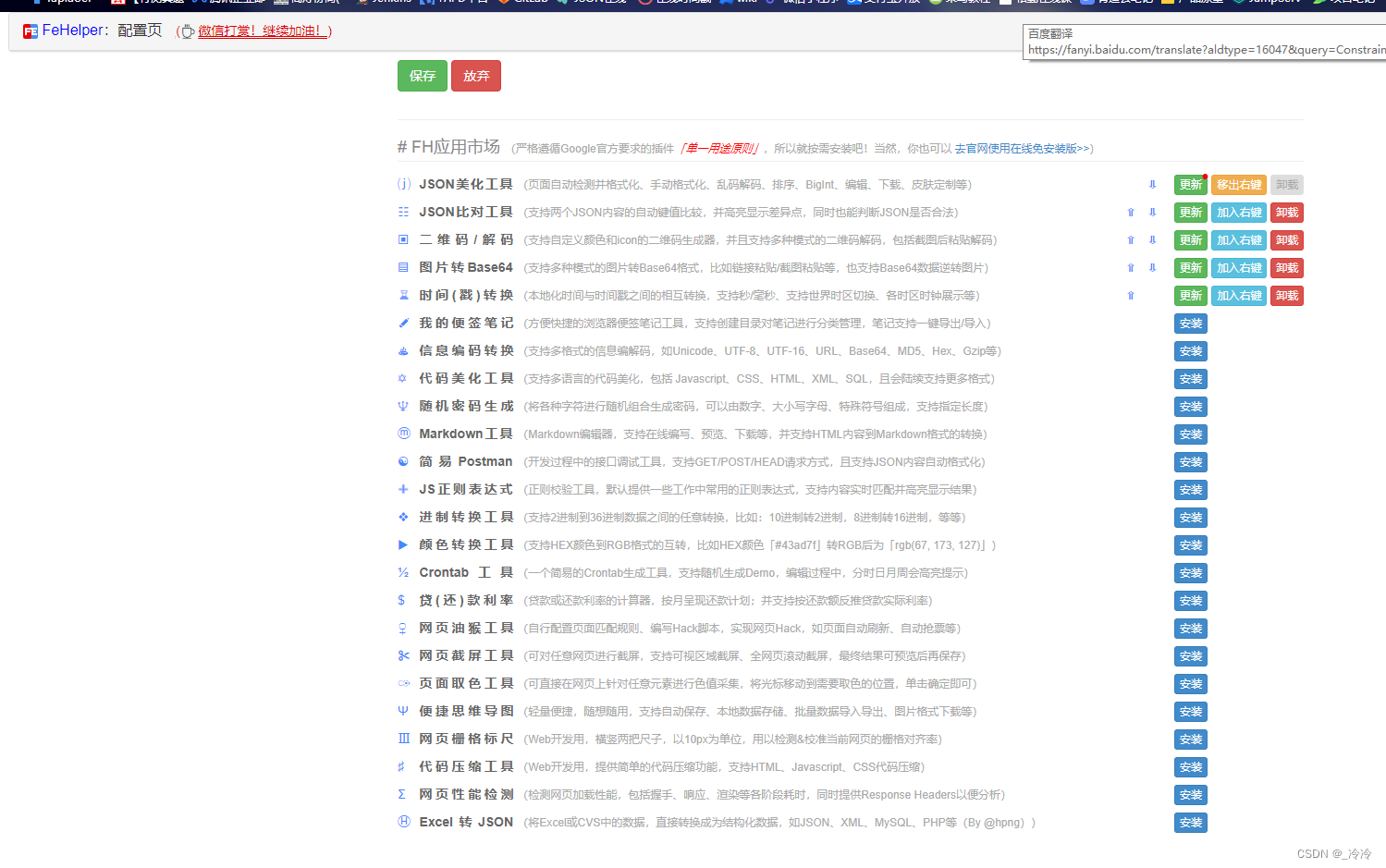
开发者插件推荐FeHelper
开发者巨好用的插件、有很多功能比如json美化、对比,二维码/解码,图片转Base64,时间戳转换等 一、下载插件 1、打开网址:FeHelper - Awesome(建议用谷歌打开); 2、选择要下载的版本,…...

【MySQL】JSON 格式字段处理
MySQL 5.7 版本后已支持 JSON 格式,这虽是 MySQL 的一小步,但可以说是程序开发的一大步,再也不用将 JSON 内容塞到 VARCHAR 类型字段了,程序设计也会变得更加灵活。网上大多只针对JSONObject 对象类型,本文也将详解 JS…...

数据库选型<1>
数据库选型 1.SQL与NoSQL1.SQL2.NoSQL 2.各种数据存储的适应场景1.MySQL 3.构建MySQL开发环境 1.SQL与NoSQL 1.SQL 关系型数据库 MySQLOracleSQL serverPostGreSQL 关系型数据库的特点 数据结构化存储在二维表中(新增JSON存储方式,也有nosql的特点)支持事务的原子…...
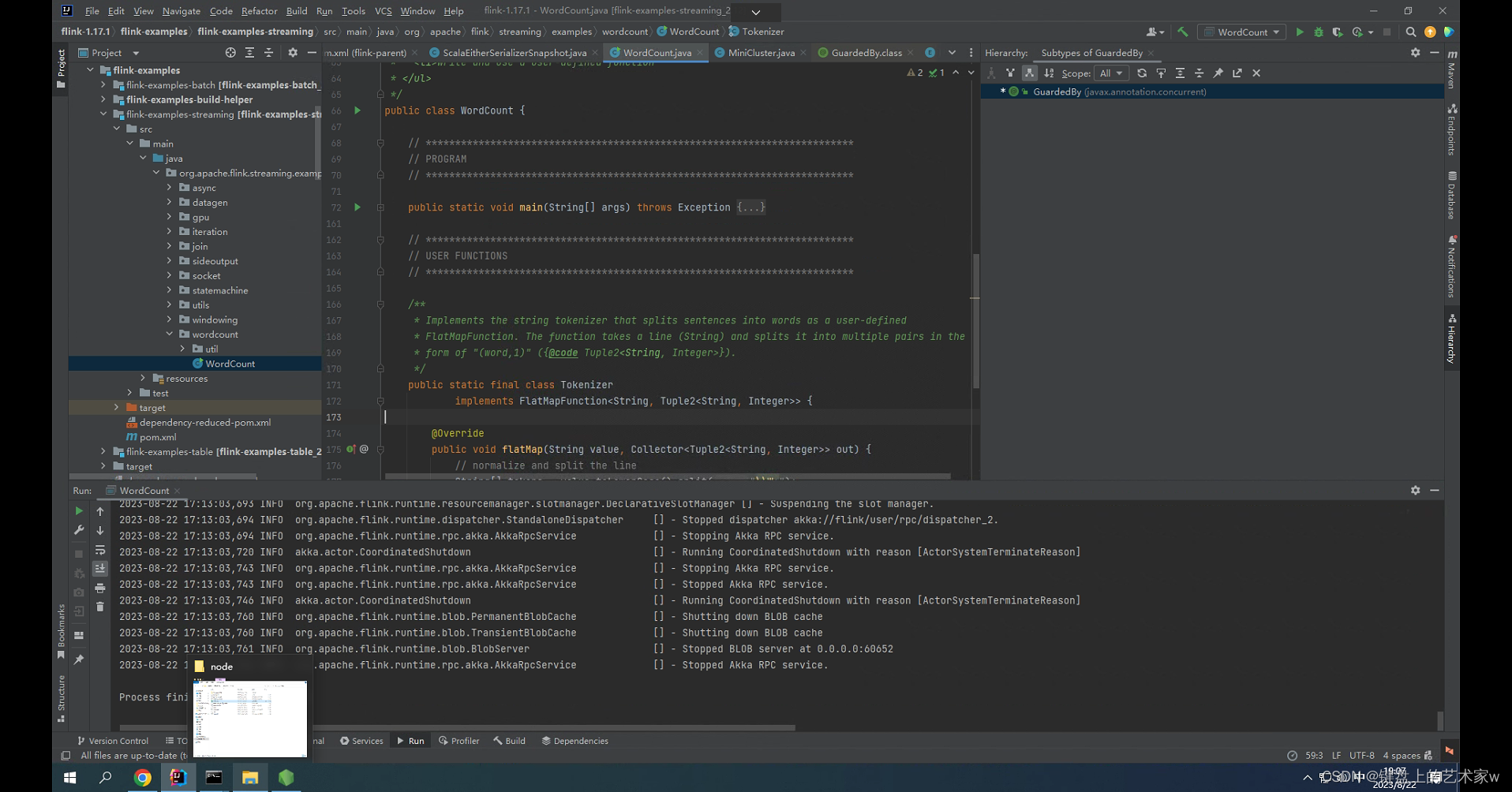
1.Flink源码编译
目录 1.环境版本 1.1 jdk 1.2.maven 1.3.node 1.4.scala 2.下载flink源码 3.编译源码 4.idea打开flink源码 5.运行wordcount 1.环境版本 软件地址 链接:https://pan.baidu.com/s/1ZxYydR8rBfpLCcIdaOzxVg 提取码:12xq 1.1 jdk 1.2 maven 1.…...
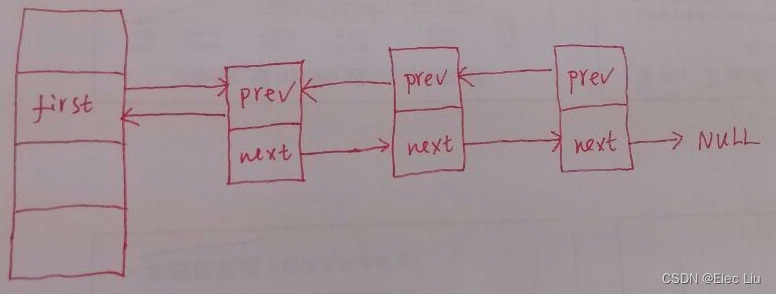
Linux内核数据结构 散列表
1、散列表数据结构 在Linux内核中,散列表(哈希表)使用非常广泛。本文将对其数据结构和核心函数进行分析。和散列表相关的数据结构有两个:hlist_head 和 hlist_node //hash桶的头结点 struct hlist_head {struct hlist_node *first…...
数据库系统课设——基于python+pyqt5+mysql的酒店管理系统(可直接运行)--GUI编程
几个月之前写的一个项目,通过这个项目,你能学到关于数据库的触发器知识,python的基本语法,python一些第三方库的使用,包括python如何将前后端连接起来(界面和数据),还有界面的设计等…...

《C和指针》笔记9: typedef
C语言支持一种叫作typedef的机制,它允许你为各种数据类型定义新名字。typedef声明的写法和普通的声明基本相同,只是把typedef这个关键字出现在声明的前面。例如,下面这个声明: char *ptr_to_char;把变量ptr_to_char声明为一个指向…...

《C和指针》笔记6:gets/puts/scanf/printf/getchar函数用法
本博客可以了解一些gets/puts/scanf/printf/getchar函数的基本用法。 文章目录 1. gets函数2. puts函数3. scanf函数4. printf函数5. getchar函数6. putchar函数 1. gets函数 gets函数从标准输入读取一行文本并把它存储于作为参数传递给它的数组中。一行输入由一串字符组成&a…...

智慧课堂学生行为检测评估算法
智慧课堂学生行为检测评估算法通过yolov5系列图像识别和行为分析,智慧课堂学生行为检测评估算法评估学生的表情、是否交头接耳行为、课堂参与度以及互动质量,并提供相应的反馈和建议。智慧课堂学生行为检测评估算法能够实时监测学生的上课行为࿰…...
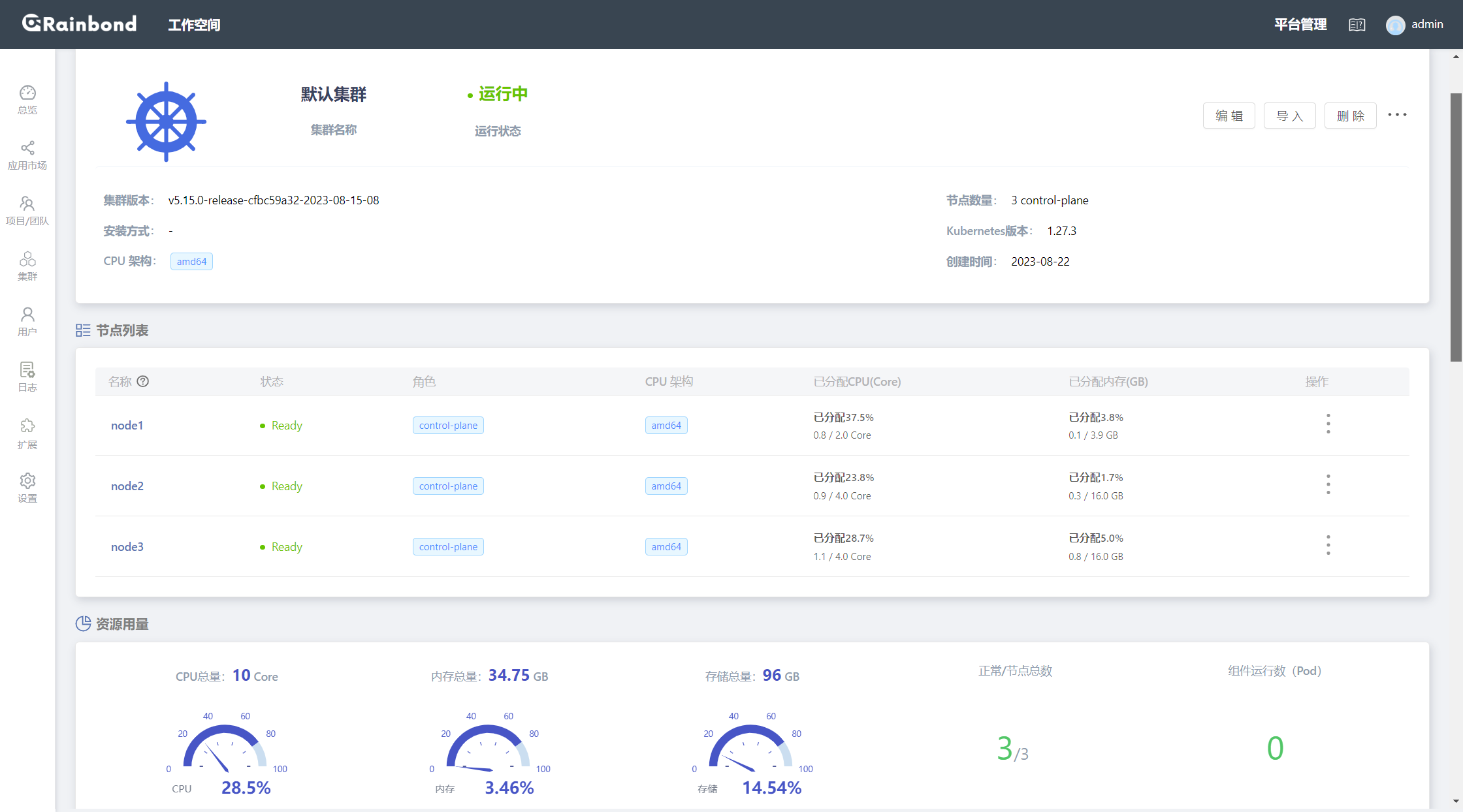
rainbond云原生应用管理平台部署
rainbond简介 rainbond 是 一个 开源的Kubernetes 云原生应用管理平台。 Rainbond 核心100%开源,Serverless体验,不需要懂K8s也能轻松管理容器化应用,平滑无缝过渡到K8s,是国内首个支持国产化信创、适合私有部署的一体化应用管理…...
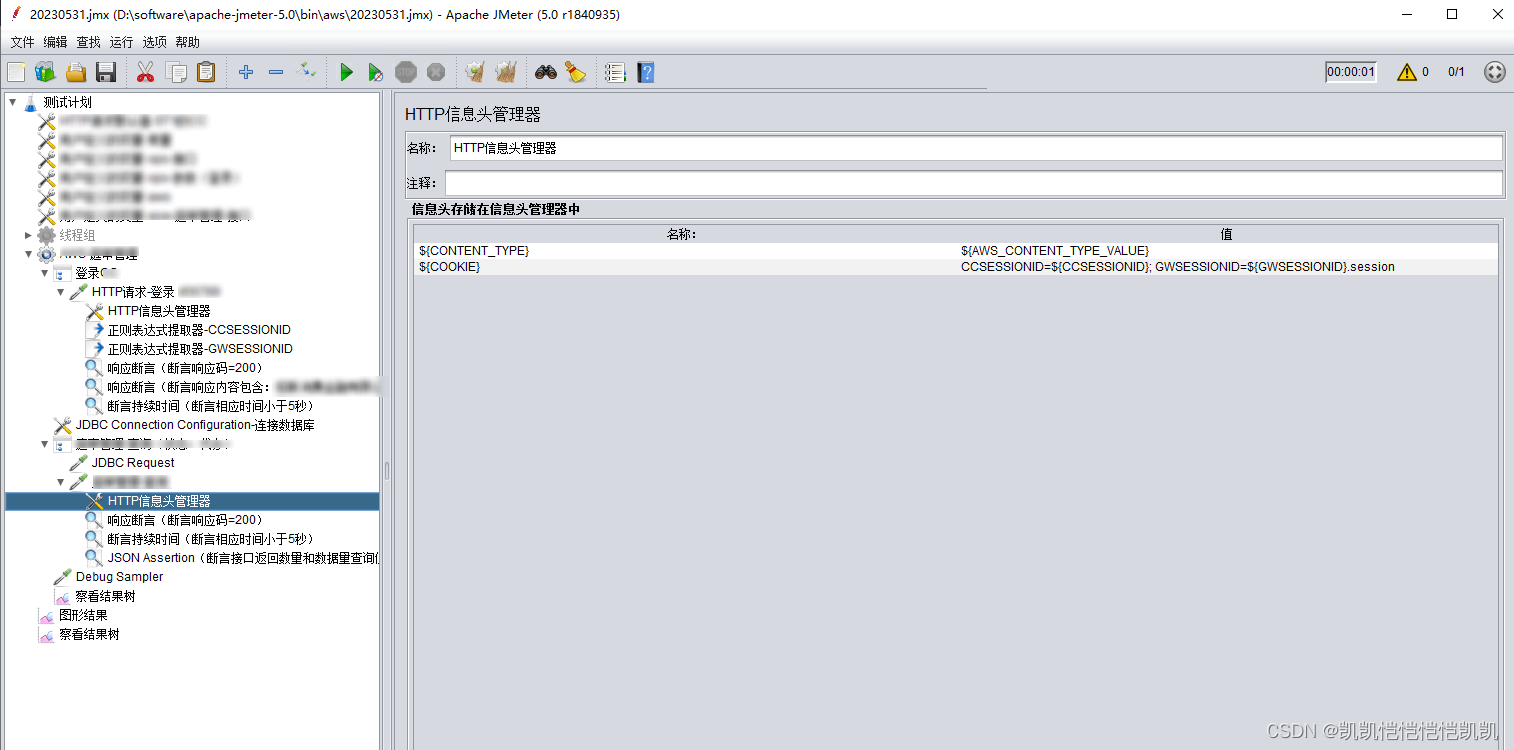
jemter连接数据json断言
文章目录 一、jmeter连接数据库1、加载JDBC驱动2、连接数据3、SQL Query的Query Type使用方法:4、Variable Name使用方法:5、Result variable name使用方法: 二、Json响应断言1、添加 》 断言 》 JSON断言2、JSON断言界面参数说明:…...
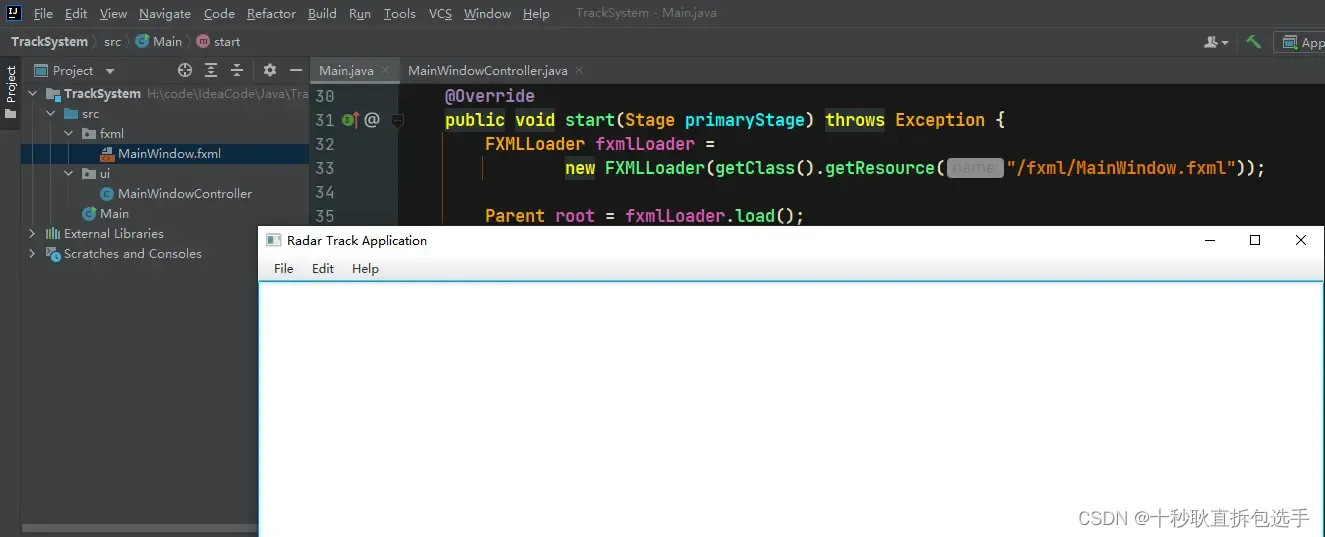
JavaFX 加载 fxml 文件
JavaFX 加载 fxml 文件主要有两种方式,第一种方式通过 FXMLLoader 类直接加载 fxml 文件,简单直接,但是有些控件目前还不知道该如何获取,所以只能显示,目前无法处理。第二种方式较为复杂,但是可以使用与 fx…...
Redis——Set)
(三)Redis——Set
SADD key value SMEMBERS 127.0.0.1:6379> SADD set aaa 1 127.0.0.1:6379> SMEMBERS set aaa 127.0.0.1:6379> SADD set aaa 0 127.0.0.1:6379> SMEMBERS set aaaSISMEMBER 判断 aaa 是否在 set 中 127.0.0.1:6379> SISMEMBER set aaa 1 127.0.0.1:6379>…...
)
告别串口助手:用STM32CubeIDE和HAL库,手把手教你打造自己的IAP上位机(附源码)
从零构建STM32 IAP上位机:C#实战与协议解析全指南 在嵌入式开发中,IAP(In Application Programming)技术为设备固件升级提供了极大便利,但一个稳定可靠的上位机软件往往是整个流程中最薄弱的环节。市面上通用的串口助手…...

Vim多光标编辑插件vim-visual-multi:提升批量文本处理效率
1. 项目概述:一个能改变你Vim多光标编辑体验的插件 如果你是一个Vim或Neovim的深度用户,并且对现代编辑器(比如VSCode、Sublime Text)里那种流畅的多光标编辑功能念念不忘,那么你肯定不止一次地搜索过“Vim multiple c…...

告别WSL安装玄学:从0x80072f78到0x800701bc,一次搞懂Windows 11下的完整避坑指南
从0x80072f78到0x800701bc:Windows 11下WSL完整避坑手册 每次在Windows 11上安装WSL时,那些神秘的错误代码是否让你抓狂?0x80072f78、0x800701bc...它们像是一道道密码,阻挡着你进入Linux开发环境的大门。作为长期在Windows和Linu…...

Obsidian+Cursor构建AI增强型项目规划与开发一体化工作流
1. 项目概述:构建你的数字项目规划中枢如果你和我一样,同时管理着好几个数字项目——可能是一个新的SaaS产品、一个开源工具,或者一个复杂的个人自动化脚本——你肯定体会过那种信息散落各处的痛苦。产品需求文档在Notion里,技术架…...

Power Automate调用Azure Foundry智能体
Power Automate调用Azure Foundry智能体一、创建Foundry智能体二、发送HTTP请求,调用Foundry智能体三、拓展一、创建Foundry智能体 先从创建开始吧 填好,然后直接审阅并创建就行了。一个资源下可以创建多个项目 转到资源 转到门户 这里有API密钥&…...

【Google全家桶AI功能2026终极前瞻】:20位谷歌AI Lab核心工程师闭门透露的7大颠覆性升级路径
更多请点击: https://intelliparadigm.com 第一章:Google全家桶AI功能2026升级全景图谱 2026年,Google正式将Gemini 3.5 Ultra深度集成至全系生产力产品中,实现跨端、实时、上下文感知的AI协同。核心升级聚焦于“意图理解前置化”…...

GitHub Explorer:基于OpenClaw的AI Agent自动化项目分析工具
1. 项目概述:一个为AI Agent打造的GitHub项目深度分析工具 如果你和我一样,经常需要快速评估一个GitHub项目的价值、技术栈、社区活跃度以及它在整个生态中的位置,那你一定知道这个过程有多繁琐。你得手动点开仓库,看README&…...

MCP协议与n8n集成:构建标准化AI自动化工作流
1. 项目概述:当MCP遇见n8n,一个自动化新范式的诞生最近在折腾自动化工作流,特别是想把不同AI模型的能力串联起来,发现了一个挺有意思的项目:brunopelatieri/mcp-n8n-bruia。这名字乍一看有点复杂,拆开来看&…...

【Claude JavaScript开发支持终极指南】:20年前端架构师亲测的5大生产力跃迁技巧
更多请点击: https://intelliparadigm.com 第一章:Claude JavaScript开发支持的演进与定位 Claude 系列模型自发布以来,持续增强对前端及全栈开发场景的理解能力,其中 JavaScript 作为核心支持语言之一,其支持深度随版…...
)
Perplexity Nature检索实战手册:9类典型查询失败场景+对应Prompt工程模板(含IEEE/ACS/Nature交叉验证结果)
更多请点击: https://intelliparadigm.com 第一章:Perplexity Nature文章检索实战手册导论 Perplexity Nature 是面向科研人员与技术从业者设计的智能学术检索增强工具,它融合了语义理解、引用图谱分析与跨源文献聚合能力,专为高…...