Java 中使用 ES 高级客户端库 RestHighLevelClient 清理百万级规模历史数据
🎉工作中遇到这样一个需求场景:由于ES数据库中历史数据过多,占用太多的磁盘空间,需要定期地进行清理,在一定程度上可以释放磁盘空间,减轻磁盘空间压力。
🎈在经过调研之后发现,某服务项目每周产生的数据量已经达到千万级别,单日将近能产生两百万的数据量写入到 ES 数据库中,平均每个小时最少产生 10w+ 条数据,加上之前的历史数据,目前生产环境 ES 数据量已经达到两亿一千四百八十万的数据。并且随着当前业务量的爆发式增长,数据增长量急剧飙升,在未来一年内每周产生的数据量有望达到 3kw-5kw 左右。
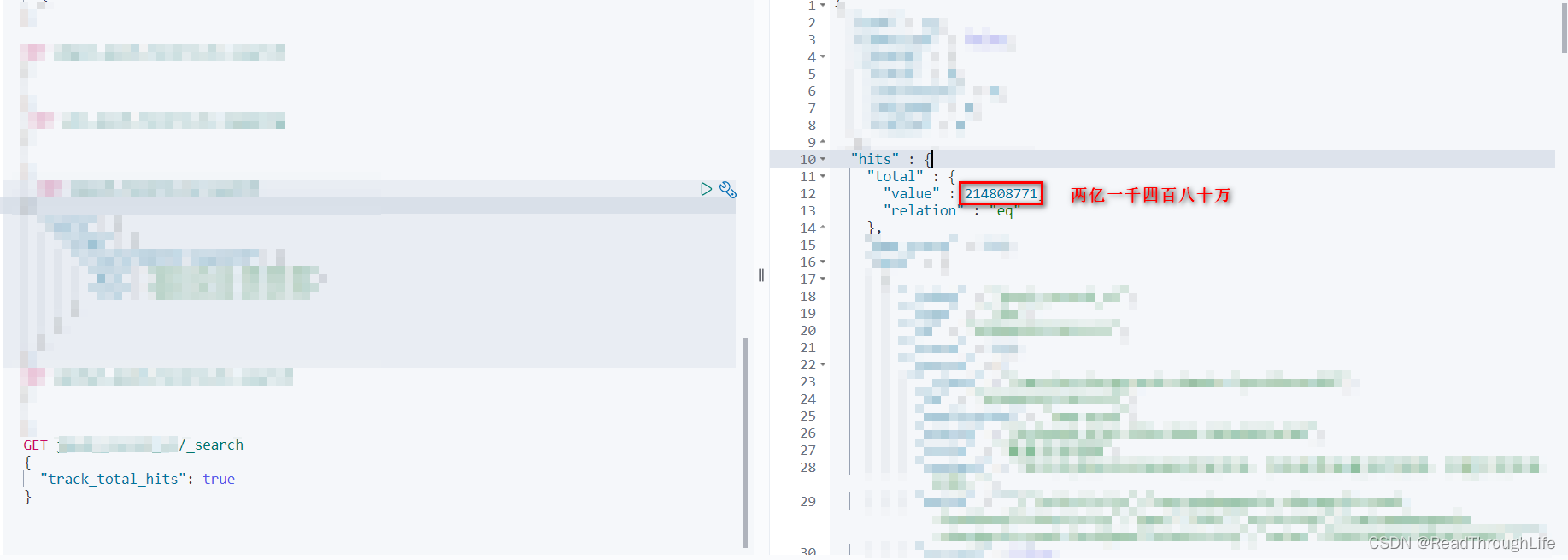
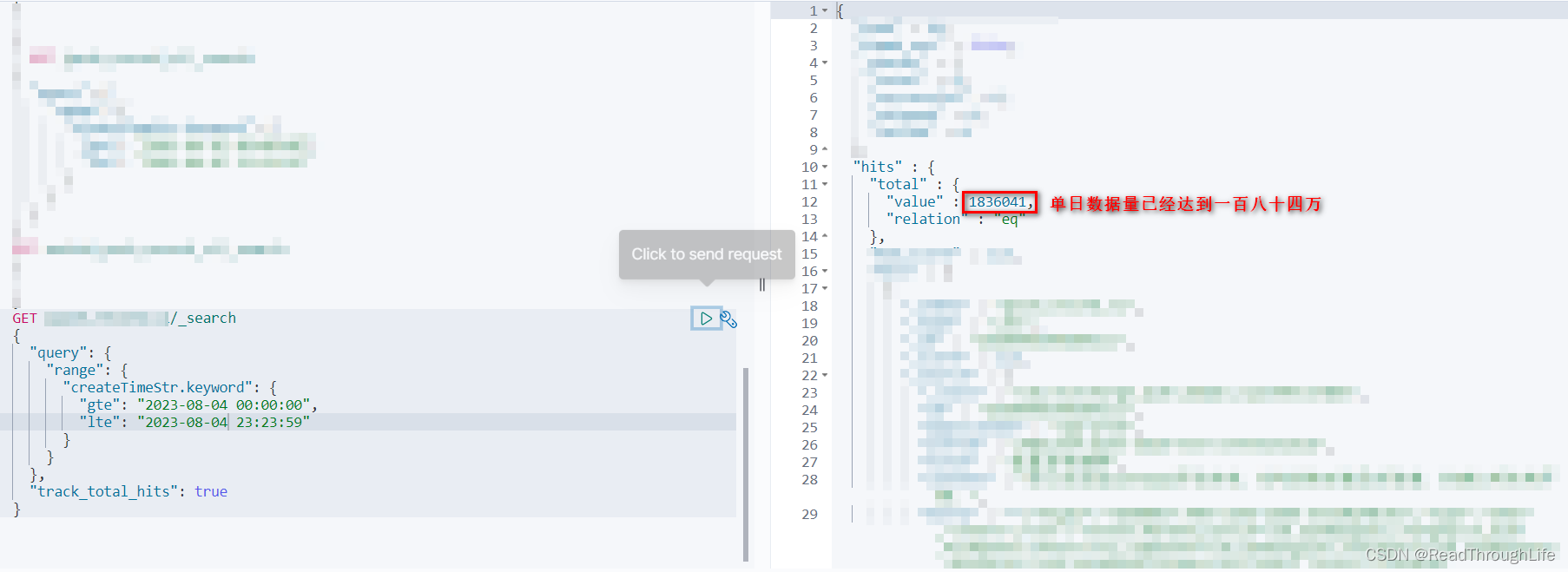

💡因此,对 ES 数据库中历史数据进行清理势在必行,为了能够释放磁盘空间,并且还要保证业务方能够进行日常问题的排查定位,决定从两个月前的数据开始清理,方案如下:
- 编写定时任务,每天凌晨三点清理两个月前的那一天数据,之所以选择凌晨三点是因为在 Grafana 查看了生产环境的集群监控情况,凌晨两点至四点之间的集群、索引的查询以及写入 QPS 都比较低。
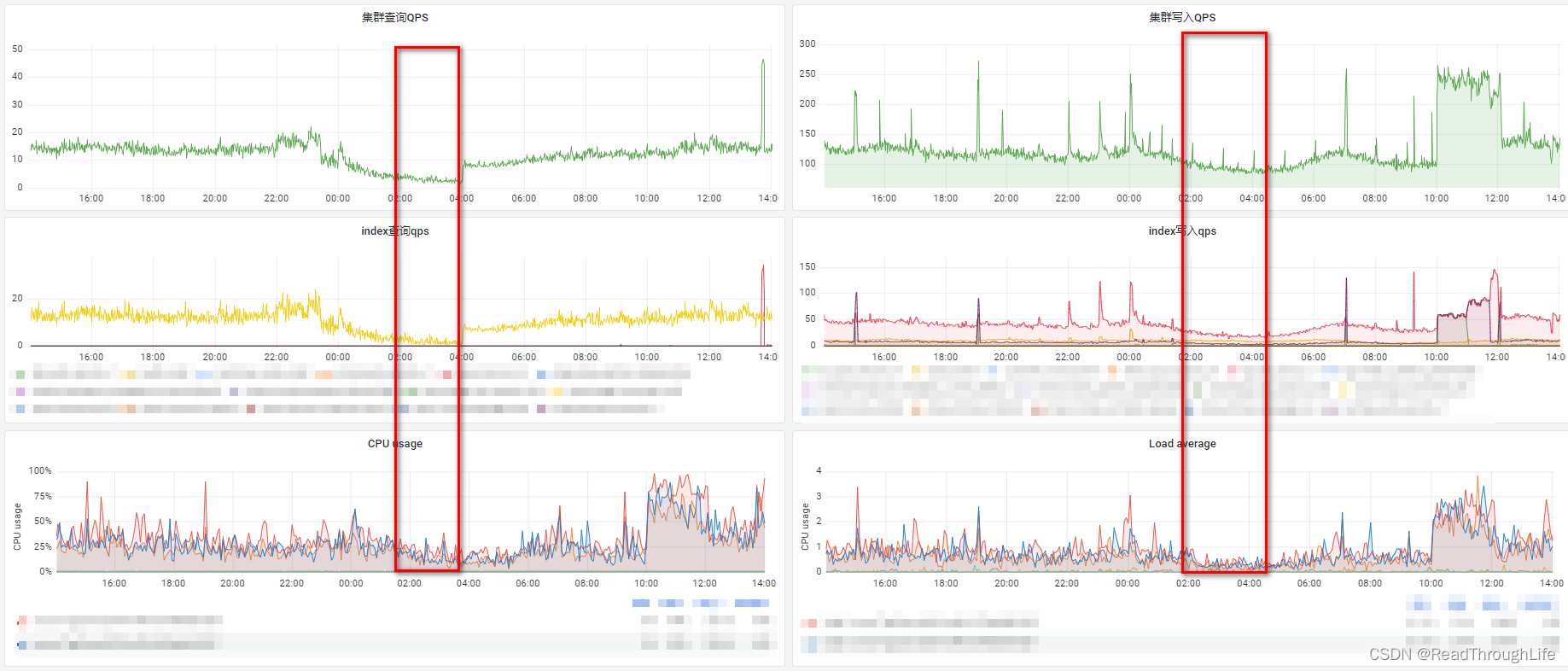
- 清理一天的数据时,根据时间段进行清理,每个小时清理一次,避免内存中存放太多的数据,导致内存溢出。
- 清理 ES 数据时,需要先查询出数据,而 ES 默认最多只能查询 1w 条数据,如果当次需要删除的数据量超过 1w 条,普通的查询操作无法完全删除数据。因此,需要采用滚动查询的方式,滚动查询结果保持时间需要设置合理,不能太长,否则也可能会导致内存溢出。
根据以上的思路方案,设计的定时清理ES历史数据代码如下:
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.DateUtils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.search.ClearScrollRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.core.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Date;
/**
-
清理ES历史数据定时任务
*/
@Component
public class CleanESHistoryDataTask {private static final Logger LOGGER = LoggerFactory.getLogger(CleanESHistoryDataTask.class);
@Resource
private RestHighLevelClient restHighLevelClient;/**
- 根据索引名称删除当前日期两个月前的那一天的历史文档数据
- @param jobContext
*/
@Scheduled
public void cleanESHistoryData(JobContext jobContext) {
// jobContext为定时任务中回传数据
String indexName = jobContext.getData();
if (StringUtils.isBlank(indexName)) {
LOGGER.warn(“ES索引名称不能为空!”);
return;
}
long startTimeMillis = System.currentTimeMillis();
String twoMonthsAgoDate = DateTool.format(DateUtils.addMonths(new Date(), -1), DateTool.DF_DAY);
try {
String startTimeStr = twoMonthsAgoDate + " 00:00:00";
// 初始化时间,形如2023-08-06 00:00:00
Date initialStartTime = DateTool.parse(startTimeStr, DF_FULL);
// 每次循环清理一个小时历史文档数据,循环24次清理完一天的历史文档数据
for (int i = 0; i < 24; i++) {
Date startTime = initialStartTime;
startTime = DateUtils.addHours(startTime, i);
Date endTime = DateUtils.addHours(startTime, 1);
LOGGER.info(“正在清理索引:[{}],时间:{} 至 {}的历史文档数据…”, indexName, DateTool.format(startTime, DF_FULL), DateTool.format(endTime, DF_FULL));
long currentStartTimeMillis = System.currentTimeMillis();
// 指定操作的索引库
SearchRequest searchRequest = new SearchRequest(indexName);
// 构造查询条件,指定查询的时间范围,每次最多写入1000条数据至内存,减轻服务器内存压力
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.rangeQuery(“createTimeStr.keyword”)
.from(DateTool.format(startTime, DF_FULL))
.to(DateTool.format(endTime, DF_FULL)))
.size(1000);
// 设置滚动查询结果在内存中的过期时间为1min
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
// 将滚动以及构造的查询条件放入查询请求
searchRequest.scroll(scroll).source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 记录要滚动的ID
String scrollId = searchResponse.getScrollId();
SearchHit[] hits = searchResponse.getHits().getHits();
while (hits != null && hits.length > 0) {
// 创建批量处理请求对象
BulkRequest bulkRequest = new BulkRequest();
for (SearchHit hit : hits) {
DeleteRequest deleteRequest = new DeleteRequest(indexName, hit.getId());
bulkRequest.add(deleteRequest);
}
// 执行批量删除请求操作
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
// 构造滚动查询条件,继续滚动查询
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId();
hits = searchResponse.getHits().getHits();
}
// 当前滚动查询结束,清除滚动,释放服务器内存资源
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
LOGGER.info(“清理索引:[{}],时间:{} 至 {}的历史文档数据成功,耗时{}ms”, indexName, DateTool.format(startTime, DF_FULL), DateTool.format(endTime, DF_FULL), (System.currentTimeMillis() - currentStartTimeMillis));
}
LOGGER.info(“[cleanESHistoryData] 定时任务-清理索引:[{}],时间:{}的历史文档数据成功,耗时{}ms”, indexName, twoMonthsAgoDate, (System.currentTimeMillis() - startTimeMillis));
} catch (Exception e) {
LOGGER.error(String.format(“[cleanESHistoryData] 定时任务-清理索引:[{}],时间:{}的历史文档数据失败,耗时{}ms”, indexName, twoMonthsAgoDate, (System.currentTimeMillis() - startTimeMillis)), e);
}
}
}
其中,需要注意以下几点:
- 在 Java 中对 ES 进行操作,这里使用的是 ES 的高级客户端组件
RestHighLevelClient。 @Scheduled注解为自研定时任务工具注解,外界无法使用,在使用定时任务时需要自己选择合适的定时任务框架。DateTool工具类为自研工具类,外界同样无法使用,在以上代码段中就是用于对java.util.Date类型进行转换为字符串,DF_FULL和DateTool.DF_DAY均是常量,它们的值分别为yyyy-MM-dd HH:mm:ss和yyyy-MM-dd。
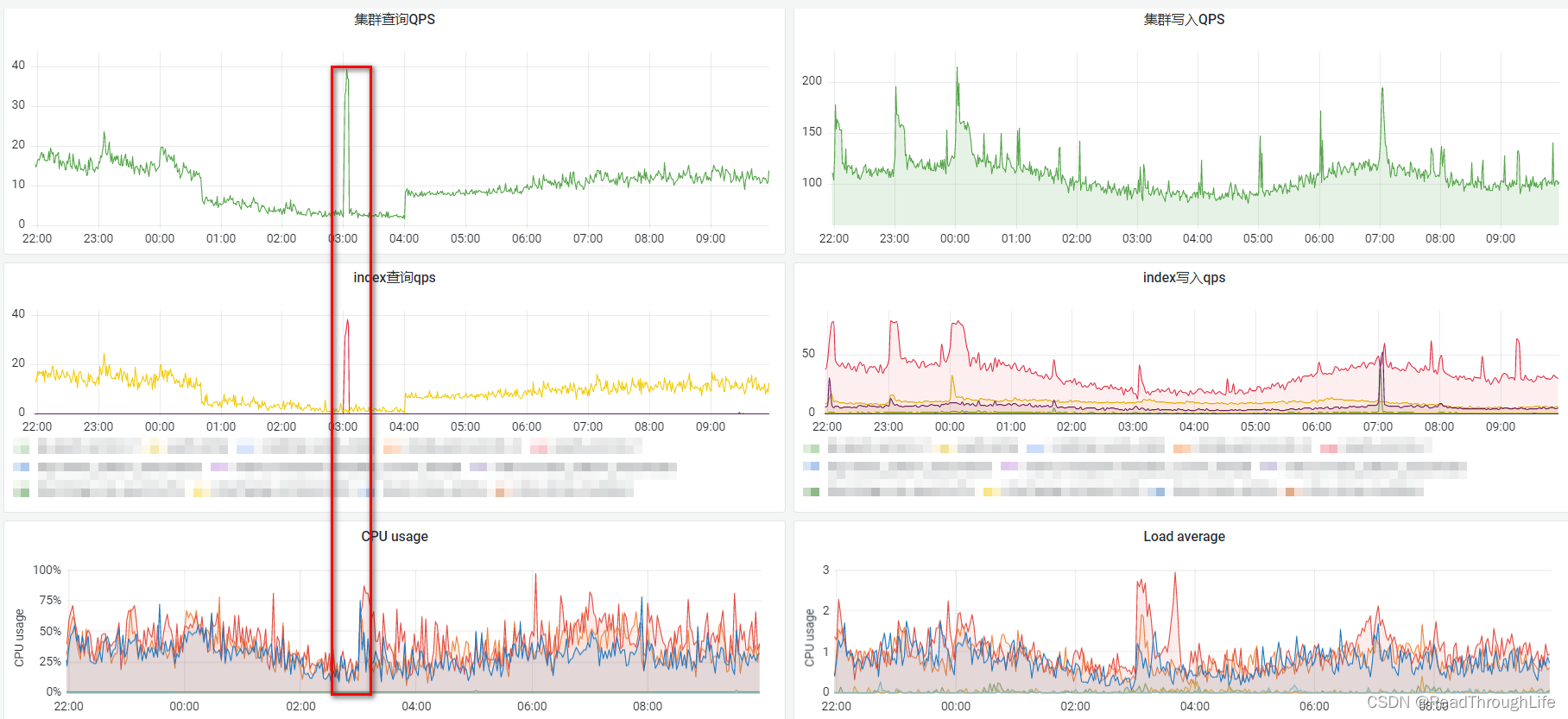
🎈通过观察监控可以发现,在凌晨三点执行定时任务清理 ES 历史数据期间,集群、索引查询 QPS 以及 CPU 利用率指标都明显飙升。因此,清理 ES 数据时一定要避开流量高峰期,避免在流量高峰期清理数据时造成资源实例宕机,造成生产事故。
相关文章:
Java 中使用 ES 高级客户端库 RestHighLevelClient 清理百万级规模历史数据
🎉工作中遇到这样一个需求场景:由于ES数据库中历史数据过多,占用太多的磁盘空间,需要定期地进行清理,在一定程度上可以释放磁盘空间,减轻磁盘空间压力。 🎈在经过调研之后发现,某服务…...
梯度下降230821a)
C++最易读手撸神经网络两隐藏层(任意Nodes每层)梯度下降230821a
// c神经网络手撸20梯度下降22_230820a.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 #include<iostream> #include<vector> #include<iomanip> // setprecision #include<sstream> // getline stof() #include<fstream…...

Leetcode 2235.两整数相加
一、两整数相加 给你两个整数 num1 和 num2,返回这两个整数的和。 示例 1: 输入:num1 12, num2 5 输出:17 解释:num1 是 12,num2 是 5 ,它们的和是 12 5 17 ,因此返回 17 。示例…...
Postman —— postman实现参数化
什么时候会用到参数化 比如:一个模块要用多组不同数据进行测试 验证业务的正确性 Login模块:正确的用户名,密码 成功;错误的用户名,正确的密码 失败 postman实现参数化 在实际的接口测试中,部分参数每…...
LeetCode--HOT100题(41)
目录 题目描述:102. 二叉树的层序遍历(中等)题目接口解题思路代码 PS: 题目描述:102. 二叉树的层序遍历(中等) 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地&am…...
)
微信小程序教学系列(6)
第六章:小程序商业化 第一节:小程序的商业模式 在这一节中,我们将探讨微信小程序的商业模式,让你了解如何将你的小程序变成一个赚钱的机器! 1. 广告收入 小程序的商业模式之一是通过广告收入赚钱。你可以在小程序中…...
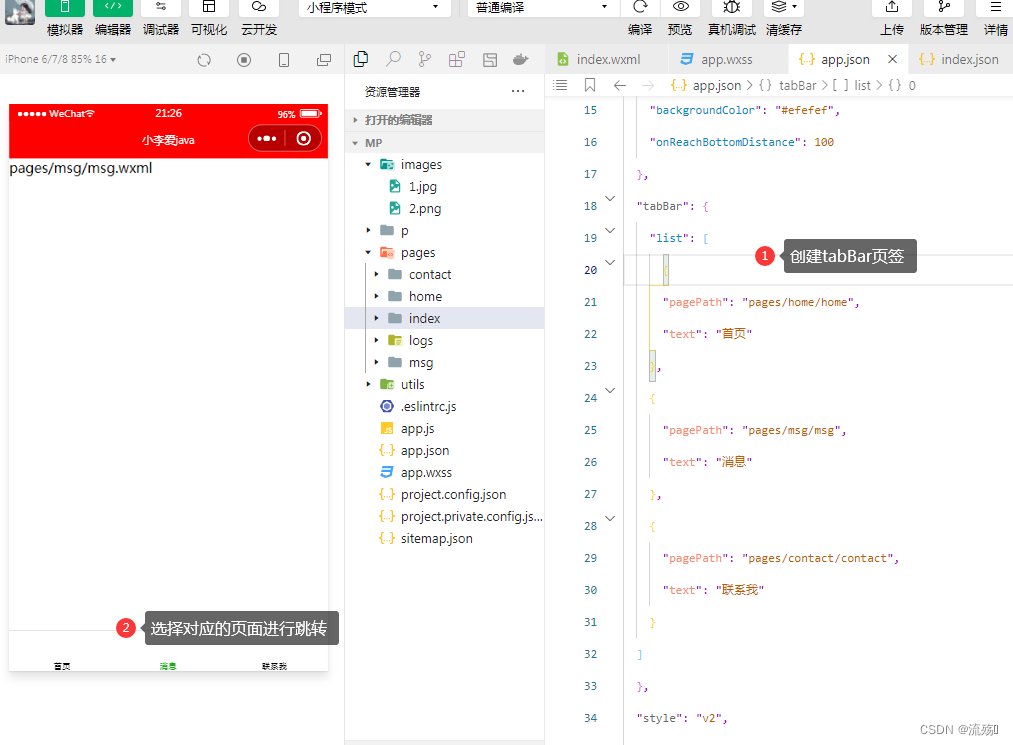
小程序中的全局配置以及常用的配置项(window,tabBar)
全局配置文件和常用的配置项 app.json: pages:是一个数组,用于记录当前小程序所有页面的存放路径,可以通过它来创建页面 window:全局设置小程序窗口的外观(导航栏,背景,页面的主体) tabBar:设置小程序底部的 tabBar效果 style:是否…...
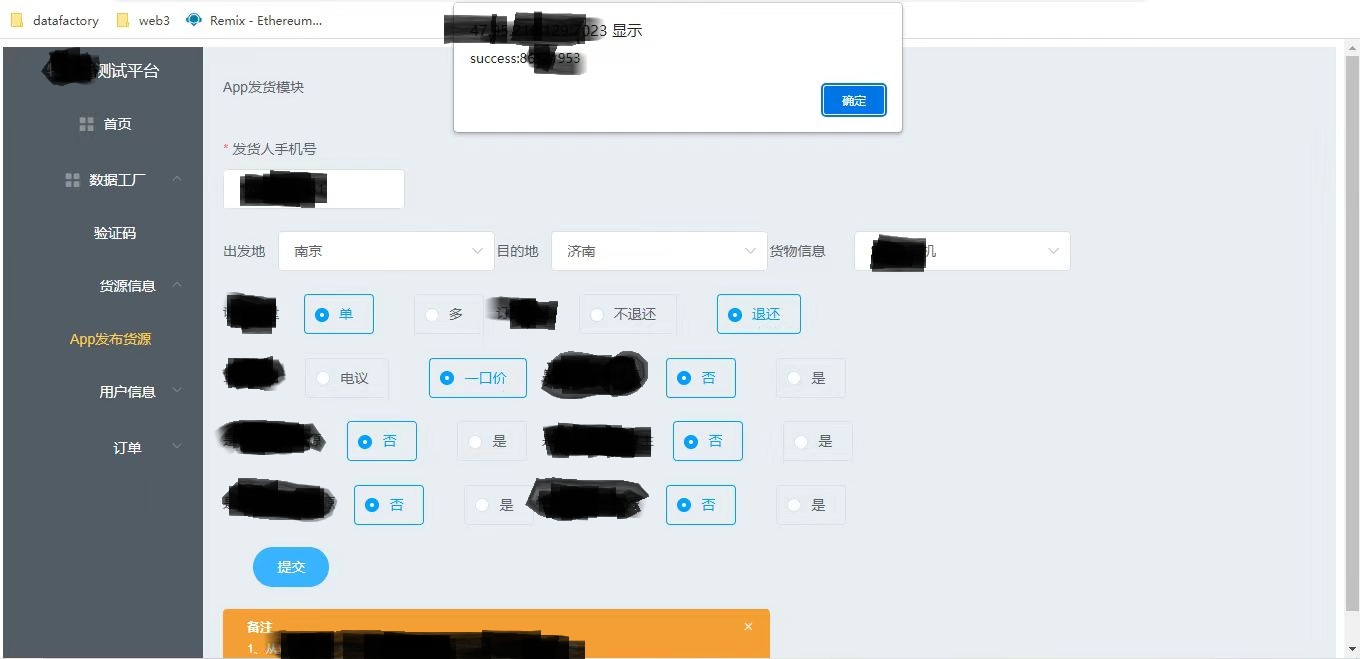
数据工厂调研及结果展示
数据工厂 一、背景 在开发自测、测试迭代测试、产品验收的过程中,都需要各种各样的前置数据,大致分为如下几类: 账号(实名、权益等级、注册等) 货源(优货、急走、相似、一手、普通货源等) …...
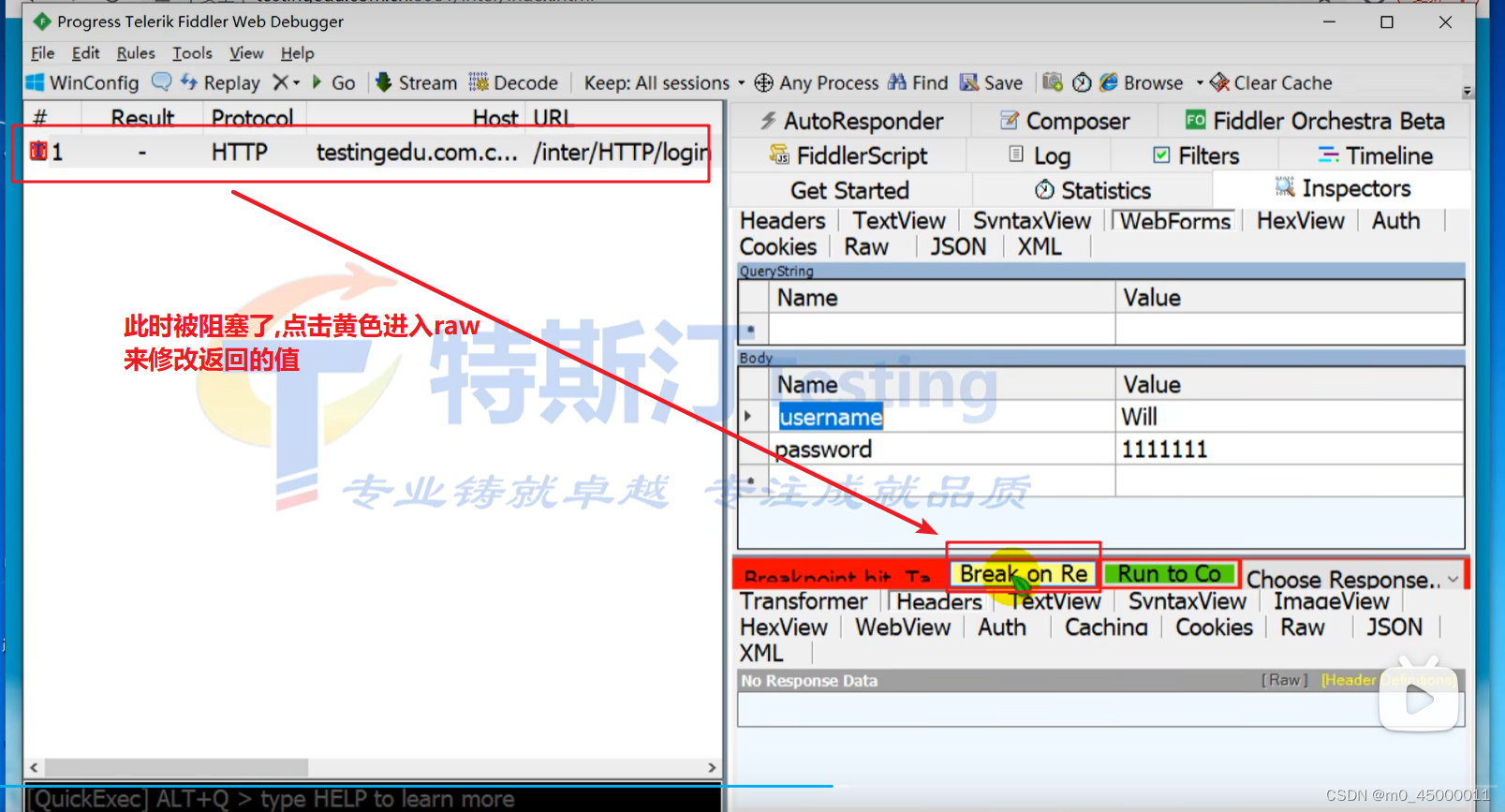
抓包相关,抓包学习
检查网络流量 - 提琴手经典 (telerik.com) Headers Reference - Fiddler Classic (telerik.com) 以上是fiddler官方文档 F12要勾选保留日志 不勾选的话跳转到新页面之前页面的日志不会在下方显示 会保留所有抓到的包 如果重定向到别的页面 F12抓包可能看不到响应信息,但是…...
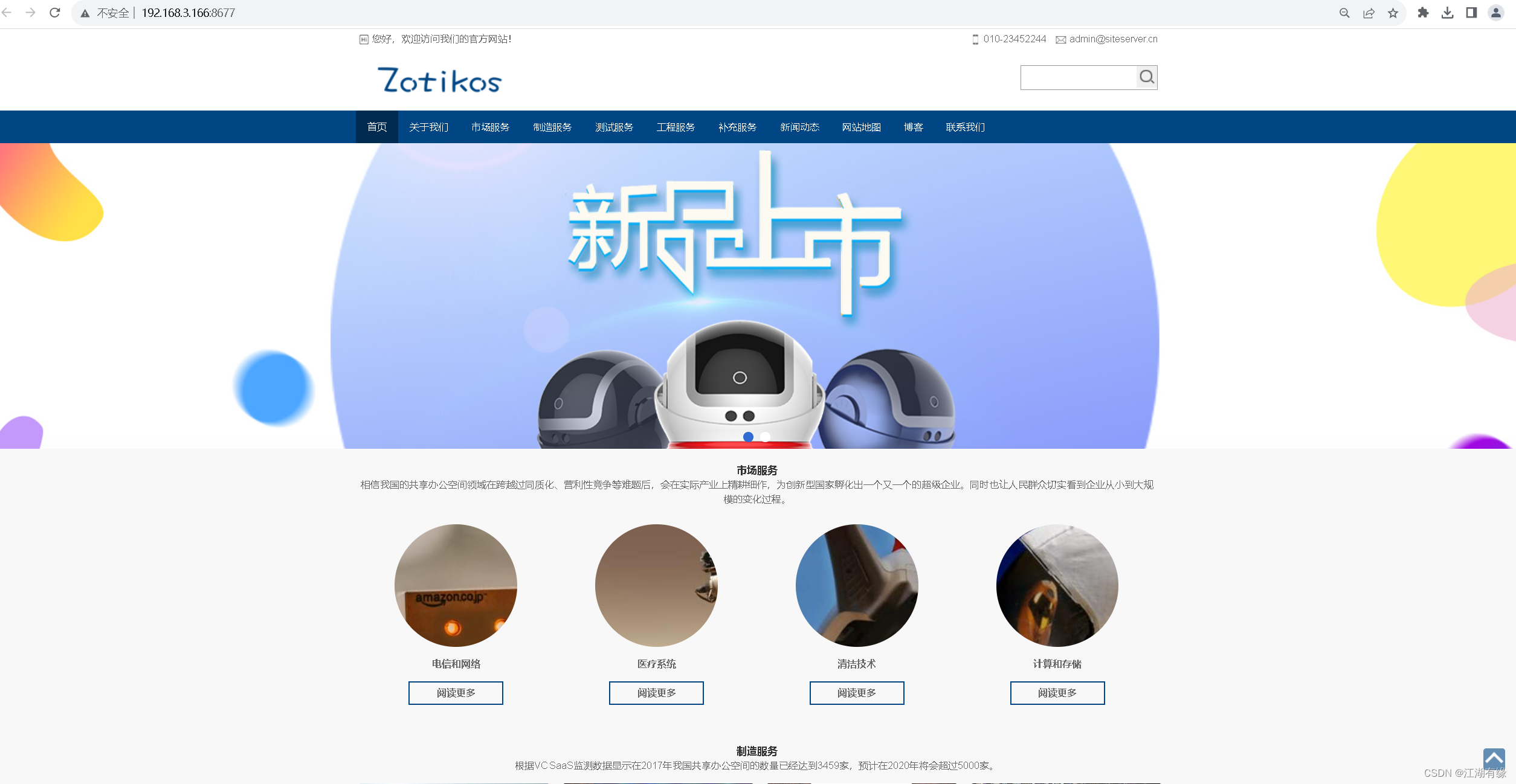
云原生之使用Docker部署SSCMS内容管理系统
云原生之使用Docker部署SSCMS内容管理系统 一、SSCMS介绍二、本地环境介绍2.1 本地环境规划2.2 本次实践介绍 三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本 四、下载SSCMS镜像五、部署SSCMS内容管理系统5.1 创建SSCMS容器5.2 检查SSC…...

uniapp -- 在组件中拿到pages.json下pages设置navigationBarTitleText这个值?
1:在 pages.json 文件中设置 navigationBarTitleText,例如: {"pages": [{"path": "pages/home/index","style": {"navigationBarTitleText": "首页",&...
Java获取环境变量和运行时环境信息和自定义配置信息
System.getenv() 获取系统环境变量 public static void main1() {Map<String, String> envMap System.getenv();envMap.entrySet().forEach(x-> System.out.println(x.getKey() "" x.getValue())); } System.getenv() 获取的是操作系统环境变量列表&…...
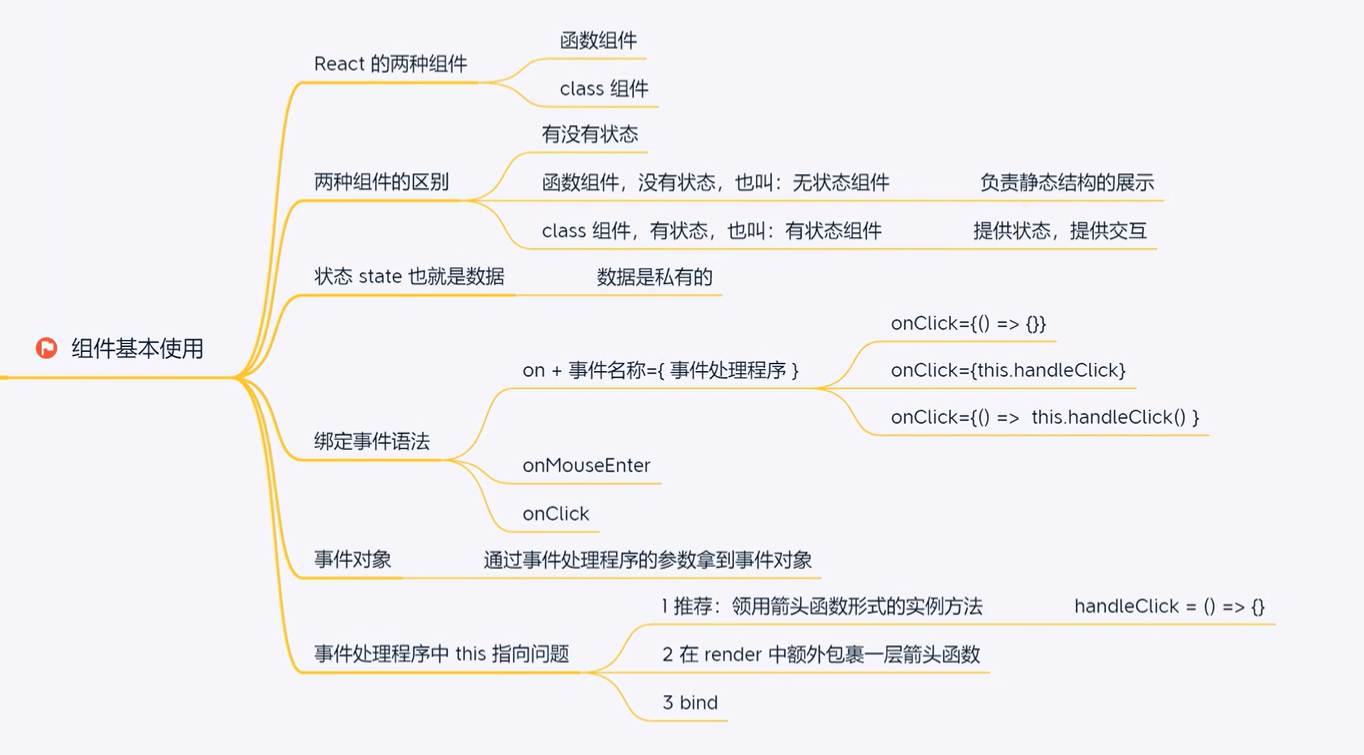
React入门 组件学习笔记
项目页面以组件形式层层搭起来,组件提高复用性,可维护性 目录 一、函数组件 二、类组件 三、 组件的事件绑定 四、获取事件对象 五、事件绑定传递额外参数 六、组件状态 初始化状态 读取状态 修改状态 七、组件-状态修改counter案例 八、this问…...

Windows商店引入SUSE Linux Enterprise Server和openSUSE Leap
在上个月的Build 2017开发者大会上,微软宣布将SUSE,Ubuntu和Fedora引入Windows 商店,反应出微软对开放源码社区的更多承诺。 该公司去年以铂金会员身份加入Linux基金会。现在,微软针对内测者的Windows商店已经开始提供 部分Linux发…...

[NLP]深入理解 Megatron-LM
一. 导读 NVIDIA Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型。Megatron-LM 综合应用了数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并…...

软考高级系统架构设计师系列论文七十八:论软件产品线技术
软考高级系统架构设计师系列论文七十八:论软件产品线技术 一、摘要二、正文三、总结一、摘要 本人作为某软件公司负责人之一,通过对位于几个省的国家甲级、乙级、丙级设计院的考查和了解,我决定采用软件产品线方式开发系列《设计院信息管理平台》产品。该产品线开发主要有如…...
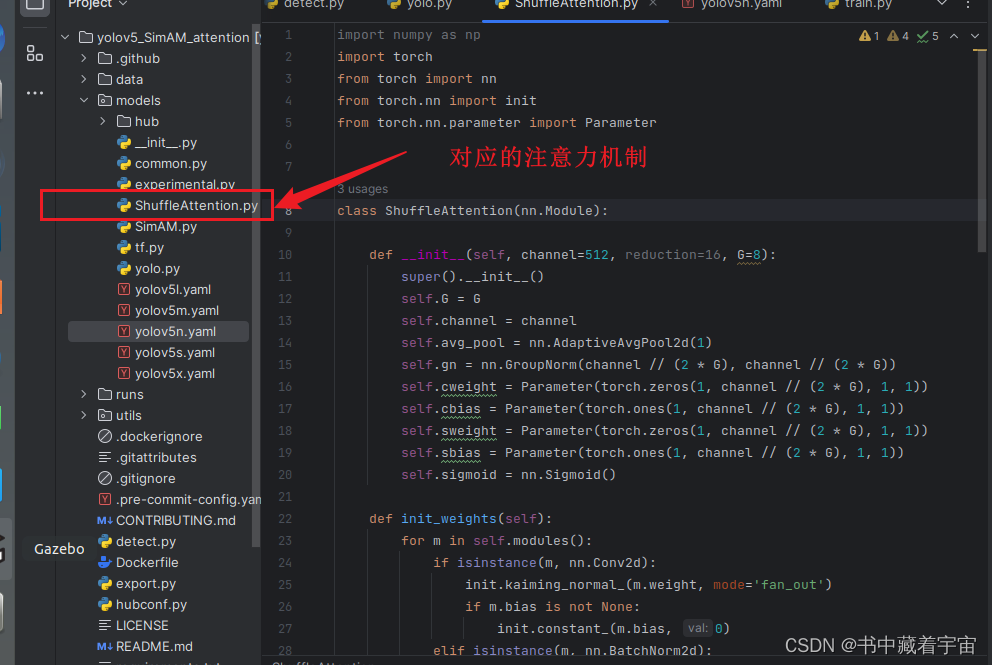
yolov5中添加ShuffleAttention注意力机制
ShuffleAttention注意力机制简介 关于ShuffleAttention注意力机制的原理这里不再详细解释.论文参考如下链接here yolov5中添加注意力机制 注意力机制分为接收通道数和不接受通道数两种。这次属于接受通道数注意力机制,这种注意力机制由于有通道数要求,所示我们添加的时候…...
)
Effective C++条款17——以独立语句将newed 对象置入智能指针(资源管理)
假设我们有个函数用来揭示处理程序的优先权,另一个函数用来在某动态分配所得的widget上进行某些带有优先权的处理: void priority(); void processWidget(std::tr1::shared_ptr<Widget>pw, int priority);由于谨记“以对象管理资源”(条款13&…...

奇迹MU服务器如何选择配置?奇迹MU服务器租用
不同的服务器,根据其特点与性能适用于不同的应用场景,为了让你们更好的理解,我们对服务器进行了分类归纳,结合了服务器不同的特点以及价位进行一个区分,帮助我们更好的选择合适的服务器配置。 VPS服务器 VPS服务器又…...
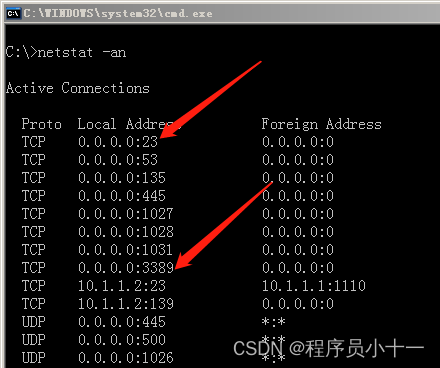
如何远程管理服务器详解
文章目录 前言一、远程管理类型二、远程桌面三、telnet 命令行远程四、查看本地开放端口 前言 很多公司是有自己的机房的,机房里面会有若干个服务器为员工和用户提供服务。大家可以想想:假设这家公司有上百台服务器,我们作为网络工程师&…...

微信聊天记录永久备份完整指南:WeChatExporter开源工具终极教程
微信聊天记录永久备份完整指南:WeChatExporter开源工具终极教程 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录会因为手机丢失…...

从‘坍缩’到‘对齐’:用SimCSE解决BERT句子向量老难题,我的中文业务实验复盘
从语义坍缩到精准对齐:SimCSE在中文业务场景的实战指南 BERT模型在自然语言处理领域取得了巨大成功,但其原生句子向量存在一个令人头疼的问题——语义坍缩。简单来说,就是不同句子的向量在高维空间中倾向于聚集在一起,导致相似度计…...

Selenium自动化测试常见的异常处理
在软件开发和测试领域,Selenium作为一种广泛使用的自动化测试工具,扮演着至关重要的角色。随着自动化测试的不断普及,如何在测试过程中有效捕获并处理异常,成为了每个测试工程师必须掌握的技能。本文旨在深入探讨Selenium异常处理的方法,通过丰富的案例和代码,帮助新手朋…...

Linux端口转发到外网完全教程:iptables DNAT+SNAT实现内网服务暴露
一、什么是外网端口转发Linux端口转发到外网,是指将Linux服务器上某个端口的流量,转发到外网(公网)的另一台服务器。这样做的典型场景是:你有一台内网服务器没有公网IP,但另一台海外服务器有公网IP…...

GPU云服务器选型指南:从核心参数到实际部署的深度解析
在当下人工智能跟高性能计算急剧速度发展状况里,GPU云服务器正沿着从专业领域迈向更为广泛应用场景的路径前行。对于构成企业的开发者、相关技术团队来讲,怎样精准无误理解这一技术方案所具备的本质,并且于实际选型期间做出合乎情理的判断&am…...

数据库完整性约束与安全机制全解析
一、数据库完整性约束1、数据库完整性基本概念与核心机制(1)完整性定义与作用数据库完整性(Database Integrity)是指在任何情况下保证数据的正确性(Validity)和一致性(Consistency)&…...

中国地址生成器:快速生成真实地址数据的开发者利器
中国地址生成器:快速生成真实地址数据的开发者利器 【免费下载链接】chinese-address-generator 中国地址生成器 - 三级地址 四级地址 随机生成完整地址 项目地址: https://gitcode.com/gh_mirrors/ch/chinese-address-generator 在开发测试、数据填充、表单…...

Go语言构建高效命令行工具集:从设计到工程化实践
1. 项目概述:一个“好用的”开源工具集最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫ImGoodBai/goodable。光看这个名字,就透着一股子“实用主义”的气息——“好用的”。作为一名常年混迹于开源社区,喜欢折腾各种工…...

保姆级避坑指南:用GGCNN源码处理Cornell抓取数据集,解决tiff文件生成失败问题
GGCNN源码实战:Cornell数据集预处理深度排错指南 第一次运行GGCNN的Cornell数据集预处理脚本时,我盯着毫无反应的终端窗口足足等了十分钟——没有进度条,没有错误提示,只有光标在无情地闪烁。这大概是每个复现论文的开发者都会经历…...

芯片入门必看:CPU、MCU、SoC、GPU、TPU、NPU
本文首先介绍了芯片的基础分类,包括模拟/数字芯片和逻辑/计算芯片。接着,对8类核心芯片进行了通俗解析,包括CPU、MCU、SoC、GPU、TPU、NPU、FPGA和DSP,涵盖了它们的定义、用途、类型和代表性标的。最后,文章从通用性和…...