卷积神经网络——下篇【深度学习】【PyTorch】【d2l】
文章目录
- 5、卷积神经网络
- 5.10、⭐批量归一化
- 5.10.1、理论部分
- 5.10.2、代码部分
- 5.11、⭐残差网络(`ResNet`)
- 5.11.1、理论部分
- 5.11.2、代码部分
- 话题闲谈
5、卷积神经网络
5.10、⭐批量归一化
5.10.1、理论部分
批量归一化可以解决深层网络中梯度消失和收敛慢的问题,通过固定每个批次的均值和方差来加速收敛,一般不改变模型精度。批量规范化已经被证明是一种不可或缺的方法,它适用于几乎所有图像分类器。
批量规划是一个线性变换,把参数的均值方差给拉的比较好。让你变化不那么剧烈。
批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。 正是由于这个基于批量统计的标准化,才有了批量规范化的名称。
B N ( x ) = γ ⊚ x − μ ^ B σ ^ B + β BN(x) = γ⊚\frac{x-\hat{μ}_B}{\hat{σ}_B}+β BN(x)=γ⊚σ^Bx−μ^B+β
其中,x∈B,x是一个小批量B的输入,比例系数γ,比例偏移β。 μ ^ β B \hat{μ}β_B μ^βB小批量B的均值, σ ^ B \hat{σ}_B σ^B小批量B的标准差。
μ ^ B = 1 ∣ B ∣ ∑ x ∈ B x \hat{μ}_B = \frac{1}{|B|}\sum_{x∈B}{x} μ^B=∣B∣1x∈B∑x
σ ^ B 2 = 1 ∣ B ∣ ∑ x ∈ B ( x − μ ^ B ) 2 + c {\hat{σ}_B}^2 = \frac{1}{|B|}\sum_{x∈B}{(x-\hat{μ}_B)^2 + c} σ^B2=∣B∣1x∈B∑(x−μ^B)2+c
差估计值中添加一个小的常量c>0,以确保永远不会尝试除以零【BN(x)分母】。通过使用平均值和方差的噪声(noise)估计来抵消缩放问题,噪声这里是有益的。
-
可学习的参数:比例系数γ,比例偏移β;
-
作用在全连接层和卷积层输出,激活函数前;
-
作用在全连接层和卷积层输入。
作用于全连接层的特征维
作用于卷积层的通道维
5.10.2、代码部分
直接使用深度学习框架中定义的BatchNorm定义Sequential块
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# nn.BatchNorm2d(6) 二维卷积操作的批归一化层,6通道nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),# # nn.BatchNorm1d(120) 一维卷积操作的批归一化层,120通道nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

批量规范化应用于LeNet
net = nn.Sequential(# BatchNorm(6, num_dims=4) num_dims 参数用来根据输入数据的维度选择适当的批归一化操作,输入6通道,输入4维,这里会选择nn.BatchNorm2d进行归一化。这里和 nn.BatchNorm2d(6) 一样的。nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10))
5.11、⭐残差网络(ResNet)
5.11.1、理论部分
核心思想:保证加更多的层效果较之前不会变差。
设计越来越深的网络,网络表现不一定会更好。
实现原理-残差块(residual blocks)
每个附加层都应该更容易地包含原始函数作为其元素之一。
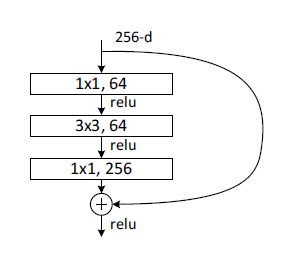
如下图:
正常块中,输出直接作为理想映射 f ( x ) f(x) f(x);
残差块中,输出为 f ( x ) − x f(x)-x f(x)−x和 x x x两部分
x经过残差映射 f ( x ) − x f(x)-x f(x)−x输出
x作为原始数据恒等映射到输出
两者共同组成 f ( x ) f(x) f(x)。

5.11.2、代码部分
实现残差块
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
生成两种类型的网络:
验证输入输出情况一致blk = Residual(3,3) #X batch_size=4,input_channel=3,shape=6*6 X = torch.rand(4, 3, 6, 6) Y = blk(X) Y.shapetorch.Size([4, 3, 6, 6])验证增加输出通道数,同时减半输出的高和宽
blk = Residual(3,6, use_1x1conv=True, strides=2) blk(X).shapetorch.Size([4, 6, 3, 3])

定义ResNet第一个Sequential块
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
定义残差块
def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
定义其他(含残差块)Sequential块
每个模块使用2个残差块
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
在ResNet中加入全局平均汇聚层,以及全连接层输出
每个模块【b2-b5】有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为
ResNet-18。

net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))
验证每模块输出形状变化
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56]) Sequential output shape: torch.Size([1, 64, 56, 56]) Sequential output shape: torch.Size([1, 128, 28, 28]) Sequential output shape: torch.Size([1, 256, 14, 14]) Sequential output shape: torch.Size([1, 512, 7, 7]) AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1]) Flatten output shape: torch.Size([1, 512]) Linear output shape: torch.Size([1, 10])
训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
话题闲谈
怎么维护自己的电脑?
对于深度学习工作者而言,电脑是最为重要的工作工具之一,因此维护电脑的健康状态对工作、学习和生活都至关重要。
首先,定期进行系统和软件的更新,保持操作系统和应用程序在最新版本,以获得更好的性能和安全性。其次,保持电脑的清洁,定期清理灰尘和污垢,确保散热良好,避免过热对硬件的损害。此外,备份重要数据是必不可少的,以防止意外数据丢失。
在学习方面,合理规划学习时间,避免长时间的连续使用电脑,适时休息,保护眼睛和身体健康。
生活娱乐方面,多参与户外活动,保持身体锻炼,减轻长时间坐在电脑前带来的压力。总之,深度学习工作者应关注电脑的硬件和软件健康,平衡工作、学习和生活,保持身心健康。
相关文章:

卷积神经网络——下篇【深度学习】【PyTorch】【d2l】
文章目录 5、卷积神经网络5.10、⭐批量归一化5.10.1、理论部分5.10.2、代码部分 5.11、⭐残差网络(ResNet)5.11.1、理论部分5.11.2、代码部分 话题闲谈 5、卷积神经网络 5.10、⭐批量归一化 5.10.1、理论部分 批量归一化可以解决深层网络中梯度消失和…...

cas md5加密
CAS Authentication Credentials #cas.authn.accept.userscasuser::Mellon 查询账号密码SQL,必须包含密码字段 cas.authn.jdbc.query[0].sqlselect * from ca_user where username? 指定上面的SQL查询字段名(必须) cas.authn.jdbc.query…...

[管理与领导-51]:IT基层管理者 - 8项核心技能 - 6 - 流程
前言: 管理者存在的价值就是制定目标,即目标管理、通过团队(他人)拿到结果。 要想通过他人拿到结果: (1)目标:制定符合SMART原则的符合业务需求的目标,团队跳一跳就可以…...

天翼物联、汕头电信与汕头大学共建新一代信息技术与数字创新(物联网)联合实验室
近日,在工业和信息化部和广东省人民政府共同主办的2023中国数字经济创新发展大会上,天翼物联、汕头电信与汕头大学共建“新一代信息技术与数字创新(物联网)”联合实验室签约仪式举行。汕头大学校长郝志峰、中国电信广东公司总经理…...
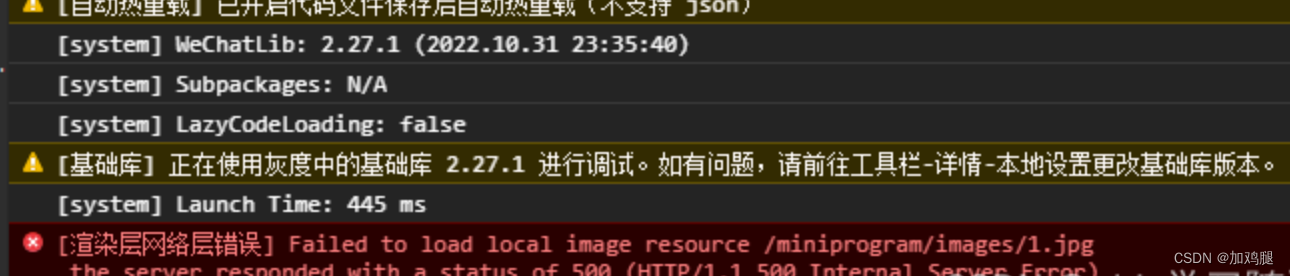
Failed to load local image resource/images/1.jpg无法加载本地图片资源
微信小程序开发无法加载本地图片 先放报错图片 绝对路径不行, <image src"../../images/1.jpg" mode"heightFix"></image>使用相对路径就可以了 <image src"../../images/1.jpg" mode"heightFix"><…...

Go和Java实现责任链模式
Go和Java实现责任链模式 下面通过一个审批流程的案例来说明责任链模式的使用。 1、责任链模式 责任链模式为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这 种类型的设计模式属于行为型模式。 在这种模式中&#x…...

C#+GDAL影像处理笔记08:生成DEM的图阔范围线
目录 1 实现思路 2 源码及解析 1 实现思路 首先获取DEM数据的转换参数信息,这个信息记录了DEM的放射变换参数,包括左上角X,X方向分辨率、0、左上角Y、0、Y方向的分辨率【负值】等信息。接着是根据转换参数,计算DEM分幅数据的四至范围坐标;主要用到上一步得到的转换参数信…...
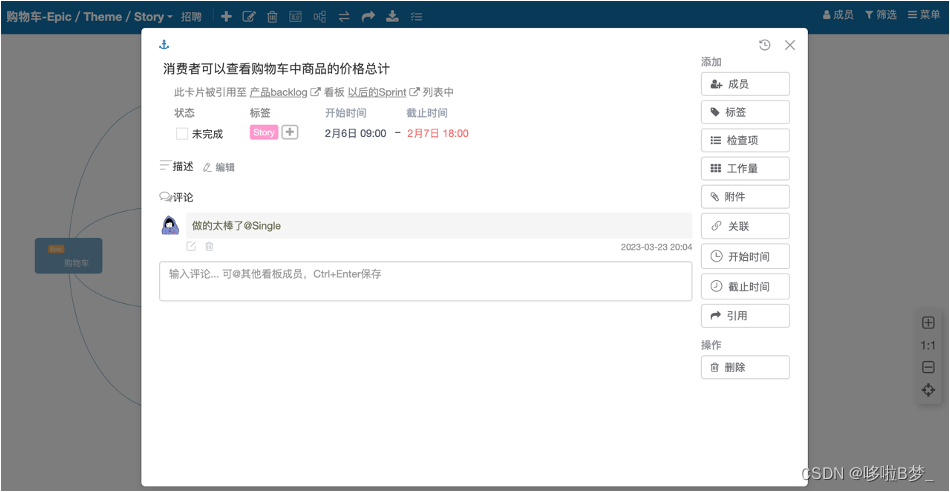
敏捷研发管理软件及敏捷管理流程
Scrum中非常强调公开、透明、直接有效的沟通,这也是“可视化的管理工具”在敏捷开发中如此重要的原因之一。通过“可视化的管理工具”让所有人直观的看到需求,故事,任务之间的流转状态,可以使团队成员更加快速适应敏捷开发流程。 …...
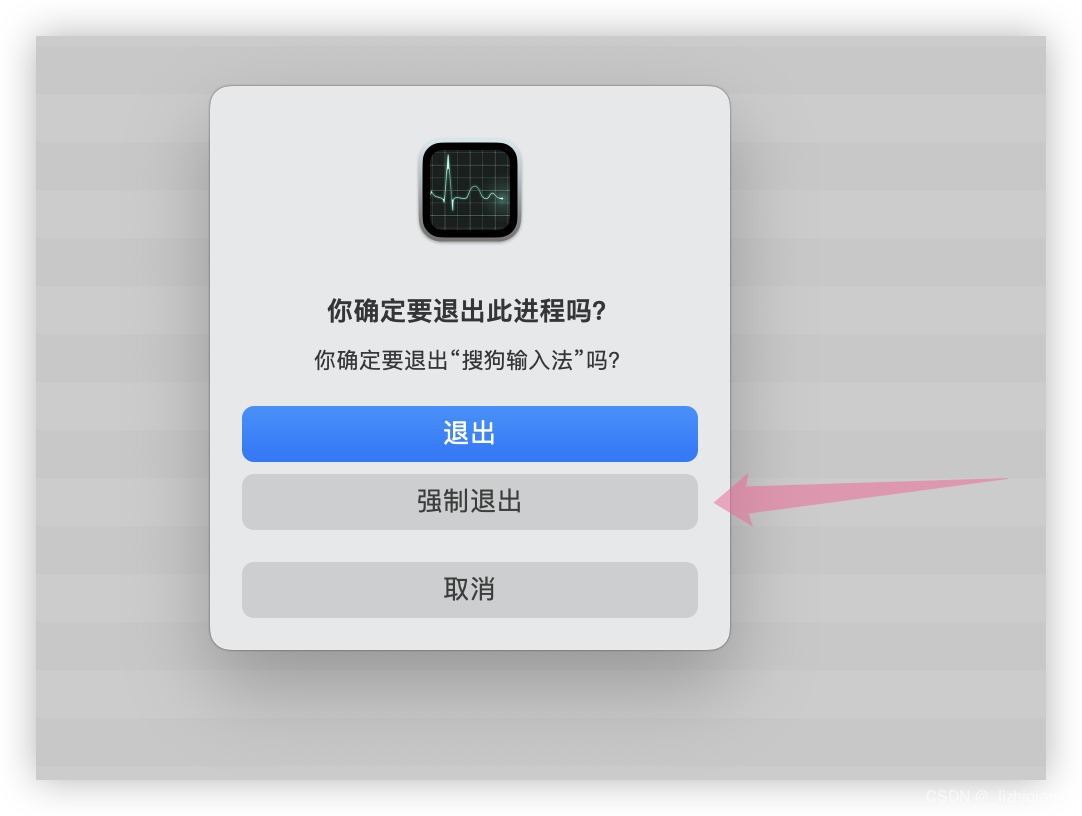
Mac OS 13.4.1 搜狗输入法导致的卡顿问题
一、Mac OS 系统版本 搜狗输入法已经更新到最新 二、解决方案 解决方案一 在我的电脑上面需要关闭 VSCode 和 Chrmoe 以后,搜狗输入法回复正常。 解决方案二 强制重启一下搜狗输入法。 可以用 unix 定时任务去隔 2个小时自动 kill 掉一次进程 # kill 掉 mac …...
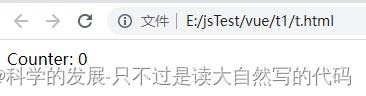
vue 简单实验 自定义组件 局部注册
1.概要 2.代码 <html> </html> <script src"https://unpkg.com/vuenext" rel"external nofollow" ></script> <body><div id"counter"><component-a></component-a></div> </body&g…...
Resnet模型详解
1、Resnet是什么? Resnet是一种深度神经网络架构,被广泛用于计算机视觉任务,特别是图像分类。它是由微软研究院的研究员于2015年提出的,是深度学习领域的重要里程碑之一。 2、网络退化问题 理论上来讲,随着网络的层…...

AI 绘画Stable Diffusion 研究(十六)SD Hypernetwork详解
大家好,我是风雨无阻。 本期内容: 什么是 Hypernetwork?Hypernetwork 与其他模型的区别?Hypernetwork 原理Hypernetwork 如何下载安装?Hypernetwork 如何使用? 在上一篇文章中,我们详细介绍了 …...
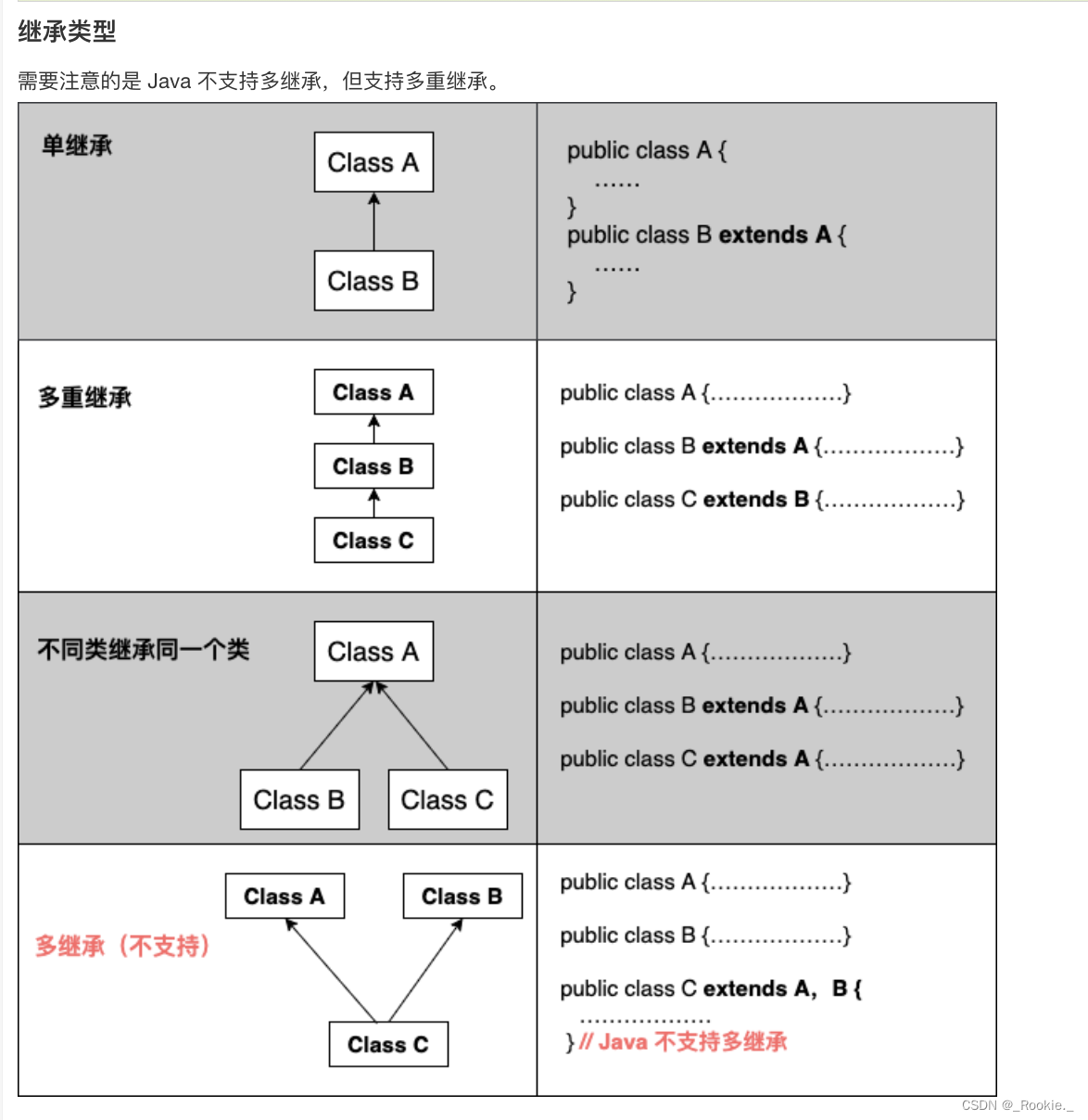
2023.8 -java - 继承
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。 继承的特性 子类拥有父类非 private 的属性、方法。 子类可以拥有自己的属性和方法…...

前端面试:【移动端开发】PWA、Hybrid App和Native App的比较
在移动端开发中,开发者有多种选择,包括渐进式Web应用(PWA),混合应用(Hybrid App)和原生应用(Native App)。每种方法都有其独特的优势和适用场景。本文将对它们进行比较&a…...
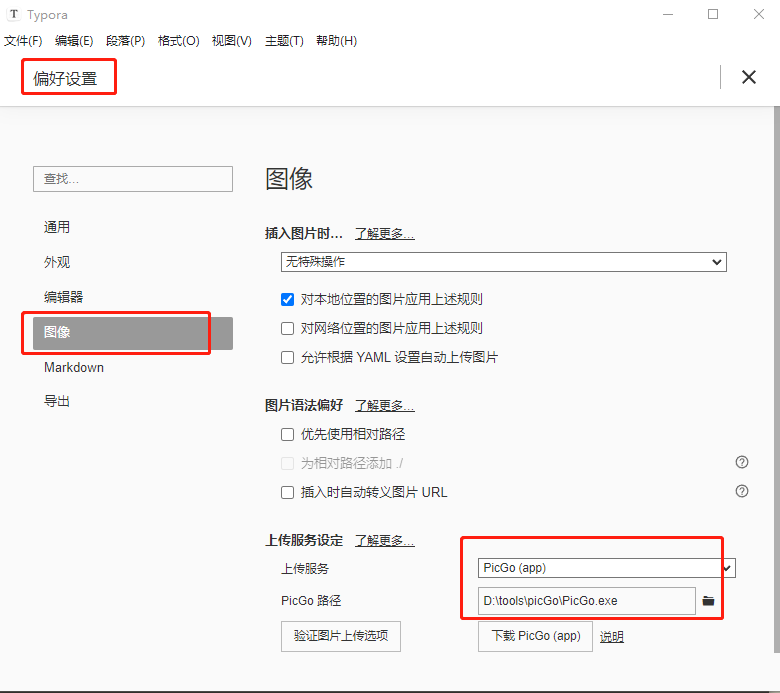
picGo+gitee+typora设置图床
picGogiteetypora设置图床 picGogitee设置图床下载picGo软件安装picGo软件gitee操作在gitee中创建仓库在gitee中配置私人令牌 配置picGo在插件设置中搜索gitee插件并进行下载 TyporapicGo设置Typora 下载Typora进行图像设置 picGogitee设置图床 当我了解picGogitee可以设置图床…...
[JavaWeb]【十三】web后端开发-原理篇
目录 一、SpringBoot配置优先级 1.1 配置优先级比较 1.2 java系统属性和命令行参数 1.3 打包运行jar 1.4 综合优先级编辑 二、Bean管理 2.1 获取bean 2.2 bean作用域 2.2.1 五种作用域 2.2.2 配置作用域 2.3 第三方bean 2.3.1 编写公共配置类 三、SpringBoot原理 …...
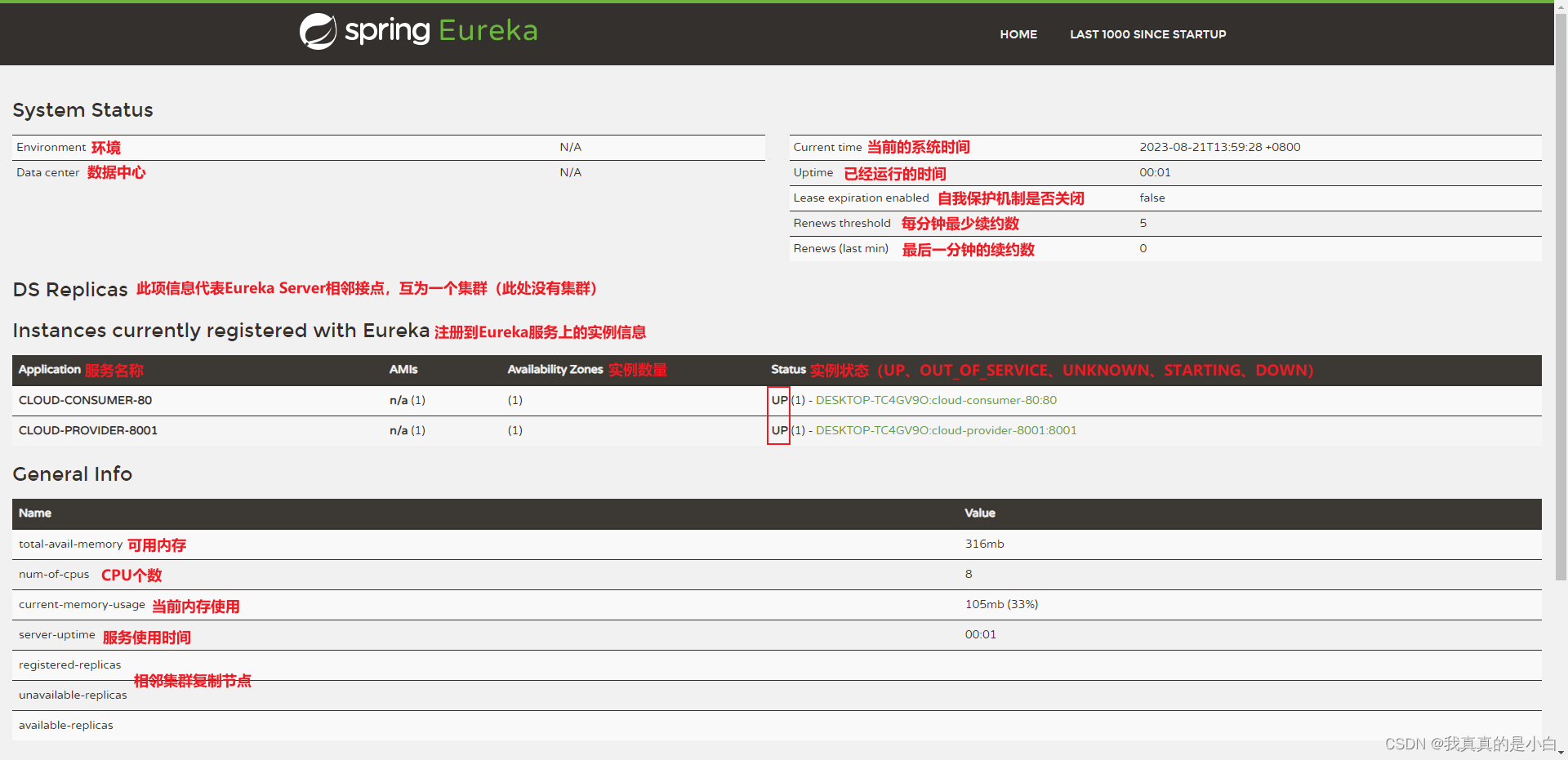
服务注册中心 Eureka
服务注册中心 Eureka Spring Cloud Eureka 是 Netflix 公司开发的注册发现组件,本身是一个基于 REST 的服务。提供注册与发现,同时还提供了负载均衡、故障转移等能力。 Eureka 有 3 个角色 服务中心(Eureka Server):…...
SpringIoC组件的高级特性
目录 一、Bean组件的周期与作用域 二、FactoryBean接口 一、Bean组件的周期与作用域 1.1 Bean组件的生命周期 什么是Bean的周期方法 我们可以在组件类中定义方法,然后当IoC容器实例化和销毁组件对象的时候进行调用!这两个方法我们成为生命周期方法&a…...
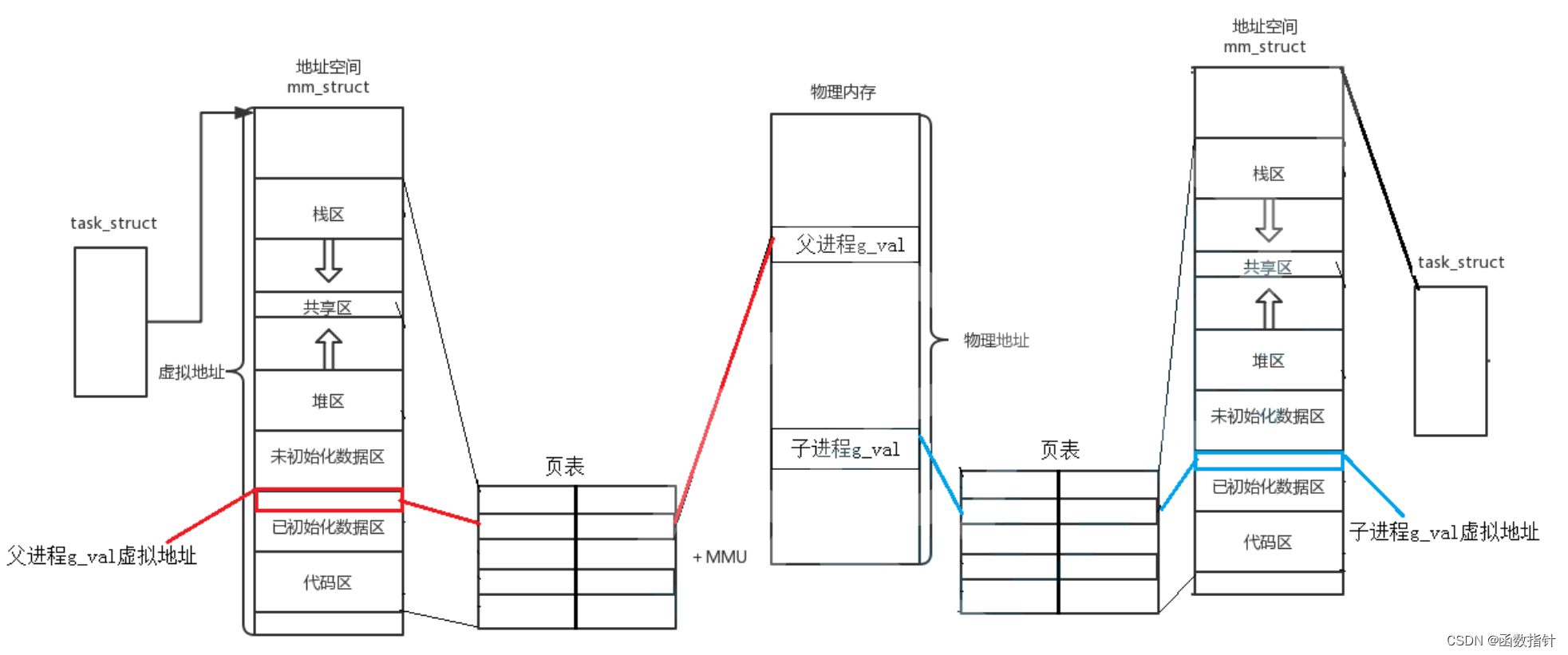
Linux--进程地址空间
1.线程地址空间 所谓进程地址空间(process address space),就是从进程的视角看到的地址空间,是进程运行时所用到的虚拟地址的集合。 简单地说,进程就是内核数据结构和代码和本身的代码和数据,进程本身不能…...
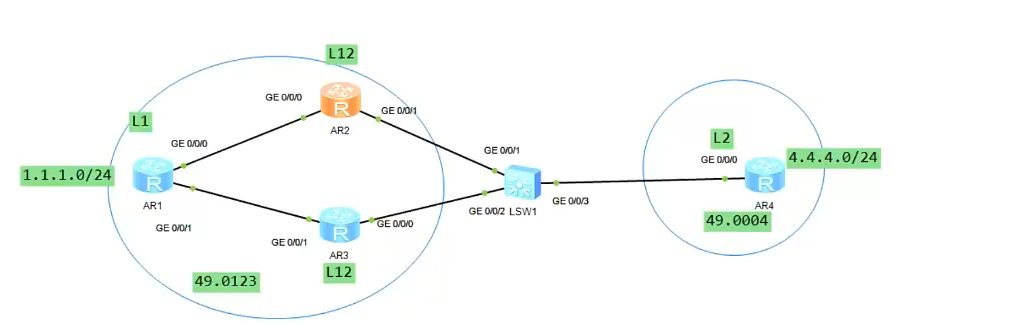
ISIS路由协议
骨干区域与非骨干区域 凡是由级别2组建起来的邻居形成骨干区域;级别1就在非骨干区域,骨干区域有且只有一个,并且需要连续,ISIS在IP环境下目前不支持虚链路。 路由器级别 L1路由器只能建立L1的邻居;L2路由器只能建立L…...

利用Taotoken模型广场为不同AI应用场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI应用场景挑选合适模型 面对文本生成、代码审查、智能对话、翻译等多样化的AI应用场景,如…...

Java SE 与 Spring Boot 在电商场景中的应用
面试:Java SE 与 Spring Boot 在电商场景中的应用 今天,我们将围绕一位求职者在一家电商公司的面试场景,与面试官进行一场激烈的技术问答。第一轮提问 面试官: 首先,请你简单介绍一下 JVM 的工作原理。 燕双非…...

3分钟快速上手:如何用res-downloader高效下载视频号资源
3分钟快速上手:如何用res-downloader高效下载视频号资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在当今数…...

从RIPv2到RIPng:IPv6时代路由协议的演进与实战部署
1. 从RIPv2到RIPng:为什么IPv6需要新的路由协议? 第一次在实验室配置RIPv2时,我盯着那些IPv4地址看了整整三天。直到某天客户突然要求支持IPv6,才发现这个诞生于1988年的老协议已经跟不上时代——就像用传呼机收发4K视频ÿ…...

Dell G15终极散热管理:开源热控中心完全指南 [特殊字符]
Dell G15终极散热管理:开源热控中心完全指南 🚀 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 还在为Dell G15游戏本的过热问题而烦恼…...
)
SITS 2026图计算方案深度解析,独家披露金融风控与生物医药两大场景的GNN工程化适配矩阵(含12个可复用配置模板)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署
技术突破开源方案:img2latex-mathpix实现公式图像转LaTeX代码的本地化部署 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any upda…...

Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验
Windows 11任务栏拖放功能终极修复指南:3步恢复高效操作体验 【免费下载链接】Windows11DragAndDropToTaskbarFix "Windows 11 Drag & Drop to the Taskbar (Fix)" fixes the missing "Drag & Drop to the Taskbar" support in Windows…...

深耕区域数字生态,智森传媒赋能本地中小企业破局增长
在本地生活流量红利消退、行业内卷加剧的当下,中小企业数字化转型已不是选择题,而是生存题。十堰智森网络传媒立足本土市场,以技术研发为根基,以区域获客为核心,以数字人直播为抓手,为中小企业搭建全链路数…...

告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南
告别‘纸片人’:在Unity URP里给角色注入灵魂——皮肤透光、发丝细节与眼神光的调校指南 在独立游戏开发中,角色往往是玩家情感投射的核心载体。一个缺乏生命力的角色模型,即使建模精度再高,也会让玩家产生"纸片人"的疏…...