【mysql是怎样运行的】-EXPLAIN详解
文章目录
- 1.基本语法
- 2. EXPLAIN各列作用
- 1. table
- 2. id
- 3. select_type
- 4. partitions
- 5. type
1.基本语法
EXPLAIN SELECT select_options
#或者
DESCRIBE SELECT select_options
EXPLAIN 语句输出的各个列的作用如下:
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个SELECT关键字都对应一个唯一的id |
| select_type | SELECT关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
2. EXPLAIN各列作用
建表
CREATETABLEs1(idINTAUTO_INCREMENT,key1VARCHAR(100),key2INT,key3VARCHAR(100),key_part1VARCHAR(100),key_part2VARCHAR(100),key_part3VARCHAR(100),common_fieldVARCHAR(100),PRIMARYKEY(id),INDEXidx_key1(key1),UNIQUEINDEXidx_key2(key2), INDEXidx_key3(key3),INDEX idx_key_part(key_part1,key_part2,key_part3)) ENGINE=INNODBCHARSET=utf8;
CREATETABLEs2(idINTAUTO_INCREMENT,key1VARCHAR(100),key2INT,key3VARCHAR(100),key_part1VARCHAR(100),key_part2VARCHAR(100),key_part3VARCHAR(100),common_fieldVARCHAR(100), PRIMARYKEY(id),INDEXidx_key1(key1),UNIQUEINDEXidx_key2(key2),INDEXidx_key3(key3),INDEX idx_key_part(key_part1,key_part2,key_part3)) ENGINE=INNODBCHARSET=utf8;
1. table
不论我们的查询语句有多复杂,包含了多少个表 ,到最后也是需要对每个表进行单表访问的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
2. id
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字,比如下边这个查询语句:
SELECT * FROM s1 WHERE key1 = 'a';
稍微复杂一点的连接查询中也只有一个 SELECT 关键字,比如:
SELECT * FROM s1 INNER JOIN s2
ON s1.key1 = s2.key1
WHERE s1.common_field = 'a';
查询语句中每出现一个SELECT关键字,设计 MySQL的大叔就会为它分配一个唯一的id值,这个 id 值就是EXPLAIN输出的第一列,比如下面查询中只有一个SELECT关键字,所以EXPLAIN结果中也就只有一条id 列为1的记录.
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';


mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2;

对于包含子查询的查询语句来说,就可能涉及多个 SELECT 关键字.所以在包含子查询的查询语句的执行计划中,每个 SELECT 关键字都会对应一个唯一的id值:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a';

查询优化器可能对涉及子查询的查询语句进行重写,从而转换为连接
查询(当然这里指的是半连接),所以这里的id值相同:
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key2 FROM s2 WHERE common_field
= 'a');

mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;


mysql> EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;

MYSQL5.6 以及之前的版本中,执行UNION ALL语句可能也会用到临时表。
小结:
- id如果相同,可以认为是一组,从上往下顺序执行
- 在所有组中,id值越大,优先级越高,越先执行
- 关注点:id号每个号码,表示一趟独立的查询,一个sql的查询趟数越少越好
3. select_type
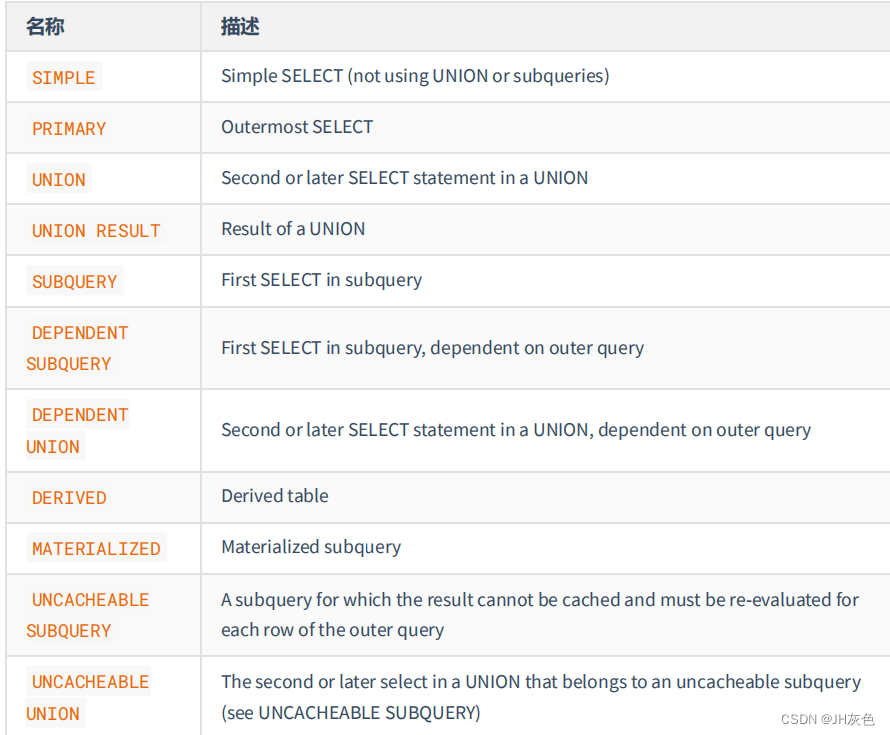
(1) SIMPLE:查询语句中不包含 UNION 或者子查询的查询都算SIMPLE类型。

(2)PRIMARY:对于包含 UNION或UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其中最左边那个查询的 select_type 值就是 PRIMARY。
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;

(3) UNION:对于包含 UNION或UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其余小查询的 select_type 值就 UNION。
(4) UNION RESULT:MySQL 选择使用临时表来完成 UNION 查询的去重工作,针对该临时表的查询的 select_type 就是 UNION RESULT,前文有。
(5) SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询是不相关子查询,而且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT 关键字代表的那个查询的 select_type 就是SUBQUERY。

(6) DEPENDENT SUBQUERY:如果包含子查询的查询语句不能够转为对应的半连接形式,并且该子查询被查询优化器转换为相关子查询的形式,该子查询的第一个SELECT 关键字代表的那个查询的 select_type就是DEPENDENT SUBQUERY。
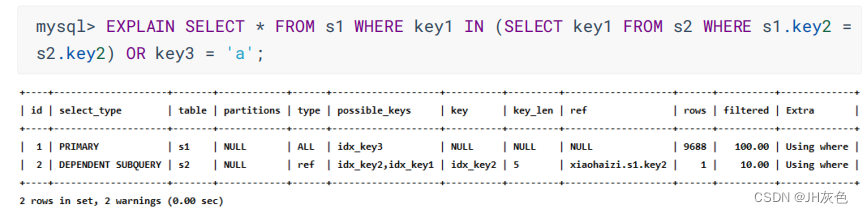
(7) DEPENDENT UNION:在包含 UNION 或者 UNION ALL 的大查询中 ,如果各个小查询都依赖于外层查询,则除了最左边的那个小查询之外 ,其余小查询的 select_type值就是 DEPENDENT UNlON。

(8) DERIVED:在包含派生表的查询中,如果是以物化派生表的方式执行查询,则派生表对应的子查询的 select_type 就是 DERIVED。
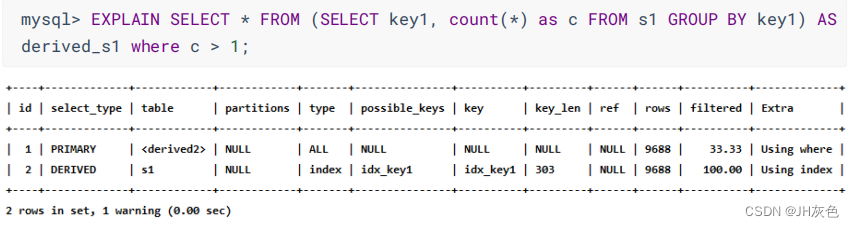
(9) MATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询 ,该子查询对应的select_type 属性就是 MATERlALIZED。

(10) UNCACHEABLE SUBQUERY
(11) UNCACHEABLE UNION
4. partitions
-- 创建分区表,
-- 按照id分区,id<100 p0分区,其他p1分区
CREATE TABLE user_partitions (id INT auto_increment,
NAME VARCHAR(12),PRIMARY KEY(id))
PARTITION BY RANGE(id)(
PARTITION p0 VALUES less than(100),
PARTITION p1 VALUES less than MAXVALUE
);
DESC SELECT * FROM user_partitions WHERE id>200;
查询id大于200(200>100,p1分区)的记录,查看执行计划,partitions是p1,符合我们的分区规则

5. type
完整的访问方法如下: system , const , eq_ref , ref , fulltext , ref_or_null ,index_merge , unique_subquery , index_subquery , range , index , ALL 。
(1) system:当表中只有一条记录并且该表使用的存储引攀 (比如 MyISAM MEMORY)的统计数据是精确的, 那么对该表的访问方法就是 system。

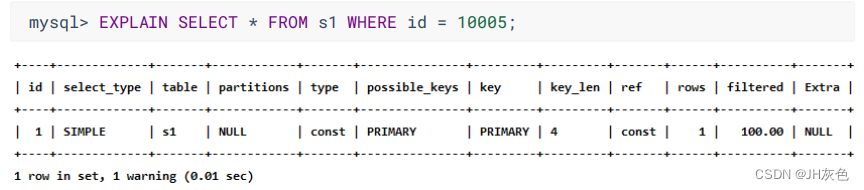
(2) const:我们根据主键或者唯一二级索引列与常数进行等值匹配
时, 对单表的访问方法就是 const。
(3) eq_ref:执行连接查询时,如果被驱动表是通过主键或者不允许存储 NULL 值的唯一二级索引列等值匹配的方式进行访问的(如果该主键或者不允许存储 NULL值的唯一二级索引是联合索引,则所有的索引列都必须进行等值比较) 。则对该被驱动表的访问方法就是eq_ref 。
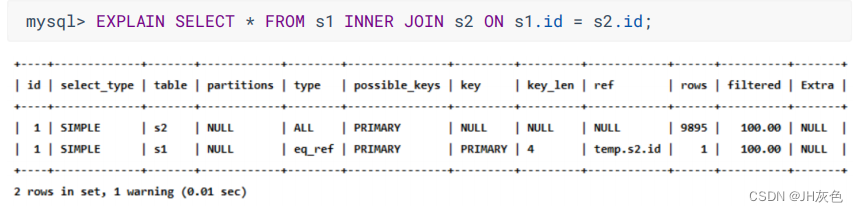
从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
(4) ref:当通过普通的二级索引列与常量进行等值匹配的方式查询某个表时,对该表的访问方法就可能是ref。

(5) fulltext:全文索引
(6):ref_or_null:当对普通的二级索引列进行等值匹配且该索引列的值也可以是NULL值时,对该表的访问方法就可能是ref_or_null。

(7) index_merge:索引合并
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';

(8) unique_subquery:类似于两表连接中被驱动表的eq_ref访问方法,unique_subquery针对的是一些包含IN子查询的查询语句。如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询在转换之后可以使用主键或者不允许存储 NULL值的唯一二级索引进行等值匹配, 那么 type 列的值就是 unique_subquery。

相关文章:
【mysql是怎样运行的】-EXPLAIN详解
文章目录 1.基本语法2. EXPLAIN各列作用1. table2. id3. select_type4. partitions5. type 1.基本语法 EXPLAIN SELECT select_options #或者 DESCRIBE SELECT select_optionsEXPLAIN 语句输出的各个列的作用如下: 列名描述id在一个大的查询语句中每个SELECT关键…...

数据结构例题代码及其讲解-链表
链表 单链表的结构体定义及其初始化。 typedef struct LNode {int data;struct LNode* next; }LNode, *LinkList;①强调结点 LNode *p; ②强调链表 LinkList p; //初始化 LNode* initList() {//定义头结点LNode* L (LNode*)malloc(sizeof(LNode));L->next NULL;return …...
[Open-source tool] 可搭配PHP和SQL的表單開源工具_Form tools(1):簡介和建置
Form tools是一套可搭配PHP和SQL的表單開源工具,可讓開發者靈活運用,同時其有數個表單模板和應用模組供挑選,方便且彈性。Form tools已開發超過20年,為不同領域的需求者或開發者提供一個自由和開放的平台,使他們可建構…...

移动数据业务价值链的整合
3G 时代移动数据业务开发体系的建立和发展,要求运营商从封闭、统一的业 务形态、单一提供业务,向开放的、个性化多元化的业务体系以及多方合作参与提 供业务的方向发展,不可避免的使通信价值链不断延长和升级,内容提供商、服务 …...
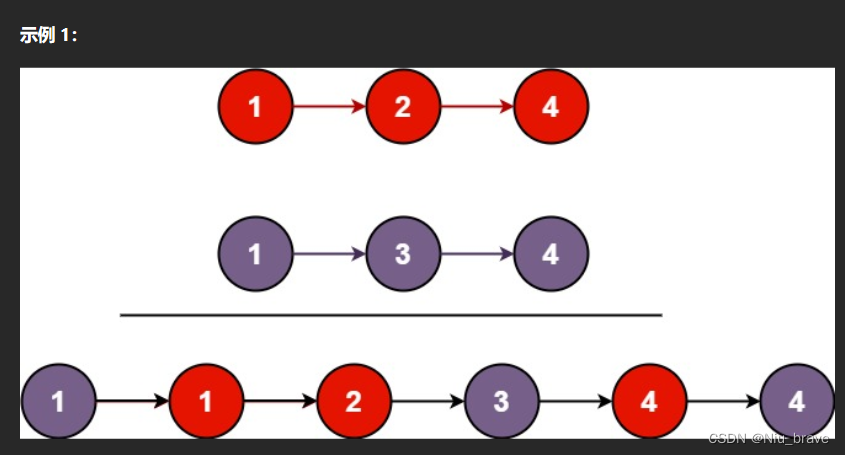
合并两个链表
题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 比如以下例子: 题目接口: /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListN…...
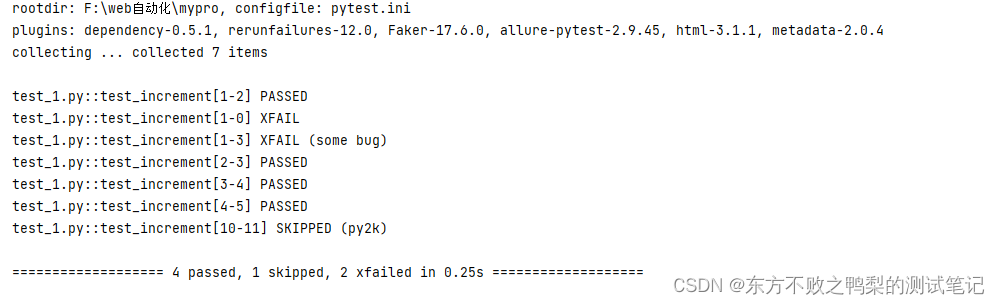
测试框架pytest教程(9)跳过测试skip和xfail
skip无条件跳过 使用装饰器 pytest.mark.skip(reason"no way of currently testing this") def test_example(faker):print("nihao")print(faker.words()) 方法内部调用 满足条件时跳过 def test_example():a1if a>0:pytest.skip("unsupported …...

HTML <textarea> 标签
实例 <textarea rows="3" cols="20"> 收拾收拾 </textarea>定义和用法 <textarea> 标签定义多行的文本输入控件。 文本区中可容纳无限数量的文本,其中的文本的默认字体是等宽字体(通常是 Courier)。 可以通过 cols 和 rows 属性来…...

探索图结构:从基础到算法应用
文章目录 理解图的基本概念学习图的遍历算法学习最短路径算法案例分析:使用 Dijkstra 算法找出最短路径结论 🎉欢迎来到数据结构学习专栏~探索图结构:从基础到算法应用 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:I…...

Redis之GEO类型解读
目录 基本介绍 基本命令 geoadd 命令 geopos 命令 geodist 命令 georadius 命令 georadiusbymember 命令 geohash 命令 基本介绍 GEO 主要用于存储地理位置信息(纬度、经度、名称)添加到指定的key中。该功能在 Redis 3.2 版本新增。 GEO&…...

uniapp 微信小程序 路由跳转
保留当前页面,跳转到应用内的某个页面,使用uni.navigateBack可以返回到原页面 //在起始页面跳转到test.vue页面并传递参数 uni.navigateTo({url: test?id1&name"lisa" }); uni.redirectTo(OBJECT) 关闭当前页面,跳转到应用…...

【android12-linux-5.1】【ST芯片】HAL移植后没调起来
ST传感器芯片HAL按官方文档移植后,测试一直掉不起来,加的日志没出来。经过分析,是系统自带了一个HAL,影响的。 按照官方文档,移植HAL后,在/device/<vendor\>/<board\>/device.mk*路径增加PROD…...

Redis Lua脚本执行原理和语法示例
Redis Lua脚本语法示例 文章目录 Redis Lua脚本语法示例0. 前言参考资料 1. Redis 执行Lua脚本原理1.1. 对Redis源码中嵌入Lua解释器的简要解析:1.2. Redis Lua 脚本缓存机制 2. Redis Lua脚本示例1.1. 场景示例1. 请求限流2. 原子性地从一个list移动元素到另一个li…...

百望云华为云共建零售数字化新生态 聚焦数智新消费升级
零售业是一个充满活力和创新的行业,但也是当前面临很大新挑战和新机遇的行业。数智新消费时代,数字化转型已经成为零售企业必须面对的重要课题。 8 月 20 日-21日,以“云上创新 韧性增长”为主题的华为云数智新消费创新峰会2023在成都隆重召…...
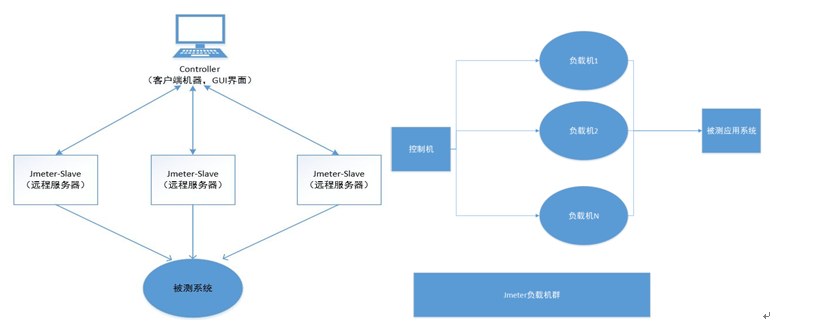
JMETER基本原理
Jmeter基本原理是建立一个线程池,多线程运行取样器产生大量负载,在运行过程中通过断言来验证结果的正确性,可以通过监听来记录测试结果; JMETER是运行在JVM虚拟机上的,每个进程的开销比loadrunner的进程开销大&#x…...

elementUI自定义上传文件 前端后端超详细过程
下面是使用Element UI自定义上传文件的前后端详细过程: 前端过程: 引入Element UI组件库:在前端项目中引入Element UI库,可以通过CDN引入或者通过npm安装并导入。 创建上传组件:在前端代码中创建一个上传组件&#x…...

快速排序笔记
一、quick_sort方法中如果 il,jr 会死循环的分析 1、示例代码 void quick_sort(int a[],int l,int r){if(l>r) return;int il,jr; //此处设置会导致死循环int x num[(lr)>>1];while(i<j){while(a[i] <x); //死循环的地方while(a[--j] >x);if(i<j) swap(a…...
java.lang.Integer cannot be cast to java.lang.Long)
JAVA:(JSON反序列化Long变成了Integer)java.lang.Integer cannot be cast to java.lang.Long
困扰了好几个小时。。。 场景:mybatisplus从数据库取数据,只是用了最基础的 LambdaQueryWrapper 来查询,实体类如下。 TableField(typeHandler JacksonTypeHandler.class) private Set<Long> ids; 得到的Set数据却是Set<Integer…...

ui设计师简历自我评价(合集)
UI设计最新面试题及答案 1、说说你是怎么理解UI的? UI是最直观的把产品展示展现在用户面前的东西,是一个产品的脸面。人开始往往是先会先喜欢上美好的事物后,在去深究内在的东西的。 那么也就意味着一个产品的UI首先要做的好看,无论风格是…...

Nginx 反向代理
一. Nginx 反向代理 1.1 反向代理介绍 在计算机网络中,反向代理一般指代理服务器,其首先代替内网的服务器接收客户端请求 并从一个或多个服务器检索资源,然后将这些资源返回给客户端。在客户端看来,这些资 源就好像来自代理服务…...
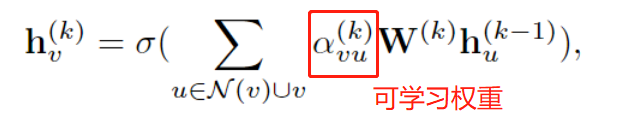
[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks
这是一篇GNN的综述, 发表于2021年的TNNLS. 这篇博客旨在对GNN的基本概念做一些记录. 论文地址: 论文 1. 引言, 背景与定义 对于图像数据来说, CNN具有平移不变性和局部连接性, 因此可以在欧氏空间上良好地学习. 然而, 对于具有图结构的数据(例如社交网络 化学分子等)就需要用…...
)
别再只点灯了!用ESP32和WebServer库做个智能家居控制面板原型(附完整代码)
用ESP32打造智能家居控制面板:从网页控制到硬件交互实战 想象一下,清晨醒来无需下床,轻点手机就能打开窗帘、调节灯光;离家时一键关闭所有电器,还能实时查看家中温湿度——这些看似未来的场景,如今用一块ES…...

告别环境报错!保姆级教程:从JRE到STM32CubeMX 6.10.0的完整安装与配置
从零搭建STM32开发环境:CubeMX 6.10.0避坑全指南 刚拿到STM32开发板时的兴奋,往往在环境配置阶段就被各种报错消磨殆尽。作为过来人,我深刻理解那种看着红色错误提示却无从下手的挫败感。本文将带你用最稳妥的方式完成从Java环境到CubeMX的全…...

抖音无水印视频下载终极指南:5分钟快速掌握免费批量下载技巧
抖音无水印视频下载终极指南:5分钟快速掌握免费批量下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

初次使用Taotoken模型广场进行选型与切换的直观体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken模型广场进行选型与切换的直观体验 对于开发者而言,接入大模型API后,面对的第一个现实问题…...

一台电脑变四台主机:Nucleus Co-Op如何让单人游戏秒变多人派对?
一台电脑变四台主机:Nucleus Co-Op如何让单人游戏秒变多人派对? 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 想象一下&a…...

Rust与Godot引擎集成:使用gdext构建高性能游戏模块
1. 项目概述:当Rust遇上Godot 如果你是一名游戏开发者,同时又对Rust语言的安全性、性能和现代特性着迷,那么你很可能和我一样,曾经在两个优秀的工具之间感到难以抉择。一边是上手快、生态繁荣的Godot引擎,另一边是能让…...

MagiskBoot深度解析:Android启动镜像处理机制与实战应用
MagiskBoot深度解析:Android启动镜像处理机制与实战应用 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk项目中的核心工具,专门负责Android启动镜像的解析、…...

WarcraftHelper:魔兽争霸3终极增强插件完全指南
WarcraftHelper:魔兽争霸3终极增强插件完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争霸3设计的…...

茉莉花插件:终极中文文献管理解决方案,三步搞定Zotero中文文献难题
茉莉花插件:终极中文文献管理解决方案,三步搞定Zotero中文文献难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasmi…...