【大数据】Doris:基于 MPP 架构的高性能实时分析型数据库
Doris:基于 MPP 架构的高性能实时分析型数据库
1.Doris 介绍
Apache Doris 是一个基于 MPP(Massively Parallel Processing,大规模并行处理)架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足 报表分析、即席查询、统一数仓构建、数据湖联邦查询加速 等使用场景,用户可以在此之上构建 用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析 等应用。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目, 2017 2017 2017 年正式对外开源, 2018 2018 2018 年 7 7 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。目前 Apache Doris 社区已经聚集了来自不同行业数百家企业的 400 400 400 余位贡献者,并且每月活跃贡献者人数也超过 100 100 100 位。 2022 2022 2022 年 6 6 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)
Apache Doris 如今在中国乃至全球范围内都拥有着广泛的用户群体,截止目前, Apache Doris 已经在全球超过 2000 2000 2000 家企业的生产环境中得到应用,在中国市值或估值排行前 50 50 50 的互联网公司中,有超过 80 % 80\% 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、微博、贝壳等。同时在一些传统行业如金融、能源、制造、电信等领域也有着丰富的应用。

2.使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到 实时数仓 Doris 和 离线湖仓(Hive、Iceberg、Hudi 中),Apache Doris 被广泛应用在以下场景中。

-
报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(
Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 100 100 亿行数据,查询并发 QPS 上万, 99 99 99 分位的查询延时 150 150 150 m s ms ms。
-
即席查询(
Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10 10 10 s s s, 95 95 95 分位的查询延时 30 30 30 s s s 以内,每天的 SQL 查询量为数万条。 -
统一数仓构建:一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由
Spark、Hive、Kudu、Hbase、Phoenix组成的旧架构,架构大大简化。 -
数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
3.技术概述
Doris 整体架构如下图所示,Doris 架构非常简单,只有两类进程
- Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- Backend(BE),主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。

在 使用接口 方面,Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。Doris 当前支持多种主流的 BI 产品,包括不限于 SmartBI、DataEase、FineBI、Tableau、Power BI、SuperSet 等,只要支持 MySQL 协议的 BI 工具,Doris 就可以作为数据源提供查询支持。
在 存储引擎 方面,Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
Doris 也支持比较丰富的索引结构,来减少数据的扫描:
- Sorted Compound Key Index:可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景。
- Z-order Index:使用
Z-order索引,可以高效对数据模型中的任意字段组合进行范围查询。 - Min/Max:有效过滤数值类型的等值和范围查询。
- Bloom Filter:对高基数列的等值过滤裁剪非常有效。
- Invert Index:能够对任意字段实现快速检索。
在存储模型方面,Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- Aggregate Key 模型:相同 Key 的 Value 列合并,通过提前聚合大幅提升性能。
- Unique Key 模型:Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新。
- Duplicate Key 模型:明细数据模型,满足事实表的明细存储。
Doris 也支持强一致的物化视图,物化视图的更新和选择都在系统内自动进行,不需要用户手动选择,从而大幅减少了物化视图维护的代价。
在 查询引擎 方面,Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。

Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD(Single Instruction Multiple Data,单指令多数据流)指令的效果。在宽表聚合场景下性能是非向量化引擎的 5 5 5 ~ 10 10 10 倍。
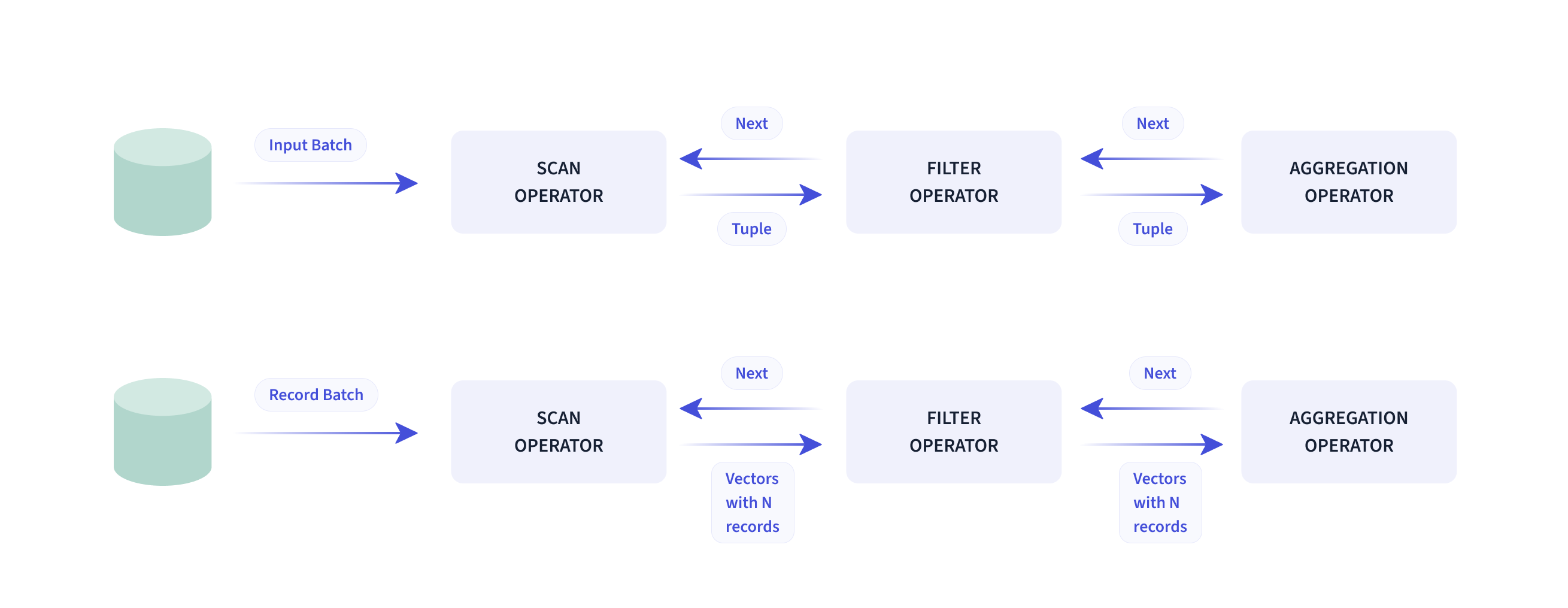
Doris 采用了 Adaptive Query Execution(自适应查询执行) 技术, 可以根据 Runtime Statistics 来动态调整执行计划,比如通过 Runtime Filter 技术能够在运行时生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。Doris 的 Runtime Filter 支持 In / Min / Max / Bloom Filter。
在 优化器 方面 Doris 使用 CBO(Rule-Based Optimizer)和 RBO(Cost-Based Optimizer)结合的优化策略,RBO 支持常量折叠、子查询改写、谓词下推等,CBO 支持 Join Reorder。目前 CBO 还在持续优化中,主要集中在更加精准的统计信息收集和推导,更加精准的代价模型预估等方面。
相关文章:
【大数据】Doris:基于 MPP 架构的高性能实时分析型数据库
Doris:基于 MPP 架构的高性能实时分析型数据库 1.Doris 介绍 Apache Doris 是一个基于 MPP(Massively Parallel Processing,大规模并行处理)架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知ÿ…...
【rust/egui】(五)看看template的app.rs:SidePanel、CentralPanel以及heading
说在前面 rust新手,egui没啥找到啥教程,这里自己记录下学习过程环境:windows11 22H2rust版本:rustc 1.71.1egui版本:0.22.0eframe版本:0.22.0上一篇:这里 SidePanel 侧边栏,如下图 …...

MTK6833_MT6833核心板_天玑700安卓5G核心板规格性能介绍
MTK6833安卓核心板采用台积电 7nm 制程的5G SoC,2*Cortex-A766*Cortex-A55架构,搭载Android12.0操作系统,主频最高达2.2GHz 。内置 5G 双载波聚合技术(2CC)及双 5G SIM 卡功能,实现优异的功耗表现及实时连网…...

Maven-Java代码格式化插件spring-javaformat
TOC 官方文档:点击进入 前言 项目研发过程中,随着团队人员的增加变更环境配置的不同,有些同学甚至没有格式化代码的习惯,导致编码风格不统一杂乱无章,为解决这一问题引入Spring提供的格式化代码插件。插件支持多种方…...

设计模式之八:模板方法模式
泡咖啡和泡茶的共同点: 把水煮沸沸水冲泡咖啡/茶叶冲泡后的水倒入杯子添加糖和牛奶/柠檬 class CoffeineBeverage { public:void prepareRecipe(){boilWater();brew();pourInCup();addCondiments();}private:void boilWater(){std::cout << "Boiling w…...

hive可以删除单条数据吗
参考: hive只操作几条数据特别慢 hive可以删除单条数据吗_柳随风的技术博客_51CTO博客...

python3-Flask实现Api接口
1、:python3-Flask实现Api接口_flask api_Shiro to kuro的博客-CSDN博客 2、 Flask框架的web开发01(Restful API接口规范)_flask patch post_~须尽欢的博客-CSDN博客...

微分享 - 超实用开发日常排查问题Linux运维命令
目录 CPUCPU基本信息CPU使用情况ps 命令可用于确定哪个进程占用了 CPU 内存free 网络查看端口curl 常用命令 文件df 、du 区别磁盘使用情况文件大小文件下载压缩&解压缩查找文件查找文件内容 进程CPU 使用来升序排序内存 使用升序排序 其他常用操作系统进本信息赋予文件执行…...
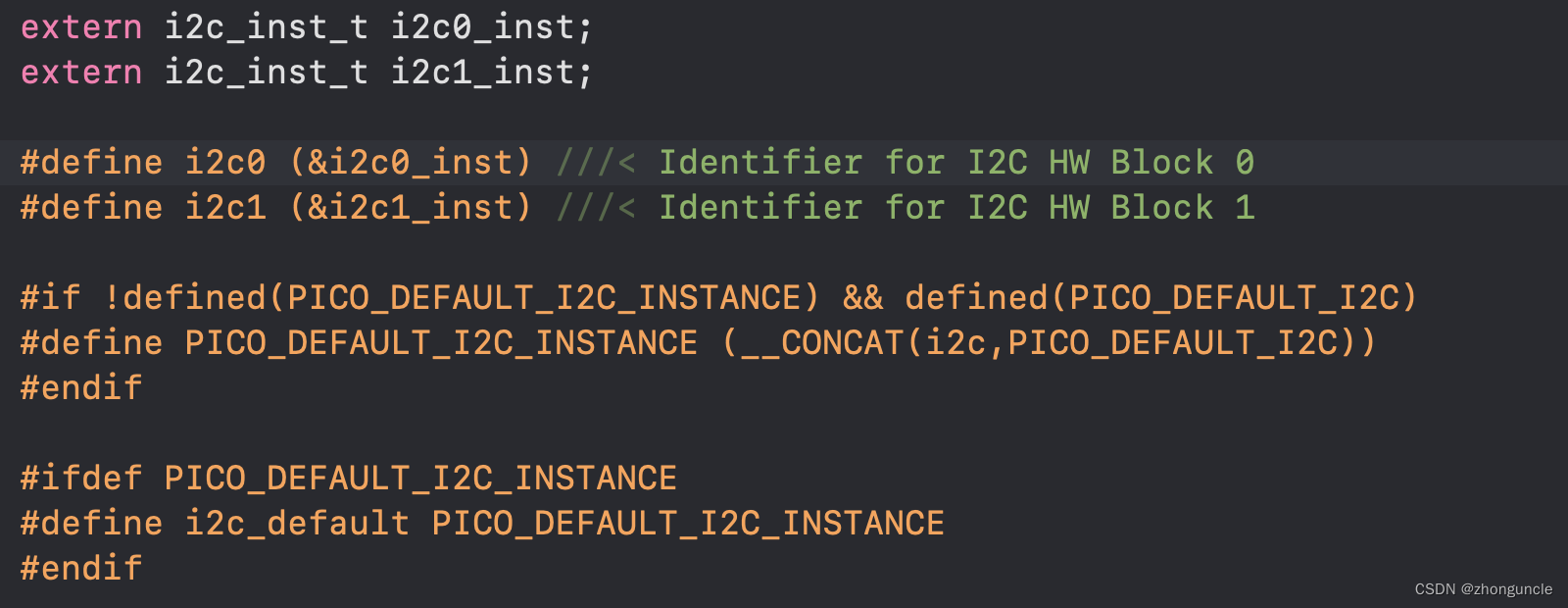
Pico如何使用C/C++选择哪个I2C控制器,以及SDA和SCL针脚
本文一开始讲述了解决方案,后面是我做的笔记,用来讲述我的发现流程和探究的 Pico I2C 代码结构。 前提知识 首先要说明一点:Pico 有两个 I2C,也就是两套 SDA 和 SCL。这点你可以在针脚图中名字看出,比如下图的 Pin 4…...
求生之路2私人服务器开服搭建教程centos
求生之路2私人服务器开服搭建教程centos 大家好我是艾西,朋友想玩求生之路2(left4dead2)重回经典。Steam玩起来有时候没有那么得劲,于是问我有没有可能自己搭建一个玩玩。今天跟大家分享的就是求生之路2的自己用服务器搭建的一个心路历程。 ࿰…...

Redis7之介绍(一)
1. 是什么 Redis:REmote Dictionary Server(远程字典服务器) Remote Dictionary Server( 远程字典服务)是完全开源的,使用ANSIC语言编写遵守BSD协议,是一个高性能的Key-Value数据库提供了丰富的数据结构,例如String、Hash、List、…...
基于Python+djangoAI 农作物病虫害预警系统智能识别系统设计与实现(源码&教程)
1.背景 随着科技的发展,机器学习技术在各个领域中的应用越来越广泛。在农业领域,机器学习技术的应用有助于提高农作物的产量和质量,降低农业生产的成本。本文针对农作物健康识别问题,提出一种基于机器学习方法的农作健康识别系统&…...

Kotlin Flow 转换以及上下游处理
本片文章主要介绍Flow上下游处理,上游一个Flow使用map,上游两个Flow使用zip,上游三个Flow及以上使用combine 1、下面代码展示了upStreamFlow作为上游,downStreamFlow作为下游,通过对upStreamFlow使用map操作符函数将…...
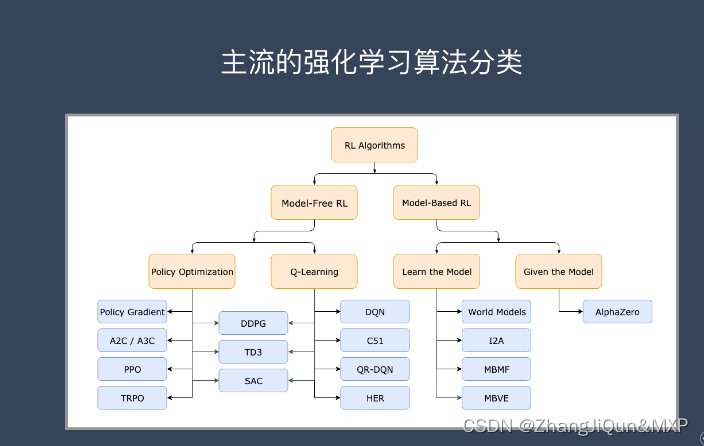
深度学习3. 强化学习-Reinforcement learning | RL
强化学习是机器学习的一种学习方式,它跟监督学习、无监督学习是对应的。本文将详细介绍强化学习的基本概念、应用场景和主流的强化学习算法及分类。 目录 什么是强化学习? 强化学习的应用场景 强化学习的主流算法 强化学习(reinforcement learning) …...

TCP/IP网络江湖武艺传承:物理层与通信江湖的幕后
目录 〇、引言:进入现代通信技术的江湖 一、数字信号与模拟信号:传承与差异...
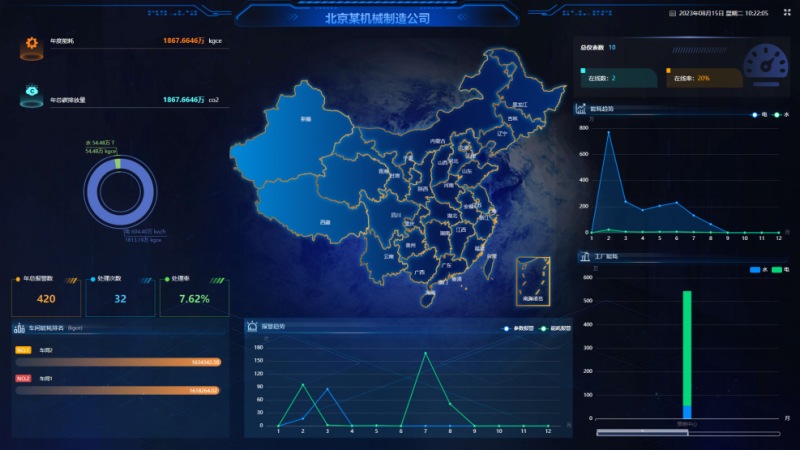
智慧能源管理系统助力某制造企业提高能源利用效率
随着全球能源需求不断增加和能源价格的上涨,企业和机构日益意识到能源管理的重要性。传统的能源管理方式不仅效率低下,还容易造成资源浪费和环境污染。因此,许多企业开始探索采用智慧能源管理系统来提高能源利用效率,降低能源成本…...
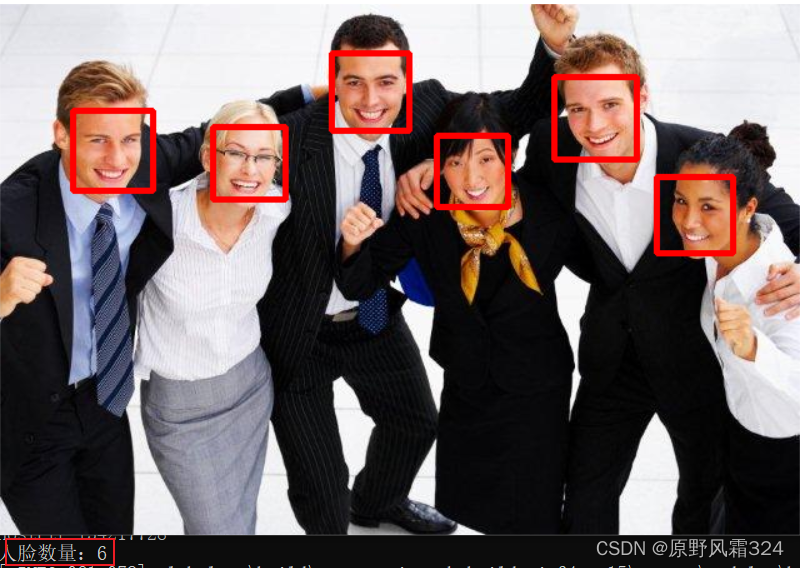
opencv/C++ 人脸检测
前言 本文使用的测试资源说明: opencv版本:opencv 4.6.0 人脸检测算法 Haar特征分类器 Haar特征分类器是一个XML文件,描述了人体各个部位的Haar特征值。包括:人脸、眼睛、鼻子、嘴等。 opencv 4.6.0自带的Haar特征分类器&…...
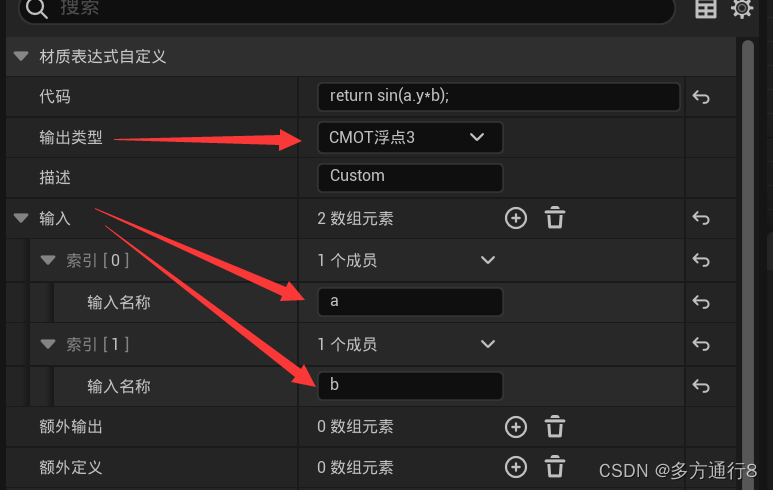
UE4/5的Custom节点:在VScode使用HLSL(新手入门用)
目录 custom节点 VSCode环境安装 将VSCode里面的代码放入Custom中 custom节点 可以看到这是一个简单的Custom节点: 而里面是可以填写代码的: 但是在这里面去写代码会发现十分的繁琐【按下enter后,不会换行,也不会自动缩进】 …...
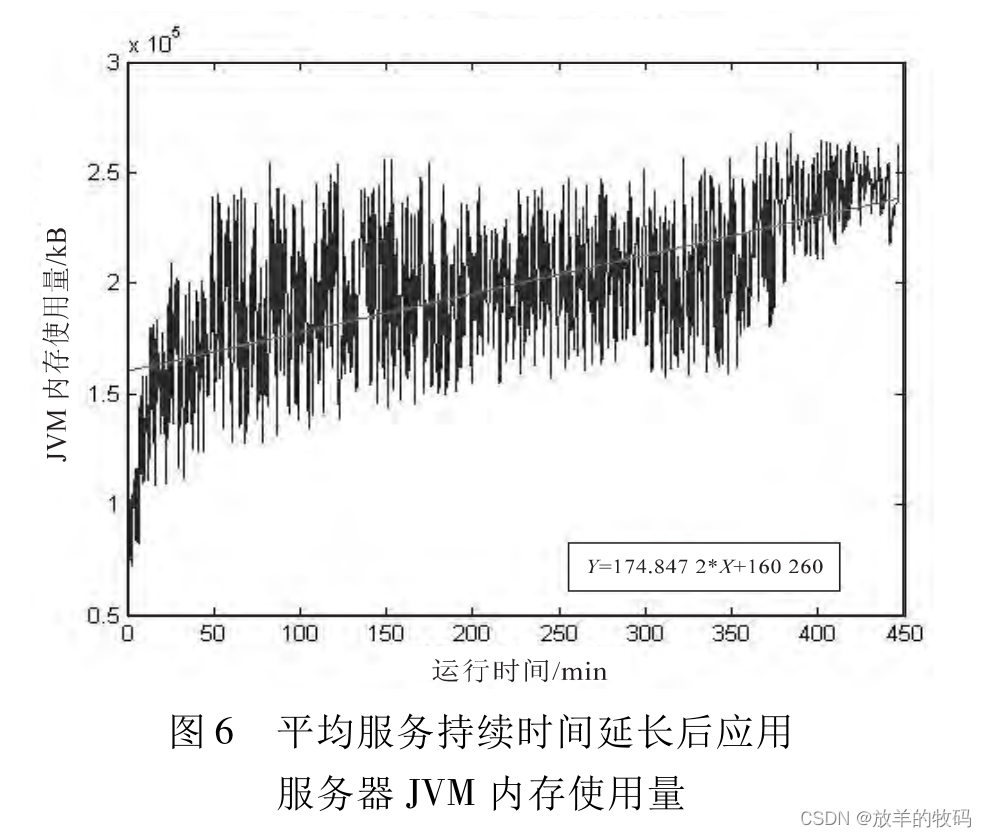
小研究 - J2EE 应用服务器的软件老化测试研究
软件老化现象是影响软件可靠性的重要因素,长期运行的软件系统存在软件老化现象,这将影响整个业务系统的正常运行,给企事业单位带来无可估量的经济损失。软件老化出现的主要原因是操作系统资源消耗殆尽,导致应用系统的性能下降甚至…...

Tomcat和Servlet基础知识的讲解(JavaEE初阶系列16)
目录 前言: 1.Tomcat 1.1Tomcat是什么 1.2下载安装 2.Servlet 2.1什么是Servlet 2.2使用Servlet来编写一个“hello world” 1.2.1创建项目(Maven) 1.2.2引入依赖(Servlet) 1.2.3创建目录(webapp&a…...

Ryujinx模拟器完整指南:在PC上免费畅玩Switch游戏的终极解决方案
Ryujinx模拟器完整指南:在PC上免费畅玩Switch游戏的终极解决方案 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾经梦想在电脑上体验《塞尔达传说:王国…...

基于Java的外卖点餐配送系统_43lq510m
目录 同行可拿货,招校园代理 ,本人源头供货商项目概述技术栈核心功能模块项目亮点部署方式学习价值 项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页--> 同行可拿货,招校园代理 ,本人源头供…...

Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112%
更多请点击: https://codechina.net 第一章:Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112% Lindy效应在流程自动化领域呈现显著反向特征:系统上线初期的效率跃升并非稳态…...

从开发者视角浅谈Taotoken用量看板对于日常调试与优化的辅助作用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从开发者视角浅谈Taotoken用量看板对于日常调试与优化的辅助作用 在日常开发工作中,当我们接入大模型API来构建智能功能…...

如何在Windows上让DualShock 3控制器重获新生?DsHidMini虚拟HID驱动技术解析
如何在Windows上让DualShock 3控制器重获新生?DsHidMini虚拟HID驱动技术解析 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 在Windows平台使用索…...

3步快速上手:Windows安卓应用安装器的终极指南
3步快速上手:Windows安卓应用安装器的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上直接运行安卓应用?告别…...

工业机器视觉工控机选型指南:从硬件配置到现场调试
1. 产品定位与核心价值解析在工业自动化领域,尤其是机器视觉应用场景中,稳定、可靠且性能强劲的硬件平台是整套系统能够7x24小时无间断运行的基石。朗锐智科推出的这款机器视觉工控机,从其核心配置来看,精准地瞄准了中高端视觉检测…...

网络资源嗅探与下载技术实践:res-downloader跨平台解决方案
网络资源嗅探与下载技术实践:res-downloader跨平台解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在当今…...

深入CPU内部:8086的MUL指令是如何工作的?从硬件视角理解乘法结果为何放在AX和DX
深入CPU内部:8086的MUL指令硬件实现原理全解析 记得第一次在调试器中单步执行MUL指令时,看到AX和DX寄存器突然被一堆十六进制数填满,那种既兴奋又困惑的感觉至今难忘。作为x86架构中最基础的乘法指令,MUL表面看似简单,…...

轨迹在线识别导向的3D折线焊缝机器人摆动GMAW实时跟踪系统【附程序】
✨ 长期致力于3D折线焊缝、机器人、GMAW、轨迹在线识别、焊缝跟踪研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于激光位移传感与密度聚类点云在线…...