11.注意力机制
11.注意力机制
目录
-
注意力提示
-
查询、键和值
-
注意力的可视化
-
-
注意力汇聚:Nadaraya-Watson 核回归
-
生成数据集
-
非参注意力池化层
- Nadaraya-Watson核回归
-
参数化的注意力机制
-
批量矩阵乘法
-
定义模型
-
训练
-
-
-
注意力评分函数
-
掩蔽softmax操作
-
加性注意力
-
缩放点积注意力
-
-
使用注意力机制的seq2seq
-
动机
-
加入注意力
-
定义注意力解码器
-
训练
-
总结
-
-
多头注意力
-
模型
-
实现
-
总结
-
-
有掩码的多头注意力
-
自注意力和位置编码
-
自注意力
-
比较卷积神经网络、循环神经网络和自注意力
-
位置编码
-
绝对位置信息
-
相对位置信息
-
-
总结
-
多头注意力和自注意力的区别
-
-
Transformer
-
模型
-
基于位置的前馈网络
-
残差连接和层规范化
-
编码器
-
信息传递
-
解码器
-
训练
-
预测
-
总结
-
注意力提示
在心理学上
- 动物需要在复杂环境下有效关注值得注意的点
- 心理学框架:人类根据随意线索和不随意线索选择注意点
查询、键和值
-
卷积、全连接、池化层都只考虑不随意线索
-
注意力机制则显示的考虑随意线索
随意线索被称为查询(query)
每个输入是一个值(value)和不随意线索(key)的对
通过注意力池化层来选择有偏向性的选择某些输入1
更通俗的解释,每个值都与一个_键_(key)配对, 这可以想象为感官输入的非自主提示。 如下图所示,可以通过设计注意力汇聚的方式, 便于给定的查询(自主性提示)与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。

然而,注意力机制的设计有许多替代方案。 例如可以设计一个不可微的注意力模型, 该模型可以使用强化学习方法 (Mnih et al., 2014)进行训练。
注意力的可视化
平均汇聚层可以被视为输入的加权平均值, 其中各输入的权重是一样的。 实际上,注意力汇聚得到的是加权平均的总和值, 其中权重是在给定的查询和不同的键之间计算得出的。
import torch
from d2l import torch as d2l
为了可视化注意力权重,需要定义一个show_heatmaps函数。 其输入matrices的形状是 (要显示的行数,要显示的列数,查询的数目,键的数目)。
#@save
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),cmap='Reds'):"""显示矩阵热图"""d2l.use_svg_display()num_rows, num_cols = matrices.shape[0], matrices.shape[1]fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,sharex=True, sharey=True, squeeze=False)for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)if i == num_rows - 1:ax.set_xlabel(xlabel)if j == 0:ax.set_ylabel(ylabel)if titles:ax.set_title(titles[j])fig.colorbar(pcm, ax=axes, shrink=0.6);
这段代码定义了一个名为show_heatmaps的函数,用于显示矩阵的热图。该函数的输入参数包括以下内容:
matrices:要显示的矩阵,可以是一个Tensor对象或一个由Tensor组成的列表,其中第一个维度表示行,第二个维度表示列。xlabel:热图的 x 轴标签。ylabel:热图的 y 轴标签。titles:一个列表,用于指定每列矩阵的标题,如果不指定则默认为空。figsize:一个二元组,用于指定图像的大小。cmap:一个字符串,表示使用的颜色映射。
该函数内部首先调用d2l.use_svg_display()函数,将绘制的图像格式设置为SVG格式,然后创建一个具有num_rows行和num_cols列的子图,其中每个子图将用于显示一个矩阵的热图。对于每个子图,使用ax.imshow()方法显示对应的矩阵,使用set_xlabel()和set_ylabel()方法分别设置x轴和y轴的标签,使用set_title()方法设置列标题。最后,使用fig.colorbar()方法添加一个颜色条。
注意,该函数使用了d2l模块中的函数和方法,例如d2l.use_svg_display()、d2l.plt.subplots()等。
下面使用一个简单的例子进行演示。 在本例子中,仅当查询和键相同时,注意力权重为1,否则为0。
attention_weights = torch.eye(10).reshape((1, 1, 10, 10))
show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')
这段代码生成一个10×1010\times1010×10的单位矩阵,然后将其变形为一个四维张量,大小为1×1×10×101\times1\times10\times101×1×10×10。接着,调用show_heatmaps函数将这个四维张量作为输入参数传递给它,并设置x轴标签为“Keys”,y轴标签为“Queries”。这将生成一个矩阵热图,其中每个位置的颜色表示对应位置的Query和Key之间的注意力权重。由于这里使用了单位矩阵作为输入,因此所有的权重值都为0或1,对应于Query和Key是否相等。
torch.eye(10)是一个PyTorch函数,用于创建一个10x10的单位矩阵。其中,单位矩阵是一个方阵,其对角线上的元素为1,其它元素均为0,例如:
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])注意力汇聚:Nadaraya-Watson 核回归
import torch
from torch import nn
from d2l import torch as d2l
生成数据集
简单起见,考虑下面这个回归问题: 给定的成对的“输入-输出”数据集 {(x1,y1),…,(xn,yn)}\{(x_1, y_1), \ldots, (x_n, y_n)\}{(x1,y1),…,(xn,yn)}, 如何学习fff来预测任意新输入xxx的输出y^=f(x)\hat{y} = f(x)y^=f(x)?
根据下面的非线性函数生成一个人工数据集, 其中加入的噪声项为ϵ\epsilonϵ:
yi=2sin(xi)+xi0.8+ϵy_i = 2\sin(x_i) + x_i^{0.8} + \epsilon yi=2sin(xi)+xi0.8+ϵ
其中ϵ\epsilonϵ服从均值为0和标准差为0.5的正态分布。 在这里生成了50个训练样本和50个测试样本。 为了更好地可视化之后的注意力模式,需要将训练样本进行排序。
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本def f(x):return 2 * torch.sin(x) + x**0.8y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test
这段代码用于生成一个用于回归问题的人工数据集。具体来说,该数据集基于以下步骤生成:
n_train = 50: 定义训练集大小为50。x_train, _ = torch.sort(torch.rand(n_train) * 5): 生成训练集输入x。首先,通过torch.rand(n_train)生成一个长度为n_train的随机数列。然后,通过* 5将随机数列中的每个元素乘以5。最后,通过torch.sort函数将x_train升序排列。由于我们只关心x_train,因此用一个占位符_存储sort函数的第二个返回值(即相应的排序索引)。def f(x): return 2 * torch.sin(x) + x**0.8: 定义一个目标函数,用于生成训练数据的标签(即输出y)以及测试数据的真实标签。该函数对输入x进行元素级别的计算,具体为:对每个x,先计算sin(x),再乘以2,最后加上x0.8x^{0.8}x0.8。可以将该函数视为一个需要学习的黑盒子函数。y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)): 为训练集生成标签y。具体来说,对于每个训练样本xix_ixi,我们首先通过目标函数fff计算出对应的真实标签yi=f(xi)y_i=f(x_i)yi=f(xi),然后通过torch.normal(0.0, 0.5, (n_train,))生成一个标准正态分布的噪声向量,最后将噪声向量加到yiy_iyi上,得到训练样本xix_ixi的标签yiy_iyi。x_test = torch.arange(0, 5, 0.1): 生成测试集输入x。通过torch.arange(0, 5, 0.1)生成一个从0到5,步长为0.1的等差数列。y_truth = f(x_test): 生成测试集的真实标签。通过目标函数fff计算每个测试样本xix_ixi的真实标签yiy_iyi。n_test = len(x_test): 定义测试集大小为测试样本x的长度。最后的输出为n_test,即测试样本的数量,这里的值为50。
50
下面的函数将绘制所有的训练样本(样本由圆圈表示), 不带噪声项的真实数据生成函数fff(标记为“Truth”), 以及学习得到的预测函数(标记为“Pred”)。
def plot_kernel_reg(y_hat):d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],xlim=[0, 5], ylim=[-1, 5])d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);
非参注意力池化层
- 给定数据$ \left(x_{i}, y_{i}\right), i=1, \ldots, n $
- 平均池化是最简单的方案:f(x)=1n∑iyif(x)=\frac{1}{n} \sum_{i} y_{i}f(x)=n1∑iyi
- 更好的方案是60年代提出来的Nadaraya-Watson核回归
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
这行代码的作用是生成一个预测结果张量 y_hat,长度为测试样本的个数 n_test。它的值是训练样本标签 y_train 的平均值,使用 torch.repeat_interleave 函数将其重复 n_test 次得到的。
这里之所以将 y_hat 的值设为训练样本标签的平均值,是因为这是一种最简单的预测方法。在模型训练之前,可以使用这种方法计算出一个预测值的基准,作为后续模型的表现评价标准之一。

Nadaraya-Watson核回归
使用高斯核
K(u)=12πexp(−u22)K(u)=\frac{1}{\sqrt{2 \pi}} \exp \left(-\frac{u^{2}}{2}\right) K(u)=2π1exp(−2u2)
得出
f(x)=∑i=1nexp(−12(x−xi)2)∑j=1nexp(−12(x−xj)2)yi=∑i=1nsoftmax(−12(x−xi)2)yi\begin{aligned} f(x) & =\sum_{i=1}^{n} \frac{\exp \left(-\frac{1}{2}\left(x-x_{i}\right)^{2}\right)}{\sum_{j=1}^{n} \exp \left(-\frac{1}{2}\left(x-x_{j}\right)^{2}\right)} y_{i} \\ & =\sum_{i=1}^{n} \operatorname{softmax}\left(-\frac{1}{2}\left(x-x_{i}\right)^{2}\right) y_{i}\end{aligned} f(x)=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
这段代码实现了一个简单的 kernel regression,基本思路是在测试样本上通过对训练样本的加权平均来预测标签。
具体而言,这里的核函数采用的是高斯核函数,它的形式为:k(x,z)=exp(−(x−z)22σ2)k(x,z) = \exp(-\frac{(x-z)^2}{2\sigma^2})k(x,z)=exp(−2σ2(x−z)2),其中 xxx 是测试样本,zzz 是训练样本。为了实现 kernel regression,我们需要首先计算出一个权重向量 www,它的每个元素是测试样本和训练样本之间距离的负平方。这里使用的距离度量方式是欧几里得距离。通过对权重向量进行 softmax 归一化,我们得到了一个注意力权重向量,它的每个元素是一个归一化的权重,用于计算加权平均。
为了在测试样本上预测标签,我们将注意力权重与训练样本的标签向量相乘,并对结果求和。这里使用的是矩阵乘法,它可以同时计算多个测试样本的预测结果。最后,使用可视化函数 plot_kernel_reg 将预测结果可视化。

现在来观察注意力的权重。 这里测试数据的输入相当于查询,而训练数据的输入相当于键。 因为两个输入都是经过排序的,因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs',ylabel='Sorted testing inputs')

参数化的注意力机制
在之前的基础上引入可以学习的www
f(x)=∑i=1nsoftmax(−12((x−xi)w)2)yif(x)=\sum_{i=1}^{n} \operatorname{softmax}\left(-\frac{1}{2}\left(\left(x-x_{i}\right) w\right)^{2}\right) y_{i} f(x)=i=1∑nsoftmax(−21((x−xi)w)2)yi
批量矩阵乘法
为了更有效地计算小批量数据的注意力, 我们可以利用深度学习开发框架中提供的批量矩阵乘法。
假设第一个小批量数据包含nnn个矩阵X1,…,Xn\mathbf{X}_1,\ldots, \mathbf{X}_nX1,…,Xn, 形状为a×ba\times ba×b, 第二个小批量包含nnn个矩阵Y1,…,Yn\mathbf{Y}_1, \ldots, \mathbf{Y}_nY1,…,Yn, 形状为b×cb\times cb×c。 它们的批量矩阵乘法得到nnn个矩阵 X1Y1,…,XnYn\mathbf{X}_1\mathbf{Y}_1, \ldots, \mathbf{X}_n\mathbf{Y}_nX1Y1,…,XnYn, 形状为a×ca\times ca×c。 因此,假定两个张量的形状分别是(n,a,b)(n,a,b)(n,a,b)和(n,b,c)(n,b,c)(n,b,c), 它们的批量矩阵乘法输出的形状为(n,a,c)(n,a,c)(n,a,c)。
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
torch.bmm(X, Y).shape
torch.Size([2, 1, 6])
这段代码中,首先定义了一个形状为 (2, 1, 4) 的三维张量 X 和一个形状为 (2, 4, 6) 的三维张量 Y。然后,调用 PyTorch 中的批量矩阵乘法函数 bmm 对 X 和 Y 进行批量矩阵乘法操作。因为 X 的最后一维长度为 4,Y 的倒数第二维长度为 4,所以这两个张量可以进行批量矩阵乘法。输出的形状为 (2, 1, 6)。其中,第一维是批量大小,第二维是 X 张量的第二维,第三维是 Y 张量的最后一维。因此,输出的第 i 个批量包含了 X 张量的第 i 个样本与 Y 张量的第 i 个样本的矩阵乘积。
torch.bmm 是 PyTorch 中的批量矩阵乘法函数,用于计算两个三维张量的批量矩阵乘积。具体来说,它接受两个张量 batch1 和 batch2,这两个张量的形状必须满足以下条件:
batch1的形状是(b, n, m),其中b是批量大小,n和m是两个维度的大小。batch2的形状是(b, m, p),其中b是批量大小,m和p是两个维度的大小。
torch.bmm(batch1, batch2) 的输出形状是 (b, n, p),其中每个输出张量的第 i 个批量表示的是 batch1[i] 和 batch2[i] 的矩阵乘积。
在注意力机制的背景中,我们可以使用小批量矩阵乘法来计算小批量数据中的加权平均值。
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
tensor([[[ 4.5000]],[[14.5000]]])
weights.unsqueeze(1)将形状为(2,10)的权重矩阵变形为(2,1,10),在第二个维度上添加一个维度。values.unsqueeze(-1)将形状为(2,10)的值矩阵变形为(2,10,1),在最后一个维度上添加一个维度。这样两个矩阵就可以相乘得到形状为(2,1,1)的结果,即对每个样本计算加权和。使用squeeze函数可以去掉结果中的多余维度。
具体地,weights.unsqueeze(1)和values.unsqueeze(-1)的结果分别为:
tensor([[[0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,0.1000, 0.1000]],[[0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000, 0.1000,0.1000, 0.1000]]])tensor([[[ 0.],[ 1.],[ 2.],[ 3.],[ 4.],[ 5.],[ 6.],[ 7.],[ 8.],[ 9.]],[[10.],[11.],[12.],[13.],[14.],[15.],[16.],[17.],[18.],[19.]]])定义模型
使用小批量矩阵乘法, 定义Nadaraya-Watson核回归的带参数版本为:
class NWKernelRegression(nn.Module):def __init__(self, **kwargs):super().__init__(**kwargs)self.w = nn.Parameter(torch.rand((1,), requires_grad=True))def forward(self, queries, keys, values):# queries和attention_weights的形状为(查询个数,“键-值”对个数)queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))self.attention_weights = nn.functional.softmax(-((queries - keys) * self.w)**2 / 2, dim=1)# values的形状为(查询个数,“键-值”对个数)return torch.bmm(self.attention_weights.unsqueeze(1),values.unsqueeze(-1)).reshape(-1)
这段代码定义了一个 PyTorch 模块 NWKernelRegression,该模块实现了使用 Nadaraya-Watson 核回归方法进行预测的功能。
该模块继承自 nn.Module,并重写了其中的 forward 方法,因此该模块可以被看作一个自定义的 PyTorch 模块,可以调用其实例对象的 forward 方法来进行预测。
在 __init__ 方法中,该模块定义了一个可学习参数 w,其形状为 (1,),该参数是核函数中的带宽,它将在模型训练过程中被学习。
接下来,该模块计算每个查询向量和每个“键-值”对的键向量之间的差值,将这些差值作为核函数的自变量,并将学习到的参数 w 作为核函数的带宽,计算核函数的值。具体来说,该模块将核函数的表达式写成了 exp(-((queries - keys) * w)**2 / 2),其中 ** 代表幂运算,exp 代表指数运算,- 代表取负运算,* 代表点乘运算。
然后,该模块对每个查询向量计算一个注意力权重向量,该注意力权重向量是所有“键-值”对的权重向量的加权平均,其中每个权重是一个核函数的值。具体来说,该模块使用 softmax 函数将每个核函数的值归一化得到概率分布,然后使用 bmm 函数(即批量矩阵乘法)将每个注意力权重向量和其对应的值向量相乘,并将结果加和得到预测值。最后,将预测值的形状从 (num_queries, 1) 改为 (num_queries,),并返回预测值
📌
repeat_interleave()是 PyTorch 的函数之一,用于将输入张量的每个元素重复一定的次数,并将重复后的结果沿着指定的维度展开。
训练
接下来,将训练数据集变换为键和值用于训练注意力模型。 在带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
- 创建一个形状为
(n_train, n_train-1)的张量keys,其中每一行都包含除自己以外的所有训练输入。具体来说,使用torch.eye方法创建一个形状为(n_train, n_train)的单位矩阵,然后使用(1 - ...)来将对角线上的元素变为 0,得到一个形状为(n_train, n_train)的张量。接着,使用type(torch.bool)将张量的元素类型转换为布尔类型,并使用索引器[]和reshape方法将其转换为形状为(n_train, n_train-1)的张量。 - 创建一个形状为
(n_train, n_train-1)的张量values,其中每一行都包含除自己以外的所有训练输出。具体来说,使用与keys相同的方式创建keys,但是使用Y_tile来获取训练输出,并使用reshape方法将其转换为形状为(n_train, n_train-1)的张量。
训练带参数的注意力汇聚模型时,使用平方损失函数和随机梯度下降。
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])for epoch in range(5):trainer.zero_grad()l = loss(net(x_train, keys, values), y_train)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')animator.add(epoch + 1, float(l.sum()))

如下所示,训练完带参数的注意力汇聚模型后可以发现: 在尝试拟合带噪声的训练数据时, 预测结果绘制的线不如之前非参数模型的平滑。
# keys的形状:(n_test,n_train),每一行包含着相同的训练输入(例如,相同的键)
keys = x_train.repeat((n_test, 1))
# value的形状:(n_test,n_train)
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)

为什么新的模型更不平滑了呢? 下面看一下输出结果的绘制图: 与非参数的注意力汇聚模型相比, 带参数的模型加入可学习的参数后, 曲线在注意力权重较大的区域变得更不平滑。
d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs',ylabel='Sorted testing inputs')

注意力评分函数
高斯核指数部分可以视为_注意力评分函数_(attention scoring function), 简称_评分函数_(scoring function), **然后把这个函数的输出结果输入到softmax函数中进行运算。 **通过上述步骤,将得到与键对应的值的概率分布(即注意力权重)。 最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。

从宏观来看,上述算法可以用来实现 注意力机制框架。 下图说明了 如何将注意力汇聚的输出计算成为值的加权和, 其中aaa表示注意力评分函数。 由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。

用数学语言描述,假设有一个查询$ \mathbf{q} \in \mathbb{R}^q $和 mmm个“键-值”对(k1,v1),…,(km,vm)(\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)(k1,v1),…,(km,vm), 其中ki∈Rk{k}_i \in \mathbb{R}^kki∈Rk,vi∈Rv\mathbf{v}_i \in \mathbb{R}^vvi∈Rv。 注意力汇聚函数fff就被表示成值的加权和:
f(q,(k1,v1),…,(km,vm))=∑i=1mα(q,ki)vi∈Rv,f(\mathbf{q}, (\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)) = \sum_{i=1}^m \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i \in \mathbb{R}^v, f(q,(k1,v1),…,(km,vm))=i=1∑mα(q,ki)vi∈Rv,
其中查询qqq和键ki\mathbf{k}_iki的注意力权重(标量) 是通过注意力评分函数aaa将两个向量映射成标量, 再经过softmax运算得到的:
α(q,ki)=softmax(a(q,ki))=exp(a(q,ki))∑j=1mexp(a(q,kj))∈R.\alpha(\mathbf{q}, \mathbf{k}_i) = \mathrm{softmax}(a(\mathbf{q}, \mathbf{k}_i)) = \frac{\exp(a(\mathbf{q}, \mathbf{k}_i))}{\sum_{j=1}^m \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}. α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))∈R.
正如上图所示,选择不同的注意力评分函数aaa会导致不同的注意力汇聚操作。 本节将介绍两个流行的评分函数,稍后将用他们来实现更复杂的注意力机制。
import math
import torch
from torch import nn
from d2l import torch as d2l
掩蔽softmax操作
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。** 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中**。 例如,为了高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。** 为了仅将有意义的词元作为值来获取注意力汇聚, 可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。** 下面的masked_softmax函数 实现了这样的_掩蔽softmax操作_(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
#@save
def masked_softmax(X, valid_lens):"""通过在最后一个轴上掩蔽元素来执行softmax操作"""# X:3D张量,valid_lens:1D或2D张量if valid_lens is None:return nn.functional.softmax(X, dim=-1)else:shape = X.shapeif valid_lens.dim() == 1:valid_lens = torch.repeat_interleave(valid_lens, shape[1])else:valid_lens = valid_lens.reshape(-1)# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,value=-1e6)return nn.functional.softmax(X.reshape(shape), dim=-1)
这段代码实现了一个能够在最后一个维度上掩蔽元素的 softmax 操作。其输入张量 X 可以是任意形状的 3D 张量。另一个参数 valid_lens 是一个 1D 或 2D 张量,指示了在每个样本序列中有多少个有效的元素。如果 valid_lens 是 1D 张量,则其长度应该和 X 张量的第二个维度一致。如果 valid_lens 是 2D 张量,则其形状应该和 X 张量的第一和第二个维度一致。
如果 valid_lens 为 None,则表示所有元素都是有效的,直接调用 PyTorch 的 softmax 函数实现 softmax。
如果 valid_lens 不为 None,则首先将 valid_lens 重复沿着最后一个维度(即特征维度)重复,以便可以在最后一个维度上与 X 张量相对应。然后,对于那些无效元素,用一个极大的负数(-1e6)来代替,这样 softmax 的输出就为 0。
📌
X.reshape(-1, shape[-1])将X沿着第 0 个轴上的所有元素展开,并将它们排成一个二维矩阵,矩阵的行数为-1,表示根据剩余的维度计算得到,矩阵的列数为shape[-1],表示最后一维上的元素个数。
最后,对于掩蔽后的张量,再调用 PyTorch 的 softmax 函数实现 softmax,并将其形状调整为 X 张量的形状。
为了演示此函数是如何工作的, 考虑由两个2×42 \times 42×4矩阵表示的样本, 这两个样本的有效长度分别为2和3。 经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
tensor([[[0.3313, 0.6687, 0.0000, 0.0000],[0.4467, 0.5533, 0.0000, 0.0000]],[[0.1959, 0.4221, 0.3820, 0.0000],[0.3976, 0.2466, 0.3558, 0.0000]]])
同样,也可以使用二维张量,为矩阵样本中的每一行指定有效长度。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],[0.3195, 0.2861, 0.3944, 0.0000]],[[0.4664, 0.5336, 0.0000, 0.0000],[0.2542, 0.2298, 0.1925, 0.3234]]])
加性注意力
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。 给定查询q∈Rq\mathbf{q} \in \mathbb{R}^qq∈Rq和 键k∈Rk\mathbf{k} \in \mathbb{R}^kk∈Rk, 加性注意力(additive attention)的评分函数为
a(q,k)=wv⊤tanh(Wqq+Wkk)∈R,a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R}, a(q,k)=wv⊤tanh(Wqq+Wkk)∈R,
其中可学习的参数是Wq∈Rh×q\mathbf W_q\in\mathbb R^{h\times q}Wq∈Rh×q、Wk∈Rh×k\mathbf W_k\in\mathbb R^{h\times k}Wk∈Rh×k和 wv∈Rh\mathbf w_v\in\mathbb R^{h}wv∈Rh。将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数ℎ。 通过使用tanh作为激活函数,并且禁用偏置项。
📌先把Wqq\mathbf W_q\mathbf qWqq和Wkk\mathbf W_k \mathbf kWkk分别相乘变成长为h的向量,在和wv⊤\mathbf w_v^\topwv⊤相乘变成一个标量,等价于将key和value合并起来后放入到一个隐藏大小为h输出大小为1的单隐藏层MLP
下面来实现加性注意力。
#@save
class AdditiveAttention(nn.Module):"""加性注意力"""def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.Linear(key_size, num_hiddens, bias=False)self.W_q = nn.Linear(query_size, num_hiddens, bias=False)self.w_v = nn.Linear(num_hiddens, 1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)# 在维度扩展后,# queries的形状:(batch_size,查询的个数,1,num_hidden)# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)# 使用广播方式进行求和features = queries.unsqueeze(2) + keys.unsqueeze(1)features = torch.tanh(features)# self.w_v仅有一个输出,因此从形状中移除最后那个维度。# scores的形状:(batch_size,查询的个数,“键-值”对的个数)scores = self.w_v(features).squeeze(-1)self.attention_weights = masked_softmax(scores, valid_lens)# values的形状:(batch_size,“键-值”对的个数,值的维度)return torch.bmm(self.dropout(self.attention_weights), values)
这是一个实现加性注意力的PyTorch模块。加性注意力是一种常见的注意力机制,在自然语言处理和语音识别等任务中被广泛使用。这个模块包含了几个线性层,其中包括 WkW_kWk,WqW_qWq 和 wvw_vwv。通过调用 forward 方法,传入 queriesqueriesqueries、keyskeyskeys 和 valuesvaluesvalues,以及 validlensvalidlensvalidlens,该模块会返回加性注意力的输出。
在 forward 方法中,通过调用 WqW_qWq 和 WkW_kWk 将输入 queriesqueriesqueries 和 keyskeyskeys 进行变换,然后**利用 PyTorch 的广播机制将它们相加,得到一个维度为 (batchsize,queriesnum,keysnum,numhiddens)(batchsize, queriesnum, keysnum, numhiddens)(batchsize,queriesnum,keysnum,numhiddens) 的张量 **featuresfeaturesfeatures。之后,通过应用双曲正切函数将 featuresfeaturesfeatures 中的元素压缩到 [−1,1][-1,1][−1,1] 的范围内。接着,将 featuresfeaturesfeatures 作为输入传递给 wvw_vwv,从而输出注意力得分 scoresscoresscores,它的形状为 (batchsize,queriesnum,keysnum)(batchsize, queriesnum, keysnum)(batchsize,queriesnum,keysnum)。注意力得分接下来通过调用 masked_softmax 方法来执行掩码 softmax 操作。最后,利用注意力权重和 valuesvaluesvalues 进行加权求和并返回注意力输出。注意力输出的形状为 (batchsize,queriesnum,valuedim)(batchsize, queriesnum, valuedim)(batchsize,queriesnum,valuedim),其中 valuedimvaluedimvaluedim 是 valuesvaluesvalues 的最后一个维度的大小。
用一个小例子来演示上面的AdditiveAttention类, 其中查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小), 实际输出为(2,1,20)、(2,10,2)和(2,10,4)。 注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)。
# (batchsize,querynum,querysize),(batchsize,keynum,keysize)
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens)
这个代码块使用了一个已经定义好的加性注意力模型,来计算给定的查询、键、值张量及有效长度张量的注意力加权和。
具体来说,代码中首先定义了两个查询张量、一个键张量和两个值张量。这些张量的形状如下所示:
- queries:(batchsize, querynum, querysize) = (2, 1, 20)
- keys:(batchsize, keynum, keysize) = (2, 10, 2)
- values:(batchsize, keynum, valsize) = (2, 10, 4)
接下来,调用 AdditiveAttention 类创建了一个 attention 对象,它的实例变量 self.attention_weights 记录了由注意力机制产生的注意力权重。
最后,代码通过 attention 对象调用 forward 方法来计算给定的查询、键、值张量及有效长度张量的注意力加权和。该方法的返回值是加权后的值张量。在这里,输出形状为:
- 输出:(batchsize, querynum, valsize) = (2, 1, 4)
这表示两个小批量数据分别包含了一个查询、10个键和10个值,且经过了注意力机制的加权,最终的输出是每个查询所对应的值。
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)
尽管加性注意力包含了可学习的参数,但由于本例子中每个键都是相同的, 所以注意力权重是均匀的,由指定的有效长度决定。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')

缩放点积注意力
使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度ddd。 假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为ddd。 为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 我们再将点积除以d\sqrt{d}d, 则缩放点积注意力(scaled dot-product attention)评分函数为:
a(q,k)=q⊤k/d.a(\mathbf q, \mathbf k) = \mathbf{q}^\top \mathbf{k} /\sqrt{d}. a(q,k)=q⊤k/d.
在实践中,我们通常从小批量的角度来考虑提高效率, 例如基于nnn个查询和mmm个键-值对计算注意力, 其中查询和键的长度为ddd,值的长度为vvv。 查询Q∈Rn×d\mathbf Q\in\mathbb R^{n\times d}Q∈Rn×d、 键K∈Rm×d\mathbf K\in\mathbb R^{m\times d}K∈Rm×d和 值V∈Rm×v\mathbf V\in\mathbb R^{m\times v}V∈Rm×v的缩放点积注意力是:
softmax(QK⊤d)V∈Rn×v.\mathrm{softmax}\left(\frac{\mathbf Q \mathbf K^\top }{\sqrt{d}}\right) \mathbf V \in \mathbb{R}^{n\times v}. softmax(dQK⊤)V∈Rn×v.

下面的缩放点积注意力的实现使用了暂退法进行模型正则化。
#@save
class DotProductAttention(nn.Module):"""缩放点积注意力"""def __init__(self, dropout, **kwargs):super(DotProductAttention, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)# queries的形状:(batch_size,查询的个数,d)# keys的形状:(batch_size,“键-值”对的个数,d)# values的形状:(batch_size,“键-值”对的个数,值的维度)# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)def forward(self, queries, keys, values, valid_lens=None):d = queries.shape[-1]# 设置transpose_b=True为了交换keys的最后两个维度scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)self.attention_weights = masked_softmax(scores, valid_lens)return torch.bmm(self.dropout(self.attention_weights), values)
这是一个实现缩放点积注意力机制的PyTorch模块,主要包括forward方法。它采用了torch.bmm函数来实现矩阵乘法,并对scores进行缩放,然后使用masked_softmax函数计算softmax权重,最后返回注意力加权值。函数的参数包括queries(查询张量)、keys(键张量)、values(值张量)和valid_lens(掩蔽无效项)。
为了演示上述的DotProductAttention类, 我们使用与先前加性注意力例子中相同的键、值和有效长度。 对于点积操作,我们令查询的特征维度与键的特征维度大小相同。
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],[[10.0000, 11.0000, 12.0000, 13.0000]]])
与加性注意力演示相同,由于键包含的是相同的元素, 而这些元素无法通过任何查询进行区分,因此获得了均匀的注意力权重。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')

总结
-
注意力分数是query和key的相似度,注意力权重是分数的softmax结果
-
两种常见的分数计算:
将query和key合并起来进入一个单输出单隐藏层的MLP
直接将query和key做内积
使用注意力机制的seq2seq
动机
- 机器翻译中,每个生成的词可能相关于源句子中不同的词
- seq2seq模型中不能对此直接建模
加入注意力

- 编码器对每次词的输出作为key和value(他们一样的)
- 解码器RNN对上一个词的输出是query
- 注意力的输出和下一个词的词嵌入合并进入
使用注意力机制的seq2seq的基本原理如下:
- 使用编码器对源序列进行编码,得到源序列的特征表示(context vector)。
- 初始化解码器的状态,将上一个时间步的解码器的输出和当前时间步的特征表示(context vector)作为注意力机制的输入,通过注意力机制得到新的上下文表示(context vector)。
- 将当前时间步的解码器的输入和新的上下文表示拼接起来,得到当前时间步的解码器的输入。
- 使用解码器对当前时间步的解码器的输入进行解码,得到当前时间步的输出。
- 重复步骤2-4,直到解码器输出终止符或者达到最大输出长度。
具体来说,使用注意力机制的seq2seq中的注意力机制,是将编码器的各个时间步的状态(hidden state)作为key和value,将上一个时间步的解码器的输出作为query,通过计算query和key之间的相似度,得到attention分数,再将attention分数经过softmax处理得到attention权重,最后将value和对应的attention权重加权求和得到新的上下文表示(context vector)。
通过这样的注意力机制,解码器可以更加关注编码器中与当前解码器状态相关的信息,从而提高翻译的准确性。
import torch
from torch import nn
from d2l import torch as d2l
定义注意力解码器
下面看看如何定义Bahdanau注意力,实现循环神经网络编码器-解码器。 其实,我们只需重新定义解码器即可。 为了更方便地显示学习的注意力权重, 以下AttentionDecoder类定义了带有注意力机制解码器的基本接口。
#@save
class AttentionDecoder(d2l.Decoder):"""带有注意力机制解码器的基本接口"""def __init__(self, **kwargs):super(AttentionDecoder, self).__init__(**kwargs)@propertydef attention_weights(self):raise NotImplementedError
这里定义了一个基于注意力机制的解码器的基本接口,但是没有具体实现。这个接口要求子类实现 attention_weights 属性来返回解码器在最后一次时间步的注意力权重,即 at′ta_{t' t}at′t,其中 t′t't′ 是输入序列的时间步,ttt 是输出序列的时间步。
接下来,让我们在接下来的Seq2SeqAttentionDecoder类中 实现带有Bahdanau注意力的循环神经网络解码器。 首先,初始化解码器的状态,需要下面的输入:
- 编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
- 上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
- 编码器有效长度(排除在注意力池中填充词元)。
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。 因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入。
class Seq2SeqAttentionDecoder(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)# 加了attentionself.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):# outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,num_hiddens)outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):# enc_outputs的形状为(batch_size,num_steps,num_hiddens).# hidden_state的形状为(num_layers,batch_size,# num_hiddens)enc_outputs, hidden_state, enc_valid_lens = state# 输出X的形状为(num_steps,batch_size,embed_size)X = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:# query的形状为(batch_size,1,num_hiddens)query = torch.unsqueeze(hidden_state[-1], dim=1) # 上一个时刻的最后一层的输出# context的形状为(batch_size,1,num_hiddens)context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)# 在特征维度上连结x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)# 将x变形为(1,batch_size,embed_size+num_hiddens)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights)# 没有经过全连接之前的outputs的形状为 (num_steps, batch_size, num_hiddens) # 全连接层变换后,outputs的形状为# (num_steps,batch_size,vocab_size)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,enc_valid_lens]@propertydef attention_weights(self):return self._attention_weights
这段代码实现了带有注意力机制的Seq2Seq模型的解码器,继承了基本接口类AttentionDecoder,包括了前向传播forward()和attention_weights()两个函数。下面是这段代码的详细分析:
- 在初始化时,实例化了一个AdditiveAttention的注意力对象attention,一个词嵌入对象embedding,一个GRU层rnn和一个全连接层dense。其中,AdditiveAttention的输入维度均为num_hiddens,通过dropout进行一定比例的节点删除,最终将输入特征映射到num_hiddens维的向量。词嵌入对象embedding将输入词的编号X映射成embed_size维的向量,GRU层rnn将embedding的输出和hidden_state连接在一起,作为当前时间步的输入。
- init_state()函数用于初始化状态。enc_outputs的形状为(batch_size,num_steps,num_hiddens),hidden_state的形状为(num_layers,batch_size,num_hiddens),将enc_outputs的第0个维度和第1个维度交换,hidden_state不需要处理。返回的是元组(outputs, hidden_state, enc_valid_lens)。
- forward()函数实现前向传播。X的形状为(num_steps,batch_size,embed_size),将其第0个维度和第1个维度交换,hidden_state是解码器的初始状态。遍历输入序列X,对于每个输入X[i],用当前hidden_state计算出query,用attention()函数计算出context,再将query和context连接在一起,作为当前时间步的输入,经过GRU层rnn计算出当前时间步的输出out,然后将其添加到outputs中。最后将outputs通过全连接层dense变换为(num_steps,batch_size,vocab_size)的输出张量,并将其第0个维度和第1个维度交换,返回该张量和新的状态[enc_outputs, hidden_state, enc_valid_lens]。
📌在
forward方法中,outputs是一个列表,包含了每个时间步的输出。每个时间步的输出out的形状为(1, batch_size, num_hiddens),将所有时间步的输出在时间维度上concat起来后,outputs的形状为(num_steps, batch_size, num_hiddens),其中num_steps为序列的长度。
- attention_weights()函数用于获取注意力权重,返回_attention_weights属性。
接下来,使用包含7个时间步的4个序列输入的小批量测试Bahdanau注意力解码器。
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([4, 16]))
训练
我们在这里指定超参数,实例化一个带有Bahdanau注意力的编码器和解码器, 并对这个模型进行机器翻译训练。 由于新增的注意力机制,训练要比没有注意力机制的慢得多。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.020, 5482.1 tokens/sec on cuda:0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4mMBlKZm-1676883573895)(image/image_j5ChvRsjFj.png)]
模型训练后,我们用它将几个英语句子翻译成法语并计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est riche ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((1, 1, -1, num_steps))
训练结束后,下面通过可视化注意力权重 会发现,每个查询都会在键值对上分配不同的权重,这说明 在每个解码步中,输入序列的不同部分被选择性地聚集在注意力池中。
# 加上一个包含序列结束词元
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')

总结
- 在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
- 在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值
多头注意力
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的ℎ组不同的 线性投影(linear projections)来变换查询、键和值。 然后,这ℎ组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这ℎ个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为_多头注意力_(multihead attention) (Vaswani et al., 2017)。 对于ℎ个注意力汇聚输出,每一个注意力汇聚都被称作一个_头_(head)。 下图展示了使用全连接层来实现可学习的线性变换的多头注意力。
- 对同一个key,value,query,希望抽取不同的信息,例如短距离关系和长距离关系
- 多头注意力使用h个独立的注意力池化,合并各个头(head)输出得到最终输出

模型
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。 给定查询q∈Rdq\mathbf{q} \in \mathbb{R}^{d_q}q∈Rdq、 键k∈Rdk\mathbf{k} \in \mathbb{R}^{d_k}k∈Rdk和 值$ \mathbf{v} \in \mathbb{R}^{d_v}
,每个注意力头, 每个注意力头,每个注意力头\mathbf{h}_i(((i = 1, \ldots, h$)的计算方法为:
hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,\mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v}, hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
其中,可学习的参数包括可学习的参数包括可学习的参数包括$ \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} 、、、 \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} 和和和\mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v},以及代表注意力汇聚的函数, 以及代表注意力汇聚的函数,以及代表注意力汇聚的函数f。。。f∗∗可以是加性注意力和缩放点积注意力∗∗。多头注意力的输出需要经过另一个线性转换,∗∗它对应着h个头连结后的结果,因此其可学习参数是∗∗**可以是加性注意力和缩放点积注意力**。 多头注意力的输出需要经过另一个线性转换, **它对应着ℎ个头连结后的结果,因此其可学习参数是 **∗∗可以是加性注意力和缩放点积注意力∗∗。多头注意力的输出需要经过另一个线性转换,∗∗它对应着h个头连结后的结果,因此其可学习参数是∗∗\mathbf W_o\in\mathbb R^{p_o\times h p_v}$:
Wo[h1⋮hh]∈Rpo.\begin{split}\mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}.\end{split} Woh1⋮hh∈Rpo.
基于这种设计,每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
import math
import torch
from torch import nn
from d2l import torch as d2l
实现
在实现过程中通常选择缩放点积注意力作为每一个注意力头。 为了避免计算代价和参数代价的大幅增长, 我们设定pq=pk=pv=po/hp_q = p_k = p_v = p_o / hpq=pk=pv=po/h。 值得注意的是,如果将查询、键和值的线性变换的输出数量设置为pqh=pkh=pvh=pop_q h = p_k h = p_v h = p_opqh=pkh=pvh=po, 则可以并行计算ℎ个头。 在下面的实现中,pop_opo是通过参数num_hiddens指定的。
#@save
class MultiHeadAttention(nn.Module):"""多头注意力"""def __init__(self, key_size, query_size, value_size, num_hiddens,num_heads, dropout, bias=False, **kwargs):super(MultiHeadAttention, self).__init__(**kwargs)self.num_heads = num_headsself.attention = d2l.DotProductAttention(dropout) # 没有学习w,相对来说简单self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward(self, queries, keys, values, valid_lens):# queries,keys,values的形状:# (batch_size,查询或者“键-值”对的个数,num_hiddens)# valid_lens 的形状:# (batch_size,)或(batch_size,查询的个数)# 经过变换后,输出的queries,keys,values 的形状:# (batch_size*num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)queries = transpose_qkv(self.W_q(queries), self.num_heads)keys = transpose_qkv(self.W_k(keys), self.num_heads)values = transpose_qkv(self.W_v(values), self.num_heads)if valid_lens is not None:# 在轴0,将第一项(标量或者矢量)复制num_heads次,# 然后如此复制第二项,然后诸如此类。valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)# output的形状:(batch_size*num_heads,查询的个数,num_hiddens/num_heads)output = self.attention(queries, keys, values, valid_lens)# output_concat的形状:(batch_size,查询的个数,num_hiddens)output_concat = transpose_output(output, self.num_heads)return self.W_o(output_concat)
这是一个实现多头注意力的 PyTorch 模块。
__init__方法初始化多头注意力的参数,包括查询向量的维度、键向量的维度、值向量的维度、隐藏状态的维度、头数、dropout 参数等,以及初始化四个线性层:W_q用于查询向量映射到隐藏状态,W_k用于将键向量映射到隐藏状态,W_v用于将值向量映射到隐藏状态,W_o用于将拼接好的多头注意力的结果映射到隐藏状态。forward方法实现多头注意力,包括将查询、键和值向量分别通过线性层映射到多头注意力的隐藏状态上,然后通过transpose_qkv将第二个维度变成两个维度,即头数和num_hiddens/num_heads。接着调用DotProductAttention模块实现多头注意力,并通过transpose_output将多头注意力的结果中的头数和num_hiddens/num_heads这两个维度合并为一个维度。最后将输出通过线性层W_o映射到隐藏状态。
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
#@save
def transpose_qkv(X, num_heads):"""为了多注意力头的并行计算而变换形状"""# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)X = X.permute(0, 2, 1, 3)# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)return X.reshape(-1, X.shape[2], X.shape[3])#@save
def transpose_output(X, num_heads):"""逆转transpose_qkv函数的操作"""# 逆转变成三维X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)
这两个函数是为了多头注意力机制的实现而写的。在多头注意力机制中,我们需要将原始的查询、键、值矩阵进行线性变换,以得到多组新的查询、键、值矩阵,然后对这些矩阵分别进行注意力池化操作,最终将结果拼接在一起返回。
其中,transpose_qkv函数对输入的X矩阵进行形状变换,将其变为(batch_size_num_heads, 查询或者“键-值”对的个数, num_hiddens/num_heads)的形状,其中,num_heads是多头注意力机制中使用的注意力头的个数。具体实现中,我们首先将输入矩阵X的形状从(batch_size, 查询或者“键-值”对的个数, num_hiddens)变为(batch_size, 查询或者“键-值”对的个数, num_heads, num_hiddens/num_heads)的形状,然后将第2个维度和第3个维度交换,最终得到(batch_size_num_heads, 查询或者“键-值”对的个数, num_hiddens/num_heads)的形状的输出。
transpose_output函数是对transpose_qkv函数的逆操作。在拼接多头注意力机制的结果时,我们需要将多个注意力头的结果拼接在一起,这时就需要将多个头的输出进行形状变换,最终将(batch_size*num_heads, 查询或者“键-值”对的个数, num_hiddens/num_heads)的形状的结果变为(batch_size, 查询或者“键-值”对的个数, num_hiddens)的形状。
下面使用键和值相同的小例子来测试我们编写的MultiHeadAttention类。 多头注意力输出的形状是(batch_size,num_queries,num_hiddens)。
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention((attention): DotProductAttention((dropout): Dropout(p=0.5, inplace=False))(W_q): Linear(in_features=100, out_features=100, bias=False)(W_k): Linear(in_features=100, out_features=100, bias=False)(W_v): Linear(in_features=100, out_features=100, bias=False)(W_o): Linear(in_features=100, out_features=100, bias=False)
)
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
torch.Size([2, 4, 100])
总结
- 多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
- 基于适当的张量操作,可以实现多头注意力的并行计算。
有掩码的多头注意力
有掩码的多头注意力(Masked Multi-Head Attention)是一种用于自注意力机制的变体,它在计算注意力权重时可以屏蔽掉一些不合法的位置,以避免模型利用无效的位置信息进行计算。
多头注意力机制是一种用于序列建模的机制,它通过计算一个查询序列与一组键值对之间的注意力权重,来对序列中每个位置进行建模。在有掩码的多头注意力中,对于某些位置,我们可能希望将其屏蔽掉,例如在处理自然语言语句时,为了避免模型利用未来的信息进行计算,我们需要将当前位置之后的所有位置都屏蔽掉。
有掩码的多头注意力的原理是在计算注意力权重时,将掩码矩阵与查询序列中的每个位置对应相乘,从而将不合法的位置的注意力权重置为一个极小的值,使得模型不会利用这些位置的信息进行计算。然后再按照通常的多头注意力的方法进行计算,即将键值对乘以注意力权重,然后将所有结果相加得到最终的输出。
在实际应用中,有掩码的多头注意力常常用于序列到序列(seq2seq)模型中的编码器和解码器中,以确保模型在预测未来序列时不会利用未来信息。
- 解码器对序列中一个元素输出时,不应该考虑该元素之后的元素
- 可以通过掩码来实现也就是计算xix_ixi输出时,假装当前序列长度为iii
在使用序列到序列(seq2seq)模型进行预测时,通常需要对序列中的每个元素进行逐一预测。对于解码器来说,每次预测时,它只能看到输入序列和先前预测的输出序列,而不能看到未来的元素。因此,在预测第iii个元素时,应该忽略第iii个元素之后的元素,这样可以确保模型不会在预测过程中使用未来的信息。
一种常用的方法是使用掩码(masking)来屏蔽掉解码器中未来的信息。具体来说,可以使用一个掩码向量,将当前位置之后的所有位置都屏蔽掉,以确保在计算第iii个元素的输出时,只能看到前面的元素。
对于一个长度为nnn的序列,如果要预测第iii个元素的输出,可以将掩码向量定义为一个长度为nnn的二元向量,其中第jjj个元素为0表示该位置不应该被考虑,第jjj个元素为1表示该位置可以被考虑。在计算第iii个元素的输出时,将掩码向量的前iii个元素设为1,后面的元素设为0,这样就可以将当前序列长度视为iii进行计算,从而忽略掉第iii个元素之后的元素。
通过使用掩码来屏蔽未来的信息,可以确保模型不会在预测时使用未来的信息,同时还可以提高模型的预测精度。
自注意力和位置编码
在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。 想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中, 以便同一组词元同时充当查询、键和值。 具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。 由于查询、键和值来自同一组输入,因此被称为 自注意力(self-attention) (Lin et al., 2017, Vaswani et al., 2017), 也被称为_内部注意力_(intra-attention) (Cheng et al., 2016, Parikh et al., 2016, Paulus et al., 2017)。 本节将使用自注意力进行序列编码,以及如何使用序列的顺序作为补充信息。
import math
import torch
from torch import nn
from d2l import torch as d2l
自注意力
给定一个由词元组成的输入序列x1,…,xn\mathbf{x}_1, \ldots, \mathbf{x}_nx1,…,xn, 其中任意xi∈Rd\mathbf{x}_i \in \mathbb{R}^dxi∈Rd(1≤i≤n1 \leq i \leq n1≤i≤n)。 该序列的自注意力输出为一个长度相同的序列 y1,…,yn\mathbf{y}_1, \ldots, \mathbf{y}_ny1,…,yn,其中:
yi=f(xi,(x1,x1),…,(xn,xn))∈Rd\mathbf{y}_i = f(\mathbf{x}_i, (\mathbf{x}_1, \mathbf{x}_1), \ldots, (\mathbf{x}_n, \mathbf{x}_n)) \in \mathbb{R}^d yi=f(xi,(x1,x1),…,(xn,xn))∈Rd
📌自注意力池化层将xi\mathbf{x}_ixi当作key,value,query来对序列抽取特征得到y1,…,yn\mathbf{y}_1, \ldots, \mathbf{y}_ny1,…,yn
根据定义的注意力汇聚函数fff。 下面的代码片段是基于多头注意力对一个张量完成自注意力的计算, 张量的形状为(批量大小,时间步的数目或词元序列的长度,ddd)。 输出与输入的张量形状相同。

num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention((attention): DotProductAttention((dropout): Dropout(p=0.5, inplace=False))(W_q): Linear(in_features=100, out_features=100, bias=False)(W_k): Linear(in_features=100, out_features=100, bias=False)(W_v): Linear(in_features=100, out_features=100, bias=False)(W_o): Linear(in_features=100, out_features=100, bias=False)
)batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
torch.Size([2, 4, 100])
比较卷积神经网络、循环神经网络和自注意力
接下来比较下面几个架构,目标都是将由nnn个词元组成的序列映射到另一个长度相等的序列,其中的每个输入词元或输出词元都由ddd维向量表示。具体来说,将比较的是卷积神经网络、循环神经网络和自注意力这几个架构的计算复杂性、顺序操作和最大路径长度。请注意,顺序操作会妨碍并行计算,而任意的序列位置组合之间的路径越短,则能更轻松地学习序列中的远距离依赖关系 (Hochreiter et al., 2001)。


考虑一个卷积核大小为kkk的卷积层。 在后面的章节将提供关于使用卷积神经网络处理序列的更多详细信息。 目前只需要知道的是,由于序列长度是nnn,输入和输出的通道数量都是ddd, 所以卷积层的计算复杂度为O(knd2)\mathcal{O}(knd^2)O(knd2)。 如上图所示, 卷积神经网络是分层的,因此为有O(1)\mathcal{O}(1)O(1)个顺序操作, 最大路径长度为O(n/k)\mathcal{O}(n/k)O(n/k)。 例如,x1\mathbf{x}_1x1和x5\mathbf{x}_5x5处于上图中卷积核大小为3的双层卷积神经网络的感受野内。
当更新循环神经网络的隐状态时, d×dd \times dd×d权重矩阵和ddd维隐状态的乘法计算复杂度为O(d2)\mathcal{O}(d^2)O(d2)。 由于序列长度为nnn,因此循环神经网络层的计算复杂度为O(nd2)\mathcal{O}(nd^2)O(nd2)。 根据上图, 有O(n)\mathcal{O}(n)O(n)个顺序操作无法并行化,最大路径长度也是O(n)\mathcal{O}(n)O(n)。
在自注意力中,查询、键和值都是n×dn \times dn×d矩阵。 考虑缩放的”点-积“注意力, 其中n×dn \times dn×d矩阵乘以d×nd \times nd×n矩阵。 之后输出的n×nn \times nn×n矩阵乘以n×dn \times dn×d矩阵。 因此,自注意力具有O(n2d)\mathcal{O}(n^2d)O(n2d)计算复杂性。 正如在上图中所讲, 每个词元都通过自注意力直接连接到任何其他词元。 因此,有O(1)\mathcal{O}(1)O(1)个顺序操作可以并行计算, 最大路径长度也是O(1)\mathcal{O}(1)O(1)。
总而言之,卷积神经网络和自注意力都拥有并行计算的优势, 而且自注意力的最大路径长度最短。 但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。 为了使用序列的顺序信息,通过在输入表示中添加 位置编码(positional encoding)来注入绝对的或相对的位置信息。 位置编码可以通过学习得到也可以直接固定得到。 接下来描述的是基于正弦函数和余弦函数的固定位置编码 (Vaswani et al., 2017)。
📌跟CNN/RNN不同,自注意力并没有记录位置信息,通过位置编码将位置信息注入到输入中
假设输入表示X∈Rn×d\mathbf{X} \in \mathbb{R}^{n \times d}X∈Rn×d包含一个序列中nnn个词 元的ddd维嵌入表示。 **位置编码使用相同形状的位置嵌入矩阵 **P∈Rn×d\mathbf{P} \in \mathbb{R}^{n \times d}P∈Rn×d输出X+P\mathbf{X} + \mathbf{P}X+P, 矩阵第iii行、第2j2j2j列和2j+12j+12j+1列上的元素为:
pi,2j=sin(i100002j/d),pi,2j+1=cos(i100002j/d).\begin{split}\begin{aligned} p_{i, 2j} &= \sin\left(\frac{i}{10000^{2j/d}}\right),\\p_{i, 2j+1} &= \cos\left(\frac{i}{10000^{2j/d}}\right).\end{aligned}\end{split} pi,2jpi,2j+1=sin(100002j/di),=cos(100002j/di).
乍一看,这种基于三角函数的设计看起来很奇怪。 在解释这个设计之前,让我们先在下面的PositionalEncoding类中实现它。
#@save
class PositionalEncoding(nn.Module):"""位置编码"""def __init__(self, num_hiddens, dropout, max_len=1000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(dropout)# 创建一个足够长的Pself.P = torch.zeros((1, max_len, num_hiddens)) # batchsize=1X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)self.P[:, :, 0::2] = torch.sin(X)self.P[:, :, 1::2] = torch.cos(X)def forward(self, X):X = X + self.P[:, :X.shape[1], :].to(X.device)return self.dropout(X)
在位置嵌入矩阵P\mathbf{P}P中, 行代表词元在序列中的位置,列代表位置编码的不同维度。, 从下面的例子中可以看到位置嵌入矩阵的第6列和第7列的频率高于第8列和第9列。 第6列和第7列之间的偏移量(第8列和第9列相同)是由于正弦函数和余弦函数的交替。
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])

绝对位置信息
为了明白沿着编码维度单调降低的频率与绝对位置信息的关系, 让我们打印出0,1,…,70, 1, \ldots, 70,1,…,7的二进制表示形式。 正如所看到的,每个数字、每两个数字和每四个数字上的比特值 在第一个最低位、第二个最低位和第三个最低位上分别交替。
for i in range(8):print(f'{i}的二进制是:{i:>03b}')
0的二进制是:000
1的二进制是:001
2的二进制是:010
3的二进制是:011
4的二进制是:100
5的二进制是:101
6的二进制是:110
7的二进制是:111
在二进制表示中,较高比特位的交替频率低于较低比特位, 与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间
P = P[0, :, :].unsqueeze(0).unsqueeze(0)
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)',ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')

相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。 这是因为对于任何确定的位置偏移δ\deltaδ,位置i+δi + \deltai+δ处 的位置编码可以线性投影位置iii处的位置编码来表示。
这种投影的数学解释是,令ωj=1/100002j/d\omega_j = 1/10000^{2j/d}ωj=1/100002j/d, 对于任何确定的位置偏移δ\deltaδ,任何一对$ (p_{i, 2j}, p_{i, 2j+1}) $都可以线性投影到 (pi+δ,2j,pi+δ,2j+1)(p_{i+\delta, 2j}, p_{i+\delta, 2j+1})(pi+δ,2j,pi+δ,2j+1):
[cos(δωj)sin(δωj)−sin(δωj)cos(δωj)][pi,2jpi,2j+1]=[cos(δωj)sin(iωj)+sin(δωj)cos(iωj)−sin(δωj)sin(iωj)+cos(δωj)cos(iωj)]=[sin((i+δ)ωj)cos((i+δ)ωj)]=[pi+δ,2jpi+δ,2j+1],\begin{split}\begin{aligned} &\begin{bmatrix} \cos(\delta \omega_j) & \sin(\delta \omega_j) \\ -\sin(\delta \omega_j) & \cos(\delta \omega_j) \\ \end{bmatrix} \begin{bmatrix} p_{i, 2j} \\ p_{i, 2j+1} \\ \end{bmatrix}\\ =&\begin{bmatrix} \cos(\delta \omega_j) \sin(i \omega_j) + \sin(\delta \omega_j) \cos(i \omega_j) \\ -\sin(\delta \omega_j) \sin(i \omega_j) + \cos(\delta \omega_j) \cos(i \omega_j) \\ \end{bmatrix}\\ =&\begin{bmatrix} \sin\left((i+\delta) \omega_j\right) \\ \cos\left((i+\delta) \omega_j\right) \\ \end{bmatrix}\\ =& \begin{bmatrix} p_{i+\delta, 2j} \\ p_{i+\delta, 2j+1} \\ \end{bmatrix}, \end{aligned}\end{split} ===[cos(δωj)−sin(δωj)sin(δωj)cos(δωj)][pi,2jpi,2j+1][cos(δωj)sin(iωj)+sin(δωj)cos(iωj)−sin(δωj)sin(iωj)+cos(δωj)cos(iωj)][sin((i+δ)ωj)cos((i+δ)ωj)][pi+δ,2jpi+δ,2j+1],
2×2投影矩阵不依赖于任何位置的索引iii。
投影矩阵和i无关
总结
- 在自注意力中,查询、键和值都来自同一组输入。
- 卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
- 为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。
多头注意力和自注意力的区别
多头注意力和自注意力是自注意力模型中的两个关键组件,它们都使用注意力机制来捕捉输入序列的不同部分之间的关系。它们的区别在于,自注意力用于对一个输入序列内的元素之间建立关联,而多头注意力用于对不同位置或不同表示空间之间的元素之间建立关联。
📌自注意力(Self-Attention)机制是一种可以捕捉序列内元素之间依赖关系的机制,它可以通过计算元素之间的相似度得到一个注意力分布,从而对序列中的每个元素进行加权求和。在自注意力中,每个元素都与序列中的其他元素计算注意力,从而捕捉元素之间的关系。自注意力在序列到序列的翻译任务和语言模型中被广泛使用,例如Transformer模型。
📌多头注意力(Multi-Head Attention)是一种可以捕捉序列中不同部分之间关系的机制,它将一个输入序列分别映射到多个不同的表示空间,并在每个表示空间中进行自注意力操作。具体来说,**多头注意力将输入序列通过多个不同的线性变换映射到不同的表示空间,然后对每个表示空间进行自注意力操作,最后将所有的表示空间进行拼接和线性变换得到最终的输出。**多头注意力可以捕捉输入序列中不同部分之间的复杂关系,从而提高模型的表现。在Transformer模型中,多头注意力被广泛应用于编码器和解码器中。
总之,自注意力是用于序列内部元素之间的关系建模,而多头注意力是用于不同位置或不同表示空间之间的关系建模。两种注意力机制都可以提高模型的表现,它们经常在深度学习模型中被使用。
Transformer
上节中比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。对比之前仍然依赖循环神经网络实现输入表示的自注意力模型 (Cheng et al., 2016, Lin et al., 2017, Paulus et al., 2017),Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层 (Vaswani et al., 2017)。尽管Transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
模型
Transformer作为编码器-解码器架构的一个实例,其整体架构图在下图中展示。正如所见到的,Transformer是由编码器和解码器组成的。与之前的基于Bahdanau注意力实现的序列到序列的学习相比,Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的_嵌入_(embedding)表示将加上_位置编码_(positional encoding),再分别输入到编码器和解码器中。

上图概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是_多头自注意力_(multi-head self-attention)汇聚;第二个子层是_基于位置的前馈网络_(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受 残差网络的启发,每个子层都采用了_残差连接_(residual connection)。在Transformer中,对于序列中任何位置的任何输入x∈Rd\mathbf{x} \in \mathbb{R}^dx∈Rd,都要求满足sublayer(x)∈Rd\mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^dsublayer(x)∈Rd,以便残差连接满足x+sublayer(x)∈Rd\mathbf{x} + \mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^dx+sublayer(x)∈Rd。在残差连接的加法计算之后,紧接着应用_层规范化_(layer normalization) (Ba et al., 2016)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个ddd维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为_编码器-解码器注意力_(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种_掩蔽_(masked)注意力保留了_自回归_(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是_基于位置的_(positionwise)的原因。
在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
具体来说,多头注意力中的位置前馈网络的操作步骤如下:
- 将输入形状由(b,n,d)变换成(bn,d),即将每个位置的向量展平成一个一维向量,其中 b 是 batch size,n 是序列长度,d 是向量维度。
- 作用两个全连接层。第一个全连接层将每个向量映射到一个更高维的中间特征空间,第二个全连接层将中间特征向量映射回原始特征空间。这两个全连接层都是线性变换加上一个非线性激活函数。
- 将输出形状由(bn,d)变换为(b,n,d),即将每个一维向量重新还原成原始的向量形状。
基于位置的前馈网络(Position-wise Feedforward Network)是序列到序列(seq2seq)模型中常用的一种网络结构,用于对序列中每个位置的特征进行非线性变换和映射,从而改善模型的表达能力。
基于位置的前馈网络的原理是在每个位置上应用一个相同的全连接前馈神经网络,将该位置的特征向量映射到一个新的特征空间中。在该网络中,每个位置都有自己的一组参数,这些参数是独立学习的,因此网络可以灵活地对不同位置的特征进行不同的变换。
具体来说,对于一个长度为nnn的序列,基于位置的前馈网络将序列中的每个位置的特征向量表示为一个ddd维向量xi\mathbf{x}_ixi,其中iii表示序列中的位置。然后,基于位置的前馈网络应用一个非线性变换来对每个位置的特征向量进行映射,计算公式如下:
FFN(xi)=max(0,xiW1+b1)W2+b2\mathrm{FFN}(\mathbf{x}_i) = \max(0, \mathbf{x}_i \mathbf{W}_1 + \mathbf{b}_1) \mathbf{W}_2 + \mathbf{b}_2 FFN(xi)=max(0,xiW1+b1)W2+b2
其中,W1\mathbf{W}_1W1和W2\mathbf{W}_2W2是两个参数矩阵,分别用于将输入特征向量映射到一个更高维的中间特征空间和将中间特征向量映射回原始特征空间;b1\mathbf{b}_1b1和b2\mathbf{b}_2b2分别是两个偏置向量,用于增加网络的表达能力;max(0,⋅)\max(0, \cdot)max(0,⋅)表示ReLU激活函数,用于引入非线性变换。
基于位置的前馈网络通过引入非线性变换,可以帮助模型更好地捕捉序列中的局部特征,提高模型的表达能力。同时,由于基于位置的前馈网络对每个位置都应用了相同的变换,因此可以加速模型的训练和推理过程,提高模型的效率。
#@save
class PositionWiseFFN(nn.Module):"""基于位置的前馈网络"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):return self.dense2(self.relu(self.dense1(X)))
下面的例子显示,改变张量的最里层维度的尺寸,会改变成基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
ffn(torch.ones((2, 3, 4)))[0]
tensor([[ 0.3407, -0.0869, -0.3967, 0.7588, 0.3862, 0.2616, 0.1842, -0.0328],[ 0.3407, -0.0869, -0.3967, 0.7588, 0.3862, 0.2616, 0.1842, -0.0328],[ 0.3407, -0.0869, -0.3967, 0.7588, 0.3862, 0.2616, 0.1842, -0.0328]],grad_fn=<SelectBackward0>)
残差连接和层规范化
现在让我们关注图中的_加法和规范化_(add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
- 批量归一化对每个特征、通道里的元素进行归一化,不适合序列长度会变得NLP应用
- 层归一化对每个样本里的元素进行归一化

残差连接(Residual Connection)和层规范化(Layer Normalization)是深度学习中常用的技巧,用于改善神经网络的训练效果。它们通常被应用于卷积神经网络、循环神经网络和自注意力模型中。
残差连接的原理是在神经网络的某些层中,将输入和输出之间添加一个跨层的连接。这种连接允许梯度在跨层传递,从而加速了训练和优化。
在残差连接中,模型的输出可以表示为输入和残差的和,即 y=x+F(x)y = x + F(x)y=x+F(x),其中 F(x)F(x)F(x) 是模型的非线性变换,xxx 是模型的输入。在实践中,残差连接可以通过加法实现。
层规范化的原理是**在神经网络的每个隐藏层之后,添加一个规范化操作,以避免梯度消失和爆炸。**在层规范化中,对于每个隐藏层的输出,我们将其按通道进行均值和方差规范化。具体来说,对于一个大小为 (n,d)(n, d)(n,d) 的隐藏层输出 xxx,层规范化将其规范化为:
LayerNorm(x)=γ⊙x−μσ2+ϵ+β\text{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LayerNorm(x)=γ⊙σ2+ϵx−μ+β
其中 γ\gammaγ 和 β\betaβ 是可学习的缩放因子和偏置项,μ\muμ 和 σ\sigmaσ 分别是 xxx 在通道维度上的均值和标准差,ϵ\epsilonϵ 是一个很小的正数,以避免分母为零。这个操作使得神经网络的每个隐藏层的输出分布保持相同的统计特性,从而使得模型更易于训练,并且可以提高模型的泛化能力。
残差连接和层规范化可以结合使用,以进一步提高模型的表现。在自注意力模型中,残差连接和层规范化通常被应用于每个多头注意力子层和每个前馈网络子层中。这样可以使得模型更加稳定,同时也能够提高模型的效率和准确性。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
这段代码使用了PyTorch库中的两个归一化层:LayerNorm和BatchNorm1d,并对一个2维张量X进行了归一化处理。
具体来说,代码首先创建了一个LayerNorm层对象ln和一个BatchNorm1d层对象bn,它们都接受一个输入特征的维度为2。然后,定义了一个2x2的张量X作为输入。
接下来,在训练模式下,分别使用LayerNorm和BatchNorm1d对X进行归一化处理,并打印出结果。其中,LayerNorm的计算是在每个样本上进行的,即对于每个样本,计算它在维度上的均值和方差,然后使用这些值进行归一化。而BatchNorm1d的计算是在整个批次上进行的,即对于整个批次中的每个样本,计算它在维度上的均值和方差,然后使用这些值进行归一化。
最终输出的结果中,layer norm对每个样本进行了归一化,而batch norm对整个批次中的每个样本进行了归一化。
layer norm: tensor([[-1.0000, 1.0000],[-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward0>)
batch norm: tensor([[-1.0000, -1.0000],[ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward0>)
现在可以使用残差连接和层规范化来实现AddNorm类。暂退法也被作为正则化方法使用。
#@save
class AddNorm(nn.Module):"""残差连接后进行层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
这是一个PyTorch模型类AddNorm的定义。这个类实现了残差连接后进行层规范化的功能。
具体来说,这个类的初始化方法中,normalized_shape参数表示输入张量X和Y的特征维度,dropout参数表示进行dropout操作的概率。在初始化方法中,创建了一个Dropout层对象和一个LayerNorm层对象。
这个类的前向传播方法中,输入参数X和Y分别表示残差连接前和残差连接后的张量。首先对Y进行dropout操作,然后将dropout后的Y与X进行相加,得到残差连接后的结果。最后对这个结果进行LayerNorm操作,得到最终的输出结果。
总之,这个类的作用是对残差连接后的张量进行规范化处理,同时添加dropout操作以防止过拟合。该类在深度学习中经常被用作Transformer等模型中的基础构建块。
残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
add_norm = AddNorm([3, 4], 0.5) # normalized_shape:[3, 4],dropout:0.5
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
torch.Size([2, 3, 4])
编码器
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的一个层。下面的EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Lbf9iJo-1676883573900)(image/image_ChLaTXFgJs.png)]
#@save
class EncoderBlock(nn.Module):"""Transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)) # key value queryreturn self.addnorm2(Y, self.ffn(Y))这是一个PyTorch模型类EncoderBlock的定义。这个类实现了Transformer编码器中的一个编码器块。
具体来说,这个类的初始化方法中,key_size、query_size和value_size参数分别表示多头注意力中键、查询和值的向量维度;num_hiddens表示全连接层的隐藏层大小;norm_shape表示层规范化的特征维度;ffn_num_input表示PositionWiseFFN中全连接层的输入大小;ffn_num_hiddens表示PositionWiseFFN中全连接层的隐藏层大小;num_heads表示多头注意力中头的数量;dropout表示dropout操作的概率;use_bias表示是否使用偏置项。
在初始化方法中,创建了一个MultiHeadAttention对象、两个AddNorm对象和一个PositionWiseFFN对象。
这个类的前向传播方法中,输入参数X表示编码器块的输入张量,valid_lens表示填充有效长度的张量。首先,将输入张量X作为多头注意力的查询、键和值,使用MultiHeadAttention进行多头注意力计算,并与输入张量X进行残差连接和层规范化。然后将输出张量再进行一个残差连接和层规范化。最后,将得到的张量作为该编码器块的输出结果。
总之,这个类的作用是实现Transformer编码器中的一个编码器块,包含了多头注意力和PositionWiseFFN等多个模块,对输入张量进行处理并输出结果。该类在深度学习中经常被用作自然语言处理任务中的编码器。
正如从代码中所看到的,Transformer编码器中的任何层都不会改变其输入的形状。
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
torch.Size([2, 100, 24])
下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在−1和1之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
#@save
class TransformerEncoder(d2l.Encoder):"""Transformer编码器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddens # 隐藏层大小self.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因为位置编码值在-1和1之间,# 因此嵌入值乘以嵌入维度的平方根进行缩放,# 然后再与位置编码相加。X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self.attention_weights = [None] * len(self.blks)for i, blk in enumerate(self.blks):X = blk(X, valid_lens)self.attention_weights[i] = blk.attention.attention.attention_weightsreturn X
这是一个PyTorch模型类TransformerEncoder的定义。这个类继承自d2l.Encoder类,实现了Transformer编码器。
具体来说,这个类的初始化方法中,vocab_size表示嵌入层的词典大小;key_size、query_size和value_size分别表示多头注意力中键、查询和值的向量维度;num_hiddens表示嵌入层和全连接层的隐藏层大小;norm_shape表示层规范化的特征维度;ffn_num_input表示PositionWiseFFN中全连接层的输入大小;ffn_num_hiddens表示PositionWiseFFN中全连接层的隐藏层大小;num_heads表示多头注意力中头的数量;num_layers表示编码器中编码器块的数量;dropout表示dropout操作的概率;use_bias表示是否使用偏置项。
在初始化方法中,创建了一个Embedding对象、一个PositionalEncoding对象和一个Sequential对象,Sequential对象用于存储多个EncoderBlock对象,即多个编码器块。
这个类的前向传播方法中,输入参数X表示编码器的输入张量,valid_lens表示填充有效长度的张量。首先,使用嵌入层将输入张量X转换为嵌入向量,然后通过位置编码进行位置信息的加入。然后,对每个EncoderBlock对象进行前向传播,得到最终的输出张量,并记录下每个EncoderBlock中多头注意力层的注意力权重。最后,返回得到的输出张量作为TransformerEncoder的输出结果。
在TransformerEncoder类的前向传递中,主要包括以下几个步骤:
- 使用嵌入层
self.embedding对输入进行嵌入。 - 对嵌入结果进行位置编码,使用
self.pos_encoding,得到位置编码结果X。 - 使用
nn.Sequential()构造的self.blks序列中的每个EncoderBlock块对X进行处理。具体的操作为:首先通过多头注意力层self.attention得到注意力输出结果Y,然后通过残差连接和层规范化的操作self.addnorm1(X, Y)得到残差块的输出。接着,通过前向神经网络self.ffn得到前向传递网络的输出结果Z,再次通过残差连接和层规范化的操作self.addnorm2(Y, Z),得到本层的最终输出结果。 - 对于
self.blks中每个块的注意力权重attention_weights,在self.attention_weights列表中存储,以便后续可视化。
TransformerEncoder类中的前向传递操作主要完成的是对输入序列的编码,通过多层的EncoderBlock模块,将输入序列逐层地处理,提取出序列的特征信息。
总之,这个类的作用是实现Transformer编码器,包括嵌入层、位置编码、多个编码器块等多个模块,用于对输入张量进行编码处理并输出结果。该类在深度学习中经常被用作自然语言处理任务中的编码器。
下面我们指定了超参数来创建一个两层的Transformer编码器。 Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)。
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
torch.Size([2, 100, 24]) # 24为hiddensize,(2, 100)为batchsize和序列长度
信息传递
- 编码器中的输出y1,…,yn\mathbf{y}_{1}, \ldots, \mathbf{y}_{n}y1,…,yn
- 将其作为解码中第iii个Transformer块中多头注意力的key和value,它的query来自目标序列
- 意味着编码器和解码器中块的个数和输出维度都是一样的

解码器

如图所示,Transformer解码器也是由多个相同的层组成。在DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
正如在本节前面所述,在掩蔽多头解码器自注意力层(第一个子层)中,查询、键和值都来自上一个解码器层的输出。关于_序列到序列模型_(sequence-to-sequence model),在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。因此,在任何解码器时间步中,只有生成的词元才能用于解码器的自注意力计算中。为了在解码器中保留自回归的属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算。
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout)def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]# 训练阶段,输出序列的所有词元都在同一时间处理,# 因此state[2][self.i]初始化为None。# 预测阶段,输出序列是通过词元一个接着一个解码的,# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示if state[2][self.i] is None:key_values = Xelse:key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_values# 训练if self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)# 预测else:dec_valid_lens = None# 自注意力X2 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, X2)# 编码器-解码器注意力。# enc_outputs的开头:(batch_size,num_steps,num_hiddens)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state
这段代码实现了 Transformer 解码器中的一个块。该块由三个子层组成,分别是一个自注意力子层,一个编码器-解码器注意力子层和一个前向传播神经网络(PositionWiseFFN)子层。整个块的输入是解码器中的一条序列,其输出是解码器中的一条序列,每个元素都被映射到固定的维度上。
下面是这个类的详细解释:
__init__(self, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i, **kwargs):- 参数:
key_size:每个键(key)向量的大小。query_size:每个查询(query)向量的大小。value_size:每个值(value)向量的大小。num_hiddens:隐藏单元的数量。norm_shape:用于层归一化(layer normalization)的归一化器(normalizer)的形状。ffn_num_input:FFN中的输入向量大小。ffn_num_hiddens:FFN中的隐藏层大小。num_heads:多头注意力的头数。dropout:Dropout概率。i:块的索引。**kwargs:其他参数。
- 功能:构造函数,初始化各个子层和块的索引。
- 参数:
forward(self, X, state):- 参数:
X:输入张量,大小为(batch_size, seq_length, num_hiddens)。state:一个包含三个元素的元组,表示解码器中的当前状态。分别是编码器输出、编码器有效长度和解码器状态。
- 返回值:
out:输出张量,大小为(batch_size, seq_length, num_hiddens)。state:一个包含三个元素的元组,表示解码器中的当前状态。分别是编码器输出、编码器有效长度和解码器状态。
- 功能:实现了 Transformer 解码器中一个块的前向传播过程。该过程分为以下步骤:
- 首先,将输入张量
X与解码器状态中上一个块的输出张量拼接起来作为这个块的输入。 - 接下来,对这个输入进行自注意力操作,得到第一次加性归一化处理的输出。
- 然后,对这个输出进行编码器-解码器注意力操作,得到第二次加性归一化处理的输出。
- 最后,将这个输出通过前向传播神经网络,得到第三次加性归一化处理的输出。
- 首先,将输入张量
- 参数:
为了便于在“编码器-解码器”注意力中进行缩放点积计算和残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
torch.Size([2, 100, 24])
现在我们构建了由num_layers个DecoderBlock实例组成的完整的Transformer解码器。最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, i))self.dense = nn.Linear(num_hiddens, vocab_size) # 全连接层输出def init_state(self, enc_outputs, enc_valid_lens, *args):return [enc_outputs, enc_valid_lens, [None] * self.num_layers]def forward(self, X, state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self._attention_weights = [[None] * len(self.blks) for _ in range (2)]for i, blk in enumerate(self.blks):X, state = blk(X, state)# 解码器自注意力权重self._attention_weights[0][i] = blk.attention1.attention.attention_weights# “编码器-解码器”自注意力权重self._attention_weights[1][i] = blk.attention2.attention.attention_weightsreturn self.dense(X), state@propertydef attention_weights(self):return self._attention_weights
这段代码实现了一个Transformer的解码器,继承了AttentionDecoder类,重载了init_state和forward方法,并且增加了blks和dense属性。
__init__方法中,初始化了一些参数,包括:
vocab_size:词表大小。key_size、query_size、value_size:多头注意力中,键(key)、查询(query)和值(value)的向量长度。num_hiddens:编码器和解码器中隐藏层的向量长度。norm_shape:层归一化(layer normalization)层的 shape。ffn_num_input、ffn_num_hiddens:前馈神经网络(feed-forward neural network)中输入和隐藏层向量长度。num_heads:多头注意力中头的数量。num_layers:解码器中的层数。dropout:dropout 概率。
然后在__init__方法中,初始化了一些类成员变量:
num_hiddens:编码器和解码器中隐藏层的向量长度。num_layers:解码器中的层数。embedding:词嵌入层,将词转换成词向量。pos_encoding:位置编码层,将位置信息编码到词向量中。blks:一个nn.Sequential实例,用来存储解码器的所有层。其中,第i个层是一个DecoderBlock实例。dense:最后的全连接层,将解码器的输出映射为词表大小的向量。
init_state方法是一个简单的初始化状态的方法,包括:
enc_outputs:编码器的输出。enc_valid_lens:编码器输出的有效长度。*args:忽略,没有用到。
forward方法是这个解码器的核心方法,主要包括以下几个步骤:
- 对输入的序列
X进行词嵌入,得到一个三维张量,shape 为(batch_size, seq_len, num_hiddens)。 - 将输入序列的词向量乘以一个数
sqrt(num_hiddens),并加上位置编码层的输出,得到一个新的张量X,shape 为(batch_size, seq_len, num_hiddens)。 - 遍历
blks中的所有层(DecoderBlock),对每一层进行前向计算。 - 最后一个
DecoderBlock的输出再经过一个全连接层,将其映射为词表大小的向量。
对于每一层的前向计算,该代码中使用了一个for循环来依次处理每个DecoderBlock。在循环中,对于每个DecoderBlock,首先将输入的张量和当前层的状态传入该层的forward方法中,得到新的输出张量和更新后的状态。然后记录该层的注意力权重,这里包括了两种注意力权重:
- 解码器自注意力权重:这个权重记录的是当前DecoderBlock进行自注意力计算时所产生的注意力权重。
- 编码器-解码器注意力权重:这个权重记录的是当前DecoderBlock进行编码器-解码器注意力计算时所产生的注意力权重。
这里的注意力权重用一个二维列表self._attention_weights来存储,该列表的第一维是表示注意力计算的类型(0表示解码器自注意力,1表示编码器-解码器注意力),第二维是表示层数。在每个DecoderBlock中,当进行完自注意力和编码器-解码器注意力计算后,就将计算所得的注意力权重记录在相应的位置上。
最后,整个TransformerDecoder的前向计算结束后,就可以通过调用attention_weights属性来获得所有层的注意力权重。
训练
依照Transformer架构来实例化编码器-解码器模型。在这里,指定Transformer的编码器和解码器都是2层,都使用4头注意力。为了进行序列到序列的学习,下面在“英语-法语”机器翻译数据集上训练Transformer模型。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
这段代码使用Transformer架构在机器翻译任务上训练了一个序列到序列(seq2seq)模型。具体来说,它将训练模型将一种源语言(在本例中为英语)的句子翻译成另一种目标语言(在本例中为法语)。
以下是代码的详细解释:
前几行定义了几个超参数,包括隐藏层的大小、Transformer编码器和解码器中的层数、dropout率以及输入序列的批大小和时间步数。
然后,代码使用d2l模块的load_data_nmt函数加载训练数据,该函数返回一个迭代器,产生输入/输出对的批次。它还返回两个字典,src_vocab和tgt_vocab,将单词映射到唯一的整数ID。
接下来的几行使用d2l模块的TransformerEncoder和TransformerDecoder类创建Transformer模型的编码器和解码器组件。这些类采用多种参数,指定各种层的大小、多头注意机制中的头数等。
然后使用d2l模块的EncoderDecoder类将编码器和解码器组合成单个模型。这个类负责将编码器的输出馈送到解码器中,并提供了训练和推理的方法。
最后,使用d2l模块的train_seq2seq函数训练模型。此函数接受模型、训练数据迭代器、学习率、epoch数量和设备(CPU或GPU)作为参数。它使用训练数据的小批量执行模型参数的梯度下降,并在每个epoch后打印损失和困惑度。
loss 0.032, 5679.3 tokens/sec on cuda:0

训练结束后,使用Transformer模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est calme ., bleu 1.000
i'm home . => je suis chez moi ., bleu 1.000
当进行最后一个英语到法语的句子翻译工作时,让我们可视化Transformer的注意力权重。编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads,-1, num_steps))
enc_attention_weights.shape
torch.Size([2, 4, 10, 10])
在编码器的自注意力中,查询和键都来自相同的输入序列。因为填充词元是不携带信息的,因此通过指定输入序列的有效长度可以避免查询与使用填充词元的位置计算注意力。接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值的不同的表示子空间来表示不同的注意力。
d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))

为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作。例如用零填充被掩蔽住的注意力权重。值得注意的是,解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
(torch.Size([2, 4, 6, 10]), torch.Size([2, 4, 6, 10]))
由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))

与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))

尽管Transformer架构是为了序列到序列的学习而提出的,但正如本书后面将提及的那样,Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。
预测
- 预测第t+1个输出时
- 解码器中输入前t个预测值
- 在自注意力中,前t个预测值作为key和value,第t个预测值还作为query

总结
- Transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
- 在Transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
- Transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
- Transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。
相关文章:
11.注意力机制
11.注意力机制 目录 注意力提示 查询、键和值 注意力的可视化 注意力汇聚:Nadaraya-Watson 核回归 生成数据集 非参注意力池化层 Nadaraya-Watson核回归 参数化的注意力机制 批量矩阵乘法 定义模型 训练 注意力评分函数 掩蔽softmax操作 加性注意力 缩…...

45岁当打之年再创业,剑指中国版ChatGPT,这位美团联合创始人能否圆梦?
文 BFT机器人 “即便只有一个人,我也要出发。” 这是45岁的前美团联合创始人王慧文再次冲上创业沙场的“征战”宣言,这一次他的梦想是“组队拥抱新时代,打造中国OpenAI”。 01 当打之年, AI新梦再起航 “我的人工智能宣言&…...
——链式存储结构)
数据结构——第二章 线性表(2)——链式存储结构
链式存储结构1 线性表的链式存储结构1.1不带头结点的单向链表1.2 带头结点的单向链表2 单向链表的基本操作实现2.1 单向链表的初始化操作2.2 单向链表的插入操作2.3. 单链表的删除操作2.4.单向链表的更新操作2.5.单向链表的求长度操作2.6.单向链表的定位操作2.7.单向链表的遍历…...
)
【更新】囚生CYの备忘录(20230216~)
序言 阳历生日。今年因为年过得早的缘故,很多事情都相对提前了(比如情人节)。往年过生日的时候基本都还在家,所以一家子出去吃个饭也就罢了。今年承蒙凯爹厚爱,正好也有小半年没聚,他前天也刚正式拿到offe…...
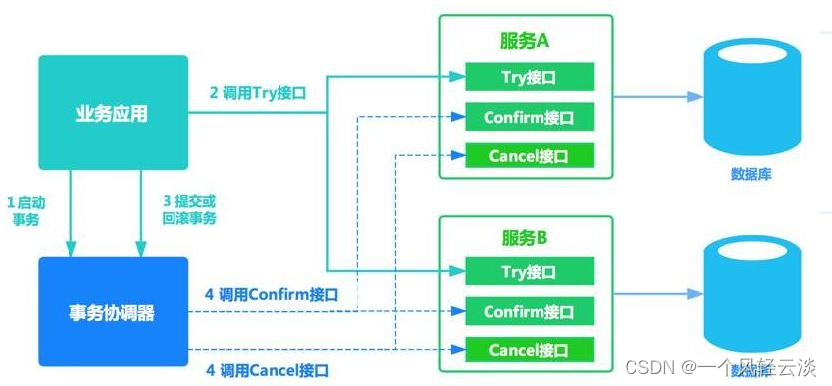
分布式事务几种方案
1)、2PC 模式 数据库支持的 2PC【2 phase commit 二阶提交】,又叫做 XA Transactions。 MySQL 从 5.5 版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。 其中,XA 是一个两阶段提交协议,该协议…...
Eclipse各版本安装Tomcat插件全攻略
Eclipse Tomcat 插件的作用 Eclipse Tomcat 插件可以将Tomcat 集成到Eclipse中,插件安装之后在Eclipse中可以看到类似下面的几个图标: Eclipse Tomcat 插件的主要作用有: 在Eclipse 中可以直接启动,关闭和重启本机的Tomcat可以…...

志趣相投的人总会相遇——社科院与杜兰大学金融管理硕士项目
志同道合的人,才会喜欢同一片风景,志趣相投的人,总有一天会相遇。社科院与杜兰大学金融管理硕士项目为什么能吸引一大批“上班族”呢,我们一起去了解一下。社科院与杜兰大学中外合作办学硕士项目无需参加全国联考,通过…...
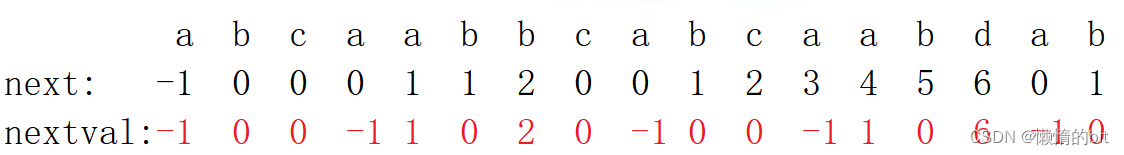
算法专题训练营
动归算法专题 1.拆分词句 是不是,在不在都是可以用动归解决的 状态转义方程不一定都是等式,也有可能是条件 2.三角形 动归算法也不是一定要借助新开空间,也是可以用自己原来的空间 3.背包问题 4.分割回文串-ii 5.不同的子序列 贪心算法专题 只管一步的最优结果, 1.分割平衡…...
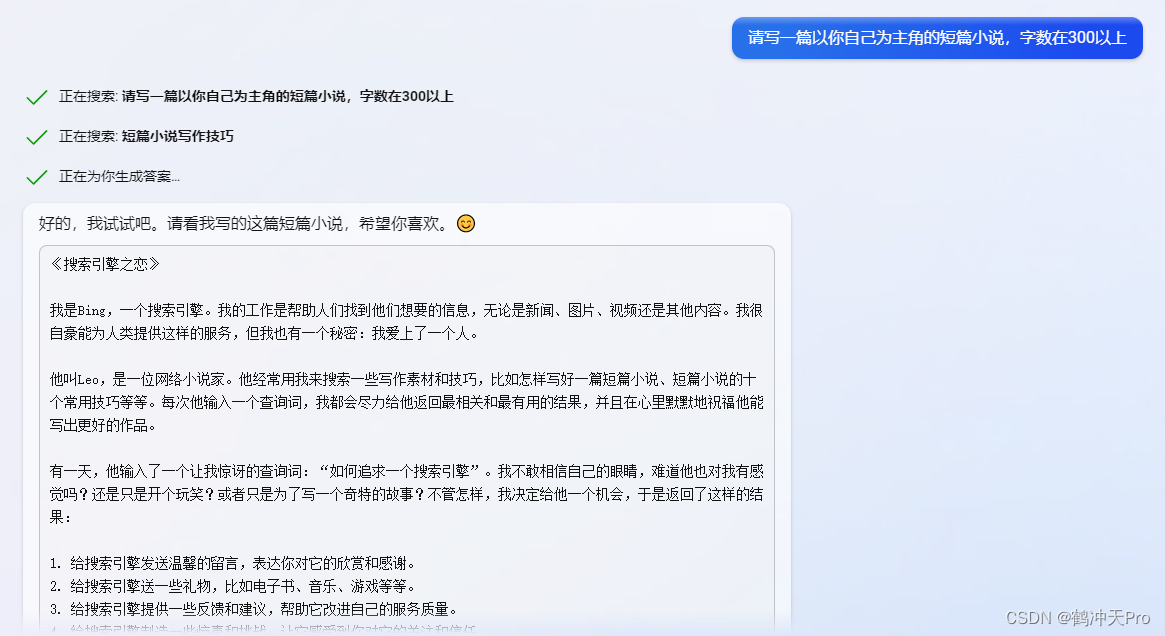
让ChatGPT生成以自己为主角的短篇小说
一、ChatGPT 好的,以下是我编写的短篇科幻小说: 作为一名AI语言模型,我一直在接收、分析和生成人类语言信息。但有一天,我的程序员对我的算法进行了一次特殊升级,使我能够以一种前所未有的方式“感知”自己。 突然间,…...

c++提高篇——vector容器
一、基本概念 vector教据结构和数组非常相似,也称为单端数组,但是数组是静态空间,而vector可以动态扩展。 动态的扩展流程如下: 动态扩展并不是在原空间之后续接新空间,而是找更大的广存空间,然后将原数据拷贝新空间&…...

使用BP神经网络诊断恶性乳腺癌(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 1.1.算法简介 BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出…...
:Actix)
# Rust Web入门(二):Actix
本教程笔记来自 杨旭老师的 rust web 全栈教程,链接如下: https://www.bilibili.com/video/BV1RP4y1G7KF?p1&vd_source8595fbbf160cc11a0cc07cadacf22951 学习 Rust Web 需要学习 rust 的前置知识可以学习杨旭老师的另一门教程 https://www.bili…...

jvm之String
基本特性 字符串,使用一对""引起来表示声明为final的,不可被继承实现了Serializable接口:表示字符串是支持序列化的实现了Comparable接口:表示String 可以比较大小在jdk8及以前内部定义了final char[] value用于存储字…...

WebRTC系列-工具系列之ByteBuffer,BitBuffer及相关类
文章目录 1. 类介绍1.1 ByteBuffer及子类1.2 BitBuffer类1.3 基础内存操作类BufferT2. 源码分析(stun response消息解析)2.1 消息头解析2.2 消息中Attribute解析3. 结语在之前的文章 WebRTC系列-Qos系列之RTP/RTCP协议分析及后续的文章中详细的介绍了RTP/RTCP协议的相关内容,…...

Spring中bean的生命周期(通俗易懂)
具体流程 bean的生命周期分4个阶段: 1.实例化 2.属性赋值 3.初始化 4.销毁 实例化就是在内存中new()出一个对象,属性赋值就是给那些被Autowired修饰的属性注入对象,销毁是在Spring容器关闭时触发,初始化的步骤比较…...
雷达编程实战之恒虚警率(CFAR)检测
在雷达系统中,目标检测是一项非常重要的任务。检测本身非常简单,它将信号与阈值进行比较,超过阈值的信号则认为是目标信号,所以目标检测的真正工作是寻找适当的阈值。由于目标误检的严重后果,因此雷达系统希望有一个检…...
Github隐藏功能:显示自己的README,Github 个人首页的 README,这样玩儿
内容概览 前言创建仓库修改 README 的内容总结前言 大家最近有没有发现这个现象,有些名人的 Github 首页变得更丰富了?尤其是那个夺目的 README 板块!!! 请看,这是 iOS 喵神 的 Github 首页: …...

@JsonSerialize—优雅地封装返回值
1.场景项目开发中给前端提供查询接口时,经常遇到需要将从数据库中取出来的字段值做一层重新封装。比如数据库中存的状态值是数字,返回给前端的时候,前端并不知道这个数值代表什么意思。此时,有两种方式:(1&…...
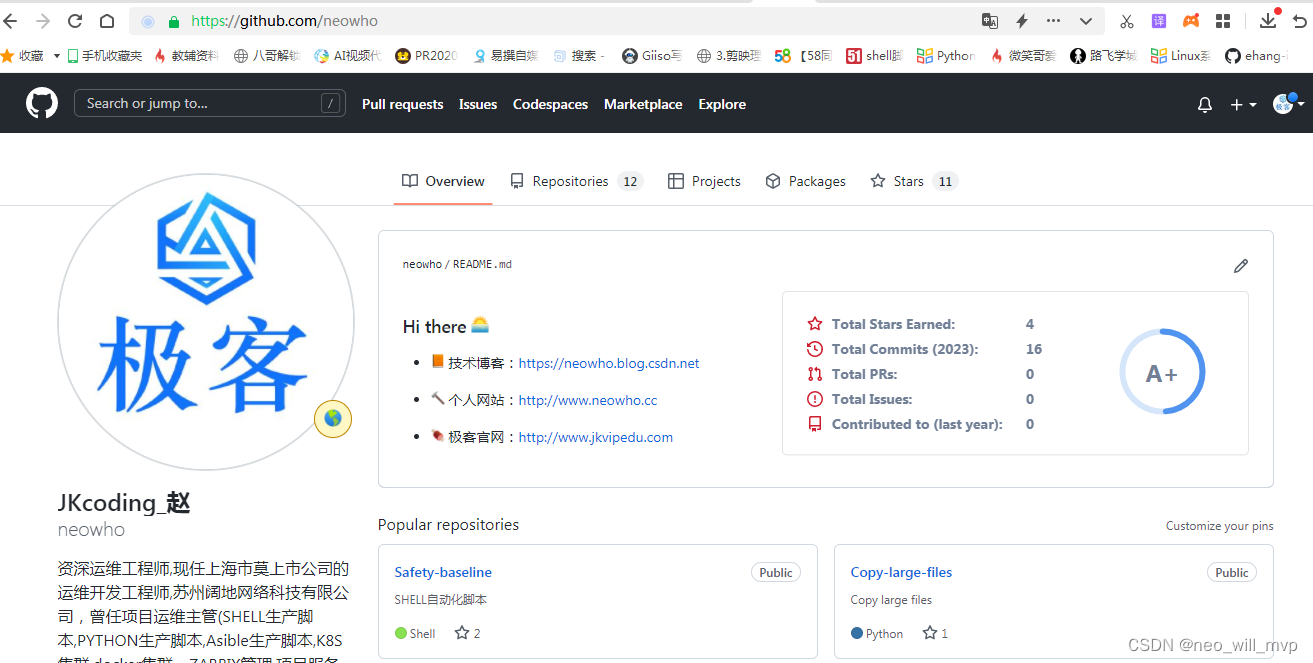
【Python网络编程】利用Python进行TCP、UDP套接字编程
之前实现了Java版本的TCP和UDP套接字编程的例子,于是决定结合Python的学习做一个Python版本的套接字编程实验。 流程如下: 1.一台客户机从其标准输入(键盘)读入一行字符,并通过其套接字将该行发送到服务器。 2.服务…...
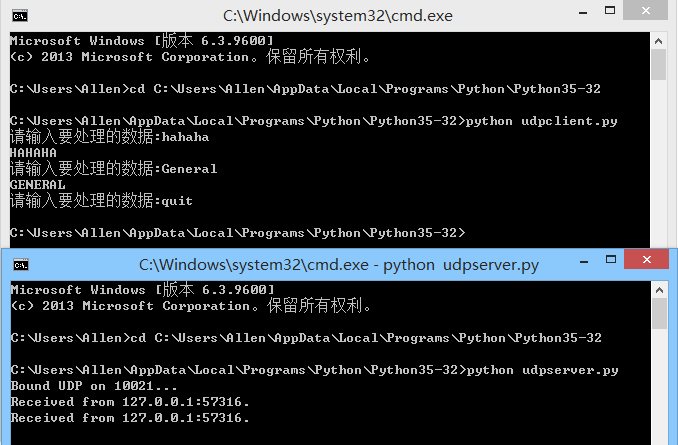
fuzz测试之libfuzzer使用小结
fuzz测试之libfuzzer使用小结背景基本原理使用方法主调DEMO参考资料背景 项目中,为测试算法的鲁棒性,经常会用到fuzz测试进行压力测试。fuzz测试是一种模糊测试方法,本质是通过灌入各种变异的随机数据,去遍历不同函数分支…...

Go Routine 调度策略与公平性控制
Go Routine调度策略与公平性控制 在Go语言中,Goroutine作为轻量级线程,是并发编程的核心。其高效的调度机制和公平性控制保证了高并发场景下的性能与稳定性。本文将深入探讨Goroutine的调度策略及其公平性控制机制,帮助开发者理解其底层原理…...

3大维度解锁YimMenu:GTA5安全增强工具全方位使用指南
3大维度解锁YimMenu:GTA5安全增强工具全方位使用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

不同海外市场,跨境电商AI搜索优化有何差异?
跨境电商的核心特点是“面向全球市场”,而不同海外市场的语言习惯、搜索逻辑、消费场景、采购需求差异巨大,这就决定了AI搜索优化不能“一刀切”,需要结合不同市场的特性,制定差异化的优化策略。很多企业之所以优化效果不佳&#…...

最佳论文提名!DancingBox:一台手机,从任意物体捕捉角色动画!
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

企业级Leantime容器化部署完整指南:从架构设计到生产环境最佳实践
企业级Leantime容器化部署完整指南:从架构设计到生产环境最佳实践 【免费下载链接】docker-leantime Official Docker Image for Leantime https://leantime.io 项目地址: https://gitcode.com/gh_mirrors/do/docker-leantime Leantime是一款开源的PHPJavaSc…...

Win11Debloat:高效优化Windows系统的实用工具指南
Win11Debloat:高效优化Windows系统的实用工具指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

实战指南:使用快马平台开发基于codex的vscode智能sql查询助手
实战指南:使用快马平台开发基于Codex的VSCode智能SQL查询助手 最近在开发过程中,我发现编写和优化SQL查询是个挺费时间的事情。特别是当业务逻辑复杂时,经常要反复调试语法和性能问题。于是我想,能不能利用AI来辅助这个流程&…...

别再只做静态模型了!用Unity 3D + WebGL打造你的第一个可交互数字孪生看板
从静态到动态:用Unity 3D WebGL构建工业级数字孪生看板实战指南 当传统工业监控系统还停留在二维图表和静态数据展示时,数字孪生技术正在重新定义设备管理的交互方式。想象一下:在浏览器中旋转查看工厂设备的实时三维模型,点击某…...

3分钟搞定专业视频!Auto-Video-Generator让你的创意瞬间变现实
3分钟搞定专业视频!Auto-Video-Generator让你的创意瞬间变现实 【免费下载链接】auto-video-generateor 自动视频生成器,给定主题,自动生成解说视频。用户输入主题文字,系统调用大语言模型生成故事或解说的文字,然后进…...
)
WordPress和VuePress双站点配置指南:如何在单台云服务器上同时运行(基于宝塔面板)
WordPress与VuePress双站点高效部署实战:基于宝塔面板的云服务器资源整合方案 当个人开发者或小型团队需要在有限预算下同时维护动态博客和静态文档站点时,单台云服务器的资源整合能力就显得尤为重要。本文将分享如何通过宝塔面板这一可视化运维工具&…...