opencv 案例实战02-停车场车牌识别SVM模型训练及验证
1. 整个识别的流程图:
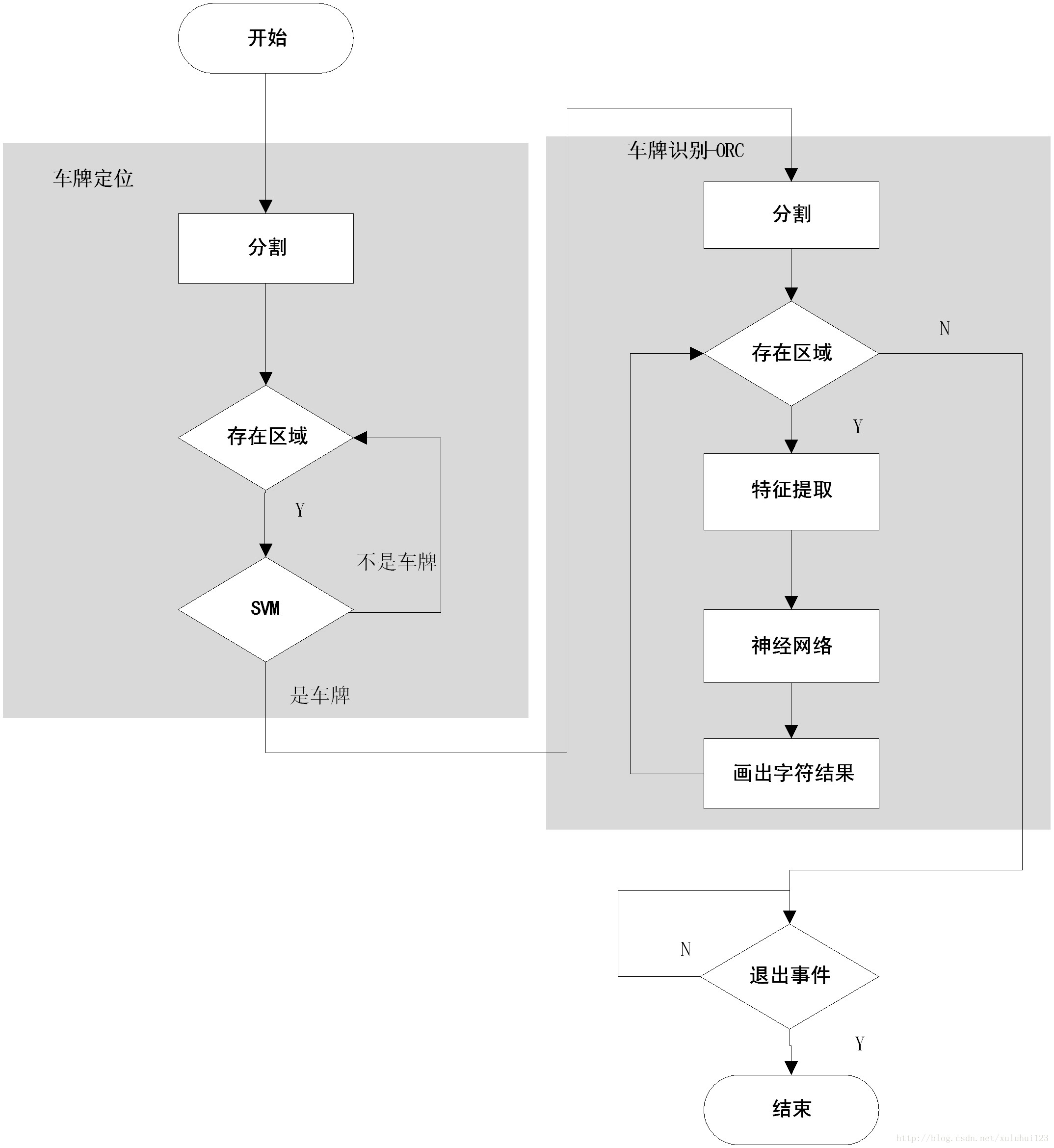
2. 车牌定位中分割流程图:
三、车牌识别中字符分割流程图:


1.准备数据集
下载车牌相关字符样本用于训练和测试,本文使用14个汉字样本和34个数字跟字母样本,每个字符样本数为40,样本尺寸为28*28。


数据集下载地址
https://download.csdn.net/download/hai411741962/88248392
下载不了,评论区留言
2. 编码训练代码
import cv2
import numpy as np
from numpy.linalg import norm
import sys
import os
import jsonSZ = 20 #训练图片长宽
MAX_WIDTH = 1000 #原始图片最大宽度
Min_Area = 2000 #车牌区域允许最大面积
PROVINCE_START = 1000
#不能保证包括所有省份
provinces = ["zh_cuan", "川","zh_e", "鄂","zh_gan", "赣","zh_gan1", "甘","zh_gui", "贵","zh_gui1", "桂","zh_hei", "黑","zh_hu", "沪","zh_ji", "冀","zh_jin", "津","zh_jing", "京","zh_jl", "吉","zh_liao", "辽","zh_lu", "鲁","zh_meng", "蒙","zh_min", "闽","zh_ning", "宁","zh_qing", "靑","zh_qiong", "琼","zh_shan", "陕","zh_su", "苏","zh_sx", "晋","zh_wan", "皖","zh_xiang", "湘","zh_xin", "新","zh_yu", "豫","zh_yu1", "渝","zh_yue", "粤","zh_yun", "云","zh_zang", "藏","zh_zhe", "浙"
]class StatModel(object):def load(self, fn):self.model = self.model.load(fn)#从文件载入训练好的模型def save(self, fn):self.model.save(fn)#保存训练好的模型到文件中class SVM(StatModel):def __init__(self, C = 1, gamma = 0.5):self.model = cv2.ml.SVM_create()#生成一个SVM模型self.model.setGamma(gamma) #设置Gamma参数,demo中是0.5self.model.setC(C)# 设置惩罚项, 为:1self.model.setKernel(cv2.ml.SVM_RBF)#设置核函数self.model.setType(cv2.ml.SVM_C_SVC)#设置SVM的模型类型:SVC是分类模型,SVR是回归模型#训练svmdef train(self, samples, responses):self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)#训练#字符识别def predict(self, samples):r = self.model.predict(samples)#预测return r[1].ravel()#来自opencv的sample,用于svm训练
def deskew(img):m = cv2.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11']/m['mu02']M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])img = cv2.warpAffine(img, M, (SZ, SZ), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)return img#来自opencv的sample,用于svm训练
def preprocess_hog(digits):samples = []for img in digits:gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)mag, ang = cv2.cartToPolar(gx, gy)bin_n = 16bin = np.int32(bin_n*ang/(2*np.pi))bin_cells = bin[:10,:10], bin[10:,:10], bin[:10,10:], bin[10:,10:]mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]hist = np.hstack(hists)# transform to Hellinger kerneleps = 1e-7hist /= hist.sum() + epshist = np.sqrt(hist)hist /= norm(hist) + epssamples.append(hist)return np.float32(samples)def save_traindata(model,modelchinese):if not os.path.exists("module\\svm.dat"):model.save("module\\svm.dat")if not os.path.exists("module\\svmchinese.dat"):modelchinese.save("module\\svmchinese.dat")def train_svm():#识别英文字母和数字model = SVM(C=1, gamma=0.5)#识别中文modelchinese = SVM(C=1, gamma=0.5)if os.path.exists("svm.dat"):model.load("svm.dat")else:chars_train = []chars_label = []for root, dirs, files in os.walk("train\\chars2"):if len(os.path.basename(root)) > 1:continueroot_int = ord(os.path.basename(root))for filename in files:filepath = os.path.join(root,filename)digit_img = cv2.imread(filepath)digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)chars_train.append(digit_img)#chars_label.append(1)chars_label.append(root_int)chars_train = list(map(deskew, chars_train))#print(chars_train)chars_train = preprocess_hog(chars_train)#print(chars_train)#chars_train = chars_train.reshape(-1, 20, 20).astype(np.float32)chars_label = np.array(chars_label)model.train(chars_train, chars_label)if os.path.exists("svmchinese.dat"):modelchinese.load("svmchinese.dat")else:chars_train = []chars_label = []for root, dirs, files in os.walk("train\\charsChinese"):if not os.path.basename(root).startswith("zh_"):continuepinyin = os.path.basename(root)index = provinces.index(pinyin) + PROVINCE_START + 1 #1是拼音对应的汉字for filename in files:filepath = os.path.join(root,filename)digit_img = cv2.imread(filepath)digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)chars_train.append(digit_img)#chars_label.append(1)chars_label.append(index)chars_train = list(map(deskew, chars_train))chars_train = preprocess_hog(chars_train)#chars_train = chars_train.reshape(-1, 20, 20).astype(np.float32)chars_label = np.array(chars_label)print(chars_train.shape)modelchinese.train(chars_train, chars_label)save_traindata(model,modelchinese)train_svm()
运行代码后会生成两个模型文件,下面验证两个模型文件。

import cv2
import numpy as npimport json
import trainSZ = 20 #训练图片长宽
MAX_WIDTH = 1000 #原始图片最大宽度
Min_Area = 2000 #车牌区域允许最大面积
PROVINCE_START = 1000
#读取图片文件
def imreadex(filename):return cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)def point_limit(point):if point[0] < 0:point[0] = 0if point[1] < 0:point[1] = 0#根据设定的阈值和图片直方图,找出波峰,用于分隔字符
def find_waves(threshold, histogram):up_point = -1#上升点is_peak = Falseif histogram[0] > threshold:up_point = 0is_peak = Truewave_peaks = []for i,x in enumerate(histogram):if is_peak and x < threshold:if i - up_point > 2:is_peak = Falsewave_peaks.append((up_point, i))elif not is_peak and x >= threshold:is_peak = Trueup_point = iif is_peak and up_point != -1 and i - up_point > 4:wave_peaks.append((up_point, i))return wave_peaks#根据找出的波峰,分隔图片,从而得到逐个字符图片
def seperate_card(img, waves):part_cards = []for wave in waves:part_cards.append(img[:, wave[0]:wave[1]])return part_cardsclass CardPredictor:def __init__(self):#车牌识别的部分参数保存在json中,便于根据图片分辨率做调整f = open('config.json')j = json.load(f)for c in j["config"]:if c["open"]:self.cfg = c.copy()breakelse:raise RuntimeError('没有设置有效配置参数')def load_svm(self):#识别英文字母和数字self.model = train.SVM(C=1, gamma=0.5)#SVM(C=1, gamma=0.5)#识别中文self.modelchinese = train.SVM(C=1, gamma=0.5)#SVM(C=1, gamma=0.5)self.model.load("module\\svm.dat")self.modelchinese.load("module\\svmchinese.dat")def accurate_place(self, card_img_hsv, limit1, limit2, color):row_num, col_num = card_img_hsv.shape[:2]xl = col_numxr = 0yh = 0yl = row_num#col_num_limit = self.cfg["col_num_limit"]row_num_limit = self.cfg["row_num_limit"]col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5#绿色有渐变for i in range(row_num):count = 0for j in range(col_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > col_num_limit:if yl > i:yl = iif yh < i:yh = ifor j in range(col_num):count = 0for i in range(row_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if limit1 < H <= limit2 and 34 < S and 46 < V:count += 1if count > row_num - row_num_limit:if xl > j:xl = jif xr < j:xr = jreturn xl, xr, yh, yldef predict(self, car_pic, resize_rate=1):if type(car_pic) == type(""):img = imreadex(car_pic)else:img = car_picpic_hight, pic_width = img.shape[:2]if resize_rate != 1:img = cv2.resize(img, (int(pic_width*resize_rate), int(pic_hight*resize_rate)), interpolation=cv2.INTER_AREA)pic_hight, pic_width = img.shape[:2]#cv2.imshow('img',img)#cv2.waitKey(0)print("h,w:", pic_hight, pic_width)blur = self.cfg["blur"]#高斯去噪if blur > 0:img = cv2.GaussianBlur(img, (blur, blur), 0)#图片分辨率调整oldimg = imgimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#去掉图像中不会是车牌的区域kernel = np.ones((20, 20), np.uint8)img_opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)img_opening = cv2.addWeighted(img, 1, img_opening, -1, 0);#找到图像边缘ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)img_edge = cv2.Canny(img_thresh, 100, 200)#边缘检测#使用开运算和闭运算让图像边缘成为一个整体kernel = np.ones((self.cfg["morphologyr"], self.cfg["morphologyc"]), np.uint8)img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel)img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel)#查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)print('len(contours)', len(contours))#找出区域contours = [cnt for cnt in contours if cv2.contourArea(cnt) > Min_Area]print('len(contours)', len(contours))#cv2.contourArea计算面积#一一排除不是车牌的矩形区域car_contours = []for cnt in contours:rect = cv2.minAreaRect(cnt)#minAreaRectarea_width, area_height = rect[1]if area_width < area_height:area_width, area_height = area_height, area_widthwh_ratio = area_width / area_height#长宽比#print(wh_ratio)#要求矩形区域长宽比在2到5.5之间,2到5.5是车牌的长宽比,其余的矩形排除if wh_ratio > 2 and wh_ratio < 5.5:car_contours.append(rect)box = cv2.boxPoints(rect)#cv2.boxPoints()可获取该矩形的四个顶点坐标。print(box)box = np.int0(box) #转成整数print(box)oldimg = cv2.drawContours(oldimg, [box], 0, (0, 0, 255), 2)print(len(car_contours))print("精确定位")card_imgs = []#矩形区域可能是倾斜的矩形,需要矫正,以便使用颜色定位for rect in car_contours:if rect[2] > -1 and rect[2] < 1:#创造角度,使得左、高、右、低拿到正确的值angle = 1else:angle = rect[2]rect = (rect[0], (rect[1][0]+5, rect[1][1]+5), angle)#扩大范围,避免车牌边缘被排除box = cv2.boxPoints(rect)heigth_point = right_point = [0, 0]left_point = low_point = [pic_width, pic_hight]for point in box:if left_point[0] > point[0]:left_point = pointif low_point[1] > point[1]:low_point = pointif heigth_point[1] < point[1]:heigth_point = pointif right_point[0] < point[0]:right_point = pointif left_point[1] <= right_point[1]:#正角度new_right_point = [right_point[0], heigth_point[1]]pts2 = np.float32([left_point, heigth_point, new_right_point])#字符只是高度需要改变pts1 = np.float32([left_point, heigth_point, right_point])M = cv2.getAffineTransform(pts1, pts2)dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))point_limit(new_right_point)point_limit(heigth_point)point_limit(left_point)card_img = dst[int(left_point[1]):int(heigth_point[1]), int(left_point[0]):int(new_right_point[0])]if(len(card_img)>0):card_imgs.append(card_img)elif left_point[1] > right_point[1]:#负角度new_left_point = [left_point[0], heigth_point[1]]pts2 = np.float32([new_left_point, heigth_point, right_point])#字符只是高度需要改变pts1 = np.float32([left_point, heigth_point, right_point])M = cv2.getAffineTransform(pts1, pts2)dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))point_limit(right_point)point_limit(heigth_point)point_limit(new_left_point)card_img = dst[int(right_point[1]):int(heigth_point[1]), int(new_left_point[0]):int(right_point[0])]card_imgs.append(card_img)#cv2.imshow("card", card_img)#cv2.waitKey(0)#开始使用颜色定位,排除不是车牌的矩形,目前只识别蓝、绿、黄车牌colors = []for card_index,card_img in enumerate(card_imgs):print(len(card_imgs))green = yello = blue = black = white = 0card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)print("card_img_hsv.shape")print(card_img_hsv.shape)#有转换失败的可能,原因来自于上面矫正矩形出错if card_img_hsv is None:continuerow_num, col_num= card_img_hsv.shape[:2]card_img_count = row_num * col_numfor i in range(row_num):for j in range(col_num):H = card_img_hsv.item(i, j, 0)S = card_img_hsv.item(i, j, 1)V = card_img_hsv.item(i, j, 2)if 11 < H <= 34 and S > 34:#图片分辨率调整yello += 1elif 35 < H <= 99 and S > 34:#图片分辨率调整green += 1elif 99 < H <= 124 and S > 34:#图片分辨率调整blue += 1if 0 < H <180 and 0 < S < 255 and 0 < V < 46:black += 1elif 0 < H <180 and 0 < S < 43 and 221 < V < 225:white += 1color = "no"#根据HSV判断车牌颜色limit1 = limit2 = 0if yello*2 >= card_img_count:color = "yello"limit1 = 11limit2 = 34#有的图片有色偏偏绿elif green*2 >= card_img_count:color = "green"limit1 = 35limit2 = 99elif blue*2 >= card_img_count:color = "blue"limit1 = 100limit2 = 124#有的图片有色偏偏紫elif black + white >= card_img_count*0.7:#TODOcolor = "bw"colors.append(color)print("blue, green, yello, black, white, card_img_count:")print(blue," " ,green," ", yello," ", black," ", white," ", card_img_count)print("车牌颜色:",color)# cv2.imshow("color", card_img)# cv2.waitKey(0)if limit1 == 0:continue#以上为确定车牌颜色#以下为根据车牌颜色再定位,缩小边缘非车牌边界xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)if yl == yh and xl == xr:continueneed_accurate = Falseif yl >= yh:yl = 0yh = row_numneed_accurate = Trueif xl >= xr:xl = 0xr = col_numneed_accurate = Truecard_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh-yl)//4 else card_img[yl-(yh-yl)//4:yh, xl:xr]if need_accurate:#可能x或y方向未缩小,需要再试一次card_img = card_imgs[card_index]card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)if yl == yh and xl == xr:continueif yl >= yh:yl = 0yh = row_numif xl >= xr:xl = 0xr = col_numcard_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh-yl)//4 else card_img[yl-(yh-yl)//4:yh, xl:xr]#以上为车牌定位#以下为识别车牌中的字符predict_result = []roi = Nonecard_color = Nonefor i, color in enumerate(colors):if color in ("blue", "yello", "green"):card_img = card_imgs[i]gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)#黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向if color == "green" or color == "yello":gray_img = cv2.bitwise_not(gray_img)ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)#查找水平直方图波峰x_histogram = np.sum(gray_img, axis=1)x_min = np.min(x_histogram)x_average = np.sum(x_histogram)/x_histogram.shape[0]x_threshold = (x_min + x_average)/2wave_peaks = find_waves(x_threshold, x_histogram)if len(wave_peaks) == 0:print("peak less 0:")continue#认为水平方向,最大的波峰为车牌区域wave = max(wave_peaks, key=lambda x:x[1]-x[0])gray_img = gray_img[wave[0]:wave[1]]#查找垂直直方图波峰row_num, col_num= gray_img.shape[:2]#去掉车牌上下边缘1个像素,避免白边影响阈值判断gray_img = gray_img[1:row_num-1]# cv2.imshow("gray_img", gray_img)#二值化# cv2.waitKey(0)y_histogram = np.sum(gray_img, axis=0)y_min = np.min(y_histogram)y_average = np.sum(y_histogram)/y_histogram.shape[0]y_threshold = (y_min + y_average)/5#U和0要求阈值偏小,否则U和0会被分成两半wave_peaks = find_waves(y_threshold, y_histogram)#车牌字符数应大于6if len(wave_peaks) <= 6:print("peak less 1:", len(wave_peaks))continuewave = max(wave_peaks, key=lambda x:x[1]-x[0])max_wave_dis = wave[1] - wave[0]#判断是否是左侧车牌边缘if wave_peaks[0][1] - wave_peaks[0][0] < max_wave_dis/3 and wave_peaks[0][0] == 0:wave_peaks.pop(0)#组合分离汉字cur_dis = 0for i,wave in enumerate(wave_peaks):if wave[1] - wave[0] + cur_dis > max_wave_dis * 0.6:breakelse:cur_dis += wave[1] - wave[0]if i > 0:wave = (wave_peaks[0][0], wave_peaks[i][1])wave_peaks = wave_peaks[i+1:]wave_peaks.insert(0, wave)#去除车牌上的分隔点point = wave_peaks[2]if point[1] - point[0] < max_wave_dis/3:point_img = gray_img[:,point[0]:point[1]]if np.mean(point_img) < 255/5:wave_peaks.pop(2)if len(wave_peaks) <= 6:print("peak less 2:", len(wave_peaks))continuepart_cards = seperate_card(gray_img, wave_peaks)for i, part_card in enumerate(part_cards):#可能是固定车牌的铆钉if np.mean(part_card) < 255/5:print("a point")continuepart_card_old = part_cardw = part_card.shape[1] // 3part_card = cv2.copyMakeBorder(part_card, 0, 0, w, w, cv2.BORDER_CONSTANT, value = [0,0,0])part_card = cv2.resize(part_card, (SZ, SZ), interpolation=cv2.INTER_AREA)cv2.destroyAllWindows()part_card = train.preprocess_hog([part_card])#preprocess_hog([part_card])if i == 0:resp = self.modelchinese.predict(part_card)#第一个字符调用中文svm模型charactor = train.provinces[int(resp[0]) - PROVINCE_START]else:resp = self.model.predict(part_card)#其他字符调用字母数字svm模型charactor = chr(resp[0])#判断最后一个数是否是车牌边缘,假设车牌边缘被认为是1if charactor == "1" and i == len(part_cards)-1:if part_card_old.shape[0]/part_card_old.shape[1] >= 8:#1太细,认为是边缘print(part_card_old.shape)continuepredict_result.append(charactor)roi = card_imgcard_color = colorbreakreturn predict_result, roi, card_color#识别到的字符、定位的车牌图像、车牌颜色if __name__ == '__main__':c = CardPredictor()c.load_svm()#加载训练好的模型img = cv2.imread("test\\car20.jpg")img = cv2.resize(img, (1000, 1000), interpolation=cv2.INTER_AREA)r, roi, color = c.predict(img)print(r)运行结果:
车牌颜色: blue
['津', 'N', 'A', 'V', '8', '8', '8']
从结果看比上一节的准确多了。
相关文章:
opencv 案例实战02-停车场车牌识别SVM模型训练及验证
1. 整个识别的流程图: 2. 车牌定位中分割流程图: 三、车牌识别中字符分割流程图: 1.准备数据集 下载车牌相关字符样本用于训练和测试,本文使用14个汉字样本和34个数字跟字母样本,每个字符样本数为40,样本尺…...

Vue实例挂载的过程
一、思考 我们都听过知其然知其所以然这句话 那么不知道大家是否思考过new Vue()这个过程中究竟做了些什么? 过程中是如何完成数据的绑定,又是如何将数据渲染到视图的等等 二、分析 首先找到vue的构造函数 源码位置:src\core\instance\…...

dvwa xss通关
反射型XSS通关 low难度 选择难度: 直接用下面JS代码尝试: <script>alert(/xss/)</script>通关成功: medium难度 直接下面代码尝试后失败 <script>alert(/xss/)</script>发现这段代码直接被输出: 尝试…...
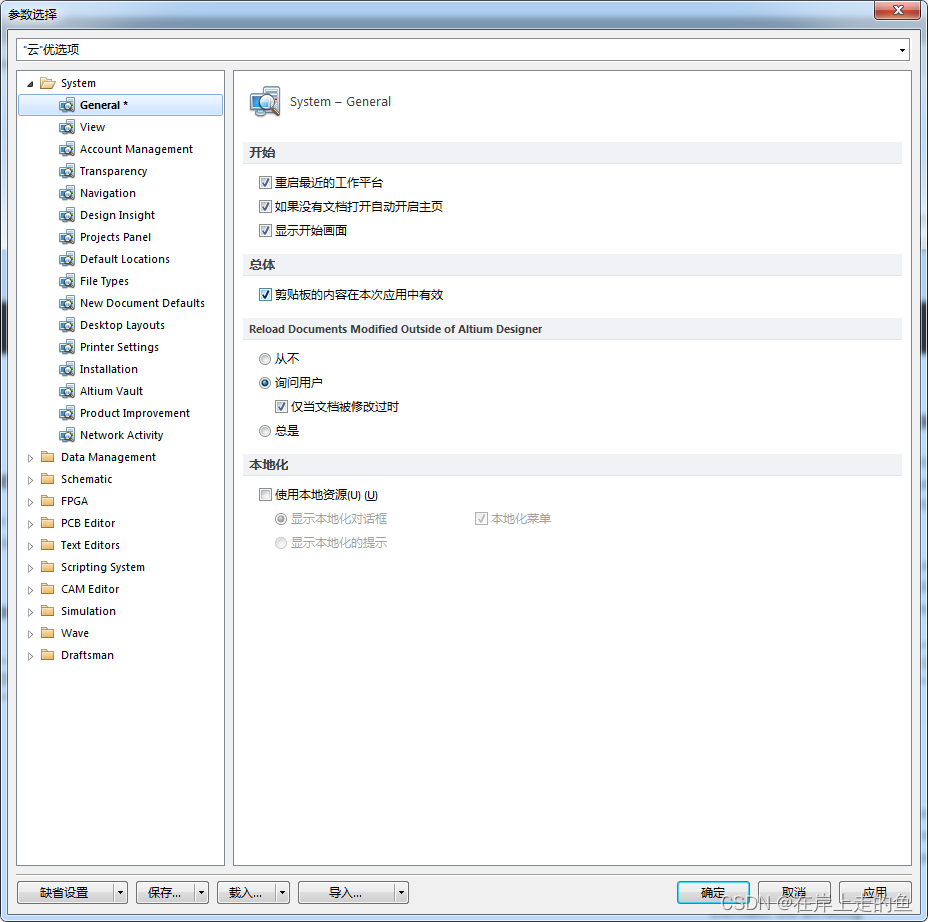
AD如何进行汉化
AD如何进行汉化 通过安装好AD后,默认都是英文界面模式,如果想汉化为中文模式,需要点击“DXP”->“参数选择”,打开界面如下: 然后将上图“本地化”下面的方框勾选上,点击“应用”,“确定”…...
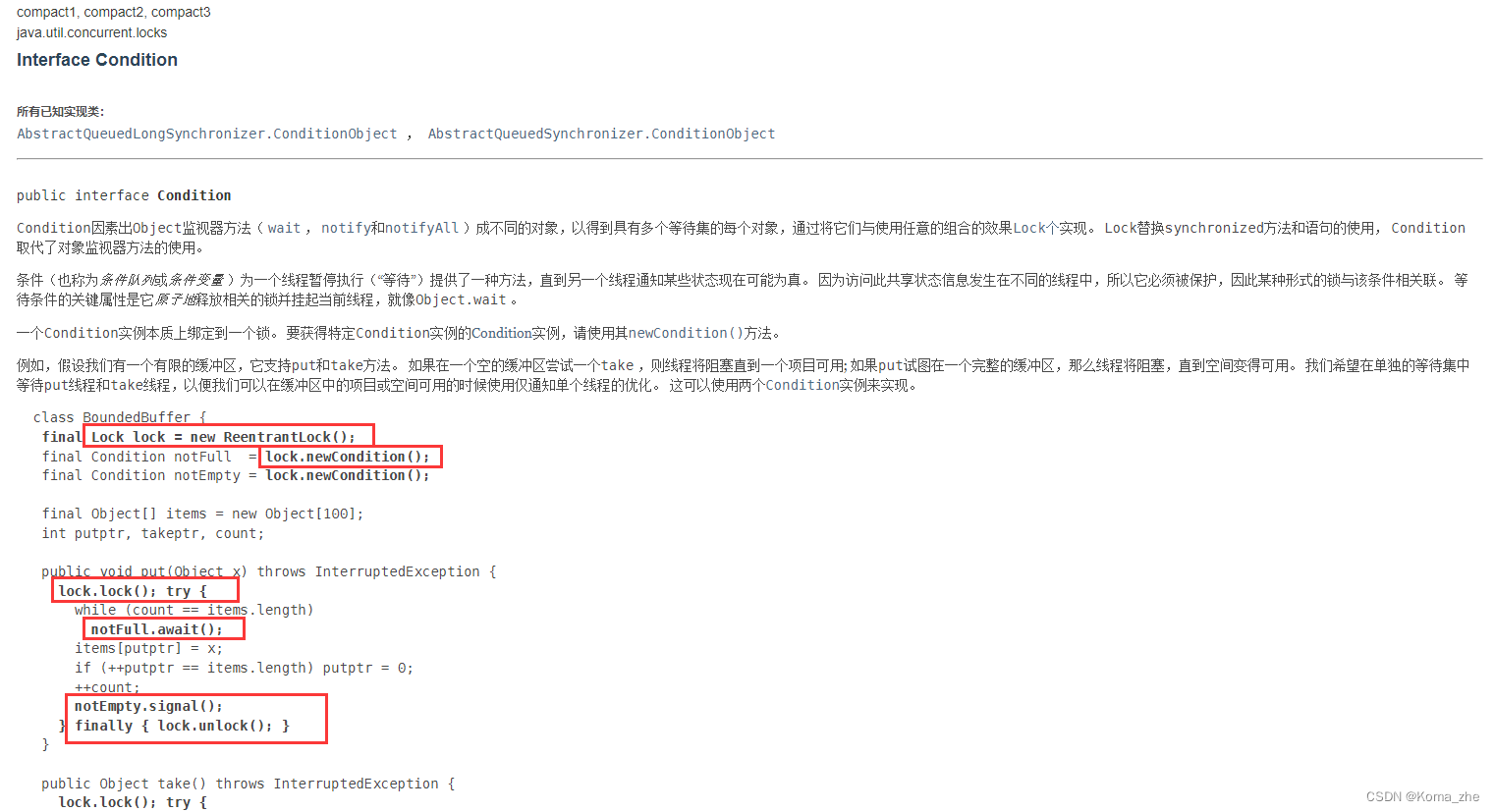
【JUC基础】JUC入门基础
目录 什么是JUC线程和进程锁传统的 synchronizedLock 锁Synchronized 与 Lock 的区别 生产者和消费者问题Synchronized 版Lock版Condition 的优势:精准通知和唤醒线程 8 锁现象问题1:两个同步方法,先执行发短信还是打电话?问题2&a…...

自然语言处理: 第十章GPT的API使用
理论基础 现在的以GPT为首的生成类模型,它拥有对话的能力,它会根据你输入的暗示(prompt)或者指令(instruct)生成对应的回答。所以,不同的输入会导致不同的输出(其实由于chatgpt最终生成的答案是beam_search 以及随机采样的机制,所…...
docker使用harbor进行镜像仓库管理演示以及部分报错解决
目录 一.安装harbor和docker-compose 1.下载 2.将该文件修改为这样,修改好自己的hostname和port,后文的用户和密码可以不改也可以改,用于登录 3.安装 二.修改daemon.json文件和/etc/hosts文件 三.使用powershell作windows端域名映射 四…...

【精算研究01/10】 计量经济学的性质和范围
一、说明 计量经济学是使用统计方法来发展理论或测试经济学或金融学中的现有假设。计量经济学依赖于回归模型和零假设检验等技术。计量经济学也可以用来预测未来的经济或金融趋势。 图片来源:https://marketbusinessnews.com 二、 计量经济之简介 计量经济学是对经济…...
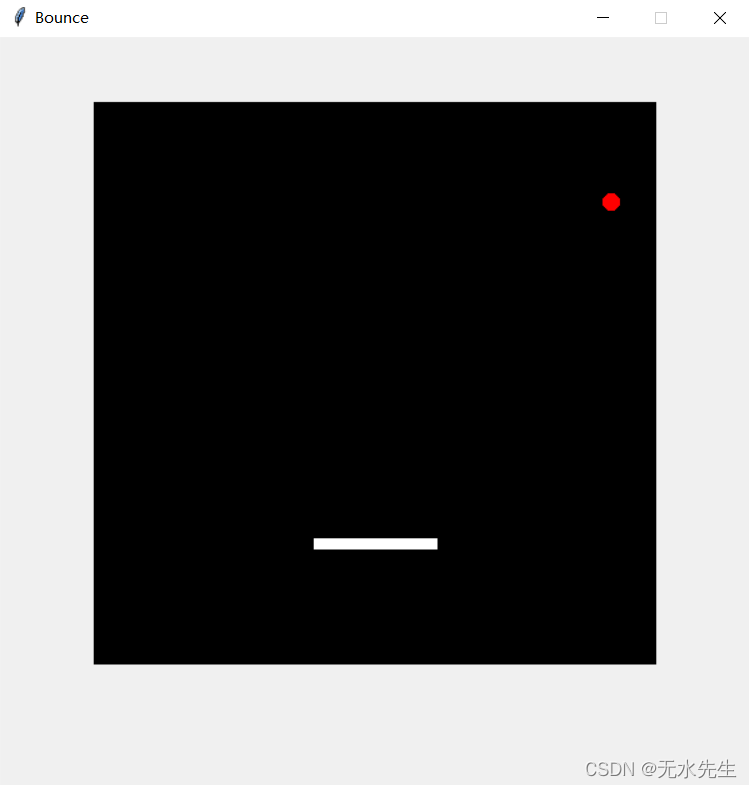
【python知识】用 Tkinter实现“剪刀-石头-布”和“弹球游戏 ”
一、提要 Tkinter是一个Python内置模块,它提供了一个简单易用的界面来创建GUI。 在实现一些动态的画面、如游戏还是需要一些创新性思维的。在本文中,我们将使用 Tkinter 探索 Python GUI 编程。我们将介绍 Tkinter 的基础知识,并演示如何使用…...

Android 绘制之文字测量
drawText() 绘制文字 绘制进度条:paint.strokeCap Paint.CAP.RONUD 线条两边样式 设置文字字体:paint.typeFace Resources.Compat.getFont(context,font) 设置加粗 paint.isFakeBoldText 设置居中: paint.setTextAlign Paint.Align.CENTER //居中, 并不是真正的居中 往…...
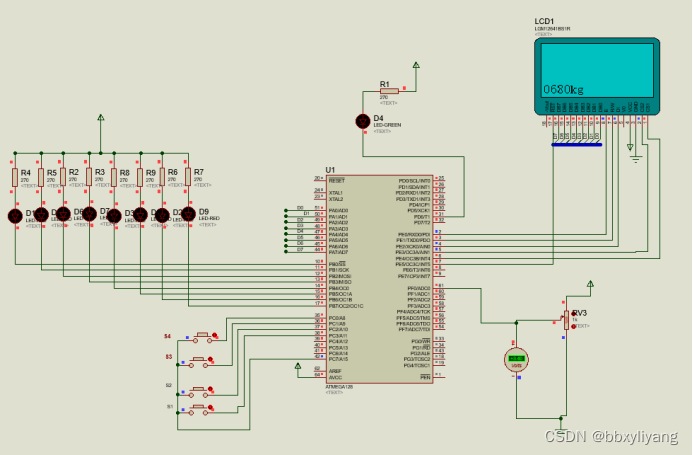
基于AVR128单片机智能传送装置
一、系统方案 1、板载可变电阻(电位器)R29的电压作为处理器ATmega128的模数转换模块中单端ADC0的模拟信号输入(跳线JP13短接)。 2、调节电位器,将改变AD转换接口ADC0的模拟信号输入,由处理器完成ADC0的A/D转…...
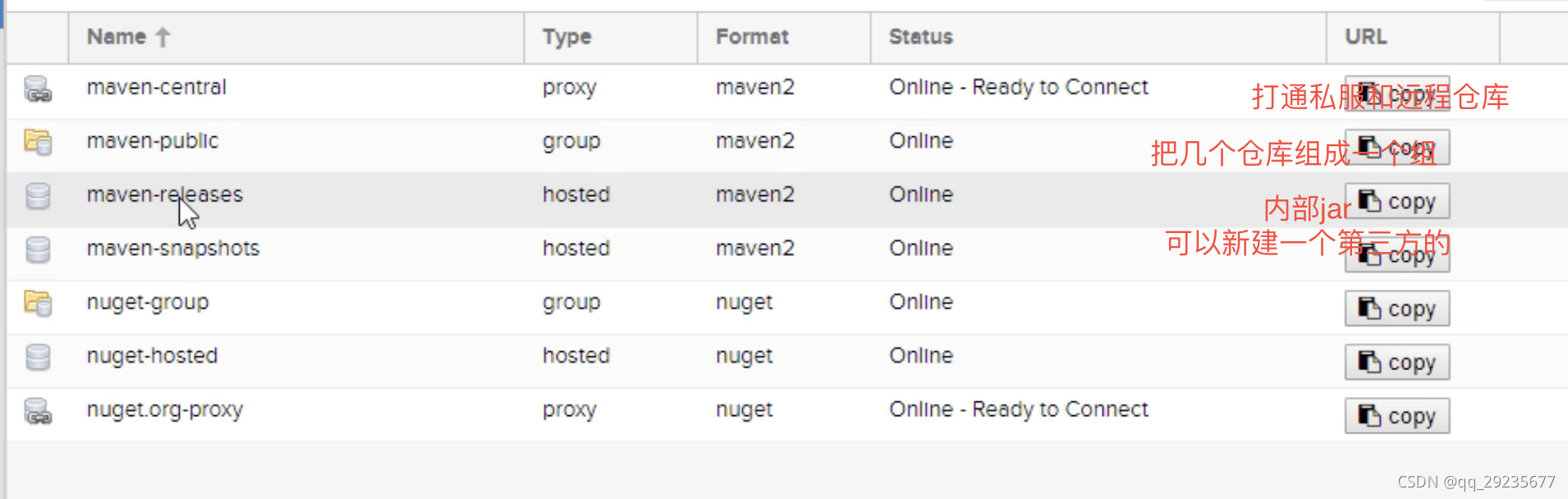
Nexus私有仓库+IDEA配置远程推送
目录 一、docker安装nexus本地私服,Idea通过maven配置deploy本地jar包(简单) 二、docker push镜像到第三方nexus远程私服(shell命令操作) 三、springboot通过maven插件自动生成docker镜像并push到nexus私服…...
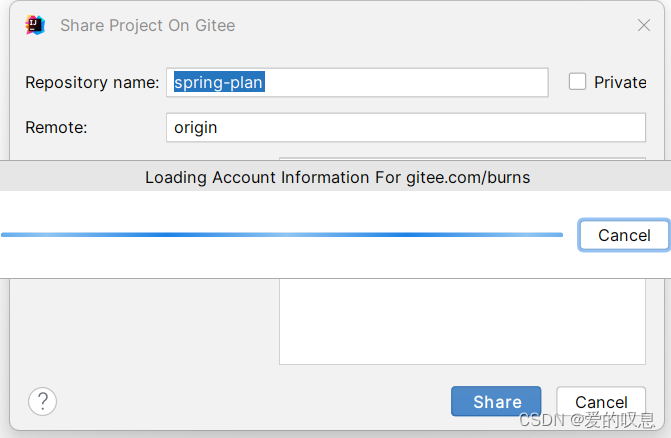
idea2023项目上传到gitee
1、按照gitee插件 File——>Settings plugins——>Marketplace下面搜索gitee,然后按照gitee插件 2、上传项目 VCS_——>Share Project on Gitee 如果第一次没登录的需要先登录,登录完后就可以上传了...
【golang】派生数据类型---指针 标识符、关键字等
1、指针 对比C/C中的指针,go语言中的指针显得极为简洁,只是简单的获取某个空间的地址 或者 根据指针变量中的内容 获取对应存储空间的内容等操作。 具体示例如下: go中使用指针需要注意的点: 可以通过指针改变它所指向的内存空…...

深度学习技术
深度学习是什么? 深度学习,英文名为Deep Learning,其实就是机器学习的一种高级形式。它的灵感来源于人脑神经网络的工作方式,是一种让机器可以自主地从数据中学习和提取特征的技术。你可以把它想象成一位小侦探,通过不…...
)
TCP/IP网络江湖——物理层护江山:网络安全的铁壁防线(物理层下篇:物理层与网络安全)
TCP/IP网络江湖——物理层护江山:网络安全的铁壁防线(物理层下篇:物理层与网络安全) 〇、引言一、物理层的隐私与保密1.1 加密技术的护盾1.2 安全传输协议的密约1.3 物理层的安全控制1.4 面对未知威胁的准备二、电磁干扰与抵御2.1 电磁干扰的威胁2.2 抗干扰技术的应用2.3 屏…...

python-数据可视化-使用API
使用Web应用程序编程接口 (API)自动请求网站的特定信息而不是整个网页,再对这些信息进行可视化 使用Web API Web API是网站的一部分,用于与使用具体URL请求特定信息的程序交互。这种请求称为API调用 。请求的数据将以易于处理的…...
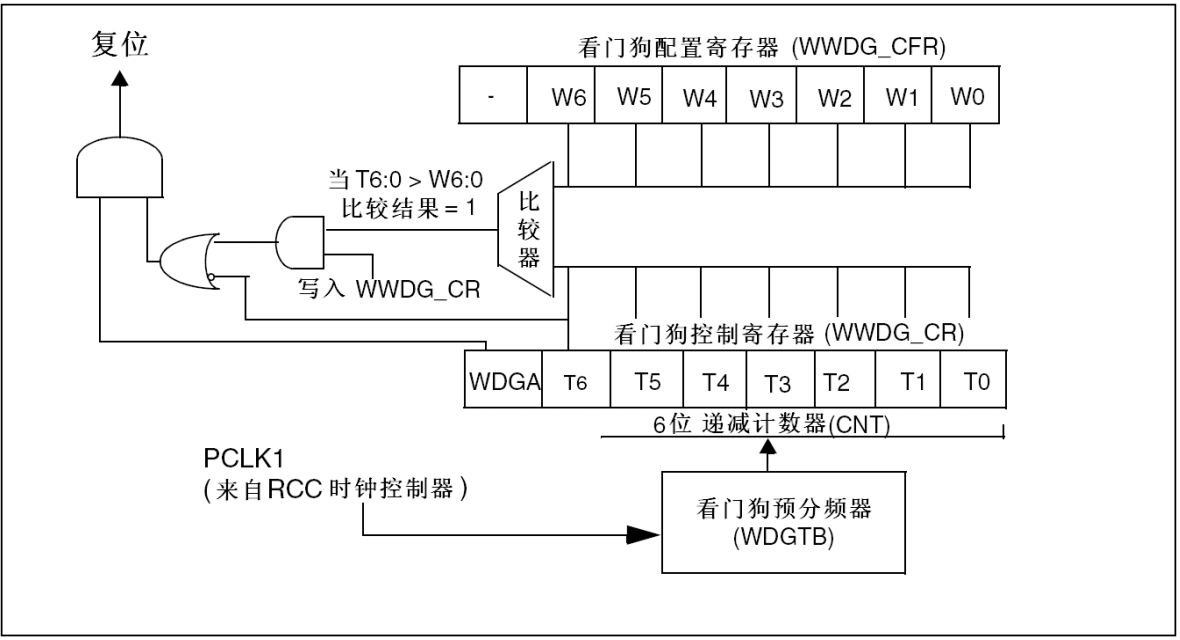
窗口看门狗
从下往上看: 1. 时钟设置 RCC_APB1PeriphClockCmd(RCC_APB1Periph_WWDG,ENABLE);//使能独立看门狗时钟 WWDG_SetPrescaler(WWDG_Prescaler_8);//看门狗预分频器WWDG counter clock (PCLK1/4096)/8 2.设置窗口值 实际就是设置WWDG_CR的低七位值, 但是这个值要大于0x40(也就是…...

开发新能源的好处
风能无论是总装机容量还是新增装机容量,全球都保持着较快的发展速度,风能将迎来发展高峰。风电上网电价高于火电,期待价格理顺促进发展。生物质能有望在农业资源丰富的热带和亚热带普及,主要问题是降低制造成本,生物乙…...
error: can‘t find Rust compiler
操作系统 win11 pip install -r requirements.txt 报错如下 Using cached https://pypi.tuna.tsinghua.edu.cn/packages/56/fc/a3c13ded7b3057680c8ae95a9b6cc83e63657c38e0005c400a5d018a33a7/pyreadline3-3.4.1-py3-none-any.whl (95 kB) Building wheels for collected p…...

ArchR实战避坑指南:从scATAC-seq数据到细胞轨迹分析,我的踩坑记录与参数调优心得
ArchR实战避坑指南:从scATAC-seq数据到细胞轨迹分析 当你在深夜第三次尝试用ArchR处理scATAC-seq数据时,突然弹出的红色报错信息是否让你感到绝望?作为一款强大的单细胞染色质可及性分析工具,ArchR的官方教程虽然详尽,…...

2026年工程师必知:20个AI核心术语,构建真正AI产品的第一性原理指南
面向真正构建AI产品的工程师——而非仅止于空谈者的第一性原理指南 坦诚而言,市面上绝大多数"AI术语汇编"类文章,其目标受众是那些希望在会议中显得见多识广的人。而本文,则专为那些真正动手构建的人而写。两者之间,存…...

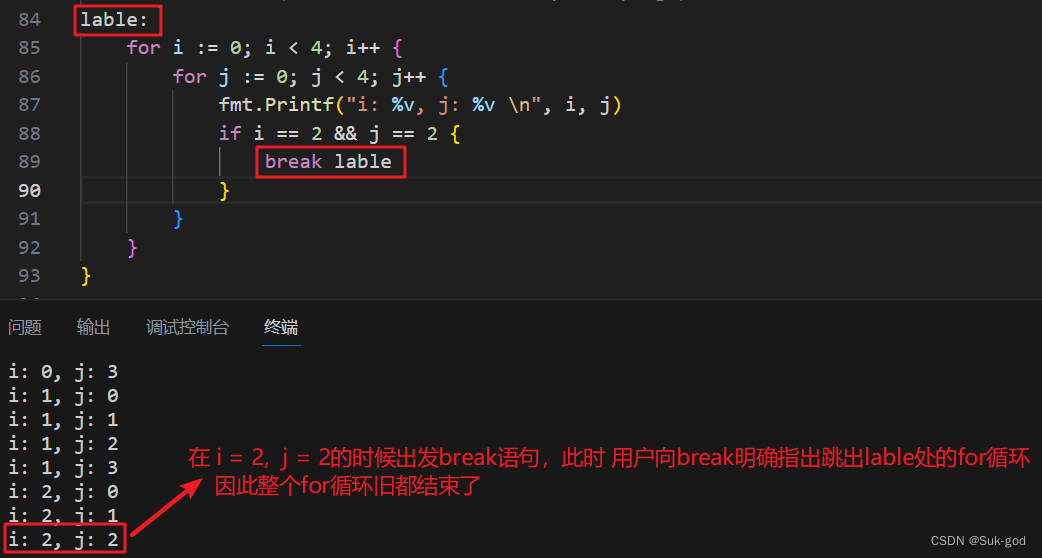
《B4003 [GESP202406 三级] 移位》
题目背景 对应的选择、判断题:https://ti.luogu.com.cn/problemset/1151 题目描述 小杨学习了加密技术移位,所有大写字母都向后按照⼀个固定数目进行偏移。偏移过程会将字母表视作首尾相接的环,例如,当偏移量是 3 的时候&#…...

ARM ETE Trace技术:非侵入式调试与TRCEVENTCTL寄存器详解
1. ARM ETE Trace技术概述在嵌入式系统开发中,调试和性能分析一直是极具挑战性的任务。传统的断点调试方式会中断程序执行流,难以捕捉实时性问题。ARM架构下的ETE(Embedded Trace Extension)技术通过非侵入式的指令跟踪机制,为开发者提供了强…...

首尔国立大学:AI读完“书“就扔掉笔记,竟比一直抄笔记更聪明?
这项由首尔国立大学数据科学研究生院主导的研究,以预印本形式发布于2026年5月,论文编号为arXiv:2605.06105,有兴趣深入了解的读者可以通过该编号查询完整论文。每次你问AI一个问题,它都要先把你给它的所有材料从头到尾读一遍&…...

前端技能树:从知识图谱到实战路径的系统学习指南
1. 项目概述:一个为掘金社区量身定制的技能树最近在GitHub上看到一个挺有意思的项目,叫Wscats/juejin-skills。光看名字,你可能会以为这是一个教你如何在掘金社区写爆款文章、玩转运营的“秘籍”。但点进去之后,你会发现它的内涵远…...

第26课:OpenClaw|日志审计与问题诊断
文章目录26.1 OpenClaw的日志体系与日志级别日志的“两个表面”日志级别的分层逻辑WebSocket日志的三级样式Cache-Trace日志:穿透Agent上下文的黑盒26.2 工作目录中的.jsonl日志文件分析三类关键日志文件读取日志的三种方式三类日志的关联追踪法26.3 结构化日志的收…...
)
iOS Swift 推送通知完整实现教程(前台/后台/杀死状态 全覆盖跳转)
一、前言 远程推送通知是iOS开发中高频必备功能,绝大多数App都需要实现推送消息提醒、点击通知跳转指定业务页面。iOS推送分为三种运行状态,开发中必须全部兼容:前台运行:App处于打开状态,直接接收推送弹窗后台挂起&am…...

2000-2024年上市公司产学研合作数据
产学研合作(University-Industry Collaboration, UIC)是衡量企业与高校及科研机构协同创新程度的核心指标。本数据集基于中国上市公司年度报告中披露的客户及合作方清单构建,由团队依据公开披露信息测算,时间覆盖20002024年。核心…...

EPUB转有声书:基于Python的自动化实现与TTS技术实践
1. 项目概述:从电子书到有声书的自动化转换 作为一名长期与数字内容打交道的开发者,我经常遇到一个需求:如何高效地将海量的 EPUB 电子书转换成方便“听”的有声书?无论是通勤路上、做家务时,还是想保护视力的时候&am…...