基于深度神经网络的分类--实现与方法说明
1、分类系统的设计
采用神经网络进行分类需要考虑以下几个步骤:
-
数据预处理: 将数据特征参数和目标数据整理成合适的输入和输出形式,可以使用过去一段时间的数据作为特征,然后将未来的数据作为输出标签,进行分类问题的预测。
-
神经网络架构: 本文是一个简化的多层神经网络架构:
- 输入层:节点数量等于特征参数的数量。
- 隐含层:可以根据实际情况增加多个隐含层,每个隐含层的节点数量可以根据经验或者调参进行设置。隐含层的激活函数可以选择ReLU等。
- 输出层:节点数量为3,对应高、中、低三个分类。
-
损失函数和优化器: 针对分类问题,可以选择交叉熵损失函数。常见的优化器有Adam、SGD等。损失函数的选择和优化器的调参可能需要多次尝试,以找到合适的组合。
-
数据集划分: 将数据集划分为训练集、验证集和测试集。训练集用于训练模型参数,验证集用于调整超参数,测试集用于评估模型性能。
-
模型训练: 使用训练集进行神经网络的训练,通过反向传播算法更新模型参数。
-
超参数调优: 调整神经网络的超参数,如隐含层节点数量、学习率、正则化等,以获得更好的模型性能。
-
模型评估: 使用测试集评估模型的性能,可以计算准确率、精确率、召回率等指标来评估模型的预测能力。
2、代码实现
以下是一个使用Keras库实现上述神经网络设计的python代码:
import numpy as np
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adam# 生成示例数据,特征参数和分类标签
num_samples = 1000
num_features = 7X = np.random.rand(num_samples, num_features)
y = np.random.choice([-1, 0, 1], num_samples) # -1: 低,0: 中,1: 高# 将标签转化为独热编码
y_onehot = np.zeros((num_samples, 3))
for i in range(num_samples):y_onehot[i, y[i] + 1] = 1# 划分训练集、验证集和测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y_onehot, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)# 创建神经网络模型
model = Sequential()
model.add(Dense(64, input_dim=num_features, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(3, activation='softmax'))# 编译模型
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_val, y_val))# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("Test loss:", loss)
print("Test accuracy:", accuracy)
3、神经网络的构建与说明
在神经网络中,各个层之间的连接是通过神经元(节点)来实现的。每个层都可以有多个神经元,而每个神经元都与上一层的所有神经元相连接。
具体来说,上述代码中构建了一个多层前馈神经网络(Feedforward Neural Network),其中包含三个全连接层(Dense层),每个层都包含一些神经元。以下是对每个层的解释:
-
model.add(Dense(64, input_dim=num_features, activation='relu')):
这是第一层,包含64个神经元。input_dim参数指定输入的特征数量,即num_features。activation='relu'表示使用ReLU(Rectified Linear Unit)作为激活函数,它可以引入非线性性到网络中。 -
model.add(Dense(32, activation='relu')):
这是第二层,包含32个神经元。不需要再指定input_dim,因为这是在前面的层中自动推断得出的。同样,使用ReLU作为激活函数。 -
model.add(Dense(3, activation='softmax')):
这是输出层,包含3个神经元,对应涨、平、跌三个分类。activation='softmax'将输出转换成一个概率分布,用于多分类问题。
每个神经元在每一层接收来自上一层所有神经元的输入,并根据权重和激活函数计算输出。这样,通过多层的组合,模型可以学习输入特征与输出标签之间的复杂关系,从而实现预测任务。
4、神经元的选择
神经网络的层和神经元数量的选择通常是基于经验、实验和问题的性质来决定的。在上述代码中,使用64个神经元作为输入层和32个神经元作为中间层的设计是基于以下一些原因:
-
逐渐减少神经元数量: 在深度神经网络中,通常会逐渐减少神经元的数量,因为随着层数的增加,每个神经元需要处理更抽象的特征。开始时使用更多的神经元可以帮助网络更好地捕捉输入数据中的细节,然后逐渐减少神经元的数量以获取更高级别的特征表示。
-
减小模型复杂度: 选择适当数量的神经元可以控制模型的复杂度,避免过拟合问题。过多的神经元可能导致模型过于复杂,容易出现过拟合,而过少的神经元可能无法捕捉数据中的关键特征。
-
计算效率: 减少神经元数量可以提高训练和推理的计算效率。过多的神经元可能导致计算负担过重,影响模型的速度和性能。
-
调试和优化: 使用适度数量的神经元可以更容易地调试和优化模型,通过较少的参数进行调整,使得模型的训练和调参过程更加稳定。
神经网络的设计是一个迭代和实验的过程。一般是根据实际情况尝试不同的层数和神经元数量,通过验证集和测试集的性能来选择最佳的网络结构。
5、选择激活函数
选择合适的激活函数(activation function)是神经网络设计中的重要决策,激活函数用于引入非线性性,使神经网络能够处理复杂的数据模式和关系。不同的激活函数适用于不同的场景,常见的激活函数包括:
-
ReLU(Rectified Linear Unit):
activation='relu'- 优点:计算高效,训练速度较快;在大多数情况下表现良好,能够有效地缓解梯度消失问题。
- 适用:通常作为中间隐含层的激活函数。
-
Sigmoid:
activation='sigmoid'- 优点:输出范围在0到1之间,适用于二分类问题。
- 缺点:容易出现梯度消失问题,不适用于深度神经网络。
-
Tanh(双曲正切函数):
activation='tanh'- 优点:输出范围在-1到1之间,能够将输入映射到更广的范围,适用于数据归一化。
- 适用:通常作为中间隐含层的激活函数。
-
Softmax:
activation='softmax'- 用于多分类问题,将多个神经元的输出映射到概率分布,适用于输出层。
-
Leaky ReLU 和 Parametric ReLU:
activation=LeakyReLU(alpha=0.01)或activation=PReLU()- 解决 ReLU 的死亡神经元问题,通过允许小于0的激活值,但不过度降低负数激活值的梯度。
- 可以在一些情况下改善训练稳定性和收敛性。
在选择激活函数时,你可以根据以下方法进行决策:
-
基于问题性质: 根据你的问题类型和数据分布,选择适合的激活函数。例如,分类问题可以使用 Sigmoid 或 Softmax,回归问题可以使用 ReLU 或 Tanh。
-
经验法则: ReLU 在大多数情况下都表现良好,通常是首选。如果遇到梯度消失问题,可以尝试 Leaky ReLU 或 Parametric ReLU。
-
尝试多个激活函数: 你可以尝试在不同层使用不同的激活函数,并根据验证集的性能来选择最佳的组合。
总之选择合适的激活函数需要根据问题的性质、实验和验证来决定。在设计神经网络时,通常会结合多种激活函数以获得更好的性能。
6、选择epochs和batch_size
选择合适的epochs(训练轮数)和batch_size(批大小)是神经网络训练中的重要参数。它们的选择通常是基于经验、问题的性质以及试验来决定的,常见的方法和经验包括:
Epochs(训练轮数):
- 少训练轮数: 如果训练轮数太少,模型可能没有足够的机会学习数据中的模式和特征,欠拟合的可能性较高。
- 适当训练轮数: 通常,训练轮数应该足够让模型充分学习数据,但不要过多,以免过拟合。可以尝试增加训练轮数直到验证集上的性能不再提升为止。
- 过多训练轮数: 如果训练轮数过多,模型可能开始过拟合,即在训练集上表现良好,但在验证集上表现不佳。
一种常见的方法是使用早停法(Early Stopping),在验证集性能不再提升时停止训练。这有助于避免过拟合。
Batch Size(批大小):
- 大batch_size: 使用大批大小可以加快训练速度,但可能会导致内存消耗增加。较大的批大小还可能在一些情况下使模型更快地收敛,但可能会损失一些泛化能力。
- 小batch_size: 使用小批大小可以更好地利用每个样本的信息,有助于更好地收敛到局部最优解。但小批大小可能会导致训练过程更加嘈杂,需要更多的迭代。
一般是在训练过程中尝试不同的批大小,观察模型在训练集和验证集上的性能,并选择性能最佳的批大小。
综合来看,选择合适的epochs和batch_size通常需要通过实验和验证集上的性能来确定。可以尝试不同的值,观察模型在训练和验证集上的表现,以找到使模型在训练集和验证集上均表现良好的参数组合。
7、选择optimizer和loss
在编译神经网络模型时,选择合适的优化器(optimizer)和损失函数(loss function)是非常重要的。它们的选择通常基于问题类型、网络结构以及实验来决定。常见的优化器和损失函数包括:
优化器(Optimizer):
-
Adam:
optimizer=Adam(learning_rate=0.001)- 优点:Adam 是一种自适应学习率的优化算法,通常在各种问题上表现良好。它结合了 AdaGrad 和 RMSProp 的优势,适用于大多数场景。
- 适用:作为默认的优化器选择,通常能够快速收敛到局部最优解。
-
SGD(Stochastic Gradient Descent):
optimizer=SGD(learning_rate=0.01)- 优点:经典的优化算法,可以通过调整学习率逐渐收敛到最优解。
- 缺点:可能会在训练初期震荡较大,收敛速度较慢,需要仔细调参。
- 适用:当计算资源有限时,或需要更精细的学习率调整时。
-
其他优化器: 如 RMSProp、Adagrad、Adadelta 等,可以根据实际情况进行选择和尝试。
损失函数(Loss Function):
-
均方误差(Mean Squared Error,MSE):
loss='mean_squared_error'- 适用:适合回归问题,优化目标是最小化预测值与真实值之间的平方差。
-
交叉熵损失(Categorical Cross-Entropy,Binary Cross-Entropy):
loss='categorical_crossentropy'- 适用:适合多分类或二分类问题,优化目标是最小化预测概率分布与真实标签之间的差异。
-
其他损失函数: 如 Huber Loss、自定义的损失函数等,可以根据问题特性选择适当的损失函数。
选择优化器和损失函数的方法和原则:
- 问题类型: 根据问题是回归、分类还是其他类型,选择对应的损失函数。
- 优化效果: 通过实验和验证集的性能,观察不同优化器和损失函数的效果,选择性能最佳的组合。
- 学习率: 在使用 Adam、SGD 等优化器时,调整学习率可以影响模型的训练速度和稳定性。需要进行实验找到合适的学习率。
- 调参: 在实际应用中,你可能需要尝试不同的优化器和损失函数组合,并进行超参数调优,以找到最佳的模型性能。
最终选择的优化器和损失函数应该通过实验和验证来决定,以获得在验证集上表现最佳的模型。
相关文章:

基于深度神经网络的分类--实现与方法说明
1、分类系统的设计 采用神经网络进行分类需要考虑以下几个步骤: 数据预处理: 将数据特征参数和目标数据整理成合适的输入和输出形式,可以使用过去一段时间的数据作为特征,然后将未来的数据作为输出标签,进行分类问题的…...
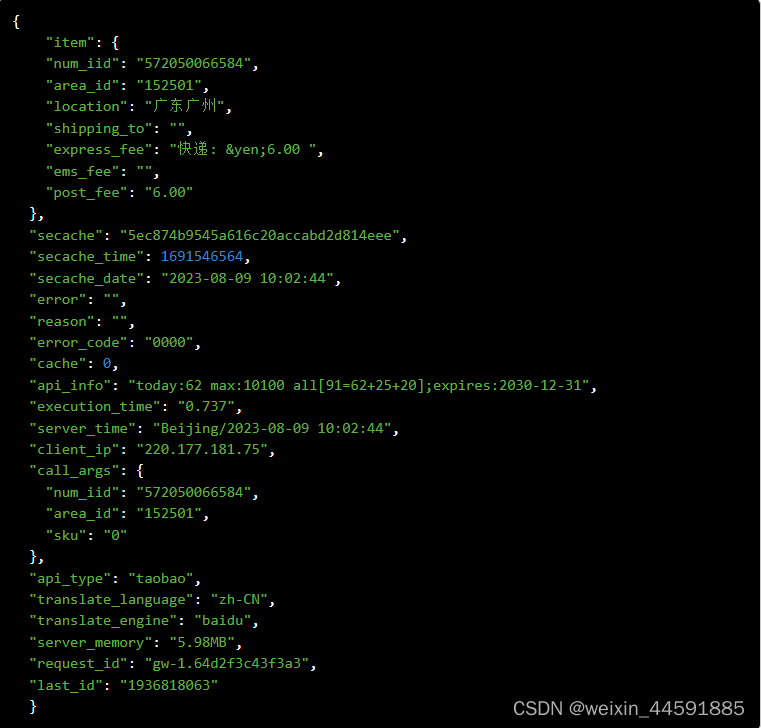
Java“牵手”天猫商品快递费用API接口数据,天猫API接口申请指南
天猫平台商品快递费用接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取天猫商品的标题、价格、库存、商品快递费用,宝贝ID,发货地,区域ID,快递费用,月销量、总销量、库存、详情…...

哲讯科技携手无锡华启动SCM定制化项目,共谋数字化转型之路
无锡华光座椅弹簧有限公司启动SCM定制化项目 近日,无锡华光座椅弹簧有限公司顺利举行了SCM定制化项目的启动会。本次启动会作为该项目实施的重要里程碑,吸引了双方项目组核心成员的共同参与,并见证了项目的正式启动。 无锡华光座椅弹簧有限公…...

ModaHub魔搭社区:将图像数据添加至Milvus Cloud向量数据库中
将图像数据添加至向量数据库中 图像分割裁剪完成后,我们就可以将其添加至 Milvus Cloud 向量数据库中了。为了方便上手,本项目中使用了 Milvus Lite 版本,可以在 notebook 中运行 Milvus 实例。接下来,使用 PyMilvus 连接至 Milvus Lite 提供的默认服务器。 这一步骤中,…...
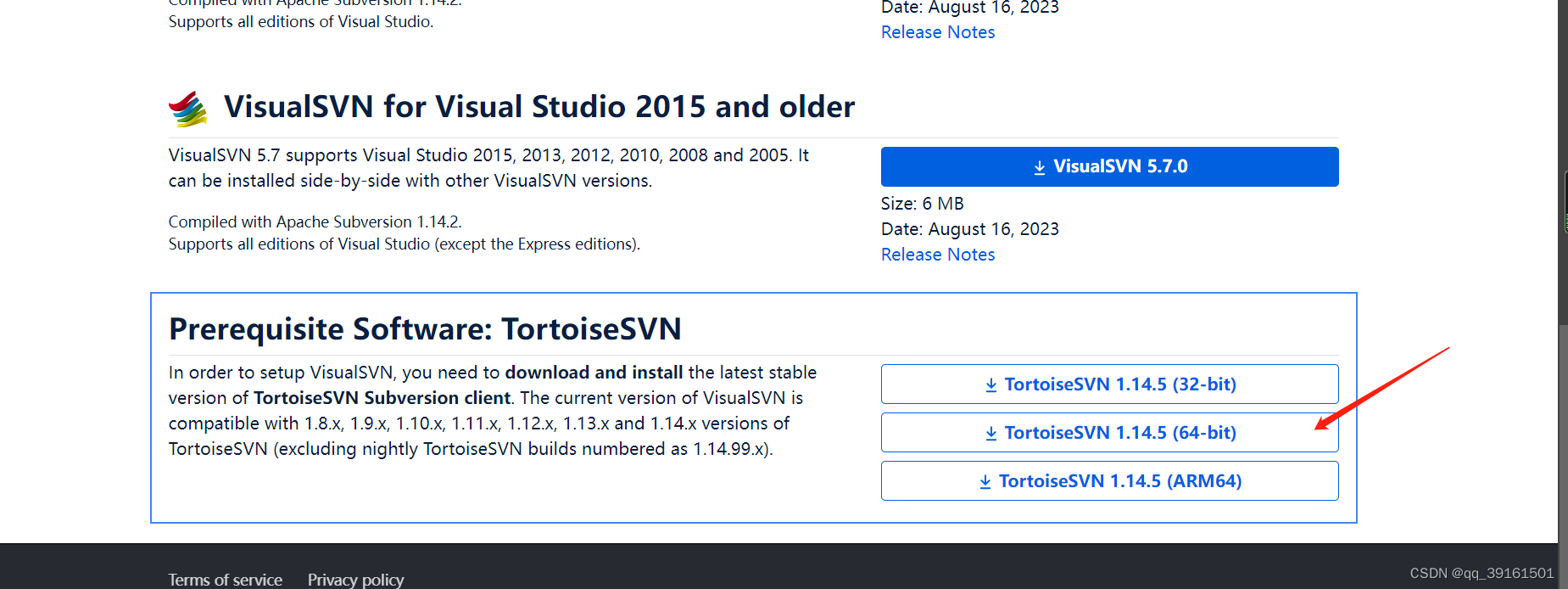
svn下载
Download | VisualSVN for Visual Studio svn下载...

为什么说es是近实时搜索
首先要理解es的存储结构: 一个index的数据,分散在多个shard(分片),一个分片又有很多segment(段),es是数据不可变模型,更新数据只是新增一个版本。 es是怎么写数据的? 每次写的时候,首先会写到…...

程序自动分析——并查集+离散化
在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足。考虑一个约束满足问题的简化版本:假设 x1,x2,x3,… 代表程序中出现的变量,给定 n 个形如 xixj 或 xi≠xj 的变量相等/不等的约束条件,请判定是否可以分别为…...
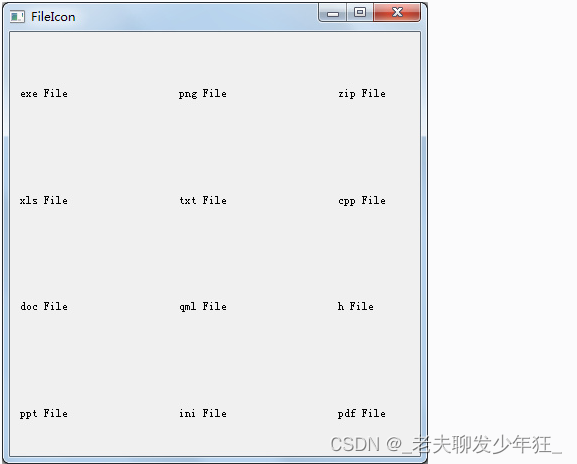
Qt 获取文件图标、类型 QFileIconProvider
Qt中获取系统图标、类型是通过QFileIconProvider来实现的,具体如下: 一、Qt获取系统文件图标1、获取文件夹图标QFileIconProvider icon_provider;QIcon icon icon_provider.icon(QFileIconProvider::Folder);2、获取指定文件图标QFileInfo file_info(n…...
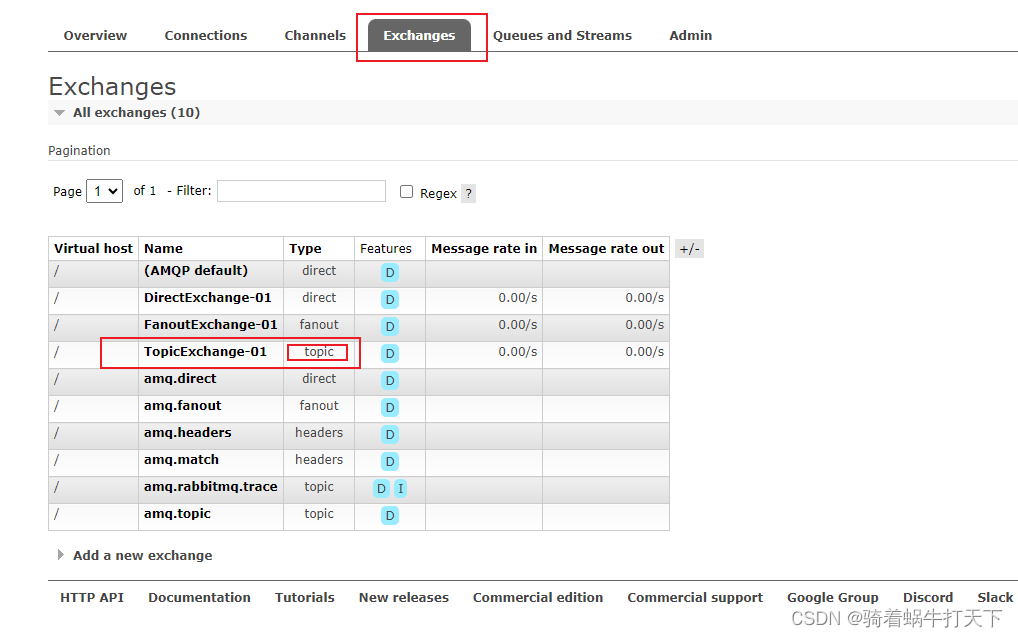
TopicExchange主题交换机
目录 一、简介 二、代码展示 父pom文件 pom文件 配置文件 config 生产者 消费者 测试 结果 一、简介 主题交换机,这个交换机其实跟直连交换机流程差不多,但是它的特点就是在它的路由键和绑定键之间是有规则的。 简单地介绍下规则࿱…...

A Survey on Large Language Models for Recommendation
本文是LLM系列的文章,针对《A Survey on Large Language Models for Recommendation》的翻译。 大模型用于推荐的综述 摘要1 引言2 建模范式和分类3 判别式LLM用于推荐4 生成式LLM用于推荐5 发现6 结论 摘要 大型语言模型(LLM)作为自然语言…...

Springboot 入门指南:控制反转和依赖注入的含义和实现方式
目录 一、什么是控制反转(IoC)? 二、什么是依赖注入(DI)? 三、如何在 springboot 中使用 IoC 和 DI? 总结 一、什么是控制反转(IoC)? 控制反转ÿ…...

使用Tampermonkey(篡改猴)向页面注入js脚本
一、Tampermonkey 简单介绍 Tampermonkey是一款浏览器插件,适用于Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox。他允许我们自定义javascript给指定网页添加功能,或修改现有功能。也可以用来辅助调试,或去除网页广告等。 官网地…...

软考高级系统架构设计师系列之:论文典型试题写作要点和写作素材总结系列文章二
软考高级系统架构设计师系列之:论文典型试题写作要点和写作素材总结系列文章二 一、论基于DSSA的软件架构设计与应用1.论文题目2.写作要点和写作素材二、论信息系统建模方法1.论文题目2.写作要点和写作素材三、论高可靠性系统中软件容错技术的应用1.论文题目2.写作要点和写作素…...
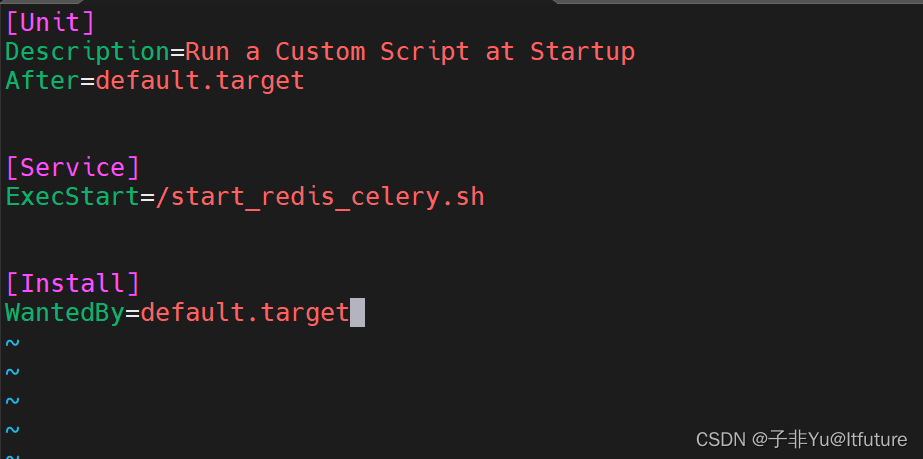
【Linux】如何在linux系统重启或启动时执行命令或脚本(也支持docker容器内部)
如何在linux系统重启或启动时执行命令或脚本(也支持docker容器内部) 第一种:使用 systemd 服务单元在重启或启动时运行命令或脚本第二种:使用 /etc/rc.d/rc.local 文件在重启或启动时运行脚本或命令第三种:使用 cronta…...

医疗中心管理环境温湿度,这样操作就对了!
随着医疗技术的不断发展,越来越多的医疗设备对于稳定的工作环境要求越来越高,而环境温湿度是影响这些设备性能和可靠性的关键因素之一。 为了确保医疗设备的正常运行和患者的安全,医疗机构越来越倾向于采用精密空调监控系统来维护设备的稳定性…...
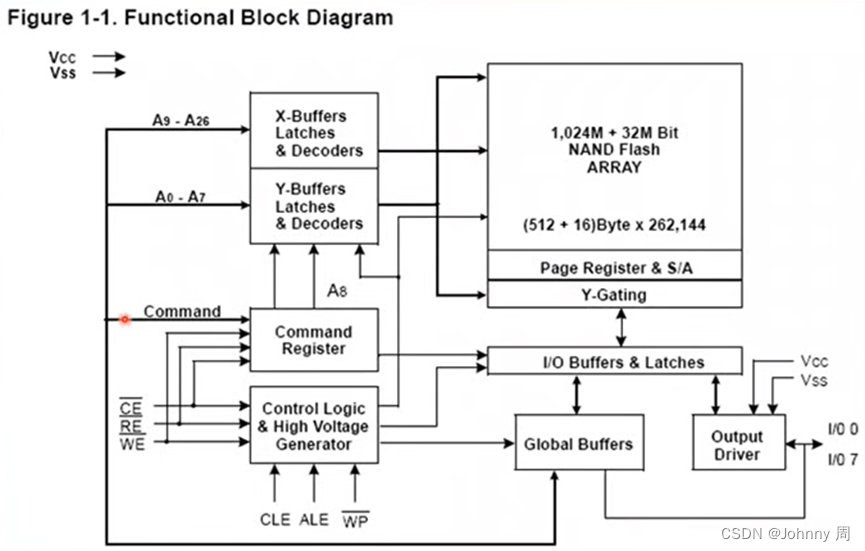
嵌入式系统存储体系
一、存储系统概述 主要分为三种:高速缓存(cache)、主存和外存。 二、高速缓存Cache 高速缓冲存储器中存放的是当前使用得最多得程序代码和数据,即主存中部分内容的副本,其本身无自己的地址空间。在嵌入式系统中Cac…...

【Java架构-版本控制】-Gitlab安装
本文摘要 Git作为版本控制工具,使用非常广泛,在此咱们由浅入深,分三篇文章(Git基础、Git进阶、Gitlab搭那家)来深入学习Git 文章目录 本文摘要1. docker接取镜像2. docker启动镜像3. 配置启动端口和ssh端口4. 获取初始…...
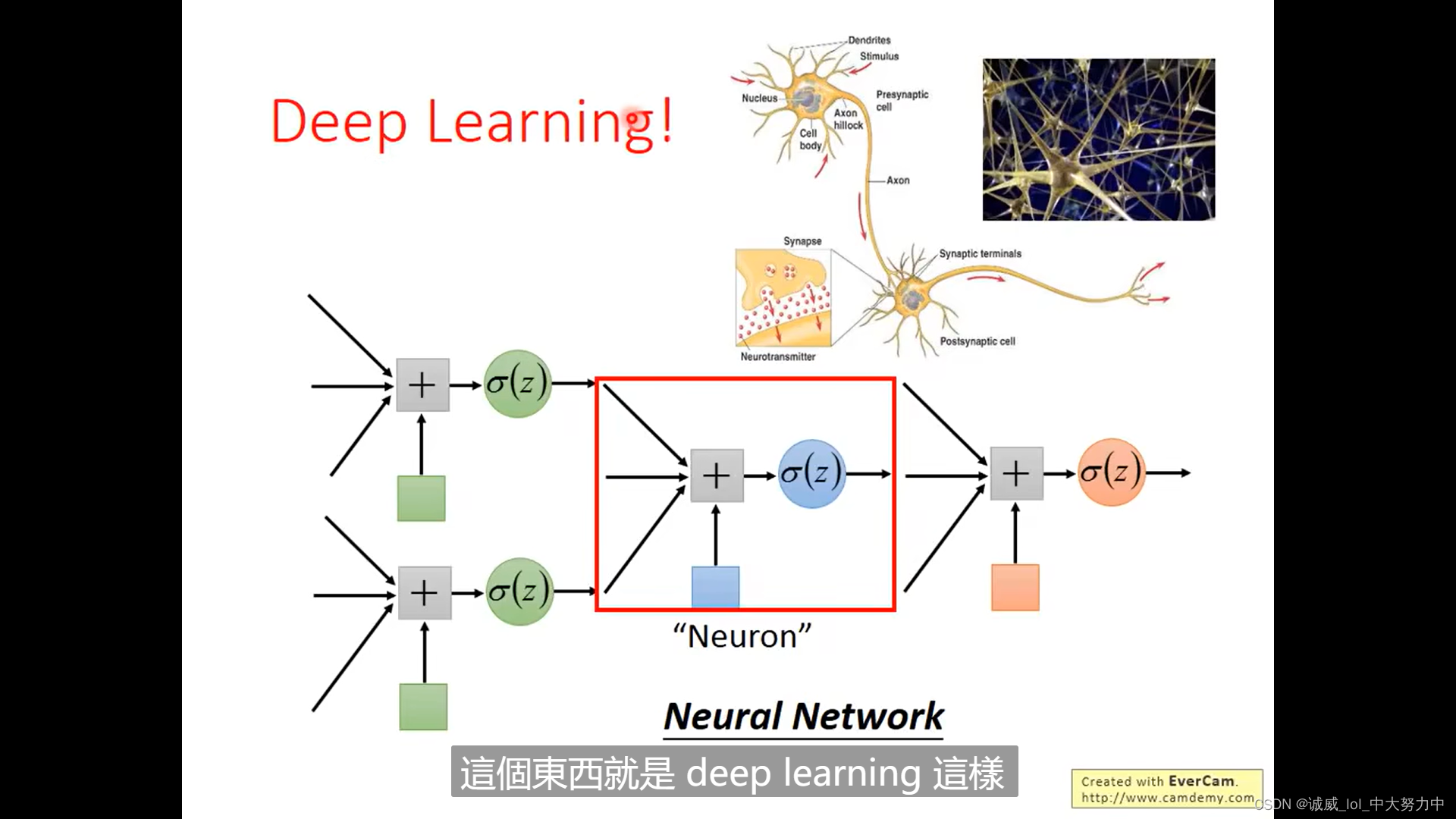
关于disriminative 和 generative这两种模型
但是,其实,根据李宏毅老师讲到的,generative model是做了一些假设的,比如,如果使用Naive Bayes的话,不同特征x1,x2...之间相互独立的话,其实是很容易出现较大的偏差的,因为不同特征变…...
关于Java中@Transient主键的作用的一些介绍
Transient主下面是关于Transient主键的使用方法、代码案例以及与transient关键字的区别,以及一些实用场景的详细介绍。 1. Transient主键的作用 在实体类中,通常需要将某些字段标记为主键,并将其映射到数据库中的主键字段。但是,…...
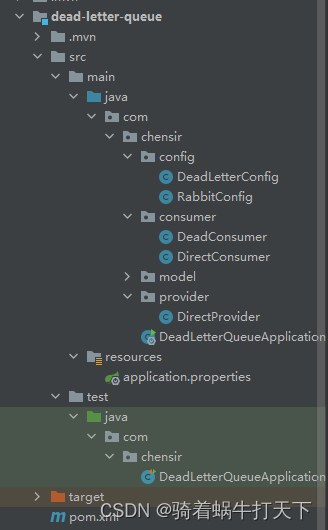
死信队列理解与使用
一、简介 在rabbitMQ中常用的交换机有三种,直连交换机、广播交换机、主题交换机; 直连交换机中队列与交换机需要约定好routingKey去进行绑定; 广播交换机并不需要routingKey绑定,只需队列与交换机绑定即可; 主题交换机最大的特…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

Windows鼠标指针主题定制:从.cur/.ani文件到个性化交互体验
1. 项目概述:一个为Windows终端注入灵魂的鼠标指针主题如果你和我一样,每天有超过8小时的时间是与Windows操作系统相伴的,那么你对那个千篇一律的白色箭头鼠标指针,恐怕早已感到审美疲劳。它就像一个沉默的、功能性的背景板&#…...
基于CircuitPython与NeoPixel打造可编程LED亚克力灯牌:从硬件选型到代码实现
1. 项目概述:打造你的专属可编程光之铭牌在创客和电子爱好者的世界里,总有一些项目能完美地融合软件编程的灵活性与硬件制作的实体成就感。今天要分享的,就是这样一个让我爱不释手的小玩意儿:一个基于CircuitPython和NeoPixel的可…...

成本优化策略:降低云资源支出
成本优化策略:降低云资源支出 一、成本优化策略概述 1.1 成本优化策略的定义 成本优化策略是指通过各种技术和管理手段,降低云资源支出的策略和方法。它包括资源优化、成本监控、预算管理和采购策略等方面。 1.2 成本优化策略的价值 成本降低:…...