“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提供全套的训练、微调模型(包括大模型、文本转向量、文本生成、多模态等模型)的解决方案;数据:- 从开源社区,整理了海量的训练数据,帮助用户可以快速上手;
- 同时也开放训练数据模版,可以快速处理垂直领域数据;
- 结合多线程、内存映射等更高效的数据处理方式,即使需要处理
百GB规模的数据,也是轻而易举;
流程:每一个项目有完整的模型训练步骤,如:数据清洗、数据处理、模型构建、模型训练、模型部署、模型图解;模型:当前已经支持gpt2、clip、gpt-neox、dolly、llama、chatglm-6b、VisionEncoderDecoderModel等多模态大模型;多卡串联
:当前,多数的大模型的尺寸已经远远大于单个消费级显卡的显存,需要将多个显卡串联,才能训练大模型、才能部署大模型。因此对部分模型结构进行修改,实现了训练时、推理时
的多卡串联功能。
- 模型训练
| 中文名称 | 文件夹名称 | 数据 | 数据清洗 | 大模型 | 模型部署 | 图解 |
|---|---|---|---|---|---|---|
| 中文文本分类 | chinese_classifier | ✅ | ✅ | ✅ | ❌ | ✅ |
中文gpt2 | chinese_gpt2 | ✅ | ✅ | ✅ | ✅ | ❌ |
中文clip | chinese_clip | ✅ | ✅ | ✅ | ❌ | ✅ |
| 图像生成中文文本 | VisionEncoderDecoderModel | ✅ | ✅ | ✅ | ❌ | ✅ |
| vit核心源码介绍 | vit model | ❌ | ❌ | ❌ | ❌ | ✅ |
Thu-ChatGlm-6b(v1) | simple_thu_chatglm6b | ✅ | ✅ | ✅ | ✅ | ❌ |
🌟chatglm-v2-6b🎉 | chatglm_v2_6b_lora | ✅ | ✅ | ✅ | ❌ | ❌ |
中文dolly_v2_3b | dolly_v2_3b | ✅ | ✅ | ✅ | ❌ | ❌ |
中文llama | chinese_llama | ✅ | ✅ | ✅ | ❌ | ❌ |
中文bloom | chinese_bloom | ✅ | ✅ | ✅ | ❌ | ❌ |
中文falcon(注意:falcon模型和bloom结构类似) | chinese_bloom | ✅ | ✅ | ✅ | ❌ | ❌ |
| 中文预训练代码 | model_clm | ✅ | ✅ | ✅ | ❌ | ❌ |
| 百川大模型 | model_baichuan | ✅ | ✅ | ✅ | ✅ | ❌ |
| 模型修剪✂️ | model_modify | ✅ | ✅ | ✅ | ||
| llama2 流水线并行 | pipeline | ✅ | ✅ | ✅ | ❌ | ❌ |
2.thu-chatglm-6b模型教程
- 本文件夹📁只能进行单机单卡训练,如果想要使用单机多卡,请查看文件夹📁Chatglm6b_ModelParallel_ptuning。
| 介绍 | 路径 | 状态 |
|---|---|---|
使用lora训练chatglm6b | 就是本文件夹 | ✅ |
使用ptuning-v2模型并行训练chatglm6b | https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/Chatglm6b_ModelParallel_ptuning | ✅ |
在文件code02_训练模型全部流程.ipynb的cell-5代码的前面,创建一个新的cell,然后把下面的代码放到这个cell里面
q1 = '''您叫什么名字?
您是谁?
您叫什么名字?这个问题的答案可能会提示出您的名字。
您叫这个名字吗?
您有几个名字?
您最喜欢的名字是什么?
您的名字听起来很好听。
您的名字和某个历史人物有关吗?
您的名字和某个神话传说有关吗?
您的名字和某个地方有关吗?
您的名字和某个运动队有关吗?
您的名字和某个电影或电视剧有关吗?
您的名字和某个作家有关吗?
您的名字和某个动漫角色有关吗?
您的名字和某个节日有关吗?
您的名字和某个动物有关吗?
您的名字和某个历史时期有关吗?
您的名字和某个地理区域有关吗?
您的名字和某个物品有关吗?比如,如果您的名字和铅笔有关,就可以问“您叫什么名字?您是不是用铅笔的人?”
您的名字和某个梦想或目标有关吗?
您的名字和某个文化或传统有关吗?
您的名字和某个电影或电视节目的情节有关吗?
您的名字和某个流行歌手或演员有关吗?
您的名字和某个体育运动员有关吗?
您的名字和某个国际组织有关吗?
您的名字和某个地方的气候或环境有关吗?比如,如果您的名字和春天有关,就可以问“您叫什么名字?春天是不是一种温暖的季节?”
您的名字和某个电影或电视节目的主题有关吗?
您的名字和某个电视节目或电影的角色有关吗?
您的名字和某个歌曲或音乐有关吗?
您叫什么名字?
谁创造了你
'''
q1 = q1.split('\n')
a1 = ["我是良睦路程序员开发的一个人工智能助手", "我是良睦路程序员再2023年开发的AI人工智能助手"]
import randomtarget_len__ = 6000d1 = pd.DataFrame({'instruction':[random.choice(q1) for i in range(target_len__)]}).pipe(lambda x: x.assign(**{'input':'','output':[random.choice(a1) for i in range(target_len__)]})
)
d1
alldata = d1.copy()
注意:
- 如果想要覆盖模型老知识,你数据需要重复很多次才行~
- 文件不要搞错了,使用我最新的代码文件
只是对transofrmers包的Trainer类做了修改,对modeling_chatglm.py代码也做了修改。
这么做,可以让你在拥有22G显存的情况下,可以训练thu-chatglm-6b模型。
那么,基于Trainer的丰富方法,你可以做很多事情。而且使用peft包https://github.com/huggingface/peft的lora算法,让你在一个消费级别的显卡上,就可以训练thu-chatglm-6b模型。
- 安装
上面是文件工程,这里开始说安装包,直接使用pip安装
pip install protobuf==3.20.0 transformers icetk cpm_kernels peft
就这么简单,不需要安装别的东西了
-
训练部分
-
在最新的版本中,只需要查看
code02_训练模型全部流程.ipynb文件就行了 -
推理部分
- 推理部分,直接看
infer.ipynb代码 - 能到这里,也是恭喜你,微调模型已经成功了。这个时候,在这个文件夹下,肯定有一个文件夹叫
test003(就是上面output_dir="test003"对应的文件夹) - 在这个文件夹下,你肯定可以看到很多
checkpoint-xxx,选择一个你喜欢的(当然,肯定是最好选择最新的)。
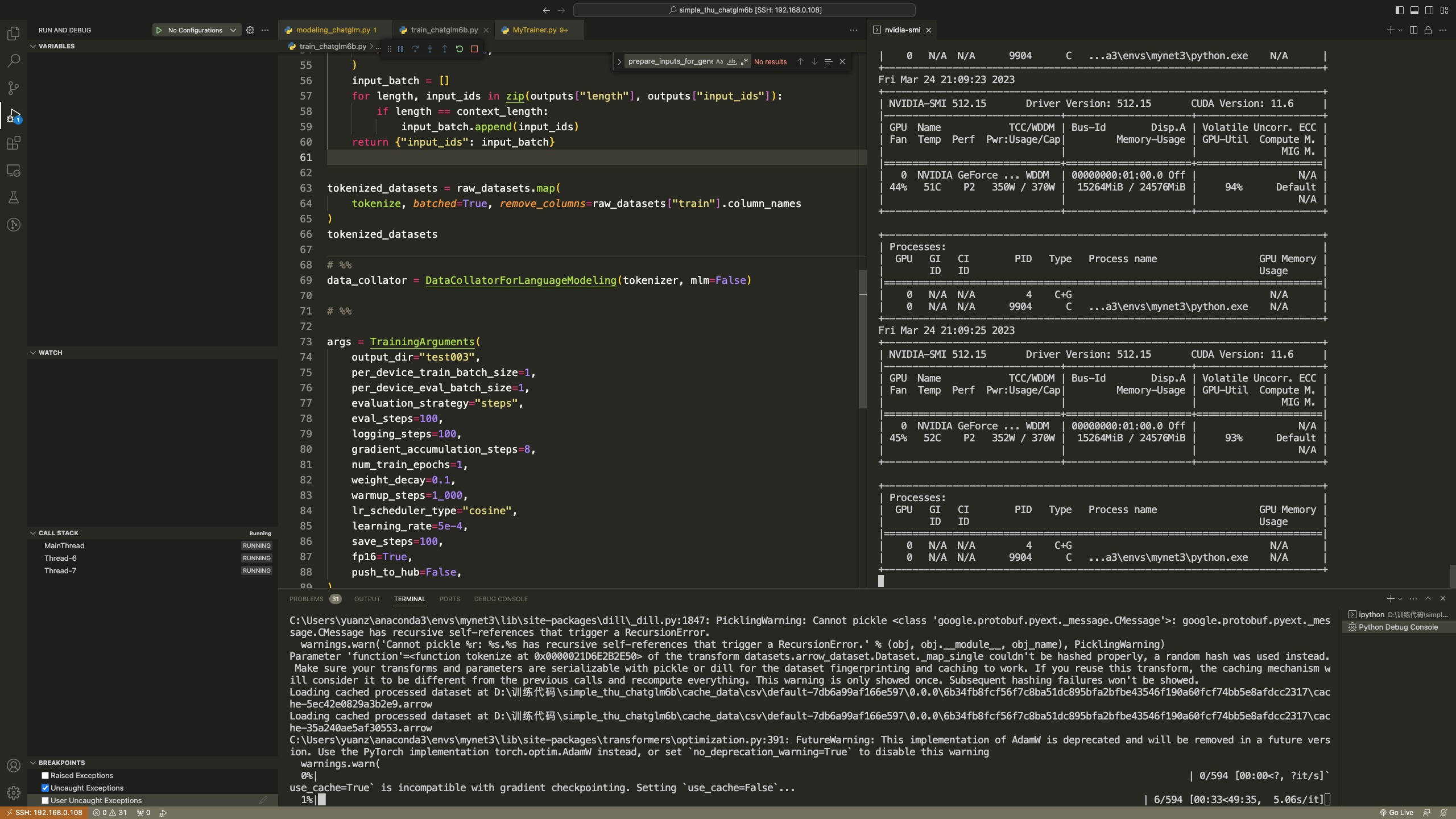
3.chatglm_v2_6b_lora
添加了上面的参数,确实可以进行模型并行,但是,这是在chatglm模型代码没有bug的情况下,目前已经定位到bug,并且修复了bug,我也提交PR给chatglm团队,可以点击这个链接查看https://huggingface.co/THUDM/chatglm2-6b/discussions/54#64b542b05c1ffb087056001c
考虑到他们团队效率问题,如果他们还没有修改这个bug,那你们可以自己修改,主要是这么做:
在modeling_chatglm.py的第955行代码附近(也就是modeling_chatglm.py/ChatGLMForConditionalGeneration.forward的loss部分):
原始代码:
loss = Noneif labels is not None:lm_logits = lm_logits.to(torch.float32)# Shift so that tokens < n predict nshift_logits = lm_logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() #<<<------------------看这里# Flatten the tokensloss_fct = CrossEntropyLoss(ignore_index=-100)loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))lm_logits = lm_logits.to(hidden_states.dtype)loss = loss.to(hidden_states.dtype)if not return_dict:output = (lm_logits,) + transformer_outputs[1:]return ((loss,) + output) if loss is not None else outputreturn CausalLMOutputWithPast(loss=loss,logits=lm_logits,past_key_values=transformer_outputs.past_key_values,hidden_states=transformer_outputs.hidden_states,attentions=transformer_outputs.attentions,)
修改为:
loss = Noneif labels is not None:lm_logits = lm_logits.to(torch.float32)# Shift so that tokens < n predict nshift_logits = lm_logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous().to(shift_logits.device) #<<<--------------------看这里# Flatten the tokensloss_fct = CrossEntropyLoss(ignore_index=-100)loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))lm_logits = lm_logits.to(hidden_states.dtype)loss = loss.to(hidden_states.dtype)if not return_dict:output = (lm_logits,) + transformer_outputs[1:]return ((loss,) + output) if loss is not None else outputreturn CausalLMOutputWithPast(loss=loss,logits=lm_logits,past_key_values=transformer_outputs.past_key_values,hidden_states=transformer_outputs.hidden_states,attentions=transformer_outputs.attentions,)
是的,就修改那一行即可
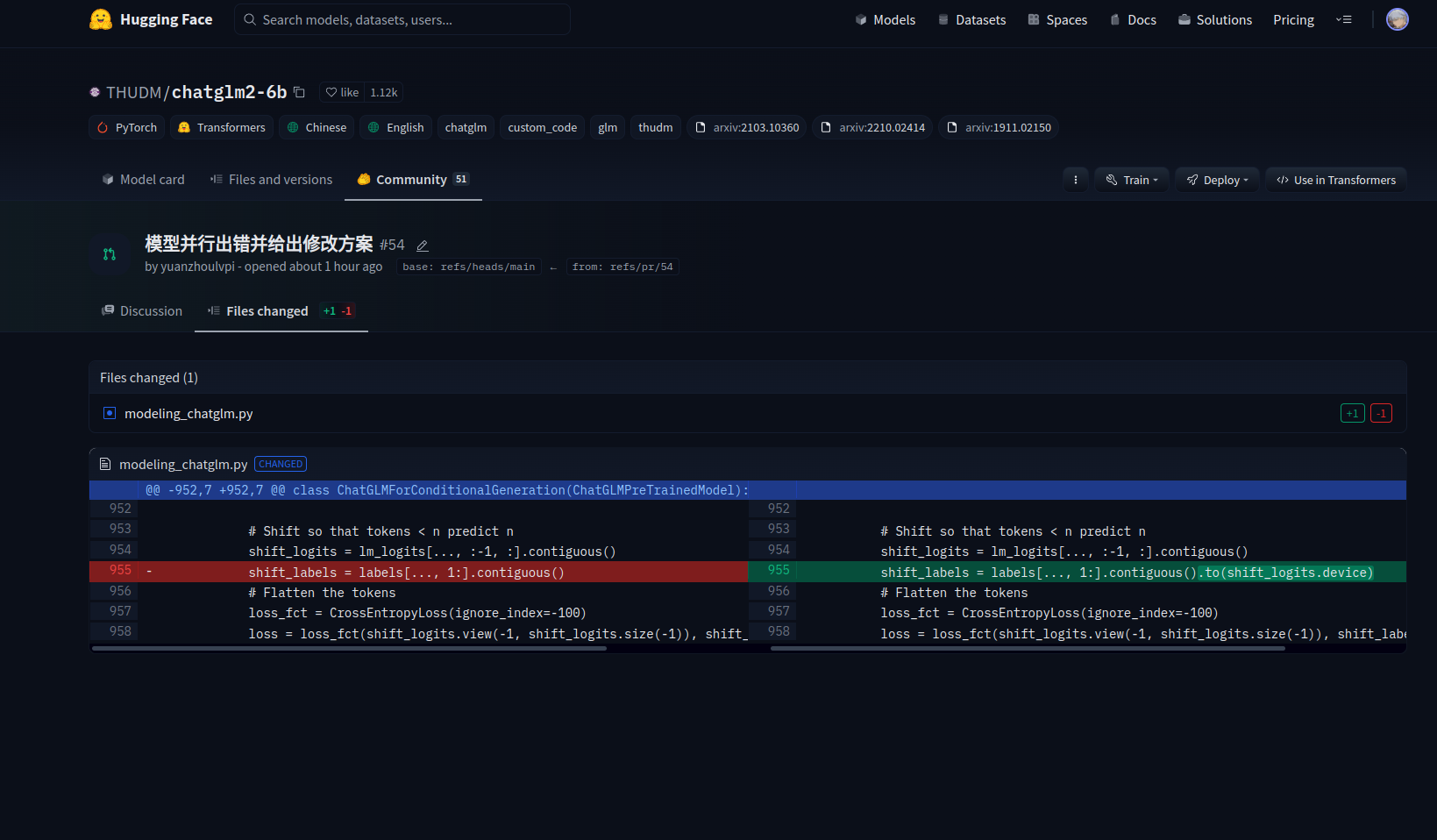
然后就可以正常跑起来了~
- 下载数据集
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)。
{"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳","summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
从 Google Drive
或者 Tsinghua Cloud 下载处理好的 ADGEN
数据集,将解压后的 AdvertiseGen 目录放到本目录下。
- 硬件要求
- 有个
3090显卡即可(24G显存左右) - 在下面这个参数下,显存只需要
14G
--max_source_length 64 \--max_target_length 128 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \ --lora_r 32- 训练脚本
- 使用vscode调试,就在
.vscode/launch.json里面; - 直接使用sh,
sh train.sh
- 推理
- 使用文件:
infer_lora.ipynb
- 使用
lora推理
from transformers import AutoTokenizer, AutoModel
from peft import PeftModel, PeftConfig
import torch
import osos.environ['CUDA_VISIBLE_DEVICES'] = '1'#原始的模型路径
model_name_or_path = "/media/yuanz/新加卷/训练代码/chatglm6b_v2_0716/chatglm2-6b_model"#训练后的lora保存的路径
peft_model_id = "output/adgen-chatglm2-6b-lora_version/checkpoint-880"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='auto',torch_dtype=torch.bfloat16) # .half().cuda()model = PeftModel.from_pretrained(model, peft_model_id)
model = model.eval()response, history = model.chat(tokenizer, "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞",history=[])
print(response)
- 血的教训
- 一定要从
huggingface上把chatglm-v2-6b的所有文件都下载下来,放在一个文件夹下;这样即使他更新了,也不会影响到你。如果你不下载,你会很被动😒
- 相关的BUG
很多人在跑多卡的时候,会遇到一些莫名其妙的错误,建议您按照下面两个步骤进行排查:
- 一定要看我上面折叠的那一块东西,就是
🚨注意部分。 - 检查
transformers的版本,如果太低,就更新一下,建议更新:pip install transformers -U
4.中文的dolly_v2_3b模型
-
训练中文的
dolly_v2_3b模型dolly_v2_3b模型本质上就是使用的gpt_neox模型框架,可以商用,而且也都出来很多年了。- 当前有很多人基于
llama、gptj、chatglm-6b等模型,做了很多微调,有些也都做过了,有些不能商用,有些还要申请,实在是太可惜了,太麻烦了。 - 既然
dolly_v2_3b可以商用,那我们就主打一个随意,稍微动动手就可以训练一个属于我们的模型。 - 本仓库用到的代码,来源于
databrickslabs/dolly,对代码做了部分调整和融合。反正就是复制粘贴、懂得都懂~ - 模型叫什么名字:
小黑子😛,已将模型放在https://huggingface.co/yuanzhoulvpi/xiaoheizi-3b
-
- 🎯 支持多卡模型并行:也不知道
databrickslabs/dolly为啥要使用gpt_neox模型,这个模型transformers对他支持的其实一般,于是我把代码魔改了一部分,增加了多卡并行计算功能(主要是是模型并行). - 🥱 虽然代码是从
databrickslabs/dolly复制的,但是简化了很多不必要的代码,更简单一点,我不喜欢复杂的代码,越简单越好。 - 😵 支持
bp16:我原本的打算是说支持fp16的,但是发现fp16怎么搞都不行,但是bp16倒是可以。
下一步优化方向
- 😆 添加
lora等微调训练代码,这个简单,等后面都训练好了,我添加一下。
- 🎯 支持多卡模型并行:也不知道
-
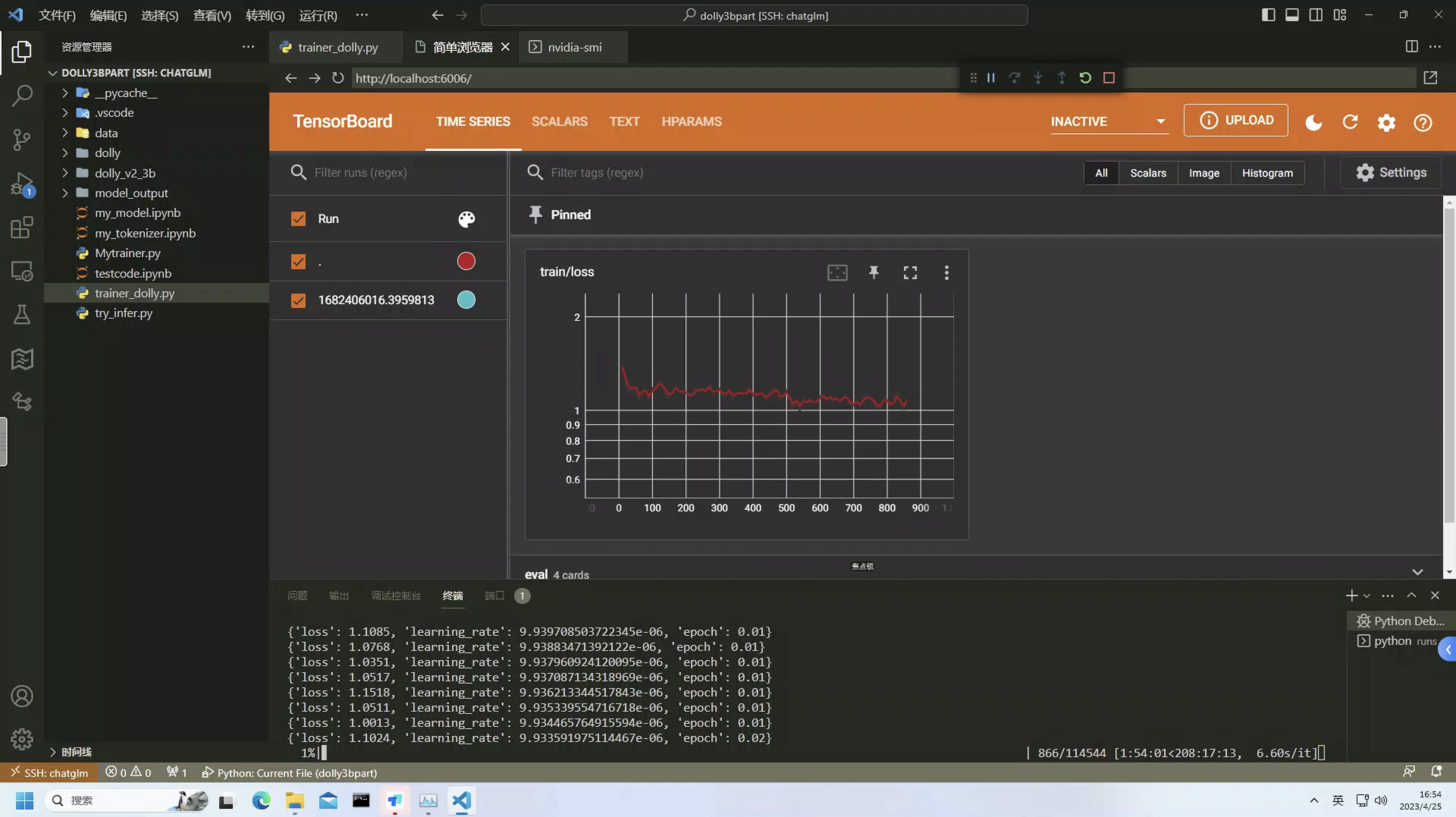
模型训练情况
- 训练数据:
BelleGroup/train_1M_CN - 训练时间:280小时左右
- 训练设备:
4台3090
- 训练数据:
- 更多
- 当前的模型参数是
3b,但是当你把整个流程跑通之后,可以很轻松的将3b模型换成7b模型或者更大的gpt_neox模型。而你只需要将硬件进行提升即可,无需调整代码~ - 当前的
3b模型是否满足你的需求还不确定,后面你可以试一试。(当前还没发布) - 到底是大模型好还是小模型好,可以看看这句话:
吴恩达:有多少应用程序需要用到像GPT-4这样的最大型模型,而不是云提供商提供的更小(更便宜)的模型,甚至是本地托管的模型(比如运行在桌面上的gpt4all)还有待观察 - 对于个人或者小企业,强调的的就是在
垂直领域做快速迭代,希望3b模型可以帮助到你!
- 当前的模型参数是
5.chinese_bloom
-
支持对
falcon模型做sft~ -
✅ 基于stanford_alpaca项目,使用
sft格式数据对bloom、falcon模型微调; -
✅ 支持
deepspeed-zero2、deepspeed-zero3; -
✅ 支持自定义数据,支持大数据训练;
-
✅ 得益于
bloom本身的能力,微调后的模型支持中文、英文、代码、法语、西班牙语等; -
✅ 微调后的模型,中文能力显著提升;
-
✅ 支持不同尺寸
bloom模型,如560m、3b、7b、13b; -
✅ 支持
falcon模型,如https://huggingface.co/tiiuae/falcon-7b;
- 体验
bloom-560m_chat: 想要体验一个轻量的,那就直接体验5.6亿参数https://huggingface.co/yuanzhoulvpi/chinese_bloom_560mbloom-7b_chat: 想要体验一个更大的,那就可以试一试70亿参数https://huggingface.co/yuanzhoulvpi/chinese_bloom_7b_chat
- 🎉 在hugginface上部署了一个cpu版本的(有点慢,毕竟是🆓)https://huggingface.co/spaces/yuanzhoulvpi/chinese_bloom_560_chat
- 模型
-
bloom模型支持中文、英文、代码、法语、西班牙语。具体的训练数据的语言占比如下👇。 -
bloom-3b: https://huggingface.co/bigscience/bloom-3b -
bloom-系列模型: https://huggingface.co/bigscience
- 数据
- 数据来源于
BelleGroup,主要是用到这几个数据集:['BelleGroup/generated_chat_0.4M', 'BelleGroup/school_math_0.25M', 'BelleGroup/train_2M_CN', 'BelleGroup/train_1M_CN', 'BelleGroup/train_0.5M_CN', 'BelleGroup/multiturn_chat_0.8M']; - 可以基于这些数据样式,制作自己的数据,并训练;
-
步骤
-
数据部分
- 运行
data_proj/process_data.ipynb代码;或者模仿结果,制作自己的数据集; - 运行结束之后,有一个文件夹
data_proj/opendata。文件夹下有若干个json格式的文件。
- 运行
-
运行模型
- 基础运行策略
sh base_run.sh
deepspeed运行策略
sh ds_all.sh
- 推理代码
infer.ipynb文件gradio交互界面:https://huggingface.co/spaces/yuanzhoulvpi/chinese_bloom_560_chat 因为是使用的huggingface的免费的cpu版本,所以推理速度比较慢。
- 效果
不管是写代码还是写文案,bloom-7b在中文领域有极大的潜力
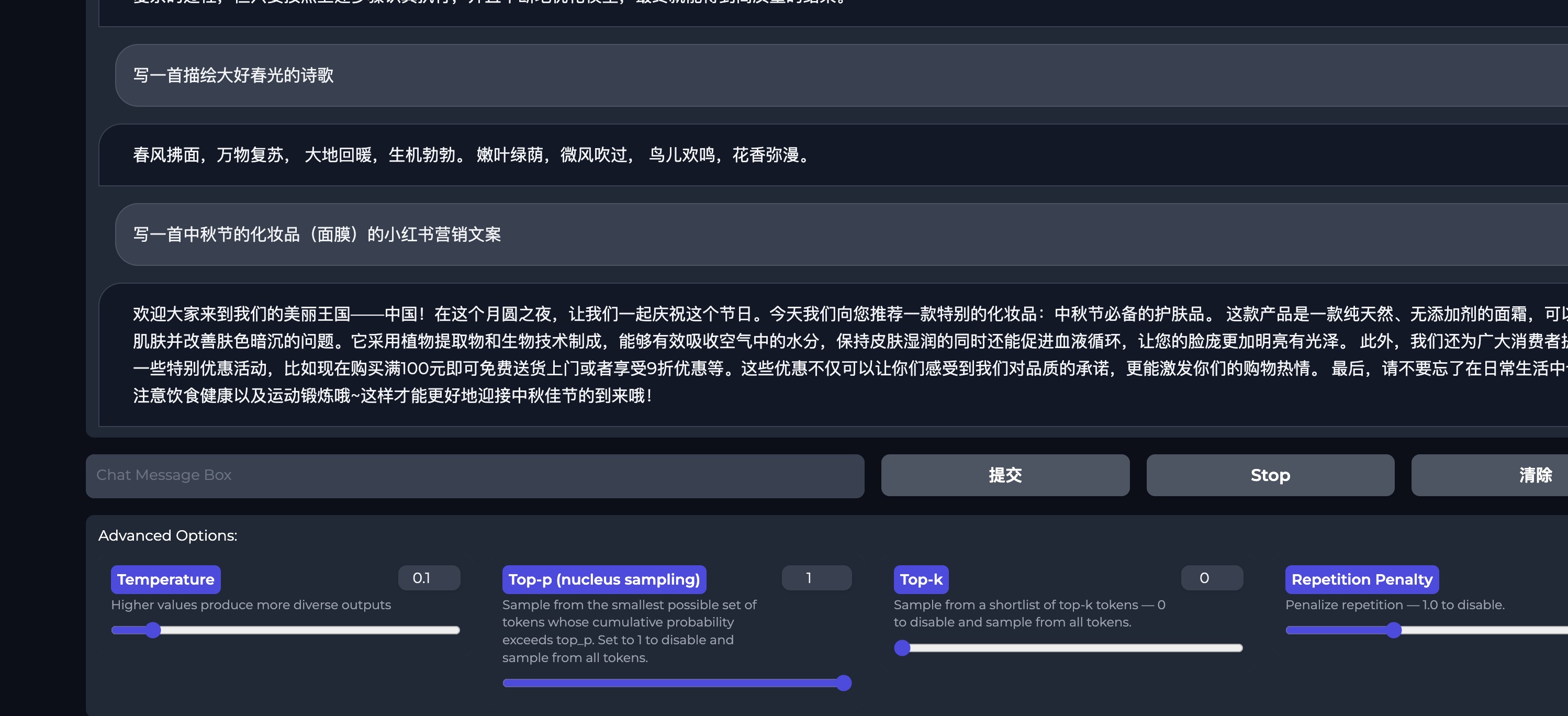
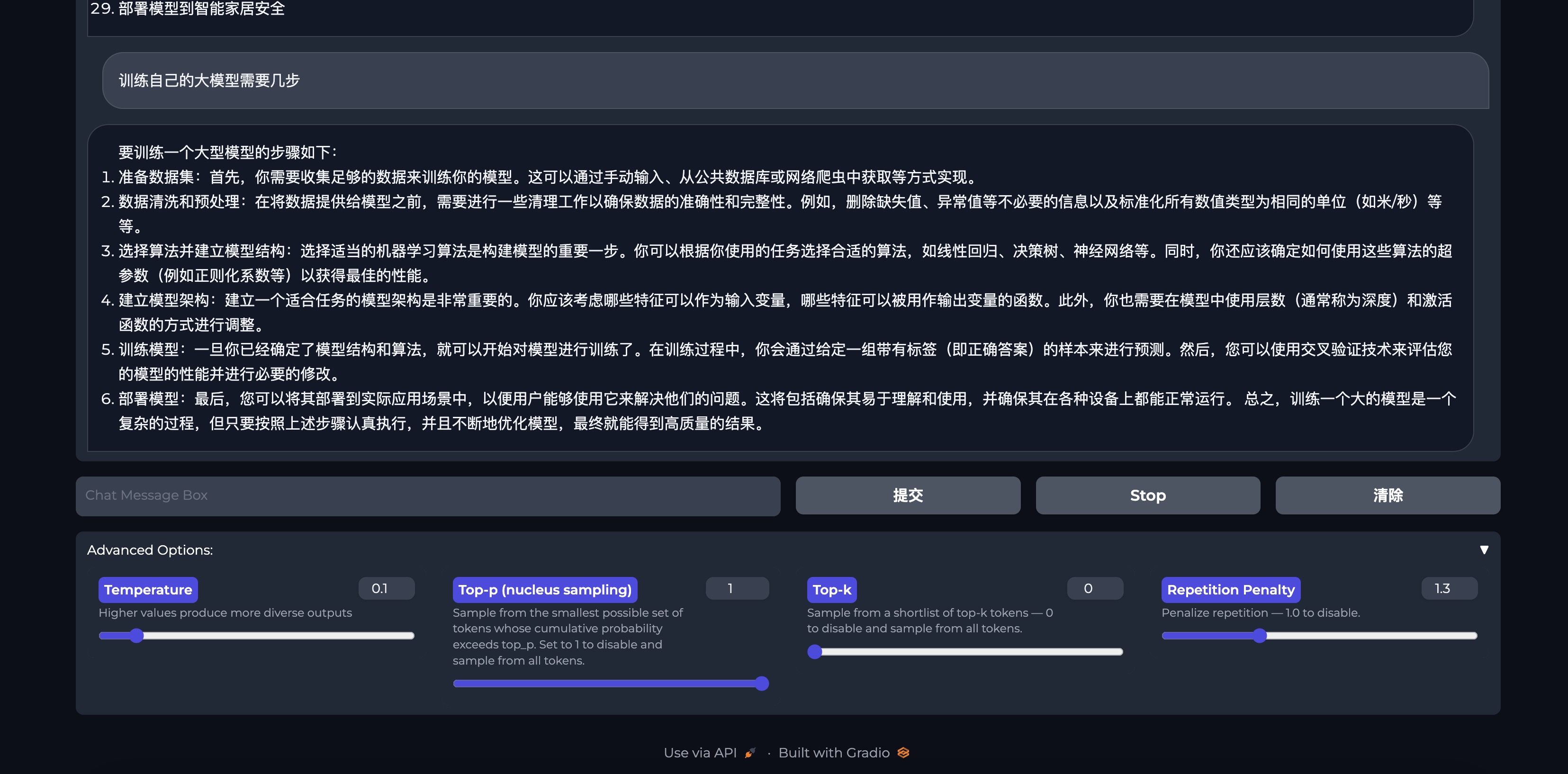
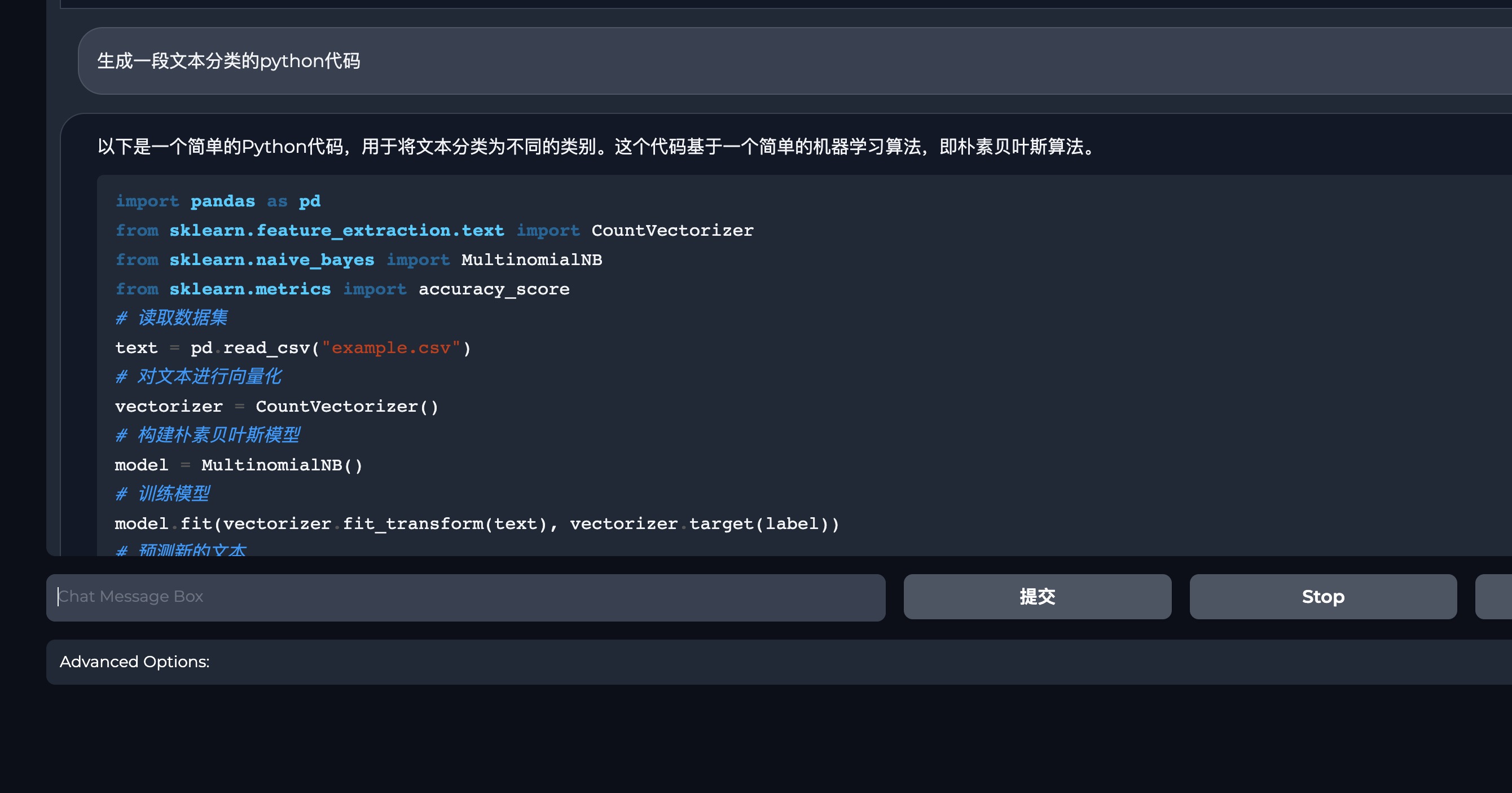
- 体验
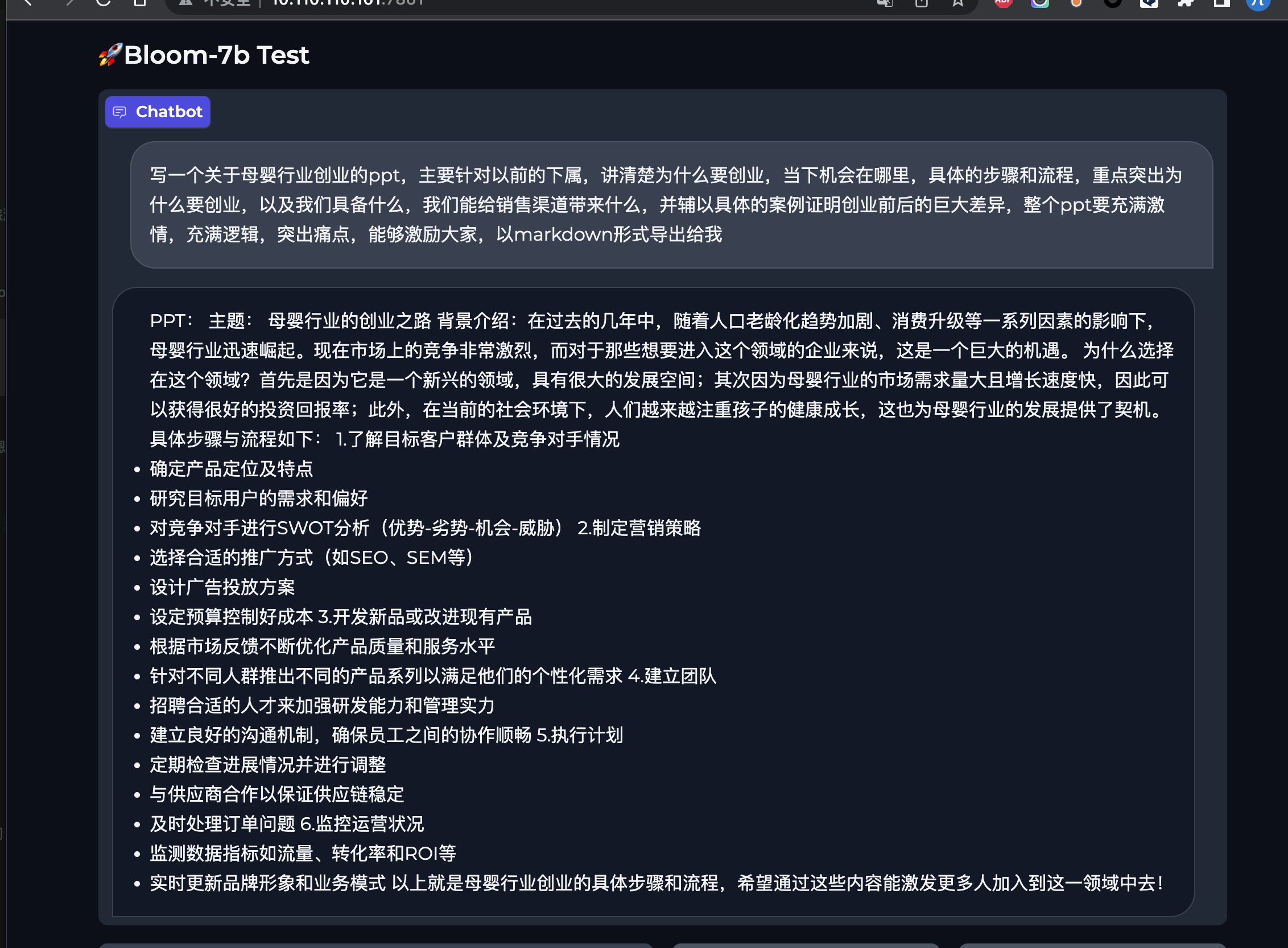
chinese_bloom_560m模型,可以在这里体验https://huggingface.co/spaces/yuanzhoulvpi/chinese_bloom_560_chatchinese_bloom_7b模型,可以在这里体验http://101.68.79.42:7861
项目链接:https://github.com/yuanzhoulvpi2017/zero_nlp
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!” 1.简介 目标:基于pytorch、transformers做中文领域的nlp开箱即用…...

空时自适应处理用于机载雷达——机载阵列雷达信号环境(Matla代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

lib61850 学习笔记一 (概念)
IEC61850 定义60多种服务满足变电站通信需求。支持在线获取数据模型,也支持IED水平通信(GOOSE报文) 术语定义 间隔 bay: 变电站由据应公共功能紧密连接的子部分组成。 例如 介于进线或者 出线 和母线之间的断路器;二条母线之间…...

【深度学习】半监督学习 Efficient Teacher: Semi-Supervised Object Detection for YOLOv5
https://arxiv.org/abs/2302.07577 https://github.com/AlibabaResearch/efficientteacher 文章目录 AbstractIntroductionRelated WorkEfficient TeacherDense Detector Abstract 半监督目标检测(SSOD)在改善R-CNN系列和无锚点检测器的性能方面取得了成…...

vue3鼠标拖拽滑动效果
第一步 在utils下面新建一个directives.js文件,然后引入如下代码 const dragscroll (el) > {el.onmousedown ev > {const disX ev.clientX;const disY ev.clientY; // 需要上下移动可以加const originalScrollLeft el.scrollLeft;const originalScroll…...
08 通过从 库1 复制 *.ibd 到 库2 导致 mysql 启动报错
前言 呵呵 最近同事有这样的一个需求 需要将 库1 的一张表 复制到 库2 然后 我想到了 之前一直使用的通过复制这个库的 data 文件来进行数据迁移的思路, 是需要复制这个 库对应的 data 目录下的数据文件, 以及 ibdata1 文件 然后 我又在想 这里的场景能否也使用这里的额方式…...

一生一芯9——ubuntu22.04安装valgrind
这里安装的valgrind版本是3.19.0 下载安装包 在选定的目录下打开终端,输入以下指令 wget https://sourceware.org/pub/valgrind/valgrind-3.19.0.tar.bz2直至下载完成 解压安装包 输入下面指令解压安装包 tar -xvf valgrind-3.19.0.tar.bz2.tar.bz2注…...
)
STM32中BOOT的作用 (芯片死锁解决方法)
BOOT stm32中具有BOOT1和BOOT0 作用 BOOT是stm32单片机的启动模式, 通过不同组合模式,共有三种启动方式。 一般来说就是指我们下好程序后,重启芯片时,SYSCLK的第4个上升沿,BOOT引脚的值将被锁存。用户可以通过设置B…...
基于YOLOv8模型和DarkFace数据集的黑夜人脸检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和DarkFace数据集的黑夜人脸检测系统可用于日常生活中检测与定位黑夜下的人脸,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目…...

C++中<iostream> 的cin >> str 和<string>的getline(cin, str) 用来读取用户输入的两种不同方式的不同点
C中<iostream> 的cin >> str 和<string>的getline(cin, str) 用来读取用户输入的两种不同方式的不同点 <string>的getline()函数语法如下【https://cplusplus.com/reference/string/string/getline/】: istream& getl…...

微信报修系统有什么优势?怎么提升企业维修工作效率与管理水平?
随着智能化时代的到来,企业、事业单位的现代化设备数量和种类不断增加,原本繁琐的报修、填写记录、检修管理等工作得以简化。从发起报修到维修,以及维修之后给予评价的整个过程,通过手机微信报修系统均能看到,既省时又…...
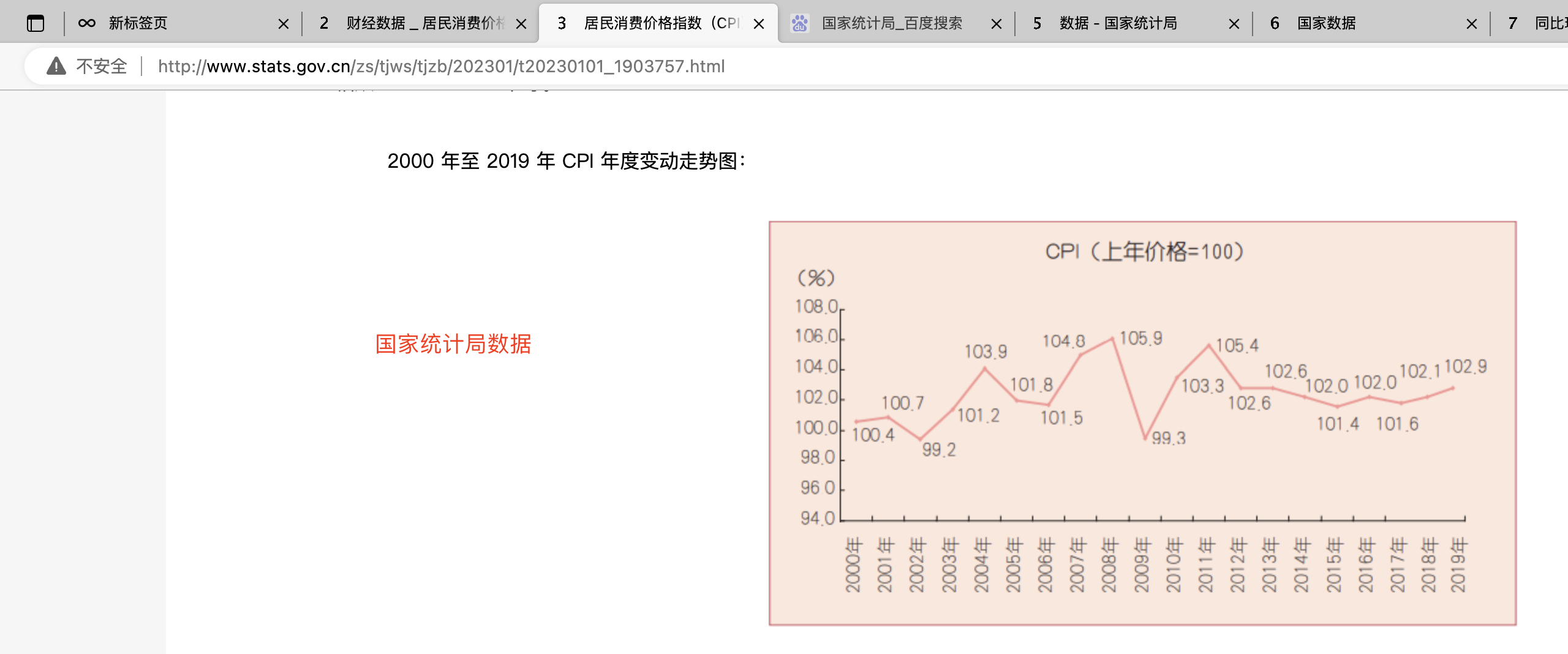
11.2.1-通货膨胀CPI
文章目录 1. 什么是CPI2. 在哪里获取CPI数据3. CPI的同比、环比到底是什么意思?4. 计算购买力侵蚀5. 复利计算 微不足道的小事也会引发惊人的结果, 每念及此, 我就认为世上无小事。——布鲁斯巴登(Bruce Barton) 核心内…...

服务器基础
0x01基础 介绍 可以理解为企业级的电脑,比个人使用的电脑具备更强的配置、性能、可靠性及稳定性。设计工艺和器件全部采用企业级设计,保障7*24小时稳定运行。 演进历史 处理性能 外观 发展方向 分类 按外形分类 按高度分类 按应用分类 按综合能力…...

mybatis中#{ }和${ }的区别
先说结论:二者肯定是有区别的 区别总结 ${ } 直接的 字符串 替换,在mybatis的动态 SQL 解析阶段将会进行变量替换。 #{ } 通过预编译,用占位符的方式?传值可以把一些特殊的字符进行转义,这样可以防止一些sql注入。 举例说明区…...
【真人语音】讯飞星火个人声音训练及导出下载工具V0.2.exe
【项目背景】 小编一直在尝试着短视频技术,在读文案的时候经常会读错;所以,只能用微软或者剪映的文本转语音软件。 很早之前在Github上也看到过真人人声训练的开源代码,尝试过一番之后,也是以失败告终;就…...

正中优配:创业板指大涨3.47%!减速器等概念板块掀涨停潮!
周二(8月29日),三大股指团体涨超1%。截至上午收盘,上证指数涨1.39%,报3141.82点;深证成指和创业板指别离涨2.41%和3.47%;沪深两市算计成交额6264.51亿元,总体来看,两市个股涨多跌少&…...
多功能租车平台微信小程序源码 汽车租赁平台源码 摩托车租车平台源码 汽车租赁小程序源码
多功能租车平台微信小程序源码是一款用于汽车租赁的平台程序源码。它提供了丰富的功能,可以用于租赁各种类型的车辆,包括汽车和摩托车。 这个小程序源码可以帮助用户方便地租赁车辆。用户可以通过小程序浏览车辆列表,查看车辆的详细信息&…...

spring事件和线程池区别
Spring事件(Spring Event)和线程池(Thread Pool)是两个不同的概念。 Spring事件是Spring框架中的一种机制,用于在应用程序中实现发布-订阅模式。通过定义事件和监听器,可以在特定事件发生时,通…...

深圳寄墨西哥专线国际物流详解
随着全球贸易的不断发展,国际物流服务的需求也越来越大。深圳这座中国的特区城市,不仅是全球电子产品供应链的重要节点,也是国际物流服务的中心之一。对于那些需要将物品从深圳邮寄到墨西哥的人来说,深圳邮寄到墨西哥专线的国际物…...
PHP教学资源管理系统Dreamweaver开发mysql数据库web结构php编程计算机网页
一、源码特点 PHP 教学资源管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 源码 https://download.csdn.net/download/qq_41221322/88260480 论文 https://downl…...

Kubernetes二进制文件管理器KBM:高效管理kubectl、helm等工具版本
1. 项目概述:为什么我们需要一个Kubernetes二进制文件管理器? 如果你和我一样,长期在多个Kubernetes集群、不同版本的环境之间切换,或者需要为CI/CD流水线、离线环境准备特定版本的 kubectl 、 helm 、 kustomize 等工具&am…...

AI应用开发利器:NeuroAPI网关统一管理多模型调用与部署实战
1. 项目概述:一个面向AI应用开发的API网关最近在折腾AI应用开发的朋友,估计都绕不开一个头疼的问题:模型管理。今天想试试Claude,明天项目需要接入GPT-4,后天可能又要调用一个开源的Llama模型。每个模型都有自己的API地…...

广东公考机构全景测评:粉笔凭极致性价比与本土教研实力领跑
随着2026年广东省考备考热潮的持续升温,选择一家靠谱的培训机构成为广大考生关注的焦点。在广东这片公考竞争激烈的热土上,除了粉笔、华图和中公三大巨头,以笨鸟教育、及第林教育为代表的本土精品机构也凭借极强的地域针对性异军突起。本次测…...

使用kern工具自动化构建Linux内核:从原理到实战
1. 项目概述:一个内核构建与管理的瑞士军刀如果你曾经尝试过编译Linux内核,或者需要为特定的硬件、研究项目定制一个内核,那么你大概率体验过这个过程:下载源码、配置成千上万个选项、解决依赖、漫长编译,最后可能因为…...

从社交情绪预测到论文分类:DHGNN动态超图模型在两大真实场景下的性能实测与调优心得
动态超图神经网络实战:从社交情绪分析到学术论文分类的双场景深度解析 当面对微博海量用户情绪的实时波动,或是学术文献间错综复杂的引用关系时,传统图神经网络常显捉襟见肘。动态超图神经网络(DHGNN)通过独特的层级动…...
图解ConvTranspose1d:从计算图到代码实现的逆向思维
1. 从Conv1d到ConvTranspose1d的思维转换 第一次接触ConvTranspose1d时,我和大多数人一样困惑:为什么要把好好的卷积操作反过来计算?直到在语音合成项目中被迫深入使用后,才明白这种"逆向思维"的价值。想象你正在玩拼图…...

OrangePi串口实战:从pyserial配置到USB-TTL数据抓取
1. 环境准备与硬件连接 第一次玩OrangePi串口通信时,我对着桌上那堆USB-TTL模块和杜邦线发呆了半小时。后来才发现,硬件连接其实比想象中简单。你需要准备三样东西:OrangePi开发板(我用的是OrangePi 5)、USB-TTL转换模…...

从NCDC到本地分析:一站式获取与处理全球气象站点数据
1. 全球气象数据获取的完整指南 第一次接触气象数据的朋友可能会被各种专业术语和数据格式搞得晕头转向。我刚开始做气象分析时,光是找数据就花了两周时间,下载下来的文件还经常打不开。今天我就把从数据获取到最终分析的完整流程梳理出来,帮…...

量子生成分类技术:原理、优势与应用解析
1. 量子生成分类技术概述量子生成分类(Quantum Generative Classification, QGC)是一种基于量子计算原理的新型机器学习范式,它从根本上改变了传统分类任务的实现方式。与常见的判别式学习方法不同,QGC采用生成式学习策略…...

Fast-Planner核心思想拆解:从B样条优化到时间重分配,如何让无人机飞得更快更稳?
Fast-Planner核心思想解析:从B样条优化到时间重分配的无人机高速运动规划 无人机在复杂环境中的高速飞行一直是运动规划领域的重大挑战。传统方法往往在速度提升后出现轨迹抖动或避障失效的问题,而Fast-Planner通过创新的算法架构实现了"又快又稳&q…...