Pandas库入门仅需10分钟
数据处理的时候经常性需要整理出表格,在这里介绍pandas常见使用,目录如下:
- 数据结构
- 导入导出文件
- 对数据进行操作
– 增加数据(创建数据)
– 删除数据
– 改动数据
– 查找数据
– 常用操作(转置,常用统计值)
参考链接:10 minutes to pandas https://pandas.pydata.org/docs/user_guide/10min.html#min
数据结构
Pandas常见的就两种数据类型:Series和DataFrame,可以对应理解为向量和矩阵,前者是一维的,后者是二维的。在DF中类似统计学中的数据组织方式,一行代表一项数据,一列代表一种特征,用这种方式记忆能够帮你更好理解DF。需要注意的是:在DF中index是行,column是列。


导入导出数据
常使用.csv格式的文件,我们在导入数据的时候使用pd.read_csv(),在导出数据的时候用df.write_csv(“/data/ymz.csv”).
# 读入数据
In [144]: pd.read_csv("foo.csv")
Out[144]: Unnamed: 0 A B C D
0 2000-01-01 0.350262 0.843315 1.798556 0.782234
1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651
2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566
3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581
4 2000-01-05 -1.044057 0.118042 2.768571 0.386039
.. ... ... ... ... ...
995 2002-09-22 -48.017654 31.474551 69.146374 -47.541670
996 2002-09-23 -47.207912 32.627390 68.505254 -48.828331
997 2002-09-24 -48.907133 31.990402 67.310924 -49.391051
998 2002-09-25 -50.146062 33.716770 67.717434 -49.037577
999 2002-09-26 -49.724318 33.479952 68.108014 -48.822030[1000 rows x 5 columns]
# 写出数据
In [143]: df.to_csv("foo.csv")
对数据进行操作
对数据操作包括增(创建),删,改,查。
增加数据(创建数据)
相比较Series,我们更常使用DataFrame数据类型,常使用的创建DataFrame类型有两种,一种是使用data创建(注意data得是一个二维list/array等),一种是使用字典创建。
1. 使用data创建DF
# 使用data导入
In [5]: dates = pd.date_range("20130101", periods=6)In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04','2013-01-05', '2013-01-06'],dtype='datetime64[ns]', freq='D')In [7]: df = pd.DataFrame(data=np.random.randn(6, 4), index=dates, columns=list("ABCD"))In [8]: df
Out[8]: A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988
2. 使用字典创建DF
# 使用字典
In [9]: df2 = pd.DataFrame(...: {...: "A": 1.0,...: "B": pd.Timestamp("20130102"),...: "C": pd.Series(1, index=list(range(4)), dtype="float32"),...: "D": np.array([3] * 4, dtype="int32"),...: "E": pd.Categorical(["test", "train", "test", "train"]),...: "F": "foo",...: }...: )...: In [10]: df2
Out[10]: A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
3. 增加一行数据
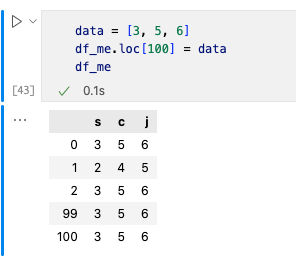
1)使用loc在行尾增加
增加一行数据的方法有loc, iloc, append, concat, merge。这里介绍一下loc,loc[index]是在一行的最后增加数据。但是你需要注意loc[index]中的index,如果与已出现过的index相同,则会覆盖原先index行,若不相同则才会增加一行数据。
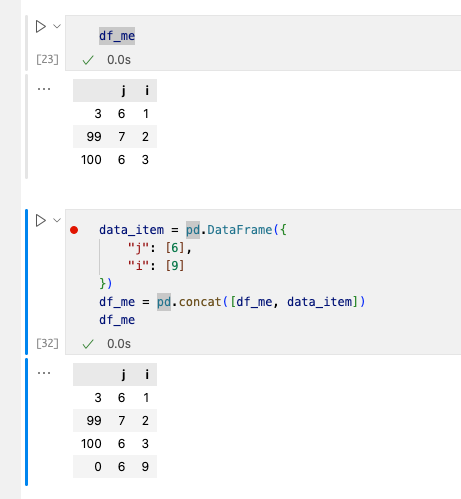
2)使用concat将两个DF合并
concat()也是一个增加数据常用的方法,常见于两个表的拼接与爬虫使用中,作用类似于append(),但是append()将在不久后被pandas舍弃,所以还是推荐使用concat()。
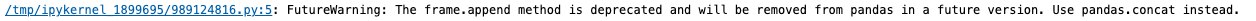
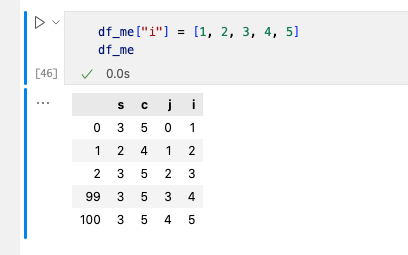
4. 增加一列数据
增加一列数据的方法直接用[]便可,例子如下:
Series用的比较少,案例如下:
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8])In [4]: s
Out[4]:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
删除数据
对于删除数据,我们使用drop()方法,并指定参数为index(行)或者column(列)
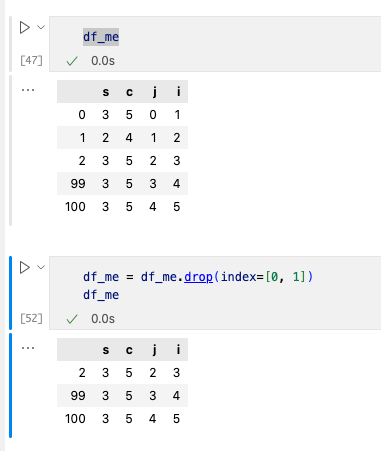
1. 删除一行数据
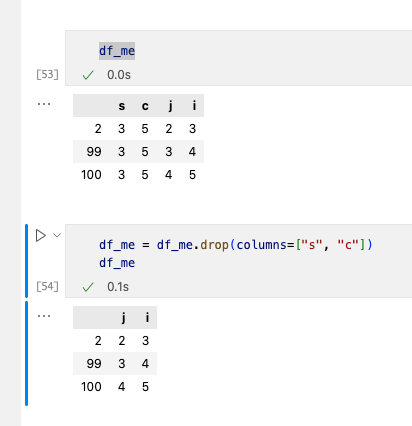
2. 删除一列数据
改动数据
改动一行,列数据常用loc()和[]方法。
1. 改动一行数据
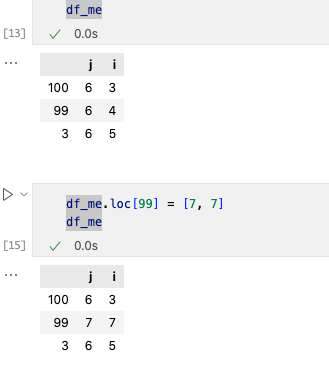
改动一行我们使用loc[]=[…]进行更改。
2. 改动一列数据
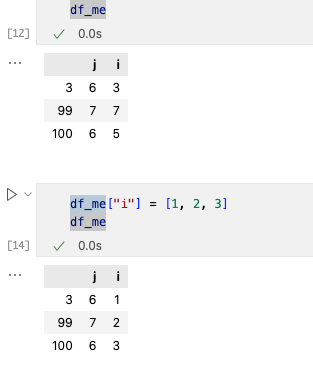
改动一列数据我们使用[]进行更改。
查找数据
在查找数据的时候,我们常使用[]来查看行列数据,配合.T来将矩阵转置。也可以使用head(),tail()来查看前几行和后几行数据。
1. 查看特定行数据
使用.loc[index]来查看特定行数据,或者[]。建议使用.loc[]方法或者.iloc[]方法,loc[]通过行的名字寻找,iloc[]通过索引寻找。
使用类似[0:2]来查看特定行数据,和python中list使用类似。这个方法其实是调用了__getitem__()方法。

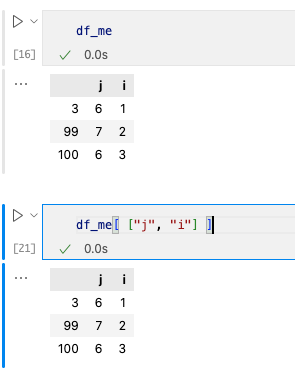
2. 查看特定列数据
我们需要使用两层[]嵌套来访问数据,例如[ [“j”, “i”] ]。
3. 查看特定元素
确定第几行第几列后,使用.loc()方法或者.iloc()方法查找。
b = a.loc[ 1, "dir_name" ]
常用操作
数据分析时常用的两个操作,转置和计算统计量。
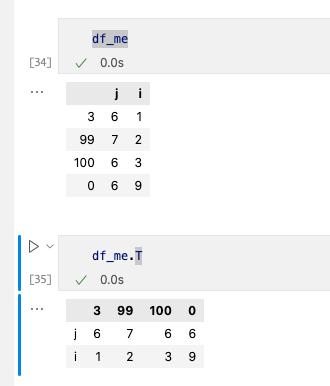
1. 转置
使用.T便可以完成。
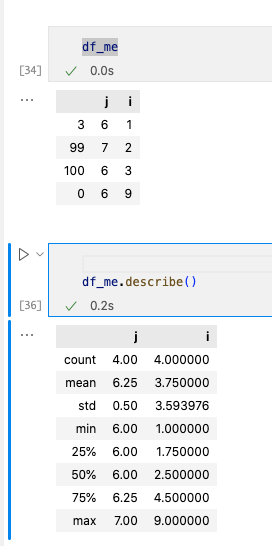
2. 计算统计量
使用.describe()。
3. 舍弃一列中多余重复数据
使用.drop_duplicates()
id_df = self.frames_meta_sub[['time_idx', 'pos_idx', 'slice_idx']].drop_duplicates()
4. 将特定列转成numpy后处理
使用.to_numpy()方法将你所选择的数据全部转成二维的或者一维的ndarray,需要注意的是to_numpy()并不仅仅局限于数字,字符串也是可以转换的(虽然这样开销比较大),ndarray能存储字符串,这会让你处理数据的过程变得异常简单。有几个维度取决于你取了几行或者几列。
df = df[ ["channel"] ]
ar = df.to_numpy()
5. 取出dataframe中特定位置的值
要取出 DataFrame 中特定位置的值,可以使用 .loc 或 .iloc 方法,具体取决于您想要使用的索引类型。
如果您使用标签索引(例如,行和列都使用标签名称),则可以使用 .loc 方法。例如,如果您有一个名为 df 的 DataFrame,它具有行标签为 row_label,列标签为 column_label 的元素,则可以使用以下代码获取该元素的值:
value = df.loc[row_label, column_label]
如果您使用整数位置索引(例如,行和列都使用整数位置),则可以使用 .iloc 方法。例如,如果您有一个名为 df 的 DataFrame,它具有第一个行和第一个列的元素,则可以使用以下代码获取该元素的值:
value = df.iloc[0, 0]
请注意,索引从零开始,因此第一个行和第一个列的位置为 0。
相关文章:
Pandas库入门仅需10分钟
数据处理的时候经常性需要整理出表格,在这里介绍pandas常见使用,目录如下: 数据结构导入导出文件对数据进行操作 – 增加数据(创建数据) – 删除数据 – 改动数据 – 查找数据 – 常用操作(转置࿰…...

python的socket通信中,如何设置可以让两台主机通过外网访问?
要让两台主机通过外网进行Socket通信,需要在网络设置和代码实现两个方面进行相应的配置。下面是具体的步骤: 确认网络环境:首先要确保两台主机都能够通过外网访问。可以通过ping命令或者telnet命令来测试两台主机之间是否可以互相访问。 确定…...
)
检测数据的方法(回顾)
检测数据类型的4种方法typeofinstanceofconstructor{}.toString.call() 检测数据类型的4种方法 typeof 定义 用来检测数据类型的运算符 返回一个字符串,表示操作值的数据类型(7种) number,string,boolean,object,u…...
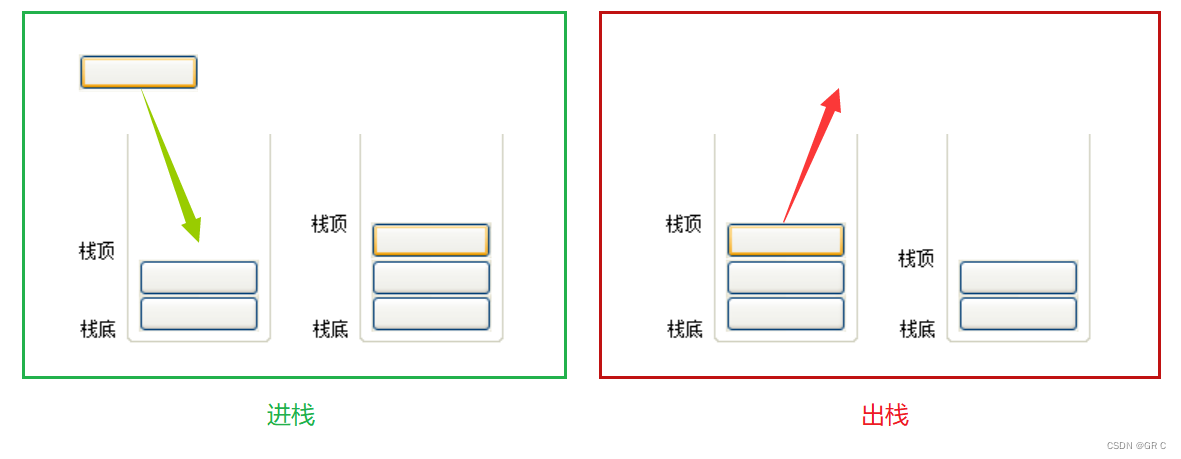
比特数据结构与算法(第三章_上)栈的概念和实现(力扣:20. 有效的括号)
一、栈(stack)栈的概念:① 栈是一种特殊的线性表,它只允许在固定的一端进行插入和删除元素的操作。② 进行数据插入的删除和操作的一端,称为栈顶 。另一端则称为 栈底 。③ 栈中的元素遵守后进先出的原则,即…...
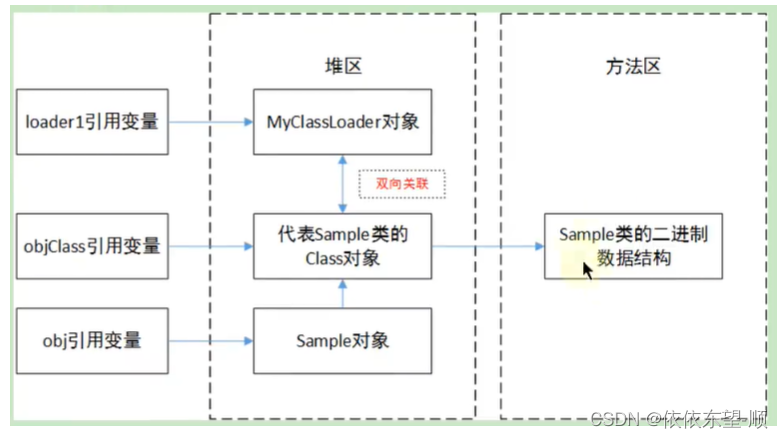
JVM13 类的生命周期
1. 概述 在 Java 中数据类型分为基本数据类型和引用数据类型。基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载。 按照 Java 虚拟机规范,从 class 文件到加载到内存中的类,到类卸载出内存为止,它的整个生命周期包…...
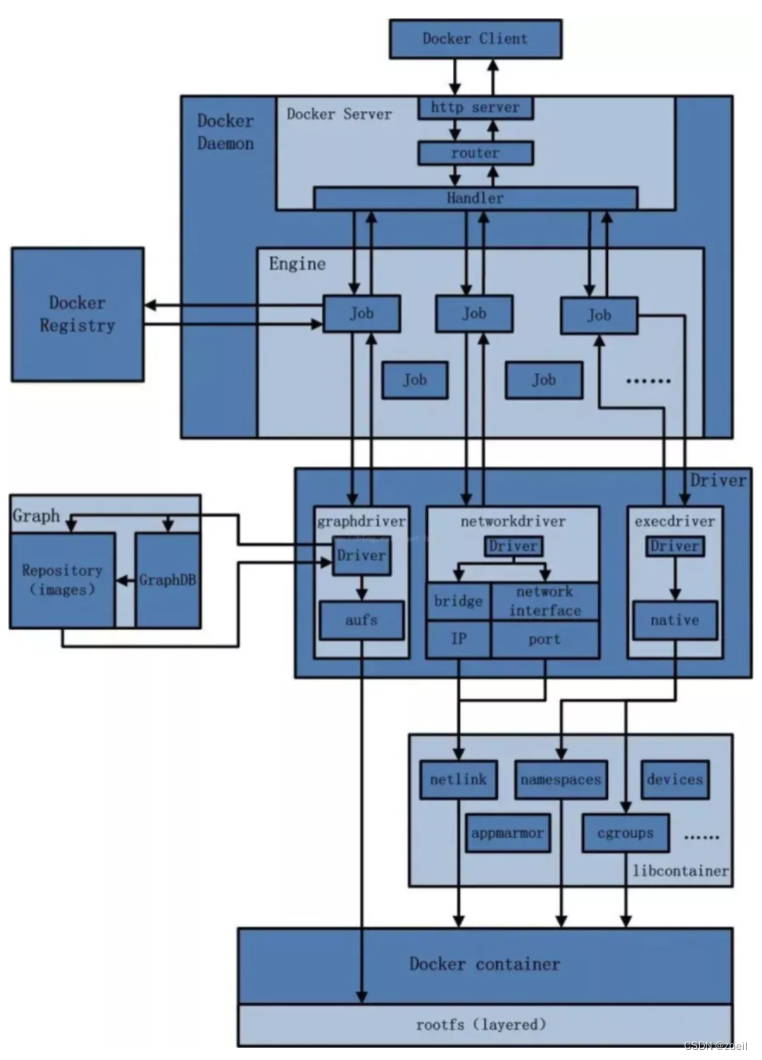
Docker网络模式解析
目录 前言 一、常用基本命令 (一)查看网络 (二)创建网络 (三)查看网络源数据 (四)删除网络 二、网络模式 (一)总体介绍 (二)…...

游山城重庆
山城楼梯多,路都是上坡。 为了赶早上8点从成都到重庆的动车,凌晨5点半就爬起床来,由于昨天喝了咖啡,所以我将尽3点才睡觉,这意味着我只睡了2个多小时。起来简单休息之后,和朋友协商好时间就一起出门了。 …...

Vuex的创建和简单使用
Vuex 1.简介 1.1简介 1.框框里面才是Vuex state:状态数据action:处理异步mutations:处理同步,视图可以同步进行渲染1.2项目创建 1.vue create 名称 2.运行后 3.下载vuex。采用的是基于vue2的版本。 npm install vuex3 --save 4.vu…...

Arduino IDE搭建Heltec开发板开发环境
Arduino IDE搭建Heltec开发板开发环境Heltec开发板开发环境下载与搭建Arduino IDE下载与安装搭建Heltec开发板的开发环境添加package URL方法通过Git的方法安装离线安装Heltec开发板开发环境下载与搭建 Arduino IDE下载与安装 Heltec的ESP系列和大部分的LoRa系列开发板都是用A…...

Using the GNU Compiler Collection 目录翻译
文章目录Introduction1 Programming Languages Supported by GCC2 Language Standards Supported by GCC2.1 C Language3 GCC Command Options3.1 Option Summary4 C Implementation-Defined Behavior6 Extensions to the C Language Family9 Binary Compatibility其他工具10 g…...

使用 OpenCV for Android 进行图像特征检测
android 开发人员,可能熟悉使用activities, fragments, intents以及最重要的一系列开源依赖库。但是,注入需要本机功能的依赖关系(如计算机视觉框架)并不像在 gradle 文件中直接添加实现语句那样简单!今天,将专注于使用 OpenCV 库…...
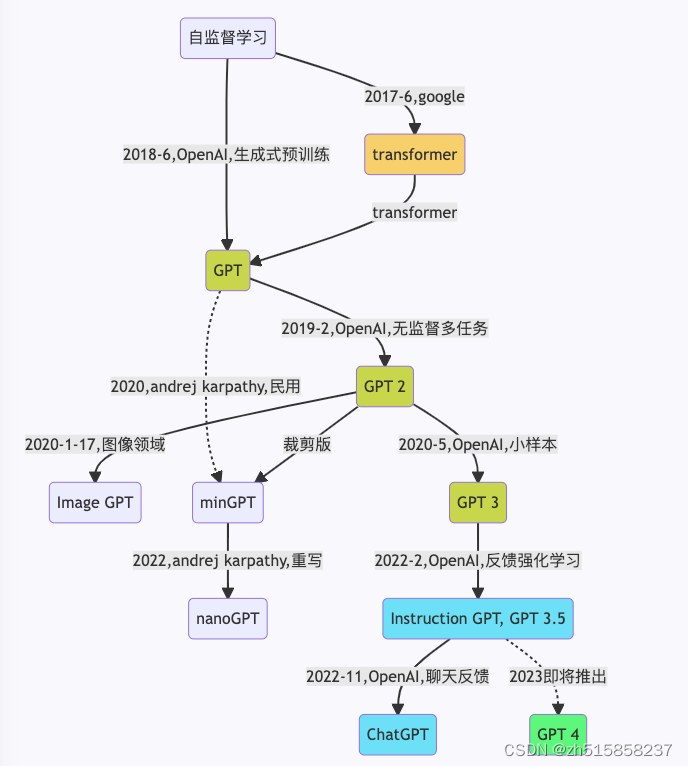
chatGPT笔记
文章目录 一、GPT之技术演进时间线二、chatGPT中的语言模型instructGPT跟传统语言LM模型最大不同点是什么?三、instructGPT跟GPT-3的网络结构是否一样四、GPT和BERT有啥区别五、chatGPT的训练过程是怎样的?六、GPT3在算数方面的能力七、GPT相比于bert的优点是什么八、元学习(…...

这么好的政策和创新基地,年轻人有梦想你就来
周末有空去参观了下一个朋友办的公司。位置和环境真不错,且租金低的离谱,半年租金才2000元,且提供4个工位。这个创新基地真不赖啊,国家鼓励创新创业,助力年轻人实现梦想。场地有办公区,休息区应有尽有&…...
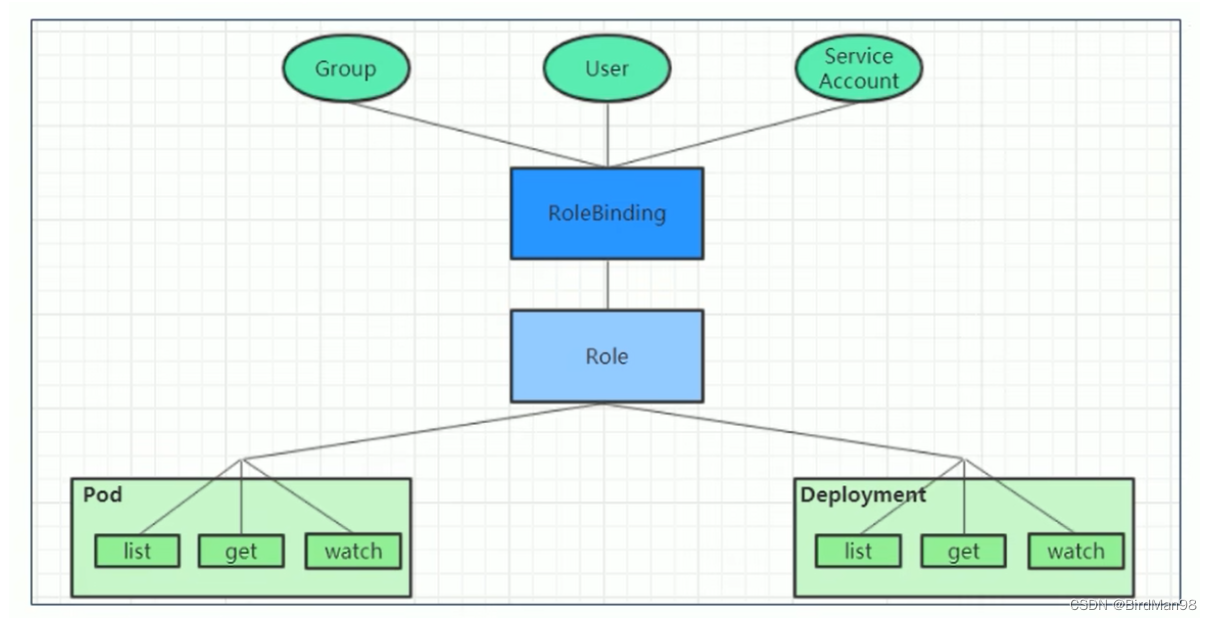
【Kubernetes】【十九】安全认证
第九章 安全认证 本章节主要介绍Kubernetes的安全认证机制。 访问控制概述 Kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。所谓的安全性其实就是保证对Kubernetes的各种客户端进行认证和鉴权操作。 客户端 在Kubernetes集群…...

Apache Flink 实时计算在美的多业务场景下的应用与实践
摘要:本文整理自美的集团实时数据负责人、资深数据架构师董奇,在 Flink Forward Asia 2022 主会场的分享。本篇内容主要分为四个部分: 实时生态系统在美的的发展和建设现状 核心传统业务场景 Flink 实时数字化转型实践 新兴业务场景 Flink …...

27 pandas 数据透视
文章目录pivot_table 函数1、index需要聚合的列名,默认情况下聚合所有数据值的列2、values在结果透视的行上进行分组的列名或其它分组键【就是透视表里显示的列】3、columns在结果透视表的列上进行分组的列名或其它分组键4、Aggfunc聚合函数或函数列表(默…...
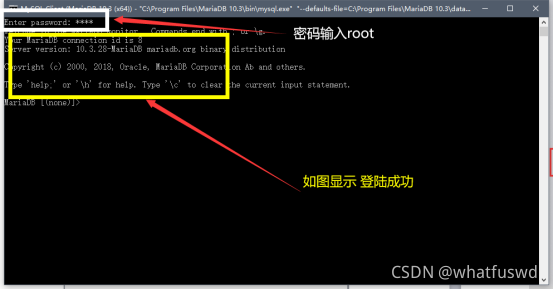
1.2 学习环境准备
文章目录1.MariaDB简介2.MariaDB服务端和客户端安装1.MariaDB简介 因为MariaDB作为MySQL的延申,其包含MySQL所有的有点,并且其包含了更丰富的特性。比如微秒的支持、线程池、子查询优化、组提交、进度报告等; 所以我们接下来将已MariaDB作为…...

Http1.0协议常识
组织:中国互动出版网(http://www.china-pub.com/)RFC文档中文翻译计划(http://www.china-pub.com/compters/emook/aboutemook.htm)E-mail:ouyangchina-pub.com译者:黄晓东(黄晓东 xd…...
“终于懂了” 系列:组件化框架 ARouter 完全解析(三)AGP/Transform/ASM—动态代码注入
ARouter系列文章: “终于懂了” 系列:组件化框架 ARouter 完全解析(一)原理全解 “终于懂了” 系列:组件化框架 ARouter 完全解析(二)APT—帮助类生成 “终于懂了” 系列:组件化框架…...

传闻腾讯引进Quest 2?我觉得可行性很低
根据36kr最新消息称,腾讯XR团队解散后,确定不碰XR硬件领域,但并未完全放弃XR规划,将转变思路和玩法,业内消息称腾讯计划引进Meta旗下Quest 2 VR一体机。消息称,该计划在2022年11月份XR部门负责人沈黎走后便…...

5个突破点:解锁时空数据金矿的ST-DBSCAN实战指南
5个突破点:解锁时空数据金矿的ST-DBSCAN实战指南 【免费下载链接】st_dbscan ST-DBSCAN: Simple and effective tool for spatial-temporal clustering 项目地址: https://gitcode.com/gh_mirrors/st/st_dbscan 问题发现:被忽视的时空关联密码 为…...

突破数据瓶颈:6大创新方法让时间序列模型性能提升150%
突破数据瓶颈:6大创新方法让时间序列模型性能提升150% 【免费下载链接】Time-Series-Library A Library for Advanced Deep Time Series Models for General Time Series Analysis. 项目地址: https://gitcode.com/GitHub_Trending/ti/Time-Series-Library 在…...

终极图像纹理合成工具:GIMP Resynthesizer 完整使用指南
终极图像纹理合成工具:GIMP Resynthesizer 完整使用指南 【免费下载链接】resynthesizer Suite of gimp plugins for texture synthesis 项目地址: https://gitcode.com/gh_mirrors/re/resynthesizer GIMP Resynthesizer 是一套功能强大的 GIMP 纹理合成插件…...

Zotero Reference插件:5个步骤实现PDF文献自动化管理
Zotero Reference插件:5个步骤实现PDF文献自动化管理 【免费下载链接】zotero-reference PDF references add-on for Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-reference Zotero Reference是一款革命性的Zotero插件,专门为学…...

现货库存MAX3221EEAE+T一款由ADI公司生产的高性能、低功耗 RS-232 收发器芯片,广泛应用于工业控制、通信设备和嵌入式系统中,具备高可靠性与出色的电气性能
MAX3221EEAET 是一款由ADI公司生产的高性能、低功耗 RS-232 收发器芯片,广泛应用于工业控制、通信设备和嵌入式系统中,具备高可靠性与出色的电气性能 。 核心性能参数 协议标准:完全兼容 EIA/TIA-232 标准,支持 RS-232 电…...

5大核心模块构建学术排版系统:STIX Two字体全面应用指南
5大核心模块构建学术排版系统:STIX Two字体全面应用指南 【免费下载链接】stixfonts OpenType Unicode fonts for Scientific, Technical, and Mathematical texts 项目地址: https://gitcode.com/gh_mirrors/st/stixfonts 一、价值解析:为什么专…...

Qwen3-14B私有化部署指南:基于RTX 4090D的GPU算力优化全流程
Qwen3-14B私有化部署指南:基于RTX 4090D的GPU算力优化全流程 1. 镜像概述与核心优势 Qwen3-14B是通义千问推出的大语言模型,具备强大的对话、推理和生成能力。本镜像针对RTX 4090D显卡进行了深度优化,解决了大模型私有化部署中的三大痛点&a…...

ESTree节点遍历终极指南:深度优先与广度优先算法完整解析
ESTree节点遍历终极指南:深度优先与广度优先算法完整解析 【免费下载链接】estree The ESTree Spec 项目地址: https://gitcode.com/gh_mirrors/es/estree JavaScript开发者们,你们是否在构建代码分析工具时遇到过AST遍历的难题?&…...

LAV Filters专业配置进阶指南:深度解析开源解码器架构与性能优化
LAV Filters专业配置进阶指南:深度解析开源解码器架构与性能优化 【免费下载链接】LAVFilters LAV Filters - Open-Source DirectShow Media Splitter and Decoders 项目地址: https://gitcode.com/gh_mirrors/la/LAVFilters LAV Filters是一套基于FFmpeg的高…...

Qwen-Image-2512像素艺术生成实操:Gradio界面各参数作用与推荐值
Qwen-Image-2512像素艺术生成实操:Gradio界面各参数作用与推荐值 1. 快速上手像素艺术生成 想创作复古游戏风格的像素画?Qwen-Image-2512结合Pixel Art LoRA的解决方案让你轻松实现。这个服务特别适合游戏开发者、独立艺术家和怀旧风格爱好者ÿ…...