【ELK日志收集系统】
目录
一、概述
1.作用
2.为什么使用?
二、组件
1.elasticsearch
1.1 作用
1.2 特点
2.logstash
2.1 作用
2.2 工作过程
2.3 INPUT
2.4 FILETER
2.5 OUTPUTS
3.kibana
三、架构类型
1.ELK
2.ELKK
3.ELFK
4.ELFKK
四、案例 - 构建ELK集群
1.环境配置
2.安装node1与node2节点的elasticsearch
2.1 安装
2.2 配置
2.3 启动elasticsearch服务
2.4 查看节点信息
3.在node1安装elasticsearch-head插件
3.1 安装node
3.2 拷贝命令
3.3 安装elasticsearch-head
3.4 修改elasticsearch配置文件
3.5 启动elasticsearch-head
3.6 访问
3.7 在node1的终端中输入:
4.node1服务器安装logstash
5.ogstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
编辑
6.node1节点安装kibana
7.企业案例
一、概述
ELK由三个组件构成
1.作用
- 日志收集
- 日志分析
- 日志可视化
2.为什么使用?
- 日志对于分析系统、应用的状态十分重要,但一般日志的量会比较大,并且比较分散。
- 如果管理的服务器或者程序比较少的情况我们还可以逐一登录到各个服务器去查看、分析。但如果服务器或者程序的数量比较多了之后这种方法就显得力不从心。基于此,一些集中式的日志系统也就应用而生。目前比较有名成熟的有,Splunk(商业)、FaceBook 的Scribe、Apache的Chukwa Cloudera的Fluentd、还有ELK等等。
二、组件
1.elasticsearch
1.1 作用
- 日志分析
- 开源的日志收集、分析、存储程序
1.2 特点
- 分布式
- 零配置
- 自动发现
- 索引自动分片
- 索引副本机制
- Restful风格接口
- 多数据源
- 自动搜索负载
2.logstash
2.1 作用
- 日志收集
- 搜集、分析、过滤日志的工具
2.2 工作过程
- 一般工作方式为c/s架构,Client端安装在需要收集日志的服务器上,Server端负责将收到的各节点日志进行过滤、修改等操作,再一并发往Elasticsearch上去
- Inputs → Filters → Outputs
- 输入-->过滤-->输出
2.3 INPUT
- File:从文件系统的文件中读取,类似于tail -f命令
- Syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
- Redis:从redis service中读取
- Beats:从filebeat中读取
2.4 FILETER
- Grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
- 官方提供的grok表达式:logstash-patterns-core/patterns at main · logstash-plugins/logstash-patterns-core · GitHub
- Grok在线调试:Grok Debugger
- Mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
- Drop:丢弃一部分Events不进行处理。
- Clone:拷贝Event,这个过程中也可以添加或移除字段。
- Geoip:添加地理信息(为前台kibana图形化展示使用)
2.5 OUTPUTS
- Elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
- File:将Event数据保存到文件中。
- Graphite:将Event数据发送到图形化组件中,踏实一个当前较流行的开源存储图形化展示的组件。
3.kibana
- 日志可视化
- 为Logstash和ElasticSearch在收集、存储的日志基础上进行分析时友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
三、架构类型
1.ELK
es
logstash
kibana
2.ELKK
es
logstash
kafka
kibana
3.ELFK
es
logstash 重量级、占用系统资源较多
filebeat 轻量级、占用系统资源较少
kibana
4.ELFKK
es
logstash
filebeat
kafka
kibana
四、案例 - 构建ELK集群
1.环境配置
设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
node1:
hostnamectl set-hostname node1
bash
vim /etc/hosts
192.168.42.3 node1
192.168.42.4 node2

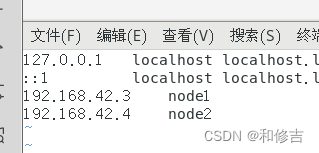
node2:
hostnamectl set-hostname node2
bash
vim /etc/hosts
192.168.42.3 node1
192.168.42.4 node2

2.安装node1与node2节点的elasticsearch
2.1 安装
mv elk-apppack elk
cd elk
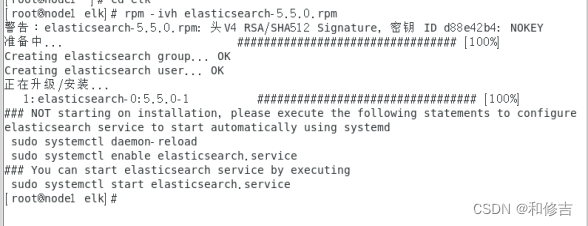
rpm -ivh elasticsearch-5.5.0.rpm
2.2 配置
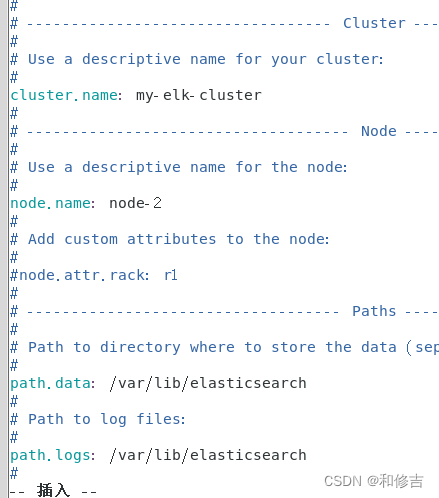
node1:
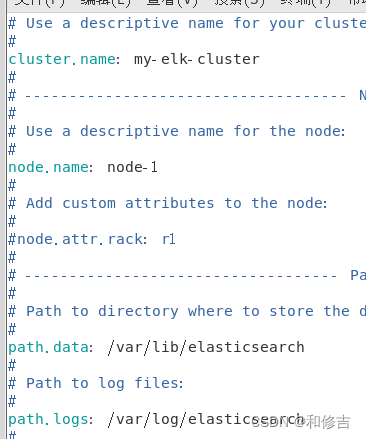
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
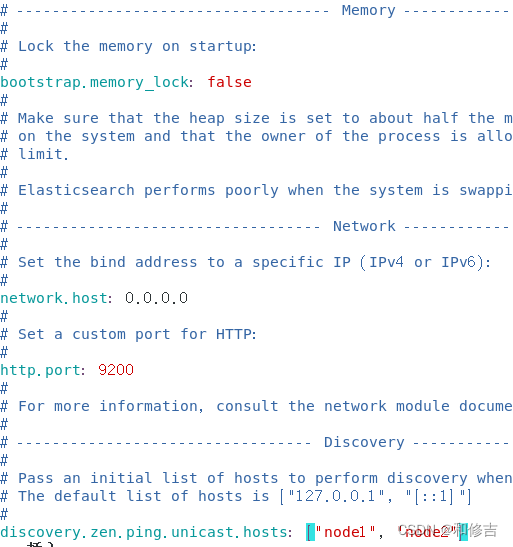
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
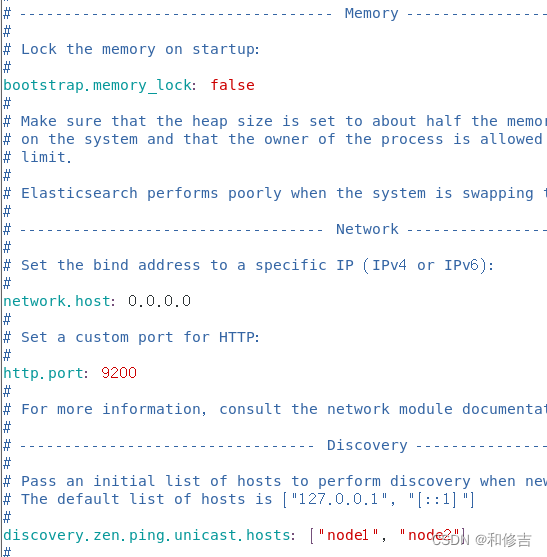
node2:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
2.3 启动elasticsearch服务
node1和node2
systemctl start elasticsearch
![]()
![]()
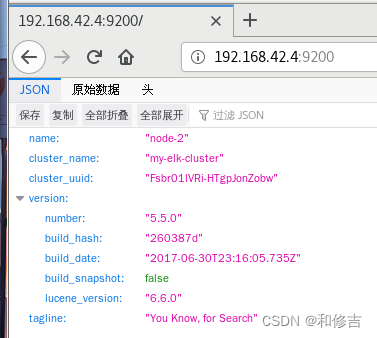
2.4 查看节点信息
http://192.168.42.3:9200
http://192.168.42.4:9200

3.在node1安装elasticsearch-head插件
3.1 安装node
cd elk
ls
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install
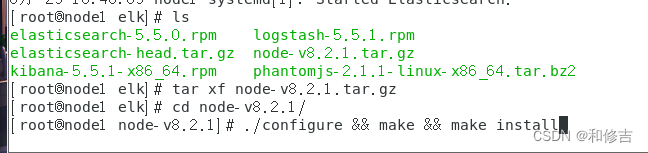
3.2 拷贝命令
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin

3.3 安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head

npm install
3.4 修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin:"*" //跨域访问允许的域名地址

重启服务: systemctl restart elasticsearch
![]()
3.5 启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
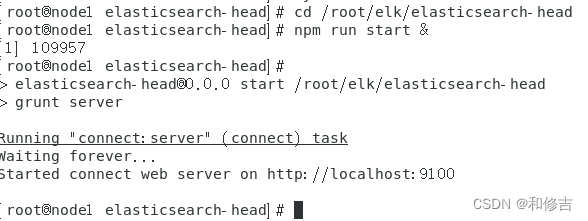
查看监听: netstat -anput | grep :9100

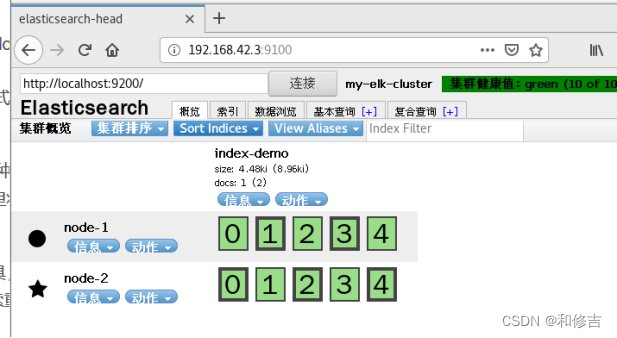
3.6 访问
http://192.168.42.3:9100
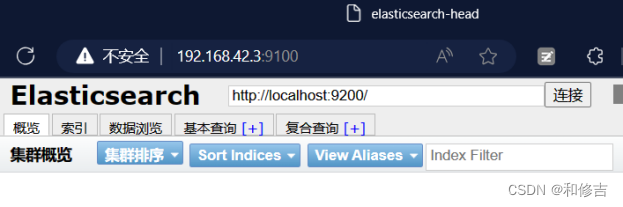
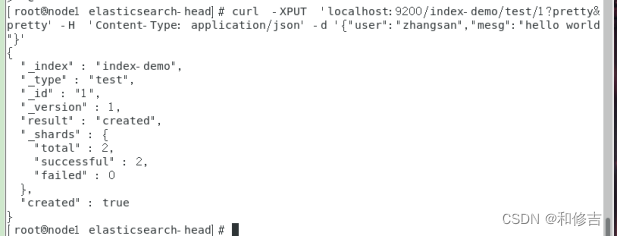
3.7 在node1的终端中输入:
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
刷新浏览器可以看到对应信息即可
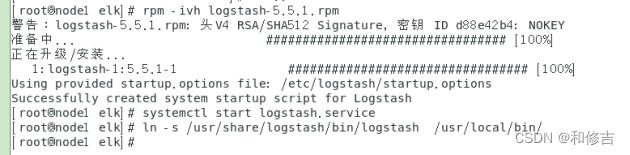
4.node1服务器安装logstash
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/
测试1: 标准输入与输出
logstash -e 'input{ stdin{} }output { stdout{} }'

测试2: 使用rubydebug解码
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'

测试3:输出到elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.42.3:9200"]} }'
查看结果:
http://192.168.42.3:9100

5.ogstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
通过logstash收集系统信息日志
chmod o+r /var/log/messages
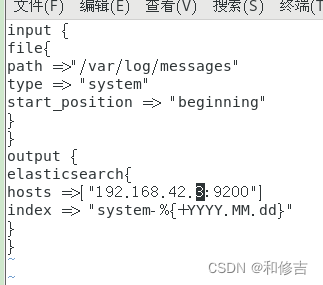
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.42.1:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
重启日志服务: systemctl restart logstash
查看日志: http://192.168.42.3:9100
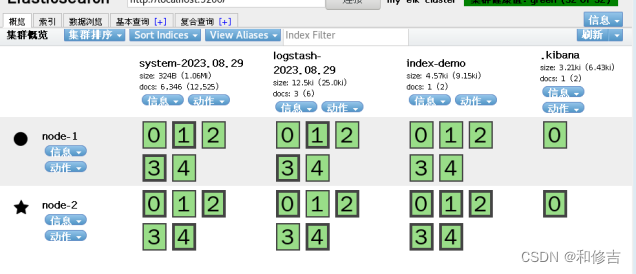
6.node1节点安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm

配置kibana
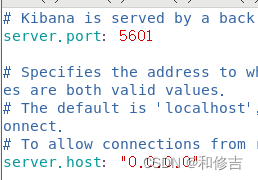
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.42.3:9200"
//和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引

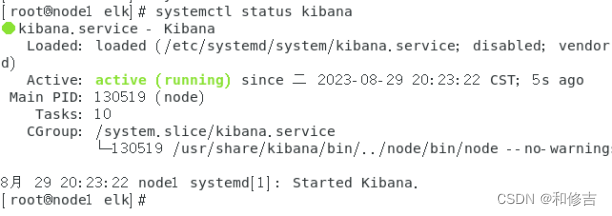
启动kibana
systemctl start kibana
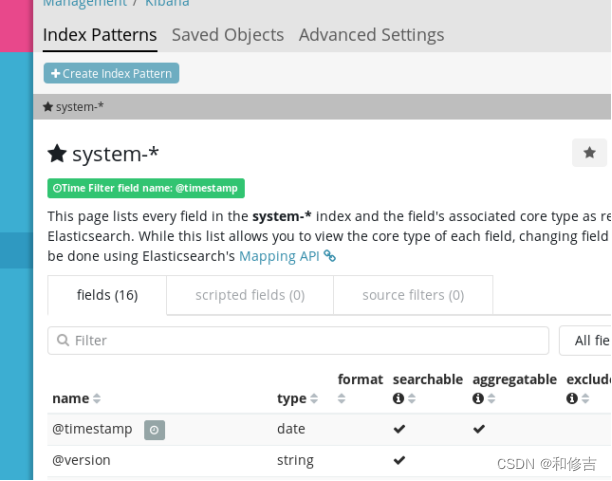
访问kibana :
http://192.168.42.3:5601
首次访问需要添加索引,我们添加前面已经添加过的索引:system-*
7.企业案例
收集httpd访问日志信息
在httpd服务器上安装logstash,参数上述安装过程,可以不进行测试
logstash在httpd服务器上作为agent(代理),不需要启动
编写httpd日志收集配置文件
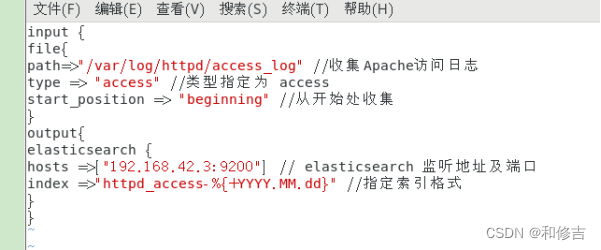
vim /etc/logstash/conf.d/httpd.conf
input {
file{
path=>"/var/log/httpd/access_log" //收集Apache访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
output{
elasticsearch {
hosts =>["192.168.42.3:9200"] // elasticsearch 监听地址及端口
index =>"httpd_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
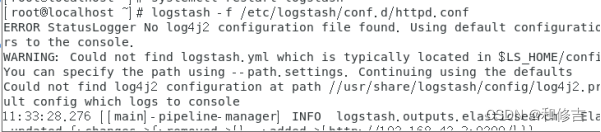
使用logstash命令导入配置:
logstash -f /etc/logstash/conf.d/httpd.conf
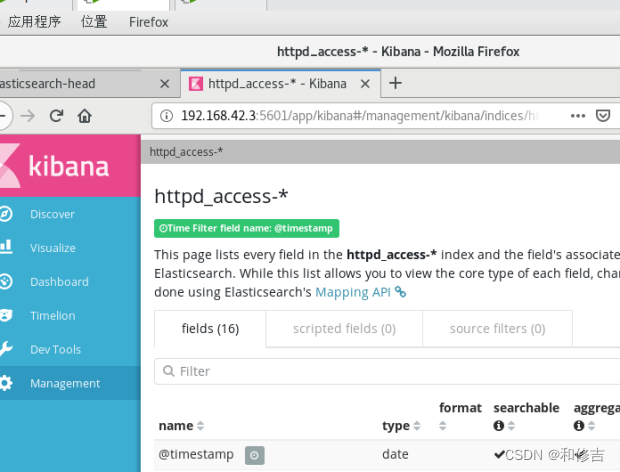
使用kibana查看即可! http://192.168.42.3:5601 查看时在mangement选项卡创建索引httpd_access-* 即可!
相关文章:
【ELK日志收集系统】
目录 一、概述 1.作用 2.为什么使用? 二、组件 1.elasticsearch 1.1 作用 1.2 特点 2.logstash 2.1 作用 2.2 工作过程 2.3 INPUT 2.4 FILETER 2.5 OUTPUTS 3.kibana 三、架构类型 1.ELK 2.ELKK 3.ELFK 4.ELFKK 四、案例 - 构建ELK集群 1.环境…...

Java项目中实现信号的连续接收
系列文章目录 文章目录 系列文章目录前言一、监听信号二、信号处理逻辑三、停止信号监听总结 前言 在Java项目中,信号的连续接收是一项重要的任务,特别是在处理异步事件或者需要对外部事件做出响应时。本篇博客将介绍如何在Java项目中实现信号的连续接收…...

vue权限管理——按钮控制
1.按钮根据后端返回数据决定展示与否 根据right中的数据对应增删改查按钮 const menuList [{id: 1, path:/uploadSpec,authName: "上传spec", icon: User, children:[], rights:[view,add,edit,delete]},{id: 2, path:/showSpec, authName: "Spec预览",…...
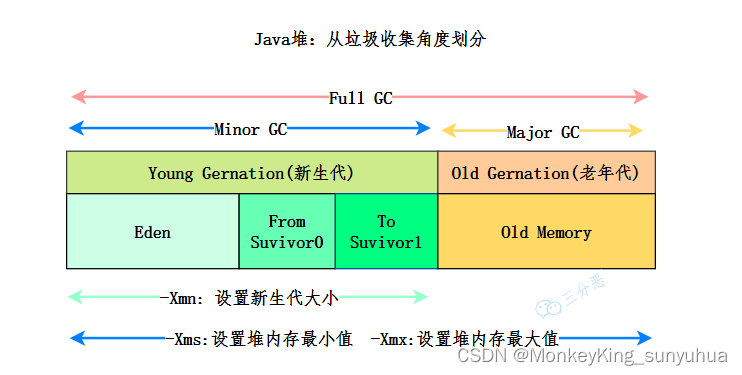
jvm的内存区域
JVM 内存分为线程私有区和线程共享区,其中方法区和堆是线程共享区,虚拟机栈、本地方法栈和程序计数器是线程隔离的数据区。 1)程序计数器 程序计数器(Program Counter Register)也被称为 PC 寄存器,是一块…...
即时通讯开发中的性能优化技巧
即时通讯开发在如今的数字化社会中扮演着重要角色,然而,随着用户对即时通讯应用的需求不断增长,开发者们面临着使其应用保持高性能和可靠性的挑战。本文将探讨即时通讯开发中关键的性能优化技巧,帮助开发者们提升应用的用户体验和…...

flinkcdc同步完全量数据就不同步增量数据了
flinkcdc同步完全量数据就不同步增量数据了 使用flinkcdc同步mysql数据,使用的是全量采集模型 startupOptions(StartupOptions.earliest()) 全量阶段同步完成之后,发现并不开始同步增量数据,原因有以下两个: 原因1: …...
)
VBA:Application.GetOpenFilename打开指定文件夹里的excel类型文件(xls、xlsx)
GetOpenFilename相当于Excel打开窗口,通过该窗口选择要打开的文件,并可以返回选择的文件完整路径和文件名。 Application.GetOpenFilename(“文件类型筛选规则(就是说明)”,“优先显示第几个类型的文件”,“标题”,“是否允许选择多个文件名”) 打开类型…...
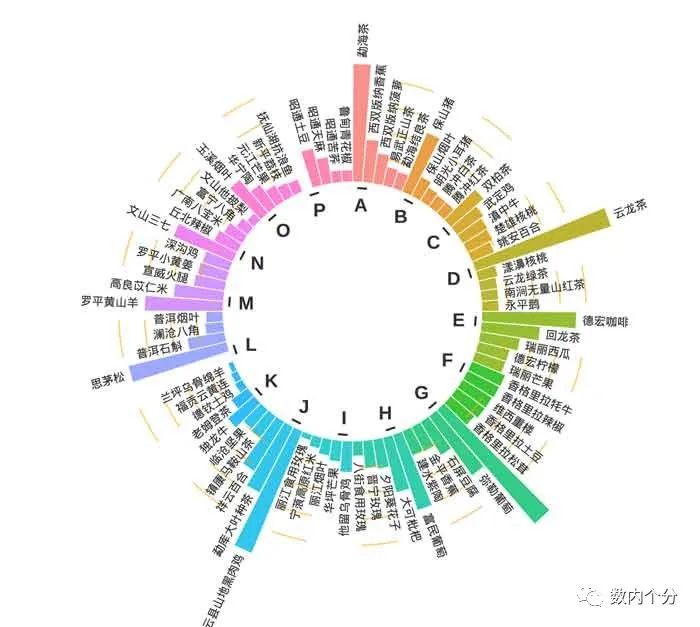
利用R作圆环条形图
从理念上看,本质就是增加了圆环弧度的条形图。如上图2。 需要以下步骤: 数据处理,将EXCEL中的数据做成3*N的表格导入系统,代码如下:library(tidyverse) library(stringr)library(ggplot2)library(viridis) stuper &…...
JavaScript(笔记)
目录 Hello World JavaScript 的变量 JavaScript 动态类型 隐式类型转换 JavaScript 数组 JavaScript 函数 JavaScript 中变量的作用域 对象 DOM 选中页面元素 事件 获取 / 修改元素内容 获取 / 修改元素属性 获取 / 修改 表单元素属性 获取 / 修改样式属性 新…...
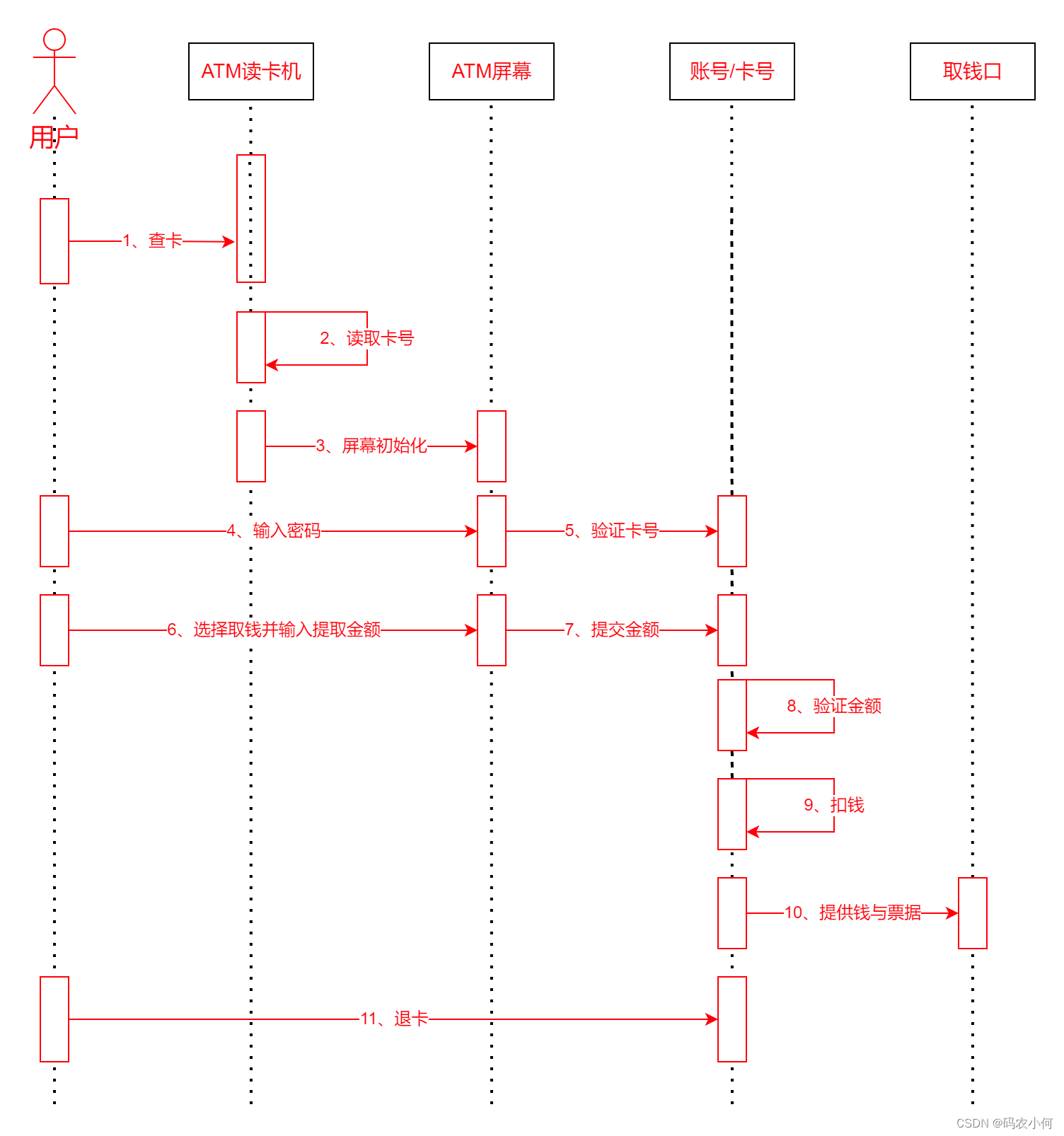
软件工程(九) UML顺序-活动-状态-通信图
顺序图和后面的一些图,要求没有用例图和类图那么高,但仍然是比较重要的,我们也需要按程度去了解。 1、顺序图 顺序图(sequence diagram, 顺序图),顺序图是一种交互图(interaction diagram),它强调的是对象之间消息发送的顺序,同时显示对象之间的交互。 下面以一个简…...
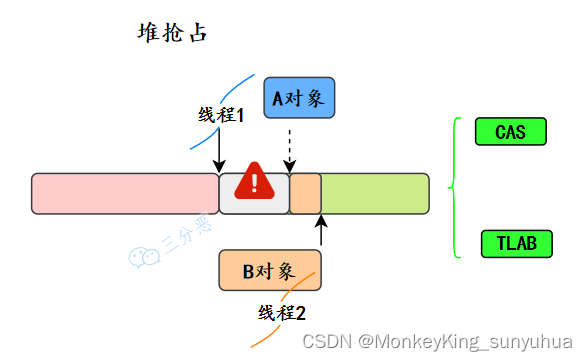
JVM 是怎么设计来保证new对象的线程安全
1、采用 CAS 分配重试的方式来保证更新操作的原子性 2、每个线程在 Java 堆中预先分配一小块内存,也就是本地线程分配缓冲(Thread Local AllocationBuffer,TLAB),要分配内存的线程,先在本地缓冲区中分配&a…...

【JavaEE基础学习打卡00】该专栏知识大纲在这里!
目录 前言一、为什么有该教程二、教程内容介绍1.JavaEE2.JDBC3.JSP编程4.JavaBean5.Servlet6.综合案例7.拦截器、过滤器 三、学习前置要求四、课程服务总结 前言 📜 本系列教程适用于 Java Web 初学者、爱好者,小白白。我们的天赋并不高,可贵…...

C# 跨线程访问窗体控件
在不加任何修饰的情况下,C# 默认不允许跨线程访问控件,实际在项目开发过程中,经常使用跨线程操作控件属性,需要设置相关属性才能正确使用,两种方法设置如下: 方法1:告诉编译器取消跨线程访问检…...
Ctenos7安装mysql-8.1.0/tomcat-9.0.80/LNMT部署
目录 一、实验拓扑 二、部署mysql 三、部署Tomcat 四、配置NGINX 五、 配置NGINX的双机热备提高可用性 一、实验拓扑 二、部署mysql 官网下载地址https://dev.mysql.com/downloads/mysql/ 1、移除mariadb,安装所需应用 mysql-8.1.0 社区版 安装说明官网下载地址…...
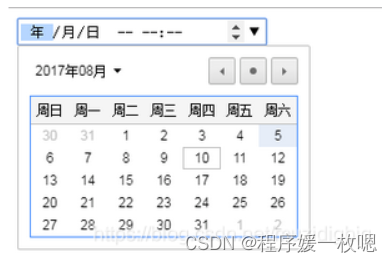
input时间表单默认样式修改(input[type=“date“])
一、时间选择的种类: HTML代码: <input type"date" value"2018-11-15" />选择日期: 选择时间: <input type"time" value"22:52" />在这里插入图片描述 选择星期: <…...
首页搜索框传递参数,并在搜索页面中的搜索框中进行显示,搜索框绑定回车键进行搜索
实现搜索条件和搜索内容固定,以及回车键搜索跳转 1.写出搜索条件和搜索框 <form class"parent"><select id"searchSelect" style"border: 1px solid #325da7;border-right: none;" value"resource"><opt…...
【Vue3+Ts】项目启动准备和配置项目代码规范和css样式的重置
项目启动准备 创建项目( 使用Vite 构建工具创建项目模板)目录介绍插件安装创建别名编译说明项目配置配置icon和标题配置项目别名配置ts.config.json检测vscode的插件是否配置 配置项目代码规范集成editorconfig配置prettier工具库ESLint检测配置 CSS样式…...

Java【手撕双指针】LeetCode 15. “三数之和“, 图文详解思路分析 + 代码
文章目录 前言一、三数之和1, 题目2, 思路分析3, 代码 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表, 链表, 堆…...

Flutter:自定义组件的上下左右弹出层
背景 最近要使用Flutter实现一个下拉菜单,需求就是,在当前组件下点击,其下方弹出一个菜单选项,如下图所示: 实现起来,貌似没什么障碍,在Flutter中本身就提供了弹出层PopupMenuButton组件和show…...

C++处理终端程序中断或意外退出的情况
目录 背景和需求解决方法关于信号类型 背景和需求 Linux环境中,有一个可执行程序,假设该程序的运行生命周期需要调用下面四个函数: int connect(); int start();int end(); int disconnect();如果用户在程序运行期间,手动CTRLC或…...

如何用openpilot升级你的驾驶体验:让300+车型秒变智能座驾
如何用openpilot升级你的驾驶体验:让300车型秒变智能座驾 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tren…...
)
pointer reference作为顶层参数(三)
一、核心代码#include "array_FIFO.h"//void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { #pragma HLS INTERFACE m_axi depth4 portd_i //#pragma HLS INTERFACE s_axilite register…...

Sequin实战教程:构建企业级变更数据捕获管道
Sequin实战教程:构建企业级变更数据捕获管道 【免费下载链接】sequin Postgres change data capture to streams, queues, and search indexes like Kafka, SQS, Elasticsearch, HTTP endpoints, and more 项目地址: https://gitcode.com/gh_mirrors/se/sequin …...

【大模型12步学习路线 · 第12步 · ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM看懂Spec
【大模型12步学习路线 第12步 ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM"看懂"Spec 时序图 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ①原理篇 —— 最后一步,Veri-Copilot v1.0 大结局。 前…...

Emacs-which-key排序与分页功能详解:高效管理大量快捷键的完整指南
Emacs-which-key排序与分页功能详解:高效管理大量快捷键的完整指南 【免费下载链接】emacs-which-key Emacs package that displays available keybindings in popup 项目地址: https://gitcode.com/gh_mirrors/em/emacs-which-key Emacs-which-key是Emacs编…...
】)
【项目实训(个人8)】
继续进行法律文书智能摘要系统的开发,新增了几个功能,并优化了用户体验概述本次开发为法律文书智能摘要系统新增了两项核心功能。其一是摘要版本管理,支持同一文档的多版本摘要生成、存储、对比和回滚。用户在生成摘要时,系统自动…...

揭秘Midjourney V6拟物化失控真相:为什么87%的设计师调不出真实皮革/金属/织物质感?
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6拟物化失控现象的底层本质 Midjourney V6 引入的拟物化(PhotorealismMaterial Fidelity)增强机制,并非单纯提升纹理细节,而是通过隐式材质…...

开发AI应用时如何借助Taotoken模型广场进行选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI应用时如何借助Taotoken模型广场进行选型 当开发者着手构建一个AI应用时,选择合适的模型往往是项目成功的关键起…...

Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践
Robo 3T:原生跨平台MongoDB管理工具的架构解析与技术实践 【免费下载链接】robomongo Native cross-platform MongoDB management tool 项目地址: https://gitcode.com/gh_mirrors/ro/robomongo Robo 3T作为一款原生跨平台的MongoDB管理工具,为开…...

通过Python快速调用Taotoken实现自动化文档生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Python快速调用Taotoken实现自动化文档生成 对于嵌入式或单片机开发者而言,为Keil5项目编写和维护技术文档是一项耗…...