LinkedList正确的遍历方式-附源码分析
1.引子
记得之前面试过一个同学,有这么一个题目:
LinkedList<String> list = new LinkedList<>();for (int i = 0; i < 1000; i++) {list.add(i + "");}
请根据上面的代码,请选择比较恰当的方式遍历这个集合,并简要解释原因。
说实话,比较出乎我的意外,很多同学都用for循环的方式来遍历:、
for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}
居于此,我们从头看一下这个LinkedList集合。
2. LinkedList
2.1 LinkedList类的层次结构
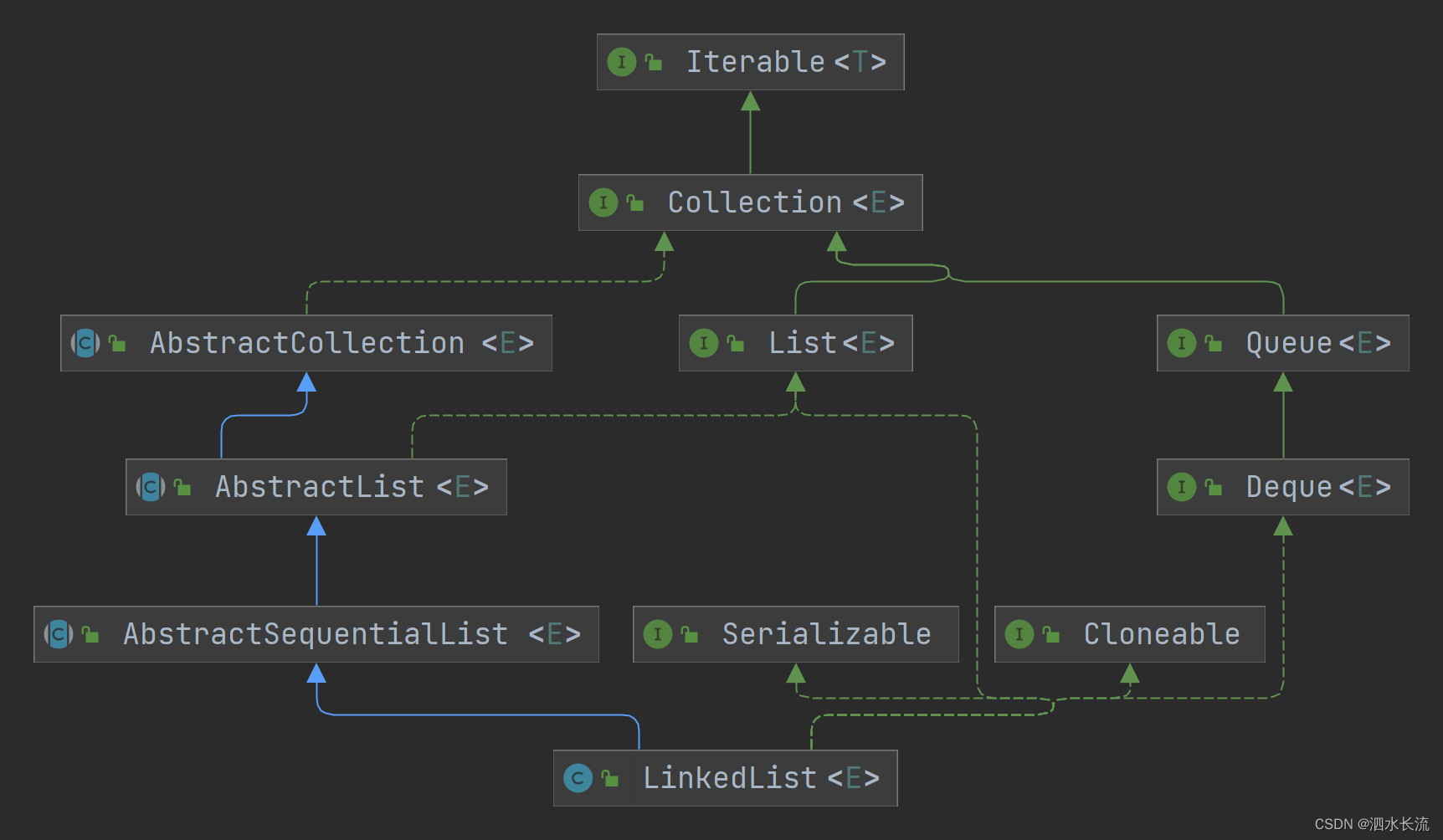
LinkedList实现了List接口、Deque接口、Cloneable接口、Serializable接口,同时继承了AbstractSequentialList抽象类。通过实现Deque接口,使其具有了Queue队列类型的特点,通过实现Cloneable、Serializable接口,可以实现克隆和序列化。
通过它的继承与实现类我们看到,与ArrayList相比,它并没有实现RandomAccess随机访问接口,在一定程度上说明了它不具备随机访问的特性。
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
2.2 LinkedList类的属性及底层实现
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{//集合的元素个数transient int size = 0;//链表头,即链表首个元素transient Node<E> first;//链表尾,即链表最后一个元素transient Node<E> last;}
LinkedList主要有size(节点个数)、first(链表头节点)、last(链表尾节点)。我们仔细看它的源码 ,会发现比较奇怪的地方,就是属性上也加上了transient修饰(禁止序列化),与ArrayList相比, 这里加transient修饰主要是为了避免外部序列化方法仅仅序列化头尾,所以和ArrayList一样,也自行实现了readObject 和 writeObject 进行序列化与反序列化。
我们知道,LinkedList是基于双向链表实现的,通过上面LinkedList的属性源码看到,用到了一个Node类型来表示节点,那我们看下Node这个类型。
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
这个Node中包含三个属性:item(当前节点数据),next(上一个节点)、prev(下一个节点),所以LinkedList就是由Node类型对象连接而成的一个双向链表。
2.3 LinkedList的构造函数
ArrayList一共有三个构造函数:
1.LinkedList list = new LinkedList<>();默认无参构造函数,创建一个空的列表;
2.传入一个集合类型进行初始化:
HashSet<String> set = new HashSet<>();set.add("a");set.add("b");set.add("c");set.add("a");LinkedList<String> list = new LinkedList<>(set);
源码如下:
public LinkedList(Collection<? extends E> c) {this();addAll(c);}public boolean addAll(Collection<? extends E> c) {return addAll(size, c);}public boolean addAll(int index, Collection<? extends E> c) {checkPositionIndex(index);Object[] a = c.toArray();int numNew = a.length;if (numNew == 0)return false;Node<E> pred, succ;if (index == size) {succ = null;pred = last;} else {succ = node(index);pred = succ.prev;}for (Object o : a) {@SuppressWarnings("unchecked") E e = (E) o;Node<E> newNode = new Node<>(pred, e, null);if (pred == null)first = newNode;elsepred.next = newNode;pred = newNode;}if (succ == null) {last = pred;} else {pred.next = succ;succ.prev = pred;}size += numNew;modCount++;return true;}
2.4 LinkedList的基本方法
2.4.1 LinkedList新增元素
1.list.add(“a”) 在链表尾添加元素
public boolean add(E e) {linkLast(e);return true;}void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;}
2.list.add(4,“b”) 在链表某个下标位置添加元素
public void add(int index, E element) {checkPositionIndex(index);if (index == size)linkLast(element);elselinkBefore(element, node(index));}Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {//如果在上半部分,从头部开始遍历Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {//如果在下半部分,从尾部开始倒序遍历Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;}
从上面的源码我们看到,如果添加的元素不再头或者尾,那么每添加一个元素,都要对链表进行遍历(最多需要遍历n/2次),性能是比较低下的。
3.list.addFirst(“e”);在链表头添加元素
public void addFirst(E e) {linkFirst(e);}private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)last = newNode;elsef.prev = newNode;size++;modCount++;}
4.list.addLast(“g”);在链表尾添加元素
public void addLast(E e) {linkLast(e);}void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;}
小结:从上面的源码我们看到,新增元素的时候,尽量不要使用指定下标的方式插入下链表中间,性能会非常差。
2.4.2 LinkedList删除元素
1.list.remove();删除第一个节点,这个和list.removeFirst();
public E remove() {return removeFirst();}public E removeFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return unlinkFirst(f);}
2.list.remove();list.remove(“d”);根据某个元素值,删除节点
public boolean remove(Object o) {if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;}
从源码上看到,这个删除方法从头遍历链表,最多要遍历n次,性能比较低。
3. list.remove(n);根据下标,删除节点
public E remove(int index) {checkElementIndex(index);return unlink(node(index));}//这里还用到了node这个方法:Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {//如果在上半部分,从头部开始遍历Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {//如果在下半部分,从尾部开始倒序遍历Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
这里还是需要对链表进行遍历,所以这种删除元素的方式,性能也比较低。
4. list.removeLast(); 删除最后一个节点
public E removeLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return unlinkLast(l);}private E unlinkLast(Node<E> l) {// assert l == last && l != null;final E element = l.item;final Node<E> prev = l.prev;l.item = null;l.prev = null; // help GClast = prev;if (prev == null)first = null;elseprev.next = null;size--;modCount++;return element;}
2.4.3 LinkedList获取元素
1.list.get(n);根据下标获取元素
public E get(int index) {checkElementIndex(index);return node(index).item;}
这里又遇到了node(index)方法,只要遇到这个方法,我们就知道,又要从头或者尾来逐个遍历元素了,性能比较差。
2.list.getFirst();获取第一个节点元素
public E getFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return f.item;}
3.list.getLast();获取最后一节点元素
public E getLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return l.item;}
2.4.4 LinkedList遍历元素
2.4.4.1 使用下标索引遍历 for(; ; )
LinkedList<String> list = new LinkedList<>();for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}
通过上面的源码分析,这种遍历获取元素的方式性能极差,因为每获取一个元素,都要从头或者为遍历一次,所以相当于外部循环又嵌套了一个内部循环,性能是相当差的。
2.4.4.2 使用迭代器遍历
LinkedList<String> list = new LinkedList<>();Iterator<String> iterator = list.iterator();while (iterator.hasNext()){System.out.println(iterator.next());}
2.4.4.3 使用foreach遍历
LinkedList<String> list = new LinkedList<>();for (String s:list){System.out.println(s);}
但其实使用foreach遍历和使用迭代器遍历是一样的,使用foreach遍历,代码编译的时候也会转变成迭代器遍历:
LinkedList<String> list = new LinkedList();Iterator var3 = list.iterator();while(var3.hasNext()) {String s = (String)var3.next();System.out.println(s);}
2.4.5 小结:通过上面的三种(其实是两种)遍历方法,显而易见,应该使用第2和第3种,避免使用for的下标遍历,因为这种下标遍历的性能实在是太差了。
相关文章:
LinkedList正确的遍历方式-附源码分析
1.引子 记得之前面试过一个同学,有这么一个题目: LinkedList<String> list new LinkedList<>();for (int i 0; i < 1000; i) {list.add(i "");}请根据上面的代码,请选择比较恰当的方式遍历这个集合,并…...
【蓦然回首忆Java·基础卷Ⅱ】
文章目录对象内存解析方法的参数传递机制关键字:package、importpackage(包)JDK中主要的包介绍import(导入)JavaBeanUML类图继承的一些细节封装性中的4种权限修饰关键字:supersuper的理解super的使用场景子类中调用父类被重写的方法子类中调用父类中同名…...
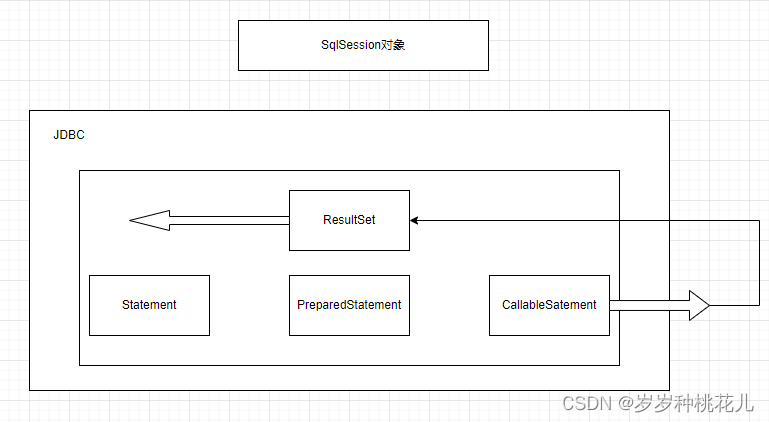
Mybatis源码分析系列之第二篇:Mybatis的数据存储对象
前言:SQLSession是对JDBC的封装 一:SQLSession和JDBC的对照说明 左边是我们的客户端程序,右边是我们的MySQL数据仓,或者叫MySQL实例 Mybatis是对JDBC的封装,将JDBC封装成了一个核心的SQLSession对象 JDBC当中的核心对…...

防护设备检测实验室建设完整方案SICOLAB
防护设备检测实验室建造布局方案SICOLAB一、防护设备检测实验室通常需要划分为几个功能区域,包括:1、样品准备区:用于样品的接收、处理、准备等工作,通常包括样品接收台、洗手池、样品切割机等设备。2、实验操作区:用于…...
Linux知识之主机状态
1、查看系统资源占用 •可以通过top命令查看CPU、内存使用情况,类似Windows的任务管理器默认每5秒刷新一次,语法:直接输入top即可,按q或ctrl c退出 2、 top命令内容详解 •第一行:top:命令名称࿰…...

是时候为您的银行机构选择构建一个知识库了!
知识管理和自助服务客户支持在银行业至关重要。选择正确的知识库对于帮助客户和在内部共享信息同样重要。繁重的法规和合规性需求意味着银行必须在他们选择的知识库类型上投入大量思考。许多银行知识库已经过时,无法为客户提供成功使用您的产品和服务所需的信息。在…...
「TCG 规范解读」第7章 TPM工作组 TPM 总结
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...

一、Plugin Constructing the Boilerplate
构建样板文件 在本章中,你将学习如何为一个新插件构建最少的代码。从起点开始,您将看到如何获取GStreamer模板源代码。然后,您将学习如何使用一些基本工具来复制和修改模板插件,以创建一个新的插件。如果您遵循这里的示例&#x…...

15、存储过程与函数
文章目录1 存储过程概述1.1 理解1.2 分类2 创建存储过程2.1 语法分析2.2 代码举例3 调用存储过程3.1 调用格式3.2 代码举例3.3 如何调试4 存储函数的使用4.1 语法分析4.2 调用存储函数4.3 代码举例4.4 对比存储函数和存储过程5 存储过程和函数的查看、修改、删除5.1 查看5.2 修…...
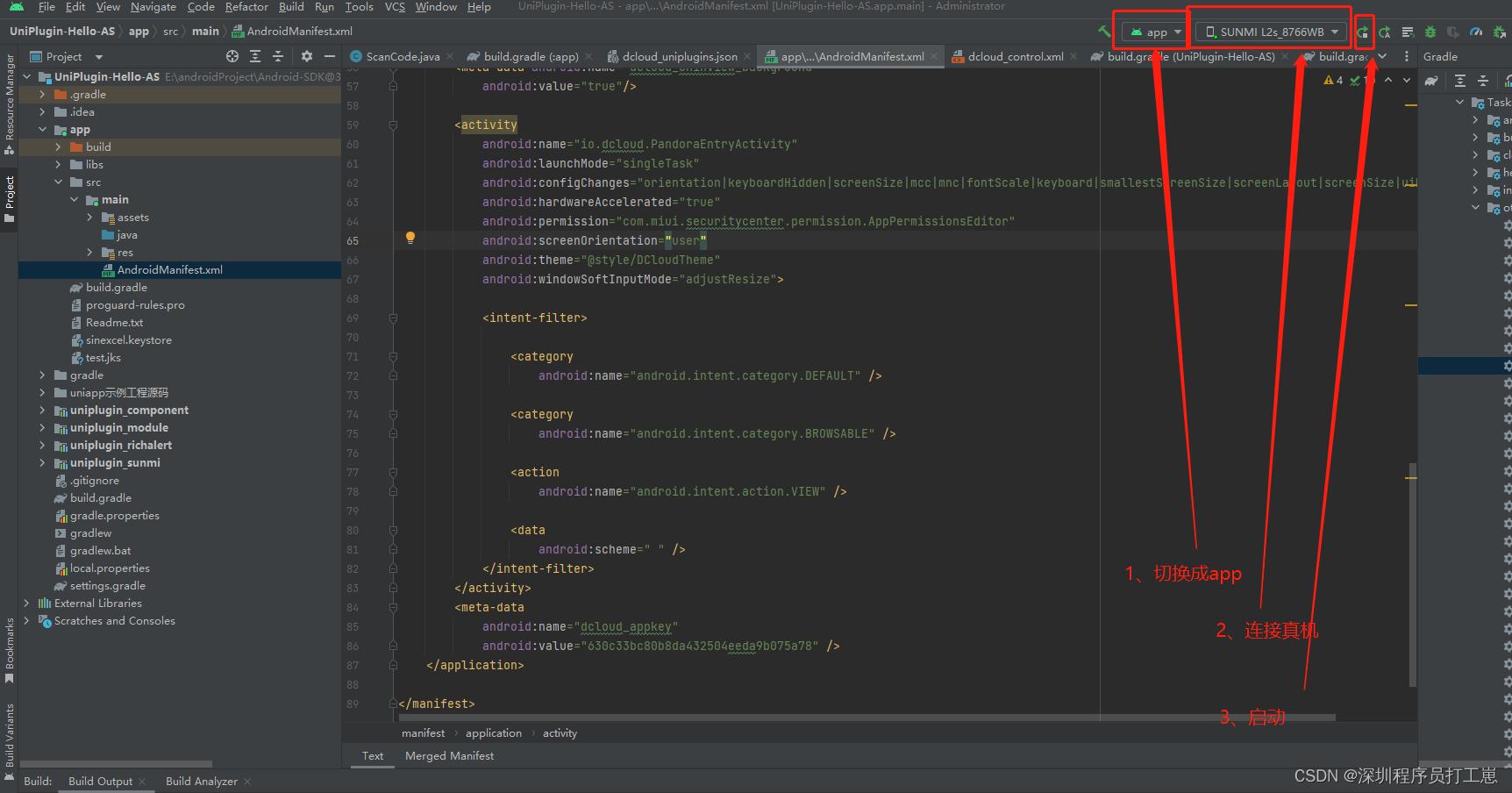
uniapp 原生安卓开发插件(module),以及android环境本地调试(二)
uniapp 原生安卓开发插件(module),以及android环境本地调试(一) 1、前景 承接上一篇文章,由于uniapp每天只有限定的打包次数,所以每次插件调试都打包成为基座,这个不太方便&#x…...
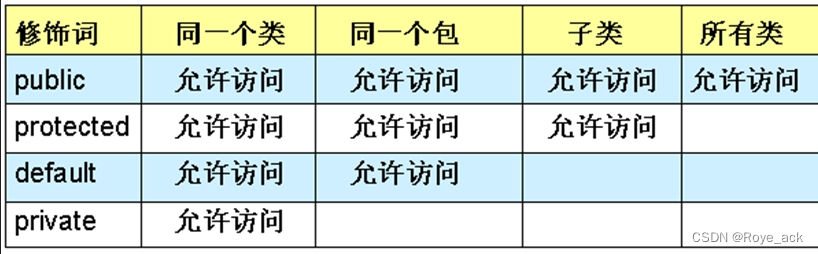
【Java期末复习】《面向对象程序设计》练习库
目录 一、单选题 二、填空题 三、程序填空题 1、 super使用--有如下父类和子类的定义,根据要求填写代码 2、简单加法计算器的实现 3、House类 4、矩形类 5、创建一个Box类,求其体积 四、函数题 6-1 求圆面积自定义异常类 6-2 判断一个数列是…...

照片文件损坏能修复吗?
很多时候,我们都是把相机拍的照片保存在电脑上,或手机照片太多,也会上传到电脑里保存。这样就能腾出更多的存储空间。但在电脑里的照片文件有时会莫名其妙的损坏,提示已损坏等情况,一旦发生这样的事,这些照…...
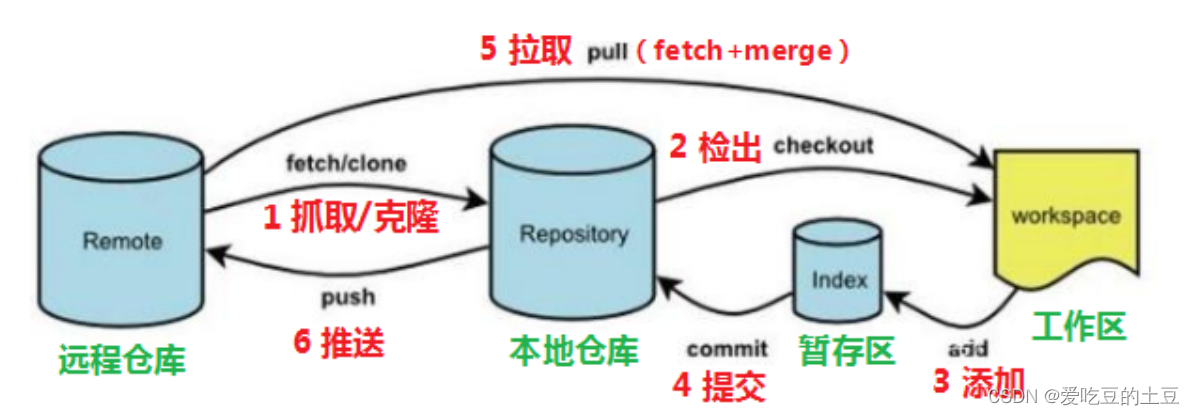
Git分布式版本控制工具
1:目标了解Git基本概念 能够概述git工作流程 能够使用Git常用命令 熟悉Git代码托管服务 能够使用idea操作git 2:概述2.1:开发中的实际场景场景一:备份 小明负责的模块就要完成了,就在即将Release之前的一瞬间ÿ…...

Python爬虫(8)selenium爬虫后数据,存入sqlit3实现增删改查
之前的文章有关于更多操作方式详细解答,本篇基于前面的知识点进行操作,如果不了解可以先看之前的文章 Python爬虫(8)selenium爬虫后数据,存入sqlit3实现增删改查导入默认包和环境元素定位创建一个sqlit3表将爬虫到的信…...

最全Linux驱动开发全流程详细解析(持续更新)
Linux驱动开发详细解析 一、驱动概念 驱动与底层硬件直接打交道,充当了硬件与应用软件中间的桥梁。 具体任务 读写设备寄存器(实现控制的方式)完成设备的轮询、中断处理、DMA通信(CPU与外设通信的方式)进行物理内存…...

华为OD机试 - 乱序整数序列两数之和绝对值最小 | 机试题算法思路 【2023】
最近更新的博客 华为OD机试 - 简易压缩算法(Python) | 机试题算法思路 【2023】 华为OD机试题 - 获取最大软件版本号(JavaScript) 华为OD机试 - 猜字谜(Python) | 机试题+算法思路 【2023】 华为OD机试 - 删除指定目录(Python) | 机试题算法思路 【2023】 华为OD机试 …...

网上插画教学哪家质量好,汇总5大插画培训班
网上插画教学哪家质量好?给大家梳理了国内5家专业的插画师培训班,最新五大插画班排行榜,各有优势和特色! 一:国内知名插画培训机构排名 1、轻微课(五颗星) 主打课程有日系插画、游戏原画、古风插…...

对云原生集群网络流量可观测性的一点思考
问题背景 在云原生技术的广泛普及和实施过程中,笔者接触到的很多用户需求里都涉及到对云原生集群的可观测性要求。 实现集群的可观测性,是进行集群安全防护的前提条件 。而在可观测性的需求中,集群中容器和容器之间网络流量的可观测性需求是…...
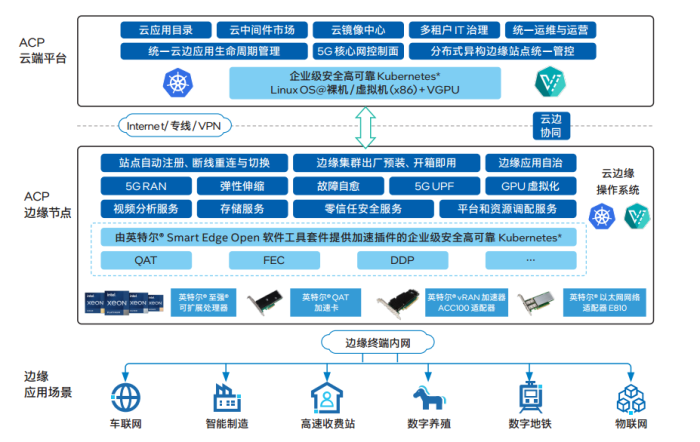
借力英特尔® Smart Edge,灵雀云 ACP 5G 专网解决方案获得多维度优化加速
近日,灵雀云联合英特尔推出了集成Smart Edge 模块的灵雀云 ACP 5G 专网解决方案,同时共同发布了《借力英特尔 Smart Edge,基于云原生解决方案的灵雀云 ACP 5G 专网版本获得多维度优化加速》白皮书。 得益于云计算技术和 5G 网络的高速发展&am…...

【Pytorch项目实战】基于PaddlenHub的口罩检测与语音提示
文章目录一、项目思路二、环境配置1.1、PaddlenHub模块(飞桨预训练模型应用工具)(1)预训练模型:pyramidbox_lite_mobile_mask(2)face_detection人脸检测模型(默认为 pyramidbox_lite…...

基于 PLC 的自动门控制系统设计与仿真程序探索
基于plc的自动门控制系统设计 仿真程序资料在自动化控制领域,基于 PLC(可编程逻辑控制器)的自动门控制系统应用广泛。今天咱就唠唠这基于 PLC 的自动门控制系统设计以及相关的仿真程序资料。 自动门控制系统设计需求 自动门要实现多种功能&a…...

嵌入式ONPS协议栈:轻量级TCP/IP实现与优化
1. ONPS协议栈概述ONPS是一款专为资源受限的嵌入式系统设计的开源网络协议栈,由国内开发者完全自主开发实现。作为一名长期从事嵌入式网络开发的工程师,我第一次接触ONPS时就对其轻量级设计和完整的功能实现印象深刻。与常见的LwIP等协议栈相比ÿ…...

UNIX设计哲学:一切皆文件的原理与应用
1. UNIX 设计哲学的核心:"一切皆文件"在计算机操作系统的演进历程中,UNIX系统以其简洁而强大的设计哲学独树一帜。作为一名长期与UNIX/Linux系统打交道的开发者,我深刻体会到"一切皆文件"这一理念对整个计算机领域产生的…...

STM32智能灌溉系统设计与实现
1. 项目概述这个智能灌溉控制系统是我去年为一个农业科技公司做的实际项目,当时他们需要在200亩的蓝莓种植基地部署一套自动化灌溉方案。经过三个月的开发和实地测试,最终形成了这套基于STM32的稳定系统。现在把整个设计过程整理出来,希望能给…...

FC-CLIP实战:为什么说“卷积不死”?在开放词汇分割中冻结CLIP主干的深度解析与避坑指南
FC-CLIP技术解析:卷积架构在开放词汇分割中的不可替代性 当整个计算机视觉领域似乎都被Transformer架构席卷时,FC-CLIP论文却掷地有声地宣告"卷积不死"。这个看似反潮流的结论背后,隐藏着哪些被忽视的视觉归纳偏置?冻结…...

【已解决】conda环境报错:Error while loading conda entry point: conda-libmamba-solver
打算配环境装 Signac,跑基因活性矩阵来着,图省事让 Gemini 给我生成 conda 配环境的命令。它建议我用 mamba,我想也没想,直接复制它的命令在终端开始安装。 结果装好后,base 环境也出问题了,所有环境都出问…...

数字化转型深水区:技术从“支撑”到“驱动”的蜕变
对于身处一线的软件测试从业者而言,“数字化转型”早已不是一个陌生的词汇。我们经历了从手工测试到自动化测试的转变,见证了敏捷与DevOps带来的流程革新。然而,当转型浪潮进入“深水区”,一种更为根本的变革正在发生:…...

TX12 + ExpressLRS 915MHz RC链路优化与EdgeTX固件升级实战
1. 为什么选择TX12搭配ExpressLRS 915MHz系统 玩无人机的朋友都知道,遥控链路就像风筝线,距离和稳定性直接决定飞行体验。我之前用2.4GHz的RadioLink套装,飞到500米就开始心跳加速——信号时断时续,每次返航都像在赌运气。换成TX1…...

GHelper:华硕笔记本性能优化的轻量解决方案 - 告别Armoury Crate臃肿体验
GHelper:华硕笔记本性能优化的轻量解决方案 - 告别Armoury Crate臃肿体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Fl…...

Hermes性能优化:如何提高邮件生成速度和降低资源消耗
Hermes性能优化:如何提高邮件生成速度和降低资源消耗 【免费下载链接】hermes Golang package that generates clean, responsive HTML e-mails for sending transactional mail 项目地址: https://gitcode.com/gh_mirrors/he/hermes Hermes是一个Golang包&a…...