Flux语言 -- InfluxDB笔记二
1. 基础概念理解
1.1 语序和MySQL不一样,像净水一样通过管道一层层过滤

1.2 不同版本FluxDB的语法也不太一样
2. 基本表达式
import "array"
s = 10 * 3
// 浮点型只能与浮点型进行运算
s1 = 9.0 / 3.0
s2 = 10.0 % 3.0 // 等于 1
s3 = 10.0 ^ 3.0 // 等于 1000
s4 = "abc" + string(v: 4)
// 输出
array.from(rows:[{"value" : s}])3. 谓词表达式 (xx 且 xx)
import "array"
s = "abc" == "abc" // 相等。返回true
s9 = "abc" != "abc" // 不等。返回false
s8 = 1 == 1 and 1==2 // 且。返回false
s7 = 1 == 1 or 1==2 // 或。返回true// 判断字符串是不是 匹配 以a开头的正则表达式,返回true
s6 = "abc" =~ /^a/
// 判断字符串是不是 不匹配 以a开头的正则表达式,返回false
s5 = "abc" !~ /^a/a = not s5 // 取反,返回trues1 = "abc" < "bbc" // 返回true
s2 = "啊" < "吧" // UTF8码值,返回false
s3 = 1 < 2.0 // 返回true,整型和浮点型不可以跨类型计算,但是可以跨类型比较
s3 = "1" < 2.0 // 报错 unsupported binary expression string > float
s4 = 0.1 + 0.2 == 0.3 // false ,因为浮点,应该是 0.1 + 0.2 > 0.3
array.from(rows:[{"value" : s}]) // 返回true4. 控制语句
三元运算符 (这是唯一用到if-else判断的地方,Flux本质上还是查询语句,同sql)
import "array"
x = 0
a = if x = 0 then "green" else "red" // 返回green
a = if x = 0 then "green" else if x == 1 then "red" else "yellow" // x为1时,返回red
array.from(rows:[{"value" : s}]) 5.十大数据类型
5.1 Boolean (true、false是关键字)
a = 1
b = bool(v: a) // a=1,输出true;a=0,输出false
// 可转换的类型:浮点 1.0、字符串"true"/"false"
5.2 bytes (Flux支持bytes,InfluxDB不支持bytes)
b = "abc"
x = bytes(v: b) // cannot represent the type bytes as column data
// bytes的作用:序列化
c = string(v: x) // 输出abc
d = display(v: x) // 输出0x616263; webUI的bug导致dispaly报错,可忽略
import "contrib/bonitoo-io/hex" // 工具中可能不会提醒,需要查官方文档
import "array"
b = "616263"
c = hex.bytes(v: b)
x = string(v: c)
array.from(rows: [{"value": x}]) // 输出abc
bytes的一个用法
import "http"
http.post(url: "http://localhost:8086/", headers: {x:"a", y:"b"}, data: bytes(v: "body"))
5.3 Time 时间点
a = 2023-08-23T15:06:00.001Z // time 类型:DATETIME: RFC3339格式的日期时间
5.4 Duration 持续时间
import "date"
a = 2023-08-23T05:06:00.001Z
b = 1d10h
c = data.add(d:b, to:a) // 输出a = 2023-08-24T15:06:00.001Z
f = -1d3h
e = data.add(d:f, to:a) // 输出a = 2023-08-22T04:06:00.001Z
array.from(rows: [{value: f}])// 报错,cannot represent the type duration as column data
// 字符串转duration
g = "1h5m"
h = duration(v:g)
语法

hour
import "data"
b = date.hour(t:now()) // 输出long型的数字
时间戳
a = 2023-08-23T05:06:00.001Z
b = time(v:1692844684000*1000*1000) // 纳秒级
c = unit(v:a) // 输出1692738360001000000
5.5 String 字符串
import "strings"
a = "abc"
a1 = "\x61\x62\x63" // 输出abc
// 字符串转换
b = string(v: 1) // 支持Integer | UInteger | Float | Boolean | Duration | Time
c = string.containsStr(v: "今天天气真好", substr: "天气") // true,字符串是否包含某个字符
d = strings.joinStr(arr:["今天", "天气", "真好"], v:"-") // 输出今天-天气-真好
e = strings.isLetter(v:"c") // 输出 true;false : < 、哈 ...
array.from(rows: [{"value": a}])
5.6 Regular expression 正则表达式
a = "albcdef"
b = /abc|bcd|def/
c = a =~ b // 输出true,b:匹配abc或bcd或def
d = regexp.findString(r: b, v: a); // 输出bcd;最左边能匹配上的条件
e = "abc|bcd|def"
f = regexp.compare(v: a) // 正则表达式的转换
array.from(rows: [{v: c}])
array.from(rows: [{v: display(v: c)}]) // 输出abc|bcd|def
array.from(rows: [{v: a =~ f}])
5.7 Integer 整型
取值范围:2^63 ~ 2^63 - 1
bug1: 2^63-1运算会提示浮点型转换错误,2^63-1.0也会报错;
bug2: 值过大时,页面显示有bug,与实际值不一致,可以通过下载csv查看实际值;
可转换的类型有:Boolean | Duration | Float | Numeric String | Time | Uinteger
小数转换时是截断型转换,不会四舍五入,可通过math.round(x: 12.5)转换,此时返回值为Double,故完整写法:int(v:math.round(x: 12.5))
hex.int(v: 'a') // 输出10,十六进制
hex.int(v: 'a0') // 输出160
5.8 Uintegers 无符号整型
取值范围:0 ~ 2^64
可转换的类型有:Boolean | Duration | Float | Integer | Numeric String | Time
unit(v: 123)// 输出123,UNSIGNEDLONG类型
5.9 Float 浮点数
8个子节
不支持科学计数法e,可以写为float(v: "1.2345e+")
正无穷大 float(v: "Inf")
不支持NaN,写成float(v: "NaN")
5.10 Null 空值
flux不支持null
import "internal/debug"
a = debug.null(type:"int") // 输出为空,类型为long
b = a == debug.null(type:"int") // cannot represent the type null as column data;此时的b不是true/false,而是null,类型也为null,与类型为LONG的a的null不一样
c = exists a // 输出false,判断a是否存在
6. 4种复合类型
6.1 record
b = {"name" : "tony", age: 18, "x y": "20,40"}
arrays.from(rows:[{display(v: b)}]) // 输出String类型的b
arrays.from(rows:[b]) // 输出多列数据,如下图
a = b.name //输出 tony
c = b["age"] // 输出18
// 不支持动态变量
key_name = "age"
d = b[key_name] // expected int but found string error@**: expected [d](array) but found {x y: string, name: string, age: int}(record)
e = {"name" : "tony", age: 18, "x y": "20,40"}
f = b==e // 输出true,比较是否完全一致,不能比较大小
g = {b with age:19,"height":200}// 输出结果更新了age的值,同时多了一列height,未提到的列沿用之前的b,如下图2


b = {
name: "tony",
address: {
country: "China"
}
}
// cannot represent the type {address:{coutry: string}} as column data
// 语法支持这样写,但是FluxDB不支持,record不支持嵌套record,相当于列里无法存储json
c = b.address.country // 输出China
d = b["address"]["country"] // 输出China
// b整体存库里
e = json.encode(v: b) // cannot represent the type bytes as column data
g = string(v: e) // 这样才能作为string数据存储成功
6.2 Dictionary 字典
字典和记录很像,但是key-value的要求不一样
所有key的类型必须相同,所有value的类型必须相同;
语法上,用方括号[]声明,key后面跟冒号:键值对之间用英文逗号分隔
[1.0: {stable: 12, latest: 12}, 1.1: {stable: 3, latest: 15}]
该数据类型不支持直接作为fluxdb的列
a = ["name": "tony", "age": "18"]
// 不支持直接通过.或[key]取值
// 查询(取值时,key可以是动态参数)
key_name = "key"
b = dict.get(dict:a, key: key_name , default: "244")// 如果key不存在,返回默认值244
// 值的插入与更新需要通过dict
c = dict.insert(dict: a, key: "age", "value": "20" )// 更新值,这里前端的文档入参有bug,错把value提示为default
d = dict.insert(dict: a, key: "weight", "value": "50" )// 插入值
// 删除
e = dict.remove(dict: a, key: "age")
// fromList
f = dict.fromList(pairs: [{key: "name",value: "tony"}, {key: "age",value: "18"}])// 输出 [name: tony, age: 18]
array.from(rows: [{"value": display(v: d)}])
6.3 Array 数组
a = ["1", "2", "3"] // 类型要一致
b = length(arr: a) // 长度
c = contains(value: 1, set: a) // true,包含判断
7. 4种复合函数
// 一个可以进行乘法运算的函数
chengfa = (x, y) => x * y
a = chengfa(x: 4, y: 5) // 输出20
// 定义默认值
chengfa1 = (x, y=10) => x * y
a1 = chengfa1(x: 4) // 输出40
// 函数体
chengfa2 = (x, y=10) => {
z = x - 2;
return z * y
}
a2 = chengfa2(x: 4) // 输出20
FLUX语言里,函数也是类型
getChengFa = () => {
chengfa = (x, y) => x * y
return chengfa
}
x = getChengFa()(x: 10, y: 5)
相关文章:
Flux语言 -- InfluxDB笔记二
1. 基础概念理解 1.1 语序和MySQL不一样,像净水一样通过管道一层层过滤 1.2 不同版本FluxDB的语法也不太一样 2. 基本表达式 import "array" s 10 * 3 // 浮点型只能与浮点型进行运算 s1 9.0 / 3.0 s2 10.0 % 3.0 // 等于 1 s3 10.0 ^ 3.0 // 等于…...

18.Oauth2-微服务认证
1.Oauth2 OAuth 2.0授权框架支持第三方支持访问有限的HTTP服务,通过在资源所有者和HTTP服务之间进行一个批准交互来代表资源者去访问这些资源,或者通过允许第三方应用程序以自己的名义获取访问权限。 为了方便理解,可以想象OAuth2.0就是在用…...

vue和node使用websocket实现数据推送,实时聊天
需求:node做后端根据websocket,连接数据库,数据库的字段改变后,前端不用刷新页面也能更新到数据,前端也可以发送消息给后端,后端接受后把前端消息做处理再推送给前端展示 1.初始化node,生成pac…...
汽车电子笔记之:基于AUTOSAR的多核监控机制
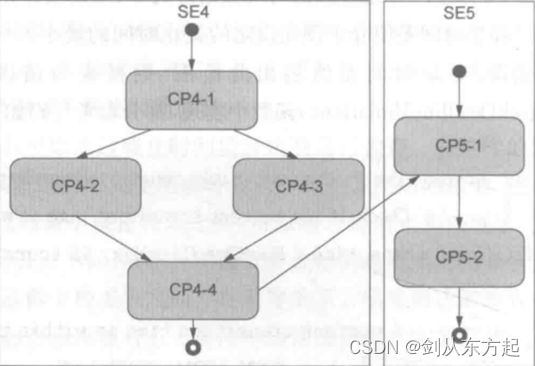
目录 1、概述 2、系统监控的目标 2.1、任务的状态机 2.2、任务服务函数 2.3、任务周期性事件 2.4、时间监控的指标 2.5、时间监控的原理 2.6、CPU负载率监控原理 2.6.1、设计思路 2.6.2、监控方法的评价 3、基于WDGM模块热舞时序监控方法 3.1、活跃监督 3.2、截至时…...
GDB 源码分析 -- 断点源码解析
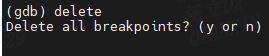
文章目录 一、断点简介1.1 硬件断点1.2 软件断点 二、断点源码分析2.1 断点相关结构体2.1.1 struct breakpoint2.1.2 struct bp_location 2.2 断点源码简介2.3 break设置断点2.4 enable break2.5 disable breakpoint2.6 delete breakpoint2.7 info break 命令源码解析 三、Linu…...
SpringMVC概述与简单使用
1.SpringMVC简介 SpringMVC也叫做Spring web mvc,是 Spring 框架的一部分,是在 Spring3.0 后发布的。 2.SpringMVC优点 1.基于 MVC 架构 基于 MVC 架构,功能分工明确。解耦合, 2.容易理解,上手快;使用简单。 就可以…...

传输层—UDP原理详解
目录 前言 1.netstat 2.pidof 3.UDP协议格式 4.UDP的特点 5.面向数据报 6.UDP的缓冲区 7.UDP使用注意事项 8.基于UDP的应用层协议 总结 前言 在之前的文章中为大家介绍了关于网络协议栈第一层就是应用层,包含套接字的使用,在应用层编码实现服务…...
CK-GW06-E03与汇川PLC的EtherNet/IP通信
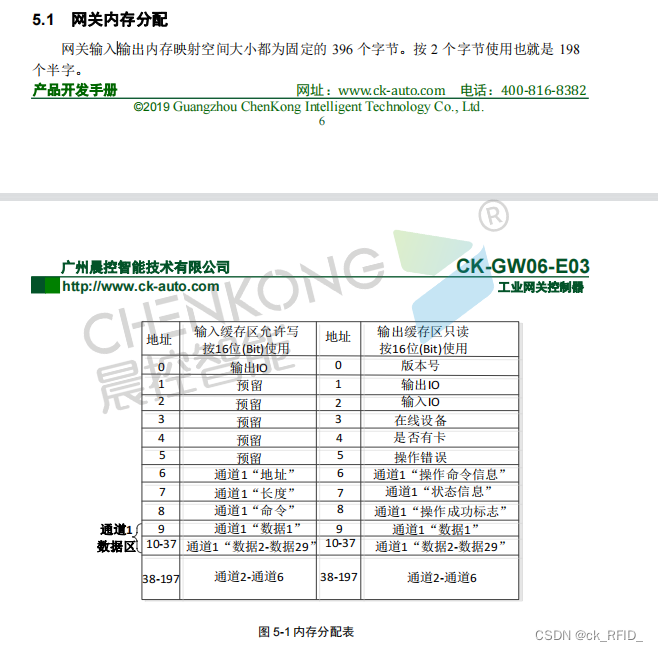
准备阶段: CK-GWO6-E03网关POE交换机网线汇川PLC编程软件汇川AC801-0221-U0R0型号PLC 1.打开汇川PLC编程软件lnoProShop(V1.6.2)SP2 新建工程,选择对应的PLC型号,编程语言选择为“结构化文本(ST)语言”,然…...

UI界面自动化BagePage
常用basepage模块代码 # -*- coding: utf-8 -*- # Desc: UI自动化测试的一些基础浏览器操作方法# 第三方库导入 import time from logging import config import randomimport allure from selenium.webdriver.common.alert import Alert from selenium.webdriver.remote.webe…...
北京开发APP的费用明细
开发APP项目时,在功能确定后需要知道有哪些可能的费用,安排项目预算。北京开发APP的费用明细可能会包括以下几个部分,每个部分都会产生一些费用。今天和大家分享APP费用明细有哪些,希望对大家有所帮助。北京木奇移动技术有限公司&…...

2023年MySQL核心技术第一篇
目录 一 . 存储:一个完整的数据存储过程是怎样的? 1.1 数据存储过程 1.1.1 创建MySQl 数据库 1.1.1.1 为什么我们要先创建一个数据库,而不是直接创建数据表? 1.1.1.2基本操作部分 1.2 选择索引问题 二 . 字段:这么多的…...
IOPCHDA_Playback)
通讯协议056——全网独有的OPC HDA知识一之接口(十一)IOPCHDA_Playback
本文简单介绍OPC HDA规范的IOPCHDA_Playback(可选)接口方法,更多通信资源请登录网信智汇(wangxinzhihui.com)。 此接口支持历史服务器的播放功能。这提供了从历史服务器获得初始数据集的能力,然后获得历史数据的持续更新。这与异…...
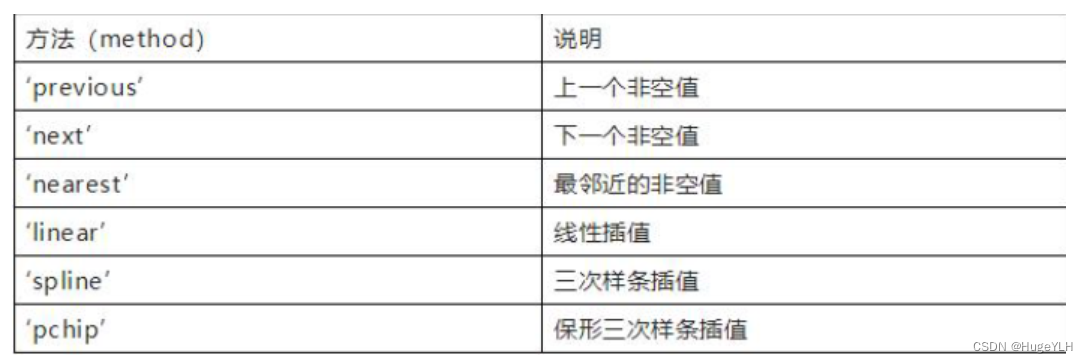
数学建模:数据的预处理
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 文章目录 数据预处理数据变换数据清洗缺失值处理异常值处理 数据预处理 数据变换 常见的数据变换的方式:通过某些简单的函数进行数据变换。 x ′ x 2 x ′ x x ′ log ( x ) ∇ f ( x k )…...
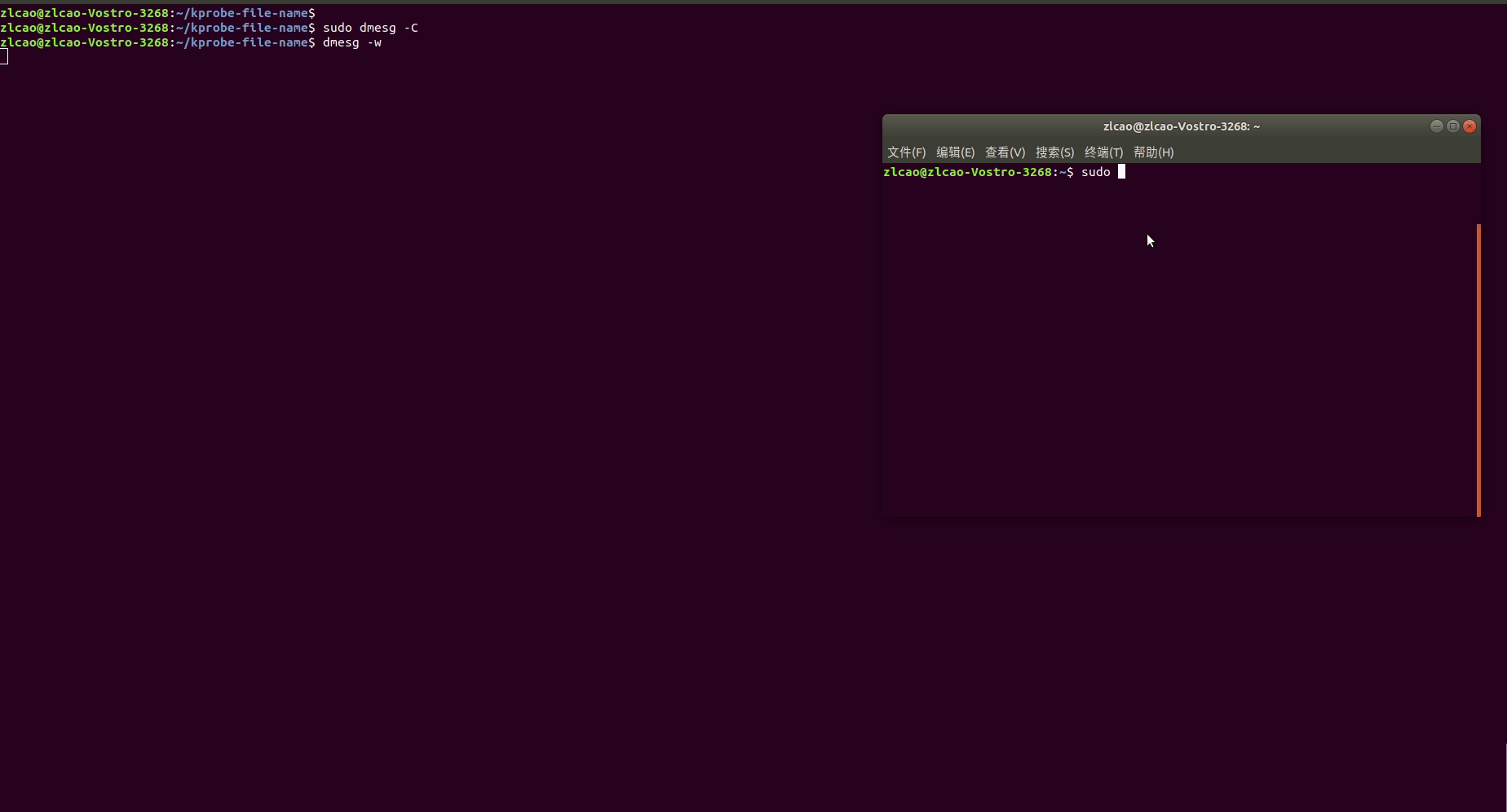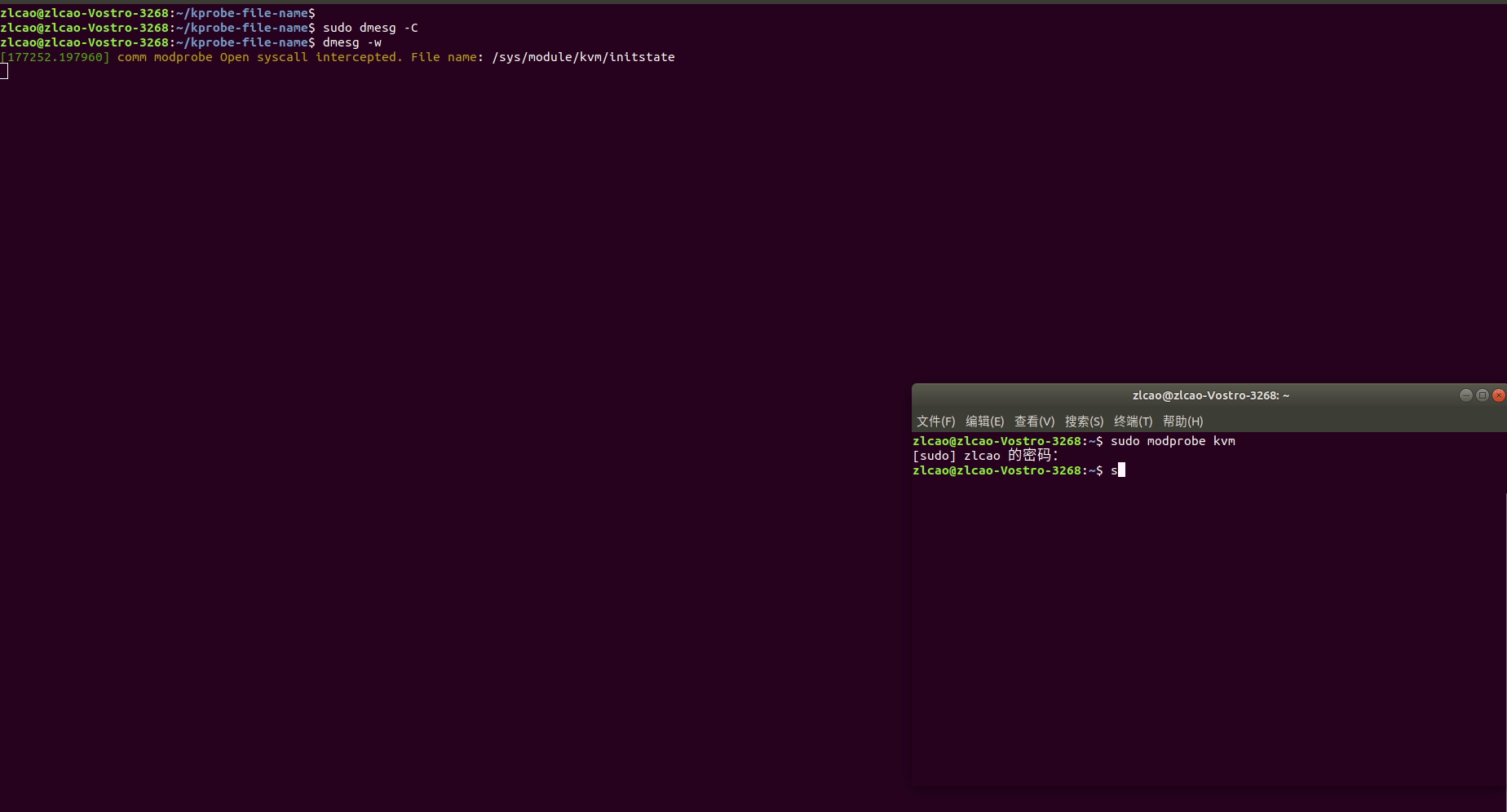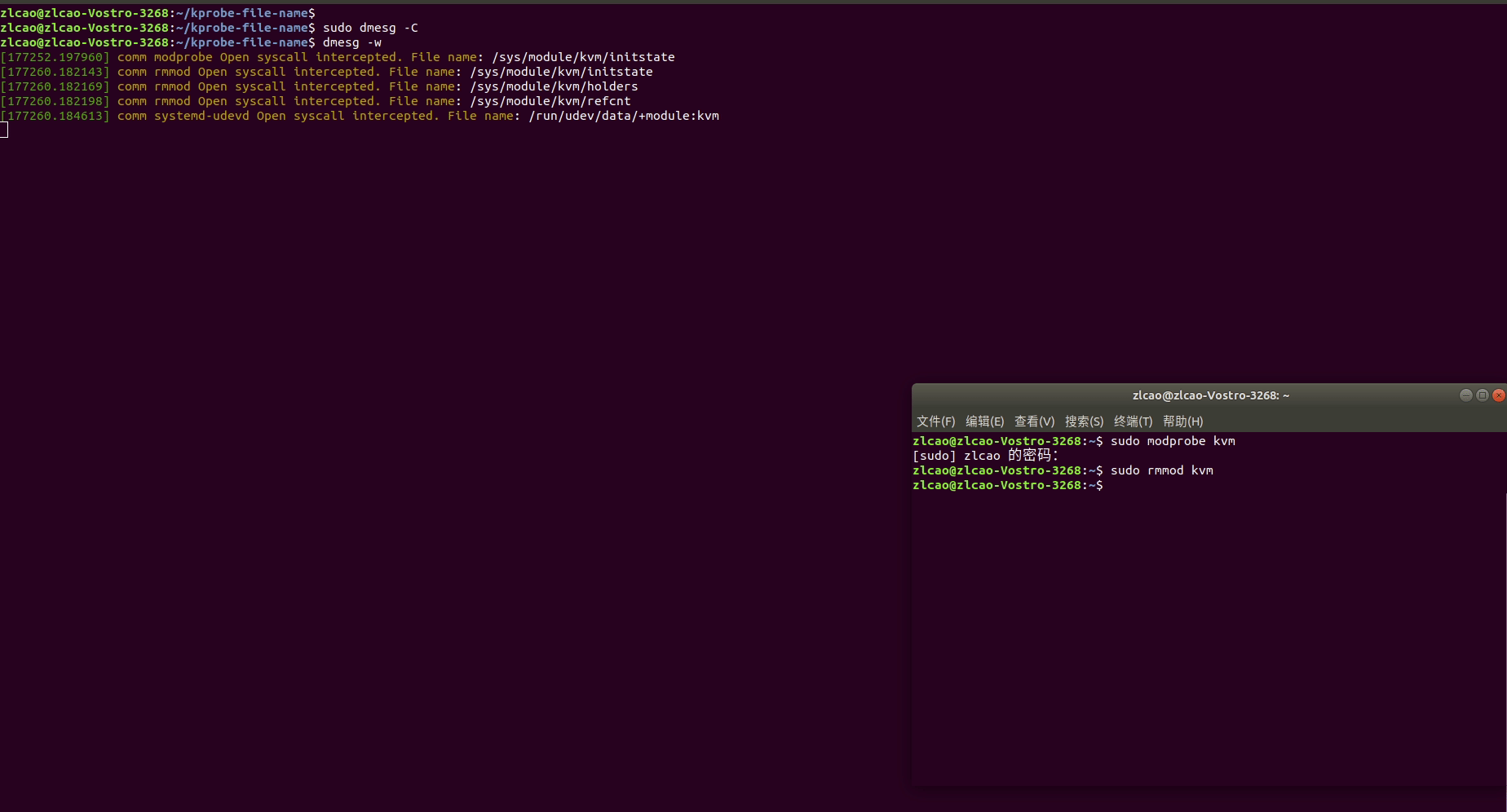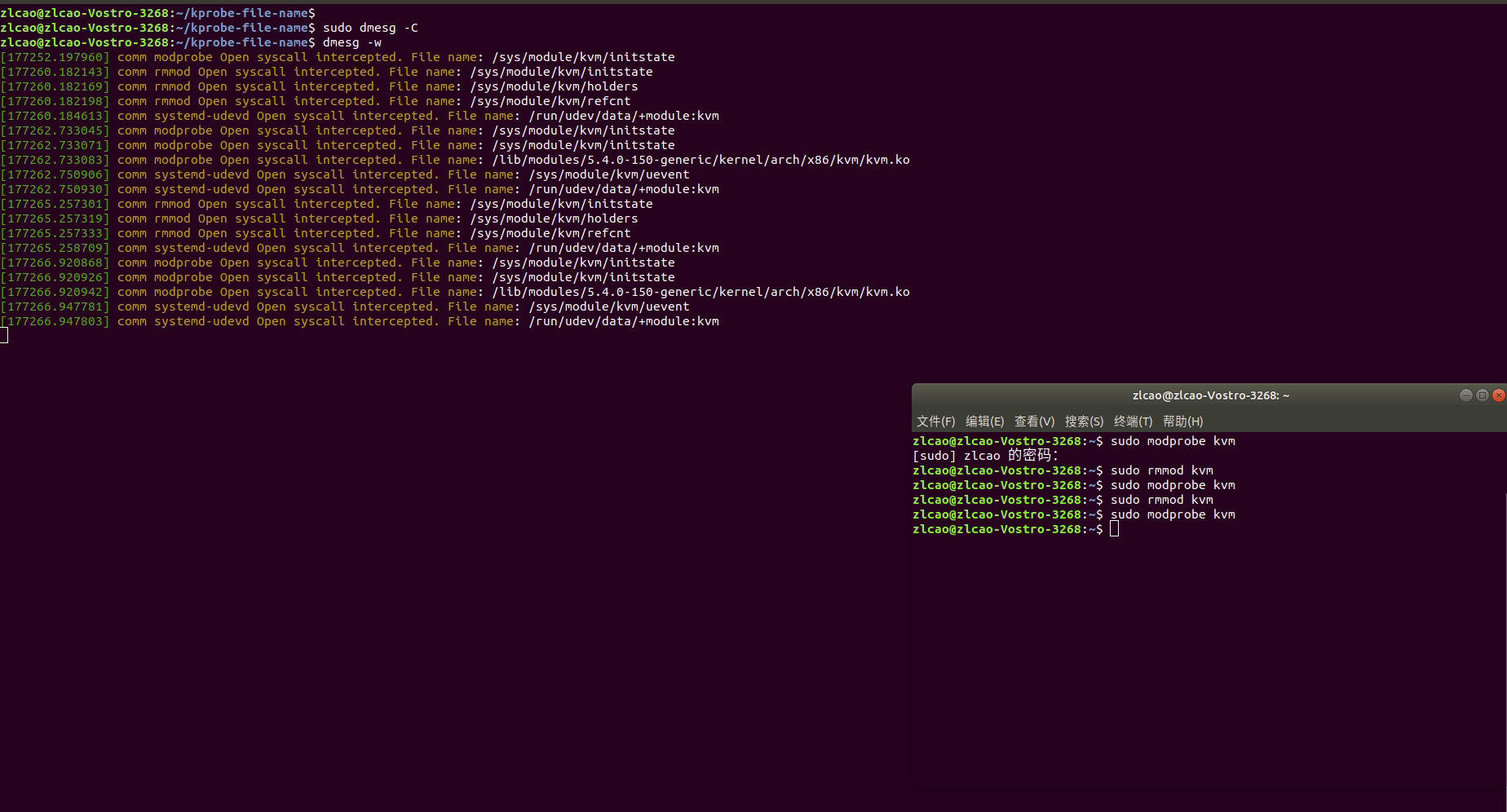
Linux土遁术之监测监测进程打开文件
分析问题过程中,追踪进程打开的文件可以在许多不同情况下有用,体现在以下几个方面: 故障排除和调试: 当程序出现问题、崩溃或异常行为时,追踪进程打开的文件可以帮助您找出问题的根本原因。这有助于快速定位错误&…...
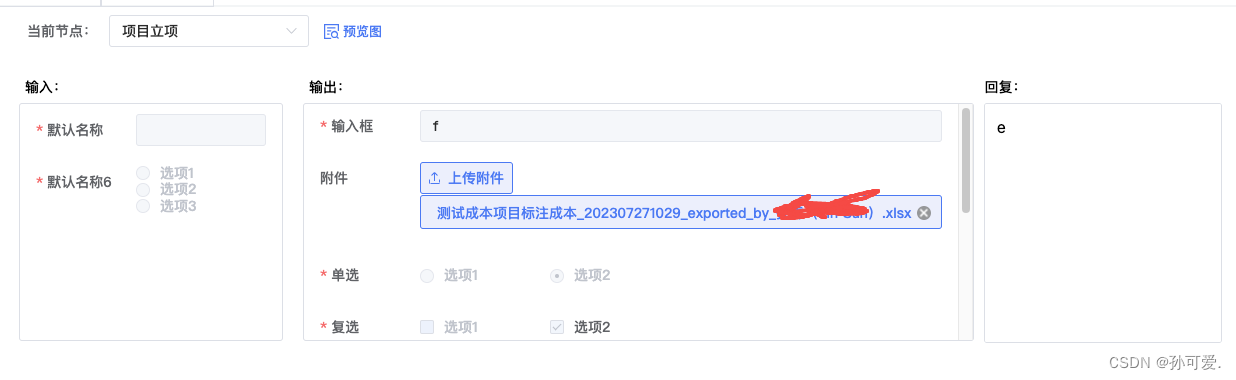
css让多个盒子强制自动等宽
1.width: calc( 100 / n% ) 2.display:flex; flex:1;width:100px; 3.display:grid;grid-template-columns: repeat(auto-fit, minmax(100px, 1fr)); 但是其中某一个内容较长的时候 会破坏1:1:1的平衡 这个时候发现附件名字过长导致不等比例,通过查看阮一峰flex文…...

【高危】Apache Airflow Spark Provider 反序列化漏洞 (CVE-2023-40195)
zhi.oscs1024.com 漏洞类型反序列化发现时间2023-08-29漏洞等级高危MPS编号MPS-qkdx-17bcCVE编号CVE-2023-40195漏洞影响广度广 漏洞危害 OSCS 描述Apache Airflow Spark Provider是Apache Airflow项目的一个插件,用于在Airflow中管理和调度Apache Spar…...
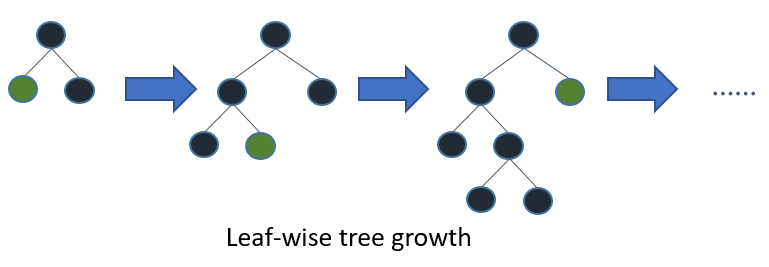
树模型与集成学习:LightGBM
目录 树模型与集成学习 LightGBM 的贡献 LightGBM 的贡献:单边梯度抽样算法 LightGBM 的贡献:直方图算法 LightGBM 的贡献:互斥特征捆绑算法 LightGBM 的贡献:深度限制的 Leaf-wise 算法 树模型与集成学习 树模型是非常好的…...

PHP多语言代入电商平台api接口采集拼多多根据ID获取商品详情原数据示例
拼多多商品详情原数据API接口的作用是获取拼多多电商平台上某一商品的详细信息,包括商品的标题、价格、库存、图片、描述、包邮信息、销量、评价、优惠券等数据。通过该API接口可以获取到商品的原始数据,用于分析、筛选和展示商品信息。 pinduoduo.item…...
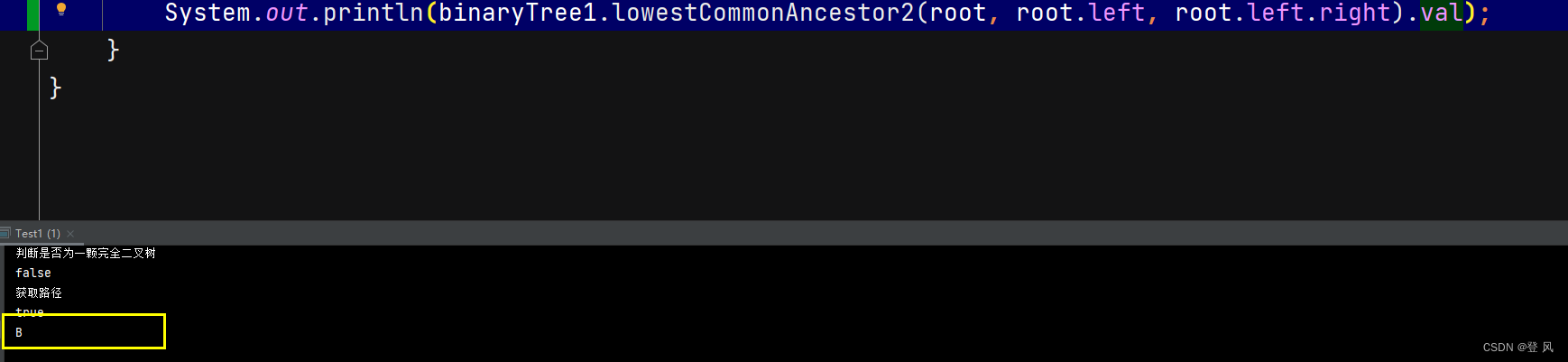
数据结构(Java实现)-二叉树(下)
获取二叉树的高度 检测值为value的元素是否存在(前序遍历) 层序遍历 判断一棵树是不是完全二叉树 获取节点的路径 二叉树的最近公共祖先...

如何利用 SmartX 存储性能测试工具 OWL 优化性能管理?
作者:深耕行业的 SmartX 金融团队 张瑞松 运维人员在日常管理集群时,有时难免会产生这样的困惑: 新业务准备上线,在具备多套存储的情况下,应如何选择承载业务的存储环境? 业务虚拟机刚上线时运行速度很快…...

GIS技巧100例23-ArcGIS像元统计实战:从月度栅格到年度气候指标
1. 像元统计基础与气候数据特点 刚接触GIS处理气候数据时,我经常被各种栅格格式和统计方法搞得晕头转向。直到有次用ArcGIS的像元统计工具批量处理了5年的月降水数据,才发现这个功能简直是隐藏的效率神器。像元统计(Cell Statisticsÿ…...

告别显示器!用VNC Viewer远程玩转树莓派4B的完整配置指南
无显示器玩转树莓派4B:VNC远程配置全攻略 当你刚拿到树莓派4B时,第一反应可能是找显示器、键盘鼠标来配置它。但现实情况往往是:手边没有多余的显示设备,或者你希望将树莓派作为服务器长期运行,根本不需要连接显示器。…...

Vue3 表单深度解析
Vue3 表单深度解析 引言 随着前端技术的发展,Vue.js 已经成为最受欢迎的前端框架之一。Vue3 作为 Vue.js 的最新版本,带来了许多改进和新特性。其中,表单处理是 Vue3 中一个非常重要的部分。本文将深入解析 Vue3 表单的用法、特点以及最佳实践。 Vue3 表单概述 在 Vue3 …...

深度拆解Pulse算法三大剪枝策略:如何让你的路径搜索快10倍?
深度拆解Pulse算法三大剪枝策略:如何让你的路径搜索快10倍? 在解决复杂的组合优化问题时,如车辆路径规划(VRP)或旅行商问题(TSP),算法的效率往往决定了实际应用的可行性。Pulse算法作…...

EC35编码器驱动踩坑实录:从波形分析到稳定读取,我的GD32调试笔记
EC35编码器驱动踩坑实录:从波形分析到稳定读取的GD32调试笔记 1. 问题初现:那些让人抓狂的"玄学"现象 第一次把EC35编码器接到GD32F303开发板上时,我天真地以为这不过是个简单的GPIO中断应用。按照常规思路配置了三个引脚的中断&am…...

京东智能评价自动化解决方案:基于NLP的批量评价系统
京东智能评价自动化解决方案:基于NLP的批量评价系统 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 京东购物后的评价工作繁琐且耗时,传统手动评价方式效率低下且内容质…...
)
【2026最新版Linux安装Mysql】CentOS 7 安装 MySQL 8.4.9 完整流程(RPM 手动安装+避坑+面试)
前言:本文记录在 CentOS 7 / RHEL 7 上,通过官网 RPM Bundle tar 包手动安装 MySQL 8.4.9(LTS) 的完整可复现流程。适合需要在老版本 CentOS 上部署 MySQL、为 Python/AI 后端或 Java 项目准备数据库环境的读者。读完可按步骤完成…...
)
别再让烙铁头‘烧死’了!手把手教你电烙铁日常保养与复活术(附温度设置建议)
电烙铁头养护全攻略:从氧化原理到实战修复技巧 1. 烙铁头氧化背后的科学原理 烙铁头氧化并非单纯由高温引起,而是高温与氧气共同作用的结果。当烙铁头暴露在空气中时,高温会加速金属表面与氧气的化学反应,形成一层致密的氧化层。这…...

3步掌握Open-Lyrics:如何让AI为你的音频自动生成专业字幕
3步掌握Open-Lyrics:如何让AI为你的音频自动生成专业字幕 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项…...

生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制
生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制 生态数据分析中,Mantel检验作为一种常用的空间相关性分析方法,被广泛应用于物种分布与环境因子关系的研究。然而,许多研究者在实际操作中…...