【MySQL】5、MySQL高阶语句
一、常用查询(增、删、改、查)
对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等
模板表:
数据库有一张info表,记录了学生的id,姓名,分数,地址和爱好
create table info (id int,name varchar(10) primary key not null ,score decimal(5,2),address varchar(20),hobbid int(5));insert into info values(1,'liuyi',80,'beijing',2);
insert into info values(2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'jiaoshou',98,'laowo',3);
insert into info values(6,'hanmeimei',10,'nanjing',3);
insert into info values(7,'lilei',11,'nanjing',5);select * from info;
1.按关键字排序
(1)语法
#按分数排序,默认不指定是升序排列
select * from info order by score;
#分数按降序排列
select * from info order by score desc;ASC|DESC
asc按升序排列,是默认的排序方式;加上desc会按降序排列order by还可以结合where进行条件过滤
例:筛选地址是杭州的学生按分数降序排列
select name,score from info where address='hangzhou' order by score desc;多字段排序
当排序的第一个字段有相同的记录时,这些记录再按照第二个字段进行排序;字段之间使用英文逗号隔开,优先级是按先后顺序而定
select * from 表名 order by 字段1 desc,字段2 desc;
① 查询学生信息先按兴趣降序排列,再按id也降序排列
select id,name,hobbid from info order by hobbid desc,id desc;2.区间判断查询,不重复记录
and/or 且/或
distinct 查询不重复记录
例:
select * from info where score >70 and score <=90;
select * from info where score >70 or score <=90;嵌套/多条件
select * from info where score >70 or (score >75 and score <90);查询不重复记录-distinct
select distinct 字段 from 表名﹔
select distinct hobbid from info;3.对结果进行分组
查询sql结果,对结果进行分组(group by)来实现;
group by通常结合聚合函数一起使用
常用聚合函数:count-计数;sum-求和;avg-平均数;max-最大值;min-最小值按hobbid相同的分组,计算各组的学生个数(基于name个数进行计数)
select count(name),hobbid from info group by hobbid;
4.限制结果条目
limit 限制输出结果记录
SELECT column1, column2, ... FROM table_name LIMIT [offset,] number
LIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。
如果不设定第一个参数,将会从表中的第一条记录开始显示。
第一条记录的位置偏移量是0,第二条是1,以此类推。
第二个参数是设置返回记录行的最大数目。例:
1、limit 2,2 #表示从第三行(偏移量2)开始,显示后2个
select * from info limit 2,2;
2、结合order by语句,按id的大小升序排列显示前三行
select id,name from info order by id limit 3;
3、输出最后三行⭐⭐
select id,name from info order by id desc limit 3;5.设置别名(alias——>as)
给字段列或表设置别名,可以方便书写或者多次使用相同的表。
使用的时候直接使用别名,简洁明了,增强可读性语法:
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;select name as 姓名,score as 成绩,assress as 地址 from ky30;列别名设置示例:
select name as 姓名,score as 成绩 from info;
表别名:
#临时设置ky30的别名为i;as 为默认,可以不写
select i.name as 姓名,i.score as 成绩,i.assress as 地址 from info as i;
#查询info表的字段数量,以number显示
select count(*) as number from info;
使用场景
1、对复杂的表进行查询的时候,别名可以缩短查询语句的长度
2、多表相连查询的时候(通俗易懂、减短sql语句)此外,AS 还可以作为连接语句的操作符。
创建t1表,将info表的查询记录全部插入t1表create table t1 as select * from info;
#此处AS起到的作用:
1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
2、但是“约束”没有被完全“复制”过来 #如果原表设置了主键,那么附表的:default字段会默认设置一个0
相似:
克隆、复制表结构
也可以省略as加上括号
create table t1 (select * from info);
#也可以加入where 语句判断
create table test1 as select * from info where score >=60;#别名不能与数据库中的其他表的名称冲突。
#列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
统计数据量
#显示表中有多少条数据
select count(*) from info;#创建表t1并赋予class表的属性和数据;但是t1没有主键,可以用来备份表
create table t1 as select * from class;
create table t2 (select * from class);
#通过条件判断写入
create table t1 as select * from class where score >= 70;6.通配符
用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通配符通常与 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务
% 表示匹配0到多个字符
_ 下划线表示匹配单个字符查询name列中以c开头的字符
select id,name from info where name like 'c%'查询name列中以c开头、第三个字符为i、并且以o结尾的字符;
name like 'c_i_o'查询name中以u开头,结尾为5的数据
select id,name from info where name like 'u%_5';查询名字中间有g的记录
select id,name from info where name like '%g%';7.子查询
子查询:内查询、嵌套查询
是指一个查询语句中,还嵌套着另一个查询语句子查询(括号里的)优先于主查询
可以在相同表和不同表之间进行查询in 用来关联主表和子表(主查询和子查询)⭐⭐语法:in用来判断某个值是否在给定的 结果集 中,通常结合子查询使用示例:
select name,score from info where id in (select id from info where score >80);
主语句:select name,score from info where id
子语句(集合): select id from info where score >80
PS:子语句中的sql语句是为了,最后过滤出一个结果集,用于主语句的判断条件多表查询
#一次性添加多条数据
insert into class values (),(),();先查括号里的再查括号外的;in用来关联表
select name,score from info where id in (select id from info where score > 80);多表查询
select id,name,score from info where id in (select id from class);
多层嵌套
语法
IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用语法:
<表达式> [NOT] IN <子查询>
当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE。
not 取反;
需要注意的是,子查询只能返回一列数据,如果需求比较复杂,一列解决不了问题,可以使用多层嵌套#查询分数大于80的记录
select name,score from info where id in (select id from info where score>80);
#将t1里的记录全部删除,重新插入info表的记录
insert into t1 select * from info where id in (select id from info);
#将caicai的分数改为50
update info set score=50 where id in (select * from ky30 where id=2);
#删除分数大于80的记录
delete from info where id in (select id where score>80);#not in 表示取反
update t1 set id=2 where id not in (select id from info where id>2);#删除
delete from t1 where id in (select id from info where age < 15);
子查询支持:select、insert、update、deleteexists 判断查询结果是否为空;否、则返回true,是、则返回false
EXISTS
用于判断子查询的结果集是否为空;如果不为空,则返回 TRUE;反之,则返回 FALSE(0)例:
#查询如果存在分数等于80的记录则计算info的字段数
select count(*) from info where exists(select id from info where score=80);
#查询如果存在分数小于50的记录则计算info的字段数;
select count(*) from info where exists(select id from info where score<50);别名as
#查询info表id,name 字段
select id,name from info;例:
需求:从info表中的id和name字段的内容做为"内容" 输出id的部分
mysql> select id from (select id,name from info);
ERROR 1248 (42000): Every derived table must have its own alias
#此时会报错,因为“表名”的位置是一个结果集,mysql无法识别
#将这个结果集设置一个别名后,就能正常查询了
select a.id from (select id,name from info) a;
相当于
select info.id,name from info;MySQL视图
视图:优化操作+安全方案 ⭐⭐
是一个虚拟表,不包含真实数据,只是做了真实数据的映射
视图可以理解为倒影/镜花水月,动态的保存结果集(数据)作用:
简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性
PS:视图适合于多表连接浏览时使用;不适合增、删、改
而存储过程适合于使用较频繁的SQL语句,可以提高执行效率!
作用场景:
针对不同的人(权限),提供不同的结果集创建视图表
#创建视图(单表)
create view 视图名 as select * from 表名 where age >=15;
create view v_score as select * from info where score>=80;#查看表状态
show table status\G#查看视图
select * from v_score;#查看视图与源表结构
desc v_score;
desc info;
多表创建视图
创建test01表
create table test01 (id int,name varchar(10),age char(10));
insert into test01 values(1,'zhangsan',20);
insert into test01 values(2,'lisi',30);
insert into test01 values(3,'wangwu',29);需求:需要创建一个视图,需要输出id、学生姓名、分数以及年龄
create view v_info(id,name,score,age) as select info.id,info.name,info.score,test01.age from info,test01 where info.name=test01.name;
select * from v_info;#修改原表数据
update info set score='60' where name='liuyi';#查看视图
select * from v_score;#同时可以通过视图修改原表
update v_score set score='120' where name='tianqi';select * from v_score;
select * from info;修改表不能修改以函数、复合函数方式计算出来的字段
特点:查询方便、安全性
查询方便:索引速度快、同时可以多表查询更为迅速(视图不保存真实数据,视图本质类似select)
安全性:我们实现登陆的账户是root,拥有权限 ,视图无法显示完整的约束连接查询⭐⭐⭐
MySQL 的连接查询,通常都是将来自两个或多个表的记录行结合起来,基于这些表之间的共同字段,进行数据的拼接。
首先,要确定一个主表作为结果集,然后将其他表的行有选择性的连接到选定的主表结果集上。常用连接查询包括:内连接、左连接和右连接
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录模版:
create table test1 (a_id int(11) default null,a_name varchar(32) default null,a_level int(11) default null);
insert into test1 values (1,'aaaa',10);
insert into test1 values (2,'bbbb',20);
insert into test1 values (3,'cccc',30);
insert into test1 values (4,'dddd',40);create table test2 (b_id int(11) default null,b_name varchar(32) default null,b_level int(11) default null);
insert into test2 values (2,'bbbb',20);
insert into test2 values (3,'cccc',30);
insert into test2 values (5,'eeee',50);
insert into test2 values (6,'ffff',60);1.内连接
MySQL 中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在 FROM 子句中使用关键字 INNER JOIN 来连接多张表,并使用 ON 子句设置连接条件,内连接是系统默认的表连接,所以在 FROM 子句后可以省略 INNER 关键字,只使用 关键字 JOIN。同时有多个表时,也可以连续使用 INNER JOIN 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
语法
#连接两个表中字段记录相等的数据记录方法一:
SELECT * FROM 表名1 别名1 INNER JOIN 表名2 别名2 ON 别名1.列名 = 别名2.列名;
select * from test1 A inner join test2 B on A.name=B.name;SELECT * FROM 表名1 INNER JOIN 表名2 ON 表名1.列名 = 表名2.列名;
select * from test1 inner join test2 on test1.name=test2.name;方法二:
select * from test1 A, test2 B where A.name=B.name;
2.左连接
左连接也可以被称为左外连接,在 FROM 子句中使用 LEFT JOIN 或者 LEFT OUTER JOIN 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
select * from test1 left join test2 on test1.name=test2.name;左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL。3.右连接
右连接也被称为右外连接,在 FROM 子句中使用 RIGHT JOIN 或者 RIGHT OUTER JOIN 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
select * from test1 right join test2 on test1.name=test2.name;在右连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹 配的行,这些记录在左表中以 NULL 补足存储过程⭐⭐⭐
1.存储过程是一组为了完成特定功能的SQL语句集合; 两个点 第一 触发器(定时任务) 第二个判断
2.存储过程可以加快数据库的处理速度,增强数据库在实际应用中的灵活性。存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。
操作数据库的传统 SQL 语句在执行时需要先编译,然后再去执行;所以相比来说存储过程在执行上速度更快,效率更高。
存储过程的优点:
(1)执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
(2)SQL语句加上控制语句的集合,灵活性高
(3)在服务器端存储,客户端调用时,降低网络负载
(4)可多次重复被调用,可随时修改,不影响客户端调用
(5)可完成所有的数据库操作,也可控制数据库的信息访问权限
语法:
CREATE PROCEDURE <过程名> ( [过程参数[,…] ] ) <过程体>[过程参数[,…] ] 格式
<过程名>:尽量避免与内置的函数或字段重名
<过程体>:语句
[ IN | OUT | INOUT ] <参数名><类型>示例:
创建存储过程
#将语句的结束符号从分号;临时改为两个$$(可以自定义)
DELIMITER $$
#创建存储过程,过程名为Proc,不带参数
CREATE PROCEDURE Proc()
#过程体以关键字 BEGIN 开始
-> BEGIN
#过程体语句
-> create table mk (id int (10), name char(10),score int (10));
-> insert into mk values (1, 'wang',13);
-> select * from mk;
#过程体以关键字 END 结束
-> END $$
#将语句的结束符号恢复为分号
DELIMITER ;例:
mysql> delimiter $$
mysql> create procedure proc()-> begin-> create table test (id int(10),name char(10),score int(10));-> insert into test values(1,'zhangsan',13);-> select * from test;-> end $$
Query OK, 0 rows affected (0.02 sec)mysql> delimiter ;
调用存储过程
CALL Proc();
例:
call proc();1.存储过程的主体都分,被称为过程体
2.以BEGIN开始,以END结束,若只有一条SQL语句,则可以省略BEGIN-END
3.以DELIMITER开始和结束
mysgl>DEL工M工TER $$ $$是用户自定义的结束符
省略存储过程其他步骤
mysql>DELIMITER ; 分号前有空格查看存储过程
#查看某个存储过程的具体信息
SHOW CREATE PROCEDURE 数据库.存储过程名;
show create procedure proc\G#查看存储过程
SHOW PROCEDURE STATUS ;
show procedure status;#查看指定存储过程信息
SHOW PROCEDURE STATUS like '%proc%'\G;
show procedure status like '%proc%'\G;存储过程的参数
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
即表示调用者向过程传入值,又表示过程向调用者传出值(只能是变量)
示例:
mysql> delimiter @@
mysql> create procedure proc (in inname varchar(40)) #行参-> begin-> select * from info where name=inname;-> end @@
mysql> delimiter @@
mysql> call proc2('wangwu'); #实参
+--------+-------+---------+
| name | score | address |
+--------+-------+---------+
| wangwu | 80.00 | beijing |
+--------+-------+---------+
1 row in set (0.00 sec)修改存储过程
ALTER PROCEDURE <过程名>[<特征>... ]
ALTER PROCEDURE GetRole MODIFIES SQL DATA SQL SECURITY INVOKER;MODIFIES SQLDATA:表明子程序包含写数据的语句
SECURITY:安全等级
invoker:当定义为INVOKER时,只要执行者有执行权限,就可以成功执行。删除存储过程
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。DROP PROCEDURE IF EXISTS Proc;
drop procedure if exists proc;相关文章:

【MySQL】5、MySQL高阶语句
一、常用查询(增、删、改、查) 对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等 模板表: 数据库有一张info表,记录了学生…...

【Linux】redhat7.8配置yum在线源【redhat7.8镜像容器内配置yum在线源】通用
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...

强大的处理器和接口支持BL304ARM控制器
在智慧医疗领域,BL304可以用于实现医疗设备的智能化、远程监控和数据交换。在智慧电力领域,BL304可以帮助实现电网的智能化管理,提升电力供应的效率。在智慧安防领域,BL304可以实现智能监控、智能门锁等应用,保障安全。…...
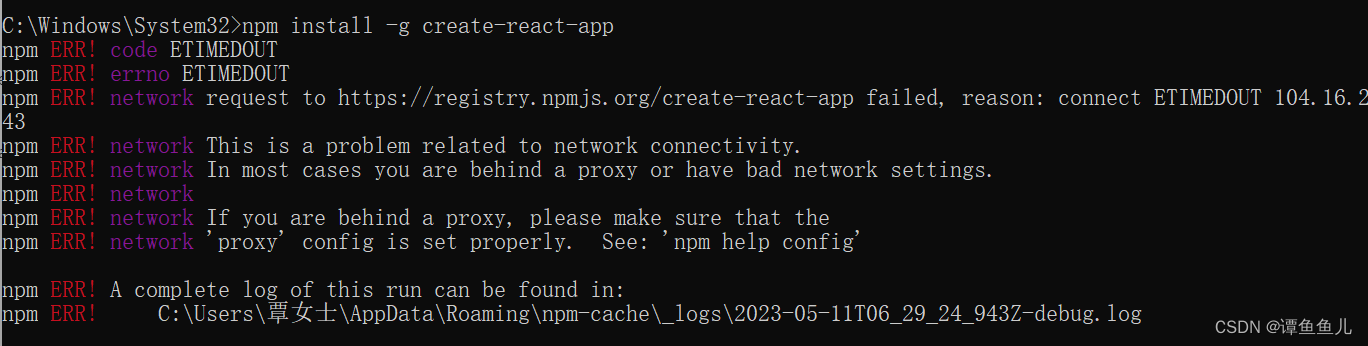
react 基础知识(一)
1、 安装1 (版本 react 18) // 安装全局脚手架(create-react-app基于webpackes6) npm install -g create-react-app //使用脚手架搭建项目 create-react-app my-app // 打开目录 cd my-app // 运行项目 npm start2、初体验 impo…...

SpringBoot整合JUnit、MyBatis、SSM
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 SpringBoot整合 一、SpringBoot整合JUnit二、Spri…...
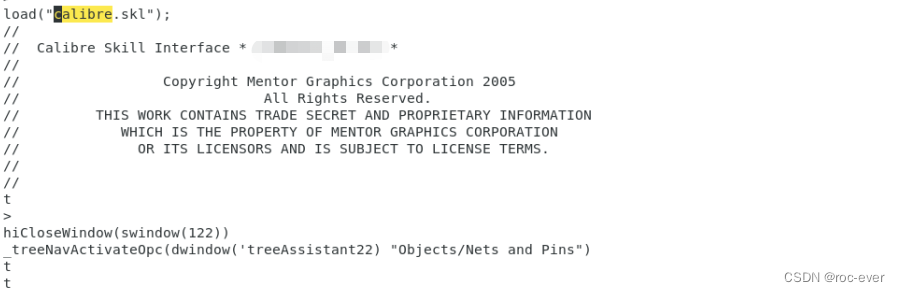
virtuoso61x中集成calibre
以virtuoso618为例,在搭建完电路、完成前仿工作之后绘制版图,版图绘制完成之后需要进行drc和lvs【仅对于学校内部通常的模拟后端流程而言】,一般采用mentor的calibre来完成drc和lvs。 服务器上安装有virtuoso和calibre,但是打开la…...

com.google.guava:guava 组件安全漏洞及健康分析
组件简介 维护者google组织许可证类型Apache-2.0首次发布2010 年 4 月 26 日最新发布时间2023 年 8 月 1 日GitHub Star48189GitHub Fork10716依赖包28,694依赖存储库219,576 Guava 是 Google 的一组核心 Java 库,其中包括新的集合类型(例如 multimap 和…...

Hadoop服务脚本
#!/bin/bash process("NameNode" "SecondaryNameNode" "DataNode" "NodeManager" "ResourceManager") JAVA_HOME"/opt/software/jdk1.8.0_371" HADOOP_HOME"/opt/software/hadoop-3.3.6"# 定义颜色的AN…...
[QT]设置程序仅打开一个,再打开就唤醒已打开程序的窗口
需求:speedcrunch 这个软件是开源的计算器软件。配合launch类软件使用时,忘记关闭就经常很多窗口,强迫症,从网上搜索对版本进行了修改。 #include "gui/mainwindow.h"#include <QCoreApplication> #include <…...
 Oracle篇)
数据库(二) Oracle篇
Oracle SQL常用函数 概述 SQL函数有单行函数和多行函数,其区别为: 单行:输入一行,返回一行,如字符、数字、转换、通用函数等多行:输入多行,返回一行,也称为分组函数、组函数、聚合函数,且多行函数会自动滤空 单行函数 字符函数 CONCAT(…...

TDengine函数大全-目录
TDengine函数大全 详情见具体页面,点击进入。 1.数学函数 ABSACOSASINATANCEILCOSFLOORLOGPOWROUNDSINSQRTTAN 2.字符串函数 CHAR_LENGTHCONCATCONCAT_WSLENGTHLOWERLTRIMRTRIMSUBSTRUPPER 3.转换函数 CAST TO_ISO8601TO_UNIXTIMESTAMPTO_JSON 4.时间和日期…...

代理模式之静态代理
代理模式是一种常见的设计模式,它允许一个对象(代理对象)代表另一个对象(真实对象)进行操作。在软件开发中,代理模式被广泛应用于各种场景,例如网络请求的代理、权限控制的代理等。 静态代理是…...
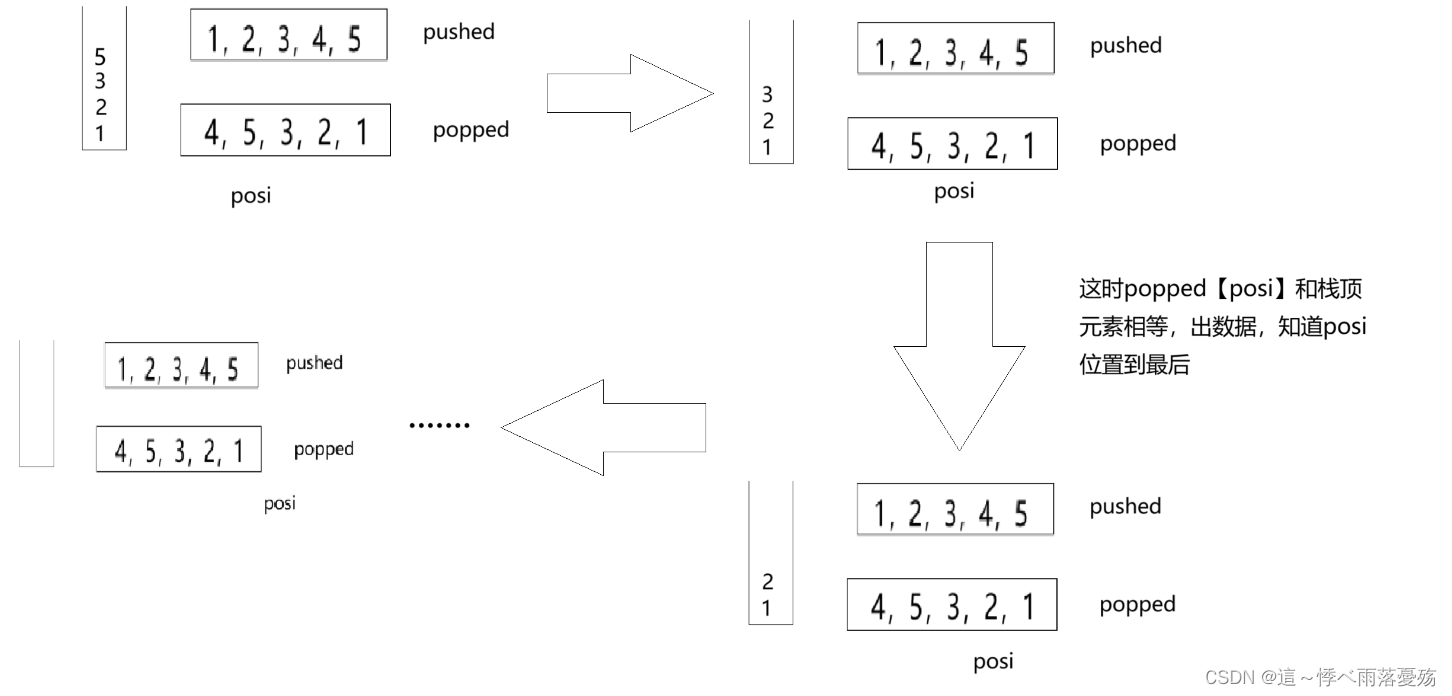
LeetCode——栈的压入、弹出序列
这里我用下面的例子子来讲解一下模拟栈的实现。 例子1:pushed [1,2,3,4,5] popped [4,5,3,2,1] 思路:第一步:我们先创建一个栈,然后将pushed的数据压进去 第二步:判断! 当压入栈的数据和popped第一个数据…...

Flutter 逆向安全
前言: 前几天在 "学习" 一个项目, 发现是用 Flutter 开发的。之前研究过 flutter 的逆向,早期 Flutter 有工具可以通过快照进行反编译:《对照表如下》 新的版本开发者没有维护了。 目前没有很好的工具 可以对 Flutter 进…...
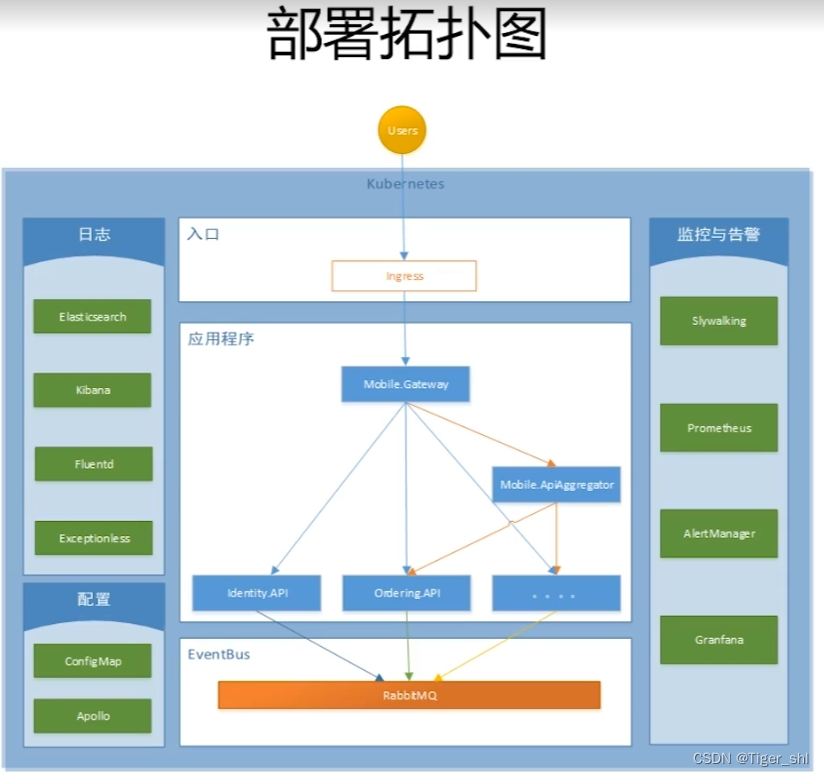
【微服务部署】01-Kubernetes部署流程
文章目录 部署1. Kubernetes是什么2. Kubernetes的优势3. 环境搭建4. 应用部署 部署 1. Kubernetes是什么 Kubernetes是一个用于自动部署、扩展和管理容器化应用程序的开源系统 2. Kubernetes的优势 自动化容器部署资源管理与容器调度服务注册发现与负载均衡内置配置与秘钥…...
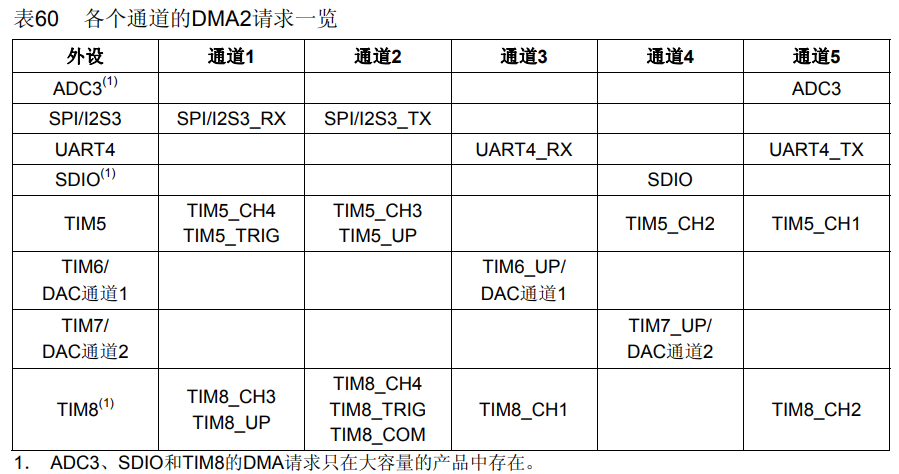
SPI3+DMA外设驱动-TFTLCD初始化
前言 (1)本系列是基于STM32的项目笔记,内容涵盖了STM32各种外设的使用,由浅入深。 (2)小编使用的单片机是STM32F105RCT6,项目笔记基于小编的实际项目,但是博客中的内容适用于各种单片…...

通过chatgpt 学习React的useEffect
定义: useEffect 是 React 中的一个 Hook,它用于处理函数组件中的副作用操作。副作用操作可以包括数据获取、订阅事件、定时器等。 useEffect 接受两个参数:第一个参数是一个回调函数,用于执行副作用操作;第二个参数…...

rabbitMq介绍及使用
点击跳转https://blog.csdn.net/qq_43410878/article/details/123656765...

rabbitmq载在.net中批量消费的问题记录
背景 最近遇到了一个问题,在使用rabbitmq的时候出现了丢消息、消息重复消费等一系列的问题,使用的是.net框架,背景是高并发压力下的mq消费,按理说即使队列中堆了几百条消息,我客户端可以同处理5个消息。 原因是多线程…...

【RPC 协议】序列化与反序列化 | lua-cjson | lua-protobuf
文章目录 RPC 协议gRPCJSON-RPC 数据序列化与反序列化lua-cjsonlua-protobuf RPC 协议 在分布式计算,远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调…...

APK Installer:重新定义Windows运行Android应用的突破性方案
APK Installer:重新定义Windows运行Android应用的突破性方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows系统上运行Android应用的传统方案往往…...

AI+HR 全生命周期智能管理实战指南:从概念到落地,解锁组织效能新增长!
在企业数字化转型的浪潮中,人力资源管理正经历着前所未有的变革。据行业数据,61% 的 HR 领导者已进入 GenAI 实施进阶阶段,82% 的企业计划在 12 个月内部署 AI 智能体,而 AI 驱动的企业人均效能已实现3.2 倍提升。当传统 HR 深陷事…...

Nodejs开发者三步接入Taotoken,实现异步聊天补全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs开发者三步接入Taotoken,实现异步聊天补全 对于使用Node.js进行开发的工程师来说,无论是构建前端应用…...

Taotoken API Key的权限管理与审计日志功能初探
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key的权限管理与审计日志功能初探 对于将大模型能力集成到业务流程中的团队而言,API Key的安全管理与操作…...

ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动
ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 当智能音箱对你说"不…...

利用Taotoken模型广场为不同AI应用场景挑选最合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI应用场景挑选最合适的模型 在构建AI驱动的应用时,一个常见的挑战是如何为不同的功能模块…...

做网安的这几年,挖漏洞接私活赚的是我工资的3倍,这些门道没几人知道
前言 这是我做网络安全工程师(简称网安)的第9个年头,从我工作的第3年起,我就一直在开始尝试去接网安方面的私活,这6年平均下来,我接私活赚的钱几乎是我工资的3倍。 而很多人要么不敢去做,要么就…...

如何让直播输入可视化:input-overlay终极指南
如何让直播输入可视化:input-overlay终极指南 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 想象一下,当你在直播中展示行云流水的操作时&#…...
步骤)
【文档编辑】打印小册子(一张A4纸4页内容)步骤
效果如下,使用“A4纸”打印变成“每一页是A5大小的翻页小册子”1、打开word格式说明书,另存为pdf格式(如果文件是pdf格式忽略步骤1) 2、用wps打开pdf文件 3、打印→打印方式:小册子→小册子子集:仅正面→装…...

G-Helper终极指南:华硕笔记本性能控制革命性突破
G-Helper终极指南:华硕笔记本性能控制革命性突破 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...