深入篇【C++】set和map(multiset/multimap)特性总结与使用
深入篇【C++】set和map(multiset/multimap)特性总结与使用
- 一.set/multiset总结
- 二.map/multiset总结
- 三.set/map应用
一.set/multiset总结

- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
- 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代(迭代完后有序)。
- set在底层是用二叉搜索树(红黑树)实现的。
底层封装着一个pair类型的对象。这个对象里面存着两个成员变量即key和value。
【函数注意1】
1.set具有排序+去重功能。
2.set的查找函数find:找到了会返回当前结点的迭代器,找不到就会返回最后一个位置的迭代器end()。
3.set还有count函数,这个是用来计算出现的个数的,但对于set而言来说没有用,因为set是去重后,的最后的结果要么是0要么是1,所以count函数还可以用来具有查找功能。
4.count函数主要用于mutilset,mutilset可以允许重复的数据。
5.set与multiset的区别就在于set里面的数据是唯一的,不能出现重复的,是去重的,而multiset是允许出现重复的,不去重的。
【结构注意2】
1. 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value,value>构成的键值对.
2. set中插入元素时,只需要插入value即可,不需要构造键值对。
3. set中的元素不可以重复(因此可以使用set进行去重)。
4. 使用set的迭代器遍历set中的元素,可以得到有序序列
5. set中的元素默认按照小于来比较compare=Less<.T.>
6. set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2n
7. set中的元素不允许修改(为什么---->const修饰)
8. set中的底层使用二叉搜索树即红黑树
二.map/multiset总结
1.在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T> value_type;
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
2.底层封装一个pair类型的成员变量。存储着也是pair类型的对象,当要插入一个数据时,这个对象是pair类型的才可以被插入,所以可以使用匿名对象的形式插入
dict.insert(pair<string, string>("run", "启动"));
也可以使用一个make_pair(T,T)函数来返回pair<.T>类型的对象
dict.insert(make_pair("string", "字符串"));
还可以以一种隐式类型转化的方式插入
dict.insert({ "int","整形" });
这里会将这个数组类型转化成pair类型,怎么转化的?调用pair的构造函数,C++11支持双参构造函数调用时会发生隐式类型转化。
3.使用迭代器访问的不是真正的数据,而是pair类型的对象,所以要真正的访问数据,还需要进一步访问。而且第一个数据是不能被修改的,只能访问,第二个数据可以被修改可以被访问。
map<string, string>::iterator it = dict.begin();while (it != dict.end()){//it是迭代器就相当于指针//正常是*it就是解引用到要访问的对象了,但这里的对象是pair不可以直接打印cout << (*it).first << (*it).second << endl;//it->first ="xxx";第一个数据不能被修改//it->second = "xxxx";第二个数据可以被修改cout << it->first << it->second << endl;//可以直接通过指针访问到里面的数据++it;}
4.对于map来说也是具有排序和去重功能,而且当插入相同的值。并不会插入进去,不会覆盖原来的数据。
5. 在内部,map中的元素总是按照键值key进行比较排序的。key是无法被修改的,而value的值可以被修改。
6. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
7. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
8. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。只不过与正常的下标访问不同,而是传key值,给你返回的是value值的引用。[ ]的本质就是通过insert完成的。
insert的返回值是pair<iterator,bool>
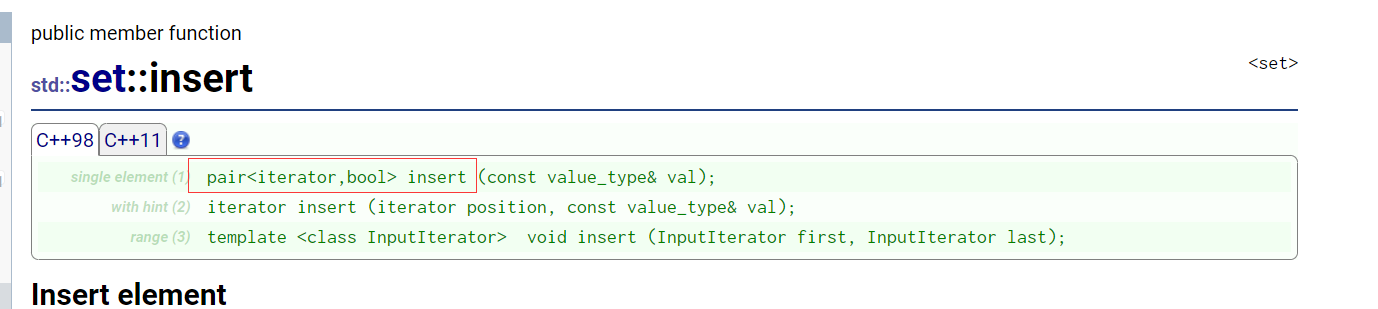
①当key在树里面,返回的是pair<在树里面key对于结点的iterator,false>。
②当key不在树里面,返回的是pair<刚插入树里面对应结点的iterator,true>。
所以[]里面其实具有两个功能,一是将数据插入进去,二是返回对应key的value值的引用。
V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.iterator->second;}
map<string, string>kv;kv.insert(make_pair("apple", "苹果"));kv.insert(make_pair("yellow", "黄色"));kv.insert(make_pair("insert", "插入"));//[ ]具有读取value的功能//跟正常的[]类似,只不过map的[]读的是value值cout << kv["apple"] << endl;kv["sort"];//插入一个空valuekv["sort"] = "排序";//修改kv["man"] = "男人";//插入+修改
【注意】
1. map中的的元素是键值对
2. map中的key是唯一的,并且不能修改
3. 默认按照小于的方式对key进行比较
4. map中的元素如果用迭代器去遍历,可以得到一个有序的序列
5. map的底层为平衡搜索树(红黑树),查找效率比较高 O ( l o g 2 N ) O(log_2 N) O(log2N)
6. 支持[]操作符,operator[]中实际进行插入查找。而multimap是不支持[],因为multimap一个key值可能对应多个value值,所以不知道返回哪一个了。
三.set/map应用
1.计算水果个数
void test3()
{string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };//map的find查找特点:当找到要要的key值后,会返回对应key-value的迭代器//如果没找到就会返回最后一个位置的后一个迭代器即end()map<string, int> count;for (auto e : arr){auto ret = count.find(e);if (ret == count.end())//说明树里没有,那就插入进去,并给1{count.insert(make_pair(e, 1));}else//说明找到了,那就将对应的数字++{ret->second++;}}for (auto e : count){cout << e.first << ":" << e.second << endl;}}
另一种计算方法
for (auto e : arr){count[e]++;//实现的原理://第一步先插入,第二步返回value值//如果不存在就插入,并且value值就是匿名对象对应类型的缺省值,然后++就变成1// 如果存在插入也没事,不会覆盖,返回value }

2.两个序列的交集

思路
1.两个序列中可能存在多个相同的数,但最终结点只会有一个,所以需要先去重,这就需要使用set。使用完set后,序列就变得有序了。
2.两个有序序列如何找交集呢?
交集:两个序列同时从头开始遍历,较小的一方就++,相同的就是交集然后再同时++。
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {//首先要考虑两个序列都去重,那就都放进set里。set<int> s1(nums1.begin(),nums1.end());set<int> s2(nums2.begin(),nums2.end());//去重+排序vector<int> v;auto it1=s1.begin();auto it2=s2.begin();while(it1!=s1.end()&&it2!=s2.end()){if(*it1<*it2){it1++;}else if(*it2<*it1){it2++;}else {v.push_back(*it1);it1++;it2++;}}return v;}
};
3.前K个高频单词

要求获取前k个出现最多的单词,不过这里还有个要求,当出现的次数相同时,就要按照字典序排序。
思路:
1.统计出现的次数我们可以利用map来统计。
2.再对根据出现的次数进行排序。选出前K个单词
3.不过这里的问题是当次数相同时,如何按照字典序再排序?
4.我们想map统计完后,单词的顺序是排序好的,每个单词的个数可能相同也可能不同。但如果当单词个数不相同时,对出现的个数排序就可以完成任务,因为没有出现相同的频率,但如果单词个数出现相同时,排序完后,如果它们的相对顺序没有被改变,那么也可以完成任务,因为相对顺序就是按照字典序排的,所以这个排序得要求是稳定的。
5.还有如何进行比较排序呢?我们需要使用仿函数来修改比较规则。根据次数进行比较,并且进行降序排序。
class Solution {
public://要求先按照频率由高到低排序也就是出现的次数,如何统计出现的次数呢?用map统计次数struct Greater//仿函数重构比较方式,利用出现的次数进行比较,并且降序排,大的在前面,小的在后面{bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2){return kv1.second>kv2.second;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countmap;for(auto &e:words){countmap[e]++;}//已经统计完次数了接下来就要按照出现的频率来排序,不过map其实已经按照字典序的排序方法将数据排好//只要要按照频率排序后稳定性不变,相对顺序不变就可以了,但sort稳定性不行//注意sort无法对map排序,所以我们可以将map里的数据放进vector里vector<pair<string,int>> v; v(countmap.begin(),countmap.end());stable_sort(v.begin(),v.end(),Greater());//stable_sort排序比较稳定vector<string> vs;for(int i=0;i<k;i++){vs.push_back(v[i].first);//选取前k个单词}return vs;}
};
还有一种方法,可以直接使用sort,不用管稳定不稳定,那就是直接更改sort的比较排序规则,除了按照次数进行降序排序外,再添加上,当次数相同时,就按照字典序对单词进行比较。
class Solution {
public://要求先按照频率由高到低排序也就是出现的次数,如何统计出现的次数呢?用map统计次数struct Greater//仿函数重构比较方式{bool operator()(const pair<string,int>& kv1,const pair<string,int>& kv2){return kv1.second>kv2.second||(kv1.second==kv2.second&&kv1.first<kv2.first);//大于就是降序前面大,后面小}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> countmap;for(auto &e:words){countmap[e]++;}//已经统计完次数了接下来就要按照出现的频率来排序,不过map其实已经按照字典序的排序方法将数据排好vector<pair<string,int>> v;v(countmap.begin(),countmap.end());sort(v.begin(),v.end(),Greater());//也可以利用仿函数的比较规则来使用sort排序,首先要按照频率比较,当频率相同时,按照字典序比较vector<string> vs;for(int i=0;i<k;i++){vs.push_back(v[i].first);}return vs;}
};
相关文章:
深入篇【C++】set和map(multiset/multimap)特性总结与使用
深入篇【C】set和map(multiset/multimap)特性总结与使用 一.set/multiset总结二.map/multiset总结三.set/map应用 一.set/multiset总结 set是按照一定次序存储元素的容器在set中,元素的value也标识它(value就是key,类型为T),并且每…...
OpenAI推出ChatGPT企业版,提供更高安全和隐私保障
🦉 AI新闻 🚀 OpenAI推出ChatGPT企业版,提供更高安全和隐私保障 摘要:OpenAI发布了面向企业用户的ChatGPT企业版,用户可以无限制地访问强大的GPT-4模型,进行更深入的数据分析,并且拥有完全控制…...

Linux虚拟机磁盘扩容
Linux虚拟机磁盘扩容 问题起源 在使用linux系统开发时遇到文件无法创建的问题,根据提示发现是磁盘空间不足。 使用df -h查看具体磁盘使用情况。 针对这个问题,有两种解决方案: 使用du -sh ./*可以查看当前工作目录下各文件的占用空间大小…...

【Go 基础篇】Go语言结构体实例的创建详解
在Go语言中,结构体是一种强大的数据类型,允许我们定义自己的复杂数据结构。通过结构体,我们可以将不同类型的数据字段组合成一个单一的实例,从而更好地组织和管理数据。然而,在创建结构体实例时,有一些注意…...

服务器上使用screen的学习记录
服务器上使用screen 训练模型的时候,花费时间是很长的,不可能一直挂在桌面上。所以就想到用screen了。 记录一下简单的操作指令。 创建screen screen -S roof # 新建一个名字为name的窗口,并进入到该窗口中进入后打开环境,运…...

基于Django+node.js+MySQL+杰卡德相似系数智能新闻推荐系统——机器学习算法应用(含Python全部工程源码)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境node.js前端环境MySQL数据库 模块实现1. 数据预处理2. 热度值计算3. 相似度计算1)新闻分词处理2)计算相似度 4. 新闻统计5. API接口开发6. 前端界面实现1)运行逻辑2࿰…...
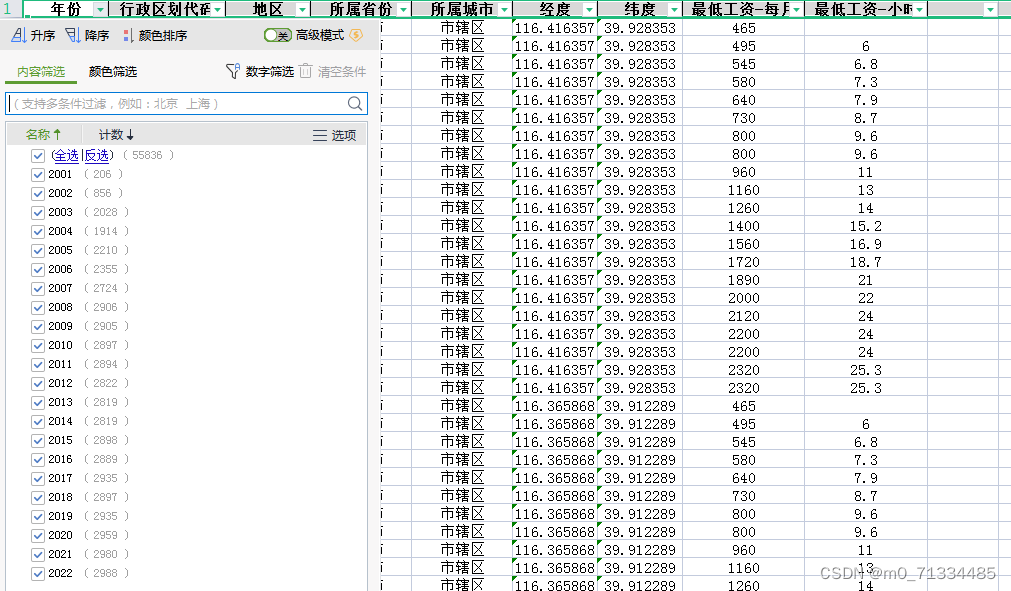
2001-2022年全国各区县最低工资数据
2001-2022年全国各区县最低工资数据 1、时间:2001-2022年 2、来源:人社部 3、指标:年份、行政区划代码、地区、所属省份、所属城市、经度、纬度、最低工资-每月、最低工资-小时 4、样本量:5.5万条 5、指标解释:最低工资标准是…...
D357周赛复盘:模拟双端队列反转⭐⭐+贪心
文章目录 2810.故障键盘1.直接用reverse解决2.双端队列 2811.判断能否拆分数组(比较巧妙的贪心)思路完整版 2812.找出最安全路径2810.故障键盘1.直接用reverse解决2.双端队列 2811.判断能否拆分数组(比较巧妙的贪心)思路完整版 28…...

大数据项目实战(安装Hive)
一,搭建大数据集群环境 1.3 安装Hive 1.3.1 Hive的安装 1.安装MySQL服务 1)检查是否安装MySQL,如安装将其卸载。卸载命令 rpm -qa | grep mysql 2)搜索MySQL文件夹,如存在则删除 find / -name mysql rm -rf /etc/s…...

跨屏无界 | ZlongGames 携手 Google Play Games 打造无缝游戏体验
一款经典游戏,会在时间的沉淀中被每一代玩家所怀念,经久不衰。对于紫龙游戏来讲,他们就是这样一群怀揣着创作出经典游戏的初心而聚集在一起的团队,致力于研发出被广大玩家喜爱的作品。 从 2015 年团队成立,到 2019 年走…...

mysql数据文件
提示:mysql相关系列的教程和笔记不断持续更新和完善 文章目录 db.opt 文件FRM 文件MYD 文件MYI 文件IBD 文件和 IBDATA 文件 :ibdata1 ibdata n文件 查看数据文件的位置 获取硬盘中数据存储的位置: SHOW VARIABLES LIKE datadir;db.opt 文件 该文件记录…...
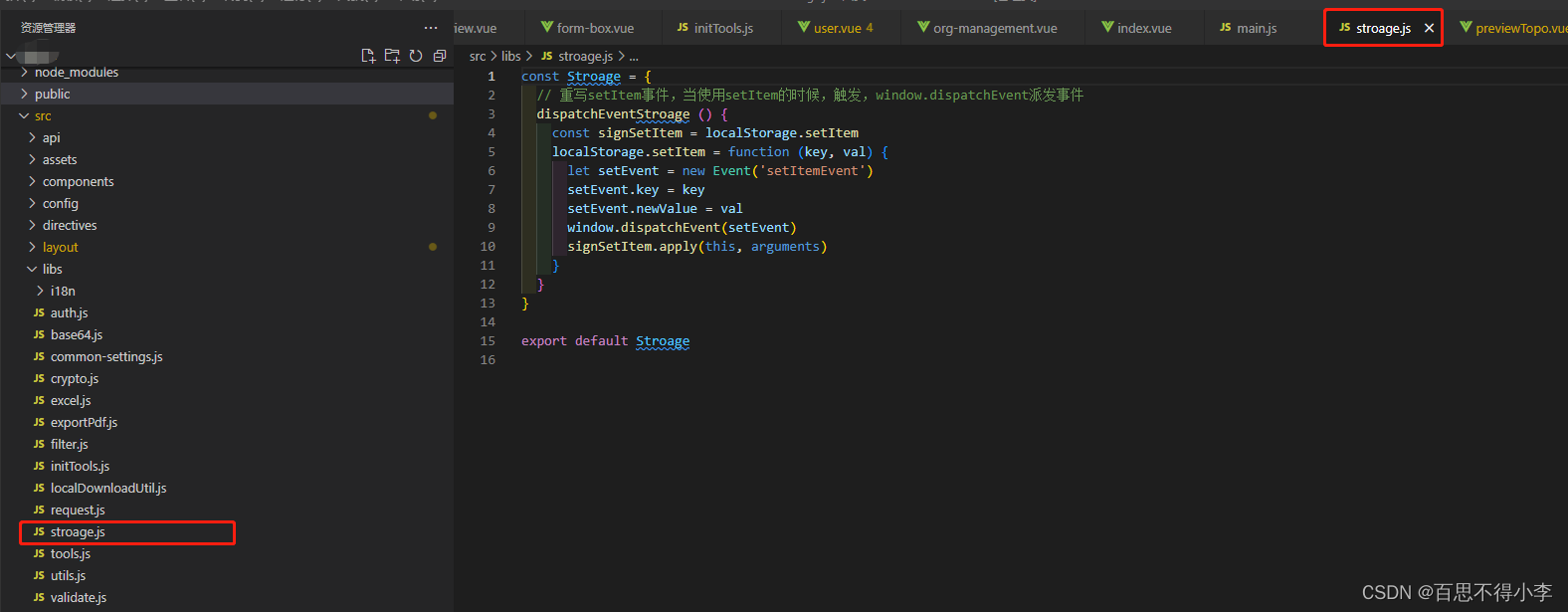
Vue2里监听localstorage里值的变化
有的时候,我们需要根据本地缓存在localstorage里值的变化做出相应的操作,这就需要我们监听localstorage: 首先,我们在src下的libs文件夹下新建一个stroage.js用于重写setItem事件,当使用setItem的时候,触发,window.dispatchEvent派发事件 const Stroage = {// 重写set…...
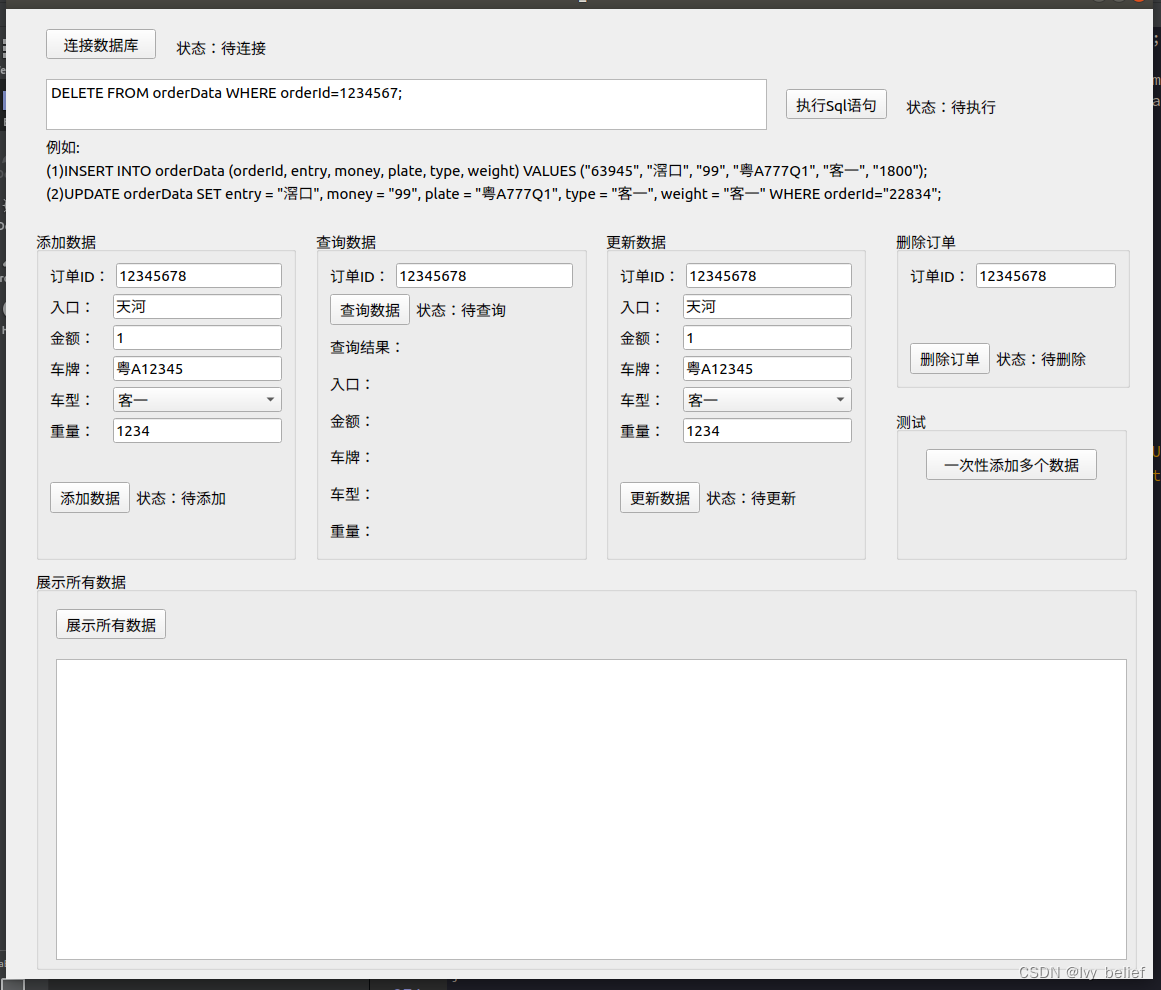
QSqlDatabase(2)实例,QTableView显示数据库表数据
目录 前言 1、实现的功能 2、具体的代码实现 前言 想了解QSqlDatabase基本知识的,以及增删改查的用法,可以浏览上一篇文章: QSqlDatabase(1)基本接口,以及(增删改除)的简单实例_Ivy_belief的博客-CSDN…...

vue3 监听props 的变化
再三说明 仅仅个人学习用,不误导别人 我觉得props 会创建对应的属性,去接受这些值,比如传递一个ref的基本值 age props.age age.value 传递一个ref的引用值 person props.person person.value 传递一个reactive的引用值 person props.person…...
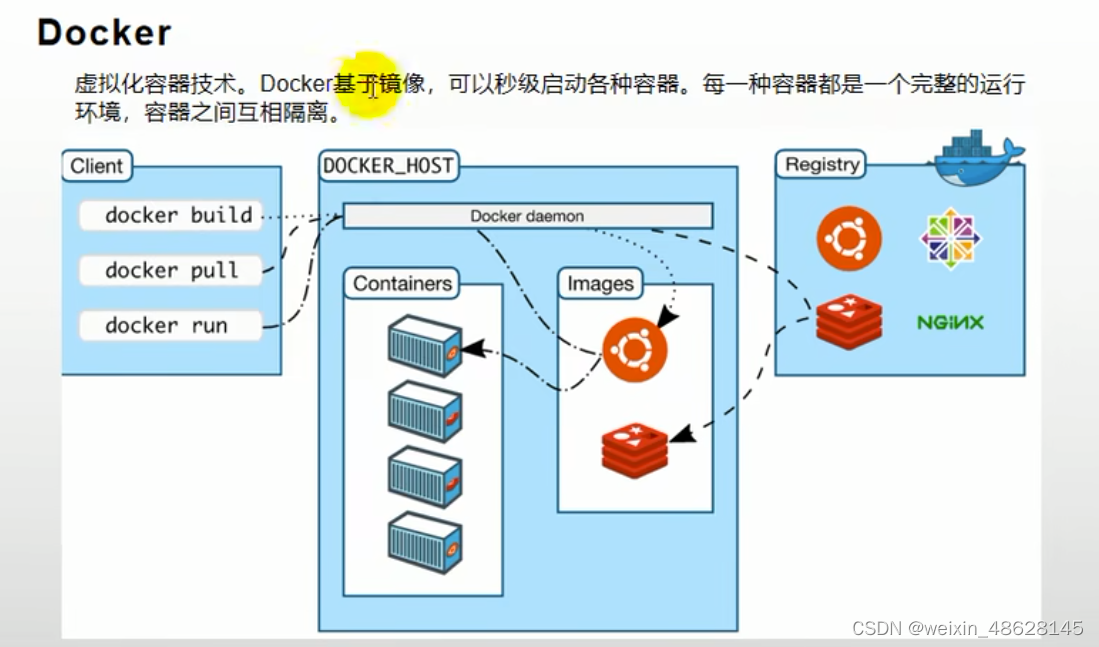
Docker容器
1、什么是docker,为什么要使用docker 有了docker,可以获取各种软件的镜像,将软件的镜像下载到linux中,基于这个镜像就能够去启动这个容器,这个容器就是这个镜像的完整运行环境,比如mysql、redis、nginx,还能秒级启动他…...

spring 请求等问题
1.post请求 /*** desc: (gateway主要接收前端请求 , 然后对请求的数据进行验证 , 验证之后请求反向代理到服务器 。*当请求 method 为 GET 时 , 可以顺利通过gateway 。 当请求 method 为 POST 时 , gateway则会报如下错误 。*jav…...

汽车制造行业,配电柜如何实施监控?
工业领域的生产过程依赖于高效、稳定的电力供应,而配电柜作为电力分配和控制的关键组件,其监控显得尤为重要。 配电柜监控通过实时监测、数据收集和远程控制,为工业企业提供了一种有效管理电能的手段,从而确保生产的连续性、安全性…...

stable diffusion实践操作-VAE
本文专门开一节写图生图相关的内容,在看之前,可以同步关注: stable diffusion实践操作 大部分底模有VAE,但是部分底模没有VAE,需要专门下载VAE才能使用。 最常用的VAE:vae-ft-mse-840000-ema-pruned 用来饱…...
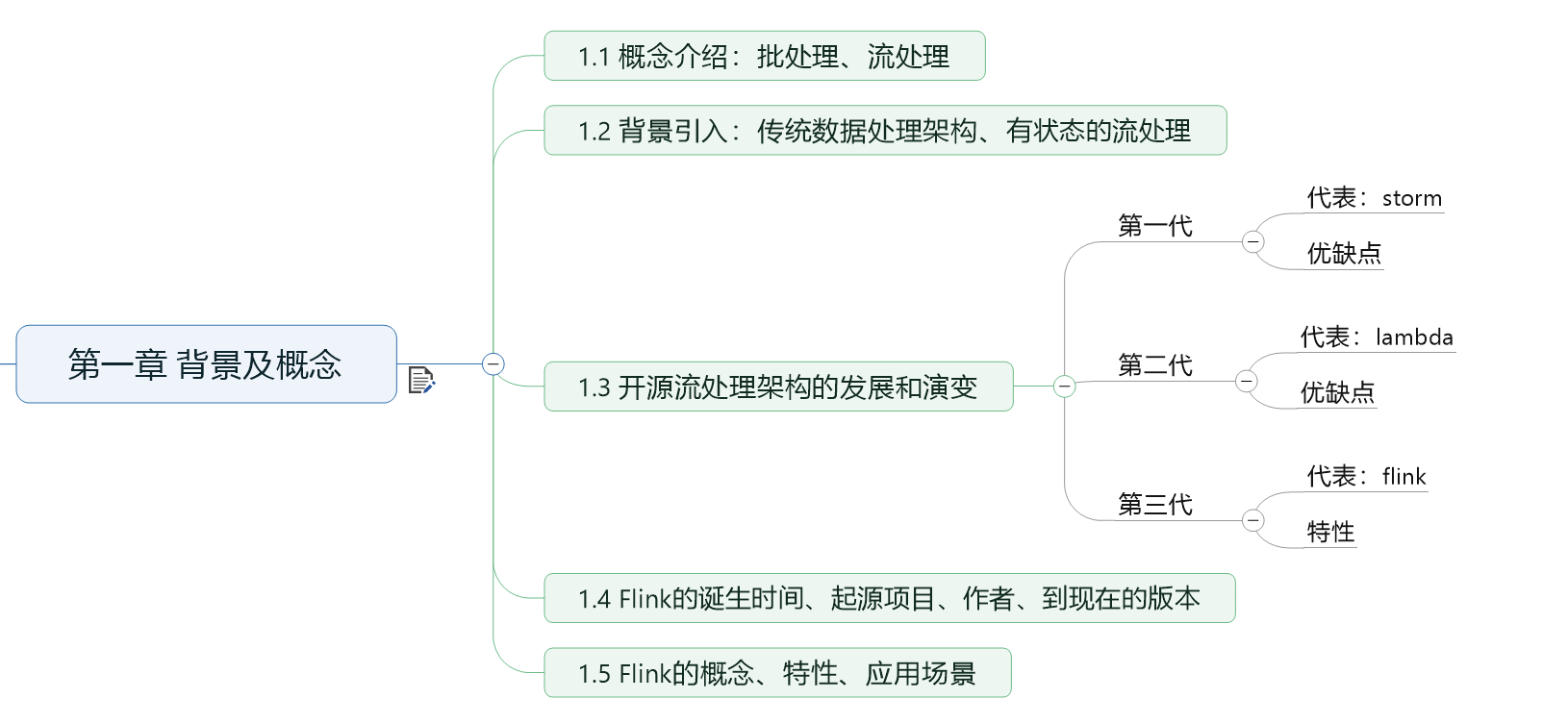
《Flink学习笔记》——第一章 概念及背景
什么是批处理和流处理,然后由传统数据处理架构为背景引出什么是有状态的流处理,为什么需要流处理,而什么又是有状态的流处理。进而再讲解流处理的发展和演变。而Flink作为新一代的流处理器,它有什么优势?它的相关背…...
顺序表链表OJ题(2)->【数据结构】
W...Y的主页 😊 代码仓库分享 💕 前言: 单链表的结构常常不完美,没有双向链表那么”优秀“,所以繁衍出很多OJ练习题。今天我们继续来look look数据结构习题。 下面就是OJ时间!!! …...

工业自动化设备电流检测解决方案——工业控制系统为什么越来越重视隔离电流检测
在工业自动化设备中,电流检测已经成为控制系统的重要组成部分。无论是PLC控制柜、伺服驱动器、工业电源、机器人控制系统还是变频器系统,控制器都需要实时获取负载电流信息,用于过流保护、闭环控制、功率计算以及设备状态监测。但很多工程师在…...

从CDP“3A”到千亿美元目标:联想集团的创新路径与AI原生转型
在全球产业链加速重构、人工智能技术范式快速迭代的背景下,中国企业的创新能力正成为各界关注的焦点。当被问及“哪些中国企业创新做得不错”时,有一家科技企业凭借其在绿色低碳、供应链协同以及混合式人工智能领域的系统性突破,给出了具有说…...

用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定
用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定 在嵌入式开发领域,PWM(脉冲宽度调制)技术堪称"瑞士军刀"般的存在。无论是调节电机转速、控制舵机角度,还是实现LED呼吸灯效果…...

软件测试行业的技术创新:有哪些新兴技术将影响测试行业
一、AI驱动的智能测试:从辅助工具到核心引擎在2026年的软件测试领域,人工智能已经从概念验证阶段全面迈入深度落地期,成为驱动测试效能提升的核心引擎。AI驱动的智能测试正在从多个维度重构传统测试范式。(一)自动化测…...
)
告别手动建模!用Python脚本自动生成Tetgen四面体网格输入文件(附完整代码)
告别手动建模!用Python脚本自动生成Tetgen四面体网格输入文件(附完整代码) 在工程仿真和科学计算领域,四面体网格生成是有限元分析、流体力学模拟等任务的关键前置步骤。Tetgen作为一款开源的四面体网格生成工具,凭借其…...

TWMessageBarManager:iOS系统级通知栏的终极解决方案
TWMessageBarManager:iOS系统级通知栏的终极解决方案 【免费下载链接】TWMessageBarManager An iOS manager for presenting system-wide notifications via a dropdown message bar. 项目地址: https://gitcode.com/gh_mirrors/tw/TWMessageBarManager TWMe…...

React动画革命:react-tween-state 完全指南 - 10分钟掌握React平滑过渡动画
React动画革命:react-tween-state 完全指南 - 10分钟掌握React平滑过渡动画 【免费下载链接】react-tween-state React animation. 项目地址: https://gitcode.com/gh_mirrors/re/react-tween-state react-tween-state 是一款轻量级的 React 动画库ÿ…...

西门子PLC对接须知:从通信到编程的实战指南
在工业自动化领域,西门子S7系列PLC凭借强大的功能和广泛的兼容性,成为众多企业的首选。无论是设备集成、数据采集还是系统升级,掌握PLC对接的核心要点,是保障项目高效落地的关键。本文将从通信连接、编程架构、数据处理三个维度&a…...

机器学习之逻辑回归算法
一、逻辑回归简介 1. 定义 逻辑回归(Logistic Regression)是一种有监督学习算法,主要用于解决二分类问题的统计学习方法。尽管名字中带有“回归”,但它实际上是一种分类算法。 大白话解释 逻辑回归就是一种“做判断题”的算法&…...

C++链接与符号管理
C链接与符号管理链接是将编译后的目标文件组合成可执行程序的过程。理解链接机制和符号管理对于解决链接错误和优化程序结构至关重要。外部链接允许符号在多个翻译单元间共享。#include extern int global_variable; extern void external_function();void external_linkage_ex…...